1. Introduction
Content Addressable Memories (CAMs), also known as Associative Memories (AM), are very popular digital devices used for data storage and data processing applications. They are exploited, for example, as look up tables for IP addresses in network routers and find applications as well in data compression algorithms, database management, and image pattern recognition processing [
1,
2,
3,
4,
5]. In recent years, they have also been exploited in Artificial Neural Networks [
6,
7] and hyperdimensional computing for Artificial Intelligence (AI) [
8], where highly efficient associative memories tend to be a common specification. Usually, CAM devices are also an important building block in the front-end for High-Energy Physics experiments, such as ATLAS and CMS (Compact Muon Solenoid) at LHC. In such systems, they are exploited for fast searching operations, especially for particle tracks recognition in the Trigger system (for filtering the huge amount of data coming from the detectors [
4]).
The CAM is a static memory whose main function is to conduct a bit-to-bit comparison of an input digital word (searching data) and all of the data stored inside the memory itself. When the input data match the stored data, the CAM simultaneously returns an acknowledge bit (MATCH) and the address of the matching data inside the memory bank. The fully parallel comparison only lasts one single clock cycle, allowing fast searching operations at a hardware level w.r.t. other software implementations. However, this architecture might lead to an increase in power consumption, due to the contemporary and continuous comparison activity in every device cell [
3]. For this reason, different hardware solutions, based on particular single-bit cells [
3,
4,
5,
9,
10,
11] or various power saving algorithms [
11,
12,
13], have been explored in the past.
The novelty of this work, compared to the state-of-the-art, is the presentation of a Content Addressable Memory developed with a full-custom design approach in the 28 nm CMOS-Bulk node (CAM-28CB). The highly downscaled technology node offers a speed increase, without a power consumption increase (with the standard digital design flow, a device speed increase and a size reduction, up to a factor of 3, result, compared to the CMOS 65 nm node [
3,
9]). Moreover, the main aim of this work is to produce aggressive power reduction achieved with a full-custom design, both in the schematic and the layout phase. The core scheme relies on a fast asynchronous architecture, with only logic XOR or NOR cells and without internal clocking or a pre-charge phase, which are characteristics that usually tend to decrease CAM speed performances and sometimes require several clock cycle latency periods before the output is provided. In terms of the layout side, the full-custom approach allows the minimization of area occupancy and layout parasitic capacitances, reducing the dynamic power consumption. A detailed analysis of the layout-induced parasite’s impact on the overall CAM power consumption will be provided in the following. Furthermore, the 28 nm CMOS-Bulk node exhibits an excellent rad-hard performance, as demonstrated in [
14], up to 1Grad-TID. Being resilient against long-term radiation damage is a crucial requirement in every system for High-Energy Physics and particle physics. Thanks to its performances, the proposed CAM meets the specifications needed for the Fast-TracKer (FTK) processor to be integrated in the next ATLAS upgrade, where CAM stages are placed very close to the detectors and a certain radiation hardness is required. Moreover, CMOS-Bulk is preferred to Fully Depleted Silicon-on-Insulator (FD-SoI), which exhibits a higher sensitivity due to radiation-induced charge entrapped in the substrate oxide. In detail, the proposed prototype (CAM-28CB) is able to store 64 different digital words with an 18-bit length (for an overall 1.152 kb storage capability). This meets the specifications of the ATLAS application, whilst increasing the digital word length does not have a significant impact on the energy spent per search per bit. On the other hand, increasing the amount of stored data may reduce the maximum device speed, especially at a low supply voltage. The prototype operates with a single supply voltage ranging from 0.85 up to 1 V, with a working frequency of up to 100 MHz. The prototype core area is 1702 µm
2. Its overall average power consumption (both static and dynamic power) is 46.86 µW, which is equivalent to 0.41 fJ/(Bit∙Search).
The rest of the paper is organized as follows.
Section 2 presents the general architecture and the transistor-level design of the proposed CAM device. Information about the layout-induced parasitic capacitances and their impact on the power consumption is provided. In
Section 3, complete experimental validation of the prototype test chip is provided. The overall CAM performances are compared with the state-of-the-art in this section. At the end of the paper, conclusions are drawn.
2. The CMOS 28NM CAM Design
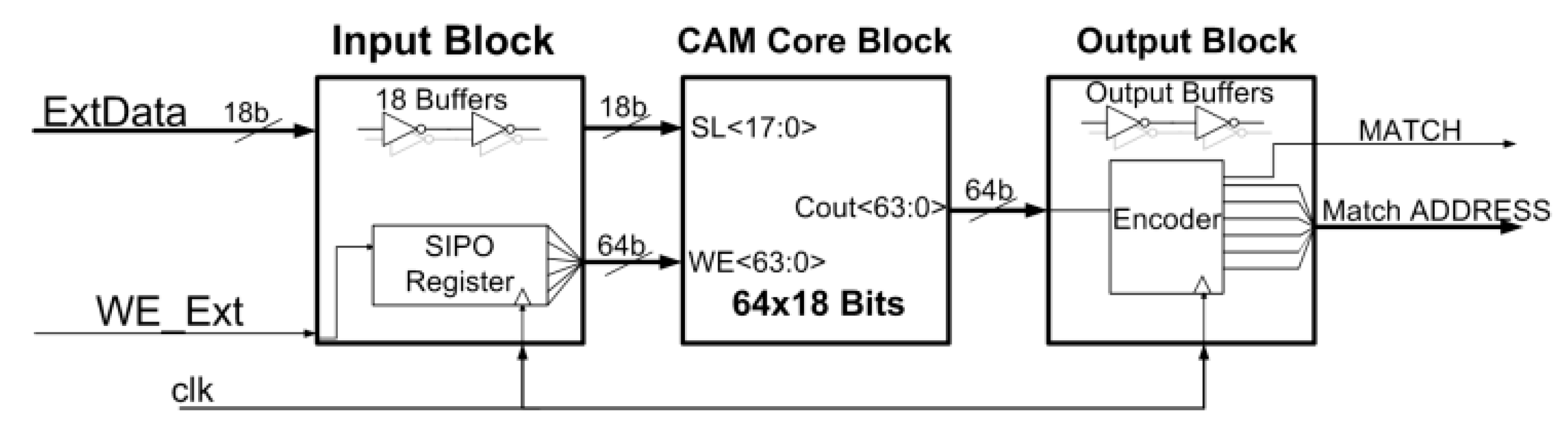
The CAM-28CB proposed in this paper is composed of three main blocks: An Input Block; a Core Block; and an Output Block. The overall functional scheme is illustrated in
Figure 1.
