Effective Intrusion Detection System Using XGBoost



Abstract
:1. Introduction
2. Motivation
3. Literature Review
- XGBoost is approximately 10 times faster than existing methods on a single platform, therefore eliminating the issue of time consumption especially when pre-processing of the network data is done.
- XGBoost has the advantage of parallel processing, that is uses all the cores of the machine it is running on. It is highly scalable, generates billions of examples using distributed or parallel computation and algorithmic optimization operations, all using minimal resources. Therefore, it is highly effective in dealing with issues such as classification of data and high-level pre-processing of data.
- The portability of XGBoost makes it available and easier to blend on many platforms. Recently, the distributed versions are being integrated to cloud platforms such as Tianchi of Alibaba, AWS, GCE, Azure, and others. Therefore, flexibility offered by XGBoost is immense and is not tied to a specific platform, hence the IDS using XGBoost can be platform-independent, which is a major advantage. XGBoost is also interfaced with cloud data flow systems such as Spark and Flink.
- XGBoost can be handled by multiple programming languages such as Java, Python, R, C++.
- XGBoost allows the use of wide variety of computing environments such as parallelization (tree construction across multiple CPU Cores), Out of core computing, distributed computing for handling large models, and Cache Optimization for the efficient use of hardware.
- The ability of XGBoost to make a weak learner into a strong learner (boosting) through its optimization step for every new tree that attaches, allow the classification model to generate less False Alarms, easy labelling of data, and accurate classification of data.
