In the process of bilateral matching, in order to make each agent satisfied with the matching object, the matching tendency can be ranked from high to low by preference list, and finally get the optimal utility of the agent. In the whole matching algorithm, M-1 and M-2 algorithms solve the problem through the following steps. In the M-1 algorithm, first all retailers announce the electricity price to clusters. After that, the distribution of resources and the demand energy in the cluster are calculated by M-2 matching algorithm based on the electricity price and channel conditions. Each cluster establishes a preference list for retailers and applies to the first retailer in the list. Then retailers decide which clusters to match and update the electricity price by comparing the energy demand of clusters that apply to match with the maximum energy available for sale. The above is an iterative process. Each iteration in the matching process will update the electricity price of retailers and the energy demand of the clusters. Specific steps for the M-1 and M-2 algorithms are explained in the following sections.
In this section, we propose distributed matching algorithms to solve the problems formulated in
Section 3. We use the following two matching algorithms, M-1 and M-2 algorithms, to solve the matching problems M-1 and M-2, respectively. From Definition 1, we define matching functions
and
for the M-1 and M-2, respectively, where
,
and
are the maximum number that can be matched.
and
are the price allocation matrices corresponding to functions
and
, respectively.
4.1. The Matching (M-1) between Retailers and Clusters
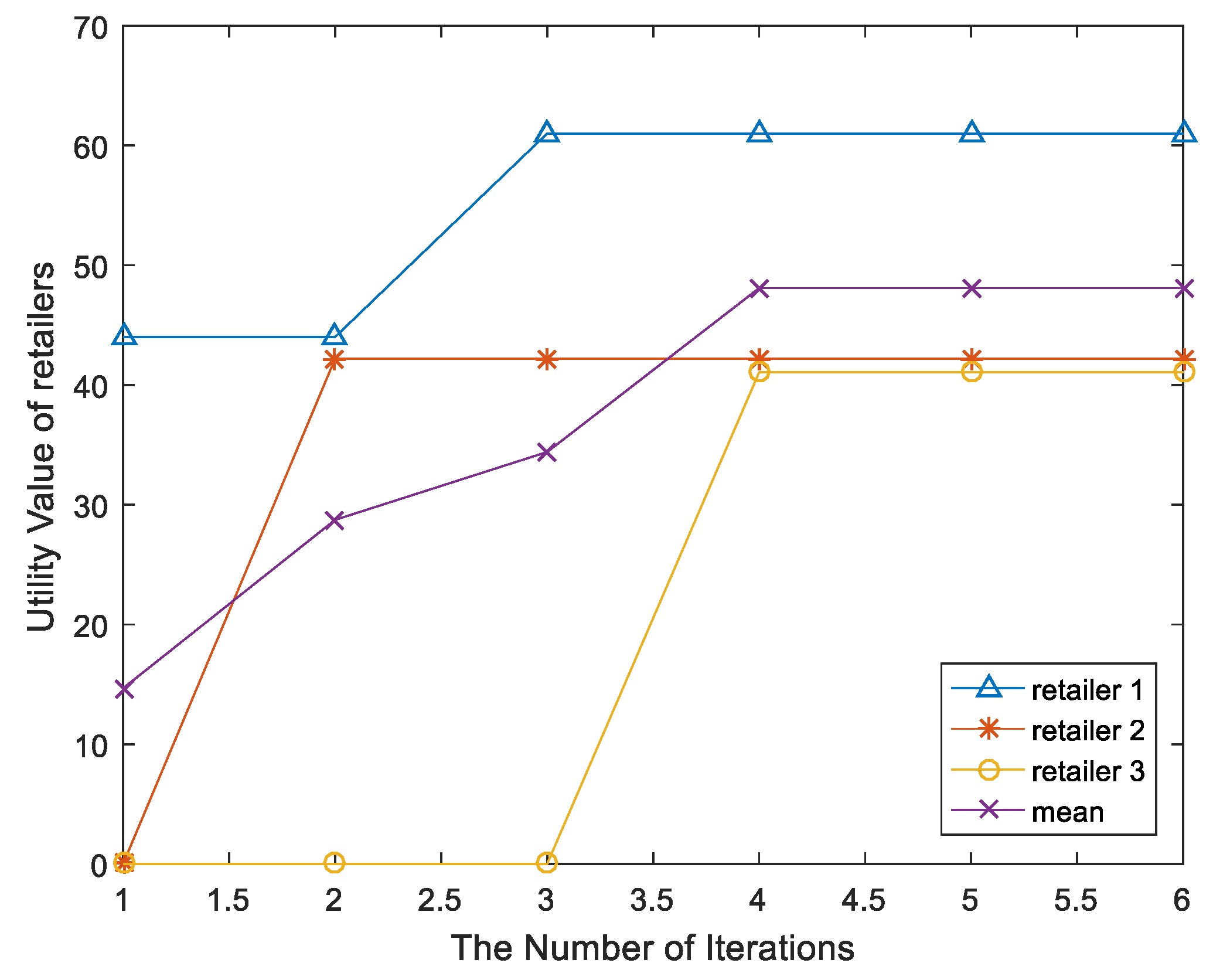
In M-1 we propose a bilateral matching algorithm where both retailers and clusters selfishly and rationally interact to maximize individual utility function. Retailers increase their profits by changing the price of electricity. At the beginning of M-1 matching algorithm, the price of the retailer’s electricity will be set as its cost price. In the matching process, the retailer z will raise the price of electricity by step-number and then sell energy to the cluster if the amount of power exceeds the maximum that can sell. Clusters will adjust the demand of electricity according to channel state and the price of the retailers, then reduce the cost of purchasing electricity and increase the rate through M-2 and power allocation. The aim of the M-1 is to optimally solve the optimization problem in (7) through matching algorithm between the retailers sets with the serving clusters . The specific details of the algorithm are described in Algorithm 1, with the notations defined below.