The Input Block stage contains 18 input buffers and a Serial-Input-Parallel-Output (SIPO) synchronous register. This stage, as well as the entire CAM, operates in two different modes: WRITE and SEARCH. Every 18-bit digital word that must be stored (or searched) inside the memory is provided by the ExtData bus signal (generated from an external setup). An external Write Enable signal (WE_Ext) asserts the CAM operation mode. In the case of the WRITE mode, this signal feeds the input of the SIPO register, which, in turn, provides the Write Enable signals (WE<63:0>) for each CAM row. In this way, 64 18-bit data, coming from the ExtData bus, are correctly stored inside the 64 rows of the CAM, once every clock cycle. In order to correctly operate, ExtData must be synchronous with the SIPO clock: ExtData changes every clock rising edge and at the same time, the WE signal shifts to the following memory row. Lastly, before reaching the CAM memory bank and being stored, digital words from ExtData are buffered into the Search Lines (SL<17:0>) bus, and are the same for storage or search operations. Driving the data lines is a power-hungry operation and, for this reason, these buffers’ power consumption must be taken into account for complete device characterization.
The second stage, as shown in
Figure 1, is the 1.152 kb CAM Core Block, performing both storage and searching operations in a completely asynchronous way. The particular architecture of the single-bit cell will be illustrated in the following text. Lastly, the prototype design also includes the output stages, which drive the output load for testing purposes, and a digital encoder, which provides the address of the matching data for developing an appropriate measurement setup.
Therefore, the device has three main output signals: The MATCH signal (logic ‘1’ if the searched word has been found inside the memory core); the 8-bit MATCH address bus; and the SIPO output. The MATCH signal and MATCH bus only operate during the search mode, while the SIPO register is only active during the write phase.
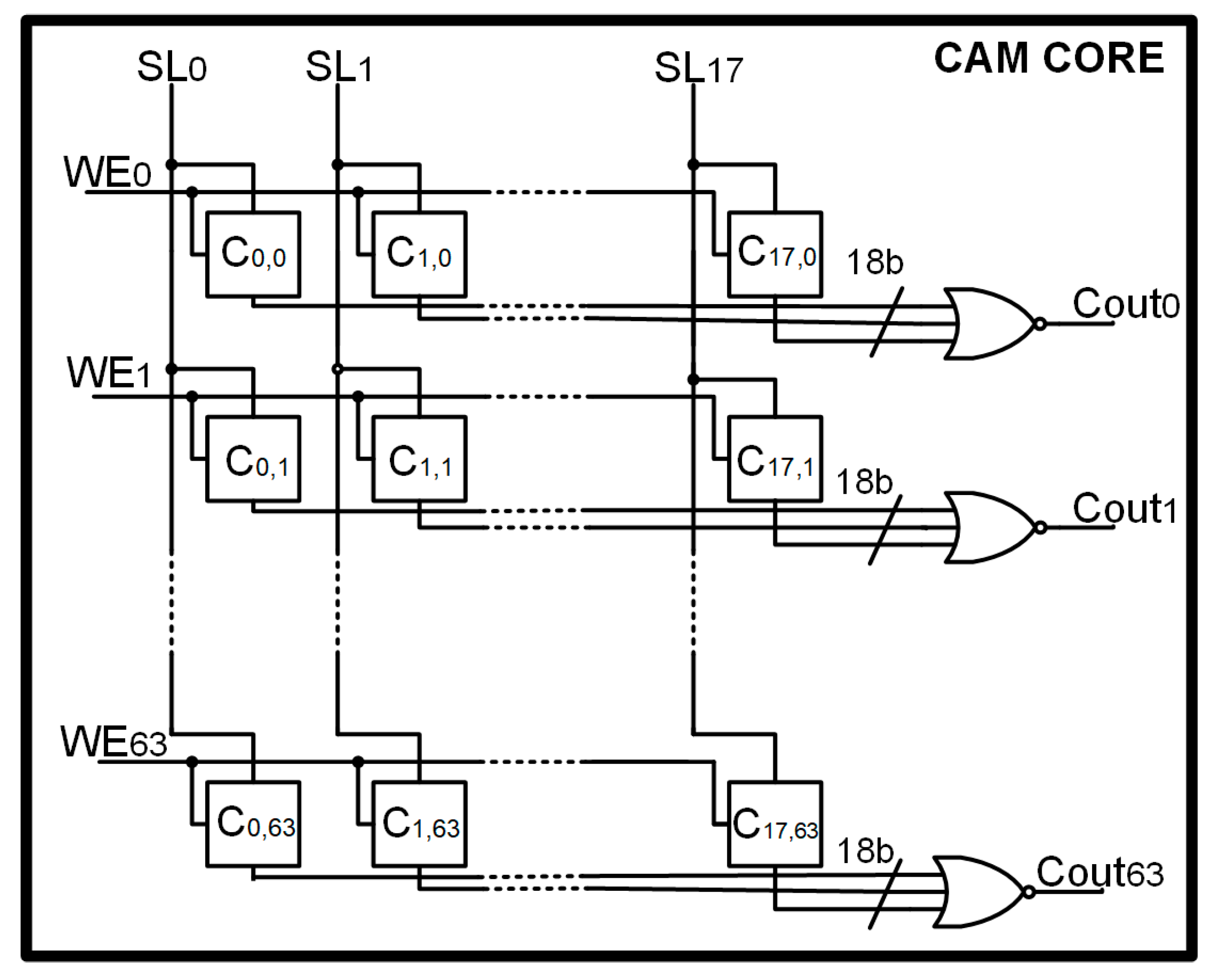
2.1. The CAM Core
The CAM-28CB Core stores 64 digital words (
j = 0–63) of 18-bit (
i = 0–17). Each one of the 18 single-bit cells in the
j-th row is connected to an NOR gate, whose output (Coutj) feeds the final encoder located in the Output Block.
