1. Introduction
Health organizations generate and store large volumes of data every day. Over the years we have observed that the evolution of technology has had an impact on how these data volumes are treated. In recent years, several methods to automate the entire data management and knowledge discovery process has appeared [
1]. The emergence of techniques such as data mining (DM) and its application in the healthcare industry has enabled the improvement of services provided to patients. Saving lives using these methods can be possible now.
One of the main problems found in intensive care units (ICUs) are related to unplanned admissions. There are some solutions to predict readmissions and other critical events, but there is a lack of solutions directed to ICU admissions. The poor selection of patients to be admitted to the ICU is a major cause of hospital resource occupation (beds, doctors, nurses, financial resources, etc.) which could be used with other patients in need. Additionally, ICU extended stays expose patients to infections and inflammations that can aggravate theirs conditions [
2,
3].
Patients can be admitted urgently if they need special care for maintaining the function of their vital organs or because they only need to be monitored continuously for a given period of time and being treated according to their clinical status [
3].
Through the predictive feature of data mining techniques, there are projects that allow the anticipation of critical events [
4], such as a patient’s readmission [
5,
6], among others. Another possibility is the use of clustering techniques to find patterns in data by creating natural groups with similar characteristics. This is the main goal of the paper.
Clustering techniques were applied to data extracted from a Clinical Decision Support System called INTCare being used in the ICU of Centro Hospitalar do Porto, in Portugal. These data were structured in different scenarios, using two different data mining tools (Orange, version 2.7, Bioinformatics Lab at University of Ljubljana, Slovenia; RapidMiner, version 7.4, RapidMiner, Inc., Boston, MA, USA) and different evaluation methods: silhouette, inter-cluster distance, and distance to centroids,
K-means, and Davies–Bouldin index. Clustering techniques were used in this work, which originated from a prior application of classification techniques. In addition, it allowed identifying some useful variables for the application of classification techniques [
7]. The data used are the same before admission. It was intended to create patterns that that allow understanding of the patient condition at admission (using data collected during the patient stay in hospital). This situation allows the clinician to easily understand if a patient has, or does not have, similar values that were presented by the clusters created. These data are stored in the electronic health record during patient admission in other services. The values are combined and humans cannot make all of the combinations without the use of a machine. Another goal of this work is alerting the clinicians to the patient’s condition. For example, the patient can have five days before ICU admission due to transplant or surgery. These data are stored in the database and, when the patient is admitted to the ICU, they are considered. When a patient is outside the ICU and has some of these values, the clinician will be alerted when there is a match of some patient conditions (outside the ICU) with another patient admitted earlier to the ICU.
All of this work is framed in INTCare research work. Several studies were performed using other tools and algorithms. This paper presents a particular part of that research work.
The best scenario used only three attributes, since the others had a negative impact on the results. The best results had a silhouette of 1, inter-cluster distance of 1.5, and distance to centroids of 6.2 × 10−17.
This document is divided into five sections. The first is the introduction of the problem and the topics that will be discussed during the paper are described. The second section provides a background, presenting the basic concepts involved in this work. The third section is the Study Description where the tools and techniques used in this work are identified, and the business understanding, data understanding, and preparation, modeling, and evaluation are presented. The fourth section is a discussion of the findings. This section presents some interesting analytical points about the results achieved within this work. The fifth section provides the achieved conclusions, with the results obtained, and where further work is introduced.
3. Study Description
3.3. Data Understanding and Data Preparation
The data were extracted from the ICU of Centro Hospitalar do Porto, using the Agency for Integration, Diffusion and Archive of Medical Information (AIDA) platform, and comes from three tables. One is composed of 12 attributes and contains data about the hospital admission of patients between 30 June 2006 and 18 February 2016. The second table is composed of eight attributes and contains information about admissions to the ICU, for example, the identification of the bed and the patient identification number, among others. The third table is composed of 53 attributes and contains clinical data about the patients admitted to the ICU. In order to understand the data, an exploration of all attributes was made. The attributes were characterized by function, type, and value ranges.
From the table containing data from hospital admissions, 86.6% of the patients were previously admitted to the ICU.
