1. Introduction
Cement is considered as the most important hydraulic material in the modern construction field [
1,
2,
3,
4]. “Smart” sensing, self-healing, and self-sealing properties are in the spotlight and are engineered by nanomaterials addition [
1,
5], contributing also to materials design revolution for key industrial applications [
1]. Since concrete is extensively studied [
4], the design parameters are well-known in order to deliver suitable mechanical properties in the relevant application field. A plethora of new data are generated by characterization of novel cement formulations [
6]; however, sufficient technology transfer to industry is scarce [
1]. Except for the technology growth, synthesis of new materials and hybrid composite structures, the need to involve emerging evaluation methodologies is highlighted [
1,
7] to assist and accelerate developments [
8,
9]. Artificial Intelligence (AI) is a promising candidate to bridge the gap between Research and Development (R&D) and industry by establishing unbiased relations of microstructure to properties [
4,
6,
7,
8,
9,
10,
11]. This is majorly appreciated in case of Safe-by-Design requirements regarding mechanical performance [
8,
12], and real-time characterization [
9]. Being representative, k-means, Random Forrest (RF), Support Vector Machines (SVM), k-Nearest Neighbors (KNN) are common Machine Learning (ML) algorithms used in multiclass classification problems [
4] for automated classification of microstructures [
8,
13]; however, these algorithms often require lot of data to train the predictive models [
14]. Also, density functional theory (DFT) has been established for predicting the structure and behavior of organic (such as proteins) and inorganic (i.e., most common are calcium carbonates, oxalates, metal sulfides, etc.) crystals, which has enabled the development of ontology databases; the calculated properties of known systems and the predicted properties of hypothetical systems are included [
10,
14]. Similar efforts have been put in practice with experimental materials characterization (CHADA, Nanoindentation—documentation structure for characterisation data) [
11].
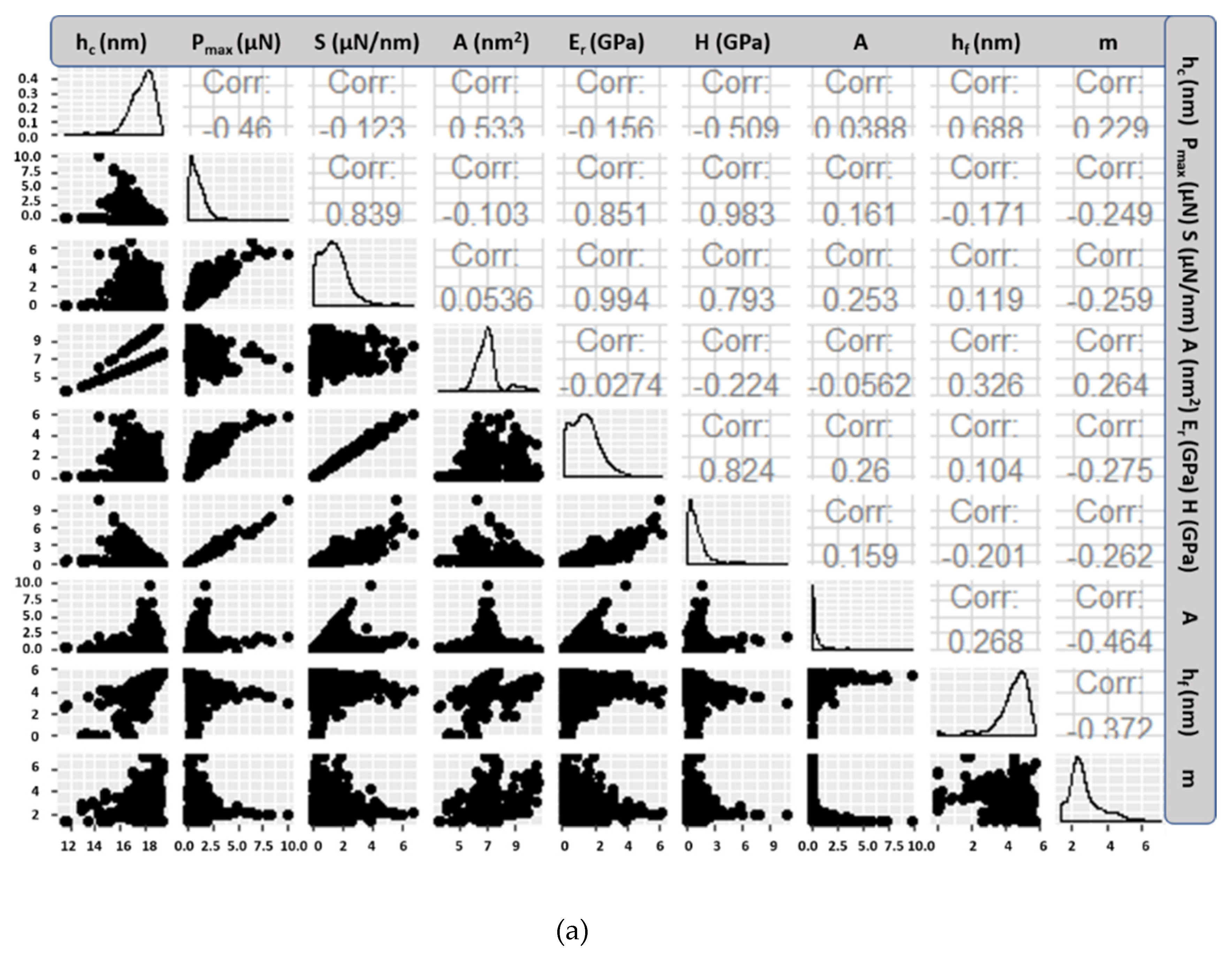
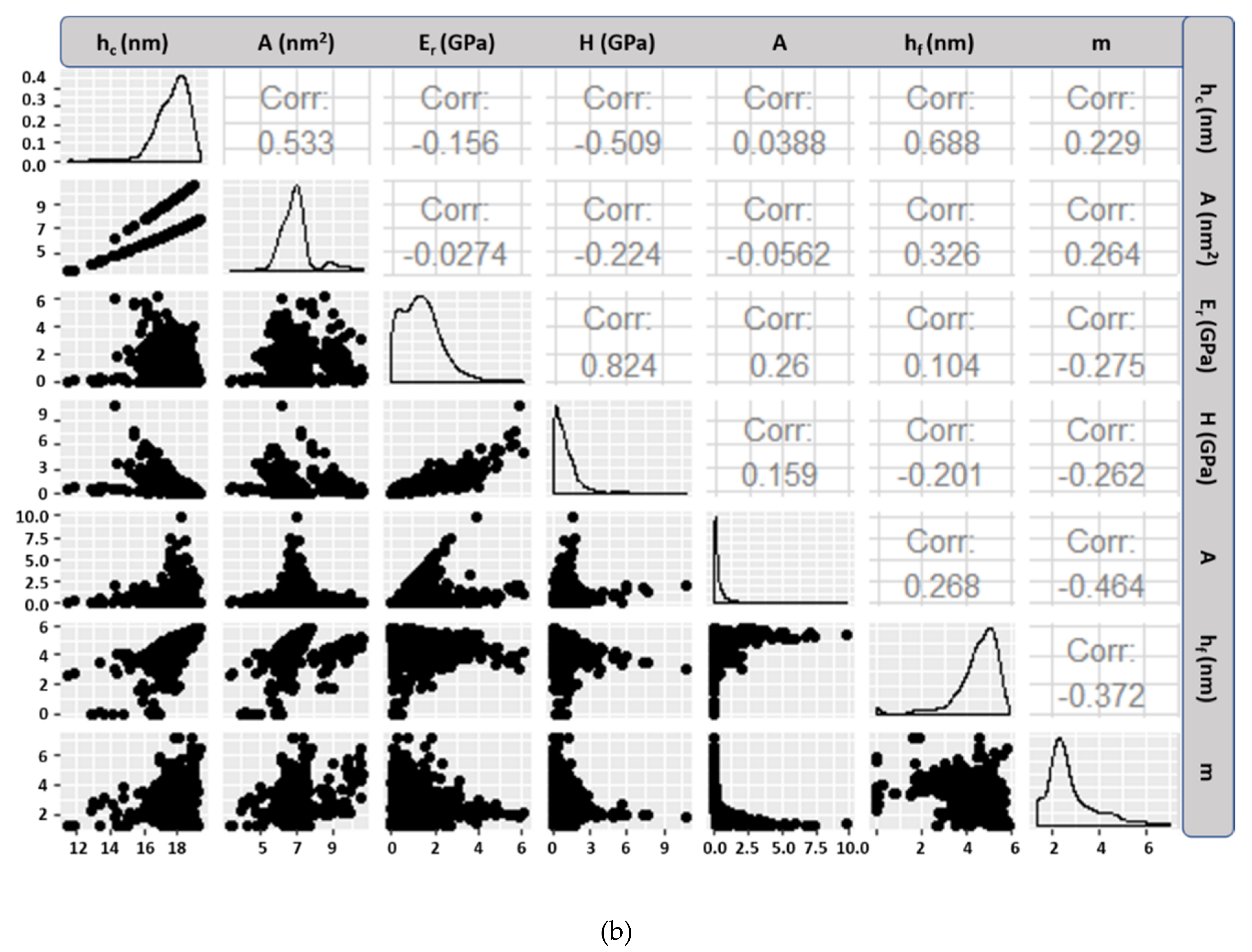
Grid nanoindentation is a highly localized and non-destructive technique with high spatial resolution [
6,
7]. It is a method that is suitable for fast and precise characterization of construction materials as concrete, metal alloys, coatings, and composites reinforced with micro- and nano- materials [
3,
6,
7,
9,
13,
15,
16], being one of the few techniques that can directly assess the mechanical properties at micro- and nano- level by a single experiment [
6,
17]. Nanomechanical properties, and especially reduced Elastic modulus (
Er), are involved in materials design and various set-ups [
18,
19]. These applications are very sensible in regards to the applied loads and are closely related to human and environmental safety. This input can be obtained in a representative manner, since statistical nanoindentation is able to characterize a surface via a multitude of indentation events [