Figure 2 illustrates a schematic view of the Core Block. Each cell located in the
j-th row shares the same WE signal, in order to store every bit of a digital word in the same clock cycle during the WRITE phase.
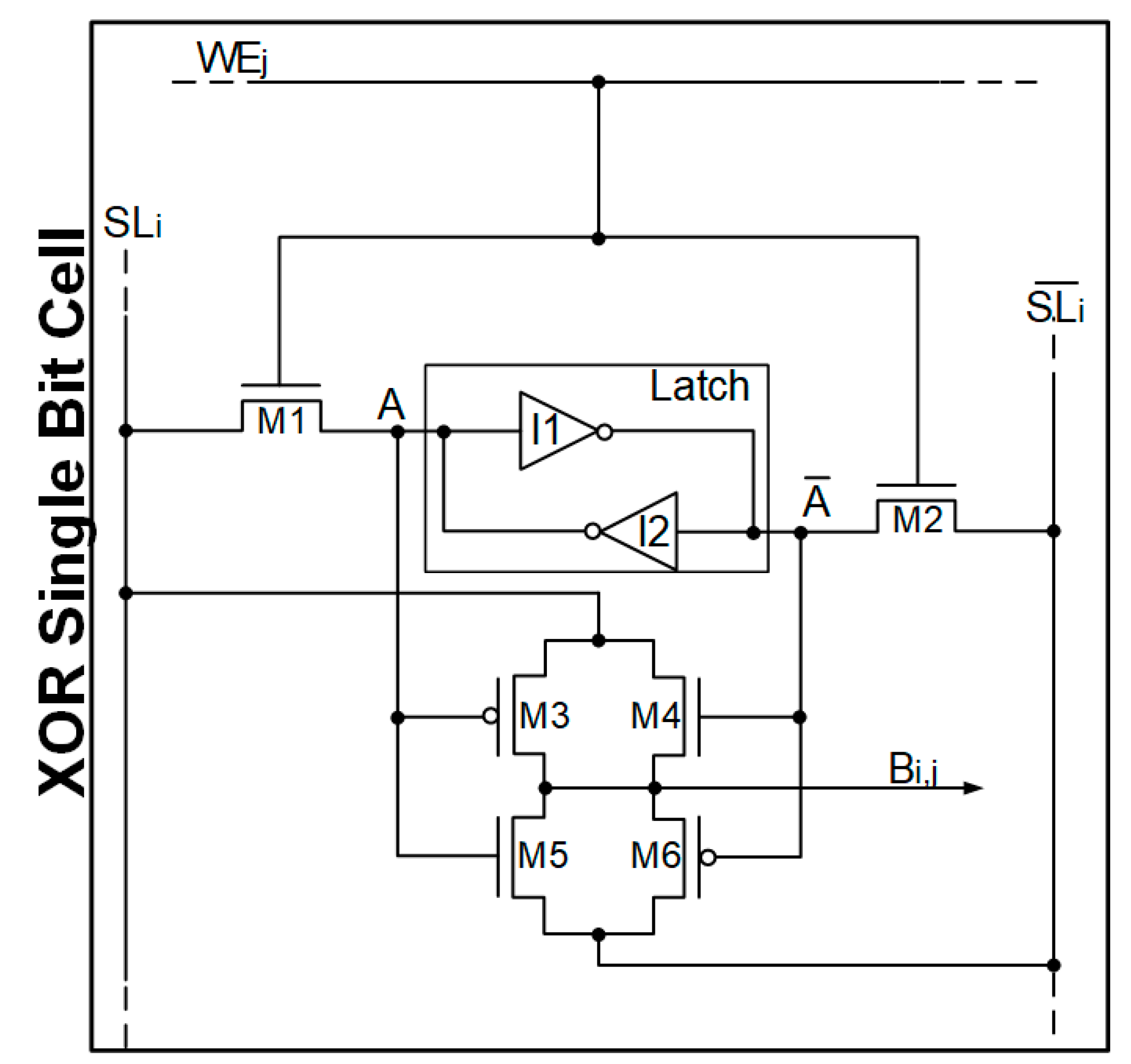
The single-bit cell is able to store a single bit, while, during the SEARCH phase, it performs an XOR logic operation. A schematic of the single-bit cell is shown in
Figure 3. It is composed of a latch (cross coupled inverters), which stores the bit, two Metal-Oxide-Semiconductor (MOS) transistors (M1 and M2) used as switches, and four MOS transistors (M3, M4, M5, and M6) performing the XOR operation between searched data (coming from the SL bus) and stored data.
As already stated, the CAM works in two different operating modes: WRITE and SEARCH.
Consider the case of a single-bit cell in the WRITE mode operation. The WRITE mode is set by the corresponding WEj signal. In this case, both M1 and M2 transistors operate as a switch connecting the i-th SL bit with the latch. In this way, data on the SLi are stored inside the cell Ci,j.
