1. Introduction
With the advance of technology, the volume of data collected and stored to attend society’s new requirements and services has increased significantly. Thus, it is practically unfeasible to analyze this large volume of data without the support of techniques of knowledge extraction and representation. One of the techniques that can be used to process and analyze information is the
Formal Concept Analysis (FCA) [
1].
The FCA is a field of mathematics applied for data analysis where associations and dependencies between instances and attributes are identified from a dataset [
2,
3]. It has been applied in different areas such as text mining [
4], Information Retrieval [
5], linguistics [
6], security analysis [
7], web services [
8], social network analysis [
9,
10,
11], software engineering [
12], Topic Detection [
13], Search engine [
14], among others. In [
15], a comprehensive revision of FCA applications and trends is given.
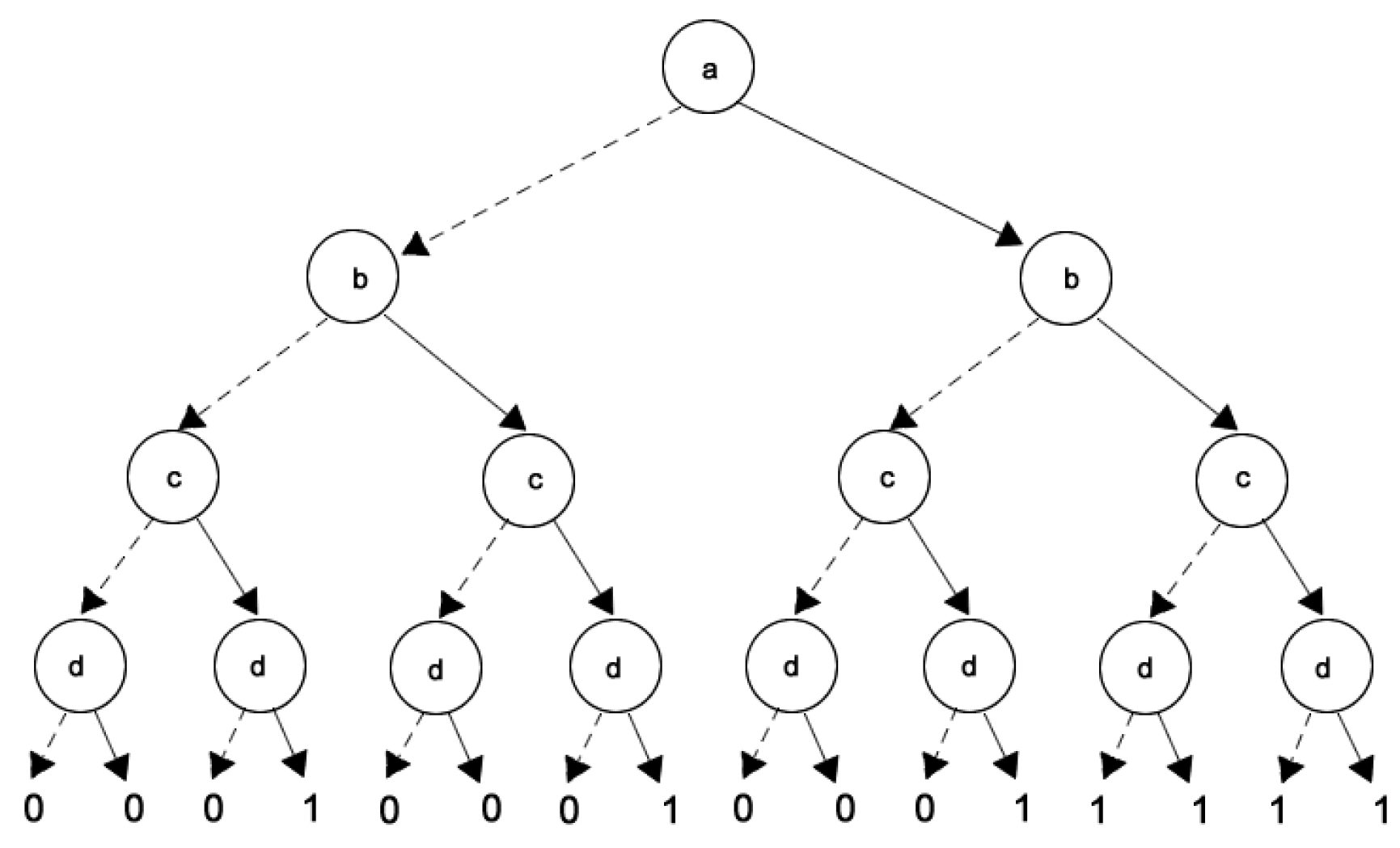
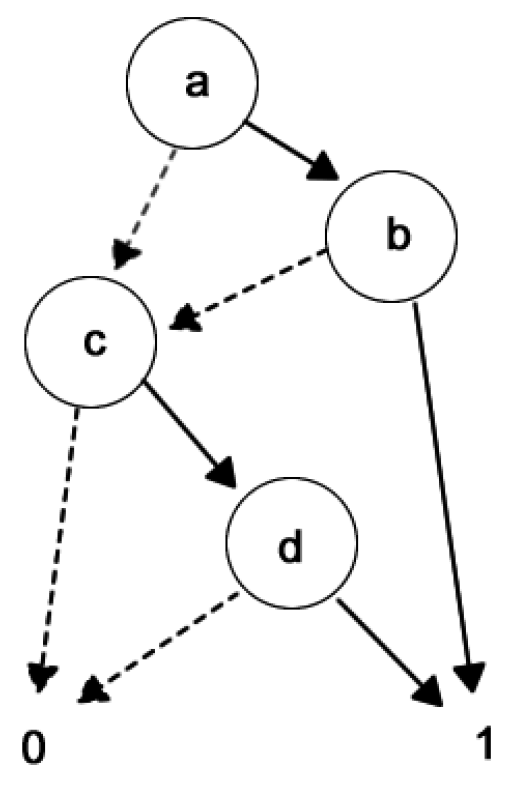
One way to represent a set of data composed of instances is through a formal context
, which is an incidence table composed of objects
, attributes
and the incidence relations
between objects (instances) and attributes. A possible knowledge that can be obtained from the formal context is the set of implications
among the attributes [
16]. The implication
, where
, reveals that
every object containing the attributes belonging to set
A has also the attributes from set
B. The sets
A and
B are called, respectively, premise and conclusion.
Applying different properties to a
set, we can generate implication sets with certain constraints for specific domains. One of these specific sets is the
proper implications set, in which for each implication the premise is minimal and the conclusion is a singleton (unit set) [
17].