- Regularization is an important aspect of XGBoost algorithm, as it helps in avoiding data overfitting problems whether it be tree based or linear models. XGBoost deals effectively with data-overfitting problems, which can help to deal when a system is under DDoS attack, that is flooding of data entries, so the classifier is needed to be fast (which XGBoost is) and the classifier should be able to accommodate data entries.
- There is enabled cross-validation as an internal function. Therefore, there is no need of external packages to get cross validation results.
- XGBoost is well equipped to detect and deal with missing values.
- XGBoost is a flexible classifier as it gives the user the option to set the objective function as desired by setting the parameters of the model. It also supports user defined evaluation metrics in addition to dealing with regression, classification, and ranking problems.
- Availability of XGBoost at different platforms makes it easy to access and use.
- Save and Reload functions are available, as XGBoost gives the option of saving the data matrix and relaunching it when required. This eliminates the need of extra memory space.
- Extended Tree Pruning, that is, in normal models the tree pruning stops as soon as a negative loss is encountered, but in XGBoost the Tree Pruning is done up to a maximum depth of tree as defined by the user and then backward pruning is performed on the same tree until the improvement in the loss function is below a set threshold value.
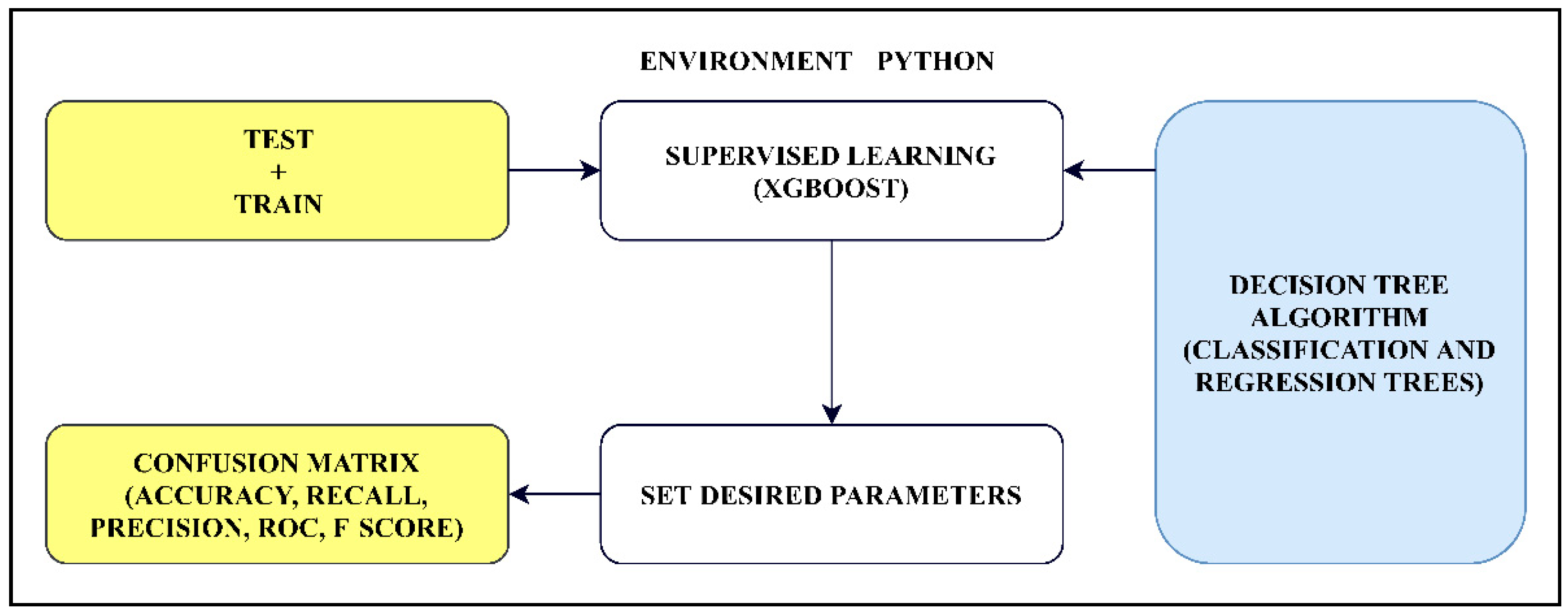
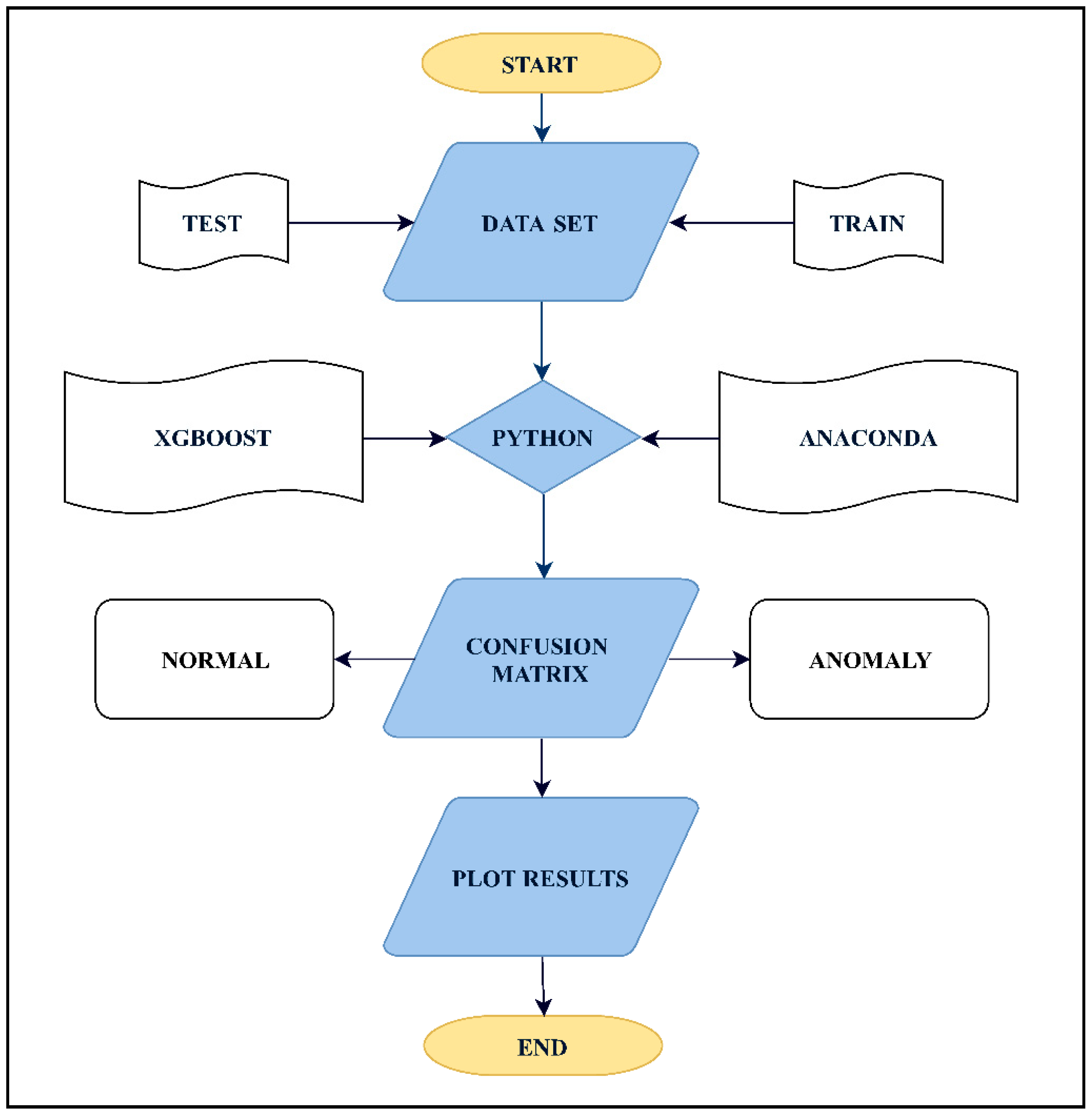
4. Classification Model
5. Theory and Background
5.1. Boosting
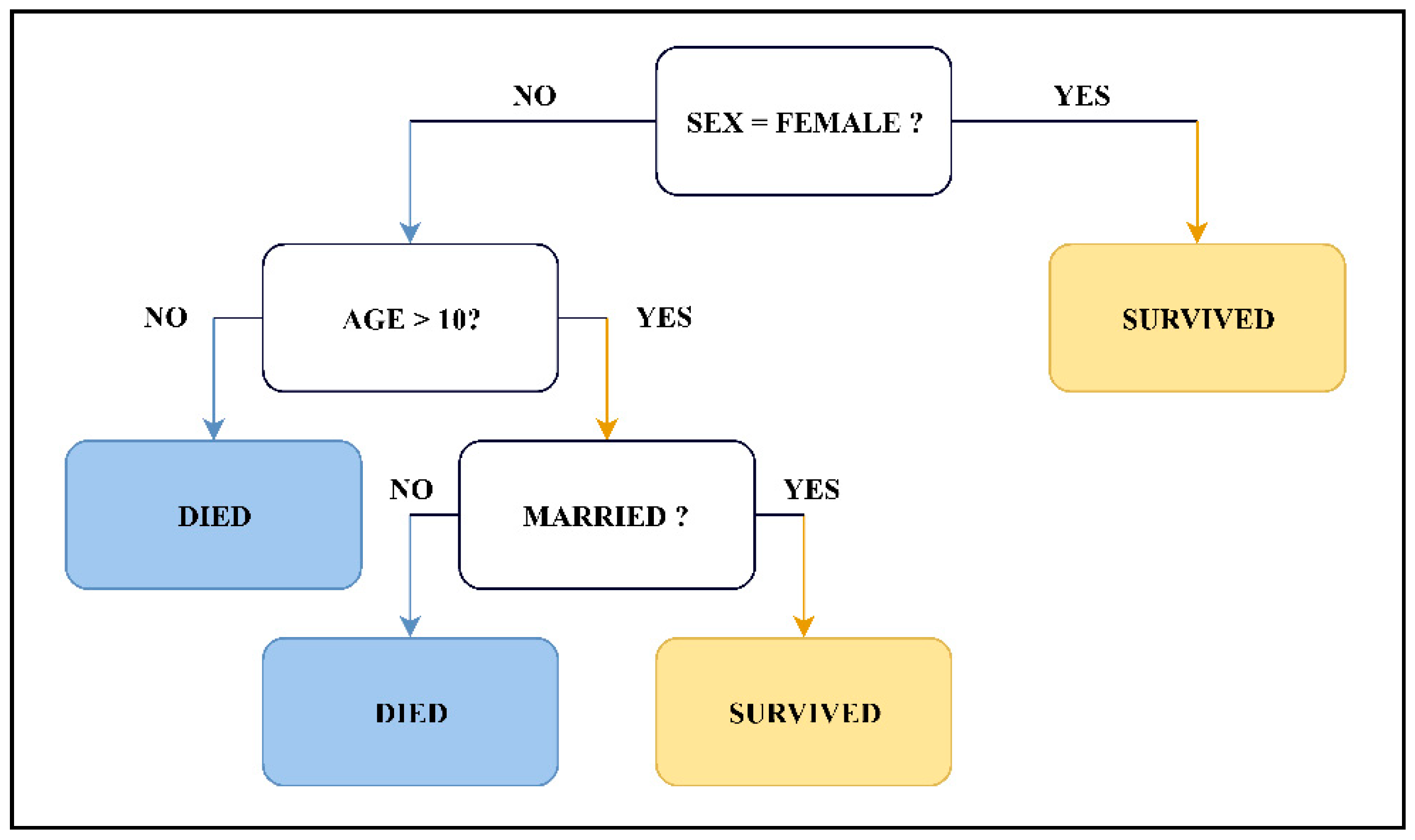
5.2. Decision Trees
5.3. XGBoost
6. Mathematical Explanation
7. Results and Discussion
7.1. Dataset Used
- In KDD dataset, the classifiers showed biasing towards the more frequent records, hence, in NSL-KDD dataset the redundant records in the train set were not included.
