Rack Aware Data Placement for Network Consumption in Erasure-Coded Clustered Storage Systems


Abstract
:1. Introduction
2. Background and Related Work
2.1. Erasure Coding in Distribution Storage Cluster System
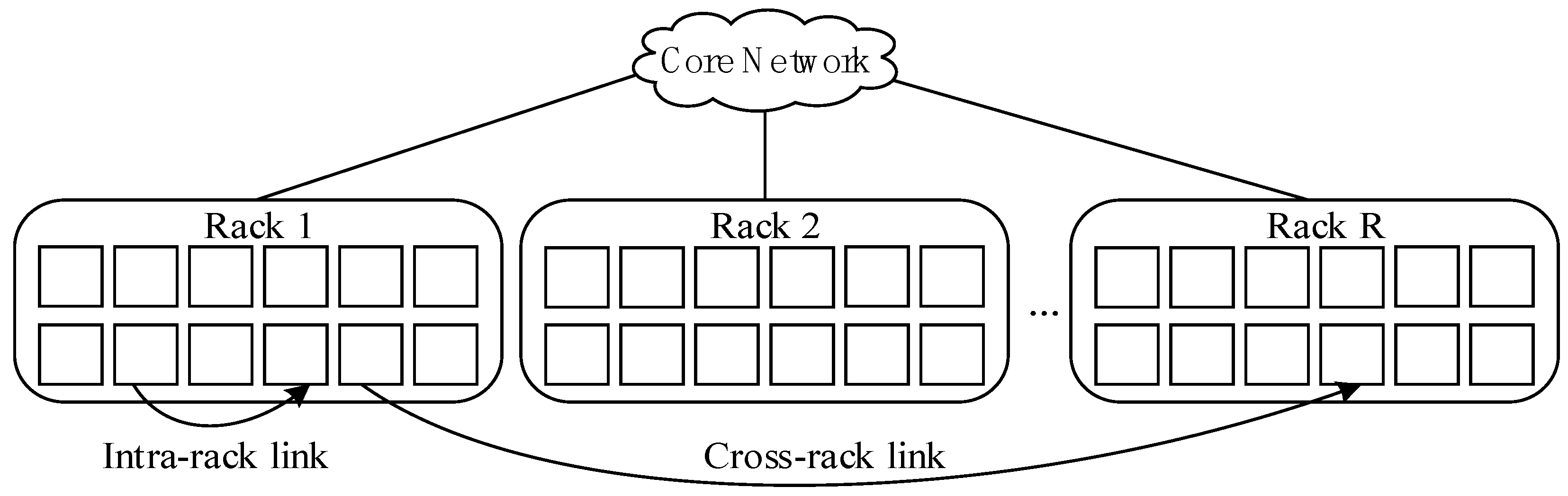
2.2. The Architecture of the Erasure-Coded Clustered System
- (1)
- Divide the data into k blocks;
- (2)
- Perform calculations on the k blocks to generate n (n > k) parity blocks, and store them separately on different server nodes;
- (3)
- When the user visits or node failure occurs, chose t (k ≤ t < n) effective blocks from the alive nodes, and download Q packets of data proportional from each block to decode for recovering the original data.
2.3. Problem Statement
- (1)
- To tolerate any n − k rack failure, it is necessary to place the k data blocks and the r parity blocks of one file in n different racks, meanwhile all these racks are not directly connected and may even be across multiple data centers. This causes a series of performance losses. To recover one failed block, k blocks are required to be downloaded. Although one block can be obtained from inside the same rack, the other k − 1 blocks need to be downloaded from another k − 1 racks, which causes high cross-rack bandwidth transmission and time delay.
- (2)
- All the data blocks and parity blocks are stored in a number of nodes of one rack. This is an assumption and does not generally exist in reality. Data reconstruction in this situation only needs intra-rack transmission, without cross-rack transmission, which reduces transmission delay and improves decoding performance. However, with this layout it is difficult to meet the requirements of rack-level fault tolerance, i.e., once the rack fails then relevant data are unrecoverable, which violates the ability of the erasure codes as a pivotal fault tolerant technology.
3. Rack Aware Encoding Data Placement Schemes
3.1. Design Goals
- (1)
- Reduce the cross-rack data transmission. Less frequent data transmission and lower transmission volume lead to better data reconstruction performance.
- (2)
- Maintain data availability. Any of the data layout plans should guarantee rack-level fault tolerance.