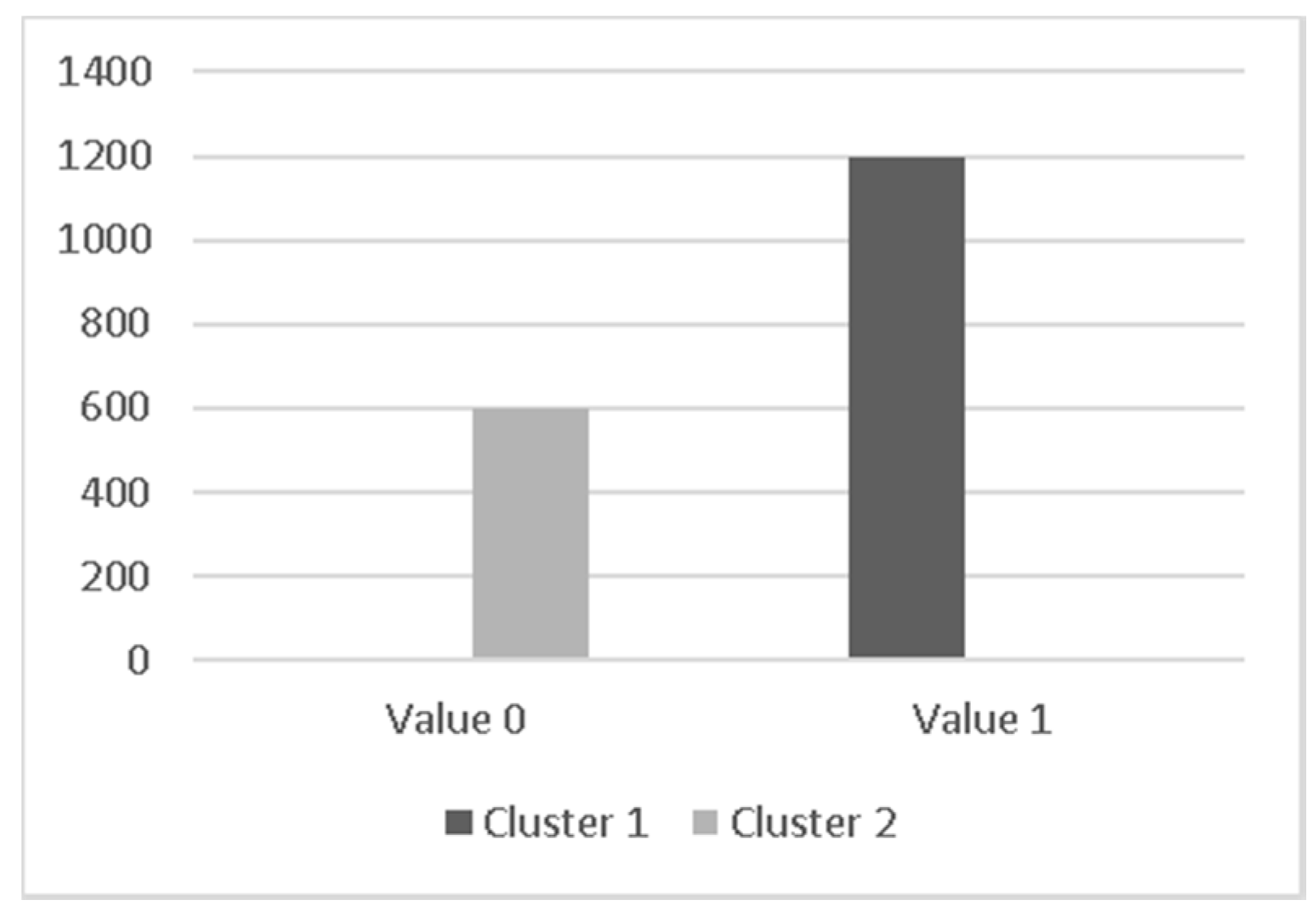
Patients’ gender analysis is represented in
Table 1. By using the sex attribute, it was possible to determine that the most predominant patients where male, both at hospital admission and ICU admission.