The proper implications set is useful because it provides a minimum representation of the data, for applications where the goal is to find the minimum set of attributes to achieve specific purposes. For example, the work developed in [
18] aimed to identify relationships between professional skills of LinkedIn users. The proper implications set was applied to identify the minimum set of skills (premise) that imply in professional competence (conclusion). Minimal path problems, such as finding the best flight routes, can also be solved using proper implication sets. Finally, they can also be applied to infer functional dependencies from relations, since they can be rapidly converted into the structure and used in database design [
19]. In addition, there are different types of rule coverage implemented by different algorithms. The minimum coverage—which contains the least number of rules describing the dataset— can be efficiently obtained, but it demands the use of axioms in order to discover new relations and implication rules. Conversely, the proper coverage makes the relationships more explicit, although it increases the number of rules describing the dataset. In several problems, the volume of data to be manipulated makes the extraction of implications unfeasible. In this article we propose a solution to extract these implications efficiently.
The algorithm originally proposed by [
16], known as
Impec, is a well-known algorithm for obtaining and extracting proper implications from a formal context.
Impec provides implications
, where
and
, in which the left side (premise) is minimal and the right side (conclusion) has only one attribute. From a set of
M attributes the algorithm finds the basis of its proper implications. However, in some cases, it may be desired that only a few attributes be considered for computing an implication, which is not possible in the
Impec algorithm without first generating all implications and then selecting those implications where the desired conclusion is on the right side of the rule.
