Leveraging Distrust Relations to Improve Bayesian Personalized Ranking

Abstract
:1. Introduction
- We propose a TNDBPR method for item recommendation tasks. To the best of our knowledge, it is the first work incorporating distrust relations to evaluate users’ item ranking preference.
- We conduct experiments to compare the proposed TNDBPR with its variations and four other representative models on Epinions dataset. The results verify that distrust relations has a significant impact on improving item recommendation results.
2. Related Work
3. Definitions and Data Description
3.1. Definitions
3.2. Data Description
4. The Proposed Method
4.1. Model Assumptions
4.2. Model Formulation
4.3. Model Learning and Complexity
| Algorithm 1 The learning algorithm of TNDBPR model. |
input: and a social network
|
5. Experiments
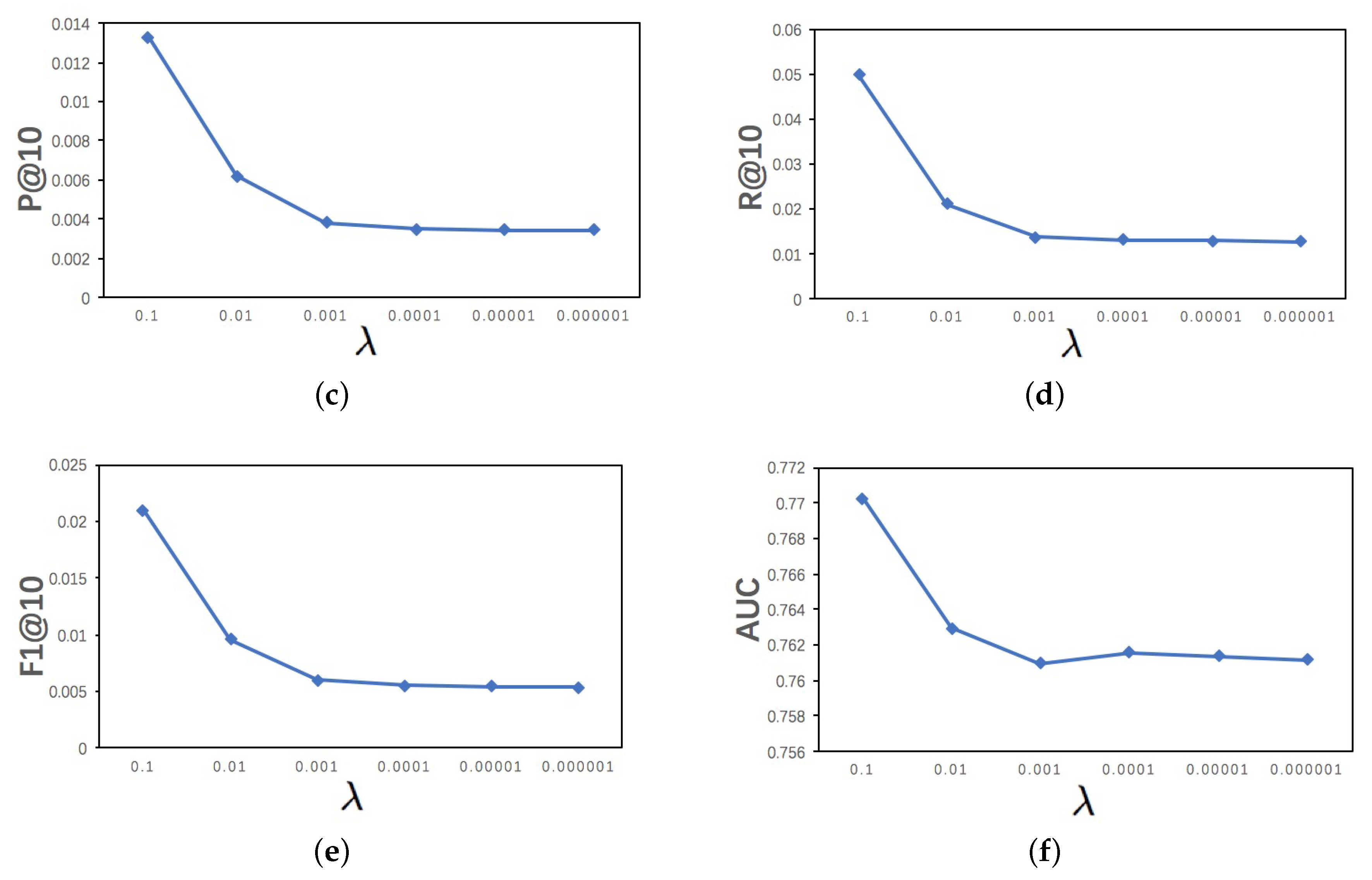
5.1. Experiment Settings
5.2. Comparison Methods
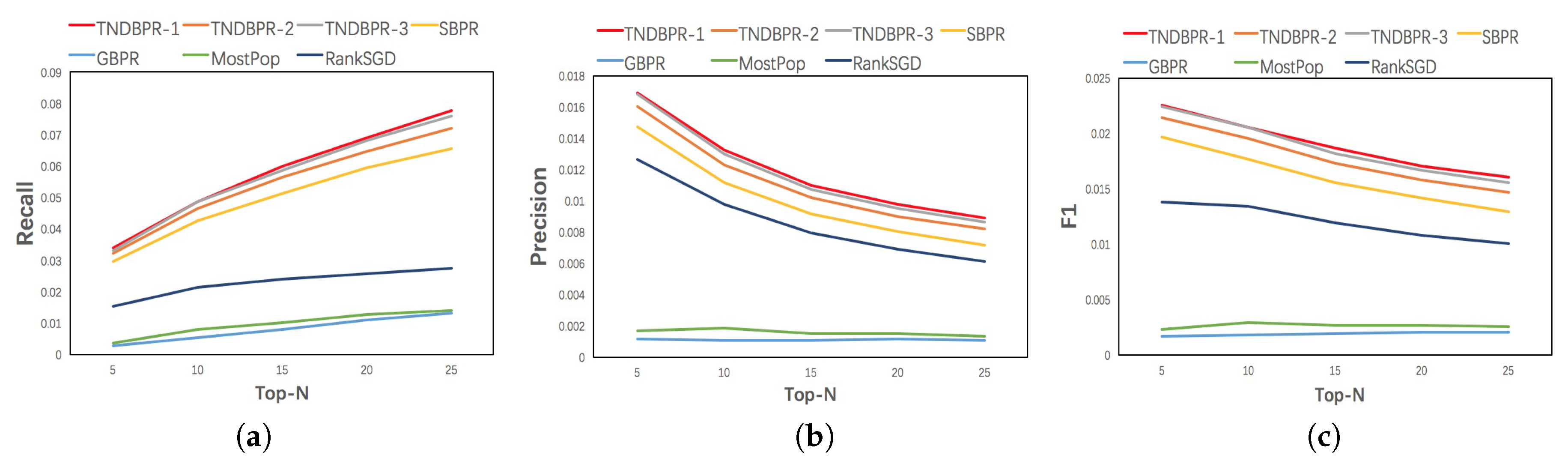
5.3. Recommendation Performance
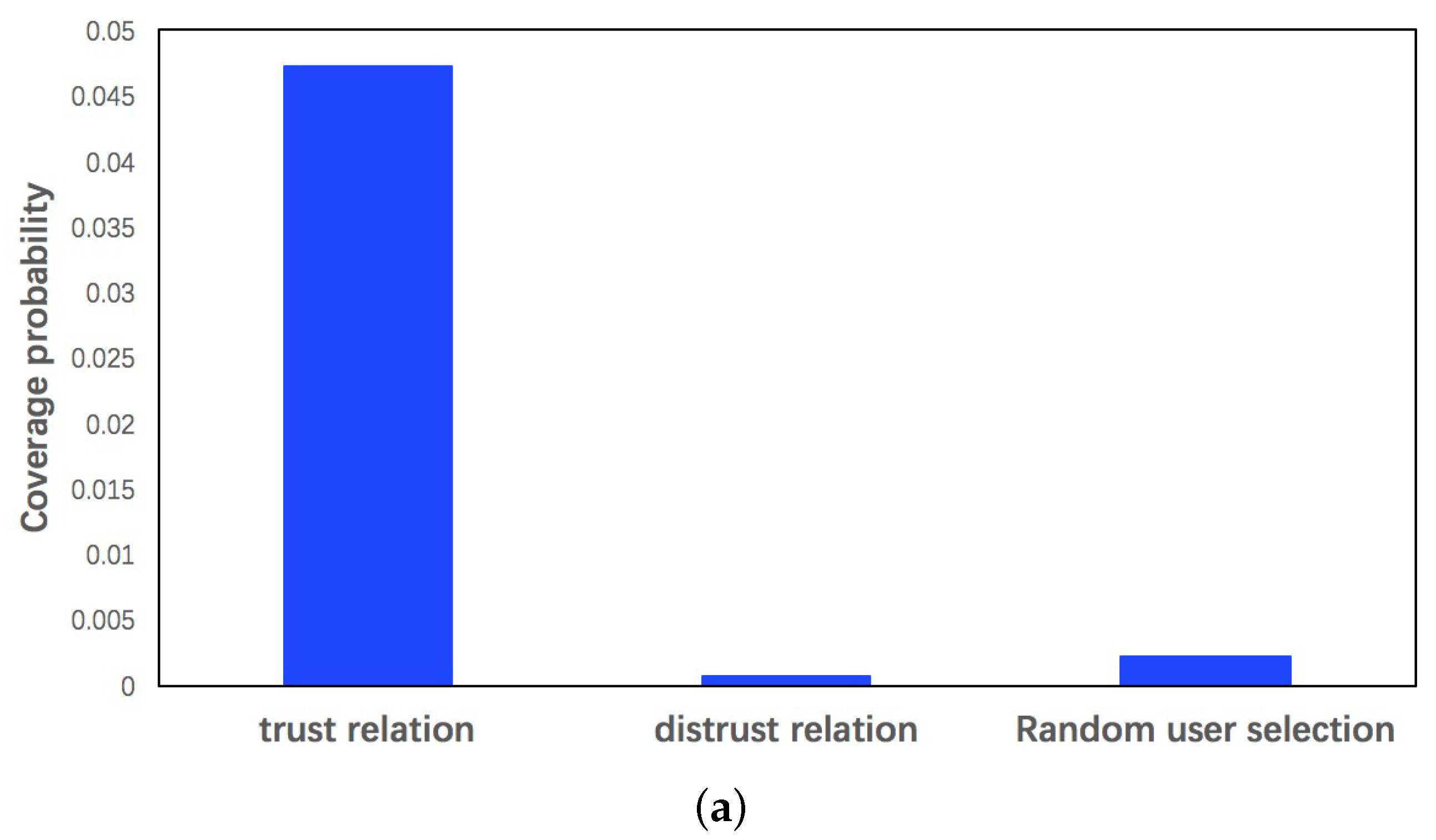
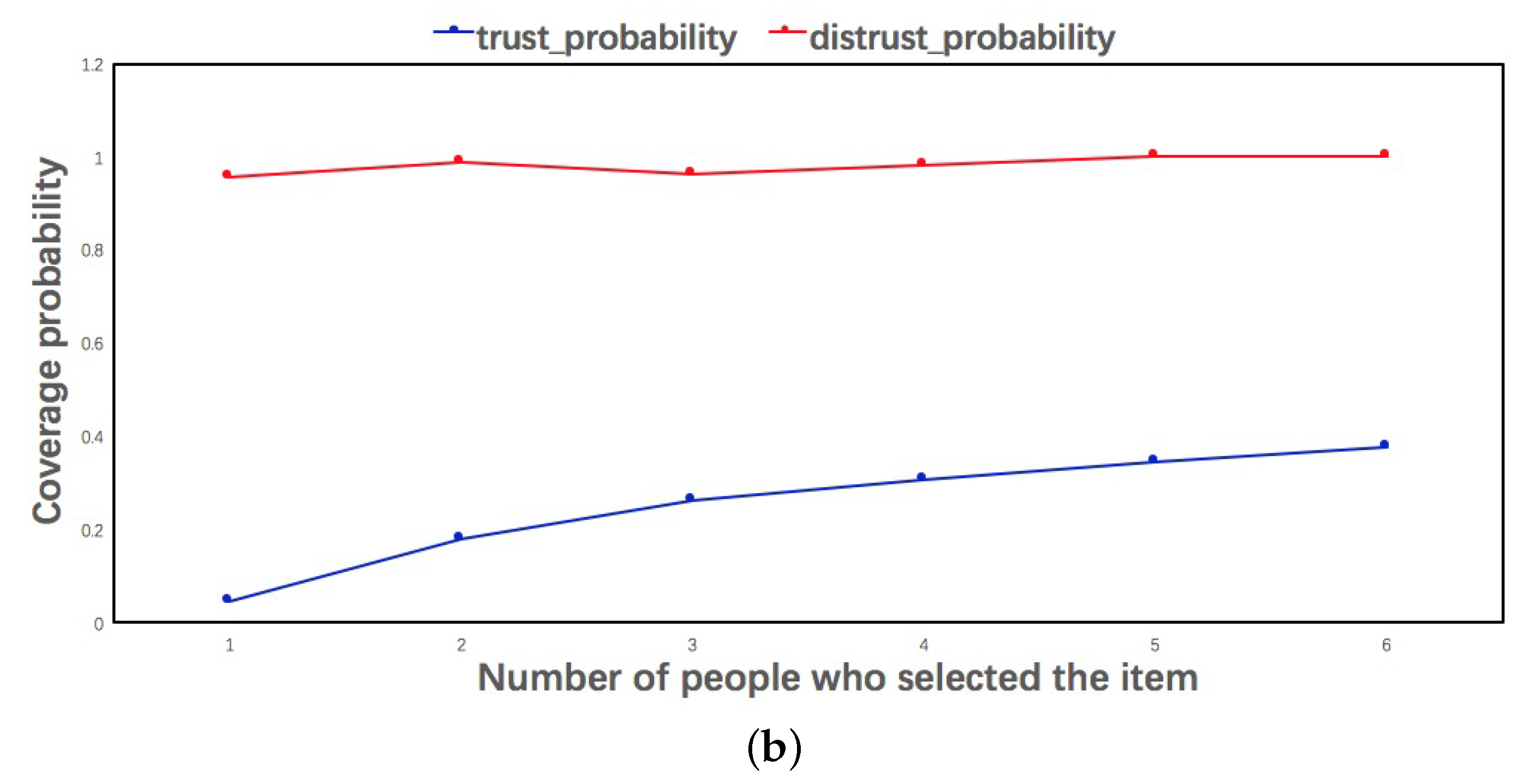
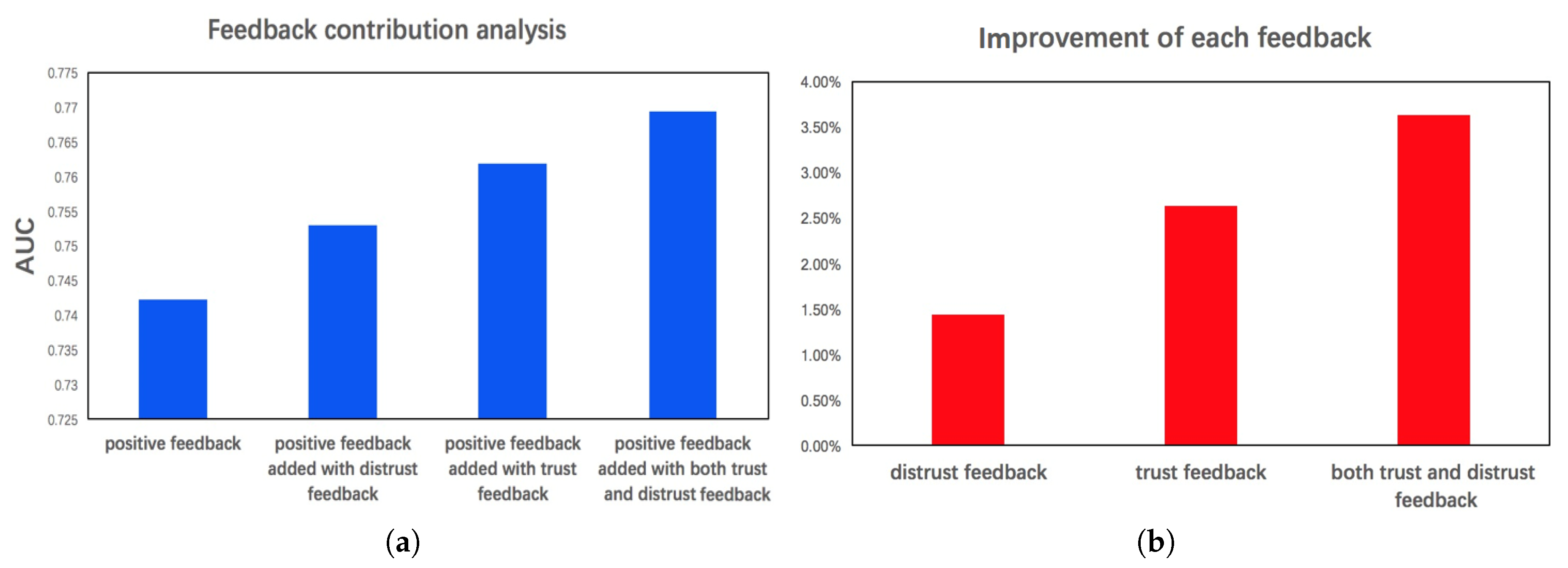
5.4. Feedback Analysis
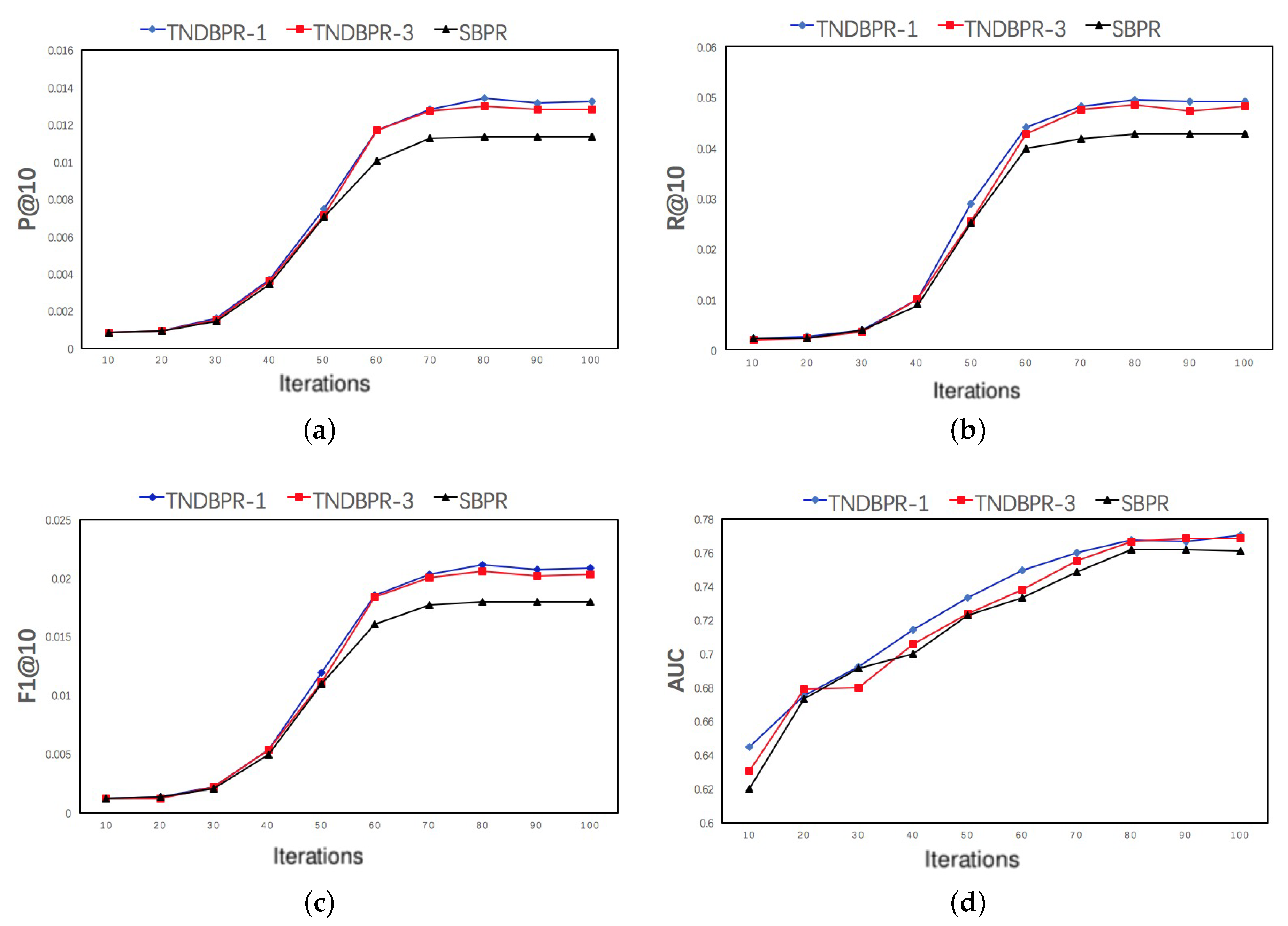
5.5. Convergence Analysis
5.6. Run Time Comparisons
