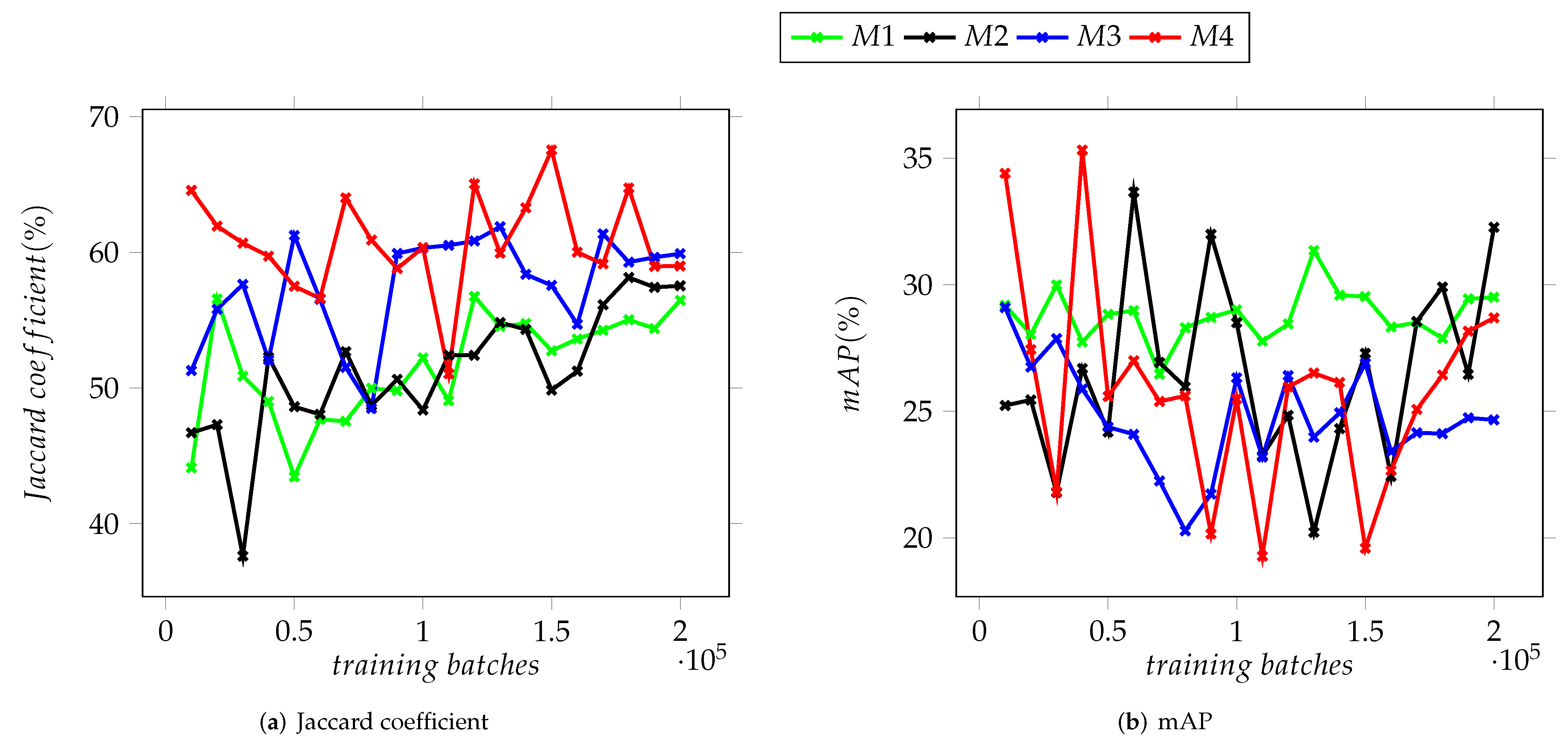
The third validation dataset, composed of micrographs of HA and Ag nanoparticles, was used to evaluate the performance of the trained models on images not belonging to the original Ag sample nor the NFFA SEM image repository. The charts displayed in
Figure 10 summarize the achieved IoU and mAP values for the third validation dataset, in which the M4 model attained values of 67.54% and 35.32%, respectively.
For this third dataset, the trained models yielded similar results to the ones obtained for the first two, a disparity between the Jaccard coefficient and mAP, regardless of the model tested and, in the case of this dataset, the distance between the nanoparticles depicted in a given image.
Detected Particles
After testing the trained models on the third validation dataset, Model M4 yielded the highest percentage of correctly detected particles at 62.50% after 10,000 training batches, analogous to the detection of 40 out of 64 annotated objects plus 31 unlabelled nanoparticles, as shown in
Table 7. This table also shows that for Models M1 and M2, the highest percentage was achieved at least twice after training with increasing numbers of training batches.