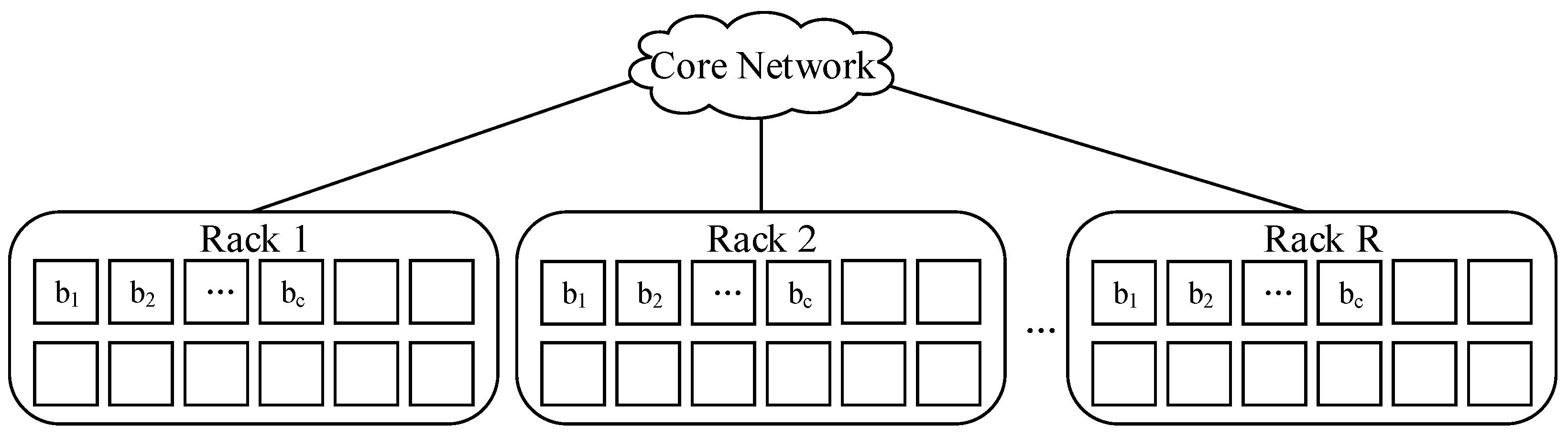
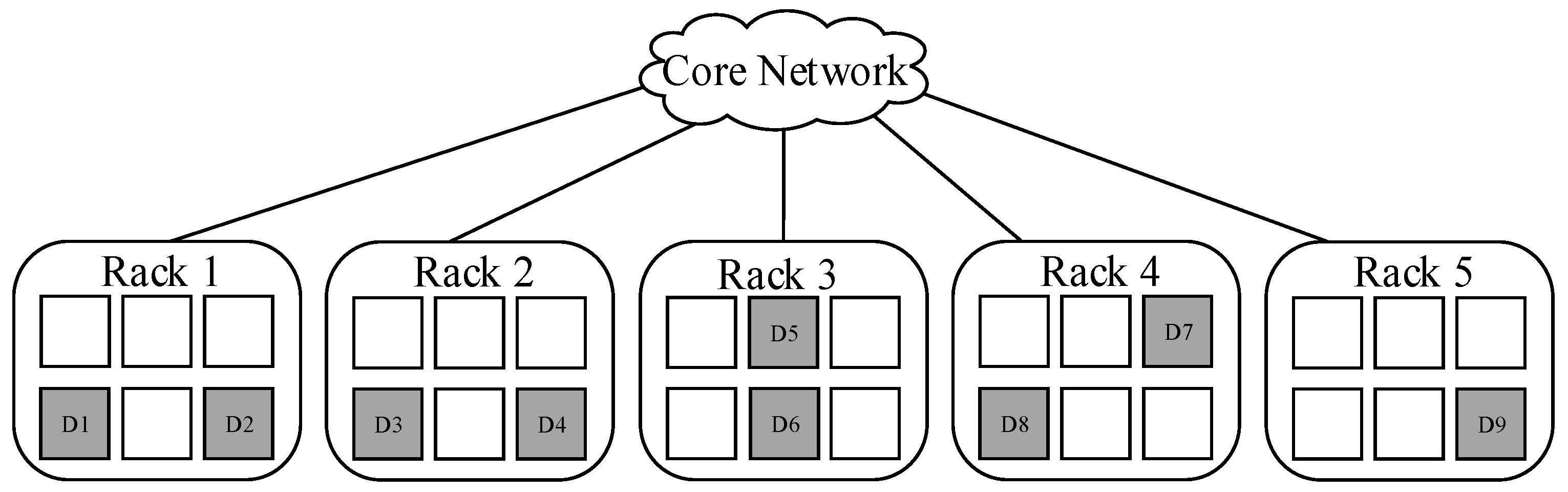
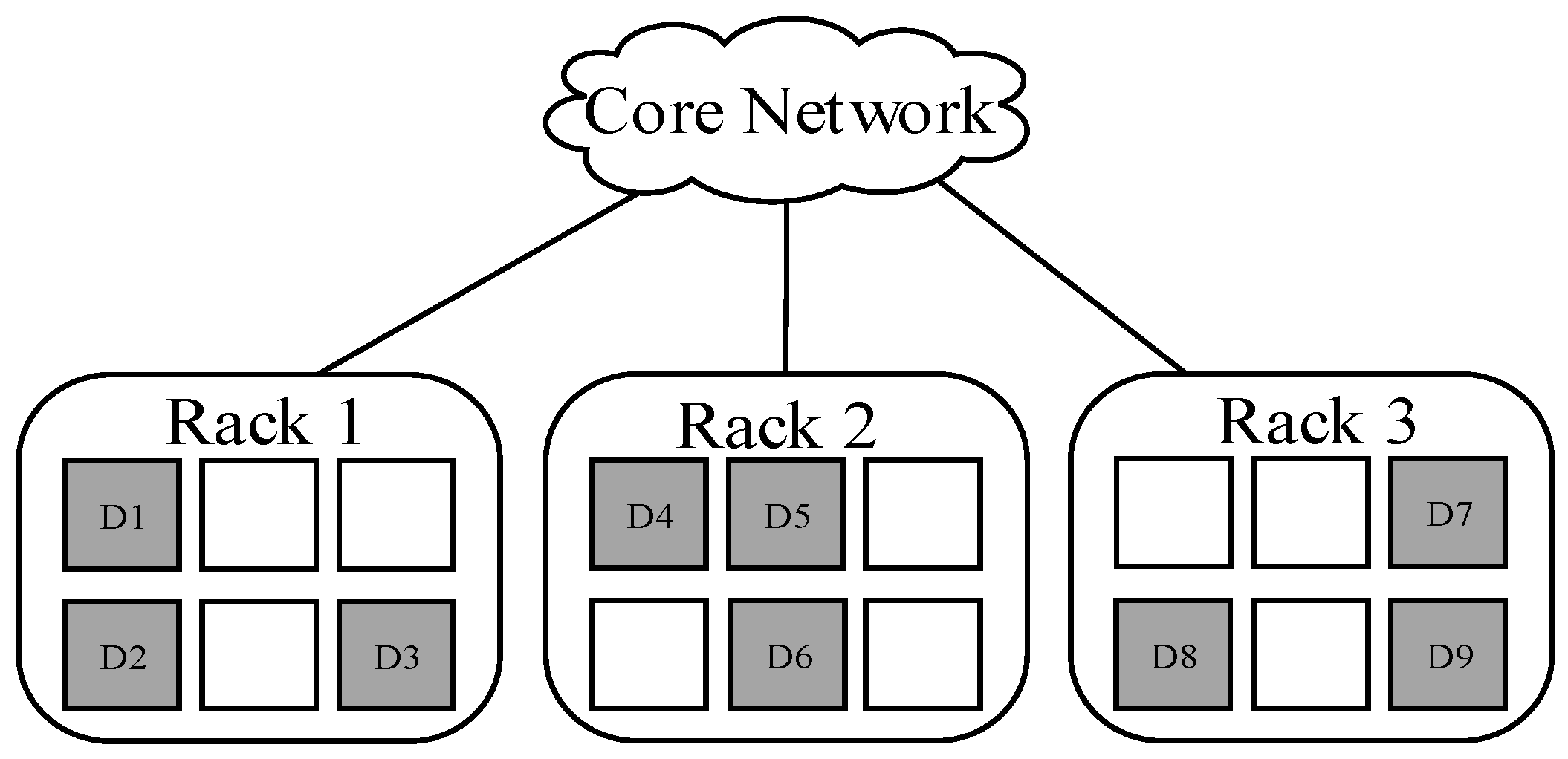
3.2. Placement Strategy for Encoded Data Blocks
3.3. Data Reliability
3.4. Placement Algorithm for Encoded Data Blocks
| Algorithm 1 Algorithm for data placement |
| Input: Original data of size S, the number of blocks placed in one rack c (1 < c ≤ n − k), the optimal rack subset (OPR) |
| Output: Rack location/serial number, the number and size of blocks placed in each rack |
| 1. Initialization: Divide the original data (Size S) into k chunks |
| 2. Encode the k chunks and get r parity chunks |
| 3. Record the data chunks as Di, i = 1, …, n |
| 4. for j = 0, j < NR, j++ |
| 5. for i = 1, i ≤ c, i++ |
| 6. D(c * j + i)—>OPRj |
| 7. end |
| Algorithm 2 An algorithm for load balancing |
| Input: The number of blocks placed in one rack c (1 < c ≤ n − k), collection of all racks R, NR |
| Output: The optimal rack subset (OPR) for placing one file |
| 1. Initialization: R = {R1, R2, …, Rm} |
| 2. Select any NR racks from R as a rack-subset |
| 3. Construct THE alternative rack set (APR) that contains all rack-subsets |
| 4. APRl is a rack-subset in APR |
| 5. for each ARPl in ARP do |
| 6. for each Rj in APRl do |
| 7. Get available bandwidth from Rj to core network (BA(Rj)) and available storage size in Rj (SA(Rj)) |
| 8. Calculate BA(APRl)—the sum of BA(Rj) when Rj IS in APRl |
| 9. Calculate SA(ARPl)—the sum of SA(Rj) when Rj IS in APRl |
| 10. RA(APRl) = BA(APRl)/ + SA(ARPl)/ |
| 11. Find the maximum RA(APRl) |
| 12. OPR is the APRl with the maximum RA(APRl) |
| 13. end |
3.5. Extensions
4. Evaluation and Discussion
4.1. Performance Analysis
4.2. Performance Testing
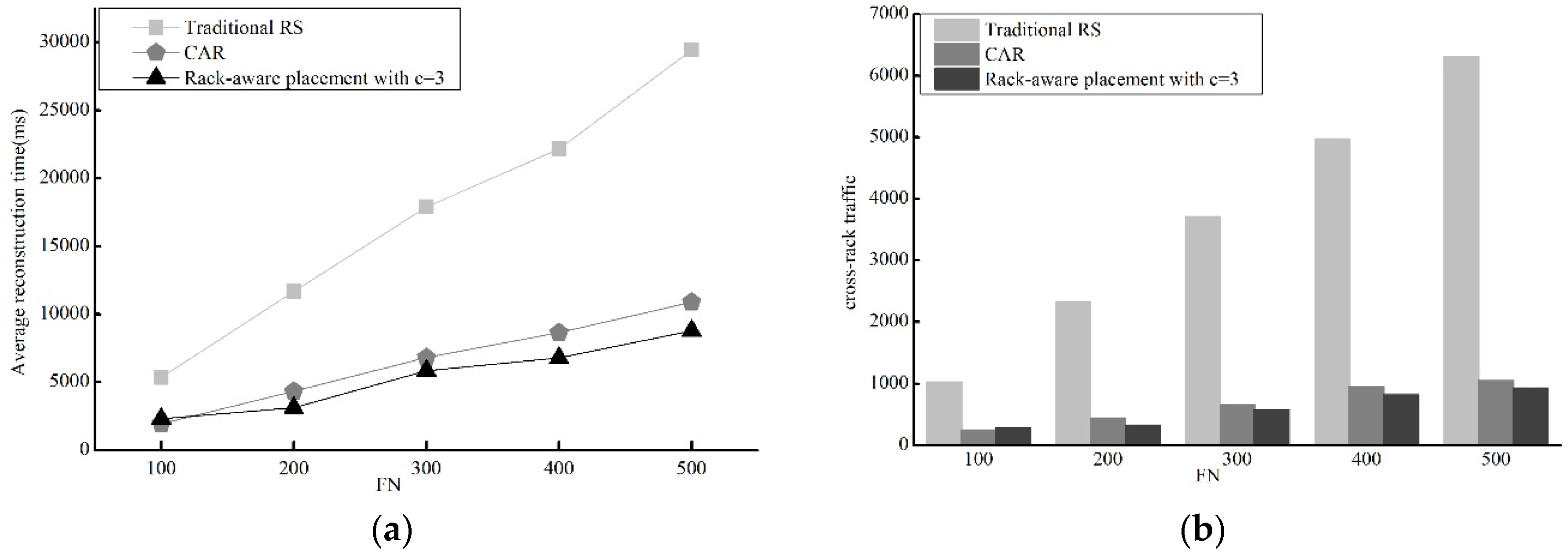