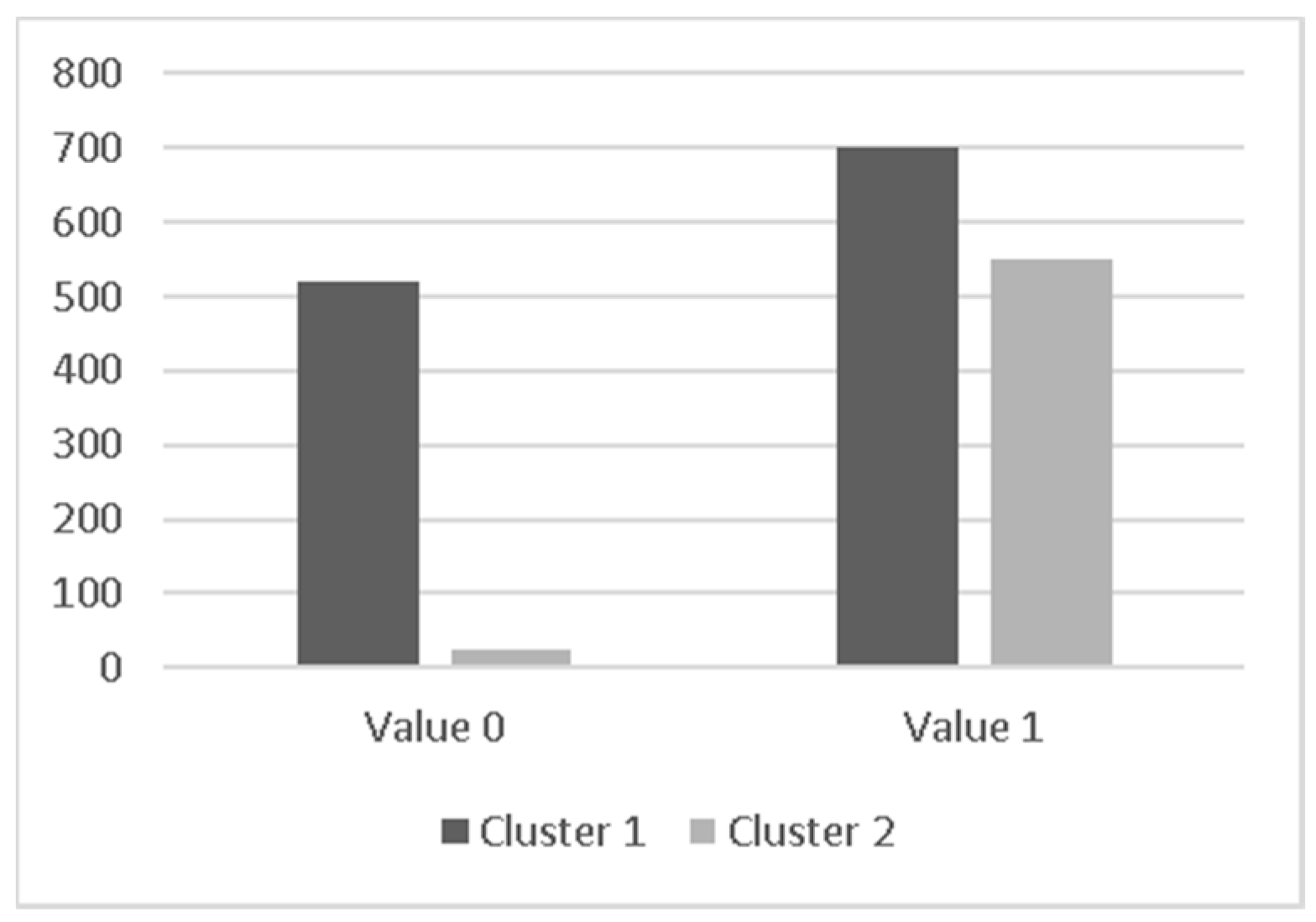
Analyzing patient’s birth dates, it was possible to make a statistical analysis. As can be understood through
Table 2, both at hospital and ICU admission 13 was the minimum patient’s age and the mode is also 75 for both locales. Analyzing the others measures, the ages do not differ much.
Considering the ICU admitted patients, most of them where admitted after surgery from an operating room and with urgency.
For patients who were hospitalized more than one day, the maximum number of days of hospitalization was 894, probably for some comatose patients; 1281 patients were hospitalized for one day, this being the most frequent number of days of hospitalization. The average number of days of hospitalization is about five days.