- There is no repetition of records even in the test set of NSL-KDD dataset. Therefore, this eliminated the classifiers ability to show deceiving high detection rates courtesy reoccurring records.
- As the number of records for each difficulty level group in NSL-KDD dataset is inversely proportional to the percentage of records in the original KDD dataset; as a result, the NSL-KDD provided a wider range for the classification methods to do detection on. This made NSL-KDD dataset more efficient in classification rates based on different classification methods.
- One major reason to set the classification method on NSL-KDD dataset was to compare it with the previously known results of different classification methods based on NSL-KDD dataset (further elaborated in Table 6 under Section 7.6). This will make the evaluation results more consistent and comparable.
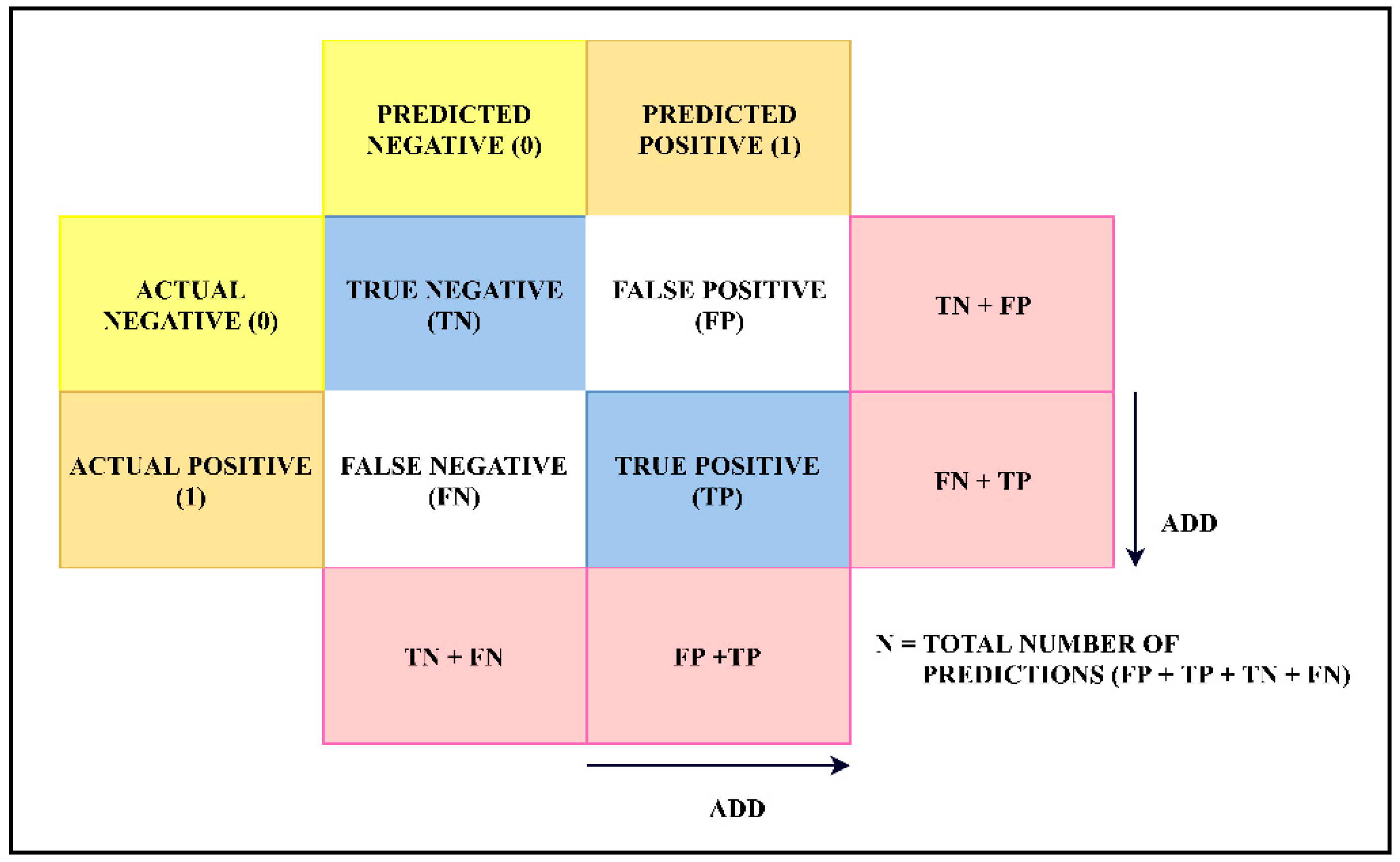
7.2. Confusion Matrix
- The “learning_rate” (also referred to as “eta”) parameter is basically set to get rid of overfitting problems. It performs the step size shrinkage, and weights relating to the new features can be easily extracted (was set as 0.1).
- The “max_depth” parameter is used to define how deep a tree runs: the bigger the value, the more complex the model becomes (was set as 3).
- The “n_estimators” parameter refers to the number of rounds or trees used in the model (was set as 100).
- The “random_state” parameter is also a learning parameter. It is also sometimes referred to as “seed” (was set as 7).
- The “n_splits” parameter is used to split up the dataset into k parts (was set as 10).
- TP = 99.11% (0.991123108469).
- FP = 1.75% (0.0174775758085).
- FN = 0.89% (0.00887689153061).
- TN = 98.25% (0.982522424192).
- Sensitivity = TP/(FN + TP) (also called TPR)= 99.11%.