15]. Also, the contact surface is in the same scale of the characterized phases as in case of heterogeneous cement interface [
20]. Grid size is usually sufficiently large, for instance when testing concrete, to encompass the various cement phases [
6]. Quantification of the constituent volume fractions provides insight of the composite as a whole entity [
6,
19]. Thus, the generated data are suitable for statistical representation of nanomechanical properties of the tested material [
6].
Focusing on the case of cement composites, a lot of effort is put in regards to nanoindentation [
7]. Nanoindentation technique is gaining widespread attention due to the ability to both identify and quantify cement phases [
6,
17,
21]. In detail, pores
Er and hardness (
H) are derived by interfacial interaction with the low density (LD) boundary phases [
22], and
Er of hydrated phases is connected to degree of hydration [
4,
23]. Hardness is related to the yield strength of the hydrated cement phases, which are considered to behave as rigid cohesive plastic solids, granted that the size of interaction volume is smaller than indentation imprint. As part of this procedure, individual hydrated cement phases have been tested and processed via statistical analysis to determine
Er and
H of these phases [
23,
24], in order to provide the ability to connect mechanical properties to structure (density, crystallinity degree).
Portland Cement is used in every-day applications due to the low-cost, and workability. Calcium Aluminate Cements (CAC) facilitate protection from corrosion, temperature resistance, high strength, but are available at higher cost [
25]. The main difference with ordinary Portland Cement lies in the active phase that is responsible for hardening due to the high aluminum content (up to 80 wt.%) [
26]; monocalcium aluminate (up to 46%) is the active phase in CAC and yields into calcium aluminate hydrates (CAHs) formation instead of C–S–H [
25]. In the present study, CEM I 52.5 N Portland Cement was used, which consists of 4.75 wt.% Al
2O
3, 19.47 wt.% SiO
2, and 63.16 wt.% CaO; the absence of aluminate hydrates is expected, considering the phase diagram of CaO-Al
2O
3-SiO
2 [
26], thus C–S–H and CaOH (Portlandite) dominate [
27]. Ettringite phase exists in the matrix phase mixed with Portlandite, at significantly lower ratios considering the sulfur role in ettringite formation and in the initial composition of CEM I 52.5 N [
27,
28]; it is expected to comprise up to ~5% combined with CAHs in the cement paste. The dominance of C–S–H is also reported in mixtures of Portland Cement and <20 wt.% of CAC, while alumina presence is restricted in the form of ettringite, calcium aluminomonosulfate, or C
4AH
x [
26]. A short summary of material parameters determined by nanoindentation and correlation to cement phases is provided in
Table 1.