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Burke, M.; Kraut, R. Mopping up: Modeling wikipedia promotion decisions. In Proceedings of the 2008 ACM Conference on Computer Supported Cooperative Work, San Diego, CA, USA, 8–12 November 2008; pp. 27–36. [Google Scholar]
- Yang, S.H.; Long, B.; Smola, A.; Sadagopan, N.; Zheng, Z.; Zha, H. Like like alike:joint friendship and interest propagation in social networks. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 537–546. [Google Scholar]
- Pan, R.; Zhou, Y.; Cao, B.; Liu, N.N.; Lukose, R.; Scholz, M. One-class collaborative filtering. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 502–511. [Google Scholar]
- Rendle, S.; Schmidt-Thieme, L. Pairwise interaction tensor factorization for personalized tag recommendation. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, New York, NY, USA, 3–6 February 2010; pp. 81–90. [Google Scholar]
- Krohn-Grimberghe, A.; Drumond, L.; Freudenthaler, C.; Schmidt-Thieme, L. Multi-relational matrix factorization using Bayesian personalized ranking for social network data. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 173–182. [Google Scholar]
- Yang, S.H.; Long, B.; Smola, A.J.; Zha, H.; Zheng, Z. Collaborative competitive filtering: Learning recommender using context of user choice. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; pp. 295–304. [Google Scholar]