On the other hand, in SEARCH mode, M1 and M2 are open. MOS M3, M4, M5, and M6 perform an XOR operation between the data stored inside the i-th latch and the data on the SLi. Only in the case of a match between searched and stored data does the cell output bit Bij’s becomes logic low.
The 18 outputs of the j-th row feed an 18-bit NOR gate that only turns quickly if every Bij node is logic low, asserting that a complete data match occurred in that row.
2.2. Power Consumption Evaluation
Power consumption is one of the most important performance indicators for static memories. In this design, it is possible to achieve very low-power performances thanks to the full-custom design approach in the layout phase. The parasitic capacitances of each switching node are reduced compared to standard cell designs and minimized according to the stringent 28 nm layout rules.
The static power consumption is assumed to be negligible, since its contribution to the overall CAM power is in the order of a few pA/bit and for this reason, only the dynamic power consumption must be taken into account.
The dynamic power consumption can be divided into two main contributions: The power of the SL buffers and the power of logic (for every row) and latches (inside the single-bit cells).
The CAM dynamic power in write mode is given by the well-known Equation (1):
where
is the overall capacitance in write mode per single bit,
fCLK is the clock frequency, and
VDD is the supply voltage. The overall capacitance in WRITE mode is composed of the parallelity between the
CA,W capacitance (the equivalent capacitance to the ground of the A setting node in
Figure 3) and the SL parasitic capacitance (
CP,SL), as shown in Equation (2):
