
Development of an Improved YOLOv7-Based Model for Detecting Defects on Strip Steel Surfaces

 ,
,
Abstract
:1. Introduction
- An improved YOLOv7-based model for detecting defects on strip steel surfaces is proposed.
- To enhance the network’s ability to extract defects features and speed up network inference, the ConvNeXt module is introduced to the backbone network of the YOLOv7 model.
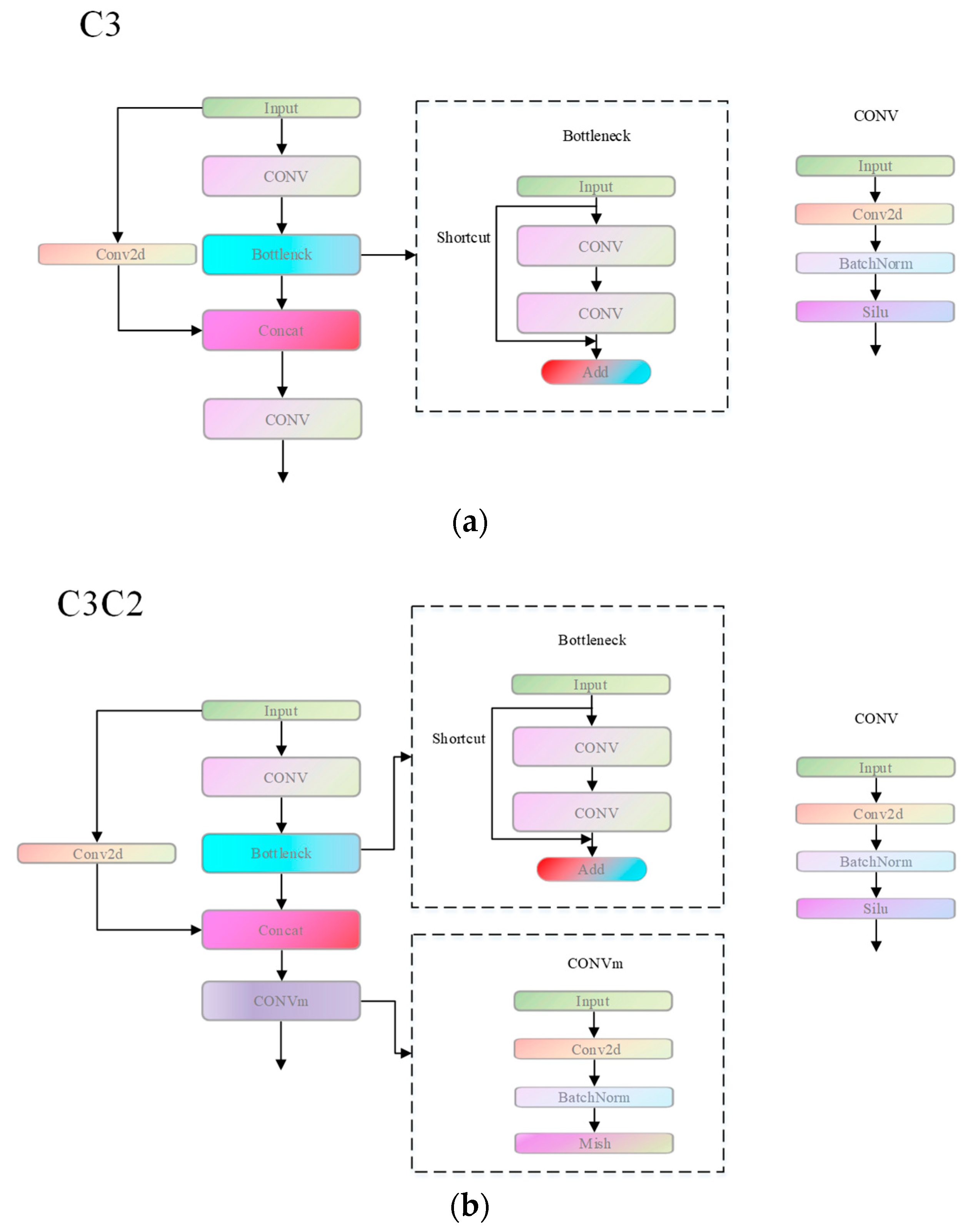
- To reduce the amount of operations and simplify the network structure, the Efficient Layer Aggregation Network (ELAN) module in the detection head of the YOLOv7 model is replaced by an improved C3 module (C3C2).