- Specificity = TN/(TN + FP)= 98.25%
- Therefore, FPR can be calculated:FPR = (1 − specificity)= (1 − 0.9825)= 0.0175
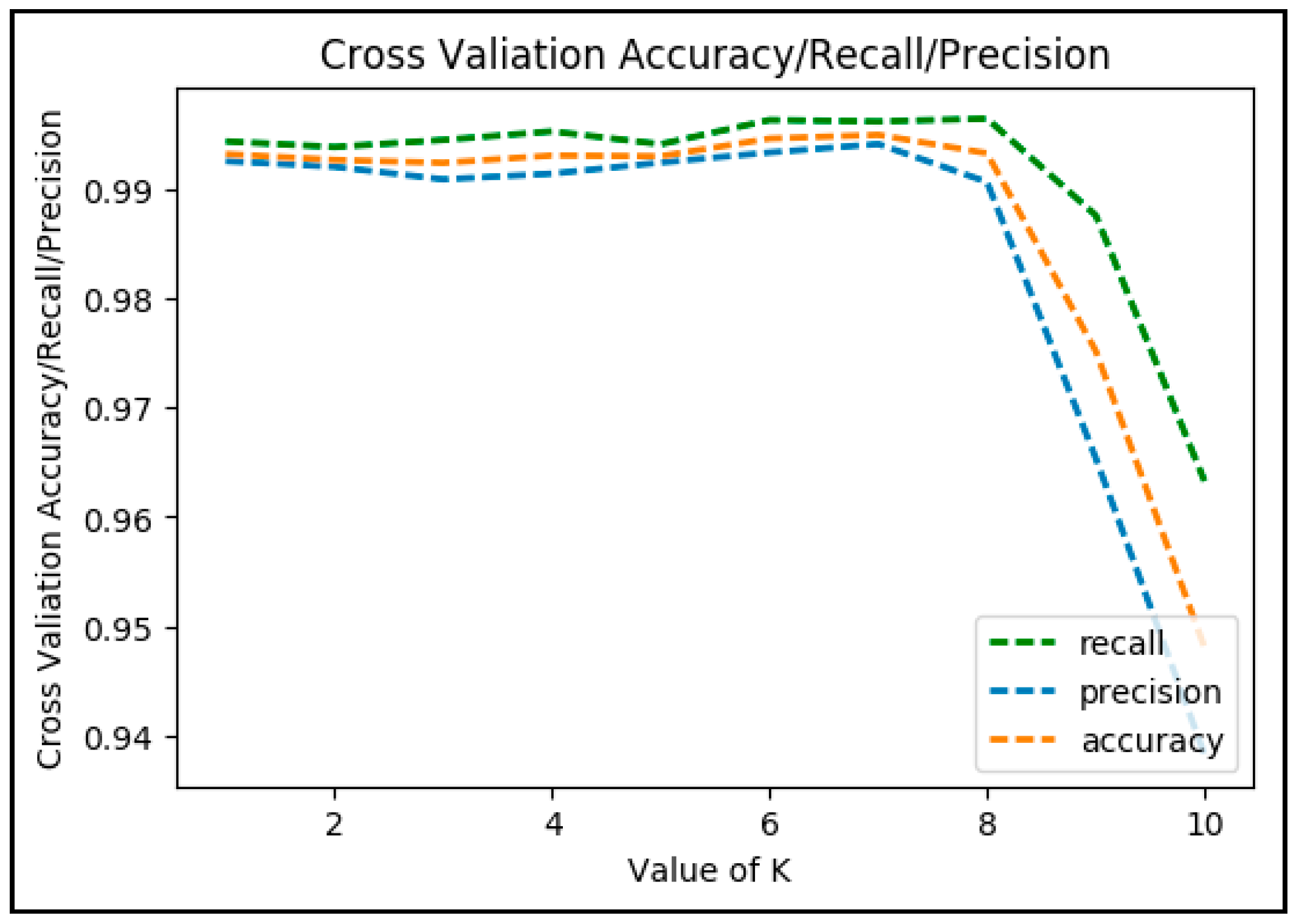
7.3. Accuracy/Recall/Precision
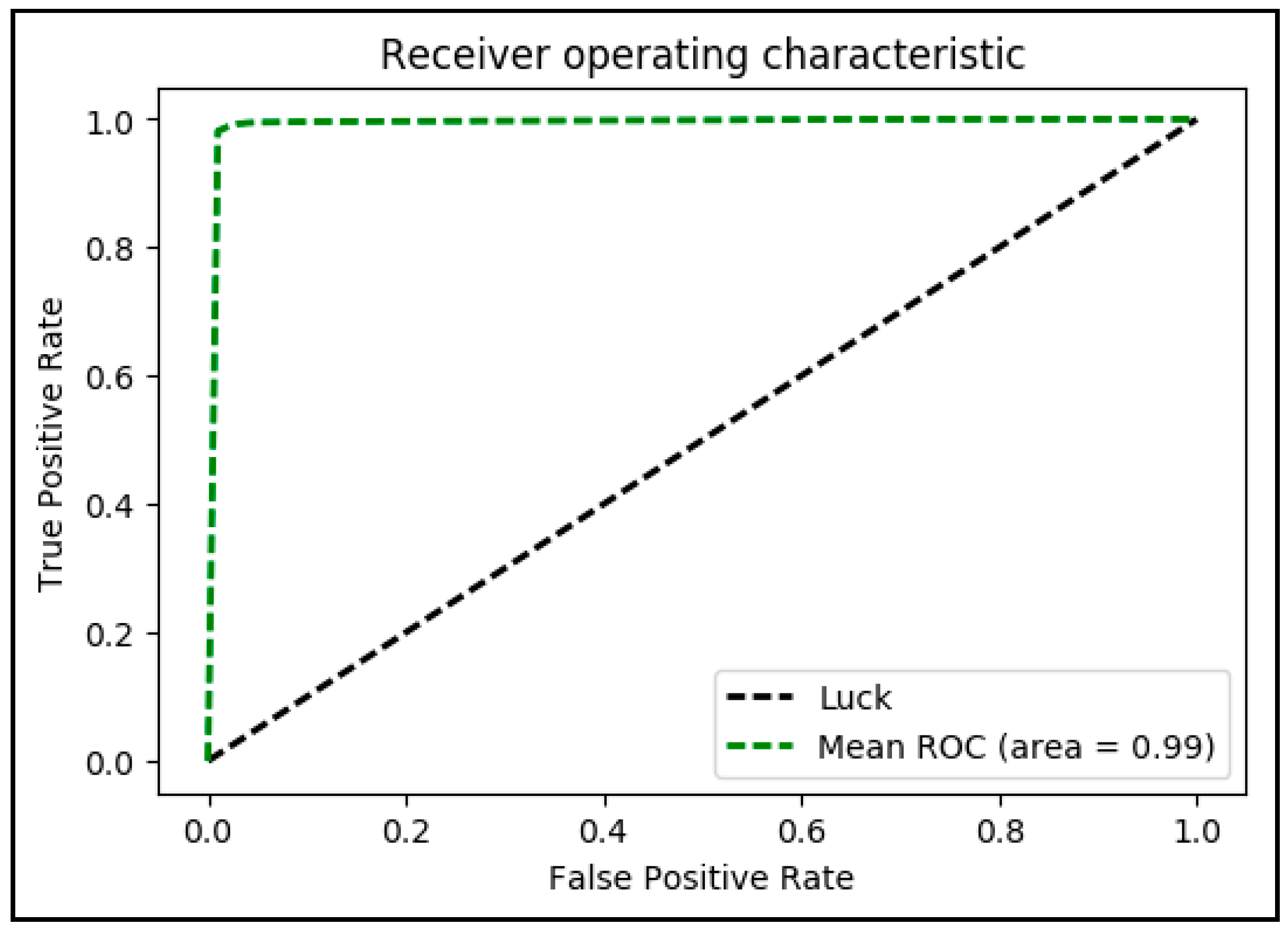
7.4. ROC Curve
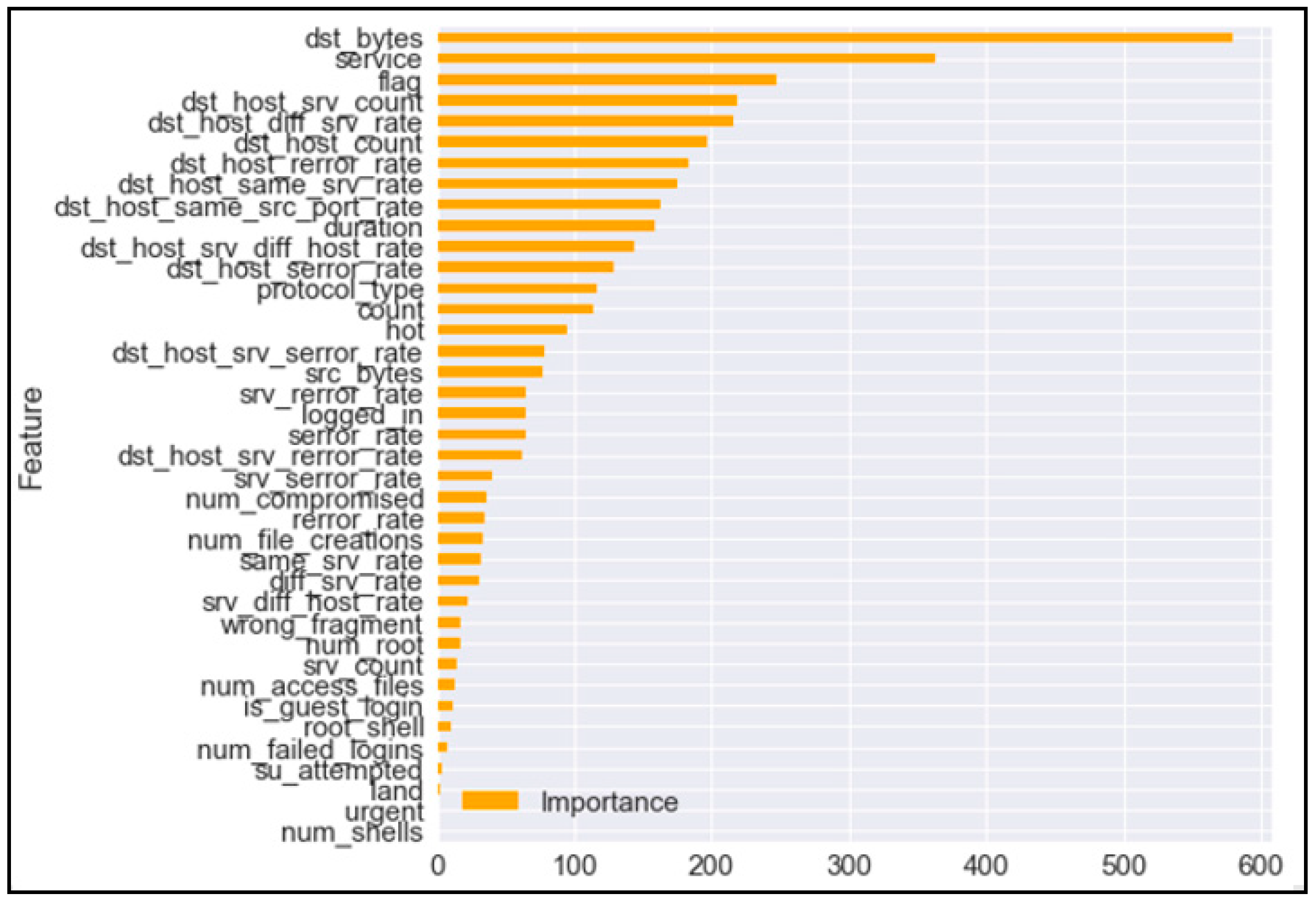
7.5. Feature Score (F-Score)
- The “min_child_weight” parameter defines the required sum of instance weight in a child. If the sum of instance weights in a leaf node falls short of this parameter, further steps are abandoned.
- The “subsample” parameter allows XGBoost to run on a limited set of data and prevents overfitting.
- The “colsample_bytree” parameter corresponds to the ratio of columns in the subsample when building trees.
- The “objective”: “binary: logistic” parameter is a learning parameter and is used to specify the task undertaken: in this case uses logistic regression for binary classification.
- “dst_bytes”—this attribute of the dataset accounted for the highest F-score of about 579.
- “num_shells” and “urgent”—this attribute of the combined test and train dataset accounted for the least F-score of 1.
- Two models were run. In the first model, the following were fixed parameters: “objective”: “binary: logistic”, “colsample_bytree”—0.8, “subsample”—0.8, “n_estimators”—1000, “seed”—0, “learning_rate”—0.1. The model was run to calculate the best values of the mean and the corresponding standard deviation for different combinations of the parameters “min_child_weight” and “max_depth”. Table 4 represents the result achieved.
- In the second model, the following parameters were fixed: “min_child_weight”—1, “seed”—0, “max_depth”—3, “n_estimators”—1000, “objective”: “binary: logistic”, “colsample_bytree”—0.8. The model was run to calculate the best values of mean and standard deviation for different combinations of the parameters of “learning_rate” and “subsample”. Table 5 represents the result achieved.
