Resting-State EEG Signal for Major Depressive Disorder Detection: A Systematic Validation on a Large and Diverse Dataset

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Related Works
1.2. Problem Description
1.3. Proposed Work
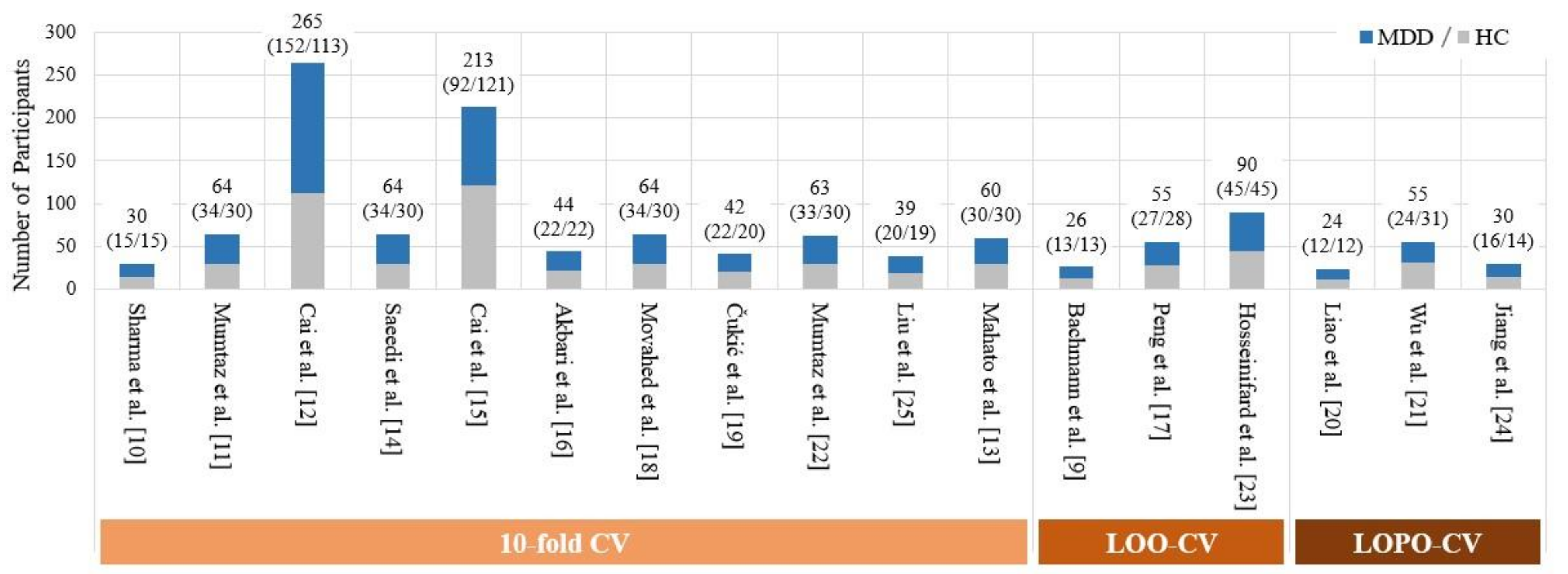
2. Cross Validation Used in Previous Works: More Detailed Review and Analysis
3. Materials and Methods
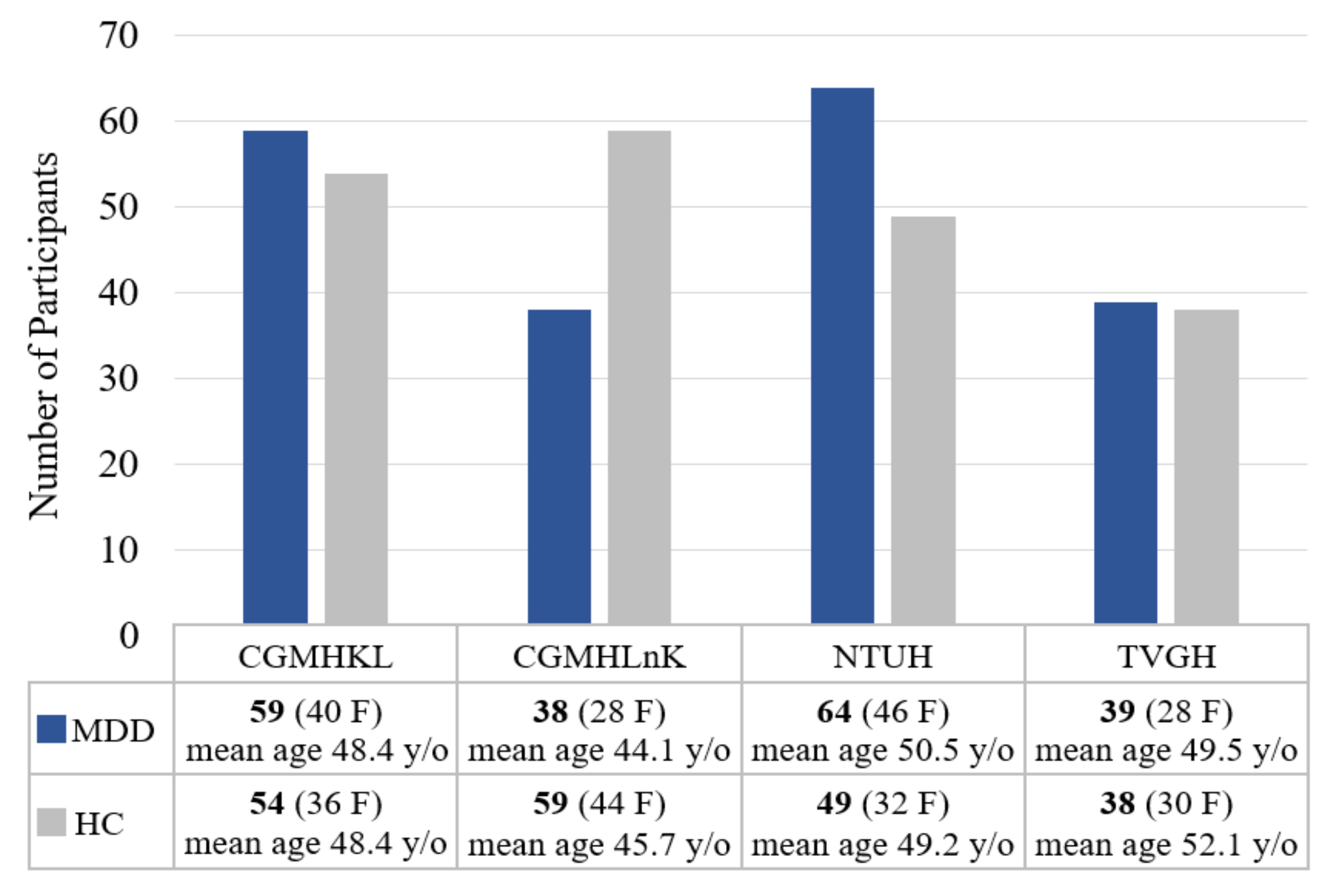
3.1. Participants
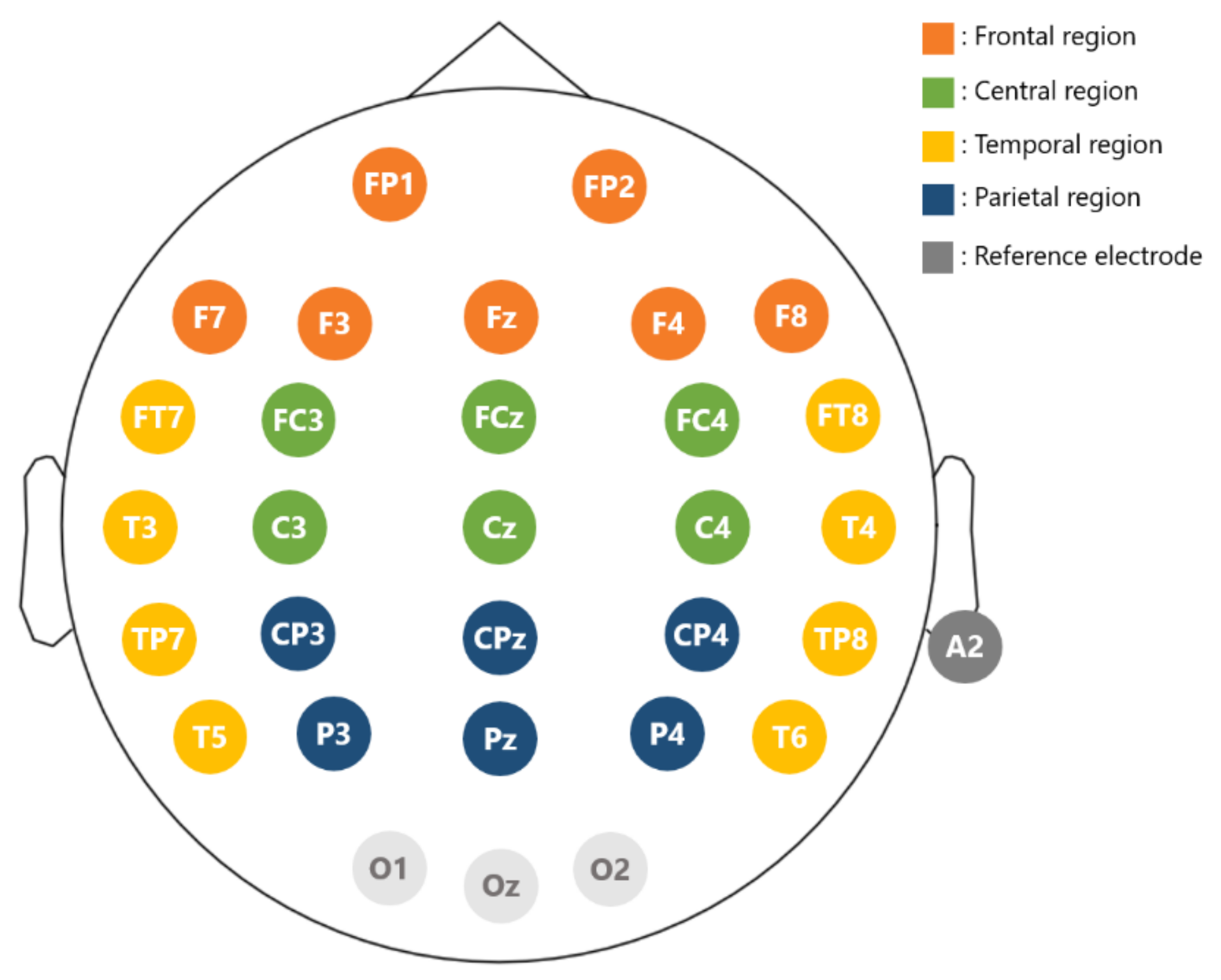
3.2. Apparatus
3.3. Data Collection and Preprocessing
3.4. Feature Extraction
3.4.1. Band Power (BP)
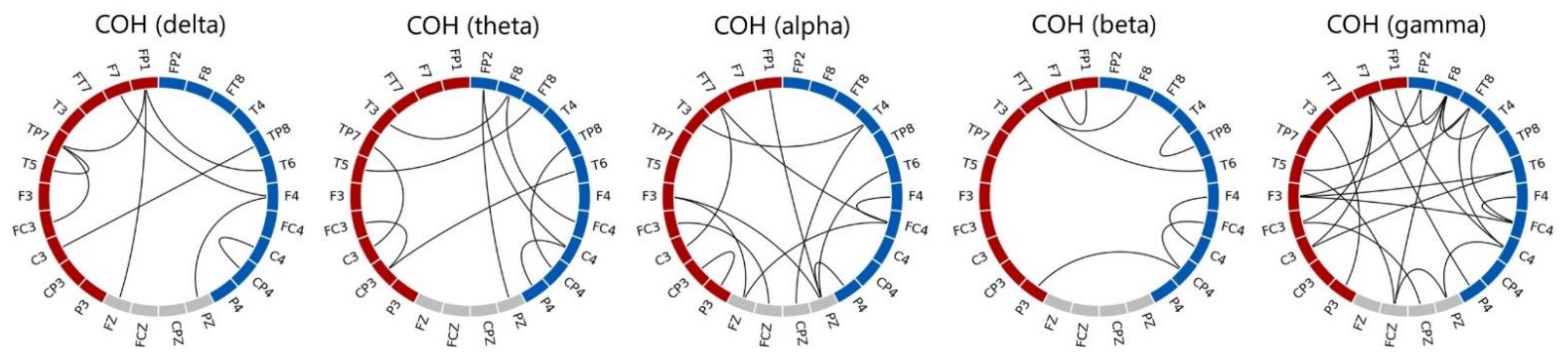
3.4.2. Coherence
3.4.3. Higuchi’s Fractal Dimension (HFD)
3.4.4. Katz’s Fractal Dimension (KFD)
3.5. Classification
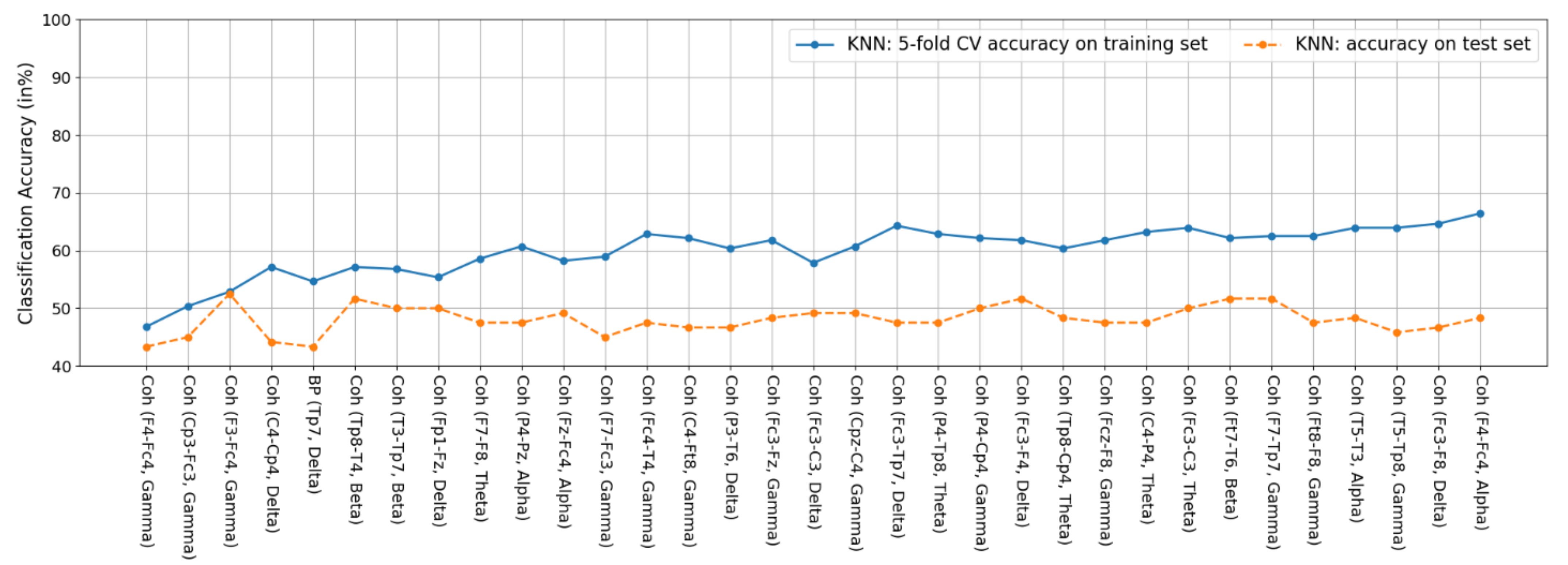
3.5.1. K-NN
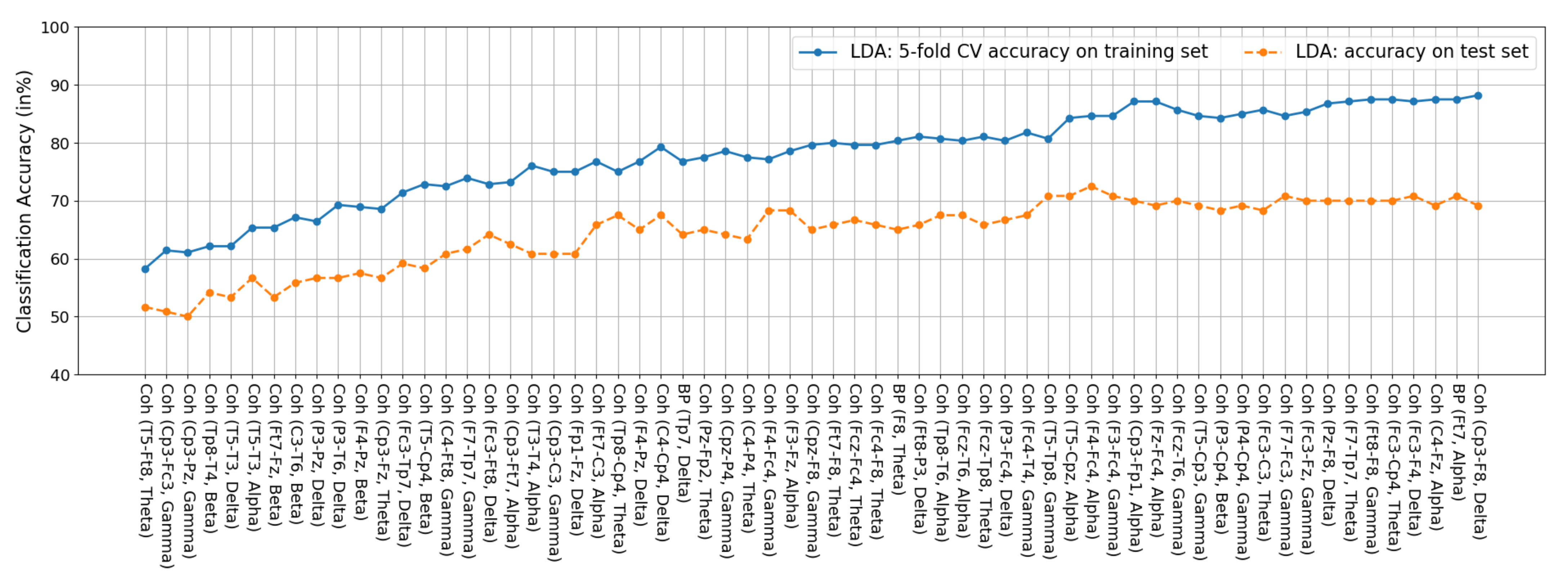
3.5.2. LDA
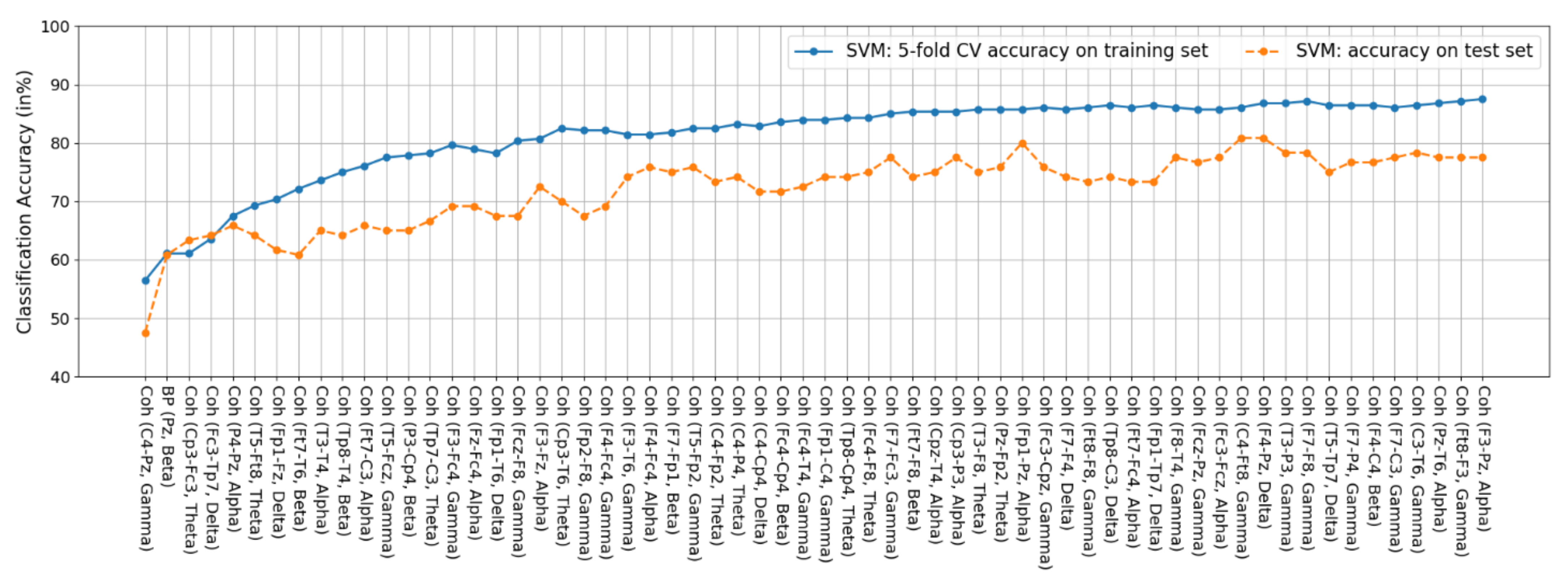
3.5.3. SVM
3.5.4. CK-SVM
3.6. Hyperparameter Optimization Procedure
3.7. Determine the Optimal Feature Subset Using Sequential Backward Selection
4. Results
4.1. Electrode- and Region-Specific Comparison of 5-Fold CV Classification Accuracy between Features Using LDA Classifier
4.2. Feature Fusion and Feature Selection Results
4.3. Comparison of Classification Accuracy between the CK-SVM and Other Classifiers
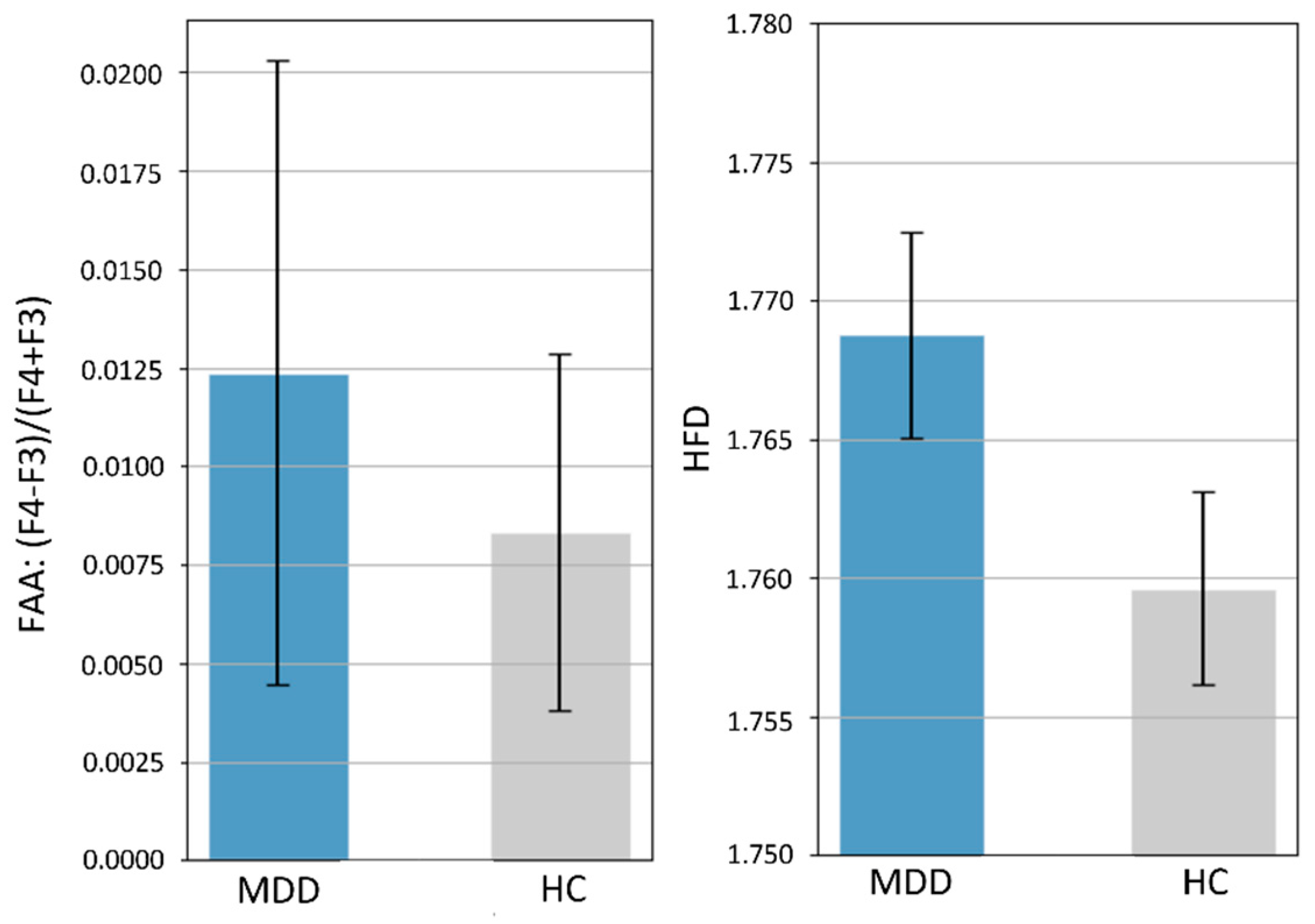
4.4. Comparison with Previous Literature: Statistical Analysis on Frontal Alpha Asymmetry (FAA) and HFD Complexity
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A



References
- Kupfer, D.J.; Frank, E.; Phillips, M.L. Major depressive disorder: New clinical, neurobiological, and treatment perspectives. Lancet 2012, 379, 1045–1055. [Google Scholar] [CrossRef] [Green Version]
- Friedrich, M.J. Depression Is the Leading Cause of Disability around the World. JAMA 2017, 317, 1517. [Google Scholar] [CrossRef]
- Greenberg, P.E.; Fournier, A.-A.; Sisitsky, T.; Simes, M.; Berman, R.; Koenigsberg, S.H.; Kessler, R.C. The Economic Burden of Adults with Major Depressive Disorder in the United States (2010 and 2018). PharmacoEconomics 2021, 39, 653–665. [Google Scholar] [CrossRef]
- Vos, T.; Abajobir, A.A.; Abate, K.H.; Abbafati, C.; Abbas, K.M.; Abd-Allah, F.; Abdulkader, R.S.; Abdulle, A.M.; Abebo, T.A.; Abera, S.F.; et al. Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Dis-ease Study. Lancet 2017, 392, 1789–1858. [Google Scholar]
- World Health Organization (WHO). Depression and Other Common Mental Disorders: Global Health Estimates. 2017. Available online: https://repository.gheli.harvard.edu/repository/11487/ (accessed on 5 December 2021).
- Proudman, D.; Greenberg, P.; Nellesen, D. The Growing Burden of Major Depressive Disorders (MDD): Implications for Re-searchers and Policy Makers. PharmacoEconomics 2021, 39, 619–625. [Google Scholar] [CrossRef]
- Goldberg, D. The heterogeneity of “major depression”. World Psychiatry 2011, 10, 226–228. [Google Scholar] [CrossRef] [PubMed]