- Anand, D.; Bharadwaj, K.K. Pruning trust–distrust network via reliability and risk estimates for quality recommendations. Soc. Netw. Anal. Min. 2013, 31, 65–84. [Google Scholar] [CrossRef]
- Forsati, R.; Mahdavi, M.; Shamsfard, M.; Sarwat, M. Matrix Factorization with Explicit Trust and Distrust Side Information for Improved Social Recommendation. ACM Trans. Inf. Syst. 2014, 32, 17. [Google Scholar] [CrossRef]
- Jamali, M.; Ester, M. Using a trust network to improve top-n recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 181–188. [Google Scholar]
- Zhao, T.; Mcauley, J.; King, I. Leveraging Social Connections to Improve Personalized Ranking for Collaborative Filtering. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 261–270. [Google Scholar]
- Shen, Y.; Jin, R. Learning personal + social latent factor model for social recommendation. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 1303–1311. [Google Scholar]
- Ye, M.; Liu, X.; Lee, W.C. Exploring social influence for recommendation: A generative model approach. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 671–680. [Google Scholar]
- Du, L.; Li, X.; Shen, Y.D. User graph regularized pairwise matrix factorization for item recommendation. In Proceedings of the International Conference on Advanced Data Mining and Applications, Beijing, China, 17–19 December 2011; pp. 372–385. [Google Scholar]
- Pan, W.; Chen, L. GBPR: Group preference based Bayesian personalized ranking for one-class collaborative filtering. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–19 August 2013; pp. 2691–2697. [Google Scholar]
- Hong, L.; Bekkerman, R.; Adler, J.; Davison, B.D. Learning to rank social update streams. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 651–660. [Google Scholar]
- Guo, L.; Jiang, H.; Wang, X. Location Regularization-Based POI Recommendation in Location-Based Social Networks. Information 2018, 9, 85. [Google Scholar] [CrossRef]
- De Meo, P.; Messina, F.; Rosaci, D.; Sarnéc, G.M.L. Combining trust and skills evaluation to form e-Learning classes in online social networks. Inf. Sci. Int. J. 2017, 405, 107–122. [Google Scholar] [CrossRef]
- Liu, H.; Xia, F.; Chen, Z.; Asabere, N.Y.; Ma, J.; Huang, R. TruCom: Exploiting Domain-Specific Trust Networks for Multicategory Item Recommendation. IEEE Syst. J. 2017, 11, 295–304. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, G.; Zhang, P.; Wang, Y. Personalized recommendation algorithm for social networks based on comprehensive trust. Appl. Intell. 2017, 47, 659–669. [Google Scholar] [CrossRef]