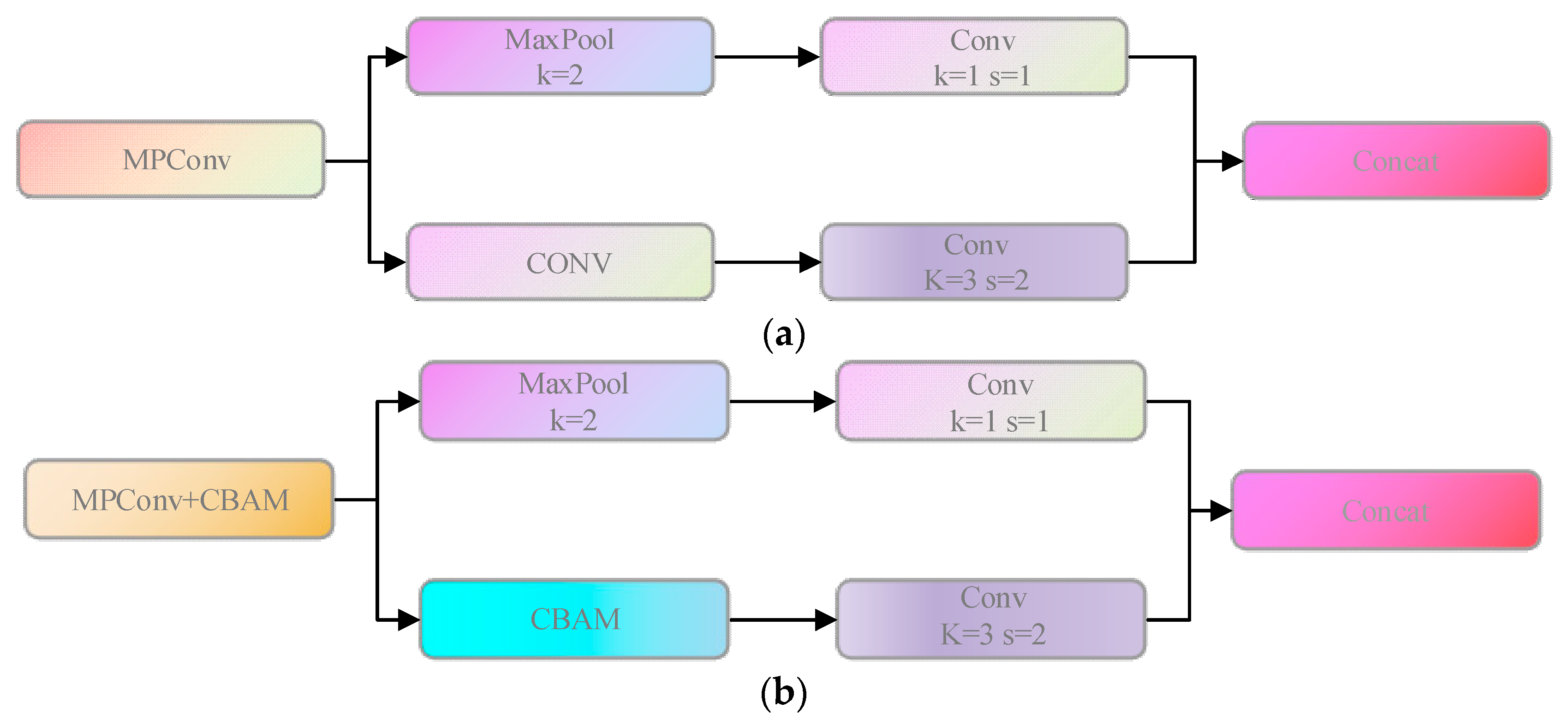
- By embedding the Convolutional Block Attention Module (CBAM) into the maximum pooling (MP) layer of the model detection head, an attention pooling structure is formed to enhance the ability to cope with complex and different strip steel surface defects.
2. Methodology
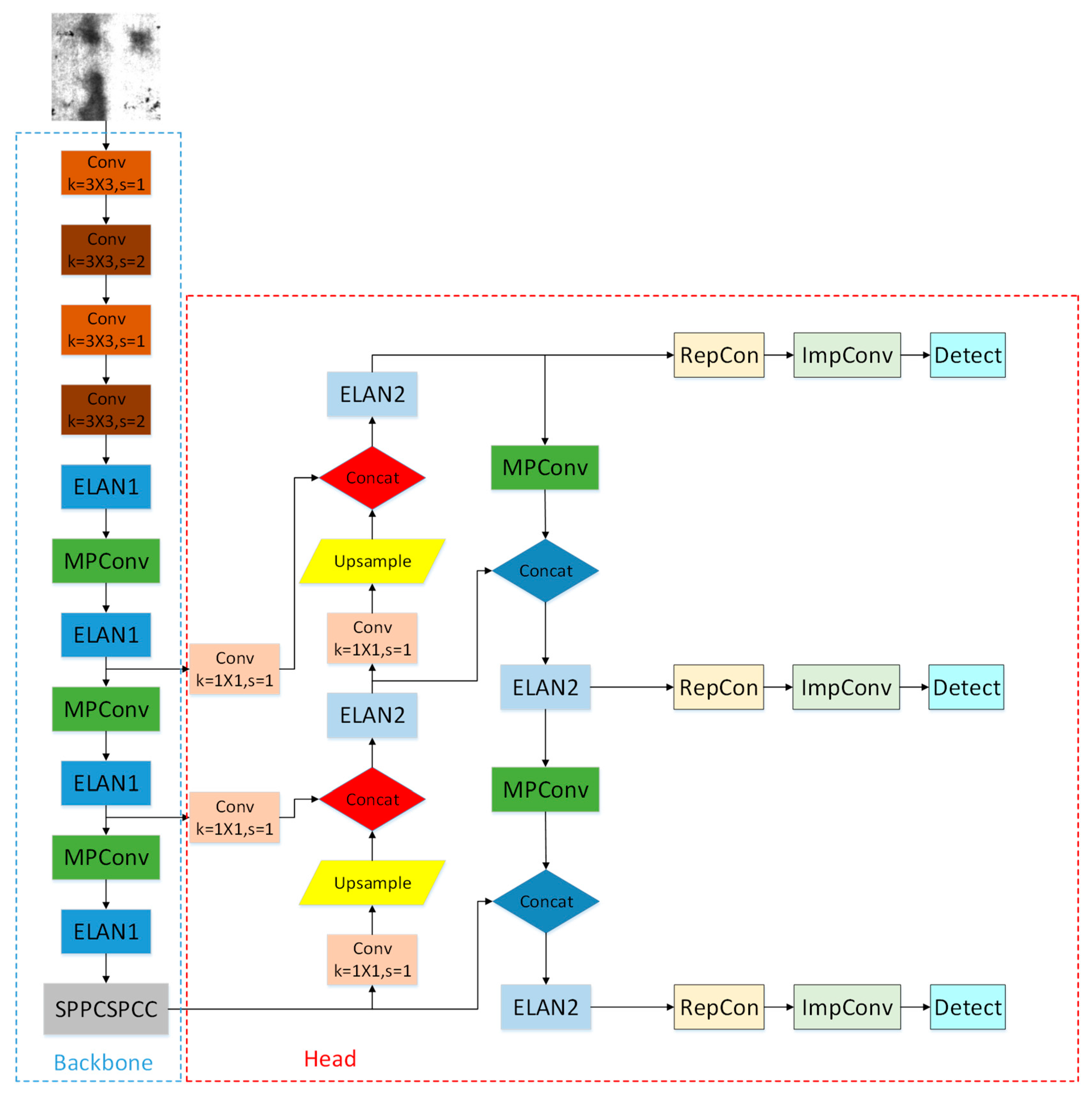
2.1. YOLOv7 Network Structure
- Using a camera with higher resolution to collect pictures of the strip steel with defects on the surface.
- Using the labelimg tools to process the defects that appear in the strip steel on these images, frame them accurately with a rectangular box and mark the category.
- Dividing the processed images into the training set, test set, and validation set according to a certain ratio; putting the training set and validation set into the model of YOLOv7 for training and validation; and using the test set to test the model training effect.
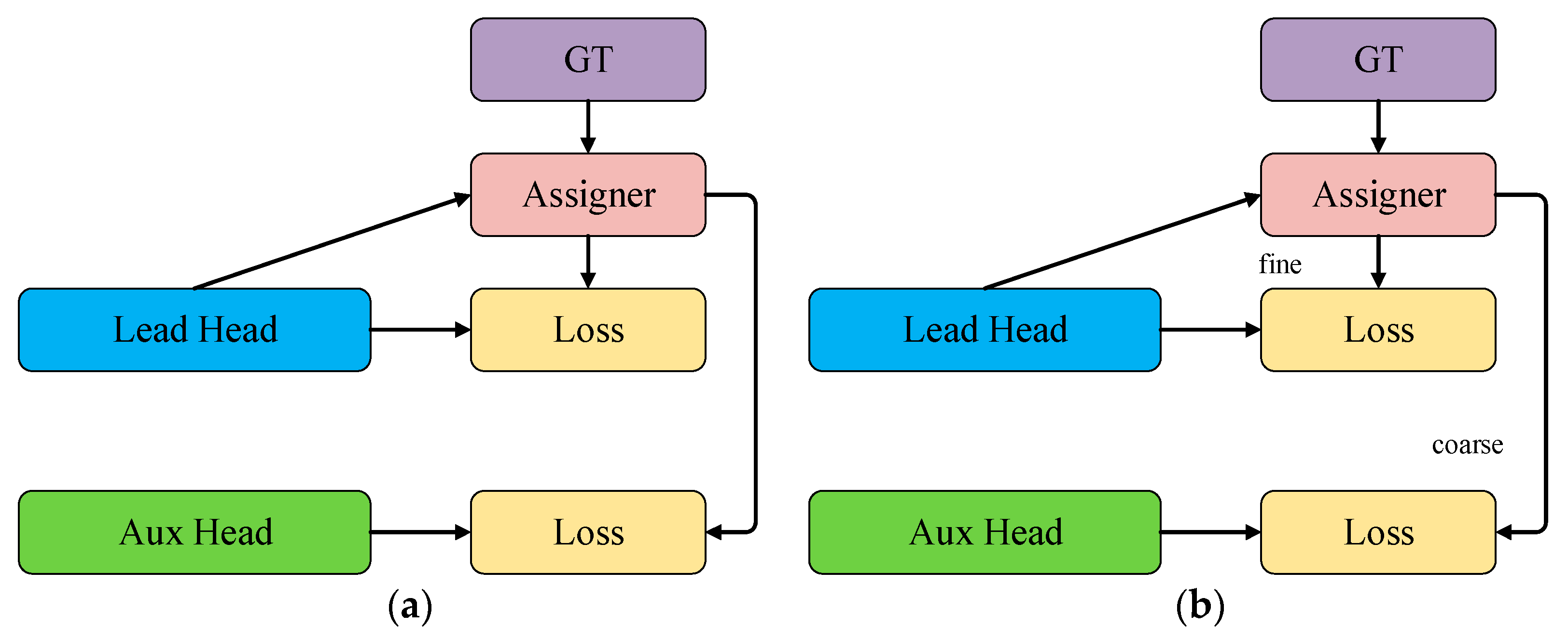
2.2. Loss Function and Label Assignment
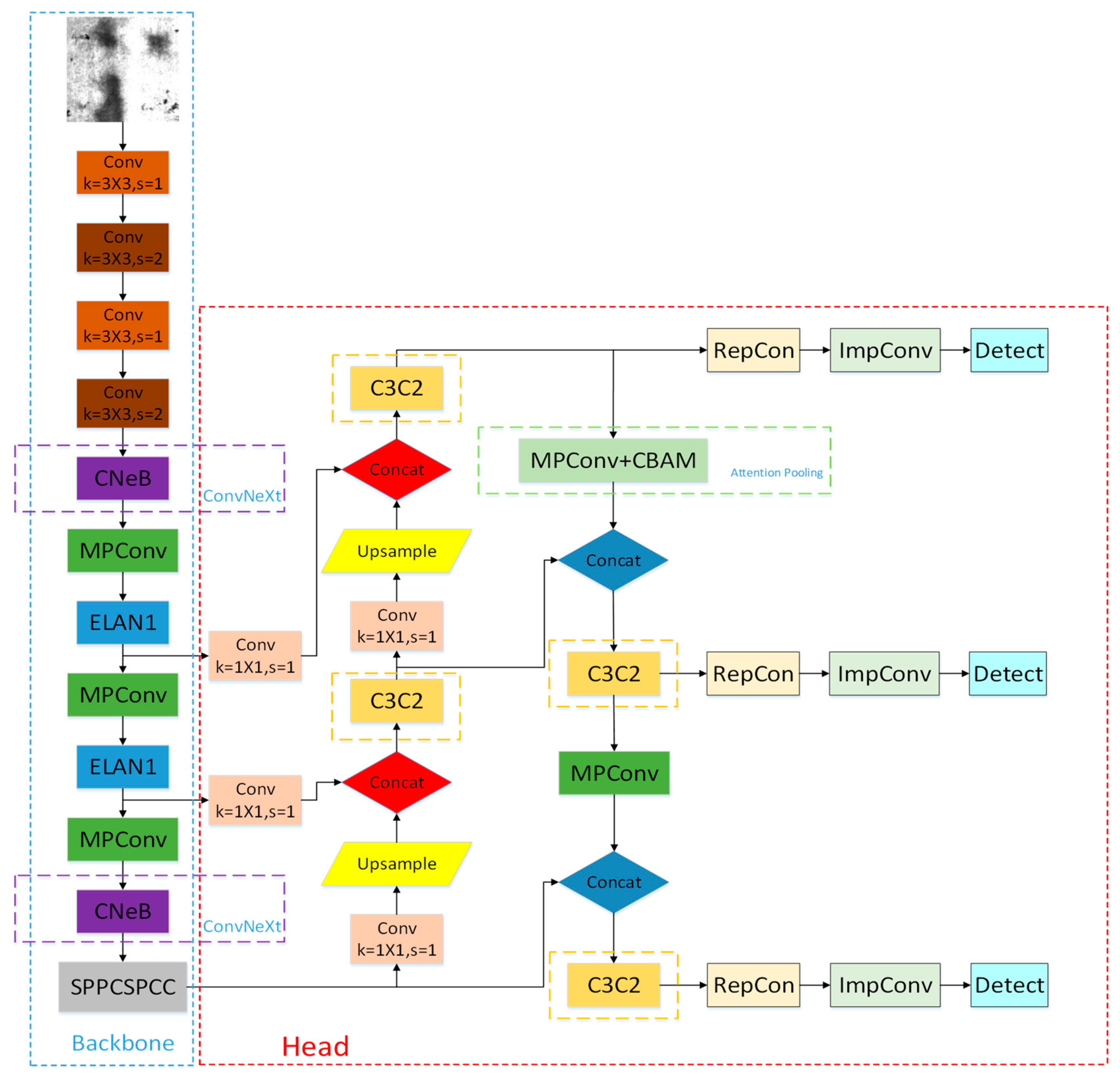
3. Improvement of YOLOv7
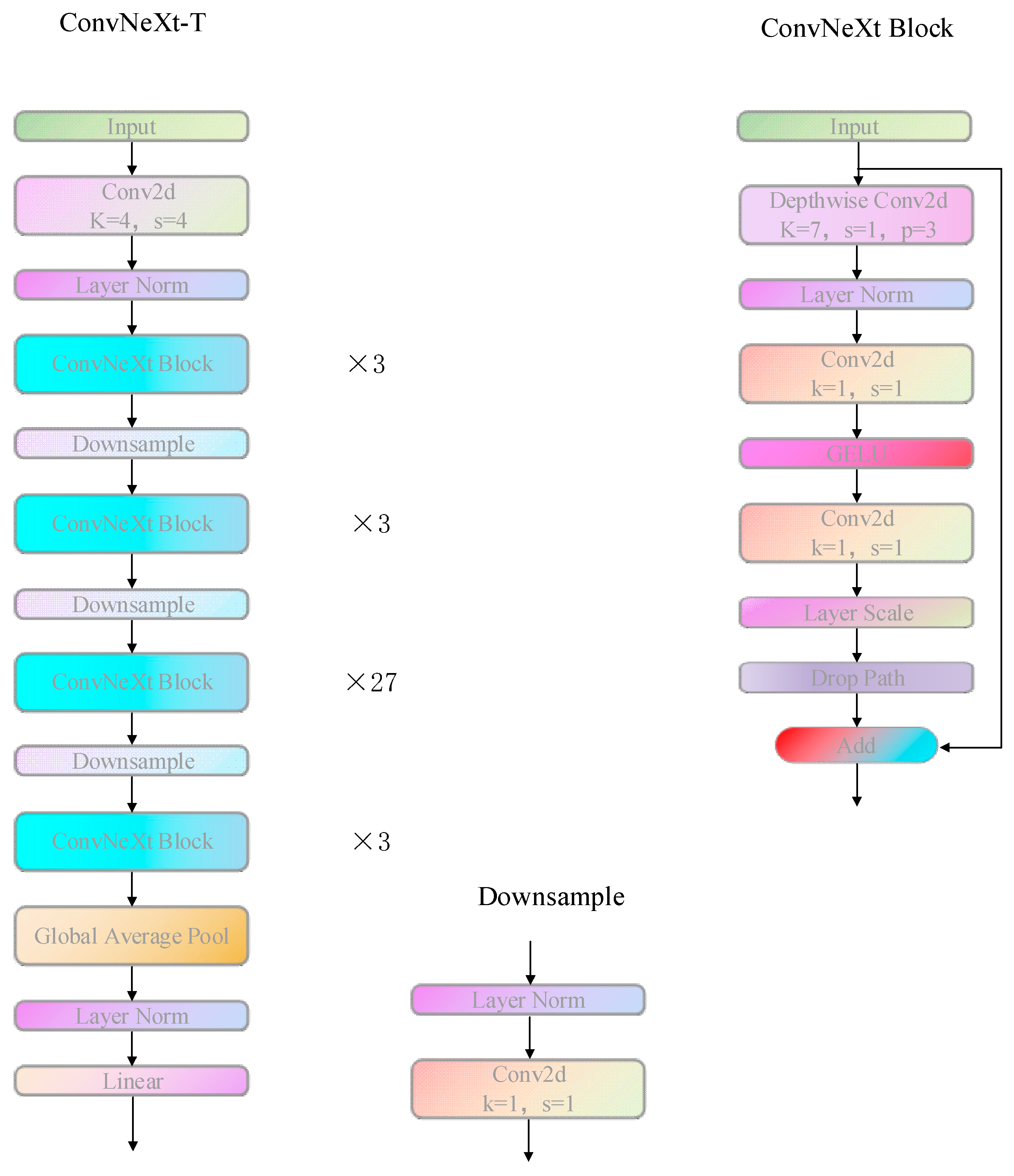
3.1. ConvNeXt Module
ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
3.2. Improvement of C3(C3C2)
3.3. Attention Pooling Module