4.2.1. Reconstruction Performance
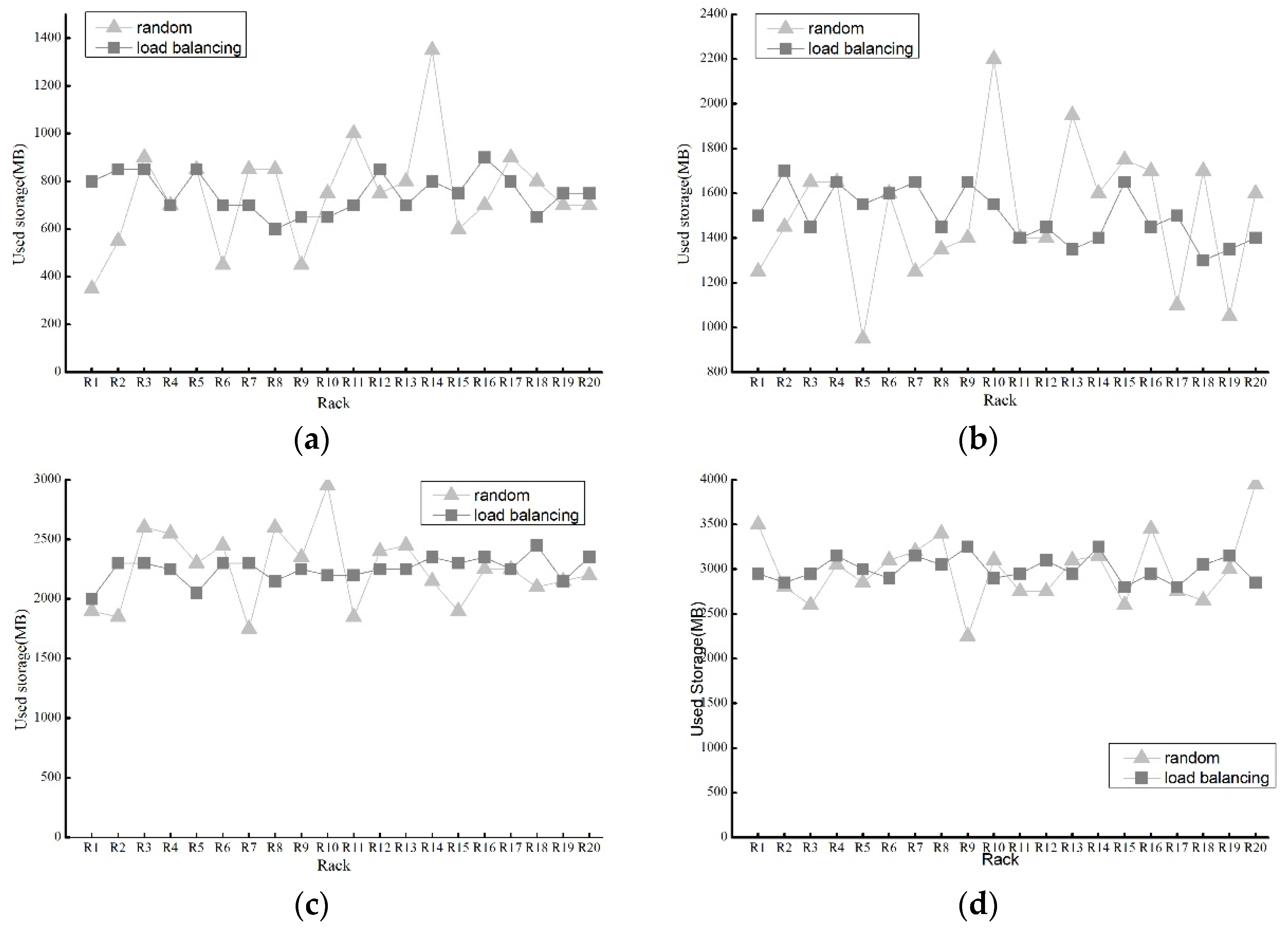
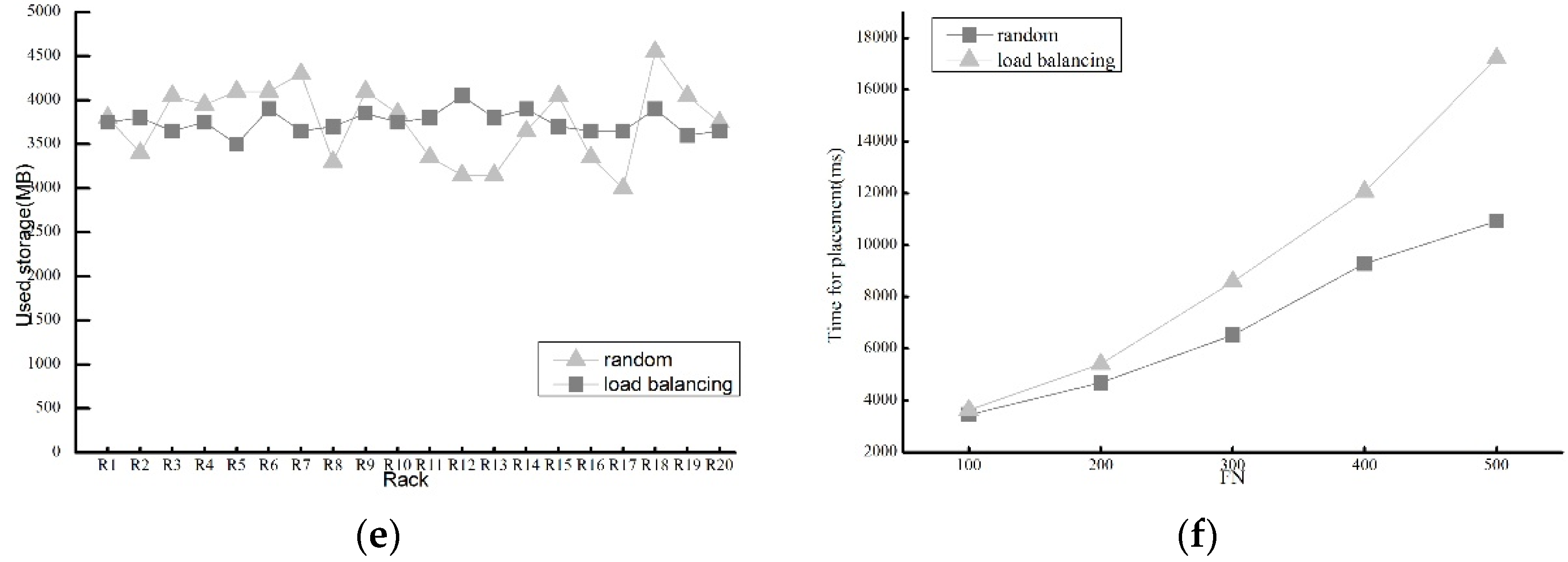
4.2.2. Load Balancing Performance
4.2.3. Reconstruction Performance for Comparison
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Xu, F.; Pei, X. Research on Erasure Code-Based Fault-Tolerant Technology for Distributed Storage. Chin. J. Comput. 2017, 40, 236–255. [Google Scholar]
- Li, R.; Hu, Y.; Lee, P.P.C. Enabling Efficient and Reliable Transition from Replication to Erasure Coding for Clustered File Systems. In Proceedings of the 45th Annual IEEE/IFIP on Dependable Systems and Networks, Rio de Janeiro, Brazil, 22–25 June 2015; pp. 148–159. [Google Scholar]
- Hu, Y.; Lee, P.P.C.; Zhang, X. Double Regenerating Codes for Hierarchical Data Centers. In Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 245–249. [Google Scholar]
- Shen, Z.; Lee, P.P.C.; Shu, J.; Guo, W. Cross-Rack-Aware Single Failure Recovery for Clustered File Systems. IEEE Trans. Dependable Secure Comput. 2017, 99, 1. [Google Scholar] [CrossRef]
- Yin, C.; Wang, J.; Lv, H.; Cui, Z.; Cheng, L.; Li, T.; Liu, Y. BDCode: An erasure code algorithm for big data storage systems. J. Univ. Sci. Technol. China 2016, 46, 188–199. [Google Scholar]
- Li, R.; Lee, P.P.C.; Hu, Y. Degraded-First Scheduling for Mapreduce in Erasure-Coded Storage Clusters. In Proceedings of the 44th Annual IEEE/IFIP on Dependable Systems and Networks, Atlanta, GA, USA, 23–26 June 2014; pp. 419–430. [Google Scholar]
- Li, R.; Li, X.; Lee, P.P.C.; Huang, Q. Repair Pipelining for Erasure-Coded Storage. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC’17), Santa Clara, CA, USA, 12–14 July 2017; pp. 567–579. [Google Scholar]
