1. Introduction
Air pollution in 2017 was estimated to have caused about 4.9 million deaths globally, while PM
2.5 alone was responsible for 2.94 million deaths [
1]. In China, the WHO’s annual median PM
2.5 concentration model shows that only parts of Tibet meet the organization’s air quality guidelines [
2]. The severely hazardous haze also causes between 1.2 and 1.6 million premature deaths per year [
3]. The excessive consumption of fossil fuels, such as coal, has been shown in previous studies to be responsible for significant deteriorations in air quality [
4,
5]. The contribution of the secondary aerosol formation of VOCs to haze formation is significant [
6,
7]. VOCs are a key precursor for the formation of O
3 and secondary organic aerosols (SOA) [
8]. SOA are an important component of fine particulate matter and a major contributor to haze pollution [
9,
10]. Studies have shown that haze pollution in China is mainly driven by SOA [
11]. Severe haze pollution leads to poor air quality and an estimated 2.6 to 4.8 million premature deaths worldwide each year [
12,
13,
14]. There is direct evidence of the human health effects of haze air pollution exposure related to respiratory VOC biomarkers, such as propanol and isoprene, in haze pollution [
15].
How to prevent and control urban haze disasters has become one of the major issues facing China’s sustainable economic development and harmonious urban development. The formation of urban haze has many causal factors, a wide impact, and a social and complex nature. The risk components of urban haze vary from place to place, and the study of urban haze risk assessment is important for proposing countermeasures for urban haze management from the perspective of risk prevention and control. This paper is expected to provide decision-making references for the development of targeted urban disaster prevention and mitigation systems, energy conservation and environmental protection, and haze management.
Haze events are frequent in China’s highly industrialized, economically developed and densely populated urban areas with a long duration and record air pollutant concentrations [
16]. Urbanization has provided inexhaustible impetus for China’s economic development, which raises the question of the relationship between the advancement of urbanization and haze pollution. Some scholars have used the development of urbanization as the main research variable through the construction of mathematical models to show that the development of urbanization exacerbates haze pollution [
17,
18]. Singh et al. also showed that for most PM
2.5 haze-causing studies in South Asia, vehicle emissions emerged as the dominant source [
19]. Latif et al. found that local vehicle emissions and industrial activities are significant contributors to haze pollutants in Malaysia [
20].
Researchers have studied the atmospheric haze causality of haze systems using a variety of methods, such as Zhang et al. who combined causal analysis and stochastic nonlinear features to construct a haze hazard prediction model for Beijing and simulated haze hazard trends under different governance and control policies [
21]. Several researchers have studied mathematical models for haze prediction, including nonparametric regression models [
22,
23], deep recurrent neural networks [
24,
25], inverse matrix-free machine learning models [
26], the nonlinear gray model [
27] and graphical networks [
28,
29]. These methods avoid the analysis of the complex details and mechanisms of haze hazards. Clarifying the causal relationships among the factors influencing haze hazards is a prerequisite for building haze prediction models. To explore the atmospheric haze causality of haze systems, some other methods have been applied including Granger causality analysis [
30,
31], convergent cross mapping [
32] and machine learning [
33,
34]. Factors influencing the haze hazard include oceanic transport at the marine level [
35,
36], local and global pollution emissions [
37,
38] and the interaction of industrial emissions with atmospheric dispersion [
39,
40].
Unfortunately, these studies were unable to describe the dynamic formation and evolutionary mechanisms of cross-regional haze hazards. The above methods have improved the efficiency of the assessment to a certain extent, but there are still obvious shortcomings, mainly because it is not easy to explain the role of each model parameter, which is similar to a “black box” operation and cannot explain the role of different indicators in the disaster risk assessment. Meanwhile, the original risk assessment model of urban haze pollution loss is slow in conducting risk assessments and has the problem of poor accuracy of the assessment results. In this paper, we selected the haze disaster cases in Fenwei Plain of China as training samples, collected 13 indicators that may affect the haze disaster risk at a county level and established a haze disaster risk assessment process model based on the PCA-MEE-ISPO-LightGBM algorithm.
2. Data Sources and Methods
2.1. Data Sources
Economic density and population density are from the Data Center for Resource and Environmental Sciences, Chinese Academy of Sciences, 2016–2021 (
https://www.resdc.cn/Default.aspx) (accessed on 16 November 2022). The annual average concentrations of PM
10, PM
2.5, SO
2, VOCs and NO
2 for 2016–2021 were calculated from the daily data downloaded from the National Real-Time Urban Air Quality Release Platform (
http://106.37.208.233:20035/) (accessed on 16 November 2022). Other data are mainly from the Shaanxi Provincial Statistical Yearbook 2016–2021, the Henan Provincial Statistical Yearbook 2016–2021, the Shanxi Provincial Statistical Yearbook 2016–2021 and the statistical yearbooks of prefecture-level cities. As shown in
Figure 1, this paper selects the Fenwei Plain as the study area including 11 cities in Shaanxi, Shanxi and Henan. Red dots indicate 129 counties’ data.
