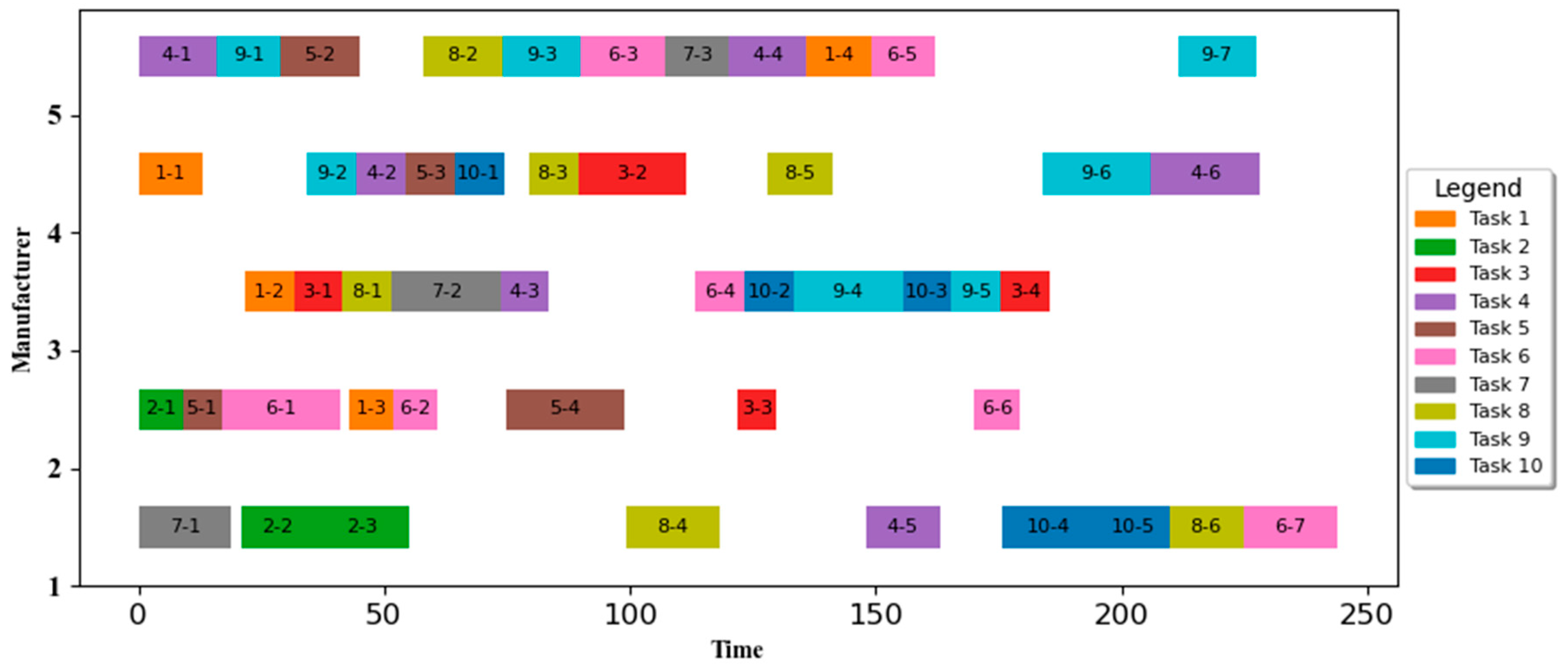
3.1. Description of the Problem
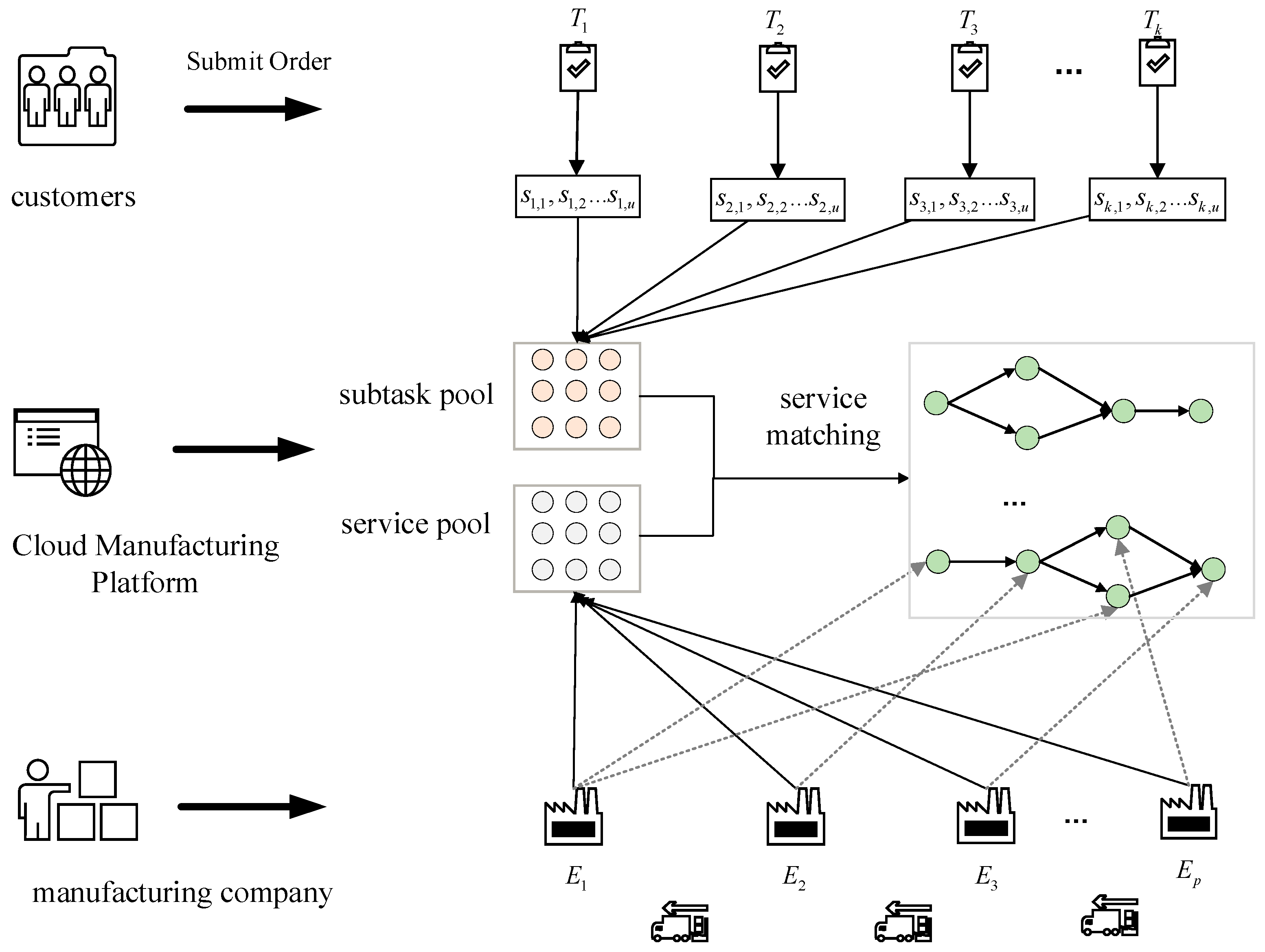
The diagram of the cloud manufacturing model is shown in
Figure 1; users continuously provide manufacturing task requirements to the cloud manufacturing platform through the Internet, and manufacturing service providers submit manufacturing services and capabilities to the cloud manufacturing platform system. The cloud manufacturing platform virtualises and services manufacturing resources, generates a set of optimal service scheduling solutions based on user task requirements, and finally sends them to each enterprise manufacturing workshop to complete the execution of specific tasks.