- Ahn, H.Y.; Lee, K.H.; Lee, Y.J. Dynamic erasure coding decision for modern block-oriented distributed storage systems. J. Supercomput. 2016, 72, 1312–1341. [Google Scholar] [CrossRef]
- Chowdhury, M.; Kandula, S.; Stoica, I. Leveraging endpoint flexibility in data-intensive clusters. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 231–242. [Google Scholar] [CrossRef] [Green Version]
- Albano, M.; Chessa, S. Replication vs erasure coding in data centric storage for wireless sensor networks. Comput. Netw. 2015, 77, 42–55. [Google Scholar] [CrossRef]
- Huang, X.; Li, H.; Zhang, Y.; Hou, H.; Zhou, T.; Guo, H.; Zhang, H. Study on Binary Regenerating Codes for Big Data Storage Systems. J. Comput. Res. Dev. 2013, 50, 54–63. [Google Scholar]
- Chen, L.; Hang, J.; Teng, P.; Wang, X. Random Binary Extensive Code (RBEC): An Efficient Code for Distributed Storage System. Chin. J. Comput. 2017, 40, 1980–1995. [Google Scholar]
- Ge, J.; Chen, Z.; Fang, Y. Erasure codes-based data placement fault-tolerant algorithm. Appl. Res. Comput. 2014, 31, 2688–2691. [Google Scholar]
- Wu, Y.; Dimakis, A.G.; Ramchandran, K. Deterministic Regenerating Codes for Distributed Storage. In Proceedings of the Allerton Conference on Communication, Control, and Computing 2007, Monticello, IL, USA, 26–28 September 2007. [Google Scholar]
- Wu, Y.; Dimakis, A.G. Reducing Repair Traffic for Erasure Coding-Based Storage via Interference Alignment. In Proceedings of the IEEE International Conference on Symposium on Information Theory, Seoul, South Korea, 28 June–3 July 2009; pp. 2276–2280. [Google Scholar]
- Cullina, D.; Dimakis, A.G.; Ho, T. Searching for Minimum Storage Regenerating Codes. In Proceedings of the Allerton Conference on Communication, Control, and Computing 2009, Monticello, IL, USA, 30 September–2 October 2009. [Google Scholar]