According to the regional hazard system theory [
41], in the formation of a disaster, the risk of disastrous factors, environmental sensitivity of the disaster and the disaster-bearing body are indispensable. The environmental sensitivity of the disaster refers to the earth’s surface environment, including the natural and man-made environment, where the disaster-causing factors are formed in the disaster-causing environment and directly lead to the occurrence of the disaster. The disaster-bearing body refers to the object that suffers from the disaster and is adversely affected. The risk of disastrous factors, environmental sensitivity of the disaster and disaster-bearing body jointly determine the magnitude of the haze disaster risk. Research shows that the main material components of urban haze are toxic gases and respirable particulate matter, which mainly come from human production and life; the formation of urban haze is influenced by human factors. In terms of the anthropogenic factors, the more developed the economy, the more motor vehicles owned by urban residents, the more exhaust emissions from motor vehicles and the increased risk of haze disasters. The development of the secondary industry is often accompanied by pollution and damage to the environment. The more a region relies on the secondary industry for its economic development, the more serious the pollution and damage to the environment and the greater the sensitivity to haze disasters. The greater the consumption of coal in a region, the more industrial emissions and the greater the risk of haze disaster. In addition, building construction is also a major source of respirable particulate matter; the larger the area of building construction in a region, the higher the concentration of respirable particulate matter and the greater the risk of haze disaster.
The regional hazard system is an earth surface heterogeneous system composed of the three aforementioned factors, and the disaster risk is influenced by the combined effect of the three aforementioned factors. In this paper, five indicators are selected from anthropogenic factors to quantitatively evaluate the sensitivity of the environmental sensitivity of disaster in the Fenwei Plain, including economic density, which represents the degree of economic development in a city; the number of motor vehicles, which represents the amount of motor vehicle emissions; the share of secondary industry, which represents the dependence of a region’s economy on the secondary industry; the share of coal consumption, which represents the industrial pollution emissions of a city; and the area of housing construction, which represents the housing construction projects of a region. The harmfulness of haze components refers to the damage of various components of haze to urban economy and residents’ health. As shown in
Table 1, five indicators, including the annual average concentration of VOCs, PM
10, PM
2.5, SO
2 and NO
2 were selected as the evaluation indicators of haze component vulnerability in Fenwei Plain. The population density, the number of health institutions and green areas in built-up areas are selected as the evaluation indicators of the vulnerability of urban haze. In hazy weather, the concentration of aerosols in the air rises, the atmospheric layer is relatively stable and unfavorable for the convective diffusion of air, the humidity and visibility of the atmosphere change dramatically, and people’s lives and health are greatly adversely affected. The greater the population density of a city, the greater the number of people suffering from haze and the greater the vulnerability of the disaster-bearing body. The greater the number of health institutions, the more developed the medical care, and the higher the carrying capacity of the medical system in the area, the more people can be treated and cured from the haze, reducing the risk of the haze and the vulnerability of the city to haze. Urban greening can absorb harmful gases and dust, reduce air pollution and reduce the vulnerability of the disaster-bearing body. Therefore, the population density, number of health institutions and green areas in built-up areas are selected as the evaluation indexes of urban haze vulnerability.
2.2. Methods
2.2.1. Matter-Element Extension Model
The basic idea of the matter-element extension model is to first delineate the categories of objects to be evaluated and delineate the different categories according to the relevant research results. Extension is a subject based on extension mathematics and matter element theory; matter element is the logical cell of extension [
42]. Assuming that the name of the thing is
N, the response thing feature is
C, and the value range of
C is
V, the ordered triple
R = {N, C, V} can be used as the basic matter element to describe the thing. The risk of haze disaster caused by VOCs is defined as the basic matter element
R, then
N represents the risk of haze disaster,
C represents the risk characteristics, and
V is the characteristic value. If
N has n features
C1,
C2, …,
Cn, then
- (1)
Determine the classical domain
According to the risk of haze disaster caused by VOCs, the risk assessment of haze disaster caused by VOCs is divided into e classification levels (
e = 1, 2, …, s). The risk level of haze disaster is set, and
is the evaluation index of emergency management ability (
j = 1,2…, n). The value range of
is
, and its classical domain can be expressed as
is the classical domain matter element.
- (2)
Determine the nodal domain
The matter-element of VOC-induced haze disaster risk assessment is essentially the atmosphere corresponding to each evaluation index (the range from the lowest value to the highest value). The eigenvalues of the object unit
Np (
p = 1, 2,
…,
m) can be evaluated according to the actual situation and scored according to the classification criteria, establishing the matter-element to be evaluated. The matter-element to be evaluated can be expressed as:
is a nodal matter element; np is the individual to be tested for VOC-induced haze disaster risk assessment; and
is the magnitude range of the node domain matter element with respect to the characteristic
, where
…
, (j = 1,2…,
n).
- (3)
Establish evaluation index correlation function
Calculating the correlation coefficient of evaluation index, the correlation function is:
- (4)
Define the entropy of evaluation indicators
denotes the element of the
th row and
th column of the normalized matrix. Let
denote the element of the
th row and
th column of the evaluation index after standardization.
Then, the entropy
of the evaluation index is
where the constant
denotes the information entropy coefficient,
,
.
Determine the entropy weight of each evaluation index
. Calculate the entropy weight of the evaluation index using the following formula:
- (5)
Calculate the comprehensive correlation degree of each evaluation index
The comprehensive correlation degree of each evaluation index, also known as multi-factor comprehensive correlation degree, refers to the degree of belonging of the evaluation index to each evaluation grade, which can be expressed as:
In the formula, is the weight vector of each evaluation index and satisfies .