Unlike
Impec algorithm, which finds its proper implications considering the set of attributes
M with support greater than or equal to 0, the
PropIm algorithm [
18] generates its proper implications (also considering the entire set
M of attributes) but only with support greater than 0. Implications with support equal to 0 are valid implications (obtained from other implications, for example, Armstrong’s axioms); however, in formal contexts, there is no occurrence of such implications.
Different challenges have been proposed by the FCA research community [
20]. One of these challenges is the manipulation of high-dimensional formal contexts such as those with 120,000 instances and 70,000 attributes. High-dimensional formal contexts can be generated from big data problems and they are computationally difficult to handle—most algorithms do not perform adequately in these contexts, because they are usually unable to process large amounts of data.
Although the
Impec and
PropIm algorithms extract the proper implications, the computational performance of these algorithms processing high-dimensional contexts (in the number of instances) becomes impracticable. An algorithm called
ProperImplicBDD, based on the
PropIm [
18], was proposed in [
21]. The
ProperImplicBDD algorithm uses a data structure known as Binary Decision Diagram (BDD) in order to manipulate high-dimensional formal contexts efficiently.
In this article, we introduce a new algorithm named
ImplicPBDD (this being an evolution of the algorithm
ProperImplicBDD [
21]), which is capable of manipulating high-dimensional formal contexts. Both algorithms used the Binary Decision Diagram (BDD) as a data structure. However, the algorithm
ImplicPBDD presents a novel pruning heuristic (described in
Section 4) to find the premises of the implications more efficiently, when compared to [
18,
21].
The main objectives of this study are:
In order to analyse the performance of the ImplicPBDD algorithm, we performed experiments using only synthetic contexts. We have decided to use synthetic contexts instead of real ones in order to control the experiments and produce concrete results regarding algorithm’s performance in high-dimensional contexts, considering the number of instances, because we can control and vary the number of attributes and context density to evaluate our approach. The variations in attributes and densities were used to analyse the time of searches using both algorithms, PropIm and ImplicPBDD.
The number of objects (instances) used in the experiments ranged from 1000, 10,000 and 100,000, partially meeting the challenge stipulated in [
20]. Regarding the densities of the formal contexts, which is the amount of incidence between objects and attributes, they were also varied to verify the impact on the algorithms’ execution times.
Considering that approach, formal contexts with 30%, 50% and 70% density were generated for the experiments, in order to analyse the algorithms’ performances in sparse and non-sparse contexts. The results showed that ImplicPBDD has a better performance—up to 80% faster—than PropIm, regardless of the number of attributes, objects and densities.
In addition, we presented the results obtained with the algorithm ImplicPBDD for a real context based on the social network LinkedIn. The main objective was to determine the minimum skills that a professional must have to reach certain job positions.
This article is organised as follows:
Section 2 presents basic concepts of the FCA and BDD approaches.
Section 3 describes the related works on BDD and implications. In
Section 4, the proposed algorithm is described.
Section 5 contains the experimental methodology, and the evaluation and discussion of the proposed algorithm
ImplicPBDD. In
Section 6, we present the real-world data case study, based on LinkedIn data. Finally,
Section 7 presents our conclusions and future work suggestions.
4. The Proposed Algorithm ImplicPBDD
In order to achieve a better performance than the
PropIm algorithm [
18] when processing larger volumes of data, all
PropIm algorithm methods were previously analyzed. With this analysis, we verified that the function that returned the objects in common from a set of attributes was the most costly part of the algorithm.
In order to optimize this function, we employed BDD to represent the formal context in a more compressed form, and to obtain a better performance in context operations with attributes and objects.
The order of complexity for the extraction of proper rules task is . The order of complexity of the algorithm is exponential. However, an heuristic was implemented to reduce the combinations of attributes in the premises.