- Dimakis, A.G.; Godfrey, P.B.; Wu, Y.; Wainwright, M.J.; Ramchandran, K. Network Coding for Distributed Storage Systems. IEEE Trans. Inf. Theory 2010, 56, 4539–4551. [Google Scholar] [CrossRef] [Green Version]
- Dimakis, A.G.; Ramchandran, K.; Wu, Y.; Suh, C. A Survey on Network Codes for Distributed Storage. Proc. IEEE 2011, 99, 476–489. [Google Scholar] [CrossRef] [Green Version]
- Hou, H.; Lee, P.P.C.; Shum, K.W.; Hu, Y. Rack-Aware Regenerating Codes for Data Centers. arXiv 2018, arXiv:1802.04031. [Google Scholar]
- Ma, Y.; Nandagopal, T.; Puttaswamy, K.P.N.; Banerjee, S. An Ensemble of Replication and Erasure Codes for Cloud File Systems. In Proceedings of the 32nd IEEE International Conference on Computer Communications, Turin, Italy, 14–19 April 2013; pp. 1276–1284. [Google Scholar]
- Zheng, Z.; Meng, H.; Li, D.; Wang, Z. Research on dynamic replication redundancy storage strategy based on erasure code. Comput. Eng. Des. 2014, 35, 3085–3090. [Google Scholar]
- Li, X.; Dai, X.; Li, W.; Cui, Z. Improved HDFS scheme based on erasure code and dynamical-replication system. J. Comput. Appl. 2012, 32, 2150–2153. [Google Scholar] [CrossRef]
- Yang, D.; Wang, Y.; Liu, P. Fault-tolerant mechanism combined with replication and error correcting code for cloud file systems. J. Tsinghua Univ. 2014, 54, 137–144. [Google Scholar]
- Gribaudo, M.; Iacono, M.; Manini, D. Improving reliability and performances in large scale distributed applications with erasure codes and replication. Future Gener. Comput. Syst. 2016, 56, 773–782. [Google Scholar] [CrossRef] [Green Version]