4. Experiment and Result Analysis
4.1. Experimental Details and Dataset
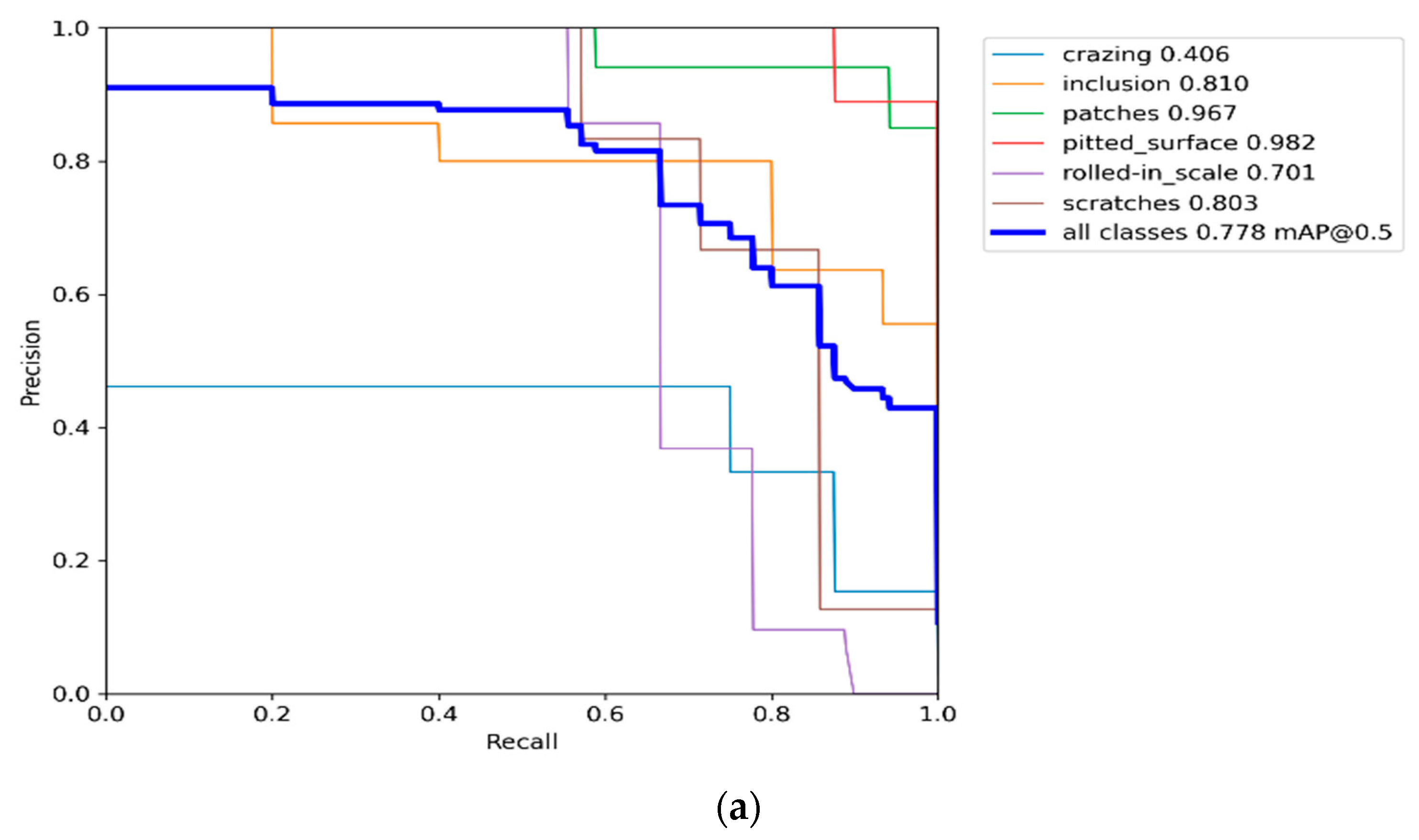
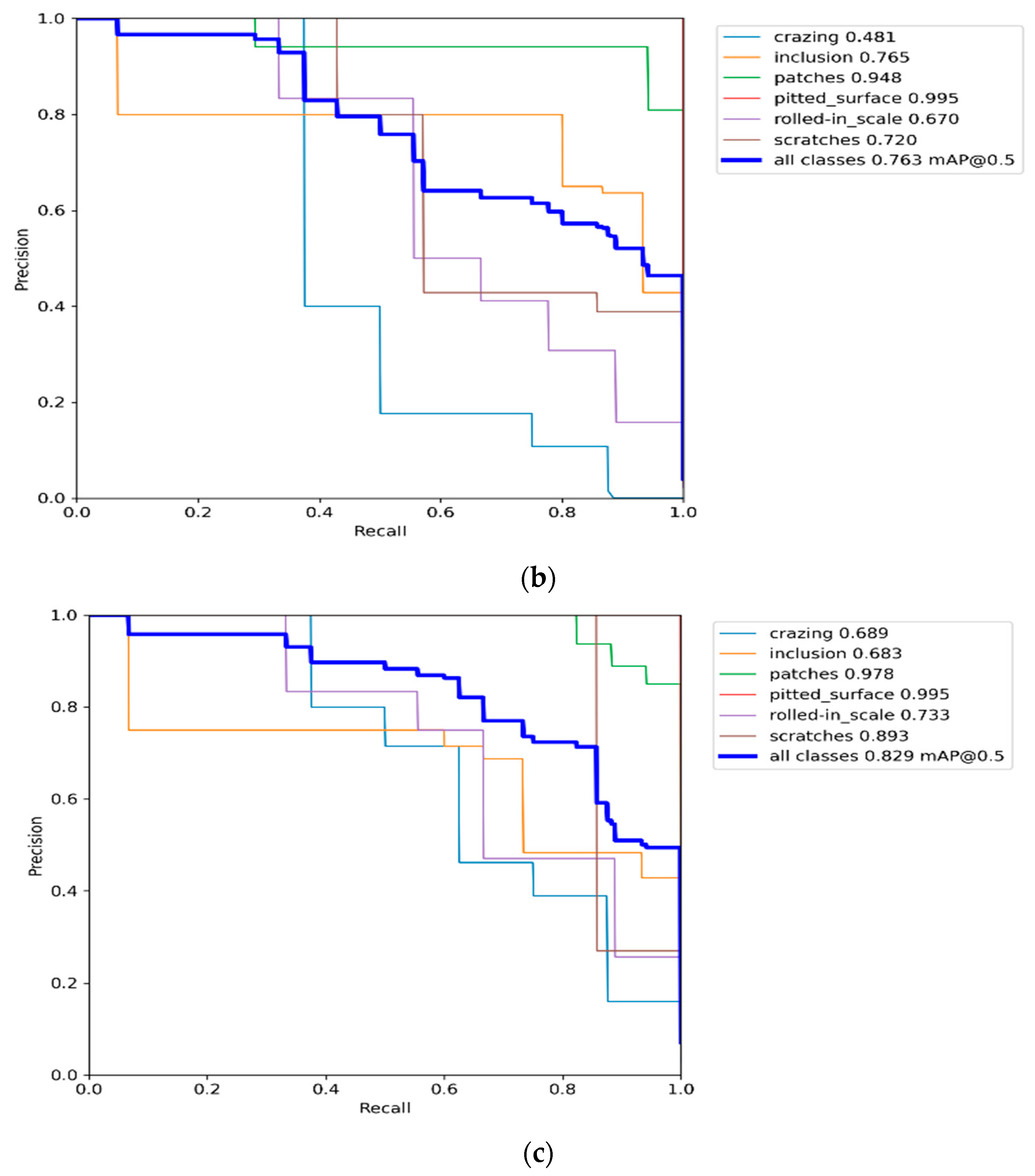
4.2. Performance Evaluation
4.3. Ablation Research
4.4. Contrasting Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kou, X.; Liu, S.; Cheng, K.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454-1–109454-9. [Google Scholar] [CrossRef]
- Mordia, R.; Verma, A.K. Visual techniques for defects detection in steel products: A comparative study. Eng. Fail. Anal. 2022, 134, 106047–106058. [Google Scholar] [CrossRef]
- Sun, B.; Cheng, L.; Du, C.-Y.; Zhang, J.-K.; He, Y.-Q.; Cao, G.-M. Effect of Oxide Scale Microstructure on Atmospheric Corrosion Behavior of Hot Rolled Steel Strip. Coatings 2021, 11, 517. [Google Scholar] [CrossRef]
- Shi, H.; Wang, J.; Li, Y. Small sample data enhancement method for strip steel based on improved ACGAN algorithm. Comput. Integr. Manuf. Syst. 2023, 1–12. Available online: https://kns.cnki.net/kcms/detail//11.5946.TP.20230104.1047.004.html (accessed on 12 April 2021).
- Hao, R.; Lu, B.; Cheng, Y.; Li, X.; Huang, B. A steel surface defect inspection approach towards smart industrial monitoring. J. Intell. Manuf. 2021, 32, 1833–1843. [Google Scholar] [CrossRef]