The dataset used in the modeling phase include only clinical data about patients admitted to the ICU, which is composed of several attributes that were used in the modeling phase:
VA: GLAGOW_HOSPITAL: classify the patients accordingly to Glasgow Coma Scale at the hospital;
VB: GLASGOW_SERVICE: classify the patients accordingly to Glasgow Coma Scale at the service;
VC: DEAF: indicates if the patient is deaf;
VD: MUTE: indicates if the patient is mute;
VE: BLIND: indicates if the patient is blind;
VF: Allergy: indicates it the patient has any allergy;
VG: RESPIRATORY: indicates if the patient has some respiratory problems;
VH; PACEMAKER: indicates if the patient has a pacemaker;
VI: PSYCHIC DESABILITY: indicates if the patient has physical disability;
VJ: PHYSIC DESABILITY: indicates if the patient has any physical disability;
VK: ALCOHOLISM indicates if the patient has alcoholism problems;
VL: DRUG ADDICT: indicates if the patient has some problem with drugs;
VM: ATTRIBUTE H: hospital attribute (confidential);
VN: ATTRIBUTE S: hospital attribute (confidential);
VO: LIVER CHRONIC INSUFFICIENCY: indicates if the patient is suffering from chronic liver insufficiency;
VP: CHRONIC RENAL FAILURE: indicates if the patient is suffering from chronic renal failure;
VQ: CARDIAC INSUFFICIENCY: indicates if the patient is suffering from cardiac insufficiency;
VR: CHRONIC RESPIRATORY FAILURE: indicates if the patient is suffering from chronic respiratory failure;
VS: COPD: indicates if the patient has chronic obstructive pulmonary disease
VT: HEMATOLOGIC DISEASE: indicates if the patient has some kind of hematologic disease;
VU: CORTICOSTEROID THERAPY: indicates if the patient is having some corticosteroid therapy;
VV: HTN: indicates if the patient has hypertension;
VW: AVC sequelae: indicates if the patient has any AVC sequelae;
VX: DIABETES: indicates if the patient has a treated or untreated diabetes;
VY: PROVENANCE: indicates where the patient comes from;
VZ: TYPEOFADMISSION: is the admission type and indicates if the patient were admitted urgently or if it was planned;
VAA: TYPEOFADMISSIONSURGERY: indicates if the patient was admitted after surgery or not;
VAB: TRANSPLANTED: indicates if the patient was admitted after transplantation;
VAC: RISK: indicates if the patient had Stroke sequelae, transplantations, arterial hypertension, chronic renal insufficiency, chronic, cardiac, or chronic respiratory insufficiency or not;
VAD: NEOPLASMS: indicates if the patient has any tumor or cancer, metastasized or not;
VAE: CHEMOTHERAPY: indicates if the patient had any chemotherapy treatment or not;
VAF: RADIOTHERAPY: indicates if the patient had any radiotherapy treatment or not; and
VAG: OTHERIMUNOSSUPRESSANT: indicates if the patient had any other immunosuppressant treatment or not.
Due to the large number of used attributes, only the attributes of the best results of the modeling phase will be demonstrated. The distribution of values from the attributes with the best results are presented in
Table 3.
To verify data quality, a search for errors, data omissions, and data integrity was conducted, and then several solutions to correct the errors were proposed. The errors encountered were blank spaces, where data was not filled in by doctors or writing errors occurred.
Next step it was to convert false and true values to 0 and 1, correspondingly, to simplify the clustering process in the used tools. After this process, the best solutions were applied and the data were corrected, so they would be ready for the data mining process.
In addition to data correction, the attributes were analyzed and weighted for their importance for clustering analyses. From this point, some of the attributes were not included into the clustering due to their insignificance. For example, data referring to the bed identification number or the patient identification number assigned by the hospital are meaningless attributes. It is important to note that only data from admitted patients was used.
The total of attributes that composed the dataset after the data preparation phase were 34.
Acknowledgments
This work has been supported by Compete: POCI-01-0145-FEDER-007043 and FCT within the Project Scope UID/CEC/00319/2013.