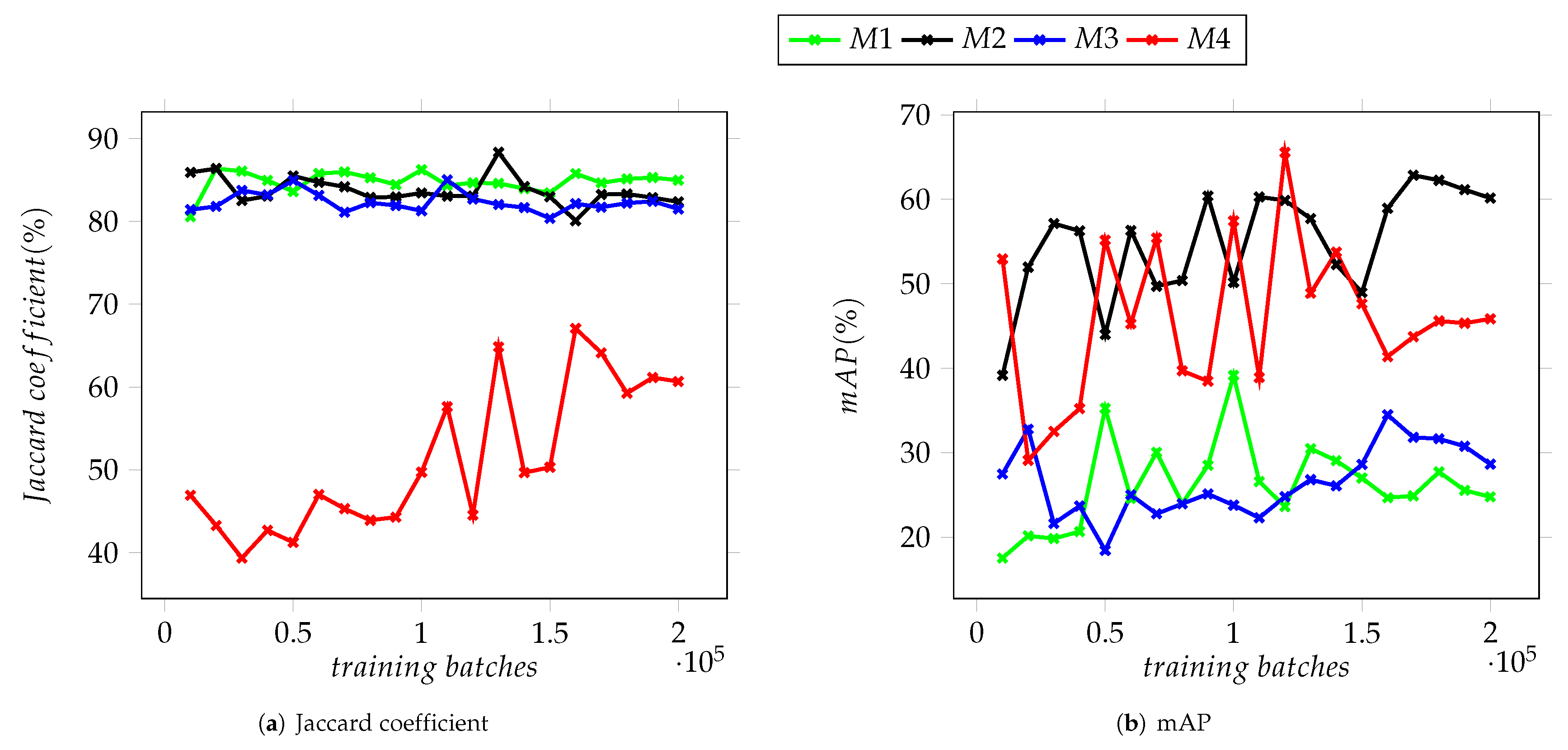
As shown in the graphs in
Figure 8,
Figure 9 and
Figure 10, there is noticeable difference between the models based on Version 3 of the YOLO neural network and the two based on Version 4 which can be attributed to the improvements between these versions. The values of mAP display the greatest variation, particularly for Dataset II and stand in contrast with the results obtained for the Jaccard coefficient, where the latter is above the 80% mark. The mAP for the four models remained under 70% (see
Figure 9b). The disparity between the Jaccard coefficient, mAP and the percentage of detected NPs seen in all datasets suggest that while most of the trained models are capable of detecting the nanoparticles present in a given image, they display moderate success in being able to correctly categorize them. This is tied to the similarity between the training datasets and the validation ones.
In
Figure 8,
Figure 9 and
Figure 10, it is observed that as the training batches increase, there is an instability in the detection of objects. This is explained considering that the complexity of the images used in the testing datasets increased as described below. It is important to mention that it was performed in this way since it is expected that any user who has micrographs obtained in a SEM, regardless of the quality of the images, can use these YOLO-based models to support the characterization of their materials.
Dataset I contains images very similar to the ones used to extract the templates for synthetic image generation. Not only are distinguishing features such as the contrast between the edges of a nanocube it faces very similar, but their position and numbers across the image resemble the scattering these nanostructures display when viewed through a scanning electron microscope, hence the high levels of detection on this dataset. Next, we have the images from the second validation dataset, which display a higher number of Ag nanoparticles per image, as well as these being much closer to each other and even having some nanocubes on top of others. This coupled with the refinement of the images during capture, which removed the bright edges on most of the observed nanocubes, and YOLO’s difficulty to detect objects that are within close proximity to each other, makes the whole set of annotated nanocubes different enough from the ones used during training to make the trained models miss most of the particles in the dataset.
Finally, the characteristics of the electron microscopes, such as maximum magnification, resolution of both SE and BSE detectors and electron source, used to capture the images used for training are different from the one used for validation. The micrographs depicting Ag nanocubes from Datasets I and II, along with the ones belonging to the NFFA repository were captured at a greater magnification than the one allowed by the SEM equipment used for the images from Dataset III. These differences, along with the variables added by the sample preparation methods used prior to characterization by electron microscopy, make the particles easier or harder to identify to both the human eye and the trained neural network models. The relatively low resolution of the latter microscope produced noise around the nanoparticles which made it difficult, even for a human expert, to distinguish a nanocube from a quasi-spherical particle.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}