First,
will announce the price of unit electricity to the cluster according to its cost price. Then,
will form a descending preference list
in terms of its utility over all the potentially available retailers, that is, the first retailer in
is obtained from the following formula (M-1-Step 1)
Thus, such that if and only if .
To summarize the M-1, to increase the throughput and reduce the cost of electricity, each cluster first chooses the best retailer and bids for it (M-1-Step 2-1). We will define a bid function as
has a descending ordered list of the clusters that bid for . The list is ordered based on the received utility, that is, the first in corresponds to , (FM-1-Step 2-1).
Thus, such that if and only if . In M-1-Step 3, retailers will decide if they want to match with the clusters that bid for them. There are three possibilities. The first possibility (M-1-Step 3-1) is that receives no bids from clusters after increasing its price-allocation number, but in the previous iteration, had received bids from multiple clusters. will choose these clusters which could maximize the utility of to be matched with. The second possibility is that has bid from multiple clusters (M-1-Step 3-2-a). will increase its price allocation number by for the next (gen+1)st iteration. Note that represents the price-step number, which indicates the price-allocation number offered from the clusters to the source increases at each step. The third possibility (M-1-Step 3-2-b) is that has received a bid from only one cluster. In this case, will be matched with this one. The last iteration of the M-1 is denoted as tEnd.
| Algorithm 1 The bilaterally matching algorithm between the retailers and the clusters. |
Step 1: Initialization
(1) Set , , , .
(2) Set .
(3) Construct the list of all the clusters that are not matched, , and preference list to all the retailers denoted by , .
Step 2: Clusters’ Demand of Power
(1) Each announces its price-allocation number to all the unmatched clusters .
(2) For all
(a) If , then - (i)
Calculate the demand of power at the price . Then figure out its utility of to denoted by , and construct preference list . - (ii)
sends an access request to that is the first in its preference list , denoted by that its index is denoted by (i.e., ).
(b) Else does not bid, set
(3) Construct the descending ordered list of clusters that bided for in terms of utility, .
(4) Tag the clusters in by index t as
Step 3: Retailers’ Decision Making
(1) For all
(a) If , then - (i)
If , and remove from - (ii)
If , reject thus , let join and remove from . - (iii)
Set , .
(b) If , for all - (i)
. - (ii)
Set and remove from . - (iii)
Set .
(c) If , then set .
(2) Set .
(3) If is not empty go to Step 2; otherwise, go to step 4.
Step 4: End of the Algorithm |
To study the stability of the matching problem between retailers and clusters, we adopt the following theorem used in the assignment game problem in [
19] and adapt it to our two-sided matching algorithm:
Theorem 1. The algorithm in Algorithm 1 produces matching and price-allocation matrices, which are in competitive equilibrium for sufficiently small values of δ.
The proof of Theorem 1 is similar as that in the literature [
19], which is omitted there.
4.2. The Matching (M-2) between Base Stations and Users
We propose a matching approach to solve the mixed integer programming problem (9). In our system, we attempt to solve the problem (9) by employing the three-dimensional matching that user equipment, base stations and sub-channels with each other. To reduce the computational complexity, we transform the original three-dimensional matching to a two-sided matching. First, we define a BS-SUB unit, which is composed of one base station and one sub-channel (SUB). Owing to the existence of K BSs and J SUBs, there are K × J different BS-SUB units, denoted by . Thus, the three-dimensional matching problem can be simplified to a two-sided matching with N UEs on one side and K × J BS-SUB units on the other side.