7.6. Comparison with other Classification Methods
- Decision Table—In this classification model, an entry follows a hierarchical structure and the entry at a higher level in the table gets split into a further table based on a pair of additional attributes.
- Logistic—is a classification model which is a typical regression model in which the relationship between various variables is analysed. The relationship between dependent and independent variables is looked at.
- SGD—a classifier based on linear models with stochastic gradient descent learning. The gradient related to the loss is estimated at each sample at a time.
- Random Forests and Random Trees—this classification method basically employs decision trees to classify data.
- Stochastic Gradient Descent—a classification method also known as incremental gradient descent. It is an iterative method deployed with the sole purpose of minimizing the objective function.
- SVM—It is a supervised learning method of classification. The training samples are categorized in two categories and new samples are split into these two categories depending on their respective closeness to the respective two categories.
- Bayesian Network—In this classification method a directed acyclic graph or DAG is used. The various nodes in the DAG represents the features and the arcs between the adjacent nodes represent the dependencies. It is a method based on conditional probability.
- Neural Networks—A backpropagation algorithm is used implementing feedforward network.
- Naïve Bayes—This classification method is based on probabilistic classifiers using Bayes theorem.
- CART—decision trees employing Classification and Regression Trees.
- J48—a decision tree classification method based on greedy algorithm.
- Spegasos—Implements the stochastic variant of the Pegasos (Primal Estimated sub-Gradient solver for SVM).
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Leswing, K. The Massive Cyberattack that Crippled the Internet. 2017. Business Insider Australia. Available online: https://www.businessinsider.com.au/amazon-spotify-twitter-githuband-etsy-down-in-apparent-dns-attack-2016-10?r=US&IR=T (accessed on 9 September 2017).
- Virtual Machine Escape. 2017. Available online: https://en.wikipedia.org/wiki/Virtual_machine_escape (accessed on 9 September 2017).
- Kuranda, S. The 20 Coolest Cloud Security Vendors of the 2017 Cloud 100. 2017. Available online: https://www.crn.com/slide-shows/security/300083542/the-20-coolest-cloud-security-vendors-of-the-2017-cloud-100.htm (accessed on 3 April 2018).
- Malware Analysis via Hardware Virtualization Extensions. Available online: http://ether.gtisc.gatech.edu/ (accessed on 21 March 2018).
- Cisco. Zone-Based Policy Firewall Design and Application Guide; Cisco: San José, CA, USA, 2010; Available online: https://www.cisco.com/c/en/us/support/docs/security/ios-firewall/98628-zone-design-guide.html (accessed on 21 March 2018).
- Ektefa, M.; Memar, S.; Sidi, F.; Affendey, L.S. Intrusion Detection Using Data Mining Techniques. In Proceedings of the 2010 International Conference on Information Retrieval & Knowledge Management (CAMP), Shah Alam, Malaysia, 17–18 March 2010; pp. 200–204. [Google Scholar]
- Holden, N.; Freitas, A. A Hybrid PSO/ACO Algorithm for Discovering Classification Rules in Data Mining. J. Artif. Evol. Appl. 2008, 2008, 316145. [Google Scholar] [CrossRef]
- Ardjani, F.; Sadouni, K. International Journal of Modern Education and Computer Science (IJMECS). 2010. Available online: http://www.mecs-press.org/ijmecs/ijmecs-v2-n2/v2n2-5.html (accessed on 26 March 2018).
- Panda, M.; Abraham, A.; Patra, M.R. A Hybrid Intelligent Approach for Network Intrusion Detection. Procedia Eng. 2012, 30, 1–9. [Google Scholar] [CrossRef]
- Petrussenko, D. Incrementally Learning Rules for Anomaly Detection. 2009. Available online: http://cs.fit.edu/~pkc/theses/petrusenko09.pdf (accessed on 26 March 2018).
- Mahoney, M.V.; Chan, P.K. Learning Rules for Anomaly Detection of Hostile Network Traffic. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003. [Google Scholar]
- Mahoney, M.V.; Chan, P.K. Packet Header Anomaly Detection for Identifying Hostile Network Traffic. 2001. Available online: https://cs.fit.edu/~mmahoney/paper3.pdf (accessed on 26 March 2018).
- Xiang, G.; Min, W. Applying Semi-Supervised Cluster Algorithm for Anomaly Detection. In Proceedings of the 3rd International Symposium on Information Processing, Qingdao, China, 15–17 October 2010; pp. 43–45. [Google Scholar]
- Wang, Q.; Megalooikonomou, V. A Clustering Algorithm for Intrusion Detection. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.59.4965&rep=rep1&type=pdf (accessed on 26 March 2018).
- Mao, C.; Lee, H.; Parikh, D.; Chen, T.; Huang, S. Semi-Supervised Co-Training and Active Learning-Based Approach for Multi-View Intrusion Detection. In Proceedings of the 2009 ACM symposium on Applied Computing, Honolulu, HI, USA, 8–12 March 2009. [Google Scholar]
- Chiu, C.; Lee, Y.; Chang, C.; Luo, W.; Huang, H. Semi-Supervised Learning for False Alarm Reduction. In Proceedings of the Industrial Conference on Data Mining, Berlin, Germany, 12–14 July 2010. [Google Scholar]
- Lakshmi, M.N.S.; Radhika, Y.D. Effective Approach for Intrusion Detection Using KSVM and R. 2005. Available online: http://www.jatit.org/volumes/Vol95No17/20Vol95No17.pdf (accessed on 26 March 2018).
- Monowar, H.B.; Bhattacharyya, D.K.; Kalita, J.K. An Effective Unsupervised Network Anomaly Detection Method. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics, Chennai, India, 3–5 August 2012. [Google Scholar]
- Lane, T. A Decision Theoretic, Semi-Supervised Model for Intrusion Detection. In Machine Learning and Data Mining for Computer Security; Springer: London, UK, 2006. [Google Scholar]
- Zhang, F. Multifaceted Defense against Distributed Denial of Service Attacks: Prevention, Detection and Mitigation. 2012. Available online: https://pdfs.semanticscholar.org/eb7d/4c742f6cd110d9c96a08e398cc415c3a8518.pdf (accessed on 26 March 2018).