- Silberstein, M.; Ganesh, L.; Wang, Y.; Alvisi, L.; Dahlin, M. Lazy Means Smart: Reducing Repair Bandwidth Costs in Erasure-Coded Distributed Storage. In Proceedings of the International Conference on Systems and Storage, Haifa, Israel, 30 June–2 July 2014; ACM: New York, NY, USA, 2014; pp. 1–7. [Google Scholar]
- Huang, C.; Simitci, H.; Xu, Y.; Ogus, A.; Calder, B.; Gopalan, P.; Li, J.; Yekhanin, S. Erasure Coding in Windows Azure Storage. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 13–15 June 2012; pp. 15–26. [Google Scholar]
- Sathiamoorthy, M.; Asteris, M.; Papailiopoulos, D.; Dimakis, A.G.; Dimakis, R.; Dimakis, S. Xoring Elephants: Novel Erasure Codes for Big Data. In Proceedings of the VLDB Endowment, Trento, Italy, 26–30 August 2013; pp. 325–336. [Google Scholar]
- Rashmi, K.V.; Nakkiran, P.; Wang, J.; Shah, N.B.; Ramchandran, K. Having Your Cake and Eating It Too: Jointly Optimal Erasure Codes for I/O, Storage, and Network-bandwidth. In Proceedings of the 13th USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 16–19 February 2015; pp. 81–94. [Google Scholar]
- Rashmi, K.V.; Shah, N.B.; Gu, D.; Kuang, H.; Borthakur, D.; Ramchandran, K. A Hitchhiker’s Guide to Fast and Efficient Data Reconstruction in Erasure-Coded Data Centers. In Proceedings of the 2014 ACM conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 331–342. [Google Scholar]
- Muralidhar, S.; Lloyd, W.; Roy, S.; Hill, C.; Lin, E.; Liu, W.; Pan, S.; Shankar, S.; Tang, L.; Kumar, S. F4: Facebook’s Warm Blob Storage System. In Proceedings of the 11th USENIX conference on Operating Systems Design and Implementation, Broomfield, CO, USA, 6–8 October 2014; pp. 383–398. [Google Scholar]
- Zhu, L.; Wang, R.; Yang, H. Multi-path Data Distribution Mechanism Based on RPL for Energy Consumption and Time Delay. Information 2017, 8, 124. [Google Scholar] [CrossRef]