- (6)
Calculate the VOCs’ haze disaster risk assessment level
The general matter-element extension model criterion adopts the principle of maximum membership degree; that is,
. Then, the risk level
N of VOCs haze disaster to be evaluated belongs to level
. This method sometimes cannot contain complete evaluation information. The use of asymmetric closeness principle can better solve the problem of maximum membership principle failure. The asymmetric proximity method [
43] is:
In the formula, and are the membership degrees of objects corresponding to A and B, respectively, which belong to . Among them, plays a regulatory role in the calculation results and compensates with the role of , which can help make the calculation results more conducive to classification. can be used, and the value should not be too large as this is not conducive to grading, and is taken in this application study. If , the emergency management capability level is .
2.2.2. Index Weight Determination Method
Traditional Principal Component Analysis
Principal component analysis is a mathematical method to reduce the dimension of a variety of sample data through certain mathematical means to improve the concentration of sample information [
44]. The specific steps of principal component analysis are as follows:
① Calculate the covariance matrix. The covariance of normalized sample data is
In the formula, is the covariance value of the evaluation index and the evaluation index; and is the normalized sample mean of the evaluation index.
② Calculate the eigenvalues and unit eigenvectors of the covariance matrix. Under the condition of data sample normalization, the covariance matrix is the correlation coefficient matrix. The eigenvalues
(
) and eigenvectors of the
th evaluation index of the correlation coefficient matrix are obtained using the Jacobian determinant method. The eigenvalues are sorted from large to small (
). The variance contribution rate is the proportion of a certain eigenvalue to the total number of eigenvalues:
is the variance contribution rate of .
③ Select the principal component. The cumulative variance contribution rate of the principal component is
In the formula, is the cumulative variance contribution rate of the first eigenvalues. When > 85%, is called the principal component.
④ Calculate principal component load:
In the formula, is the principal component score, and is the evaluation index of the normalized sample matrix.
⑤ Calculation of principal component scores:
where
is the
th principal component score, and
is the
th evaluation indicator of the normalized sample matrix.
⑥ Calculate the composite principal component score:
is the comprehensive principal component score of traditional principal component analysis.
The Improvement of Principal Component Analysis using Entropy Weight Method
The entropy weight method is an objective weighting method to describe the irreversible phenomenon of molecules. The greater the difference between the parameters of a system, the more information it contains and the smaller the entropy value; in contrast, the greater the entropy value, to evaluate the contribution of a weight index to the system. The entropy weight method has the advantages of highlighting the local information of the system and being less affected by subjective factors and has been widely used in many engineering fields [
45]. When the first principal component of the traditional principal component analysis method does not meet the requirement that the cumulative variance contribution rate is greater than 85%, multiple principal components need to be fused, and the weight distribution among the principal components is the main factor affecting the lithology stratification effect. The traditional principal component analysis method is to calculate the variance contribution rate of each principal component by weighting the principal components, but the principal components are independent of each other, and the information content of the calculation results may not rise but fall. In this paper, the entropy weight method is used to improve the traditional principal component analysis method. According to the variation degree of each principal component of the traditional principal component analysis method, the entropy weight method is used to recalculate the weight of each principal component. Finally, the comprehensive value of the entropy weight principal component is used as the index parameter of the haze risk division. The steps are as follows:
① Normalization calculation of each principal component:
In the formula, is the normalized score of the principal component of the first sample, is the score of the principal component of the sample, is the maximum score of the principal component, and is the minimum score of the principal component.
② Calculate the proportion of each principal component sample:
is the entropy of the
principal component.
③ Calculate the weight of each principal component:
where
is the weight of the
th principal component.
④ Calculate the entropy principal component composite score:
2.3. Calculate the Weight of Each Evaluation Index
As shown in
Table 2, the KMO sampling fitness number for this principal component analysis is 0.684, which is greater than its threshold value of 0.5, indicating that there is correlation between the variables, which meets the requirements. The Sig value is 0.000, which is less than 0.05, which indicates that this data can be subjected to principal component analysis and is scientific and informative. The eigenvalues and contribution rates of each principal component are shown in
Table 3. According to the principle that the eigenvalue is greater than 1, the first three items are selected as the main components, and the variance contribution of these three items are 39.76, 22.74 and 15.39%, respectively, and the cumulative contribution of the three items is 77.9%, which can basically reflect the information of the original indexes. The first 3 items are used as principal component factors and denoted by F1, F2 and F3, so that the original 13 indicators are replaced by the first 3 principal components, and the loading status of each factor on the original indicators can be calculated at the same time.
As seen in
Table 3, the F1 eigenvalue is 5.169, with a contribution rate of 39.76%. As seen in
Table 4, tops the three principal components and is the primary driver of haze risk formation in Fenwei Plain cities. Analysis of the principal component F1 loadings reveals that the 1st principal component F1 has large values above 0.66 for indicators X1 (economic density), X4 (share of coal consumption), X11 (population density) and X12 (number of health institutions), which indicates that economic development density, coal consumption, population density and health institutions are the first constituents of haze risk. The top 3 loadings of principal component F2 are X3 (number of motor vehicles), X5 (housing construction areas), X6 (annual average concentration of VOCs) and X8 (annual average concentration of SO
2), which shows that the haze hazard in Fenwei Plain cities is mainly dominated by the toxic gases VOCs and SO
2. The indicator with the highest principal component F3 loading value is X7 (annual average PM
10 concentration), followed by PM
2.5 and the share of secondary industry, reflecting that PM
2.5, PM
10 and secondary industry are also important environmental factors in the formation of haze risk.
