
Efficient Binarized Convolutional Layers for Visual Inspection Applications on Resource-Limited FPGAs and ASICs


Abstract
:1. Introduction
Related Work
2. Background
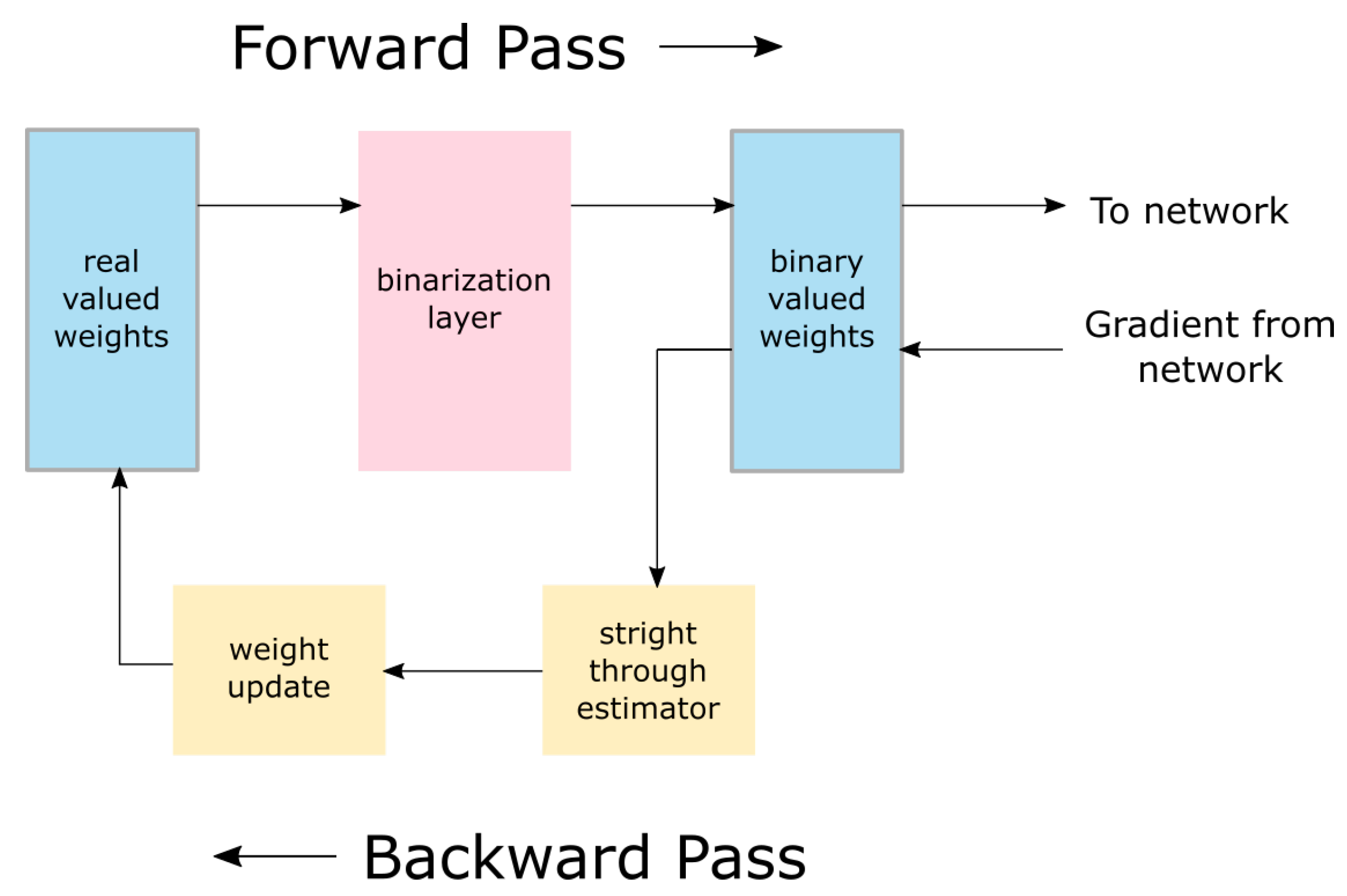