The distributed algorithm which solves the optimization problem (9) involves each UE and BS-SUB strategically maximizing their utility functions. From
Section 2, we know that the static power consumption of the base stations in the cluster is constant. Therefore, in the setting of utility function (13), we’re going to make an analogy to the utility of the user to the function of the cluster. Users’ utility value is also divided into two parts: throughput benefit and energy consumption. At the same time, in order to better allocate resources to users, BS-SUB takes the channel condition between the user applying for it and BS-SUB as its utility. Compared with the utility of all users that apply to match, BS-SUB allocates its own resources to the best user and matches it.
The utility functions of UEs’ and BS-SUBs’ are respectively expressed as follows:
After obtaining the price of electricity published by retailers, the dependent variables of clusters’ utility are channel conditions and power allocation. In order to better analyze the effect of these two dependent variables on cluster utility, we divided the resource allocation problem into two sub-problems: M-2 matching and power allocation. In order to distinguish between channel state and power distribution in the utility function, we do not consider the effects of the distribution of power in the matching algorithm (M-2). We know that in the same power allocation, the user will transmit at a higher rate with better channel conditions, so they will be inclined to choose the BS-SUB unit with better channel state to match. In order to simplify the complexity of the matching process, we denote the function of the user’s preference for BS-SUBs as:
Then UE will establish the preferences list for BS-SUB based on this function.
The aim of the M-2 is to optimally solve the optimization problem in Equation (9) through matching the UEs sets with the serving BS-SUBs , while maximizing the sum rates of all the UEs in the cluster. The specific details of the algorithm are described in Algorithm 2, with the notations defined below.
First, will form a descending order preference list in terms of its utility over all the potentially available BS-SUB, i.e., the first BS-SUB in corresponds to . Thus, such that if and only if .
To summarize the M-2, each UE first chooses the best BS-SUB and bids for its (FM-2-Step 2-1). We will define a bid function as:
has a descending ordered list of the UEs that bid for . The list is ordered based on the received utility, that is, the first UE in corresponds to (FM-2-Step 2-1). Thus, such that if and only if .
Because each BS-SUB can serve at most one user, we can make the following two cases in M-2-Step 3. The first possibility (M-2-Step 3-1-a) is that is not matched with the user, and then selects the highest utility value user match in the iteration and rejects the rest users. The second possibility (M-2-Step 3-1-b) is that the has already matched user n and it will compare the current matching user with the user who is applying for the iteration, and selects the user with the highest utility value. If the user has no higher utility value than the current matched user, the current matching result is retained. Otherwise, replace it and reject the remaining users.
In M-2-Step 4, BSs and SUBs will decide if they want to match with the UEs that bid for them respectively. There are two possibilities. The first possibility (M-2-Step 4-1-a) is that the receives more than bids from UEs. will choose select the top users in the bid list and reject the remaining UEs. The second possibility (M-2-Step 4-1-b) is that the receives applications less than . In this case, will be matched directly with this UE. SUBs can also get results in the same way. Then we will end the bilaterally matching algorithm until is empty.
| Algorithm 2 The bilaterally matching algorithm between BS-SUBs and UEs. |
Step 1: Initialization- (1)
Set , m = 1, t = 1, c = 1, . - (2)
Construct preference list, and the list of all UEs that are not matched denoted by .
Step 2: UEs Making Their Decisions
For all - (a)
send an access request to the BS-SUB that the first in its preference list , denoted by that its index is denoted by (i.e., ). - (b)
Construct the descending ordered list of UEs that bid for in terms of utility and we can also construct the descending ordered list for BSs and sub-channels, and . - (c)
Tag the UEs in by index x as .
Step 3: BS-SUBs’ Decision Making
(1) For all
(a) If , then- (i)
If , let and remove from . - (ii)
Else, reject thus , let join and remove from . - (iii)
Set .
(b) Else, for all
(i) .
(ii) Set and remove from .
(2) .
(3) If is not empty go to Step 2; otherwise, go to step 4.
Step 4: BSs’ and subs’ Decision Making
(1) For all
(a) If , then - (i)
If , reject thus , let join . - (ii)
Set .
(2) For all
(a) If , then- (i)
If , reject thus , let join . - (ii)
Set .
(3) .
(4) If is not empty go to Step 2; otherwise, go to step 5.
Step 5: End of the Algorithm |
In order to study the stability of Algorithm 2 proposed by matching theory, first, we adopt the following concept used in the so-called college admissions problem in [
20] and adapt it to our matching approach:
Definition 1. An assignment of BS-SUBs to users will be called unstable if there are two BS-SUBs α and β which are assigned to users A and B, respectively, although β prefers A to B and A prefers β to α.