2.4. Haze Hazard Risk Principal Component Composite Score and Ranking
The loadings in the principal component loadings matrix reflect the extent to which the indicators play a role in the formation of haze risk, so the indicator weights can be expressed in terms of the indicator loadings. Using the weighted model, the scores of the evaluation units on the 3 principal components and the haze risk indices on the different principal components can be calculated as:
where
is the haze risk index of the
th evaluation unit on different principal components, e.g., in the 1st principal component, it is the haze risk index of evaluation unit
on F1.
is the loading value of the
th indicator on the corresponding principal component, and
is the standardized value of the
th indicator of the
th evaluation unit.
According to the principle of principal component analysis, the proportion of each principal component to the cumulative contribution reflects the importance of each principal component. The weight can be determined by analyzing the contribution of the principal components, and the weighting model can be used to calculate the comprehensive score of the evaluation unit, which is the comprehensive haze risk index
F. It is calculated as:
where
,
and
represent the scores of the first, second and third principal components, respectively, whereas
,
and
represent their corresponding contribution rates.
2.5. LightGBM
The light gradient lifter is a decision tree algorithm proposed based on gradient one-sided sampling and unique feature bundling with optimization in the negative gradient direction of the loss function [
46]. The LightGBM algorithm is more efficient in processing high-dimensional big data due to the unique feature bundling (EFB) algorithm and gradient-based one-sided sampling (GOSS) algorithm in LightGBM. Suppose a training set
,
, consisting of
N samples, where
represents the data,
denotes the
-dimensional vector space,
represents the category labels, and
denotes the faulty samples. The objective of the LightGBM algorithm is to find a mapping relation
to approximate the function
, such that the loss function
is minimized. The objective function can be expressed as:
where
is the loss function, and
denotes the regular term unlike the fast descent method of GBDT.
LightGBM uses Newton method to quickly approximate the objective function. Equation can be derived as:
represents the first-order loss function, and
represents the second-order loss function. The equation is as follows:
The information gains in LightGBM are as follows:
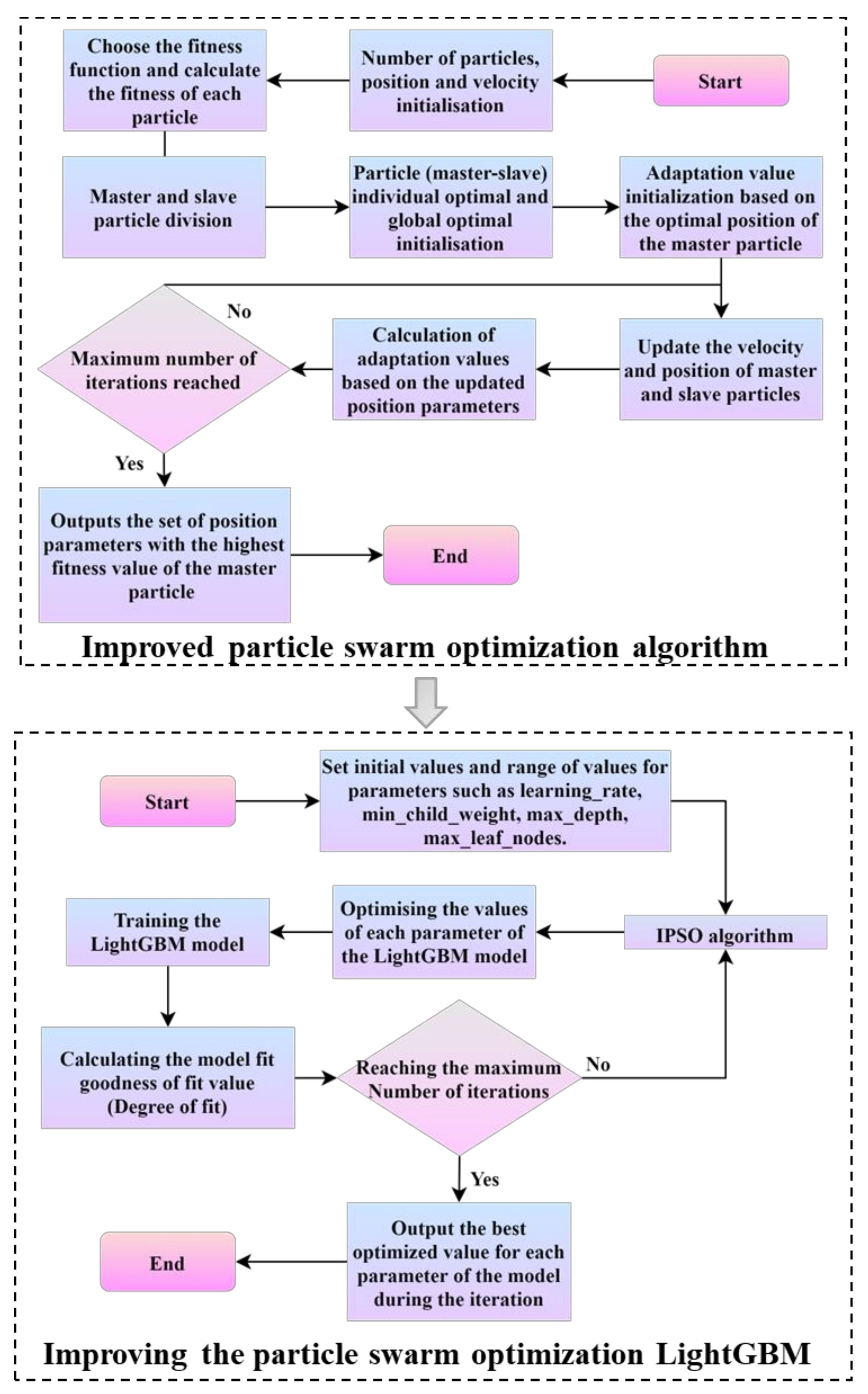
2.6. Improved PSO Algorithm
As a swarm intelligence algorithm, particle swarm optimization (PSO) has been widely used in various industries to solve practical problems in recent years. The traditional PSO algorithm is easily falls into local optimum and has poor convergence speed and accuracy in the iterative process. It is difficult to ensure the efficiency of the algorithm in practical engineering tasks. After using the topology, the optimization process of particle swarm is carried out as follows:
① All particles in the particle swarm are arranged from large to small according to the fitness value of the particles at the initial time. The first N particles are selected as the main particles, N is a positive integer, and all particles in the particle swarm except the main particles are used as the slave particles.