- Čukić, M.; López, V.; Pavón, J. Classification of Depression through Resting-State Electroencephalogram as a Novel Practice in Psychiatry: Review. J. Med. Internet Res. 2020, 22, e19548. [Google Scholar] [CrossRef]
- Bachmann, M.; Päeske, L.; Kalev, K.; Aarma, K.; Lehtmets, A.; Ööpik, P.; Lass, J.; Hinrikus, H. Methods for classifying de-pression in single channel EEG using linear and nonlinear signal analysis. Comput. Methods Programs Biomed. 2018, 155, 11–17. [Google Scholar] [CrossRef]
- Sharma, M.; Achuth, P.; Deb, D.; Puthankattil, S.D.; Acharya, U.R. An automated diagnosis of depression using three-channel bandwidth-duration localized wavelet filter bank with EEG signals. Cogn. Syst. Res. 2018, 52, 508–520. [Google Scholar] [CrossRef]
- Mumtaz, W.; Ali, S.S.A.; Yasin, M.A.M.; Malik, A.S. A machine learning framework involving EEG-based functional connectivity to diagnose major depressive disorder (MDD). Med. Biol. Eng. Comput. 2018, 56, 233–246. [Google Scholar] [CrossRef]
- Cai, H.; Chen, Y.; Han, J.; Zhang, X.; Hu, B. Study on Feature Selection Methods for Depression Detection Using Three-Electrode EEG Data. Interdiscip. Sci. Comput. Life Sci. 2018, 10, 558–565. [Google Scholar] [CrossRef] [PubMed]
- Mahato, S.; Paul, S. Classification of Depression Patients and Normal Subjects Based on Electroencephalogram (EEG) Signal Using Alpha Power and Theta Asymmetry. J. Med. Syst. 2020, 44, 28. [Google Scholar] [CrossRef]
- Saeedi, M.; Saeedi, A.; Maghsoudi, A. Major depressive disorder assessment via enhanced k-nearest neighbor method and EEG signals. Phys. Eng. Sci. Med. 2020, 43, 1007–1018. [Google Scholar] [CrossRef] [PubMed]
- Cai, H.; Han, J.; Chen, Y.; Sha, X.; Wang, Z.; Hu, B.; Yang, J.; Feng, L.; Ding, Z.; Chen, Y.; et al. A Pervasive Approach to EEG-Based Depression Detection. Complexity 2018, 2018, 5238028. [Google Scholar] [CrossRef]
- Akbari, H.; Sadiq, M.T.; Rehman, A.U.; Ghazvini, M.; Naqvi, R.A.; Payan, M.; Bagheri, H.; Bagheri, H. Depression recognition based on the reconstruction of phase space of EEG signals and geometrical features. Appl. Acoust. 2021, 179, 108078. [Google Scholar] [CrossRef]
- Peng, H.; Xia, C.; Wang, Z.; Zhu, J.; Zhang, X.; Sun, S.; Li, X. Multivariate pattern analysis of EEG-based functional connectivity: A study on the identification of depression. IEEE Access 2019, 7, 92630–92641. [Google Scholar] [CrossRef]
- Movahed, R.A.; Jahromi, G.P.; Shahyad, S.; Meftahi, G.H. A major depressive disorder classification framework based on EEG signals using statistical, spectral, wavelet, functional connectivity, and nonlinear analysis. J. Neurosci. Methods 2021, 358, 109209. [Google Scholar] [CrossRef]
- Čukić, M.; Stokić, M.; Simić, S.; Pokrajac, D. The successful discrimination of depression from EEG could be attributed to proper feature extraction and not to a particular classification method. Cogn. Neurodyn. 2020, 14, 443–455. [Google Scholar] [CrossRef] [Green Version]