- Ferdaus, M.H.; Murshed, M.; Calheiros, R.N.; Buyyab, R. An algorithm for network and data-aware placement of multi-tier applications in cloud data centers. J. Netw. Comput. Appl. 2017, 98, 65–83. [Google Scholar] [CrossRef] [Green Version]
- Mitra, S.; Panta, R.; Ra, M.R.; Bagchi, S. Partial-Parallel-Repair (PPR): A Distributed Technique for Repairing Erasure Coded Storage. In Proceedings of the Eleventh European Conference on Computer Systems, London, UK, 18–21 April 2016; ACM: New York, NY, USA, 2016. [Google Scholar]
- Ford, D.; Labelle, F.; Popovici, F.I.; Stokely, M.; Truong, V.; Barroso, L.; Grimes, C.; Quinlan, S. Availability in Globally Distributed Storage Systems. In Proceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation, Vancouver, BC, Canada, 4–6 October 2010; pp. 1–7. [Google Scholar]
- Gastón, B.; Pujol, J.; Villanueva, M. A Realistic Distributed Storage System that Minimizes Data Storage and Repair Bandwidth. In Proceedings of the Data Compression Conference, Snowbird, UT, USA, 20–22 April 2013; p. 491. [Google Scholar]
- Ahmad, F.; Chakradhar, S.T.; Raghunathan, A.; Vijaykumar, T.N. ShuffleWatcher: Shuffle-Aware Scheduling in Multi-Tenant MapReduce Clusters. In Proceedings of the USENIX Annual Technical Conference 2014, Philadelphia, PA, USA, 19–20 June 2014; pp. 1–12. [Google Scholar]
- Li, J.; Yang, S.; Wang, X.; Li, B. Tree-Structured Data Regeneration in Distributed Storage Systems with Regenerating Codes. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 15–19 March 2010; pp. 1–9. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definitions |
|---|---|
| n | Total number of encoded data blocks and parity blocks |