Author Contributions
This work was developed under the Ana Ribeiro master degree Work under the supervision and collaboration of Filipe Portela, Manuel Santos, and Fernando Rua. José Machado and António Abelha contributed to this work through the development of some features in AIDA platform. All authors have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Milovic, B.; Milovic, M. Prediction and decision making in Health Care using Data Mining. Kuwait Chapter Arab. J. Bus. Manag. Rev. 2012, 1, 126. [Google Scholar] [CrossRef]
- Arabi, Y.; Venkatesh, S.; Haddad, S.; Malik, S.A.; Shimemeri, A.A. The characteristics of very short stay ICU admissions and implications for optimizing ICU resource utilization: The Saudi Experience. Int. J. Qual. Health Care 2004, 16, 149–155. [Google Scholar] [CrossRef] [PubMed]
- Ramon, J.; Fierens, D.; Güiza, F.; Meyfroidt, G.; Blockeel, H.; Bruynooghe, M.; Van Den Berghe, G. Mining data from intensive care patients. Adv. Eng. Inform. 2007, 21, 243–256. [Google Scholar] [CrossRef]
- Silva, Á.; Cortez, P.; Santos, M.F.; Gomes, L.; Neves, J. Rating organ failure via adverse events using data mining in the intensive care unit. Artif. Intell. Med. 2008, 43, 179–193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Braga, P.; Portela, F.; Santos, M.F.; Rua, F. Data Mining to Predict Patient’s Readmission in Intensive Care Units. In Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART 2014), Loire Valley, France, 6–8 March 2014.
- Veloso, R.; Portela, C.F.; Santos, M.F.; Silva, Á.; Rua, F.; Abelha, A.; Machado, J. Categorize readmitted patients in Intensive Medicine by means of Clustering Data Mining. Int. J. E-Health Med. Commun. 2015, in press. [Google Scholar]
- Ribeiro, A.; Portela, F.; Santos, M.F.; Machado, J.; Abelha, A.; Martins, F.R. Predicting Patients admission in Intensive Care Units using Data Mining. POLIBITS 2017, in press. [Google Scholar]
- Avaliação da Situação Nacional das Unidade de Cuidados Intensivos—Relatório Final. Available online: https://www.sns.gov.pt/wp-content/uploads/2016/05/Avalia%C3%A7%C3%A3o-nacional-da-situa%C3%A7%C3%A3o-das-unidades-de-cuidados-intensivos.pdf (accessed on 16 February 2017).
- Portela, F.; Santos, M.F.; Machado, J.; Abelha, A.; Silva, Á.; Rua, F. Pervasive and Intelligent Decision Support in Intensive Medicine—The Complete Picture. In Information Technology in Bio- and Medical Informatics; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Bersten, A.D.; Soni, N. Oh’s Intensive Care Manual; Elsevier Health Sciences: London, UK, 2013. [Google Scholar]
- de Saúde, D.-G.; de Planeamento, D.S. Cuidados Intensivos: Recomendações para o seu Desenvolvimento; Direcção-Geral da Saúde: Lisboa, Portugal, 2003. (In Portuguese) [Google Scholar]
- “Medicine” in Oxford Dictionaries. Available online: https://en.oxforddictionaries.com/definition/medicine (accessed on 17 February 2017).
- Caldeira, V.M.; Silva Júnior, J.M.; Oliveira, A.M.; Rezende, S.; Araújo, L.A.; Santana, M.R.; Amendola, C.P.; Rezende, E. Criteria for patient admission to an intensive care unit and related mortality rates. Rev. Assoc. Med. Bras. 1992, 56, 528–534. [Google Scholar] [CrossRef]
- Xu, R.; Wunsch, D. Clustering; John Wiley & Sons: Hoboken, NJ, USA, 2008; p. 364. [Google Scholar]
- Basu, S.; Davidson, I.; Wagstaff, K. Constrained Clustering: Advances in Algorithms, Theory, and Applications; CRC Press: Boca Raton, FL, USA, 2008; p. 472. [Google Scholar]
- Anderberg, M.R. Cluster Analysis for Applications: Probability and Mathematical Statistics: A Series of Monographs and Textbooks; Academic Press: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Portela, F.; Santos, M.; Machado, J.; Abelha, A.; Silva, Á. Pervasive and Intelligent Decision Support in Critical Health Care Using Ensembles. In Information Technology in Bio- and Medical Informatics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–16. [Google Scholar]