- Fu, Z.; Papatriantafilou, M.; Tsigas, P. CluB: A Cluster-Based Framework for Mitigating Distributed Denial of Service Attacks. In Proceedings of the 2011 ACM Symposium on Applied Computing, Taichung, Taiwan, 21–24 March 2011. [Google Scholar]
- Zhang, F.; Papatriantafilou, M.; Tsigas, P. Mitigating Distributed Denial of Service Attacks in Multiparty Applications in the Presence of Clock Drifts. IEEE Trans. Depend. Secure Comput. 2012, 9, 401–413. [Google Scholar] [Green Version]
- Catania, C.; Garino, C. Automatic Network Intrusion Detection: Current Techniques and Open Issues. Comput. Electr. Eng. 2012, 38, 1062–1072. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Boosting (Machine Learning). Available online: https://en.wikipedia.org/wiki/Boosting_(machine_learning) (accessed on 5 November 2017).
- Brodley, C.; Utgoff, P. Multivariate Decision Trees—Semantic Scholar. 1995. Available online: https://www.semanticscholar.org/paper/Multivariate-Decision-Trees-Brodley-Utgoff/21a84fe894493e9cd805bf64f1dc342d4b5ce17a (accessed on 3 April 2018).
- Brownlee, J. A Gentle Introduction to XGBoost for Applied Machine Learning. Machine Learning Mastery. Available online: http://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/ (accessed on 2 March 2018).
- Reinstein, I. XGBoost a Top Machine Learning Method on Kaggle, Explained. Available online: http://www.kdnuggets.com/2017/10/xgboost-top-machine-learning-method-kaggle-explained.html (accessed on 2 March 2018).
- Introduction to Boosted Trees—Xgboost 0.7 Documentation. Available online: http://xgboost.readthedocs.io/en/latest/model.html (accessed on 3 March 2018).
- NSL-KDD | Datasets | Research | Canadian Institute for Cybersecurity | UNB. Available online: http://www.unb.ca/cic/datasets/nsl.html (accessed on 16 March 2018).
- XGBoost Parameters—Xgboost 0.7 Documentation. Available online: http://xgboost.readthedocs.io/en/latest/parameter.html (accessed on 12 March 2018).
- Brownlee, J. Classification Accuracy is not enough: More Performance Measures You Can Use. Machine Learning Mastery. 2014. Available online: https://machinelearningmastery.com/classification-accuracy-is-not-enough-more-performance-measures-you-can-use/ (accessed on 16 March 2018).
- Joshi, R. Accuracy, Precision, Recall & F1 Score: Interpretation of Performance Measures. 2016. Available online: http://blog.exsilio.com/all/accuracy-precision-recall-f1-score-interpretation-of-performance-measures/ (accessed on 3 April 2018).
- Plotting and Intrepretating an ROC Curve. Available online: http://gim.unmc.edu/dxtests/roc2.htm (accessed on 16 March 2018).
- A Study on NSL-KDD Dataset for Intrusion Detection System Based on Classification Algorithms. Available online: https://pdfs.semanticscholar.org/1b34/80021c4ab0f632efa99e01a9b073903c5554.pdf (accessed on 26 March 2018).
- Garg, T.; Khurana, S.S. Comparison of Classification Techniques for Intrusion Detection Dataset Using WEKA. In Proceedings of the International Conference on Recent Advances and Innovations in Engineering, Jaipur, India, 9–11 May 2014. [Google Scholar]
- Hussain, J.; Lalmuanawma, S. Feature Analysis, Evaluation and Comparisons of Classification Algorithms Based on Noisy Intrusion Dataset. Procedia Comput. Sci. 2016, 92, 188–198. [Google Scholar] [CrossRef]
- Chauhan, H.; Kumar, V.; Pundir, S. A Comparative Study of Classification Techniques for Intrusion Detection. In Proceedings of the 2013 International Symposium on Computational and Business Intelligence, New Delhi, India, 24–26 August 2013. [Google Scholar]
- A Detailed Analysis on NSL-KDD Dataset Using Various Machine Learning Techniques for Intrusion Detection. 2013. Available online: http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=7C05CDF892E875A01EDF75C2970CBDB9?doi=10.1.1.680.6760&rep=rep1&type=pdf (accessed on 10 May 2018).
- Yadav, A.; Ingre, B. Performance Analysis of NSL-KDD Dataset Using ANN. In Proceedings of the 2015 International Conference on Signal Processing and Communication Engineering Systems, Guntur, India, 2–3 January 2015. [Google Scholar]
- Zygmunt, Z. What is Better: Gradient-Boosted Trees, or a Random Forest?—FastML. 2016. Available online: http://fastml.com/what-is-better-gradient-boosted-trees-or-random-forest/ (accessed on 10 May 2018).
- Validated, C. Gradient Boosting Tree vs. Random Forest. Available online: https://stats.stackexchange.com/questions/173390/gradient-boosting-tree-vs-random-forest (accessed on 10 May 2018).