Specifically, in order to achieve a very low CP,SL, the SL is realized with a minimum width/minimum length metal 1 connection, which is evaluated at 0.46 fF by the parasitic extraction tool.
The
CA,W is, in turn, the equivalent capacitance of the A setting node, given by Equation (3):
where
CG,I1 is the I1 gate capacitance,
CD,I2 is the I2 output capacitance,
CG,M35 represents the input capacitance of both M3 and M5 transistors, and
CBij is the total capacitance on the XOR single-bit output node, described by Equation (4):
where
CG,NORj is the input capacitance of the following
j-th NOR gate in the same row,
CD,M35 represents the output capacitance of both M3 and M5 transistors, and
CD,M46 represents the output capacitance of both M4 and M6 transistors.
Moreover, the total capacitance in WRITE mode at node A also depends on the routing parasitics in both A and Bij nodes, and more specifically, on CP,LAYOUT A and CP,LAYOUT B. Unfortunately, it is not possible to avoid vias when designing these nodes because of the 28 nm stringent layout rules. In order to minimize the impact of parasitics, these nodes are designed to have the minimum number of vias and the minimum area of metal possible. In this way, it is possible to achieve a very low value for parasitic capacitance in these nodes (0.21 and 1.05 fF for CP,LAYOUT A and CP,LAYOUT B respectively).
On the other hand, the dynamic power in search mode (more important, since this is the usual operating mode of the CAM) is given by Equation (5):
where
is the overall capacitance per bit given by Equation (6):
Table 1 shows some of the most important parasitic routing and small-signal capacitance values of the MOS transistor in both search and write mode. All transistors in the design have a minimum size (W/L = 100 nm/30 nm) to minimize the total gate capacitance