| k | Number of blocks of a divided file |
| r | Number of parity blocks, n = k + r |
| c | Maximum number of block placed in each rack |
| S | File size |
| NR | Number of racks for storing a file |
| FT | Number of failed racks that a storage system can tolerate |
| m | Total number of racks in a storage system |
| R{} | Collection of all racks R {R1, R2, …, Rm} |
| Rj | The j-th rack in the collection of all rack |
| Di | The i-th block of a file |
| OPR | Optimal rack subset for placing one file |
| APR | Alternative rack set that contains all rack-subsets consisting of any NR racks from R |
| BA(Rj) | Available bandwidth from Rj to the core network |
| SA(Rj) | Available storage size in Rj |
| BA(APRl) | Sum of BA(Rj) when Rj is in APRl |
| SA(APRl) | Sum of SA(Rj) when Rj is in APRl |
| RA(APRl) | Entire resource availability of APRl |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, B.; Song, D.; Bian, G.; Zhao, Y. Rack Aware Data Placement for Network Consumption in Erasure-Coded Clustered Storage Systems. Information 2018, 9, 150. https://doi.org/10.3390/info9070150
Shao B, Song D, Bian G, Zhao Y. Rack Aware Data Placement for Network Consumption in Erasure-Coded Clustered Storage Systems. Information. 2018; 9(7):150. https://doi.org/10.3390/info9070150
Chicago/Turabian StyleShao, Bilin, Dan Song, Genqing Bian, and Yu Zhao. 2018. "Rack Aware Data Placement for Network Consumption in Erasure-Coded Clustered Storage Systems" Information 9, no. 7: 150. https://doi.org/10.3390/info9070150
APA StyleShao, B., Song, D., Bian, G., & Zhao, Y. (2018). Rack Aware Data Placement for Network Consumption in Erasure-Coded Clustered Storage Systems. Information, 9(7), 150. https://doi.org/10.3390/info9070150