2.1. Binarized Neural Networks
2.1.1. Binarization of Weights
2.1.2. Binarization of Activations
2.1.3. Performance and Improvements
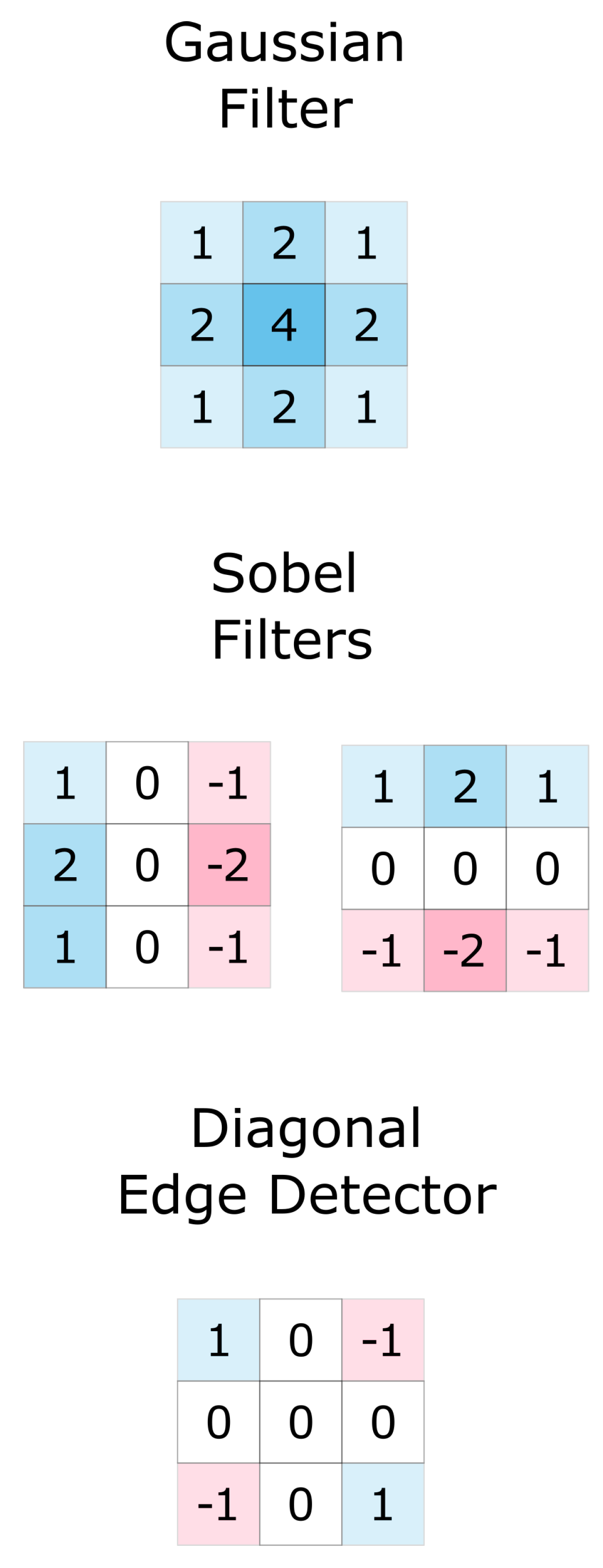