- De Meo, P.; Nocera, A.; Rosaci, D.; Ursino, D. Recommendation of reliable users, social networks and high-quality resources in a Social Internetworking System. AI Commun. 2011, 24, 31–50. [Google Scholar]
- Fotia, L.; Messina, F.; Rosaci, D.; Sarnéc, G.M.L. Using Local Trust for Forming Cohesive Social Structures in Virtual Communities. Comput. J. 2017, 60, 1717–1727. [Google Scholar] [CrossRef]
- Albanese, M.; Moscato, V.; Persia, F.; Picariello, A. A multimedia recommender system. Acm Trans. Internet Technol. 2013, 13, 3. [Google Scholar] [CrossRef]
- Ma, H.; Lyu, M.R.; King, I. Learning to recommend with trust and distrust relationships. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 23–25 October 2009; pp. 189–196. [Google Scholar]
- Victor, P.; Verbiest, N.; Cornelis, C.; Cock, M.D. Enhancing the trust-based recommendation process with explicit distrust. Acm Trans. Web 2013, 7, 6. [Google Scholar] [CrossRef]
- Forsati, R.; Barjasteh, I.; Masrour, F.; Esfahanian, A.H.; Radha, H. PushTrust: An Efficient Recommendation Algorithm by Leveraging Trust and Distrust Relations. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 51–58. [Google Scholar]