- Liao, S.C.; Wu, C.T.; Huang, H.C.; Cheng, W.T.; Liu, Y.H. Major Depression Detection from EEG Signals Using Kernel Eigen-Filter-Bank Common Spatial Patterns. Sensors 2017, 17, 1385. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.-T.; Dillon, D.G.; Hsu, H.-C.; Huang, S.; Barrick, E.; Liu, Y.-H. Depression Detection Using Relative EEG Power Induced by Emotionally Positive Images and a Conformal Kernel Support Vector Machine. Appl. Sci. 2018, 8, 1244. [Google Scholar] [CrossRef]
- Mumtaz, W.; Xia, L.; Ali, S.S.; Mohd, Y.; Mohd, A.; Hussain, M.; Malik, A. Electroencephalogram (EEG)-based computer-aided technique to diagnose major depressive disorder (MDD). Biomed. Signal Process. Control 2017, 31, 108–115. [Google Scholar] [CrossRef]
- Hosseinifard, B.; Moradi, M.H.; Rostami, R. Classifying depression patients and normal subjects using machine learning techniques and nonlinear features from EEG signal. Comput. Methods Programs Biomed. 2013, 109, 339–345. [Google Scholar] [CrossRef]
- Jiang, C.; Li, Y.; Tang, Y.; Guan, C. Enhancing EEG-Based Classification of Depression Patients Using Spatial Information. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 566–575. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, C.; Wang, X.; Xu, J.; Chang, Y.; Ristaniemi, T.; Cong, F. Functional connectivity of major depression disorder using ongoing EEG during music perception. Clin. Neurophysiol. 2020, 131, 2413–2422. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, Z.; Gong, T.; Zeng, S.; Li, X.; Hu, B.; Li, J.; Sun, S.; Zhang, L. An Improved Classification Model for Depression Detection Using EEG and Eye Tracking Data. IEEE Trans. NanoBiosci. 2020, 19, 527–537. [Google Scholar] [CrossRef]
- Fried, E. Moving forward: How depression heterogeneity hinders progress in treatment and research. Expert Rev. Neurother. 2017, 17, 423–425. [Google Scholar] [CrossRef] [Green Version]
- Farzan, F.; Atluri, S.; Frehlich, M.; Dhami, P.; Kleffner, K.; Price, R.; Lam, R.W.; Frey, B.N.; Milev, R.; Ravindran, A.; et al. Standardization of electroencephalography for multi-site, multi-platform and multi-investigator studies: Insights from the canadian biomarker integration network in depression. Sci. Rep. 2017, 7, 7473. [Google Scholar] [CrossRef] [Green Version]
- Zao, J.K.; Gan, T.-T.; You, C.-K.; Chung, C.-E.; Wang, Y.-T.; Rodríguez Méndez, S.J.; Mullen, T.; Yu, C.; Kothe, C.; Hsiao, C.-T.; et al. Pervasive brain monitoring and data sharing based on multi-tier distributed computing and linked data technology. Front. Hum. Neurosci. 2014, 8, 370. [Google Scholar] [CrossRef] [Green Version]
- Yeh, S.C.; Hou, C.L.; Peng, W.H.; Wei, Z.Z.; Huang, S.; Kung, E.Y.C.; Lin, L.; Liu, Y.H. A multiplayer online car racing virtual-reality game based on internet of brains. J. Syst. Archit. 2018, 89, 30–40. [Google Scholar] [CrossRef]