2.2. Jet Features
2.2.1. Definition of Jet Features
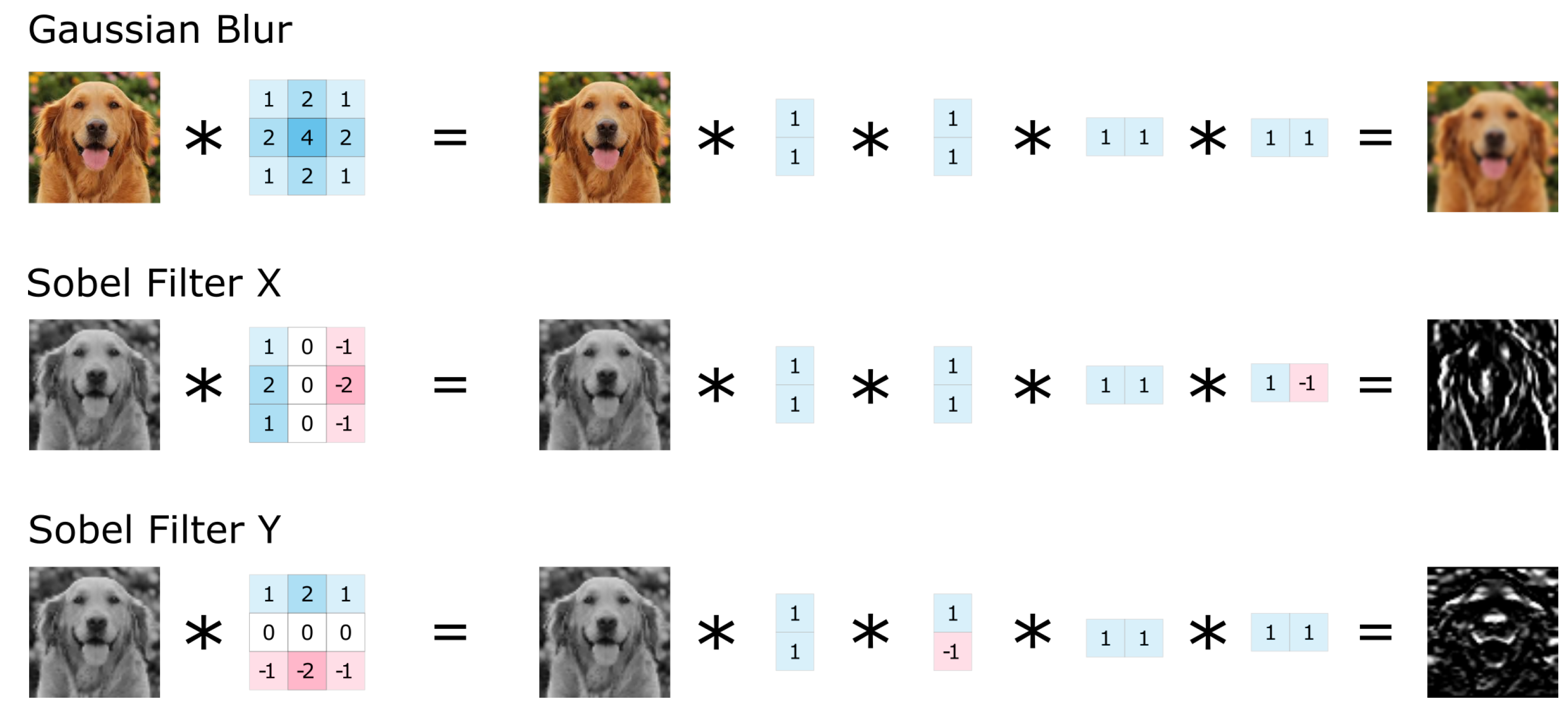
2.2.2. Efficient Calculation
2.2.3. Multiscale Local Jets
2.2.4. The ECO Jet Features Algorithm
3. Neural Jet Features