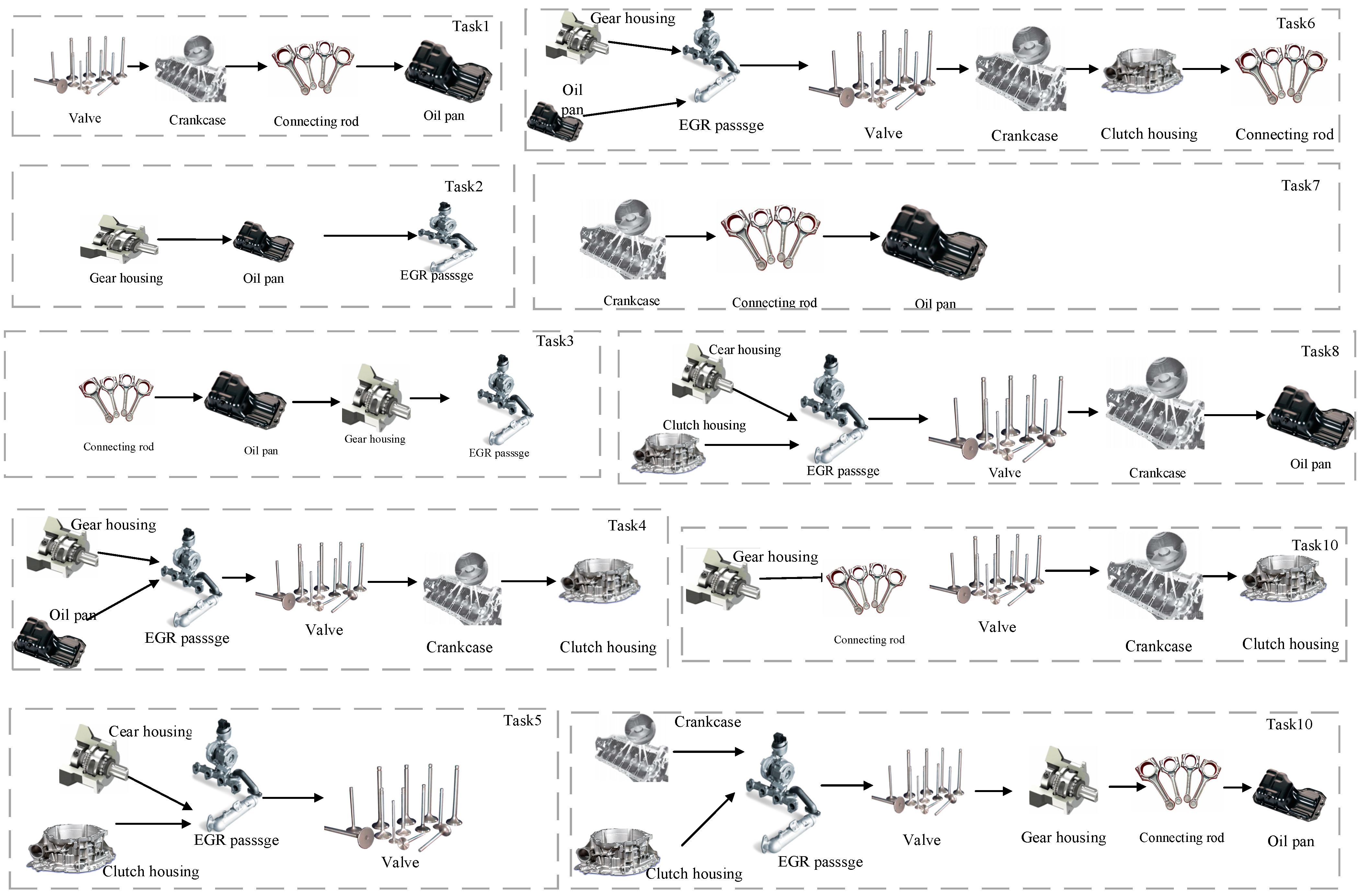
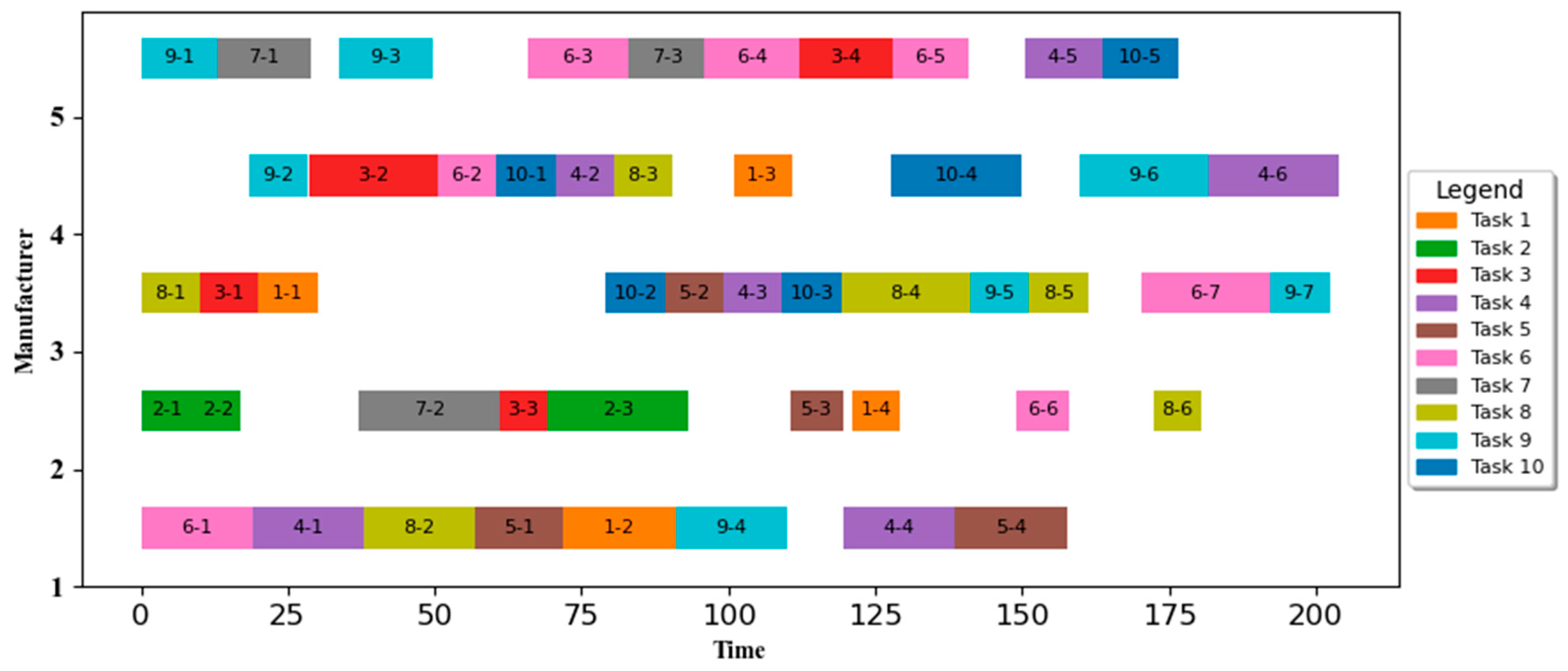
Suppose that under the current cloud manufacturing platform consists of manufacturing service enterprises, denoted as , which the enterprise can provide i types of manufacturing services, which the type of services provided by the enterprise is denoted as . The time, cost, and quality of processing vary from enterprise to enterprise for the same type of processing. Demand tasks from the cloud manufacturing platform user order decomposition, assuming different customers in the cloud manufacturing platform under the submission of single or multiple orders, the cloud platform to receive the allocation for the task processing.
The cloud platform receives the allocation for I tasks to process, denoted as , each task includes single or multiple sub-tasks, which may require one or more types of services, and can be decomposed into j sub-tasks, denoted as , where the corresponding attributes of each subtask are different and the attributes of the subtasks are denoted by the symbols . The decomposed subtasks are performed by manufacturing resource providers in the CMfg system by providing manufacturing services. The following assumptions are made for the model.
- (1)
Tasks are all available and have the same priority at the beginning;
- (2)