② The K-means clustering method is used to classify the subordinate particles by using each main particle as the clustering center.
③ Each master particle from the particle group and its corresponding cluster center is used as an improved particle group to obtain N improved particle groups.
④ Using Formulas (28) and (29) to update the velocity of the main particle and the slave particle in the improved particle group and multiple slave particle groups, each slave particle group has the same number of slave particles.
In the formula, represents the position record of the main particle in the i th improved particle group at the current time t. denotes the position record of the j th slave particle in the i th improved particle group at the current time t. denotes the velocity of the main particle in the i th improved particle group at the current time t. represents the velocity value of the j th slave particle in the i th improved particle group at the current time t. k is the convergence factor and a constant. and are learning factors. represents the historical optimal position record of the main particle in the ith improved particle group at time t (taking the optimal position value of the main particle in the i th improved particle group). represents the historical optimal position record of the j th slave particle in the i th improved particle group at time t. and are constants greater than 0 and less than 1. represents the optimal historical position record of the primary particles in all improved particle groups at the current time t. denotes the optimal record of the historical position of the particle in the i th improved particle group at the current time t.
⑤ The positions of master and slave particles are updated using Formulas (27) and (28) according to the updated velocity value:
⑥ According to the updated position parameters of the master-slave particles, the fitness value is recalculated, and iterative optimization is performed. Through the above process, it can be concluded that when the proposed improved particle swarm relationship topology is adopted, other main particle swarms can also jump out of the local extremum as much as possible to search for the global optimum and improve the accuracy of parameter optimization when the slave particle group in a certain region falls into the local optimum. On the other hand, in the traditional particle swarm optimization algorithm,
and
are fixed values, generally taking a constant between 0 and 2, which limits the global and local search ability of particles to a certain extent. Therefore, linear increasing and decreasing functions are introduced to improve this part. The improved formula is as follows:
In the formula,
and
are the initial values of the learning factor.
and
are the current and maximum number of iterations, respectively. The improved master–slave particle velocity update formula is as follows:
In summary, the IPSO-LightGBM model construction process is shown in
Figure 2.
2.7. Model Establishment and Performance Evaluation Index
Based on the ISPO-LightGBM algorithm, this paper establishes five risk assessment models, including population, transportation, crop and economic disaster risks and integrated risk. All models take the three types of indicators of disaster-causing factors, disaster-pregnant environments and disaster-affected bodies as input vectors, and different loss risk levels as output vectors. The specific model establishment process is shown in
Figure 3.
The LightGBM model optimized using IPSO has higher fitness values during the iterative process and converges faster than the PSO algorithm. In the iterative search process, the search stability of IPSO algorithm is high, and the optimal hyperparameter combination of LightGBM model has been searched for around 300 iterations. In contrast, the PSO algorithm is more volatile in the iterative search process, and the convergence does not appear at 600 iterations, and the gap between the adaptation degree and IPSO algorithm is further widened, and the final convergence adaptation degree of the experiment is lower than that of the IPSO algorithm. Under the given termination iteration condition, the model parameters obtained using IPSO optimization are Learing_rate = 0.25, gamma = 0.13, max_depth = 7, min_child_weight = 3, and lambda = 1.
Among them, the model tuning parameters were optimized using 10-fold cross-test, and the grid search was performed for the main three parameters of the XGBoost model, which are the number of weak classifiers, the maximum depth of the decision tree and the learning rate. The five model optimal parameters and the accuracy of the training set are shown in
Table 5.
To evaluate the model accuracy, four evaluation indicators were selected, including accuracy (ACC), detection rate (
P), recall (
R) and
F-value (
F):
where
TP means true positive, which is itself a positive sample, and the prediction is also a positive sample.
TN means true negative, which is itself a negative sample, and the prediction is also a negative sample.
FP means false positive, which is itself is a positive sample, and the prediction is a negative sample.
FN denotes false negative, which is itself a negative sample, and the prediction is a positive sample. In the above evaluation index, the accuracy rate indicates the proportion of all correctly predicted samples to the total sample. Accuracy indicates the proportion of samples with positive predictions that are true positive samples. Recall indicates the proportion of positive cases in the actual sample that are correctly predicted. The F-value is an indicator that balances the accuracy and recall rates and is the summed average of the two.