CG (mainly, the overlap capacitance given by Cox∙W∙L) and area occupancy.
Table 1 demonstrates that the transistor MOS small signal capacitance is typically negligible in 28 nm CMOS-Bulk technology in terms of the effects on the power and speed. On the other hand, this also forces dedicated layout solutions able to reduce both the
CP,LAYOUT B and
CP,LAYOUT SL term as much as possible in SEARCH mode, since they are dominant and increase the power.
From post-layout simulations, the falling time for the
ij-th cell output node (Bij) is 82.8 ps. This results in a 0.012 V/ps output slew-rate that will need an average switching current of approximately 8.37 µA, provided by the SL buffers. From Equation (5), assuming a 100 MHz clock frequency and 0.85 V supply voltage, applying capacitance values from
Table 1, PWSEARCH is 75 nW per bit.
3. Experimental Results
A chip photo of the integrated CAM-28CB device is shown in
Figure 4.
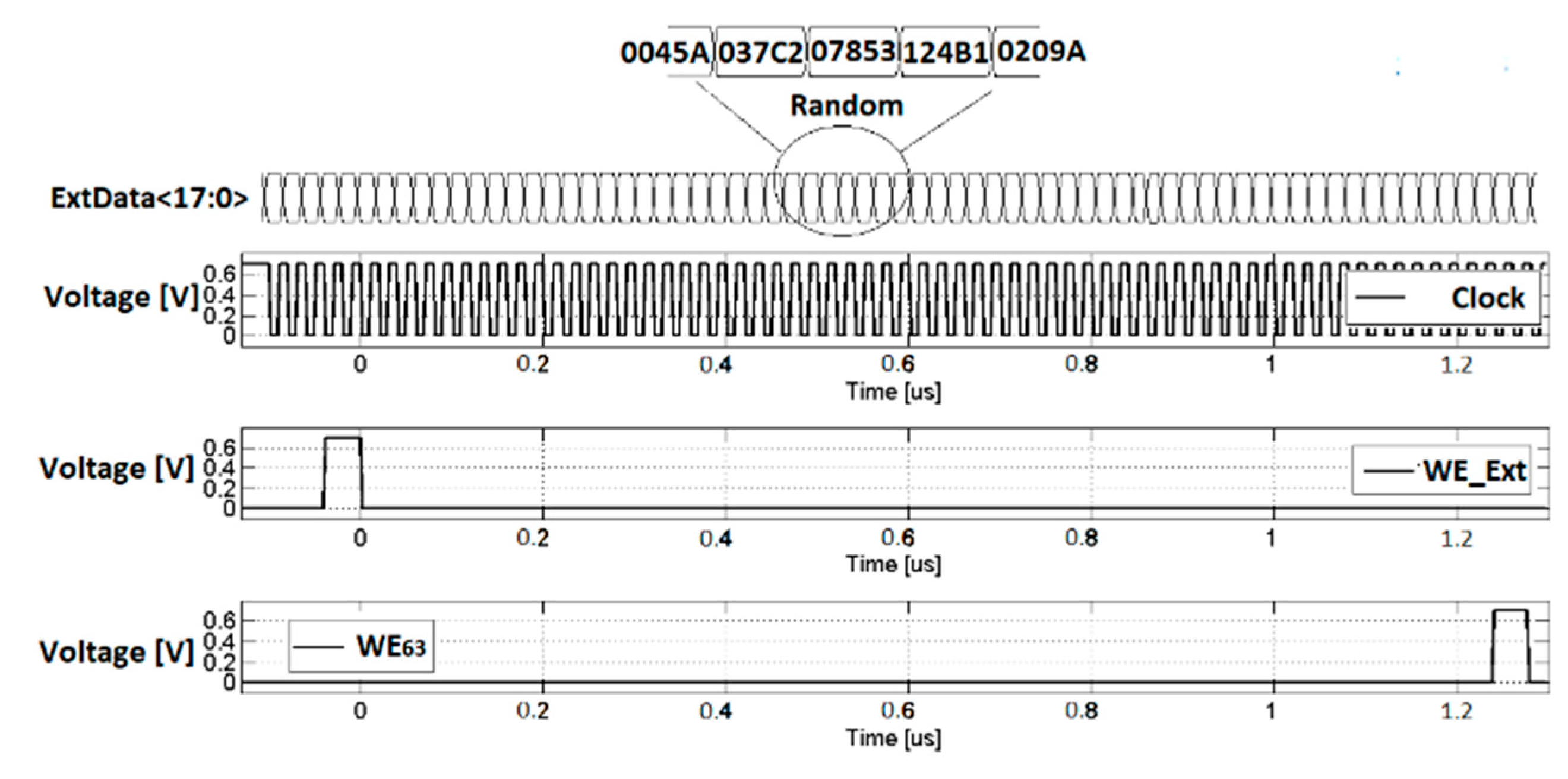
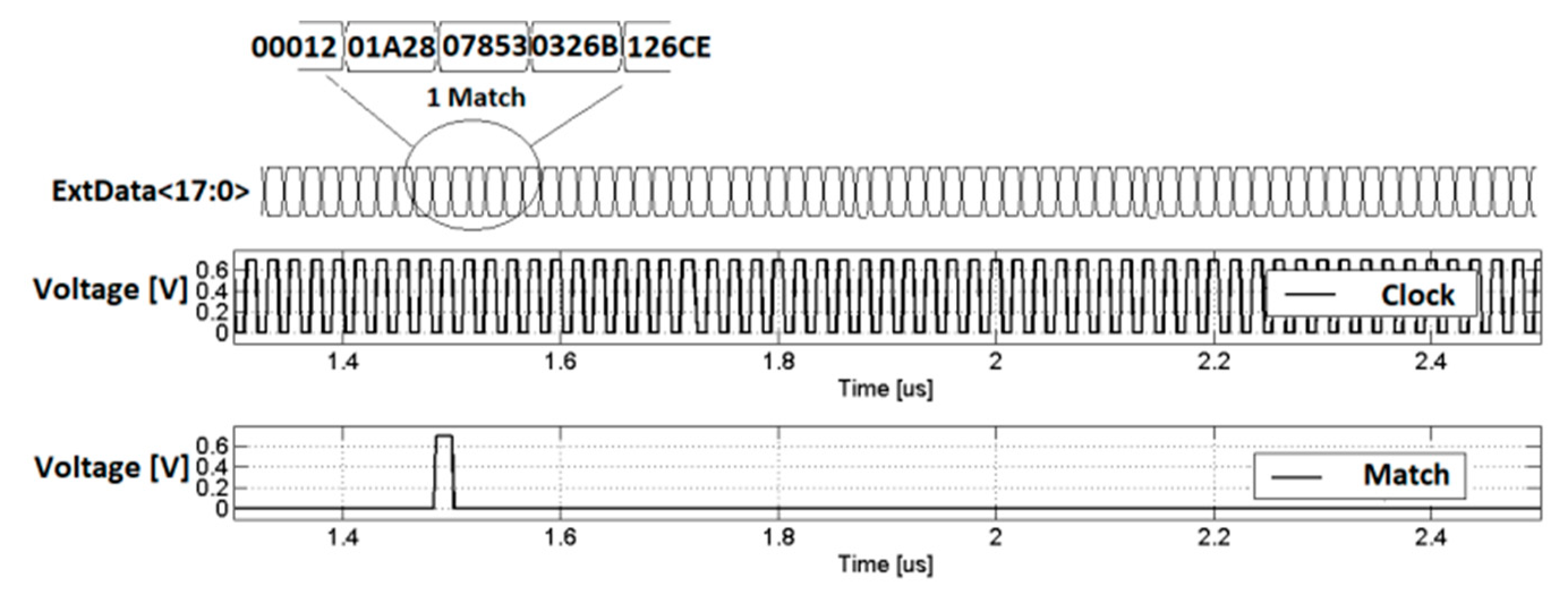
For testing purposes, the memory is filled with a random 64 data pattern (WRITE Mode,
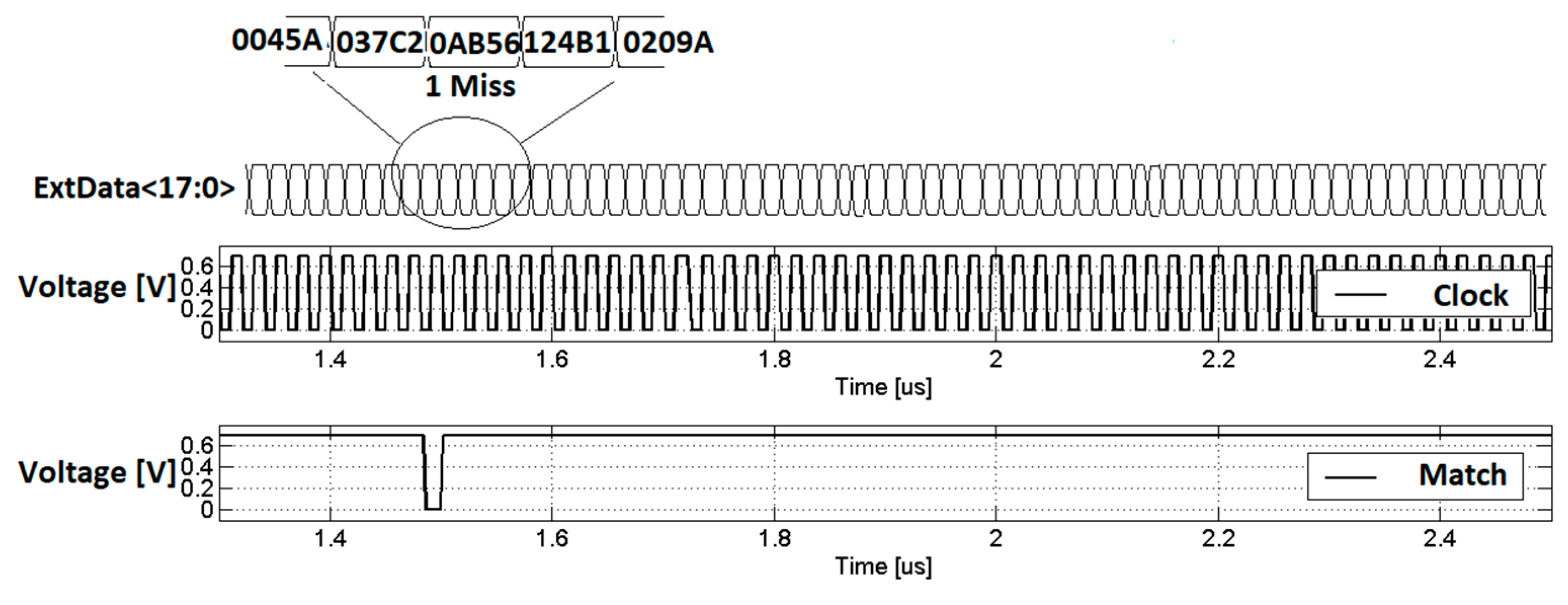
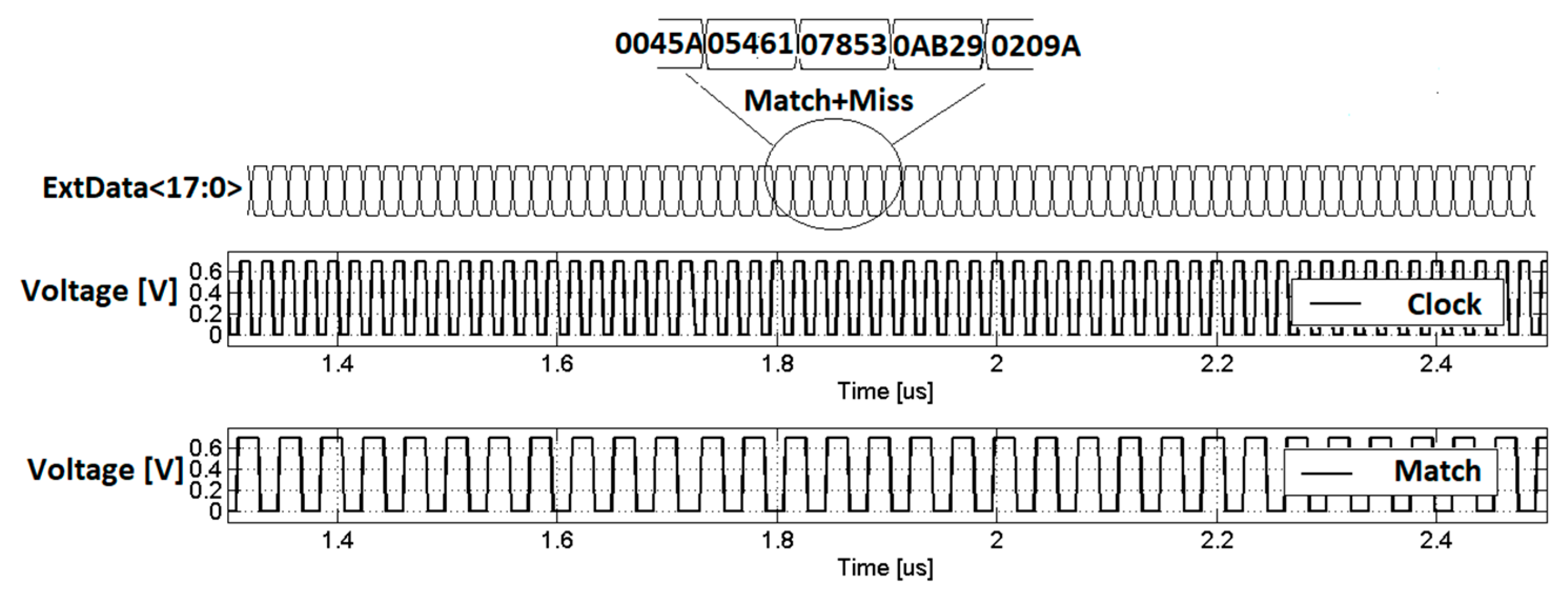
Figure 5). Afterwards the SEARCH mode runs with one pattern for four different input patterns, repeated cyclically, in order to test several minutes of device activity. These patterns are used to measure CAM performances in terms of the power consumption and speed. The four patterns are as follows:
The first three patterns are limited to only 128 different searched data values, periodically repeated.