The Algorithm uses a heuristic to reduce the combinations of required assumptions to obtain the rules (presented in Algorithm 4) and also the BDD data structure to simplify the representation of a formal context and increase the performance in manipulating objects.
We also created a function—primeAtrSetBDD—to improve the calculation of the similarity among attributes and objects (Algorithm 5). parameters, and returns a BDD containing all objects of M.
A pre-processing step is performed to transform a formal context into its corresponding BDD. For the creation of the BDD representing the formal context, we used the
algorithm, proposed by [
26], as presented and described in Algorithm 1.
The Algorithm 4 receives as input a formal context , and its output is a set of proper implications with support greater than 0.
| Algorithm 4: ImplicPBDD. |
![Information 09 00266 i004]() |
Line 1 initializes the empty set. The following for (lines 2–19) parses each attribute of the M set. Initially, each m attribute can be a conclusion for a set of premises. For each m, the algorithm calculates the premises .
The variable in the primeAtrSetPBDD function receives and stores the BDD containing all objects of the m attribute (line 3). This BDD will be used to verify the equality between the premise BDD () and the conclusion BDD (m). Algorithm 5 describes the primeAtrSetPBDD (ListAttributes) function, which is responsible for getting the BDD containing all objects from the list of attributes passed as parameters.
The P variable stores all the attributes that contain the same objects of m (line 4).
The variable determines the size of each premise. Because the smallest possible size is 1 (an implication of type ), its value is initialized as 1 (Line 5).
A set of auxiliary assumptions that can generate an implication using m as conclusion is stored in (in line 6, is initialized as empty). In lines 8–16, the set of minimum assumptions is found and is limited by |P|. In line 9, the set C gets all combinations of size of elements in P. It receives, as a parameter, the elements in P, , start position of the combination and the list in which the result list of the combinations will be stored.
In line 9, the getP() function uses heuristics to reduce the total number of assumption combinations. Each candidate premise ⊂ is checked to ensure that premise and conclusion m result in a valid correct implication. In case ≠ ∅ and , the premise is added to the set of auxiliary premises , and also the implication {P1 →m} is added to the list of implications line 14.
In Line 10, the set of candidate premises is created through the getCP() function, which obtains all subsets that do not contain an attribute that belongs to the premise. It receives, as a parameter, sets C and and returns a set of D premises.
Note that using the solution proposed in the Algorithm getP(), it is possible to generate a smaller number of combinations for assumptions of a certain size of the variable. During the generation of a given set of assumptions, if a premise attribute to be generated has already been used as an implication for the current conclusion, the generation sequence is discarded improving the final performance of the algorithm. If there is no implication for the current conclusion using the premise attribute, the entire sequence will be generated. The original algorithm always generates all combinations of all premises for all sizes of .
For each candidate premise ⊂, stores the BDD that contains all the objects of the premise. In line 12, a check is made between and to ensure that the premise P1 and conclusion m result in a valid implication. If = the implication is valid. Considering that, the implication is valid, the premise is added to the premises hypothesis and also the implication {P1→m} is added to list of implications line 15.
Algorithm 5 presents the primeAtrSetBDD() function, responsible for obtaining the BDD that contains all objects from the list of attributes informed as a parameter. The function computes the conjunction between the BDD that represents the entire formal context and the BDD of each attribute of the list of attributes. It outputs a BDD containing only the objects that contain all the attributes informed.
| Algorithm 5: primeAtrSetPBDD. |
![Information 09 00266 i005]() |
5. Methodology of Experiments
The methodology we adopted in our study was to use randomly generated synthetic contexts with controlled densities and dimensions in the experiments. The considered contexts had 1000, 10,000 and 100,000 objects, combined with sets of 16 and 20 attributes (eight time more combinations than 16), with densities ranging from the minimum, 30%, 50% and 70% the maximum density for each generated context. For contexts creation, the SCGAz tool [
26] was used, to generate random contexts within the limits of controlled densities and sizes. We also added a time-limit constraint for the time expent extracting the implication rules. This limit was set to up to 3 days, and it was necessary because some experiments performed with the
PropIm algorithm did not return any result or finished execution, even after long periods of processing.