- Marins, F.; Cardoso, L.; Portela, F.; Santos, M.; Abelha, A.; Machado, J. Intelligent Information System to Tracking Patients in Intensive Care Units. In Ubiquitous Computing and Ambient Intelligence. Context-Awareness and Context-Driven Interaction; Springer: Cham, Switzerland, 2013; Volume 8276, pp. 54–61. [Google Scholar]
- Veloso, R.; Portela, F.; Santos, M.F.; Silva, Á.; Rua, F.; Abelha, A.; Machado, J. A Clustering Approach for Predicting Readmissions in Intensive Medicine. Proced. Technol. 2014, 16, 1307–1316. [Google Scholar] [CrossRef] [Green Version]
- Kamath, A.F.; Gutsche, J.T.; Kornfield, Z.N.; Baldwin, K.D.; Kosseim, L.M.; Israelite, C.L. Prospective Study of Unplanned Admission to the Intensive Care Unit after Total Hip Arthroplasty. J. Arthroplast. 2013, 28, 1345–1348. [Google Scholar] [CrossRef] [PubMed]
- Labarère, J.; Schuetz, P.; Renaud, B.; Claessens, Y.-E.; Albrich, W.; Mueller, B. Validation of a Clinical Prediction Model for Early Admission to the Intensive Care Unit of Patients with Pneumonia. Acad. Emerg. Med. 2012, 19, 993–1003. [Google Scholar] [CrossRef] [PubMed]
- Subbe, C.P.; Kruger, M.; Rutherford, P.; Gemmel, L. Validation of a modified Early Warning Score in medical admissions. QJM 2001, 94, 521–526. [Google Scholar] [CrossRef] [PubMed]
- Tsai, J.C.-H.; Weng, S.-J.; Huang, C.-Y.; Yen, D.H.-T.; Chen, H.-L. Feasibility of using the predisposition, insult/infection, physiological response, and organ dysfunction concept of sepsis to predict the risk of deterioration and unplanned intensive care unit transfer after emergency department admission. J. Chin. Med. Assoc. 2014, 77, 133–141. [Google Scholar] [PubMed]
- Van den Bosch, G.E.; Merkus, P.; Buysse, C.M.; Vaessen-Verberne, A.A.; Hop, W.C.; de Hoog, M. Risk Factors for Pediatric Intensive Care Admission in Children With Acute Asthma. Respir. Care 2012, 57, 1391–1397. [Google Scholar] [CrossRef] [PubMed]
- Goldman, L.; Cook, E.F.; Johnson, P.A.; Brand, D.A.; Rouan, G.W.; Lee, T.H. Prediction of the need for intensive care in patients who come to emergency departments with acute chest pain. New Engl. J. Med. 1996, 334, 1498–1504. [Google Scholar] [CrossRef] [PubMed]
- Brunelli, A.; Ferguson, M.K.; Rocco, G.; Pieretti, P.; Vigneswaran, W.T.; Morgan-Hughes, N.J.; Zanello, M.; Salati, M. A Scoring System Predicting the Risk for Intensive Care Unit Admission for Complications after Major Lung Resection: A Multicenter Analysis. Ann. Thorac. Surg. 2008, 86, 213–218. [Google Scholar] [CrossRef] [PubMed]
- Portela, F.; Santos, M.F.; Machado, J.; Abelha, A.; Rua, F.; Silva, Á. Real-time Decision Support using Data Mining to predict Blood Pressure Critical Events in Intensive Medicine Patients. In Ambient Intelligence for Health; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Portela, F.; Santos, M.F.; Silva, Á.; Rua, F.; Abelha, A.; Machado, J. Preventing Patient Cardiac Arrhythmias by using Data Mining Techniques. In Proceedings of the IEEE Conference on Biomedical Engineering and Sciences (IECBES 2014), Sarawak, Malaysia, 8–10 December 2014.
- Pereira, A.; Portela, F.; Santos, M.F.; Abelha, A.; Machado, J. Pervasive Business Intelligence: A New Trend in Critical Healthcare. Proced. Comput. Sci. 2016, 98, 362–367. [Google Scholar] [CrossRef]
- Pereira, A.; Portela, F.; Santos, M.F.; Rua, F. Pervasive Business Intelligence in Intensive Medicine—An overview of clinical solution. 2017; In Submission. [Google Scholar]
- Peixoto, R.; Portela, F.; Santos, M.F. Towards a Pervasive Data Mining Engine—Architecture Overview. In New Advances in Information Systems and Technologies; Springer: Cham, Switzerland, 2016; Volume 445, pp. 557–566. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).





 and
and 


{kind=link}
{kind=link}