- Ma, Y.; Zhao, H.; Yan, C.; Feng, H.; Yu, K.; Liu, H. Strip steel surface defect detection method by improved YOLOv5 network. J. Electron. Meas. Instrum. 2022, 36, 150–157. [Google Scholar]
- Liang, X.; Xiao, H. Lightweight strip defect real-time detection algorithm based on SDD-YOLO. China Meas. Test. 2023, 1–8. Available online: https://kns.cnki.net/kcms/detail//51.1714.TB.20230109.1648.002.html (accessed on 12 April 2021).
- Wu, H.; Lv, Q.; Giovanni, D. Hot-Rolled Steel Strip Surface Inspection Based on Transfer Learning Model. J. Sens. 2021, 2021 Pt 3, 6637252-1–6637252-8. [Google Scholar] [CrossRef]
- Guan, S.; Chang, J.; Shi, H.; Xiao, X.; Li, Z.; Wang, X.; Wang, X. Strip Steel Defect Classification Using the Improved GAN and EfficientNet. Appl. Artif. Intell. 2021, 35, 1887–1904. [Google Scholar] [CrossRef]
- Chu, M.-X.; Liu, X.-P.; Gong, R.-F.; Zhao, J. Multi-class classification method for strip steel surface defects based on support vector machine with adjustable hyper-sphere. J. Iron Steel Res. Int. 2018, 25, 706–716. [Google Scholar] [CrossRef]
- Huang, X.; Sun, S.; Zhang, Y.; Li, B.; Ren, Y.; Zhao, L. Research on the detection method of surface defects of strip steel under uneven illumination. Mech. Sci. Technol. Aerosp. Eng. 2023, 1–8. [Google Scholar] [CrossRef]