That storage buffers are infinite;
- (3)
Manufacturers have unlimited manufacturing resources;
- (4)
A service provider can handle different types of subtasks, but can only service one subtask at a time;
- (5)
Different service providers process the same type of subtask with different costs and times;
- (6)
That the quality of service for completing different types of subtasks is different;
- (7)
That all subtasks cannot be interrupted once processing has begun.
The relevant parameters involved in the mathematical model are as shown in
Table 2:
3.2. Multi-Task Scheduling Model
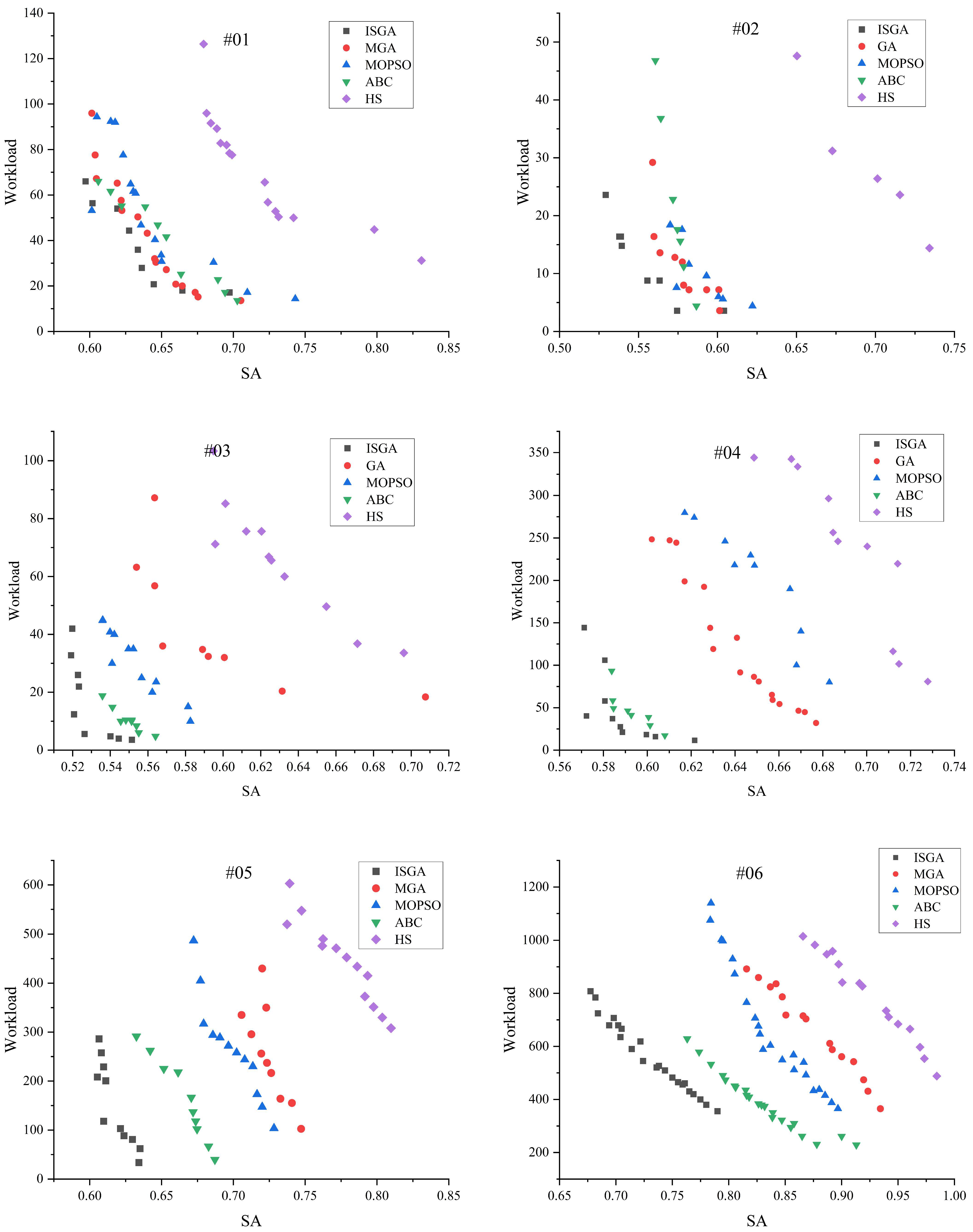
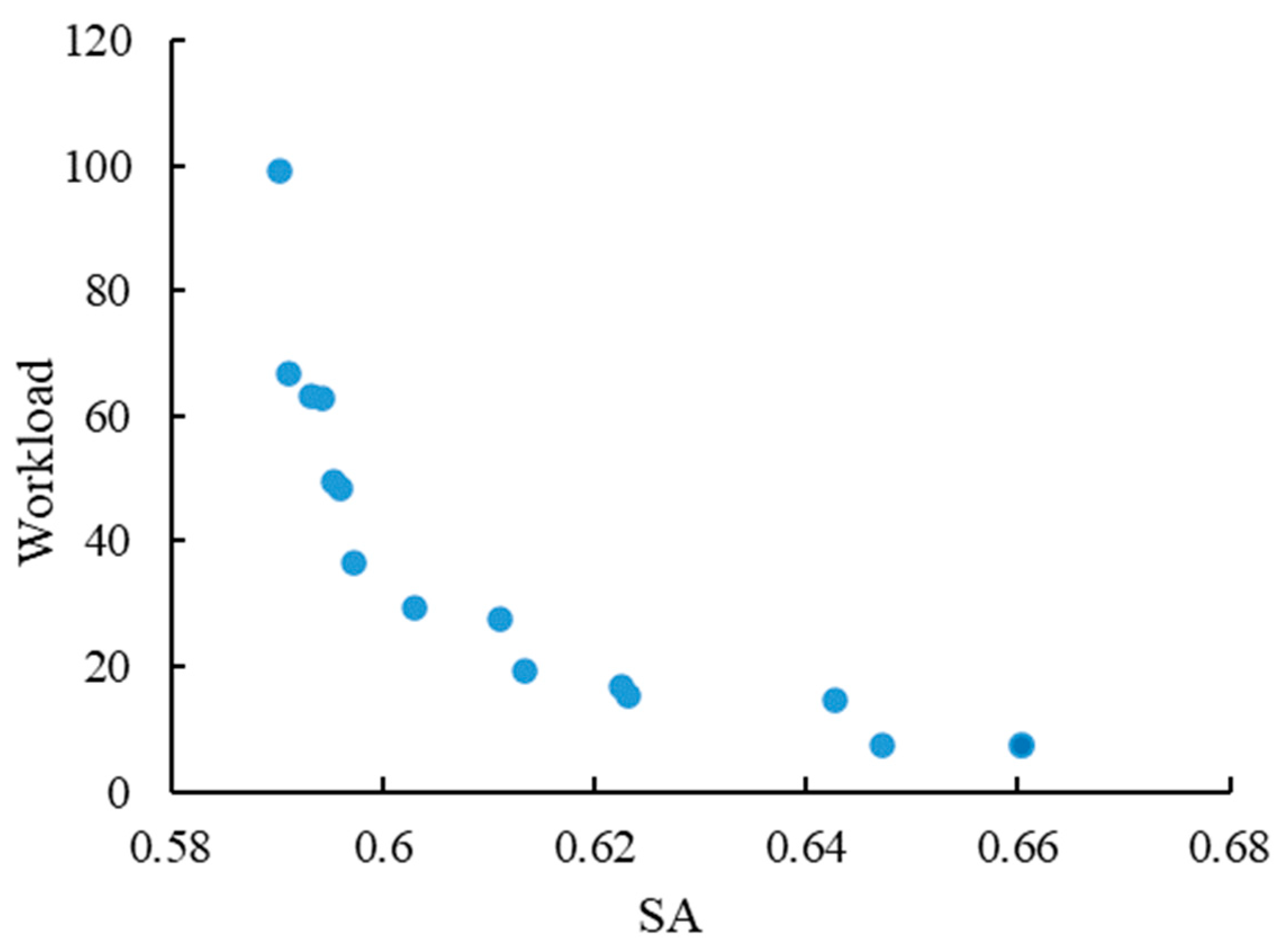
In this paper, the objective function of the multi-objective optimisation model is established as follows with the optimisation objectives of minimising the workload on the service supply side and maximising the satisfaction on the service demand side in the cloud manufacturing process:
Maximum demand-side satisfaction:
Based on the perspective of service providers, it aims to avoid the overloading of some service providers or idling of some service providers, thus improving the resource utilisation. Load balancing is controlled by calculating the sum of the absolute value of the difference between the working time and the average working time of each service provider, thus protecting the interests of the service providers. The calculation method is shown in Equation (3).