The main target of this work is to identify each cement phase nucleation dependence on nano-reinforcement by carbon nanotubes (CNTs) by clustering material parameters determined by nanoindentation initially and by identifying the hydrated cement phases with k-nearest neighbors, support vector machines, and classification tree algorithms further on. Nanoindentation data analysis is used to train models for prediction of hydrated cement phases by using raw data as input. This step is essential to overcome exhaustive probability distribution fitting approach, in order to reach unbiased conclusions about phase composition. Till now, this approach involved the use of error minimization procedures, due to the non-uniqueness of the solution [
44] and depends on the selection of initial values [
6], i.e., when fitting five phases with five Gaussians, a 15-dimensional (3 Gaussian parameters × 5 phases) is created and the solution represents one of the local optima [
43]. Also, skewness of fitting is usually omitted by nullifying the third and fourth statistical moments in order to simplify analysis [
38]. This is a task of predictive modeling, which was performed using statistics in the past decades due to insufficient computational power. Predictive modeling is rapidly growing, due to the availability of computational resources, and better results are obtained with implementation of ML [
45]. Consequently, structure-property relations will enhance objectivity and knowledge-gain for decision making by the incorporation of ML.
The matrix area of Portland Cement was selected for characterization, considering the fact that C–S–H is the major contributor in the final properties and durability of hardened cement [
27]; measure nanomechanical properties in the interface transition zone to monitor phases nucleation. To our knowledge, this is the first time that cement mechanical properties are processed with ML to monitor the microstructure evolution and establish unbiased structure-property relations. Except for image classification (i.e., from Scanning Electron Microscopy, X-ray Tomography) and elemental analysis (i.e., from Energy Dispersive X-Ray Spectroscopy–EDX) no other data have been processed with ML algorithms to date, in order determine the cement and concrete hydrated phases quantitatively [
4,
17,
31,