- Ghaznavi, F.; Alizadeh, S.H. Assessing Usage of Negative Similarity and Distrust Information in CF-Based Recommender System. In Proceedings of the 2017 Artificial Intelligence and Robotics (IRANOPEN), Qazvin, Iran, 9 April 2017; pp. 132–138. [Google Scholar]
- Fei, Z.Q.; Sun, W.; Sun, X.X.; Feng, G.Z.; Zhang, B.Z. Recommendation Based on Trust and Distrust Social Relationships. In Proceedings of the 2017 6th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 21–22 October 2017. [Google Scholar]
- Mahtar, S.N.A.M.; Masrom, S.; Omar, N.; Khairudin, N.; Rahim, S.K.N.A.; Rizman, Z.I. Trust aware recommender system with distrust in different views of trusted users. J. Fundam. Appl. Sci. 2017, 9, 168–182. [Google Scholar] [CrossRef]
- Chug, S.; Kant, V.; Jadon, M. Trust Distrust Enhanced Recommendations Using an Effective Similarity Measure. In Proceedings of the International Conference on Mining Intelligence and Knowledge Exploration, Hyderabad, India, 13–15 December 2017. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. Bpr: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Jahrer, M. Collaborative filtering ensemble for ranking. In Proceedings of the International Conference on KDD Cup, San Diego, CA, USA, 21 August 2011; pp. 153–167. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Quantity |