3. Results and Discussion
3.1. Analysis of Evaluation Results
As seen from
Table 6, F1, F2 and F3 represent the scores of the three principal component analyses, respectively, which are calculated by Equation (21). F is the composite haze risk index, which is calculated by Equation (22). The haze risk index is high in the Fenwei Plain urban agglomeration, especially in Xi’an, which is as high as 9.773. The analysis of the three principal component scores of the Fenwei Plain urban agglomeration reveals that the scores in F1 are much larger than those in F2 and F3, indicating that the main drivers are economic density, the number of motor vehicles, housing construction areas and the number of health institutions. Xi’an has been the center of economic development in Northwest China and is rich in industrial and mineral-rich resources, and urbanization is also rapid, resulting in increased environmental pressures, serious air pollution, the proximity of cities and the influence of the spatial spillover effects of pollutants, making it an extremely high-risk area for haze. To effectively control the risk of haze, the Fenwei Plain urban agglomeration should actively transform its economic development, improve traffic laws and regulations and regulate motor vehicles, thus reducing motor vehicle exhaust pollution and relieving the pressure on traffic. City governments should strengthen joint control and prevention mechanisms to control the construction area of an area within a certain period of time through macro regulation so that it does not gather too much, make good isolation measures to reduce respirable particulates brought about by construction work, control the source of haze components and accelerate the improvement of urban greening. Urban greening can, to a certain extent, absorb harmful gases and dust generated by the city, reduce air pollution, purify the air and help reduce the vulnerability of disaster-bearing bodies. Xi’an, Sanmenxia, Lvliang and Luoyang belong to the high-risk area of haze. Analyzing the scores of their three principal components revealed that Xi’an, Sanmenxia and Luoyang are in the first principal component, indicating that the haze risk drivers in these two cities have the first principal component of economic density, the number of motor vehicles and housing construction areas. First, to carry out haze risk prevention and control, we must adjust the energy structure and promote clean energy. We must replace coal with other clean energy sources to reduce coal consumption, thus reducing the material components of haze formation and the risk of haze. Second, in the case of irreplaceable coal, we must improve the desulfurization of coal, denitrification and dust removal technology to reduce the emissions of sulfide and other emissions due to burning coal and achieve the purpose of reducing the risk of haze. Third, relevant enterprises should increase investment in research and development and actively develop new technologies to improve energy utilization, reduce energy consumption and achieve energy conservation, emission reduction and green development. The middle-risk areas are Lvliang, Luoyang, Linfen, Yuncheng and Baoji. Both Tongchuan and Jinzhong have high scores with the second principal component, while the SO
2 concentration, PM
10 concentration and coal consumption share of the second principal component also play an important role in the formation of haze risk. Weinan, Xianyang, Tongchuan and Jinzhong are four cities with relatively high scores for the third principal component; with rich forest vegetation, the strong self-cleaning ability of the atmosphere and a high rate of good air, their haze pollution is small and low risk. Therefore, small enterprises with low capacity and high emissions should be eliminated by strengthening the regulation of pollutant emissions from factories. The approval system of enterprise project engineering should be established, improved and strictly enforced, raising the threshold of enterprise access and controlling the emission of haze material components from the source.
3.2. Case Verification
In this paper, we use the large-scale haze pollution in Fenwei Plain from 1 November 2021 to 31 December 2021 as a case study to validate the application of the major haze hazard assessment model based on the ISPO-LightGBM algorithm. This haze process caused a massive haze disaster in 11 prefecture-level cities in the Fenwei Plain, affecting a total of 52 million people. The established models were used to evaluate the affected population, transportation, crop and economic disaster risks and integrated risk, and were then compared with the actual disaster loss levels at the county level, and the results are shown in
Table 7. The five types of disaster risks in the Fenwei Plain are shown in
Figure 4.