Cloud manufacturing is the embodiment of the manufacturing-as-a-service concept, and customer satisfaction reflects the degree of customer satisfaction with the resource scheduling service provided by the cloud manufacturing platform, which is one of the key factors in evaluating the success of the cloud manufacturing model. In this paper, we investigate the comprehensive impact of the three dimensions of time, cost, and service quality on customer satisfaction SA.
Customer satisfaction with the total completion cost is expressed as the ratio of the actual completion cost to the maximum acceptable cost to the customer. Since the number of subtasks varies from task to task, for a more accurate representation of satisfaction, a weighted summation is used, with the size of the weight depending on the number of subtasks. When the value is smaller, it represents the lower actual total completion cost required, i.e., the higher the cost satisfaction of the customer. The formula is shown in Equation (4).
where the total cost consists of the manufacturing cost
CC and the transport cost
LC; the manufacturing cost
CC consists of the installation cost
SC and the processing cost
PC, which are calculated in Equations (5) and (6).
Customer satisfaction with the total completion time is expressed as the ratio of the actual total cost of completion to the customer’s maximum acceptable cost. The smaller the value, the shorter the actual total completion time required, i.e., the higher the customer’s time satisfaction. Total completion time includes the manufacturing time and logistics time. The calculation is shown in Equation (7).
In this paper, transport time
TT, installation time
ST, and processing time
PT are considered, and the time required for different sub-tasks and selected service combinations is different. The specific calculations are shown in Equations (8)–(13).
where
represents the predicted start time of sub-task
when it is processed by service provider m, and
is the time required to transport sub-task
, which is processed by service provider n to service provider m. If service providers m and n are in the same company, then
.
Equation (10) represents the completion time of the subtask at service provider m. The actual start time of the subtask depends on the actual start time of the task, while the actual start time of the subtask depends on the completion time of the previous subtask and the current service provider’s available time , the earliest time at which the service M can handle the current request for the subtask.