46]. Specifically, the spatial deconvolution of Calcium(-Silicate)-Hydrates (C–S–H) of lower and higher density is not yet envisioned with AI, while there is no feedback for the interface effect induced by the neighboring clinker regions; image analysis of these regions is restricted by the color definition, which is the same for C–S–H and interfacial effect of clinker may be considered as Portlandite (pixels attributed to clusters) [
31]. This fact hinders any straightforward connection of hydration progress and hydrated cement phases; this challenge is met by involving nanomechanics and supported further by the prediction metrics, which are exceeding relevant reported values for identification of individual phases of cement matrix using nanoindentation compared to image data analysis. The methodology implementation for phase identification in cement is expected to enhance analysis of testing ordinary Portland Cement by the transfer learning potential of the developed models. It is also expected to contribute to testing other formulations or concrete; similar principles are involved, along with data preprocessing, the use of classification algorithms by making several adaptations.
4. Discussion
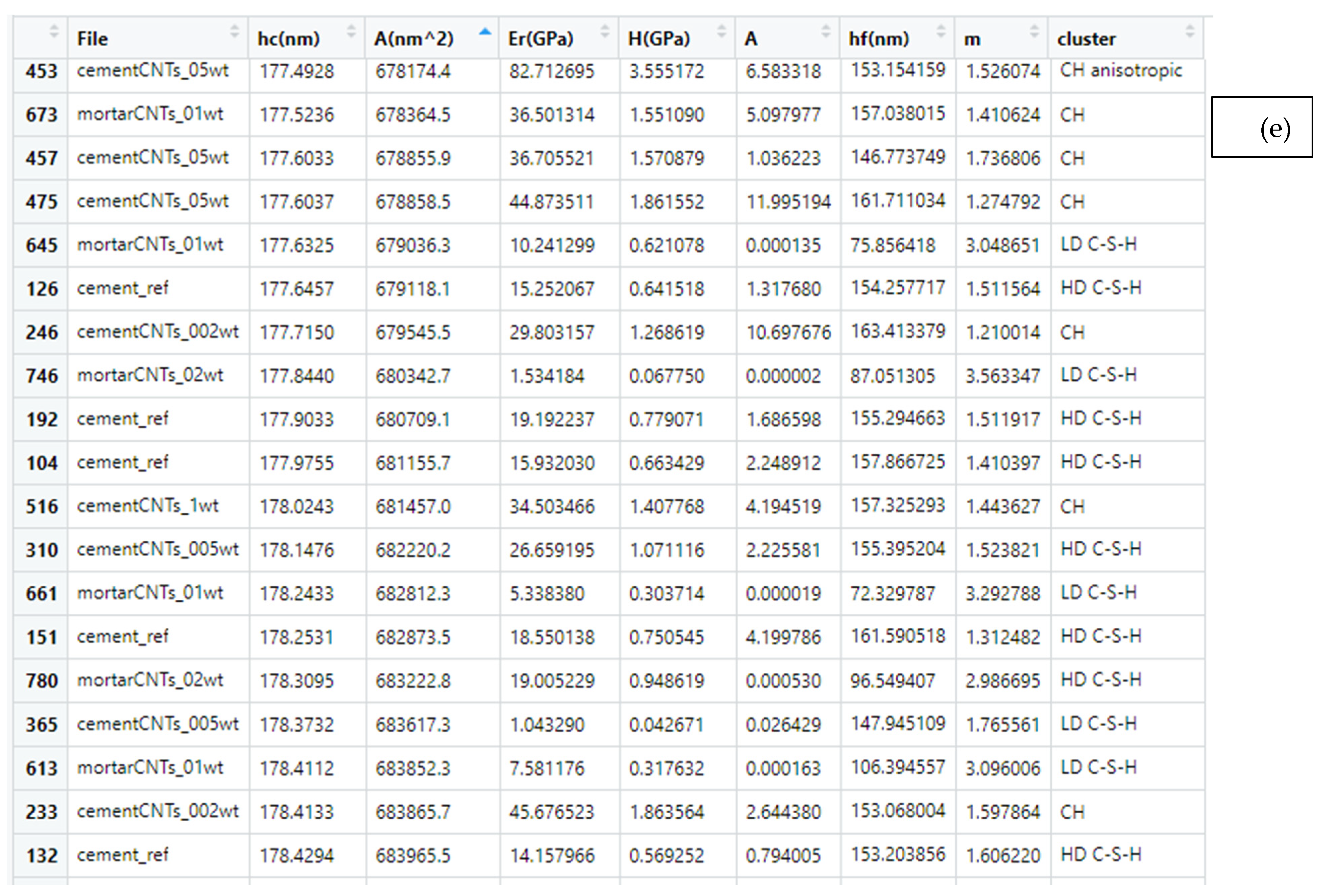
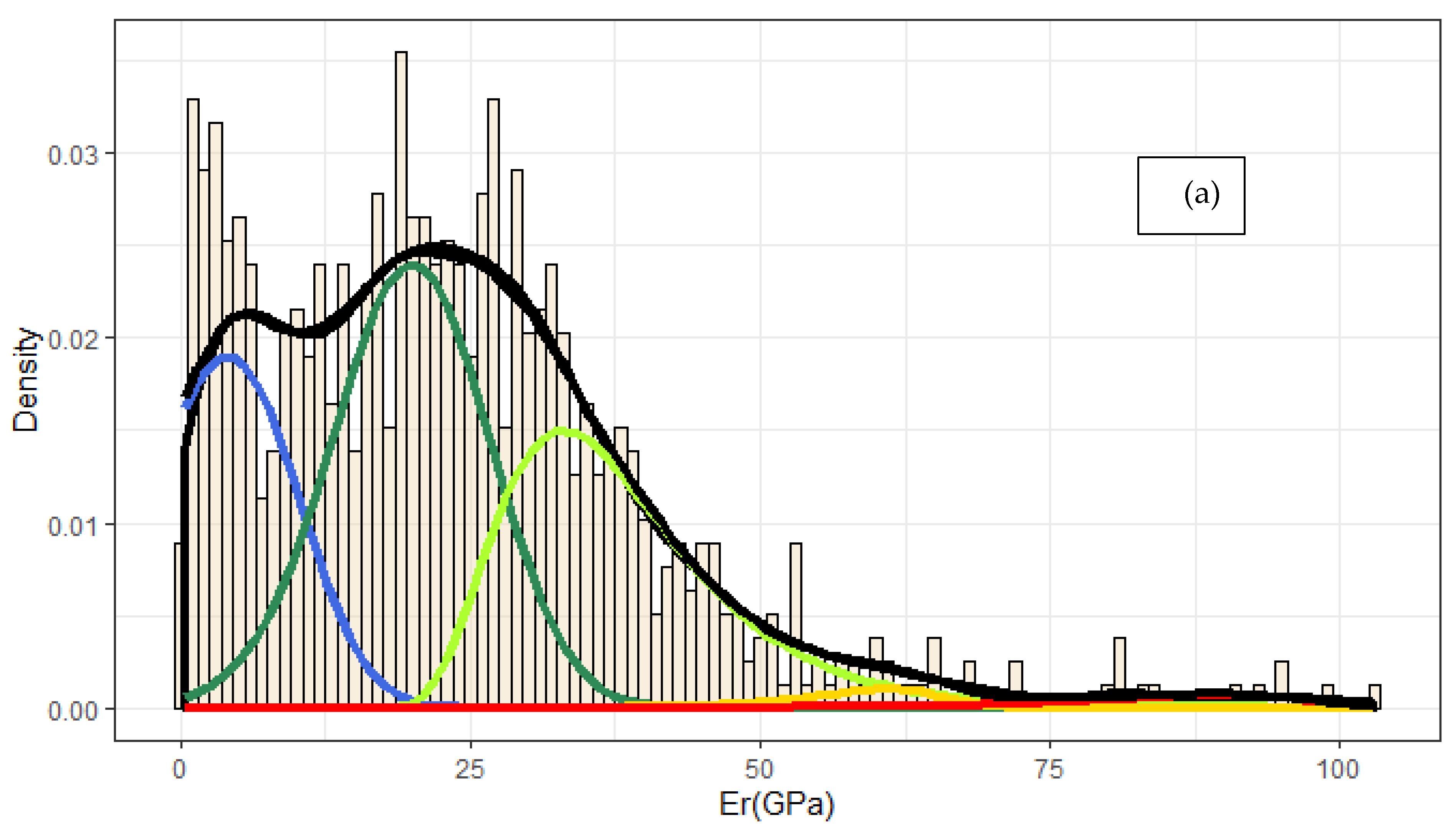
Till now, the most common approach when studying the cement hydrated phases with nanoindentation included Probability Distribution Analysis. This approach was based solely on deconvolution by Gaussian fittings, which suffers from the non-uniqueness of the solution. The number of peaks in the density plot, and thus the number of Gaussians, create a multidimensional space when measuring the parameters of the solution, and this approach suffers by the existence of more than one global optima. As a consequence, the analysis of the same nanoindentation data may vary amongst individuals. Moreover, third and fourth statistical moments are nullified by assuming zero skewness and using Gaussians to fit data, which introduces another factor for error evolution. Within this study, a practical approach in PDA is summarized by introducing skewness by the incorporation of Fraser–Suzuki equation for fitting. The input parameters of pi, si, Em,I, di are useful for later analysis with integrals and calculation of the composition percentage of each individual phase.