In the proposed approach, the users bid to the first BS-SUBs of their preference list. Each BS-SUB is allocated to the user with the higher preference, that is, the user with the larger value. If α is assigned to A rather than B, A has a higher preference value on α when compared to B. Similar reasoning can be made for user B and BS-SUB β. Then certainly, A prefers α to β; otherwise user A would be allocated subcarrier β and not α. If α is allocated to A instead of B, then the value of A is higher than B over BS-SUB α. Thus, the assignment that is performed in our proposed algorithm abides by the preferences of the users and BS-SUBs, and therefore it is a stable assignment. The assignment is stable at each iteration of the algorithm. In fact, after utility evaluation, the preference list of each user is updated and the matching routine is repeated, each time resulting in a stable assignment.
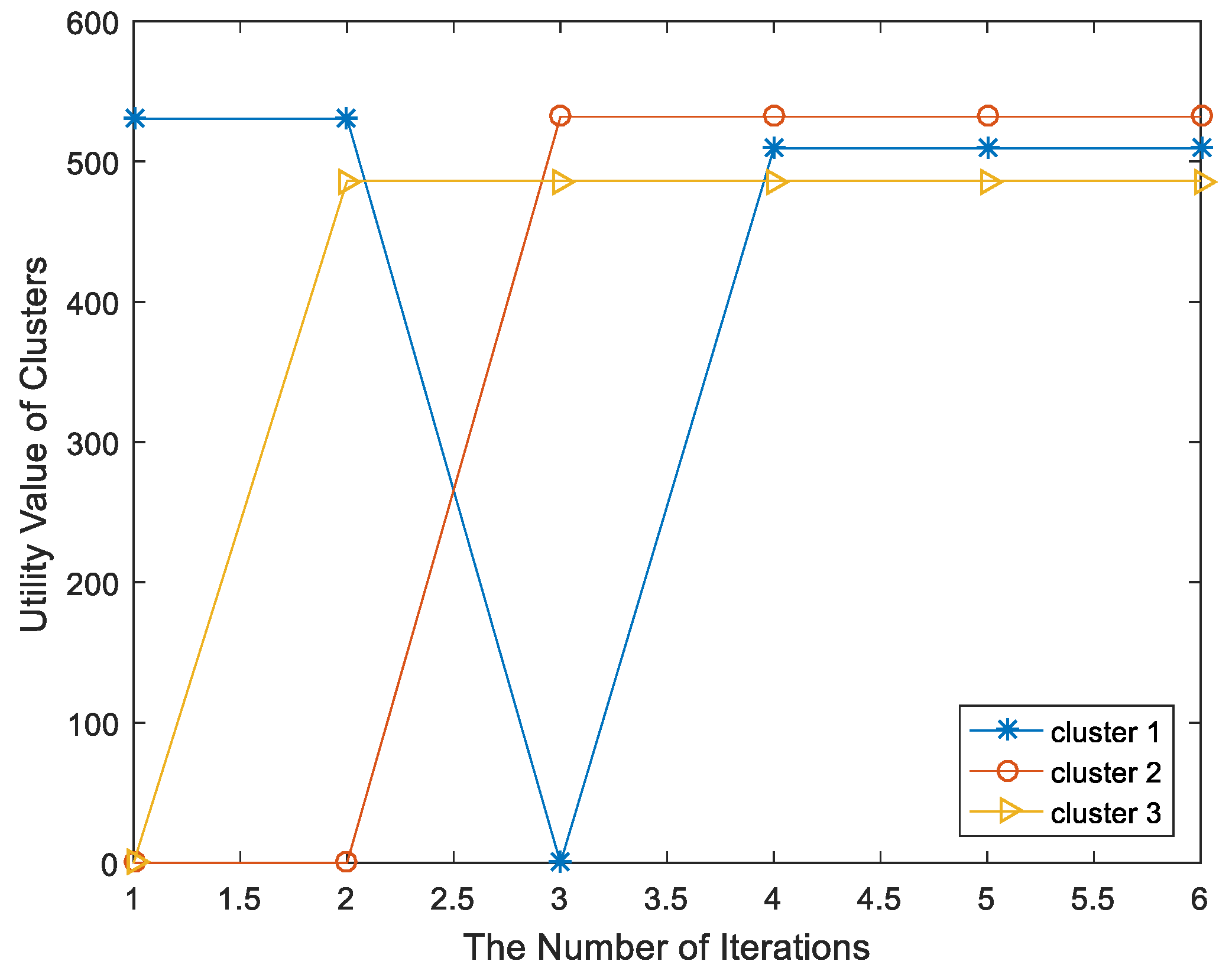
We refer to the analysis of the stability of three-dimensional matching in literature [
21], and finally reach the following conclusions: the matching process would end with finite iterations; the proposed Algorithm 2 can converge to a two-sided stable matching in finite iterations; and the solution of three-dimensional matching is weak Pareto optimal for users on combinations of base stations and sub-channels.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