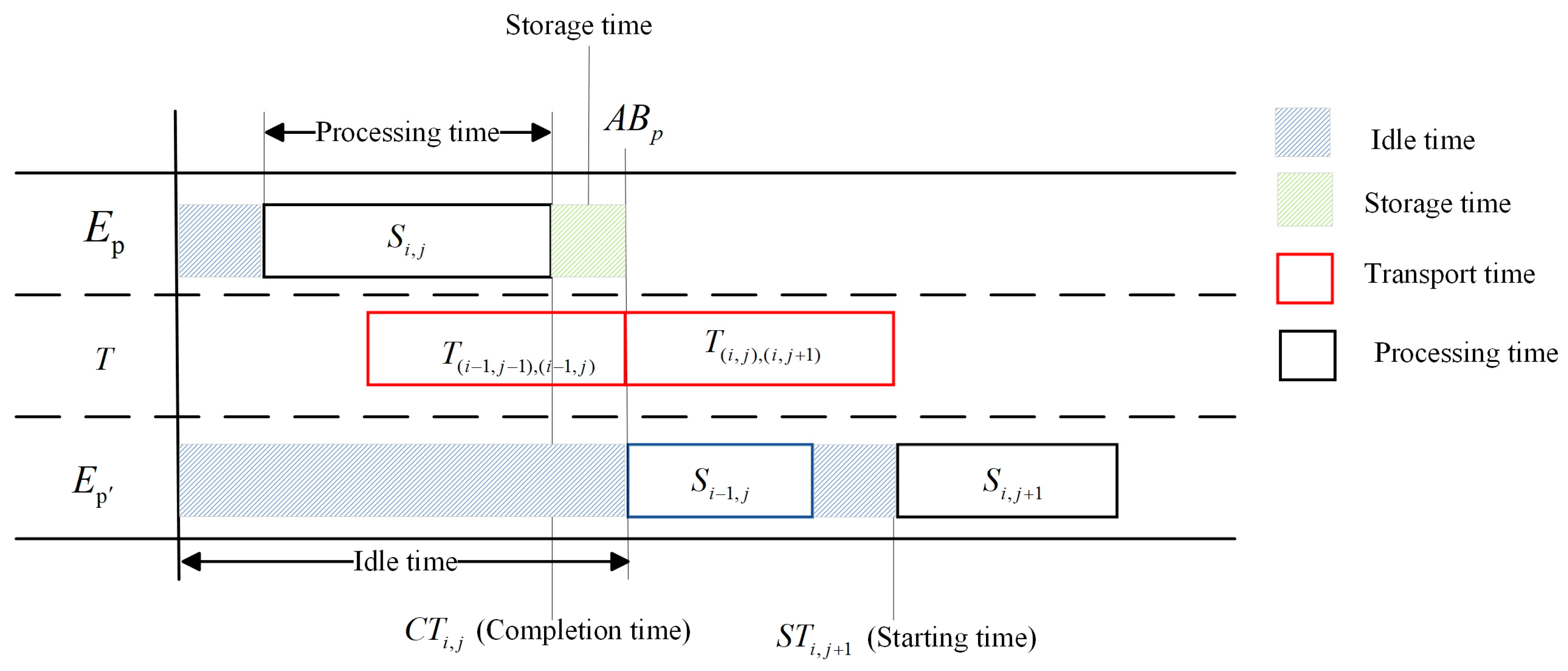
Since each manufacturing service provider in cloud manufacturing is geographically dispersed, the transport time required by the vehicles is non-negligible, so we consider two cases of the number of vehicles, which are finite and infinite. And if the manufacturing service provider completes the sub-tasks if they cannot be transported immediately, they are put into the warehouse for storage. When sub-task
is processed at manufacturing service provider
, whether its subsequent sub-task
can start immediately depends on the processing progress of another manufacturing service provider
, on the one hand, and on the transport time of sub-task
. And when the available time of the vehicle under the manufacturing service provider
is less than the completion time of the subtask, the subtask is put into the storage area until a free vehicle is available. As shown in
Figure 2.
Consequently, a priority transport strategy is considered to minimise transport time. This strategy includes the following: (1) transporting subtasks with services assigned by subsequent subtasks first if immediate initiation is not possible; (2) prioritising subtasks for transportation based on their completion time when either both sub-tasks can start immediately or neither can; (3) otherwise, placing them in the storage area to await transport.
Customer satisfaction with total service quality is expressed as the ratio of the actual total quality of completion to the minimum acceptable service to the customer. A higher value means a higher level of satisfaction. The formula is shown in (14).
By assigning appropriate weights to different factors affecting customer satisfaction, a composite value of
SA is calculated to better represent customer satisfaction. The calculation is shown in Equation (15).