- Yang, Y.; Truong, N.D.; Eshraghian, J.K.; Maher, C.; Nikpour, A.; Kavehei, O. A multimodal AI system for out-of-distribution generalization of seizure detection. bioRxiv 2021. [Google Scholar] [CrossRef]
- Knott, V.; Mahoney, C.; Kennedy, S.; Evans, K. EEG power, frequency, asymmetry and coherence in male depression. Psychiatry Res. Neuroimaging 2001, 106, 123–140. [Google Scholar] [CrossRef]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Wu, S.; Amari, S.-I. Conformal Transformation of Kernel Functions: A Data-Dependent Way to Improve Support Vector Machine Classifiers. Neural Process. Lett. 2002, 15, 59–67. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Wu, C.-T.; Cheng, W.-T.; Hsiao, Y.-T.; Chen, P.-M.; Teng, J.-T. Emotion Recognition from Single-Trial EEG Based on Kernel Fisher’s Emotion Pattern and Imbalanced Quasiconformal Kernel Support Vector Machine. Sensors 2014, 14, 13361–13388. [Google Scholar] [CrossRef] [Green Version]
- Mumtaz, W.; Xia, L.; Yasin, M.A.M.; Ali, S.S.A.; Malik, A.S. A wavelet-based technique to predict treatment outcome for Major Depressive Disorder. PLoS ONE 2017, 12, e0171409. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Data Preparation for Machine Learning: Data Cleaning, Feature Selection, and Data Transforms in Python; Machine Learning Mastery: Melbourne, VIC, Australia, 2020. [Google Scholar]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef]
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; DSM-5; American Psychiatric Publishing: Washington, DC, USA, 2013. [Google Scholar]
- Lecrubier, Y.; Sheehan, D.V.; Weiller, E.; Amorim, P.; Bonora, I.; Sheehan, K.H.; Janavs, J.; Dunbar, G. The Mini International Neuropsychiatric Interview (MINI). A short diagnostic structured interview: Reliability and validity according to the CIDI. Eur. Psychiatry 1997, 12, 224–231. [Google Scholar] [CrossRef]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B. The PHQ-9: Validity of a brief depression severity measure. J. Gen. Intern Med. 2001, 16, 606–613. [Google Scholar] [CrossRef]
- Beck, A.T.; Steer, R.A.; Brown, G.K. Manual for the Beck Depression Inventory-II; Psychological Corporation: San Antonio, TX, USA, 1996. [Google Scholar]
- Zigmond, A.S.; Snaith, R.P. The hospital anxiety and depression scale. Acta Psychiatr. Scand. 1983, 67, 361–370. [Google Scholar] [CrossRef] [Green Version]
- Belmaker, R.H.; Agam, G. Major Depressive Disorder. N. Engl. J. Med. 2008, 358, 55–68. [Google Scholar] [CrossRef] [Green Version]
- Ablin, P.; Cardoso, J.; Gramfort, A. Faster ICA under orthogonal constraint. Faster ICA under orthogonal constraint. In Proceedings of the International Conference on Acoustics, Speech & Signal Processing, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Stapleton, P.; Dispenza, J.; McGill, S.; Sabot, D.; Peach, M.; Raynor, D. Large effects of brief meditation intervention on EEG spectra in meditation novices. IBRO Rep. 2020, 9, 290–301. [Google Scholar] [CrossRef] [PubMed]
