
Prediction of Temperature of Liquid Steel in Ladle Using Machine Learning Techniques



Abstract
:1. Introduction
2. FEM Solution of Fourier Equation
- The temperature of the inner surface of the ladle is equal to the temperature of the molten steel.
- The heat transfer inside liquid steel, insulation layer, and lining is carried out by conduction
- The heat transfer from the outer surface of the ladle and the slag layer occurs by convection (qc) and radiation (qr):
3. Statistical Data Analysis and Decision Trees
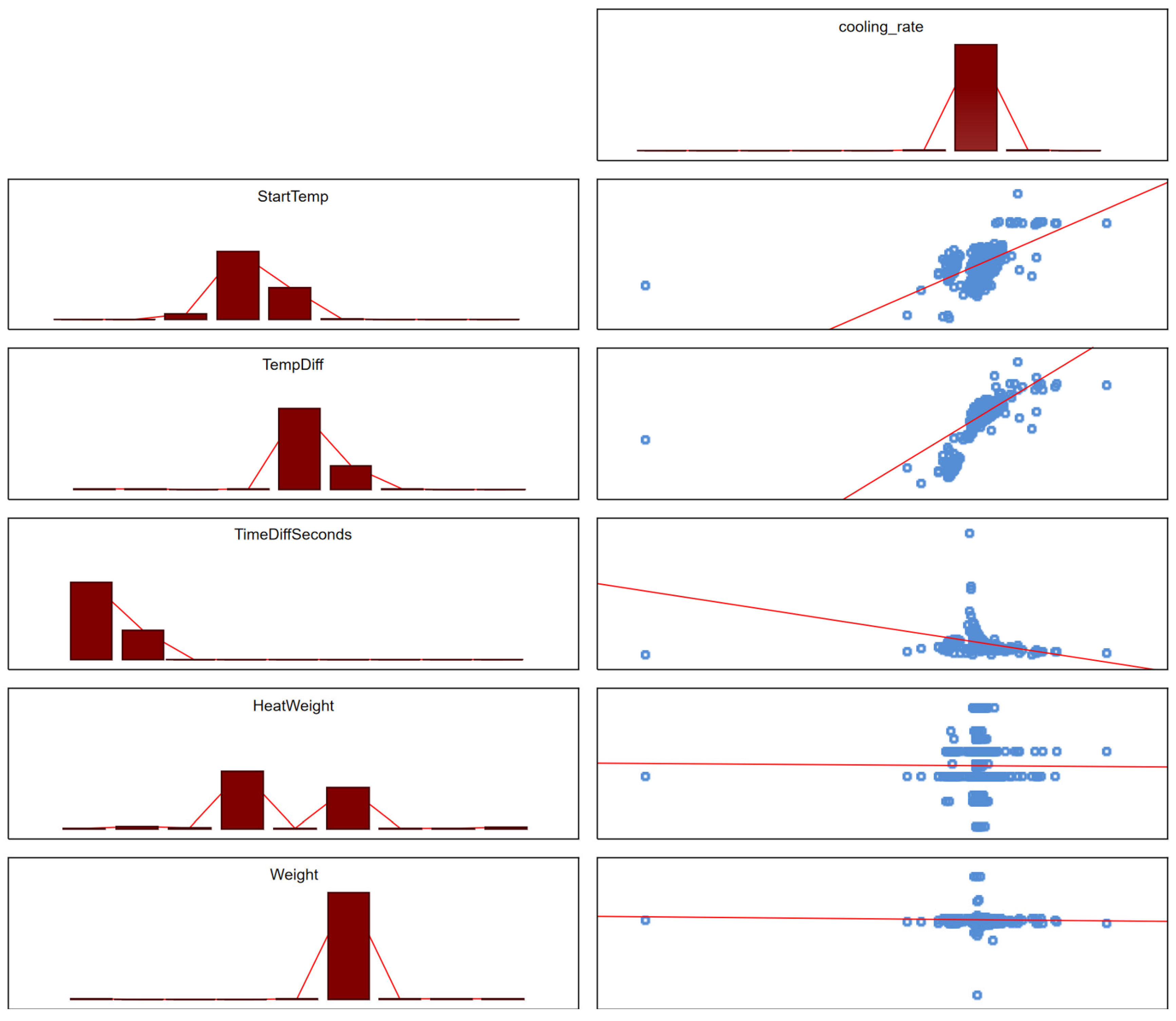
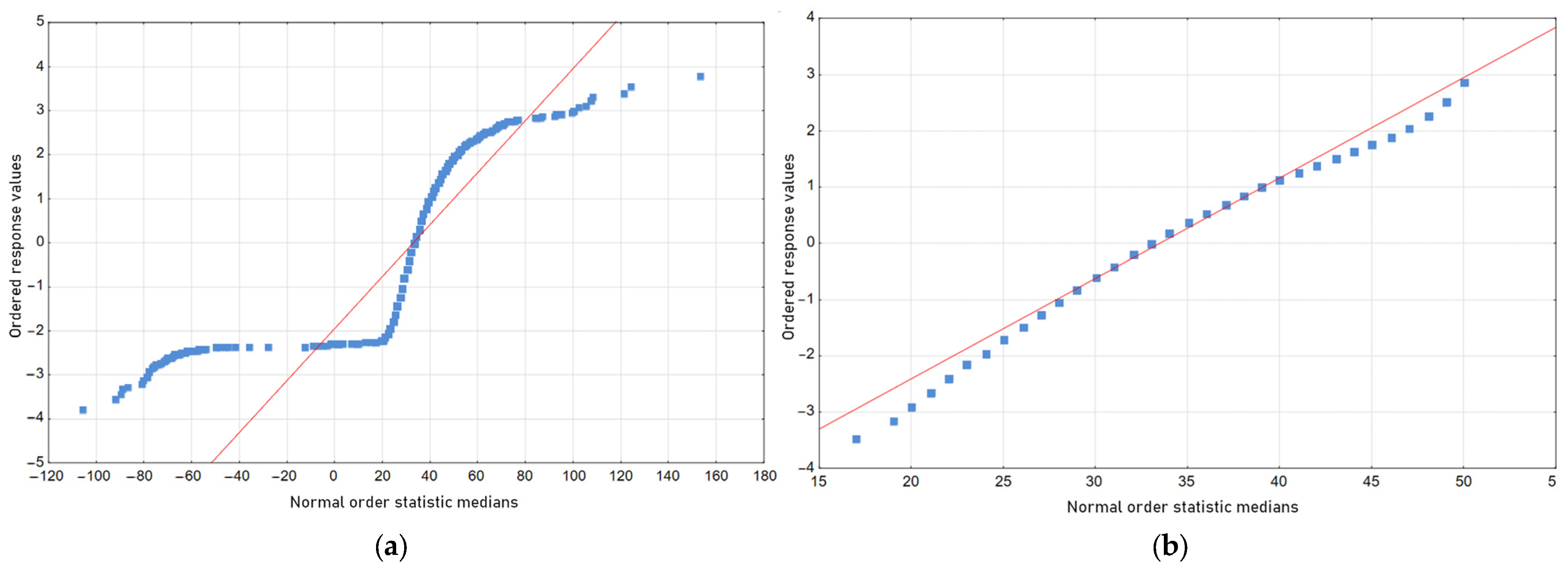
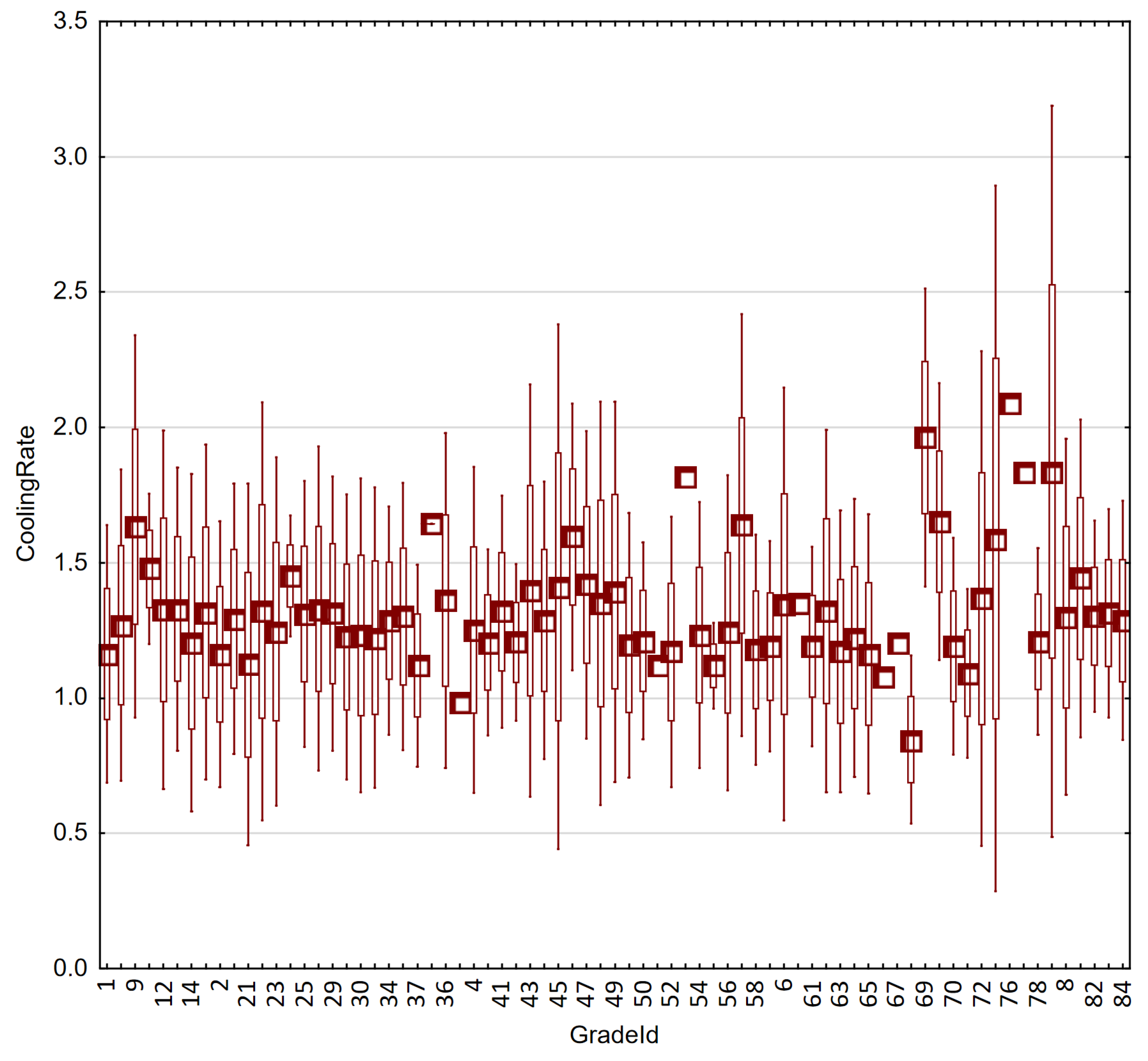
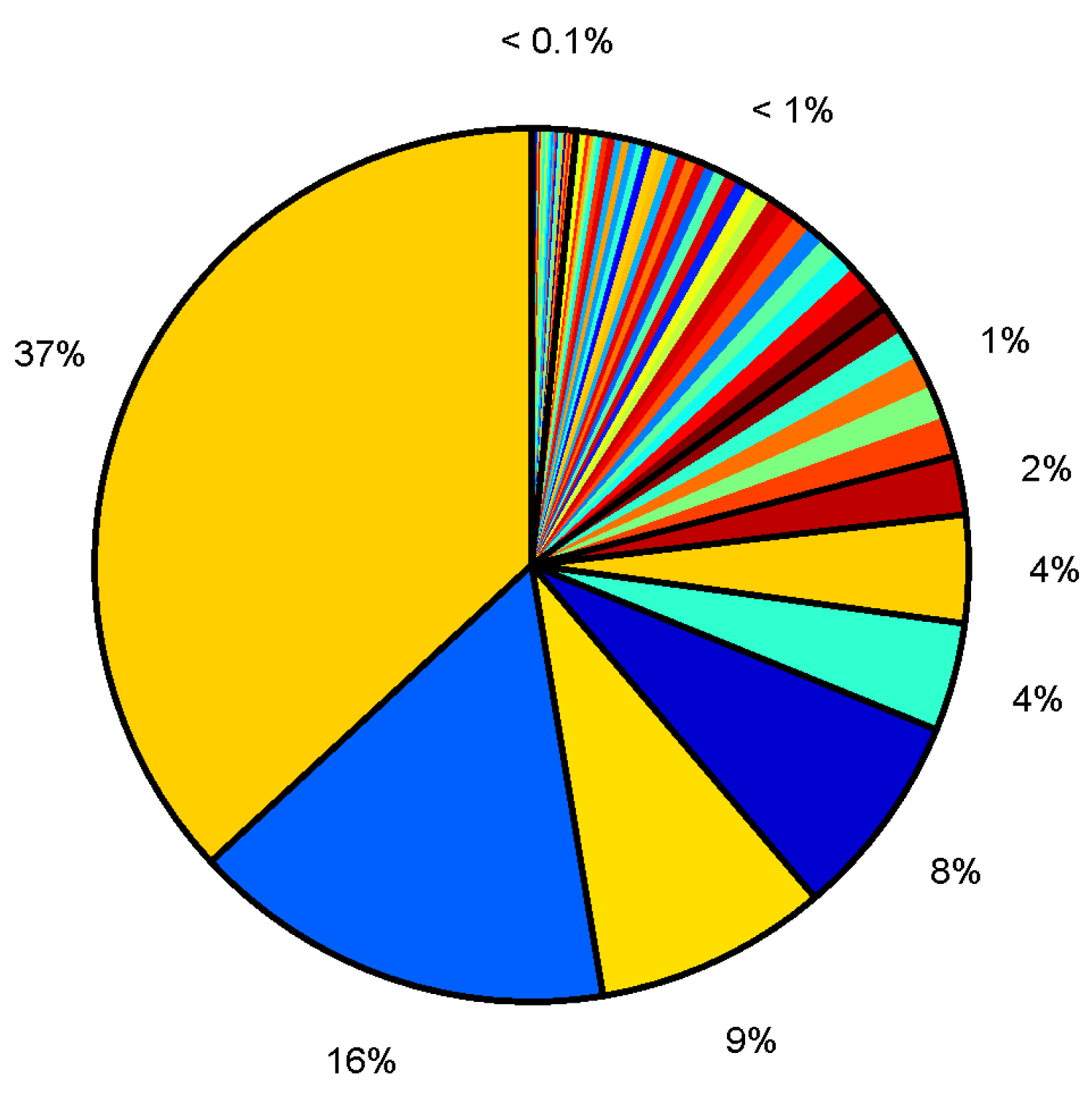
3.1. Statistical Data Analysis
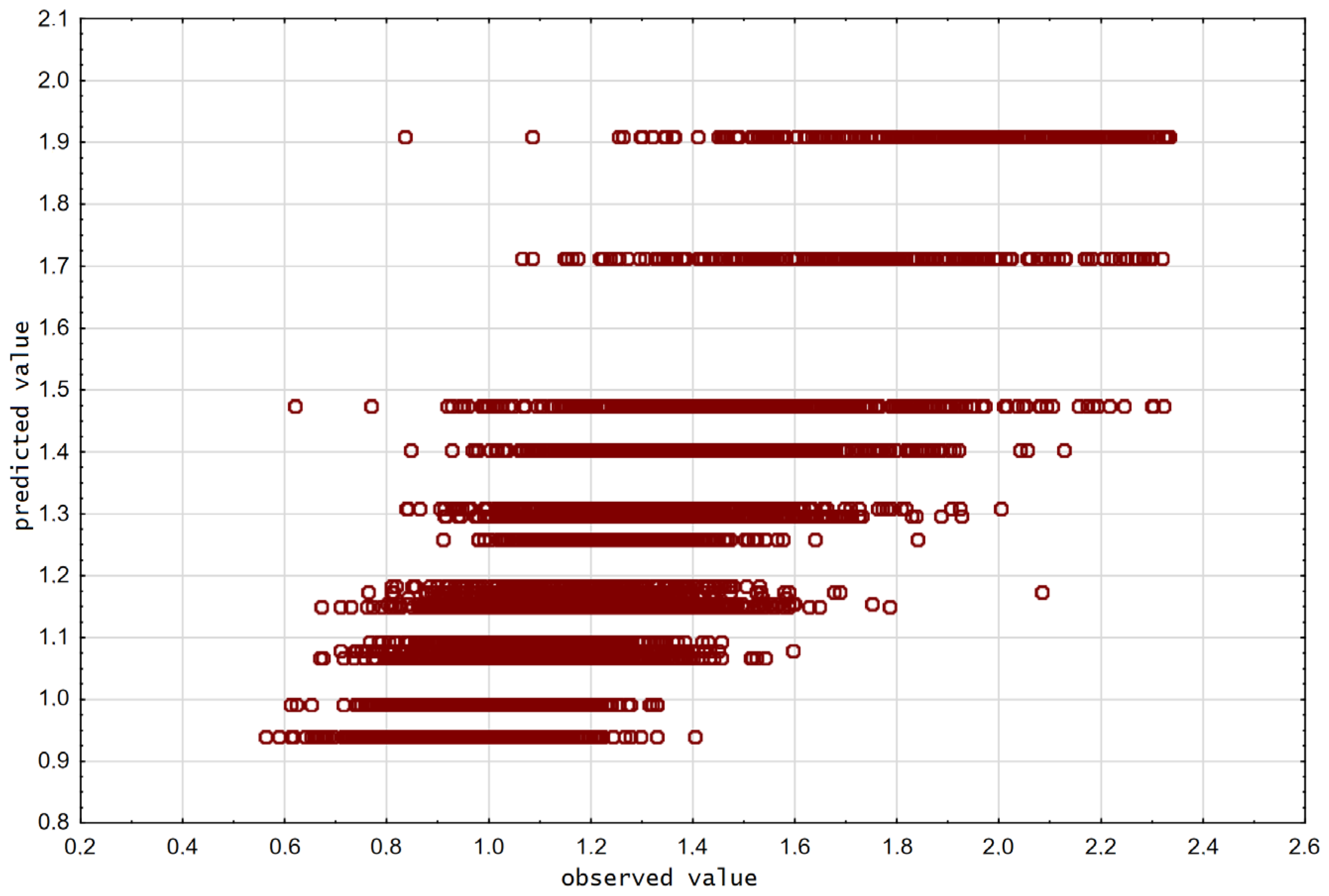
3.2. Regression Trees
4. Regression and Artificial Neural Networks
4.1. Linear Regression
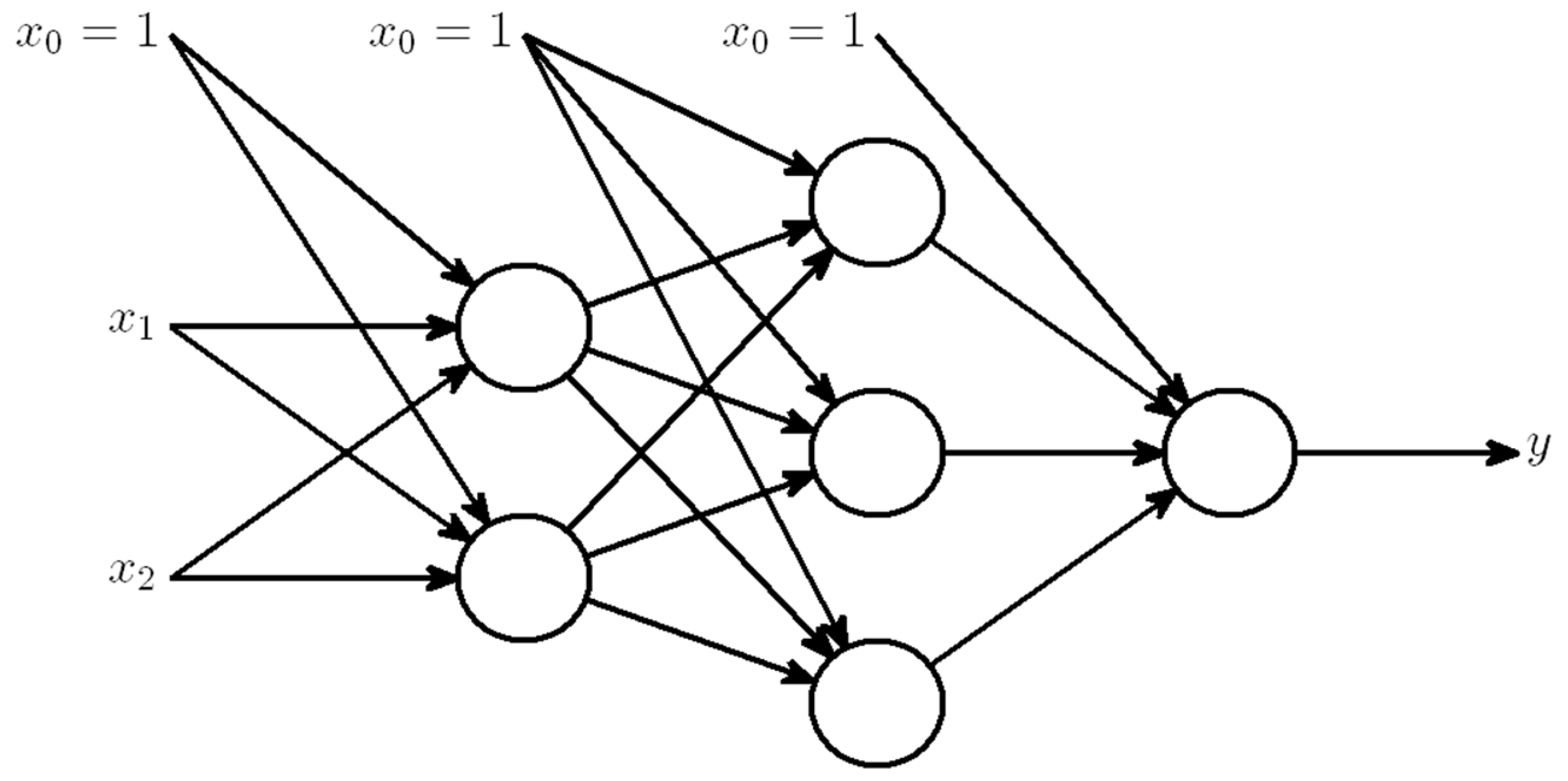
4.2. Artificial Neural Network
5. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hay, T.; Visuri, V.-V.; Aula, M.; Echterhof, T. A Review of Mathematical Process Models for the Electric Arc Furnace Process. Steel Res. Int. 2020, 3, 2000395. [Google Scholar] [CrossRef]
- You, D.; Michelic, S.C.; Bernhard, C. Modeling of Ladle Refining Process Considering Mixing and Chemical Reaction. Steel Res. Int. 2020, 91, 2000045. [Google Scholar] [CrossRef]
- Zappulla, M.L.S.; Cho, S.-M.; Koric, S.; Lee, H.-J.; Kim, S.H.; Thomas, B.G. Multiphysics modeling of continuous casting of stainless steel. J. Mater. Process. Technol. 2020, 278, 116469. [Google Scholar] [CrossRef]
- Santos, M.F.; Moreira, M.H.; Campos, M.G.G.; Pelissari, P.I.B.G.B.; Angélico, R.A.; Sako, E.Y.; Sinnema, S.; Pandolfelli, V.C. Enhanced numerical tool to evaluate steel ladle thermal losses. Ceram. Int. 2018, 44, 12831–12840. [Google Scholar] [CrossRef]
- Kusiak, J.; Sztangret, Ł.; Pietrzyk, M. Effective strategies of metamodelling of industrial metallurgical processes. Adv. Eng. Softw. 2015, 89, 90–97. [Google Scholar] [CrossRef]
- Tan, P.-N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Addison-Wesley: Boston, MA, USA, 2005. [Google Scholar]
- Rokach, L.; Maimon, O. Top-Down Induction of Decision Trees Classifiers—A Survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2005, 35, 476–487. [Google Scholar] [CrossRef]
- Barros, R.C.; de Carvalho, A.; Freitas, A.A. Automatic Design of Decision-Tree Induction Algorithms; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Regulski, K.; Wilk-Kołodziejczyk, D.; Kluska-Nawarecka, S.; Szymczak, T.; Gumienny, G.; Jaśkowiec, K. Multistage discretization and clustering in multivariable classification of the impact of alloying elements on properties of hypoeutectic silumin. Arch. Civ. Mech. Eng. 2019, 19, 114–126. [Google Scholar] [CrossRef]