In order to better determine the share of the cost, time, and service quality in customer satisfaction, hierarchical analysis is used. Hierarchical analysis allows for the layering of problems. Depending on the nature of the problem and the objectives to be achieved, the problem is broken down into different components. The interactions and connections between the factors will form an ordered hierarchical model. The relative importance of the hierarchical factors in the model is then expressed quantitatively based on one’s judgement of the objective reality. A comparative judgement matrix was constructed, and the weights for ranking the relative importance of each factor at each level were mathematically determined. Finally, the weights of the relative importance of each factor were comprehensively calculated as the basis for evaluation and selection.
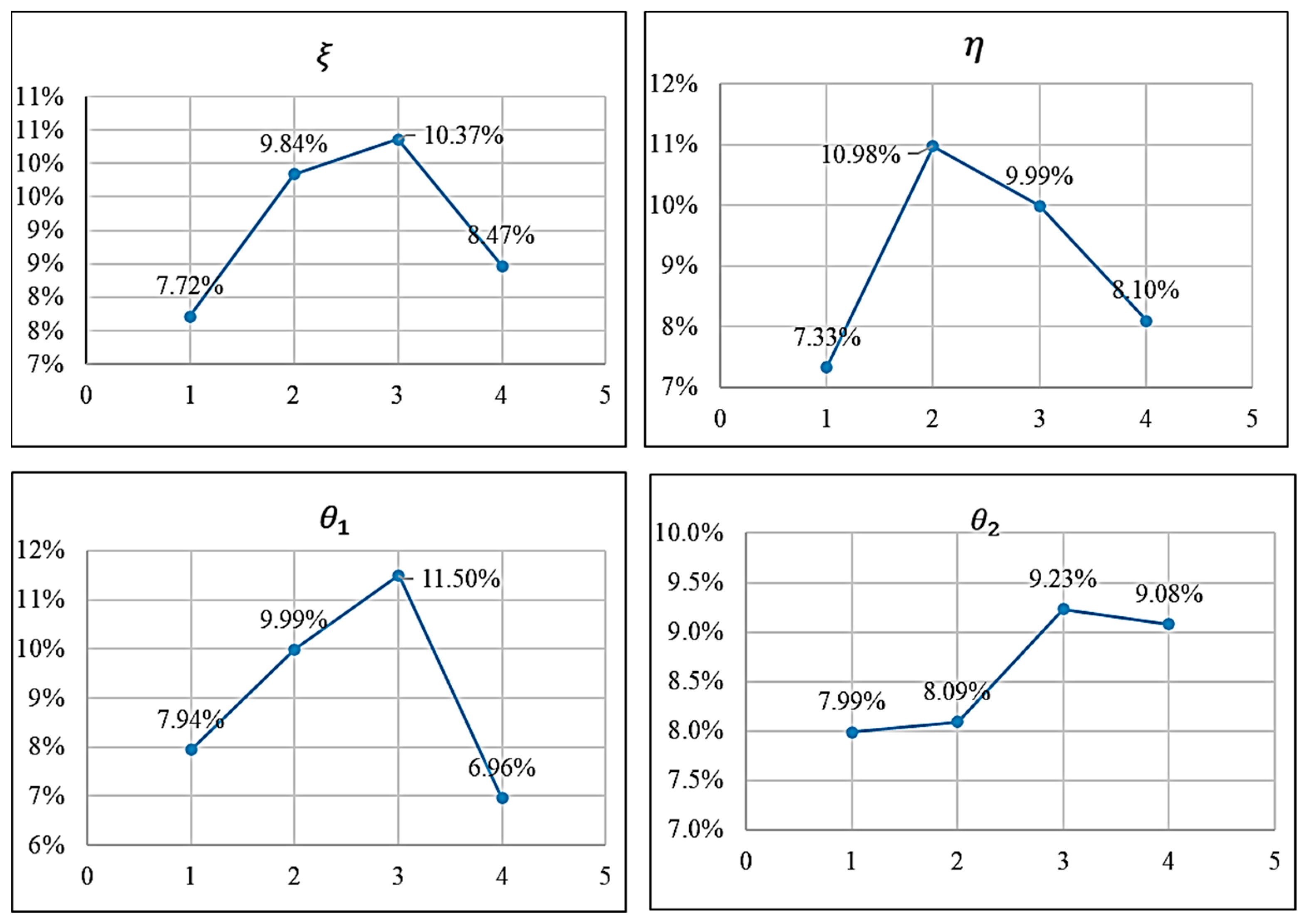
The values of , , and were obtained through the calculation as 0.63, 0.26, and 0.11, and since the evaluation index of service quality is the bigger the better, the value of is negative for the purpose of unifying the indexes, and the values of in the final mathematical model are 0.63, 0.26, and −0.11.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}