|---|---|
| Number of Users | 103,286 |
| Number of Item | 415,877 |
| Number of Observed feedback | 1,255,757 |
| Number of Social relations | 297,781 |
| Number of Average Positive feedback | 12 |
| Number of Average trust | 6 |
| Number of Average distrust | 3 |
| Method | P@10 | R@10 | AUC | F1@10 | NDCG@10 |
|---|---|---|---|---|---|
| Improve | 14.30% | 13.90% | 1.10% | 14.20% | 2.50% |
| TNDBPR-1 | 0.01327 | 0.04978 | 0.77027 | 0.02096 | 0.14364 |
| TNDBPR-2 | 0.01195 | 0.04500 | 0.763187 | 0.01888 | 0.141392 |
| TNDBPR-3 | 0.01302 | 0.04863 | 0.76992 | 0.02054 | 0.142687 |
| SBPR | 0.01138 | 0.04286 | 0.76191 | 0.01798 | 0.14001 |
| GBPR | 0.00100 | 0.00539 | 0.74040 | 0.00169 | 0.10895 |
| MostPop | 0.00180 | 0.00803 | 0.70412 | 0.00294 | 0.10207 |
| RankSGD | 0.00979 | 0.02120 | 0.54189 | 0.01339 | 0.10583 |
| Method | P@10 | R@10 | AUC | F1@10 | NDCG@10 |
|---|---|---|---|---|---|
| TNDBPR-1 | 0.01327 | 0.04978 | 0.77027 | 0.02076 | 0.14364 |
| 0.01133 | 0.04178 | 0.76607 | 0.01782 | 0.01374 | |
| SBPR | 0.01138 | 0.04286 | 0.76191 | 0.01798 | 0.14001 |
| 0.00997 | 0.03442 | 0.75647 | 0.01546 | 0.13270 | |