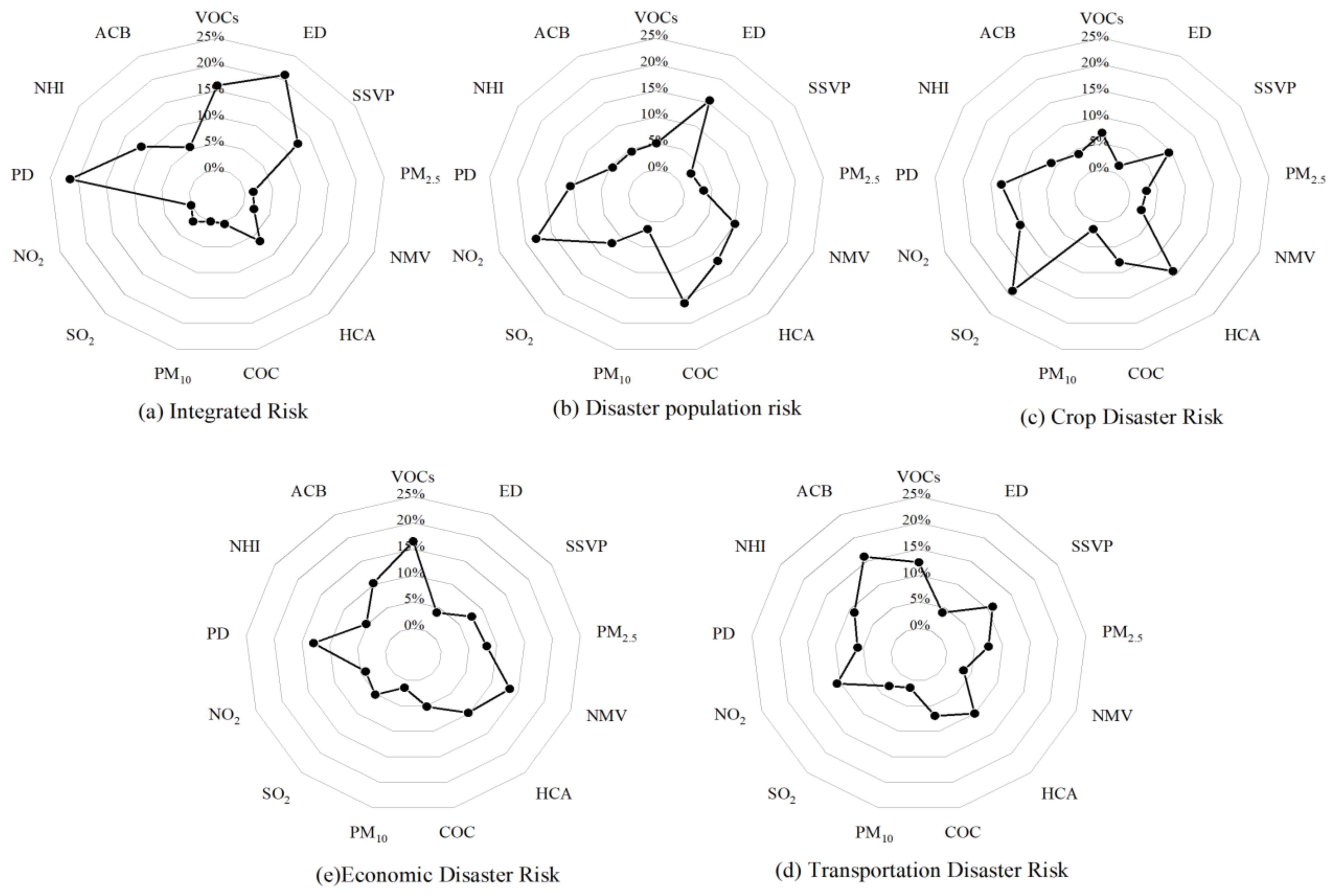
3.3. Importance of Indicators
To understand the various factors that influence the assessment results, it is necessary to calculate the specific contribution of each assessment indicator. The LightGBM algorithm calculates the importance of an indicator based on the principle that the more times an input indicator is selected as a branching feature when the decision tree branches, the more important the feature is. In this paper, the importance of indicators was calculated for each of the five types of risk assessment objectives, and the results are shown in
Figure 5.
Among them, the most important indicators affecting the risk assessment of the affected population are NO2, economic density and coal consumption, indicating that the risk of disastrous factors, environmental sensitivity of disaster and disaster-bearing body all contribute to the assessment results. The transportation disaster risk has a greater relationship with NO2 and VOCs in green areas in built-up areas, indicating that transportation risk has a greater correlation and impact with pregnant environments. The crop disaster risk has a great relationship with SO2, the proportion of secondary industry, housing construction areas and population density; in particular, the impact of SO2 is prominent, indicating that the disaster of crops is closely related to the disaster environment. The main influencing factors of economic disaster risk are VOCs, population density and the number of motor vehicles. The economic disaster risk is closely related to disaster-causing factors and disaster-pregnant environments. The main influencing factors of integrated risk are population and GDP densities. The possible reason is that GDP itself is a comprehensive index. GDP cannot only reflect the comprehensive exposure of the disaster-bearing body in the region but also the vulnerability of the disaster-bearing body in the region to a certain extent. In other words, it can be considered that the comprehensive disaster prevention and mitigation capacity of a region with high GDP is stronger than that of the region with low GDP. Overall, the contribution of different indicators to different risk assessment results is not the same, and none of the indicators can contribute to a negligible extent, with the contribution of each indicator ranging from 5 to 12%.
3.4. Impact of Indicator Size on Assessment Results
As shown in
Table 8, RD denotes the risk of disastrous factors, ESD denotes the environmental sensitivity of disaster, and DBB denotes the disaster-bearing body. To examine the influence of the number of indicators on the accuracy of the assessment model, this paper combined the input indicators of different dimensions and compared the accuracy in the haze risk assessment results using only the causative factor, the combination of the risk of disastrous factors, the environmental sensitivity of disaster, the disaster-bearing body and the use of all indicators. By comparison, it was found that the change in the number of indicators had less impact on the assessment results of the two models of population and transportation disaster risks. However, the number of indicators has a large impact on the accuracy of the assessment of the three models of crop and economic disaster risks and integrated risk, and the accuracy is the lowest if the model input is only the causative factor, which is 4–16% lower than the full indicator. In addition to the disaster-causing factors, the addition of both the environmental sensitivity of disaster and disaster-bearing body indicators will improve the accuracy, and the disaster-bearing body indicators will improve more than the environmental sensitivity of the disaster indicators because the disaster-bearing body indicators have more subcomponents. The highest accuracy rate was achieved by using all indicators together as input, indicating that the amount of indicators has a significant impact on the assessment results.