- Benoit, O.; Daurat, A.; Prado, J. Slow (0.7–2 Hz) and fast (2–4 Hz) delta components are differently correlated to theta, alpha and beta frequency bands during NREM sleep. Clin. Neurophysiol. 2000, 111, 2103–2106. [Google Scholar] [CrossRef]
- Esteller, R.; Vachtsevanos, G.; Echauz, J.; Litt, B. A comparison of waveform fractal dimension algorithms. IEEE Trans. Circuits Syst. I Regul. Pap. 2001, 48, 177–183. [Google Scholar] [CrossRef] [Green Version]
- Higuchi, T. Approach to an irregular time series on the basis of the fractal theory. Phys. D Nonlinear Phenom. 1988, 31, 277–283. [Google Scholar] [CrossRef]
- Phothisonothai, M.; Nakagawa, M. Fractal-Based EEG Data Analysis of Body Parts Movement Imagery Tasks. J. Physiol. Sci. 2007, 57, 217–226. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.-H.; Huang, S.; Huang, Y.-D. Motor Imagery EEG Classification for Patients with Amyotrophic Lateral Sclerosis Using Fractal Dimension and Fisher’s Criterion-Based Channel Selection. Sensors 2017, 17, 1557. [Google Scholar] [CrossRef] [Green Version]
- Katz, M.J. Fractals and the analysis of waveforms. Comput. Biol. Med. 1988, 18, 145–156. [Google Scholar] [CrossRef]
- Liu, Y.H.; Liu, Y.C.; Chen, Y.J. Fast support vector data descriptions for novelty detection. IEEE Trans. Neural Netw. 2010, 21, 1296–1313. [Google Scholar]
- Fang, L.; Zhao, H.; Wang, P.; Yu, M.; Yan, J.; Cheng, W.; Chen, P. Feature selection method based on mutual information and class separability for dimension reduction in multidimensional time series for clinical data. Biomed. Signal Process. Control 2015, 21, 82–89. [Google Scholar] [CrossRef] [Green Version]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Conference on Information and Communication Technology, Electronics and Microelectronics, Opatija, Croatia, 25–29 May 2015. [Google Scholar]
- Debener, S.; Beauducel, A.; Nessler, D.; Brocke, B.; Heilemann, H.; Kayser, J. Is resting anterior EEG alpha asymmetry a trait marker for depression? Findings for healthy adults and clinically depressed patients. Neuropsychobiology 2000, 41, 31–37. [Google Scholar] [CrossRef] [Green Version]
- Roh, S.-C.; Kim, J.S.; Kim, S.; Kim, Y.; Lee, S.-H. Frontal Alpha Asymmetry Moderated by Suicidal Ideation in Patients with Major Depressive Disorder: A Comparison with Healthy Individuals. Clin. Psychopharmacol. Neurosci. 2020, 18, 58–66. [Google Scholar] [CrossRef] [Green Version]
- van der Vinne, N.; Vollebregt, M.; van Putten, M.; Arns, M. Frontal alpha asymmetry as a diagnostic marker in depression: Fact or fiction? A meta-analysis. NeuroImage Clin. 2017, 16, 79–87. [Google Scholar] [CrossRef]
- Smith, E.E.; Cavanagh, J.F.; Allen, J.J.B. Intracranial source activity (eLORETA) related to scalp-level asymmetry scores and depression status. Psychophysiology 2018, 55, e13019. [Google Scholar] [CrossRef] [Green Version]
- Bachmann, M.; Lass, J.; Suhhova, A.; Hinrikus, H. Spectral asymmetry and Higuchi’s fractal dimension measures of depres-sion electroencephalogram. Comput. Math. Methods Med. 2013, 2013, 251638. [Google Scholar] [CrossRef] [Green Version]