Note that the randomly generated incident table can vary between two contexts with the same dimensions and densities, giving rise to different implication sets. Therefore, a different performance was obtained for each context. For each combination between the number of objects (1000, 10,000 and 100,000), attributes (16 and 20) and density (30%, 50% and 70%), two formal contexts were generated. Since the contexts were randomly generated, initially there was no a set of conclusions. Therefore, each attribute of the context was considered as conclusion in our experiments.
Thus, for the formal context with 16 attributes, for example, we have 16 executions using each attribute as the desired conclusion and the remaining 15 as premises, totaling 32 executions for each combination set.
The main objective of the experiments was to compare the performances of our ImplicPBDD algorithm and the PropIm algorithm, when generating the proper implications sets. As mentioned, the comparisons were made using synthetic contexts where the number of objects, attributes and density were varied.
The algorithms were implemented in Java and executed on an IBM Server (OS Ubuntu 16.04) with an Intel Xeon processor (3.1 GHz) with 4 cores, 32 GB of RAM and 30 GB of SSD storage. We kept the compatibility with the language in which the
PropIm algorithm was written (JAVA). It was used a library that provides support for the BDD in JAVA. The library chosen was JavaBDD [
36] which provides JNI for relevant BDD libraries which are CUDD, BuDDy and CAL [
26].
The experiments with the synthetic contexts allowed for a better control regarding the generation of contexts for analysis. In every experiment, we evaluated the performance of
PropIm and
ImplicPBDD running the same context with a maximum run-time of 3 days to obtain the proper implications set. Our algorithm obtained significant gains in execution time when compared to
PropIm (see
Table 3,
Figure 4 and
Figure 5).
A significant improvement in relation to the execution time is noticeable, when comparing our proposed algorithm to the PropIm algorithm. The results pointed out a run-time gain ranging from 32.1% (1000 objects, 20 attributes and 70% density) to 80.4% (1000 objects, 20 attributes and 30% density), with an average performance gain of 51.6%. In general, the algorithm ImplicPBDD has a better performance for contexts with a low range of density.
It is also possible to observe, based on the gain lines in
Figure 4 and
Figure 5, that the variation in the number of objects did not generate a significant impact in the execution time of the evaluated algorithms, since the increase in the number of objects was not proportional to the increase in execution time. In other words, as we can see by the dotted-line (gain), when the amount of objects increased 100 times, the processing time only increased by less than 30%. However, the execution time of both of the evaluated algorithms tends to grow when we increase the quantity of attributes and, mainly, the density of incidence in the formal context.
The hypothesis raised to explain this observation is that the higher the incidence density of the formal contexts, the greater the quantity of attributes will be used as premises in the implications. To verify this hypothesis, we analyzed the impact of the number of assumptions in the execution time of the algorithms.
Scenarios with 30% of density (incidence of attributes in relation to objects) were the ones that presented the least amount of attributes in the premises, which resulted in the least time spent to find the proper implications set. This occurs because that is the best scenario for the heuristic used in the algorithms presented in this article, since when finding a minimum rule, for example, , no new rule will be generated anymore using the attribute on the left side of the implication.
On the other hand, when we analyzed the scenarios with 70% of density, in general, we found a greater amount of attributes in the premises of the implications, which demands a greater computational effort to find the set of rules of implication.
6. Case Study: LinkedIn
The job market is becoming increasingly competitive, because companies are advancing and demanding highly prepared professionals to fill job positions. Thus, people who are looking for a job opportunity may benefit from help to become potential candidates. Such guidance could be build from a knowledge base composed by the set of competences that people have developed in their actual jobs. One type of information source to build the knowledge base are the on-line professional social networks, where the people made their resume available. The LinkedIn is the largest and most popular on-line professional social network with over 500 millions users [
37]. The network provides a source of information which can be used to build the knowledge base to help job seekers to improve their resume with the competences necessary to achieve an specific job position.