3.5. Impact of Environmental Factor Variables on Assessment Results
We added the meteorological conditions as well as the terrain as a factor for comparison. Pearson analysis was performed for topographic and meteorological factors, as shown in
Table 9. Altitude, temperature and wind speed were found to be moderately positively correlated with haze risk. Other factors such as woodland, grassland, relative humidity and precipitation showed weak negative correlations.
As shown in
Table 10, we added topographic and meteorological factors to each of the five integrated models, and we found that the topographic factor enhances the model less, and the meteorological factor enhances the model significantly relative to the topographic factor. The combined input of topographic and meteorological factors improves the models more significantly. Compared with the model before input, the accuracy of the five risk models was improved by 6.12% on average.
3.6. Comparison with other Studies
A comparison of the risk assessment model proposed in this study with models proposed in other similar studies can better elucidate the differences between this study and other studies, as shown in
Table 11. Currently, there are few detailed studies on haze risk assessment. Second, in terms of feature selection methods, this paper uses the new gradient enhancement algorithm LightGBM to filter the features. To the best of our knowledge, there are few studies using the LightGBM algorithm to filter features. Compared with other mainstream integration algorithms in the boosting family, optimizing the LightGBM model using ISPO requires less parameter tuning, shows faster adaptation to the model and is more scalable. In conclusion, compared with the models proposed in other studies, the model proposed in this paper can effectively solve the haze risk assessment problem and has good prediction performance, especially with a precision of 0.91.
4. Conclusions
In this paper, based on nearly 300,000 indicators of haze cases in 11 cities in Fenwei Plain in China, a haze disaster assessment model is established using the PCA-MEE-ISPO-LightGBM algorithm, and the model is validated with data from the haze pollution process in Fenwei Plain region in mid-November 2021. The results show that the model can be used for the assessment of the affected population, transportation, crop and economic disaster risks and integrated risk before major haze disaster events, which is important for disaster risk management operations.
(1) Through the matter-element analysis, we construct the classical domain, determine the matter-element to be evaluated and calculate the correlation degree of the evaluation index and the haze disaster assessment level. Introducing the asymmetric closeness degree criterion, the index weight is improved using the entropy weight method to the principal component analysis method, and the haze disaster evaluation method based on the matter-element extension model of the improved principal component analysis is proposed. The IPSO optimization algorithm which divides the topological relationship between master and slave particles and dynamically adjusts the iterative learning factor is proposed to solve the problem that the particle swarm easily falls into the local optimal region in the iterative process. The IPSO is integrated into the parameter optimization process of the LightGBM model, and the hyperparameters of the LightGBM prediction model are optimized. The disaster risk assessment models based on the PCA-MEE-ISPO-LightGBM algorithm show good applicability. The performance indexes of the five models in the risk assessment, such as accuracy, detection rates, recall rates and F-values, are above 80%, indicating that the models show good generalization performance and can be used in actual disaster risk assessment work.
(2) The average annual concentration of VOCs, economic density, number of motor vehicles, housing construction areas, average annual concentration of SO2 and PM2.5, and the share of secondary industry and coal consumption have a strong influence on the risk of urban haze disaster. The higher the level of economic development in a city, the more motor vehicles, the higher the dependence of economic development on the secondary industry, the higher the coal consumption and the higher the risk of urban haze. Xi’an has the highest risk of haze disaster, and Jinzhong has the lowest risk of haze. The haze hazard risk degree of Fenwei Plain has obvious geographical differences, and the haze risk of Xi’an urban agglomeration is extremely high and centers on it, gradually decreasing roughly in the west, south and north directions.
(3) The model can calculate the contribution of importance evaluation indicators to the risk assessment results. In addition to the influence of VOC indicators on most of the assessment targets, different risk assessment targets have different influencing factors. Economic disaster risk is influenced by the factors of the disaster-bearing body. The affected population, crop and economic disaster risks are mainly influenced by the environmental sensitivity of disaster, whereas the main influencing factors of integrated disaster risk are population and GDP densities. The importance of indicators increases the interpretability of the risk assessment models, improves the understanding of the relationship between indicators and assessment results, and helps improve the understanding of the “black box” model of machine-learning algorithms.
(4) The amount of indicators and sample size play an important role for data-driven assessment models. Integrated learning algorithms in disaster risk assessment downplay hazard mechanisms such as hazards and vulnerabilities and purely use disaster system-related data for learning and simpler modeling, which also requires the sufficient accumulation of assessment indicators and sample size. On the one hand, hazard-causing factor indicators, hazard-inducing environment indicators and hazard-bearing body indicators all have an important impact on the results of hazard risk assessment, and the use of the full indicator volume can improve the accuracy of assessment by 10–15% compared with only the hazard-causing factor indicators. On the other hand, increasing the sample size by one to two orders of magnitude can improve the assessment accuracy by 5–13%. This indicates that disaster big data can be of great help to improve the performance of disaster risk assessment models.
A disaster risk assessment model for the haze process in the Fenwei Plain is established using disaster big data. With rapid socio-economic development, the regional disaster-bearing body and environmental sensitivity of disaster will undergo many changes. In future research, it is necessary to continuously introduce the latest data, update and accumulate big data, and improve the reliability of the model. To summarize the next step, the focus is on two directions. The first is to continue to improve the indicator system and sample distribution, update the indicators using the first national comprehensive natural disaster risk census data and further improve the model. The second is to collect cases of major haze disaster processes Y.R.: editing, revision. in other regions and verify whether the model is generalizable in the Beijing-Tianjin-Hebei and Yangtze River Delta regions.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}