- Čukić, M.; Pokrajac, D.; Stokić, M.; Simić, S.; Radivojević, V.; Ljubisavljević, M. EEG machine learning with Higuchi fractal dimension and sample entropy as features for successful detection of depression. arXiv 2018, arXiv:1803.05985. [Google Scholar]
- Čukić, M.; Stokić, M.; Radenković, S.; Ljubisavljevic, M.; Simić, S.; Savić, D. Nonlinear analysis of EEG complexity in episode and remission phase of recurrent depression. Int. J. Methods Psychiatr. Res. 2019, 29, e1816. [Google Scholar] [CrossRef] [Green Version]
- Chella, F.; Pizzella, V.; Zappasodi, F.; Marzetti, L. Impact of the reference choice on scalp EEG connectivity estimation. J. Neural Eng. 2016, 13, 036016. [Google Scholar] [CrossRef]
- Fries, P. A mechanism for cognitive dynamics: Neuronal communication through neuronal coherence. Trends Cogn. Sci. 2005, 9, 474–480. [Google Scholar] [CrossRef]
- Nunez, P.L. Electric Fields of the Brain: The Neurophysics of EEG; Oxford University Press: New York, NY, USA, 2006. [Google Scholar]
- La Rocca, D.; Campisi, P.; Vegso, B.; Cserti, P.; Kozmann, G.; Babiloni, F.; Fallani, F.D.V. Human Brain Distinctiveness Based on EEG Spectral Coherence Connectivity. IEEE Trans. Biomed. Eng. 2014, 61, 2406–2412. [Google Scholar] [CrossRef] [Green Version]
- Sheline, Y.I.; Price, J.L.; Yan, Z.; Mintun, M.A. Resting-state functional MRI in depression unmasks increased connectivity between networks via the dorsal nexus. Proc. Natl. Acad. Sci. USA 2010, 107, 11020–11025. [Google Scholar] [CrossRef] [Green Version]
- Tas, C.; Cebi, M.; Tan, O.; Hızlı-Sayar, G.; Tarhan, N.; Brown, E. EEG power, cordance and coherence differences between unipolar and bipolar depression. J. Affect. Disord. 2015, 172, 184–190. [Google Scholar] [CrossRef] [PubMed]
- Connolly, C.; Wu, J.; Ho, T.C.; Hoeft, F.; Wolkowitz, O.; Eisendrath, S.; Frank, G.; Hendren, R.; Max, J.E.; Paulus, M.; et al. Resting-State Functional Connectivity of Subgenual Anterior Cingulate Cortex in Depressed Adolescents. Biol. Psychiatry 2013, 74, 898–907. [Google Scholar] [CrossRef] [Green Version]
- Alalade, E.; Denny, K.; Potter, G.; Steffens, D.; Wang, L. Altered cerebellar-cerebral functional connectivity in geriatric depression. PLoS ONE 2011, 6, e20035. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | MDD, n = 200 | HC, n = 200 | p-Values | Effect Size |
|---|---|---|---|---|
| Gender | 142 F, 58 M | 142 F, 58 M | 1.000 | 0 |
| Age | 53.44 (±16.44) | 51.24 (±17.85) | 0.1969 | 0.1293 |
| BDI-II | 25.79 (±14.30) | 4.18 (±6.74) | 5.60 × 10−59 | 1.9282 |
| PHQ-9 | 12.64 (±7.30) | 2.09 (±3.73) | 4.51 × 10−54 | 1.8150 |
| HADS-A | 10.46 (±4.91) | 3.53 (±3.37) | 1.18 × 10−46 | 1.6425 |
| HADS-D | 10.29 (±5.19) | 2.50 (±2.85) | 7.91 × 10−56 | 1.8556 |
| Variable | MDD (n = 140) | HC (n = 140) | p-Values | Effect Size |
|---|---|---|---|---|