| GBPR | 0.00100 | 0.00539 | 0.74040 | 0.00169 | 0.10895 |
| 0.00103 | 0.00566 | 0.72690 | 0.00172 | 0.10120 | |
| MostPop | 0.00180 | 0.00803 | 0.70412 | 0.00294 | 0.10207 |
| 0.00153 | 0.00741 | 0.70944 | 0.00253 | 0.10124 | |
| RankSGD | 0.00979 | 0.02120 | 0.54189 | 0.01339 | 0.10583 |
| 0.00981 | 0.02193 | 0.50420 | 0.01355 | 0.11412 |
| TNDBPR | SBPR | GBPR | MostPop | RankSGD | |
|---|---|---|---|---|---|
| Average time | 61 min | 59 min | 55 min | 39 min | 574 min |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Xu, K.; Cai, Y.; Min, H. Leveraging Distrust Relations to Improve Bayesian Personalized Ranking. Information 2018, 9, 191. https://doi.org/10.3390/info9080191
Xu Y, Xu K, Cai Y, Min H. Leveraging Distrust Relations to Improve Bayesian Personalized Ranking. Information. 2018; 9(8):191. https://doi.org/10.3390/info9080191
Chicago/Turabian StyleXu, Yangjun, Ke Xu, Yi Cai, and Huaqing Min. 2018. "Leveraging Distrust Relations to Improve Bayesian Personalized Ranking" Information 9, no. 8: 191. https://doi.org/10.3390/info9080191
APA StyleXu, Y., Xu, K., Cai, Y., & Min, H. (2018). Leveraging Distrust Relations to Improve Bayesian Personalized Ranking. Information, 9(8), 191. https://doi.org/10.3390/info9080191