- Balamurugan, M.; Kannan, S. Performance analysis of cart and C5.0 using sampling techniques. In Proceedings of the IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24–24 October 2016. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H. Neural Network Design; PWS Pub. Co., Ltd.: London, UK, 1996. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Hoboken, NJ, USA, 1999. [Google Scholar]
- Seber, G.A.F.; Lee, A.J. Linear Regression Analysis; Wiley-InterScience: Hoboken, NJ, USA, 2003. [Google Scholar]
- Kung, S.Y. Kernel Methods and Machine Learning; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Joshi, A.V. Machine Learning and Artificial Intelligence; Springer Nature: Cham, Switzerland, 2020. [Google Scholar]
- Hajder, P.; Opaliński, A.; Pernach, M.; Sztangret, Ł.; Regulski, K.; Bzowski, K.; Piwowarczyk, M.; Rauch, Ł. Cyber-physical System Supporting the Production Technology of Steel Mill Products Based on Ladle Furnace Tracking and Sensor Networks. In Computational Science–ICCS 2023; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; p. 10477. [Google Scholar] [CrossRef]
- Gajdzik, B.; Wolniak, R. Framework for activities in the steel industry in popularizing the idea of industry 4.0. J. Open Innov. Technol. Mark. Complex. 2022, 8, 133. [Google Scholar] [CrossRef]
- Zhang, C.J.; Zhang, Y.C.; Han, Y. Industrial cyber-physical system driven intelligent prediction model for converter end carbon content in steelmaking plants. J. Ind. Inf. Integr. 2022, 28, 100356. [Google Scholar] [CrossRef]
- Graupner, Y.; Weckenborg, C.; Spengler, T.S. Designing the technological transformation toward sustainable steelmaking: A framework to provide decision support to industrial practitioners. Procedia CIRP 2022, 105, 706–711. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Temperature | Density | Thermal Conductivity | Heat Capacity | Emmisivity | ||