| Gender | 100 F, 40 M | 97 F, 43 M | 0.7935 | 0.0474 |
| Age | 53.06 (±16.31) | 50.83 (±17.64) | 0.2734 | 0.1312 |
| BDI-II | 25.82 (±14.23) | 3.69 (±5.98) | 1.43 × 10−44 | 2.0201 |
| PHQ-9 | 12.85 (±7.31) | 2.00 (±3.52) | 1.77 × 10−40 | 1.8855 |
| HADS-A | 10.52 (±4.97) | 3.19 (±3.05) | 4.85 × 10−37 | 1.7720 |
| HADS-D | 10.29 (±5.24) | 2.32 (±2.71) | 4.63 × 10−41 | 1.9046 |
| Variable | MDD (n = 60) | HC (n = 60) | p-Values | Effect Size |
|---|---|---|---|---|
| Gender | 42 F, 18 M | 45 F, 15 M | 0.6826 | 0.1091 |
| Age | 54.32 (±16.70) | 52.18 (±17.40) | 0.4983 | 0.1240 |
| BDI-II | 25.70 (±14.46) | 5.30 (±8.41) | 4.22 × 10−16 | 1.7237 |
| PHQ-9 | 12.13 (±7.25) | 2.30 (±4.18) | 4.05 × 10−15 | 1.6475 |
| HADS-A | 10.32 (±4.76) | 4.32 (±3.91) | 1.42 × 10−11 | 1.3662 |
| HADS-D | 10.27 (±5.08) | 2.90 (±3.12) | 3.16 × 10−16 | 1.7334 |
| EEG Features | Frontal | Central | Temporal | Parietal | ALL | |
|---|---|---|---|---|---|---|
| BP | δ | 49.53 ± 6.80 (55.82 ± 3.19) | 56.35 ± 4.24 (60.77 ± 4.71) | 53.86 ± 3.50 (61.19 ± 5.49) | 51.80 ± 3.81 (58.09 ± 5.30) | 48.80 ± 6.76 (63.07 ± 3.11) |
| θ | 49.63 ± 11.93 (58.91 ± 4.74) | 51.24 ± 6.88 (55.26 ± 2.08) | 52.62 ± 7.25 (57.25 ± 5.37) | 45.83 ± 4.57 (55.44 ± 4.97) | 52.58 ± 8.61 (59.82 ± 9.68) | |
| α | 47.06 ± 7.21 (56.28 ± 3.85) | 51.67 ± 7.20 (54.01 ± 1.82) | 44.49 ± 7.36 (49.16 ± 2.90) | 46.16 ± 6.84 (54.93 ± 3.19) | 42.09 ± 9.95 (57.65 ± 4.32) | |
| β | 52.53 ± 5.36 (58.61 ± 5.71) | 55.00 ± 7.35 (55.42 ± 3.64) | 53.87 ± 6.51 (56.29 ± 3.11) | 50.76 ± 7.64 (53.96 ± 2.62) | 51.74 ± 9.00 (64.21 ± 4.43) | |
| γ | 48.28 ± 7.21 (54.63 ± 4.43) | 55.51 ± 2.19 (56.88 ± 4.13) | 46.62 ± 8.46 (51.61 ± 3.64) | 43.94 ± 6.00 (53.13 ± 5.46) | 44.15 ± 11.66 (60.29 ± 3.81) | |
| COH | δ | 53.44 ± 8.04 (61.94 ± 2.53) | 54.38 ± 5.86 (59.88 ± 9.68) | 46.70 ± 5.95 (59.08 ± 4.32) | 52.85 ± 3.23 (62.83 ± 3.57) | 52.49 ± 4.85 (81.27 ± 3.64) |
| θ | 56.30 ± 7.58 (64.24 ± 6.83) | 58.64 ± 7.65 (61.49 ± 5.30) | 51.86 ± 5.64 (61.53 ± 5.60) | 52.47 ± 10.46 (63.58 ± 4.43) | 49.16 ± 9.78 (75.36 ± 3.46) | |
| α | 52.67 ± 8.48 (66.11 ± 6.43) | 56.08 ± 4.45 (62.44 ± 3.11) | 56.36 ± 8.28 (65.28 ± 2.62) | 52.34 ± 13.05 (63.25 ± 6.64) | 51.32 ± 6.17 (79.06 ± 6.25) | |
| β | 55.43 ± 6.91 (66.28 ± 4.60) | 58.68 ± 2.92 (62.97 ± 5.30) | 55.78 ± 7.18 (64.49 ± 1.96) | 53.15 ± 6.28 (64.17 ± 6.53) | 53.37 ± 7.41 (85.65 ± 10.68) | |
| γ | 50.05 ± 6.86 (62.17 ± 6.74) | 58.60 ± 8.13 (63.82 ± 4.29) | 46.13 ± 5.57 (63.26 ± 8.07) | 55.66 ± 5.33 (59.42 ± 4.43) | 49.70 ± 5.41 (78.11 ± 4.71) | |
| HFD | kmax = 50 | 51.28 ± 6.06 (59.01 ± 8.10) | 57.38 ± 3.30 (59.47 ± 4.07) | 52.23 ± 7.21 (60.09 ± 5.82) | 48.52 ± 6.25 (55.50 ± 4.97) | 50.25 ± 6.29 (62.08 ± 5.91) |
| kmax = 100 | 52.93 ± 6.93 (59.46 ± 6.02) | 59.42 ± 3.90 (60.10 ± 2.42) | 55.31 ± 5.98 (60.17 ± 4.92) | 51.47 ± 3.54 (57.35 ± 4.92) | 54.33 ± 4.38 (63.81 ± 6.39) | |