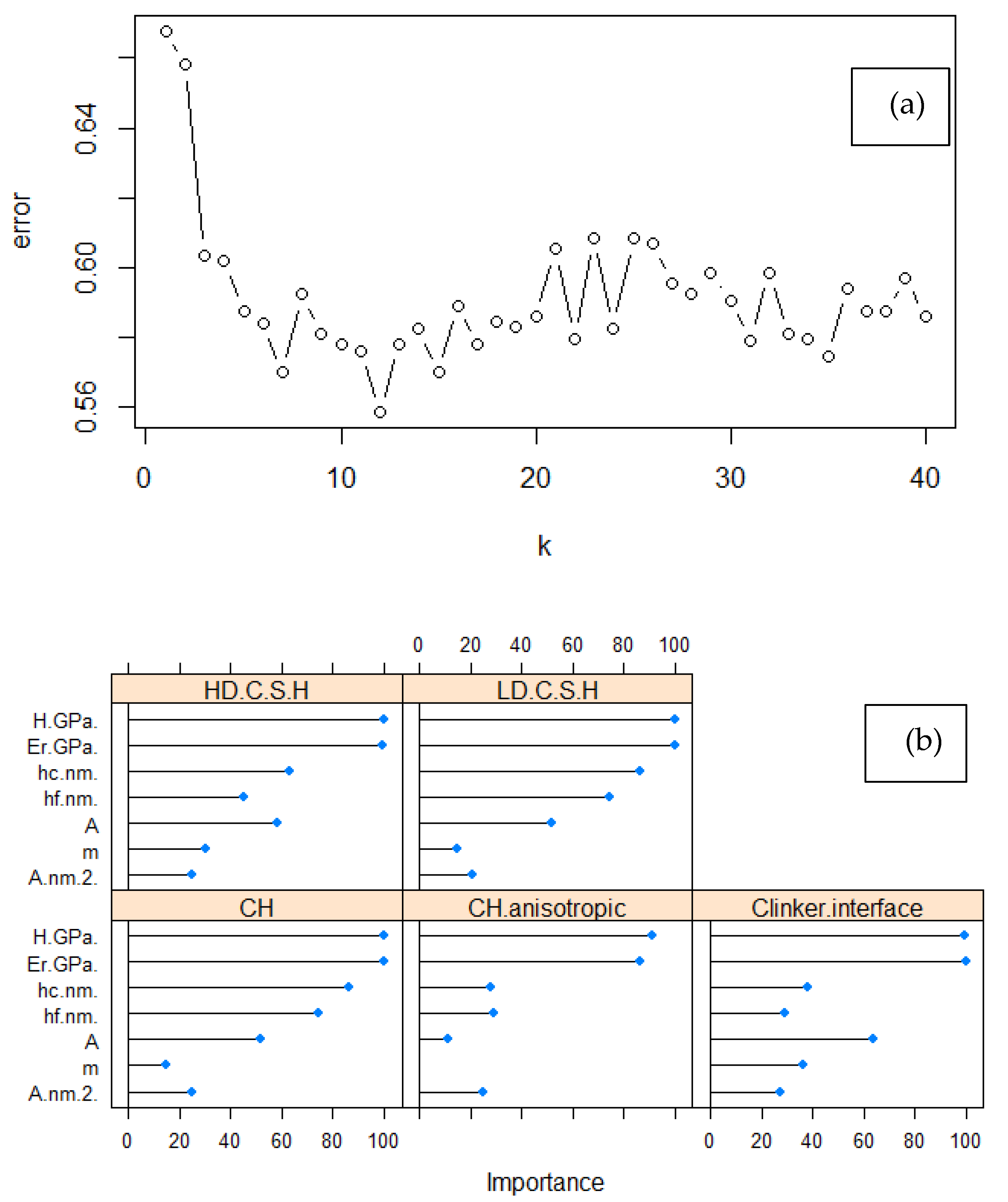
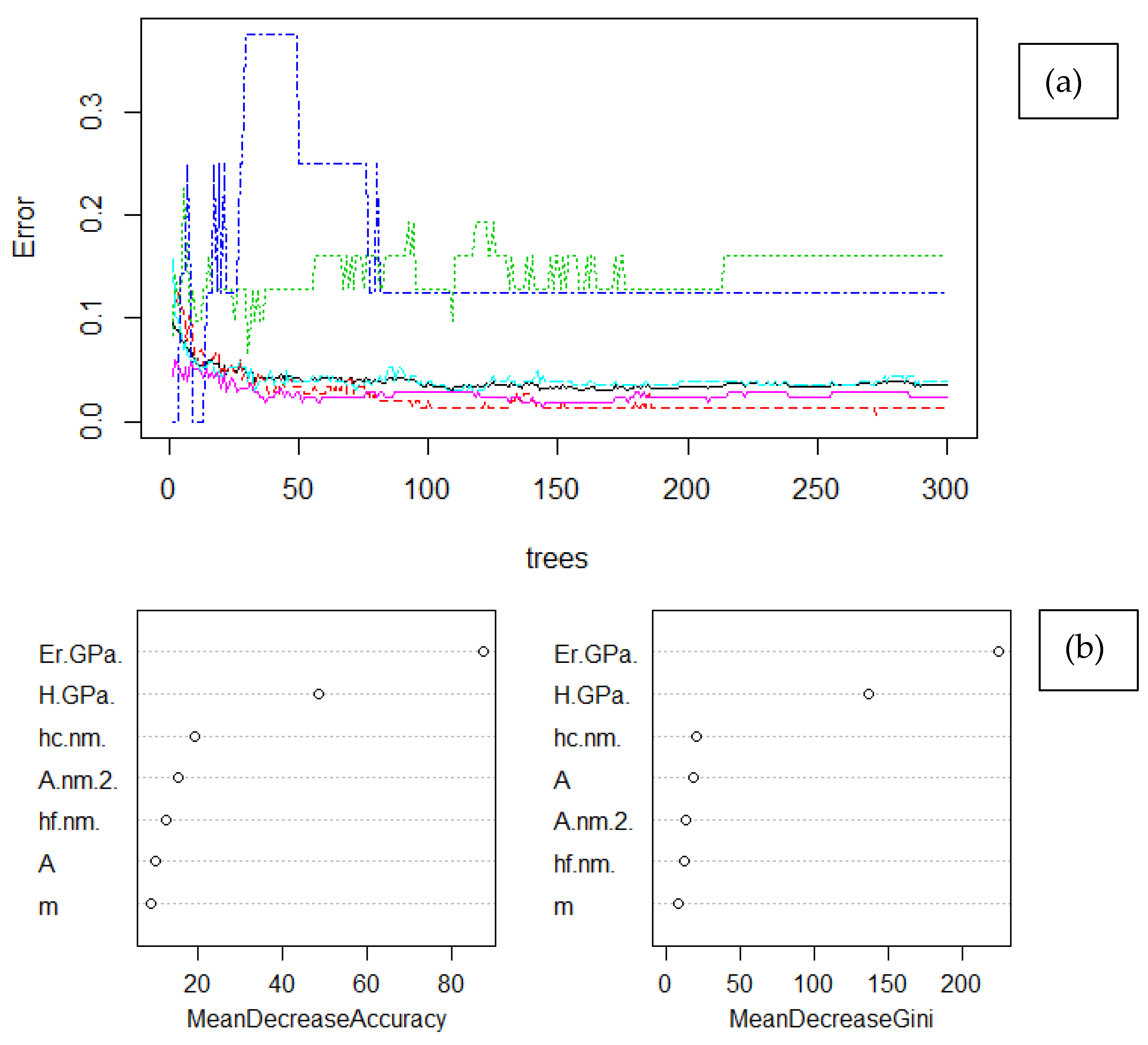
Machine Learning came up as a more efficient route to deal with the multivariate problem of nanoindentation raw data. Implementation of an unsupervised ML algorithm for unbiased determination of cement phases was demonstrated using k-means clustering. Unsupervised phase identification showed the magnitude of variation in microstructures volume fraction. This is an introductory step for labelling the test data. Labelling is useful to perform quick evaluation of cement composition by training supervised ML models for performing quality control of the synthesized or nano-enforced cementitious structures. This approach known as semi-supervised Machine Learning is also unbiased, can be reproduced, and combines multidimensional features. Inclusion of seven variables enables establishing structure (cement phase)—property (parameters: Er, H) relations to contribute in reinforcement identification due to possible enhanced propagation of hydration and nucleation aided by nanomaterials. This reinforcement is envisioned especially in cement interface (or matrix) and the compositional changes in LD, HD C–S–H, and CH phases, considering that better interfacial properties will improve overall performance.