|---|---|---|---|---|---|---|
| Material | [°C] | [kg/m3] | [W/m × K] | [J/kg × K] | ||
| 1 | Ladle armor | measurment | 7800 | 52 | 787 | 0.8 |
| 2 | Insulation | 1000 | 2750 | 0.95 | 1056 | 0.75 |
| Lining | ||||||
| 3 | ANCARBON C S1T12-EU | 1100 | 2960 | 8 | 800 | 0.75 |
| 4 | SYNCARBON C F7T05P | 1100 | 3040 | 6.0 × 10−3 (1000 °C) | 800 | 0.75 |
| 5.0 × 10−3 (1200 °C) | ||||||
| 5 | SINDOFORM C-EU | 1100 | 2900 | 3 | 800 | 0.75 |
| 6 | SINDOFORM C5-EU | 1100 | 2880 | 3.5 | 800 | 0.75 |
| 7 | Molten steel | measurment | 7100 | 41 | 750 | - |
| 8 | Slag | measurment | 3807 | 1.21 | 838 | 0.8 |
| MAE | 0.13 | Mean absolute error |
| R2 | 0.62 | Determination Coefficient |
| MODEL | MAE | R2 |
|---|---|---|
| Tree | 0.13 | 0.62 |
| Linear regression | 0.12 | 0.70 |
| Artificial neural network | 0.11 | 0.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sztangret, Ł.; Regulski, K.; Pernach, M.; Rauch, Ł. Prediction of Temperature of Liquid Steel in Ladle Using Machine Learning Techniques. Coatings 2023, 13, 1504. https://doi.org/10.3390/coatings13091504
Sztangret Ł, Regulski K, Pernach M, Rauch Ł. Prediction of Temperature of Liquid Steel in Ladle Using Machine Learning Techniques. Coatings. 2023; 13(9):1504. https://doi.org/10.3390/coatings13091504
Chicago/Turabian StyleSztangret, Łukasz, Krzysztof Regulski, Monika Pernach, and Łukasz Rauch. 2023. "Prediction of Temperature of Liquid Steel in Ladle Using Machine Learning Techniques" Coatings 13, no. 9: 1504. https://doi.org/10.3390/coatings13091504
APA StyleSztangret, Ł., Regulski, K., Pernach, M., & Rauch, Ł. (2023). Prediction of Temperature of Liquid Steel in Ladle Using Machine Learning Techniques. Coatings, 13(9), 1504. https://doi.org/10.3390/coatings13091504