- Why XGBoost? And Why Is It So Powerful in Machine Learning. Available online: http://www.abzooba.com/blog/why-xgboost-and-why-is-it-so-powerful-in-machine-learning/ (accessed on 10 May 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Rows | No. of Columns | Memory Space |
|---|---|---|---|
| Train | 125973 | 42 | 40.4 MB |
| Test | 22544 | 42 | 7.2 MB |
| Combined (not converted) | 148517 | 42 | 48.7 MB |
| Combined (converted) | 148517 | 42 | 44.8 MB |
| Dataset | Float64 | Int64 | Object | Int8 |
|---|---|---|---|---|
| Train | 15 | 23 | 4 | - |
| Test | 15 | 23 | 4 | - |
| Combined (not converted) | 15 | 23 | 4 | - |
| Combined (converted) | 15 | 23 | - | 4 |
| Name of Feature | Meaning of Feature |
|---|---|
| duration | It represents the connection time. |
| protocol_type | It represents the protocol used in the connection. |
| service | It represents the service used by the destination network. |
| flag | It represents the connection status (error or no error). |
| dst_bytes | The number of data bytes transferred from destination to source in a single connection. |
| src_bytes | The number of data bytes transferred from source to destination in a single connection. |
| land | It is 1 if source and destination IP addresses and port numbers match, 0 if not. |
| wrong_fragment | It represents the number of wrong fragments in a single connection. |
| urgent | It represents the number of urgent packets (urgent bit is present) in a single connection. |
| hot | It represents the number of root or administrator indicators in the data sent, that is whether the packet is entering the system directory, and is it creating and executing programs. |
| num_failed_logins | It represents the number of times a login attempt has failed. |
| logged_in | It is 1 if successfully logged in, otherwise 0. |
| num_compromised | It represents the number of compromised positions in the data in a single connection. |
| root_shell | It toggles to 1 if the root shell is obtained, otherwise remains 0. |
| su_attempted | It toggles to 1 if “su root” command used, otherwise remains 0. |
| num_root | It represents the number of times operations were performed as the root in the connection. |
| num_file_creations | It represents the number of times the file creation command was used in the connection. |
| num_shells | It represents the number of shell prompts encountered in the connection. |
| num_access_files | It represents the number of times operations were performed using access control files. |
| num_outbound_commands | It represents the number of times an outbound command was issued in a connection. |
| is_hot_login | It represents whether the login belongs to the root or administrator. If so 1, else 0. |
| is_guest_login | It toggles to 1 if the login belongs to a guest, otherwise remains 0. |
| count | It counts the number of times the same destination host is used as the current connection in the past 2 s. |
| srv_count | It represents the number of times a connection in the past 2 s used the same destination port number as that of the current connection. |
| serror_rate | The connections (in percentage) that used “flag” s3, s2, s1 or s0 among the connections aggregated in “count”. |
| srv_serror_rate | The connections (in percentage) that used “flag” s3, s2, s1 or s0 among the connections aggregated in “srv_count”. |
| rerror_rate | The connections (in percentage) aggregated in “count”, that used the “REJ” flag. |
| srv_rerror_rate | The connections (in percentage) aggregated in “srv_count”, that used the “REJ” flag. |
| same_srv_rate | The connections (in percentage) aggregated in “count”, that used the same service. |
| diff_srv_rate | The connections (in percentage) aggregated in “count”, that used a different service. |
| srv_diff_host_rate | The connections (in percentage) aggregated in “srv_count”, that had a different destination addresses. |
| dst_host_count | The feature counts when connections have the same destination host IP address. |
| dst_host_srv_count | The connections that used the same port number. |
| dst_host_same_srv_rate | The percentage of connections aggregated in “dst_host_count”, that used the same service. |
| dst_host_diff_srv_rate | The percentage of connections aggregated in “dst_host_count”, that used a different service. |
| dst_host_same_src_port_rate | The percentage of connections aggregated in “dst_host_srv_count”, that used the same port number. |
| dst_host_srv_diff_host_rate | The percentage of connections aggregated in “dst_host_srv_count”, that had a different destination address. |
| dst_host_serror_rate | The percentage of connections aggregated in “dst_host_count”, that used “flag” s3, s2, s1 or s0. |
| dst_host_srv_serror_rate | The percentage of connections aggregated in “dst_host_srv_count”, that used “flag” s3, s2, s1 or s0. |
| dst_host_rerror_rate | The percentage of connections aggregated in “dst_host_count”, that used the “REJ” flag. |
| dst_host_srv_rerror_rate | The percentage of connections aggregated in “dst_host_srv_count”, that used the “REJ” flag. |
| Parameters | |||
|---|---|---|---|
| “max_depth” | “min_child_weight” | Mean | Standard Deviation |
| 3 | 1 | 0.99913 | 0.00013 |
| 3 | 3 | 0.99907 | 0.00010 |
| 3 | 5 | 0.99894 | 0.00014 |
| 5 | 1 | 0.99921 | 0.00015 |
| 5 | 3 | 0.99914 | 0.00013 |
| 5 | 5 | 0.99907 | 0.00010 |
| 7 | 1 | 0.99919 | 0.00018 |
| 7 | 3 | 0.99913 | 0.00014 |
| 7 | 5 | 0.99905 | 0.00015 |
| Parameters | |||
|---|---|---|---|
| “learning_rate” | “subsample” | Mean | Standard Deviation |
| 0.1 | 0.7 | 0.99912 | 0.00016 |
| 0.1 | 0.8 | 0.99913 | 0.00013 |
| 0.1 | 0.9 | 0.99917 | 0.00013 |
| 0.01 | 0.7 | 0.99601 | 0.00028 |
| 0.01 | 0.8 | 0.99589 | 0.00022 |
| 0.01 | 0.9 | 0.99583 | 0.00023 |
| Classifier | Accuracy on NSL-KDD Dataset (%) |
|---|---|
| Proposed XGBoost | 98.7 |
| Decision Table [37] | 97.5 |
| Logistic [38] | 97.269 |
| SGD [38] | 97.443 |
| RBF Classifier [37] | 96.7 |
| Rotation Forest (using 5 classes for labelling data as Normal and (Probe, DoS, R2L, and U2R) as Anomaly) [36] | 96.4 |
| SMO (Sequential Minimal Optimization) [37] | 96.2 |
| Random Tree (using 5 classes for labelling data as Normal and (Probe, DoS, R2L, and U2R) as Anomaly) [36] | 96.14 |
| Random Forest (using 5 classes for labelling data as Normal and (Probe, DoS, R2L, and U2R) as Anomaly) [36] | 96.12 |
| Spegasos [37] | 95.8 |
| Stochastic Gradient Descent [37] | 95.8 |
| SVM [37] | 92.9 |
| Bayesian Network [37] | 90.0 |
| RBF Network [37] | 87.9 |
| Naïve Bayes [37] | 86.2 |
| CART (using 5 classes for labelling data as Normal and (Probe, DoS, R2L, and U2R) as Anomaly) [39] | 81.5 |
| ANN (Artificial Neural Network) (binary class) [40] | 81.2 |
| J48 (using 5 classes for labelling data as Normal and (Probe, DoS, R2L, and U2R) as Anomaly) [39] | 80.6 |
| Voted Perception [37] | 76.0 |
| Self-Organizing Map (SOM) (Neural Network) [37] | 67.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dhaliwal, S.S.; Nahid, A.-A.; Abbas, R. Effective Intrusion Detection System Using XGBoost. Information 2018, 9, 149. https://doi.org/10.3390/info9070149
Dhaliwal SS, Nahid A-A, Abbas R. Effective Intrusion Detection System Using XGBoost. Information. 2018; 9(7):149. https://doi.org/10.3390/info9070149
Chicago/Turabian StyleDhaliwal, Sukhpreet Singh, Abdullah-Al Nahid, and Robert Abbas. 2018. "Effective Intrusion Detection System Using XGBoost" Information 9, no. 7: 149. https://doi.org/10.3390/info9070149
APA StyleDhaliwal, S. S., Nahid, A.-A., & Abbas, R. (2018). Effective Intrusion Detection System Using XGBoost. Information, 9(7), 149. https://doi.org/10.3390/info9070149