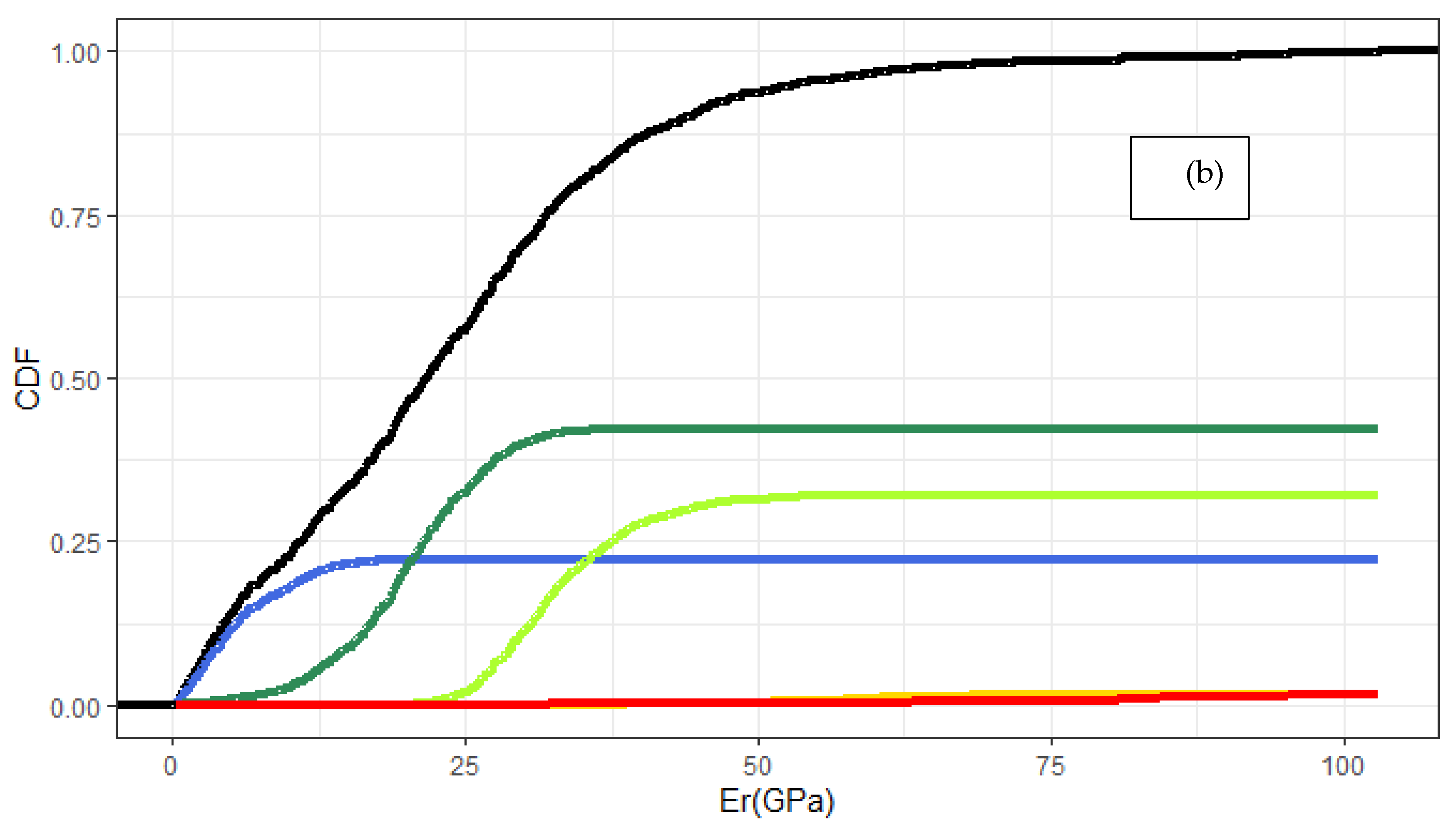
Cement phase identification, which was implemented using two methodologies, a PDF fitting with skewness and unsupervised ML algorithm of k-means enabled to identify the strengths of each approach directly. In the first case, PDF was applied based on Fraser–Suzuki function in order to improve fitting results as asymmetry is enabled. This implementation is also available in the shape of Shiny app to fit
Er nanoindentation data using R language [
62]. Two significant aspects should be pointed out. Firstly, the presented case required 5 PDF fittings, which means that a 20-dimensional space (5 PDFs × 4 parameters) is created for the problem solution. Thus, the proposed fitting falls within one of the local optima set of solutions. As a result, it can be understood that another solution may be chosen by another individual. Secondly, the solution in PDA is about the single-parameter problem (here: reduced elastic modulus). The deviation is high, as expected, compared to k-means clustering approach, which incorporated more variables to provide the microstructure clusters. As demonstrated in
Figure 10a, the PDA predictions were biased to HD C–S–H and CH phases. This deviation was not encountered for the clinker interface, as both methodologies lead to similar results in case of
Er value, possibly due to the low population of available data. In this direction, k-means correlated material parameters to cement chemical structure using both parameters
H and
Er as input. Consequently, k-means was used for unbiased labelling of the nanoindentation data in order to feed the data for multiclass classification and perform semi-supervised Machine Learning. In conclusion, identification of cement phases using nanoindentation data is improved when it is approached as a multivariate problem with Machine Learning, which was expected in principle [
45].