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show the time diagrams, taken from a Logic Analyzer (LA), of some of the most important input and output signals. A specific Pattern Generator module, embedded in the LA, synchronizes the input signal with the CAM clock and outputs.
The last pattern is a fully Random Pattern generated by a Field Programmable Gate Array (FPGA). In this case, a dedicated algorithm, which exploits a Fibonacci Linear-Feedback Shift-Register (LFSR), is used to randomly generate every possible data value from 1 to 218−1. In this way, only 64 random matches occur every 218 clock cycles, emulating CAM real-life utilization.
After the WRITE mode operation is concluded, the ExtData bus starts to switch as a function of the selected pattern. The input (WE_Ext) and output (WE
63) signals of the SIPO register in write mode are also shown in
Figure 5, in order to assert the start and end of the WRITE phase. The clock frequency in this case is set to 100 MHz. The power consumption of the prototype has been measured, cyclically repeating these patterns and also spreading the supply voltage and clock frequency. The power (
) is mainly dynamic and can be in first approximation expressed as a function of the total number of bits of the memory (
Nbit,i), switching at frequency
fCLK,i (usually different bit switches at different frequencies) and the equivalent capacitance (
Cbit) per bit, according to Equation (7):
depends on the chosen pattern. In the simplest case (MIN, MAX, and Medium pattern), and meaning that the MSB switches every clock cycle, the second MSB switches at half the clock frequency, and so on. In this way, Cbit can be easily calculated and is equal to 1.914 fF, in perfect agreement with the simulated post-layout net-list power.
For a random pattern, it is not possible to determine the
fCLK,i term, since every
i-th bit randomly switches. For this reason, it is necessary to exploit Equation (8):
where
Nbit,eq is the equivalent number of bits switching at clock frequency (
fCLK) and is equal to 378.15, which is a much lower value than the overall number of bits (1152), as expected. The
vs.
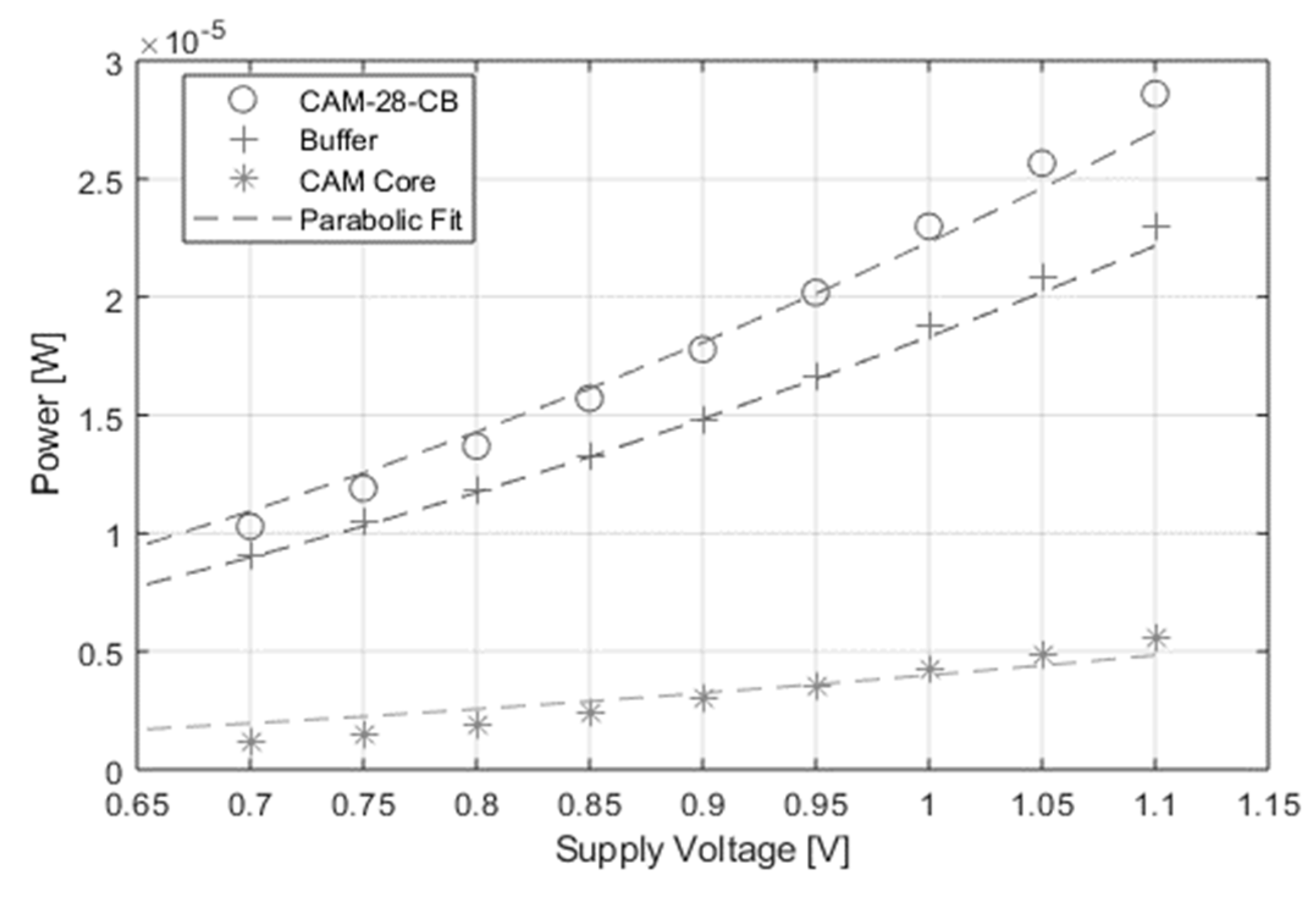
VDD at a 100 MHz clock frequency has been plotted in
Figure 9, fitting with the parabolic behavior vs.