- Tsai, D.-M.; Chen, M.-C.; Li, W.-C.; Chiu, W.-Y. A fast regularity measure for surface defect detection. Mach. Vis. Appl. 2012, 23, 869–886. [Google Scholar] [CrossRef]
- Liu, K.; Wang, H.; Chen, H.; Qu, E.; Tian, Y.; Sun, H. Steel Surface Defect Detection Using a New Haar-Weibull-Variance Model in Unsupervised Manner. IEEE Trans. Instrum. Meas. 2017, 66, 2585–2596. [Google Scholar] [CrossRef]
- Neogi, N.; Mohanta, D.K.; Dutta, P.K. Defect Detection of Steel Surfaces with Global Adaptive Percentile Thresholding of Gradient Image. J. Inst. Eng. Ser. B 2017, 98, 557–565. [Google Scholar] [CrossRef]
- Tong, L.; Wong, W.K.; Kwong, C.K. Differential evolution-based optimal Gabor filter model for fabric inspection. Neurocomputing 2016, 173, 1386–1401. [Google Scholar] [CrossRef]
- Choi, D.-C.; Jeon, Y.-J.; Kim, S.H.; Moon, S.; Yun, J.P.; Kim, S.W. Detection of Pinholes in Steel Slabs Using Gabor Filter Combination and Morphological Features. ISIJ Int. 2017, 57, 1045–1053. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Li, Q.; Gan, J.; Yu, H.; Yang, X. Surface Defect Detection via Entity Sparsity Pursuit with Intrinsic Priors. IEEE Trans. Ind. Inform. 2019, 16, 141–150. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ross, G. Fast R-CNN[A] in: Institute of Electrical and Electronics Engineers. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV 2015), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Joseph, R.; Santosh, D.; Ross, G.; Ali, F. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Joseph, R.; Ali, F. YOL09000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5 Release v5.0. 2021. Available online: https://github.com/ultralytics/yolov5/releases/tag/v5.0 (accessed on 12 April 2021).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2021, arXiv:2207.02696. [Google Scholar]
- Wang, S.; Xia, X.; Ye, L.; Yang, B. Automatic Detection and Classification of Steel Surface Defect Using Deep Convolutional Neural Networks. Met.-Open Access Metall. J. 2021, 11, 388. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Li, M.-J.; Wang, H.; Wan, Z.-B. Surface defect detection of steel strips based on improved YOLOv4. Comput. Electr. Eng. 2022, 102, 45–53. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. MSFT-YOLO: Improved YOLOv5 Based on Transformer for Detecting Defects of Steel Surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Lee, Y.; Hwang, J.-W.; Lee, S.; Bae, Y.; Park, J. An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2019), Long Beach, CA, USA, 16–17 June 2019; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2016; pp. 752–760. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual Conference, 19–25 June 2021; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2016; pp. 13024–13033. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2017, arXiv:1611.05431. [Google Scholar]
- Diganta, M. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| mAP% | AP% | ||||||
|---|---|---|---|---|---|---|---|
| Crazing | Inclusion | Patches | Pitted Surface | Rolled-In Scale | Scratches | ||
| YOLOv7 | 76.3 | 48.1 | 76.5 | 94.8 | 99.5 | 67.0 | 72.0 |
| YOLOv7–ConNeXt-B | 76.3 | 54.1 | 62.3 | 96.4 | 95.6 | 67.6 | 82.1 |
| YOLOv7–C3C2 | 75.5 | 35.9 | 76.8 | 99.1 | 93.1 | 71.5 | 76.5 |
| YOLOv7–CBAM | 79.4 | 63.6 | 66.7 | 97.7 | 99.5 | 65.5 | 83.6 |
| Ours | 82.9 | 68.9 | 68.3 | 97.8 | 99.5 | 73.3 | 89.3 |
| mAP% | AP% | ||||||
|---|---|---|---|---|---|---|---|
| Crazing | Inclusion | Patches | Pitted Surface | Rolled-In Scale | Scratches | ||
| YOLOv5 | 77.80 | 40.60 | 81.00 | 96.70 | 98.20 | 70.10 | 80.30 |
| YOLOv7 | 76.30 | 48.10 | 76.50 | 94.80 | 99.50 | 67.00 | 72.00 |