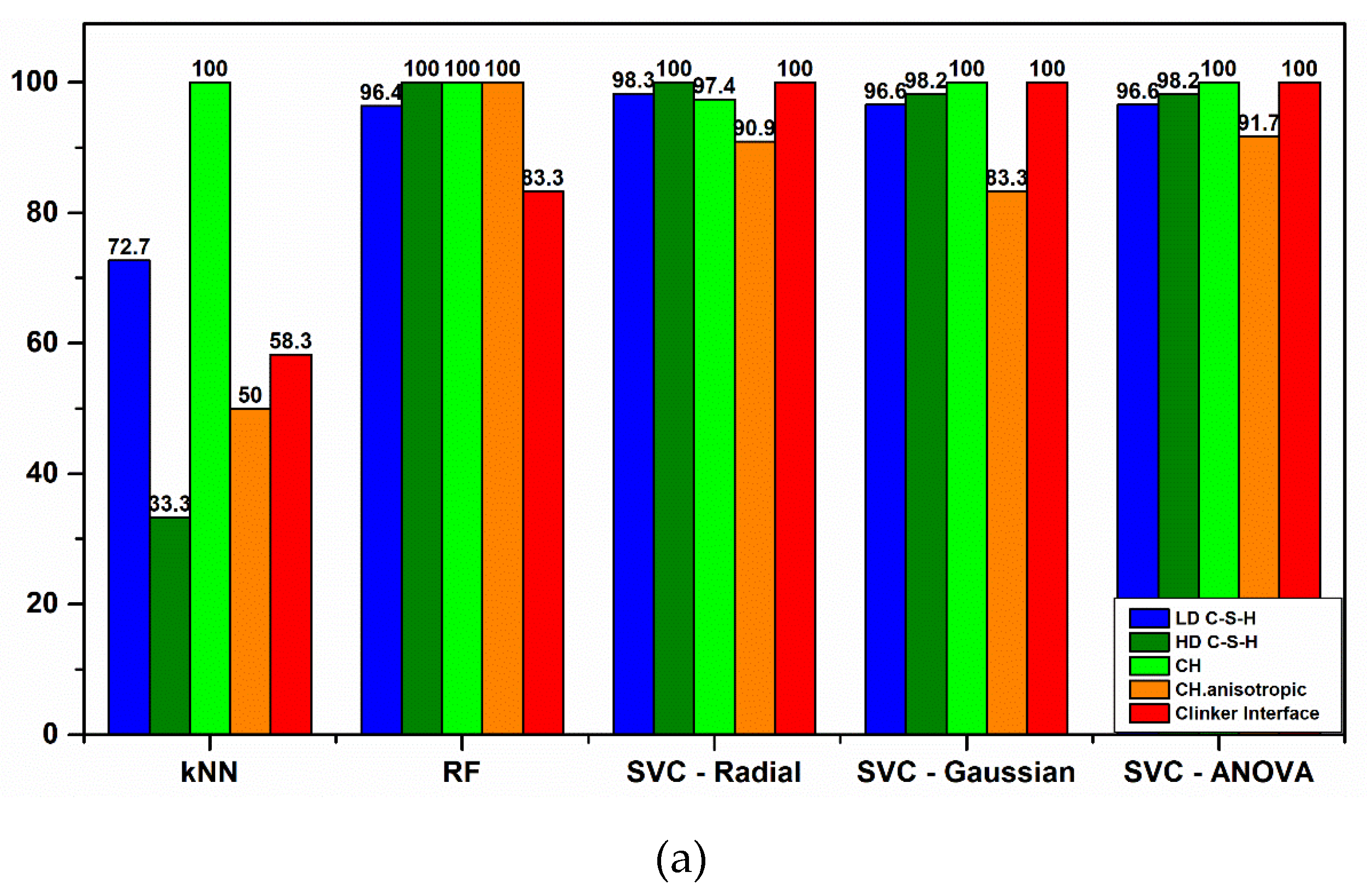
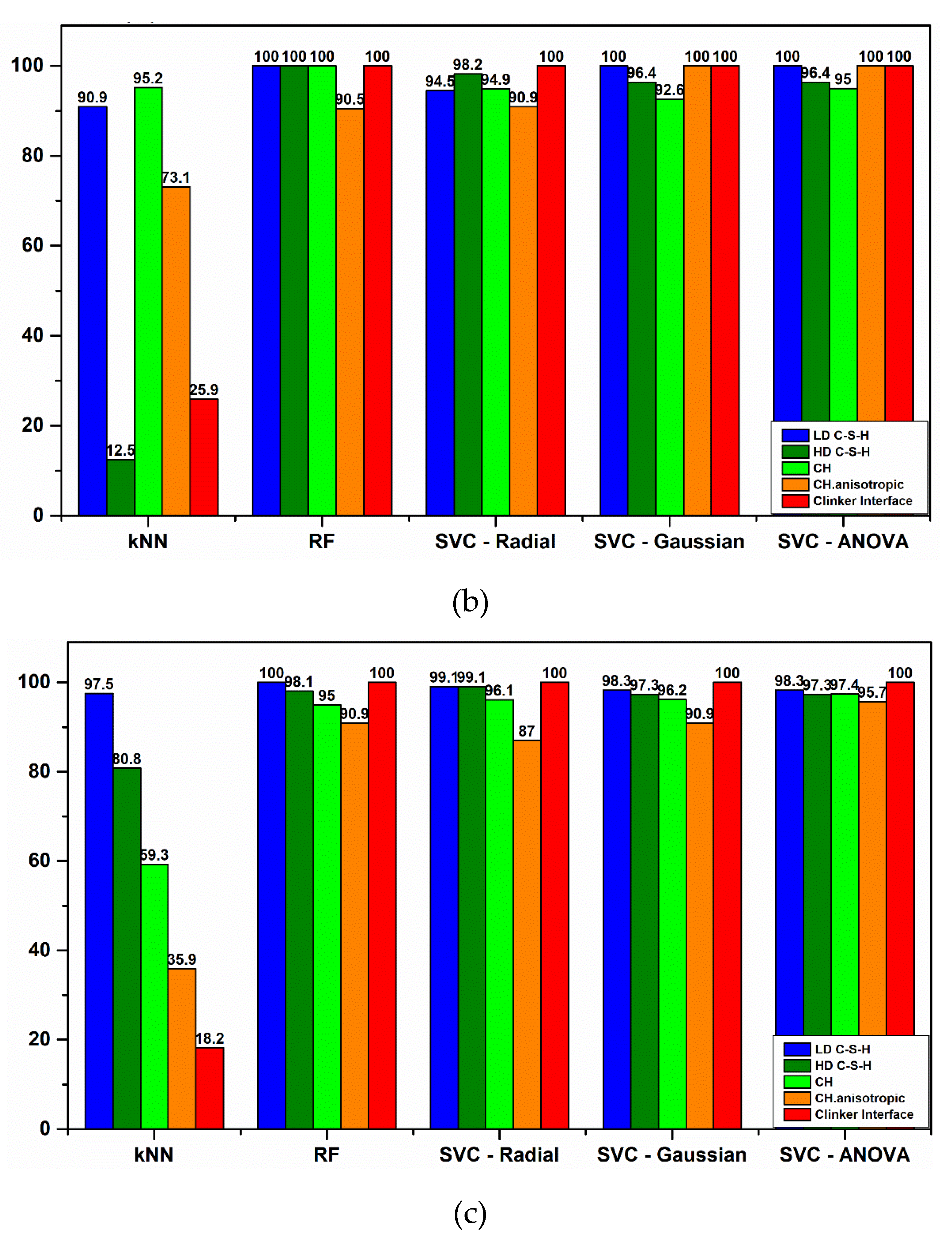
In another case, k-means clustering has been used in order to predict the nanoindentation response of a given location in FCC single crystals [
51], with overall accuracy to reach 90%. In this work, multiclass classification was performed using common algorithms of KNN, RF, and SVC reaching a maximum accuracy of 97.6% (
Figure 10b). In detail, KNN model was trained in order to predict the classes in the test dataset. However, the model performance was not adequate even after tuning of hyperparameters, especially for the high-stiffness phases identification, reaching a minimum F1 score of 0.18 (
Figure 10e). This result could be possibly correlated to the low population of data for these cement phases and imbalance in the population amongst cement microstructure classes [
53]. On the other hand, all other algorithms (RF and Radial, Gaussian, and ANOVA SVC kernel types) after being properly tuned were able to use all seven variables to correctly classify nanoindentation events to Portland Cement phases. A minimum score of F1 = 0.87 in case of Radial SVC kernel was achieved and the highest minimum-class predictive score of F1 = 0.96 was accomplished with ANOVA kernel. Also, with ANOVA kernel the weakness of SVC in Precision metric was overcome. Although RF demonstrated the same number of misclassifications in the test dataset as ANOVA SVC kernel, in fact, misclassifications are not accumulated in a single category when using ANOVA, which is preferable compared to Random Forrest. The key in finding the best possible algorithm for each scenario is identified in testing a variety of classification algorithms in order to find the right balance between Precision and Recall metrics, since often it is challenging to keep both high in value (
Figure 11a–c). Even if Random Forrest provided the highest Recall in HD C–S–H and CH phases, it was preferred to sacrifice Recall in favor of achieving higher Precision in classification of those two phases, in order to reduce misclassification error of the trained models in future input of unseen data and achieve high prediction metrics in all hydrated cement phases.
5. Conclusions
This study aimed in the implementation of an enhanced practice for analysis of cement microstructure with nanoindentation testing. Step-by-step methodology of data preprocessing, labelling, and classification is summarized in order to enhance interlaboratory reproducibility of the results. It is important to note that nanoindentation protocol for mapping majorly affects the usability of data for phase identification and highlights the necessity for establishing good practices in testing cement formulations. A common approach in characterization protocols is essential to enable data exchange and further developments in