VDD presented in Equation (7).
Figure 10 shows the
vs. clock frequency at a 0.85 V supply voltage and compares the measurement results with the linear fitting vs.
fCLK derived from Equation (4). In both
Figure 9 and
Figure 10, the power has been divided into buffer and core power consumption, in order to better highlight all the contributions to the overall power consumption of the prototype.
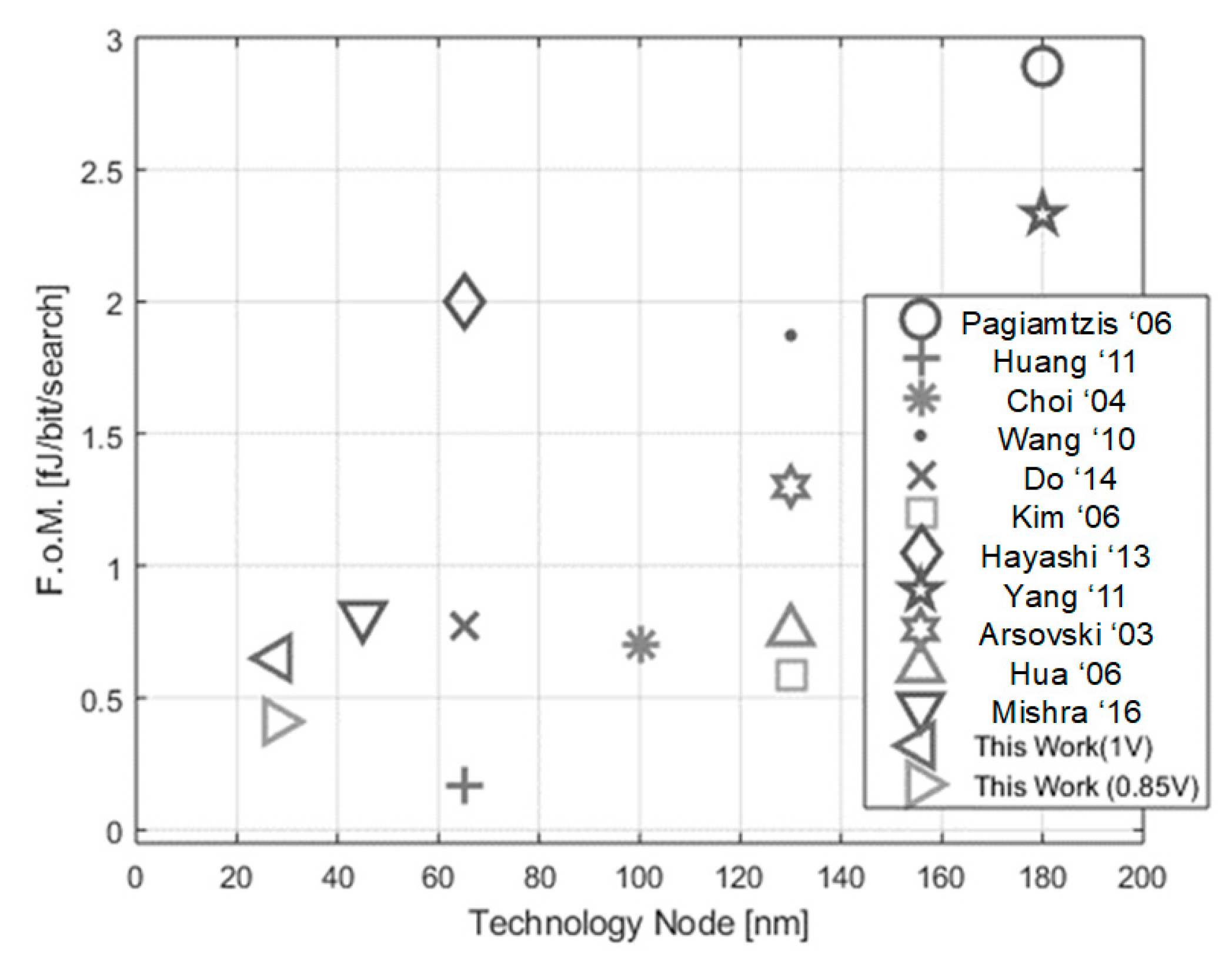
Finally, the overall performance of this memory prototype has been compared with the state-of-the-art of the associative memories available in the literature. More specifically,
Table 2 reports the most important performance and
Figure 11 shows the Figure-of-Merit (F.o.M.) vs. CMOS Technology node of this prototype and the literature [
2,
3,
9,
11,
12,
13,
15,
16,
17,
18,
19]. The adopted F.o.M. is given by Equation (9):
where
PWCAM is the total power consumption expressed in Watt (W),
fCLK is the clock frequency (100 MHz), and SIZE is the CAM memory size (1.152 kb).
Thanks to the 28 nm CMOS-Bulk node and the customized layout solutions that minimize the parasitic capacitance contribution in the XOR single-bit cell, this work has achieved one of the lowest F.o.M. in the literature. Moreover, it reaches a factor of 3 in size reduction compared to the 65 nm technology node [
15]. On the other hand, the same factor is not reached in the power consumption as a consequence of the fact that the channel length (on which the device size depends) scales faster than the parasitic capacitance (on which the power consumption depends, according to Equation (7)) with the technology node [
16]. Moreover, the purpose of the CAM-28-CB is to conduct power consumption reduction through the single-bit XOR cells’ architecture and parasitic capacitance minimization in a strongly downscaled technology such as CMOS 28 nm, and for this reason, the proposed CAM architecture does not implement any advanced algorithm for power saving, such as pipeline or hierarchical SL. At the same time, the CAM-28-CB performances are comparable and even improved compared to other nanoscale technologies.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}