| kmax = 150 | 52.93 ± 6.93 (59.24 ± 4.60) | 58.93 ± 3.86 (60.66 ± 3.75) | 54.14 ± 8.45 (60.21 ± 3.64) | 50.56 ± 5.60 (58.04 ± 5.71) | 54.04 ± 4.73 (64.96 ± 6.04) | |
| KFD | 44.60 ± 8.37 (58.36 ± 4.60) | 41.05 ± 10.18 (63.01 ± 2.90) | 35.65 ± 9.99 (58.23 ± 5.58) | 50.75 ± 10.15 (54.41 ± 6.87) | 46.38 ± 8.46 (61.89 ± 4.87) | |
| K-NN | LDA | SVM | |
|---|---|---|---|
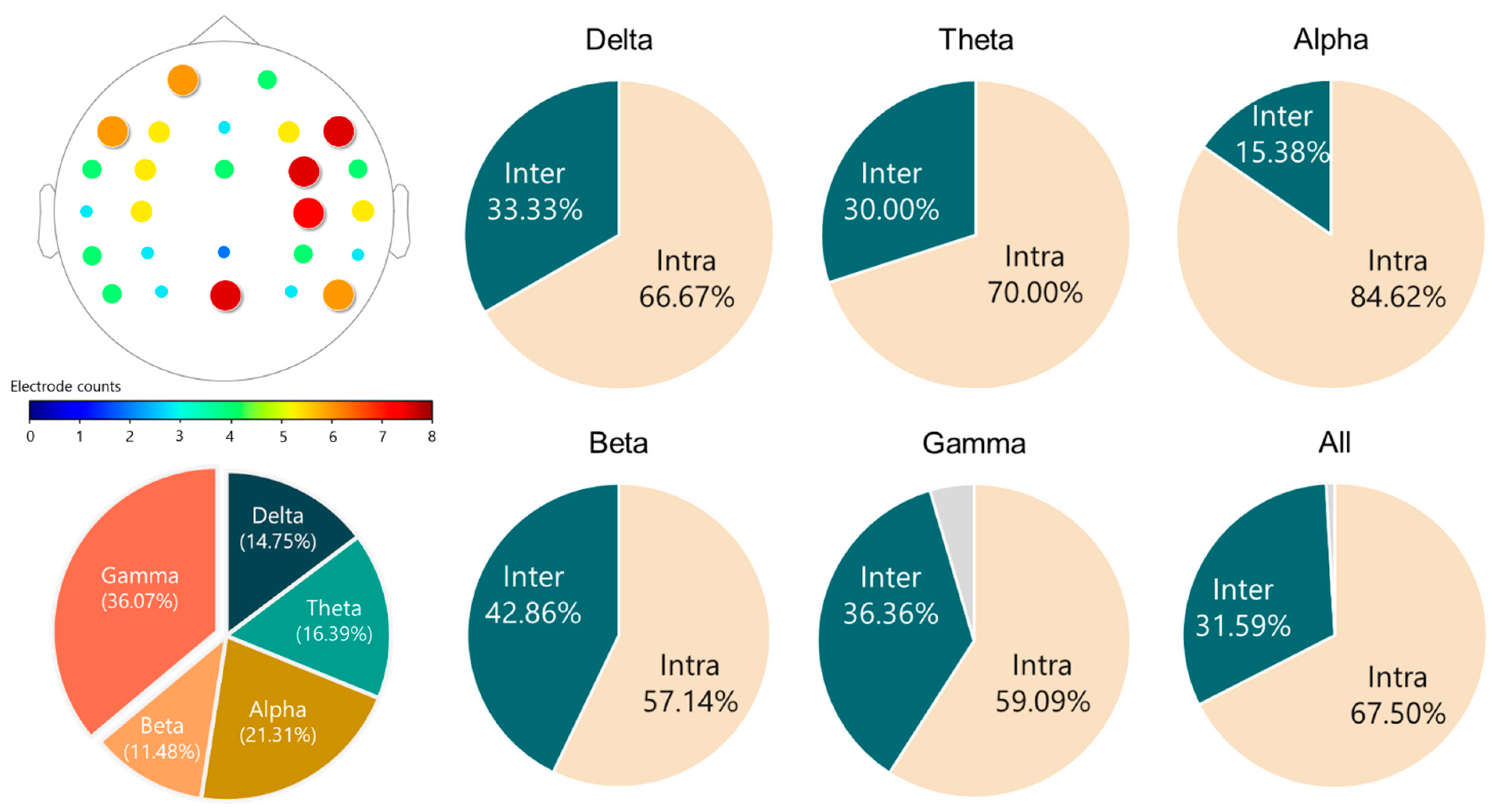
| BP | 3.03% (1) | 4.76% (3) | 1.61% (1) |
| COH | 96.97% (32) | 95.24% (60) | 98.39% (61) |
| HFD | 0 (0) | 0 (0) | 0 (0) |
| KFD | 0 (0) | 0 (0) | 0 (0) |
| Classifier (Number of Features) | Training Set | Test Set | ||
|---|---|---|---|---|
| 5-Fold CV Accuracy | (Accuracy | Sensitivity | Specificity) | |
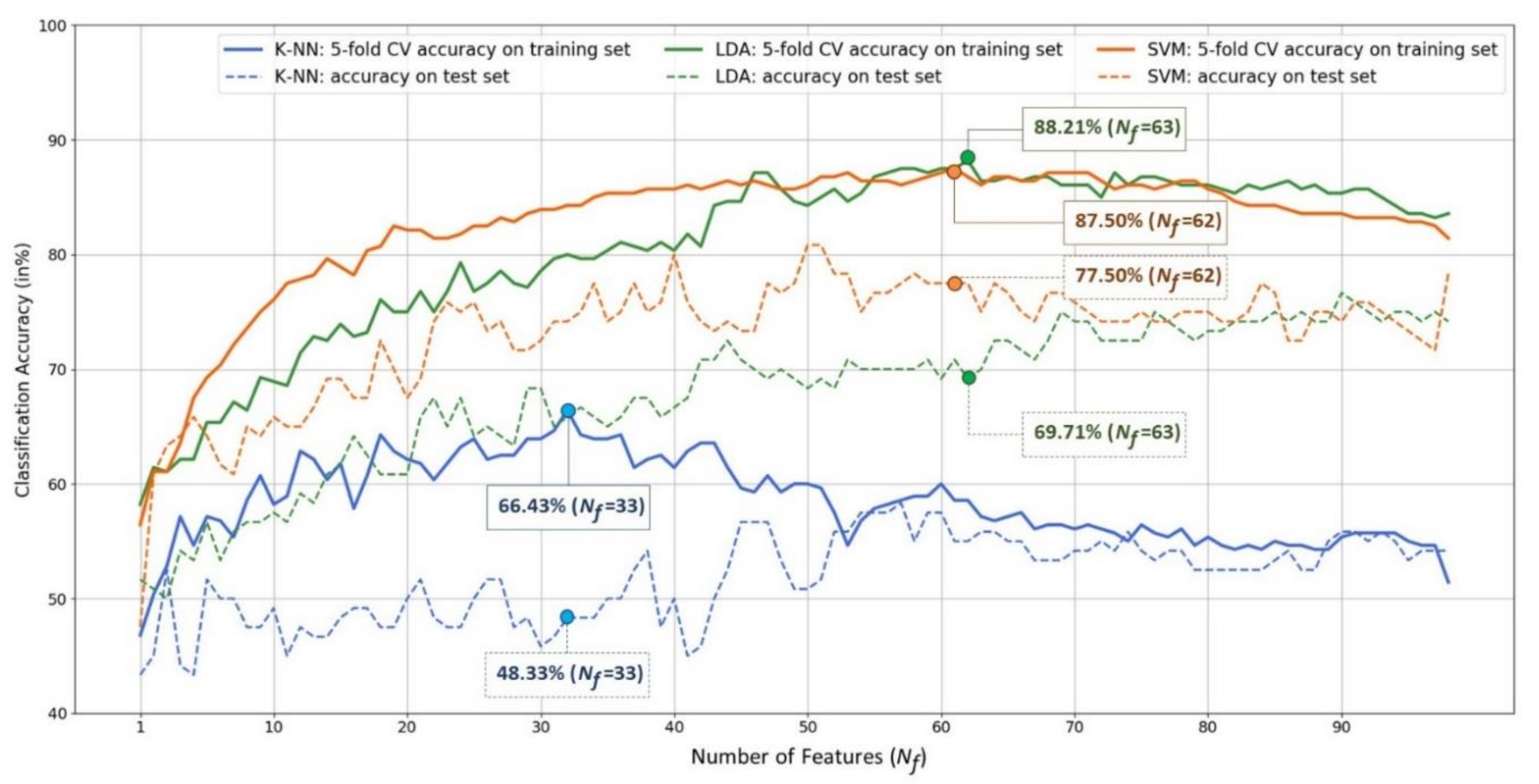
| K-NN () | 66.43 ± 7.79 | 48.33 | 48.33 | 48.33 |
| LDA () | 88.21 ± 5.60 | 69.17 | 75.00 | 63.33 |
| SVM () | 86.07 ± 4.71 | 80.83 | 86.67 | 75.00 |
| SVM () | 87.50 ± 4.92 | 77.50 | 85.00 | 70.00 |
| CK-SVM () | 91.07 ± 3.43 | 84.16 | 88.33 | 80.00 |
| CK-SVM () | 89.28 ± 3.29 | 80.83 | 88.33 | 73.33 |
| EEG Features | Frontal | Central | Temporal | Parietal | ALL | |
|---|---|---|---|---|---|---|
| Normalized BP | δ | 52.14 (56.43) | 57.14 (58.57) | 53.35 (58.21) | 42.86 (51.43) | 50.00 (63.57) |
| θ | 53.93 (58.21) | 52.86 (54.64) | 57.14 (58.21) | 43.93 (54.64) | 54.29 (60.36) | |
| α | 51.43 (58.57) | 51.43 (52.86) | 46.43 (53.93) | 46.43 (53.93) | 49.29 (57.50) | |
| β | 54.29 (56.07) | 56.43 (57.86) | 56.07 (57.86) | 51.43 (55.00) | 52.50 (62.86) | |
| γ | 54.29 (58.21) | 59.29 (59.29) | 50.00 (56.43) | 46.79 (55.00) | 48.21 (63.21) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.-T.; Huang, H.-C.; Huang, S.; Chen, I.-M.; Liao, S.-C.; Chen, C.-K.; Lin, C.; Lee, S.-H.; Chen, M.-H.; Tsai, C.-F.; et al. Resting-State EEG Signal for Major Depressive Disorder Detection: A Systematic Validation on a Large and Diverse Dataset. Biosensors 2021, 11, 499. https://doi.org/10.3390/bios11120499
Wu C-T, Huang H-C, Huang S, Chen I-M, Liao S-C, Chen C-K, Lin C, Lee S-H, Chen M-H, Tsai C-F, et al. Resting-State EEG Signal for Major Depressive Disorder Detection: A Systematic Validation on a Large and Diverse Dataset. Biosensors. 2021; 11(12):499. https://doi.org/10.3390/bios11120499
Chicago/Turabian StyleWu, Chien-Te, Hao-Chuan Huang, Shiuan Huang, I-Ming Chen, Shih-Cheng Liao, Chih-Ken Chen, Chemin Lin, Shwu-Hua Lee, Mu-Hong Chen, Chia-Fen Tsai, and et al. 2021. "Resting-State EEG Signal for Major Depressive Disorder Detection: A Systematic Validation on a Large and Diverse Dataset" Biosensors 11, no. 12: 499. https://doi.org/10.3390/bios11120499
APA StyleWu, C. -T., Huang, H. -C., Huang, S., Chen, I. -M., Liao, S. -C., Chen, C. -K., Lin, C., Lee, S. -H., Chen, M. -H., Tsai, C. -F., Weng, C. -H., Ko, L. -W., Jung, T. -P., & Liu, Y. -H. (2021). Resting-State EEG Signal for Major Depressive Disorder Detection: A Systematic Validation on a Large and Diverse Dataset. Biosensors, 11(12), 499. https://doi.org/10.3390/bios11120499