In this case study, the goal is to analyze and represent professional LinkedIn profiles using FCA. This will be done by building a conceptual model, transforming it into a formal context, scraping and pre-processing the data into formal concepts, then finally extracting the implication sets to be analyzed.
Figure 6 presents the flowchart of the process used to compute the proper implications set using our
ImplicPBDD algorithm.
Before building the formal context, it was necessary to define the conceptual model that represents the problem domain. For this purpose, we adopted a
model of competence [
38], where the authors define professionals by their competence in accomplishing a certain purpose. The competence was divided into three dimensions: knowledge, attitudes and skill. Then, following the methodology by [
39], the on-line professional resume categories were mapped into the competence model dimensions, as follows: the academic education information was classified into knowledge dimension, the professional experience was linked to the skill dimension, and the user’s interaction with the network were linked to the attitudes dimension.
After formally representing the problem, the next step was to collect the LinkedIn users’ data. This process was divided into two phases: selecting the initial seeds and collecting the public profiles. It is important to mention that this process was executed from October 2016 to February 2017, and during this period some LinkedIn profiles were publicly available and could be accessed without logging into the network.
The initial seeds was selected randomly following basic definitions such as location and occupation area. An approach named open collection was applied to extract the data of public profiles, because the network did not provide an API (Application Programming Interface) to extract data directly from the server. This process started by accessing the initial seed. In the public profile there is a section denoted “People also viewed”—a list with the ten most similar profiles related to the visited profile [
40]. The automated collector visited these ten profiles, and verified which fit into the collection scope. Valid profiles are stored and each one becomes a new seed to extract new links, restarting the scrapping process until it reaches the stop criteria, which was based on the percentage of new extracted profiles. Each iteration checks if 65% of the profiles were already in the database in the last data collection iteration. If the response is “yes”, the process stops and restarts with a new seed.
From the variables extracted in the data collection phase and the mapping of the informational categories of LinkedIn proposed by [
39], for this paper it was chosen to address only the variables
ability and
experience was sufficient to determine the skills needed to hold professional positions.
7. Conclusions and Future Works
This article contains the proposal of a novel algorithm, ImplicPBDD, for extracting proper implications sets with a better performance than the PropIm algorithm, in high-dimensional contexts considering the number of objects (instances). After the experiments, we realized that the algorithm obtained substantial speed gains.
The proposed algorithm was faster in all contexts used in the experiments. In contexts with 100,000 objects, which is close to the challenge defined in [
20], the
ImplicPBDD algorithm was able to extract the set of proper implication up to 80% faster compared to the
PropIm algorithm.
The ImplicPBDD algorithm only finds implications with support greater than 0, that is, only rules that are present in the formal context (unlike the algorithm Impec). This avoids the generation of rules with support value equal to 0, which are valid but irrelevant in formal contexts.
Considering that we aimed to find proper implications in only a certain number of attributes, that is, it is known a priori which attribute is desired as the conclusion of a rule (as presented in the case study for the LinkedIn dataset), the algorithm proposed in this article demonstrated to be an efficient alternative to determine the proper implications.
An important observation of using a Binary Decision Diagram (BDD) as the data structure was that in denser contexts, as more similar objects exists, the context becomes more optimized and performs better.
In order to compute proper implications from a formal context with a greater number of attributes, we suggest, as a future work, a modification in the algorithm to support distributed computing. Note that, as the number of attributes increases, the required computational time increases substantially. However, the workload can be distributed, i.e., each conclusion can be computed independently.
Additionally, we suggest that ImplicPBDD is evaluated in contexts of real-world problems with greater number of attributes. Since the high-density contexts presented the smallest gains, we suggest modifications in our heuristics to work with dual formal contexts, that is, converting a high density formal context into low density ones.
Real-world problems normally tend to generate low density contexts (sparse). Our experiments showed that our algorithm can be performed in big data environment, with feasible execution time. To illustrate this, for 16 attributes and 10,000 objects, with 30% density, the algorithm needed 3.13 min to find the proper implications set.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}