characterization methods. Semi-supervised Machine Learning was implemented due to the enhanced efficiency in predictive modeling of microstructure. In principle, Machine Learning exceeds traditional statistics for predictive modeling. This is derived by the inclusion of more variables, and thus data, to pattern relationships in the labeled data. The fitted patterns become more complex and contain more information for the microstructure classes. This is a gain compared to traditional statistics for prediction of cement phases, which in case of Probability Distribution Analysis, uses a single parameter for identification. Increased complexity in relations of nanoindentation data and cement microstructures enhances the level of prediction accuracy when testing other formulations not previously used for training Machine Learning models. High values obtained for prediction metrics demonstrate the transfer learning potential, which is performed with extrapolation in traditional statistic and usually suffers from poor accuracy.
This work contributes to the field of cement nanocomposites design and quality control associated with identifying the effect of low dosages of engineered nanomaterials inclusion in reinforcement assessment; microstructure, and mechanical properties of cement-based composites can also be correlated to the fabrication, workability, and hydration in optimization tasks. The extensive use of statistics in the microstructure identification in the past decades was reasonable since computational strength was limited. However, technology evolution increases the necessity of materials scientists to adapt and improve their tools and data capacity for closing the gap of new ideas for design and applicability evaluation with less effort and need for resources. In this direction, Artificial Intelligence can provide a module for enabling fast, in-line, and real-time metrological characterization of nanoindentation data. Emphasis is located on classification of newly characterized data (specimen testing) based on a labelled database, which is promising to minimize the requirement for human effort in quality control and life assessment of Portland Cement formulations. The proposed microstructure analysis of Portland Cement using AI on nanoindentation data processing provided considerable proceedings; namely, classification reached an ultimate plateau value of 97.6% model accuracy using ANOVA SVC kernel and minimum F1 score of 95% in the five-class classification problem. Additionally, all approaches required a few seconds of computational time for clustering, training, and fitting. The high levels of accuracy hold promise for transfer learning potential and scalability of this methodology to expand prior obtained knowledge on new data.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