| YOLOX | 73.37 | 46.06 | 73.26 | 86.58 | 83.55 | 52.80 | 97.98 |
| SSD | 75.43 | 62.72 | 75.63 | 94.31 | 71.46 | 65.89 | 82.54 |
| RetinaNet | 67.56 | 45.65 | 68.34 | 89.99 | 81.52 | 58.60 | 61.27 |
| Ours | 82.90 | 68.90 | 68.30 | 97.80 | 99.50 | 73.30 | 89.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Liang, F.; Mou, X.; Chen, L.; Yu, X.; Peng, Z.; Chen, H. Development of an Improved YOLOv7-Based Model for Detecting Defects on Strip Steel Surfaces. Coatings 2023, 13, 536. https://doi.org/10.3390/coatings13030536
Wang R, Liang F, Mou X, Chen L, Yu X, Peng Z, Chen H. Development of an Improved YOLOv7-Based Model for Detecting Defects on Strip Steel Surfaces. Coatings. 2023; 13(3):536. https://doi.org/10.3390/coatings13030536
Chicago/Turabian StyleWang, Rijun, Fulong Liang, Xiangwei Mou, Lintao Chen, Xinye Yu, Zhujing Peng, and Hongyang Chen. 2023. "Development of an Improved YOLOv7-Based Model for Detecting Defects on Strip Steel Surfaces" Coatings 13, no. 3: 536. https://doi.org/10.3390/coatings13030536
APA StyleWang, R., Liang, F., Mou, X., Chen, L., Yu, X., Peng, Z., & Chen, H. (2023). Development of an Improved YOLOv7-Based Model for Detecting Defects on Strip Steel Surfaces. Coatings, 13(3), 536. https://doi.org/10.3390/coatings13030536