3.1. Constrained Neural Jet Features
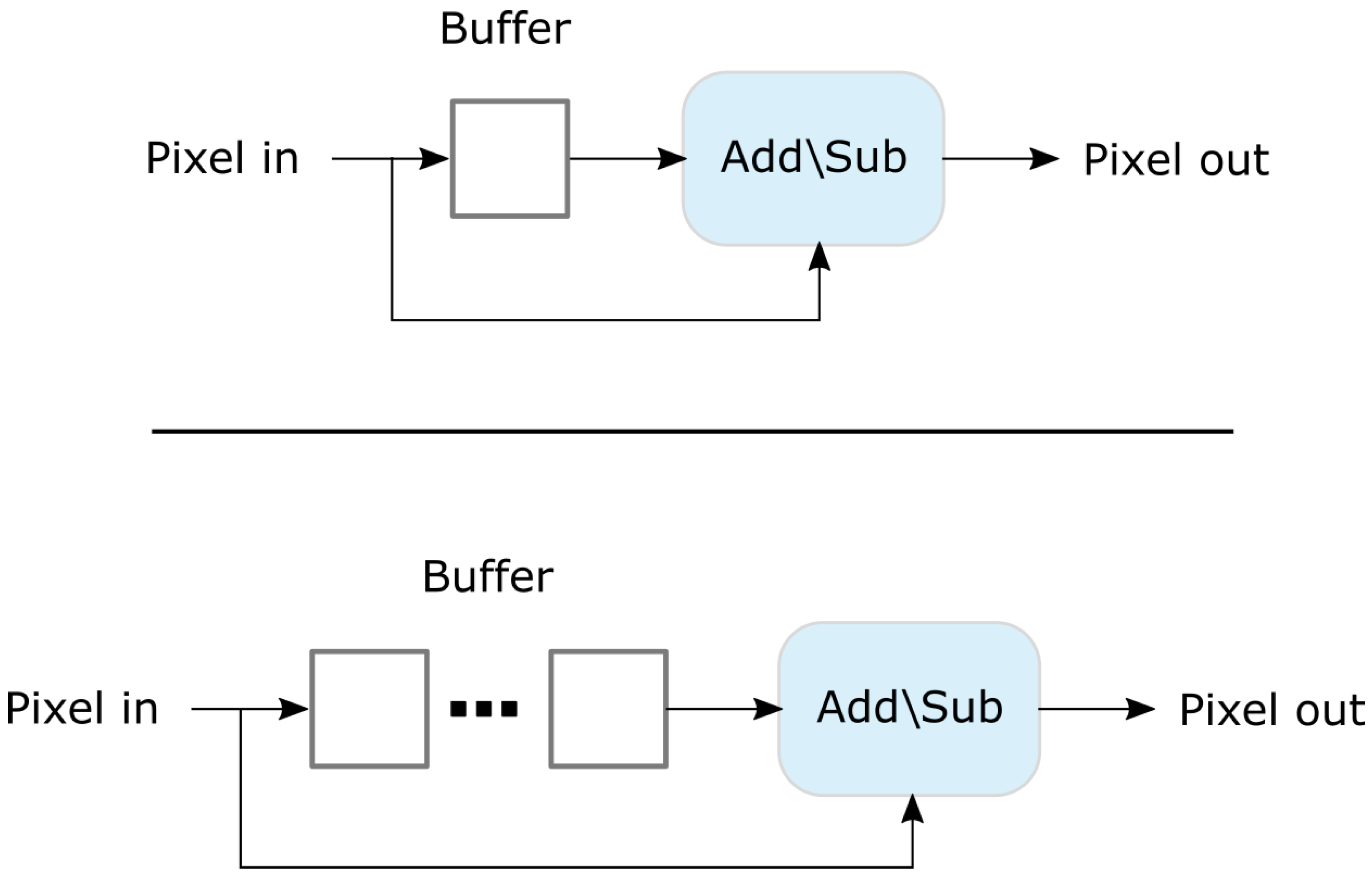
3.2. Computational Efficiency
4. Results
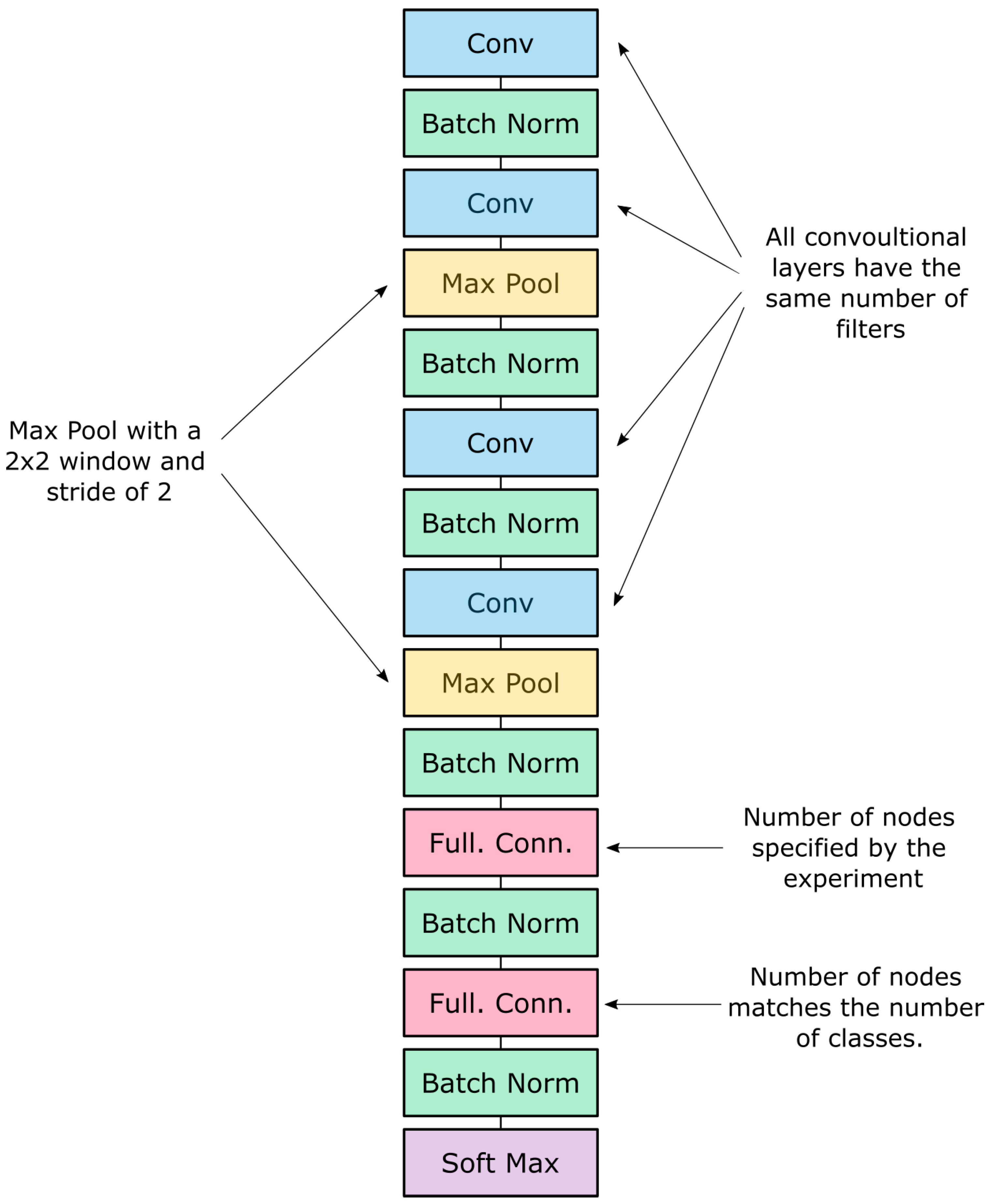
4.1. Model Architecture
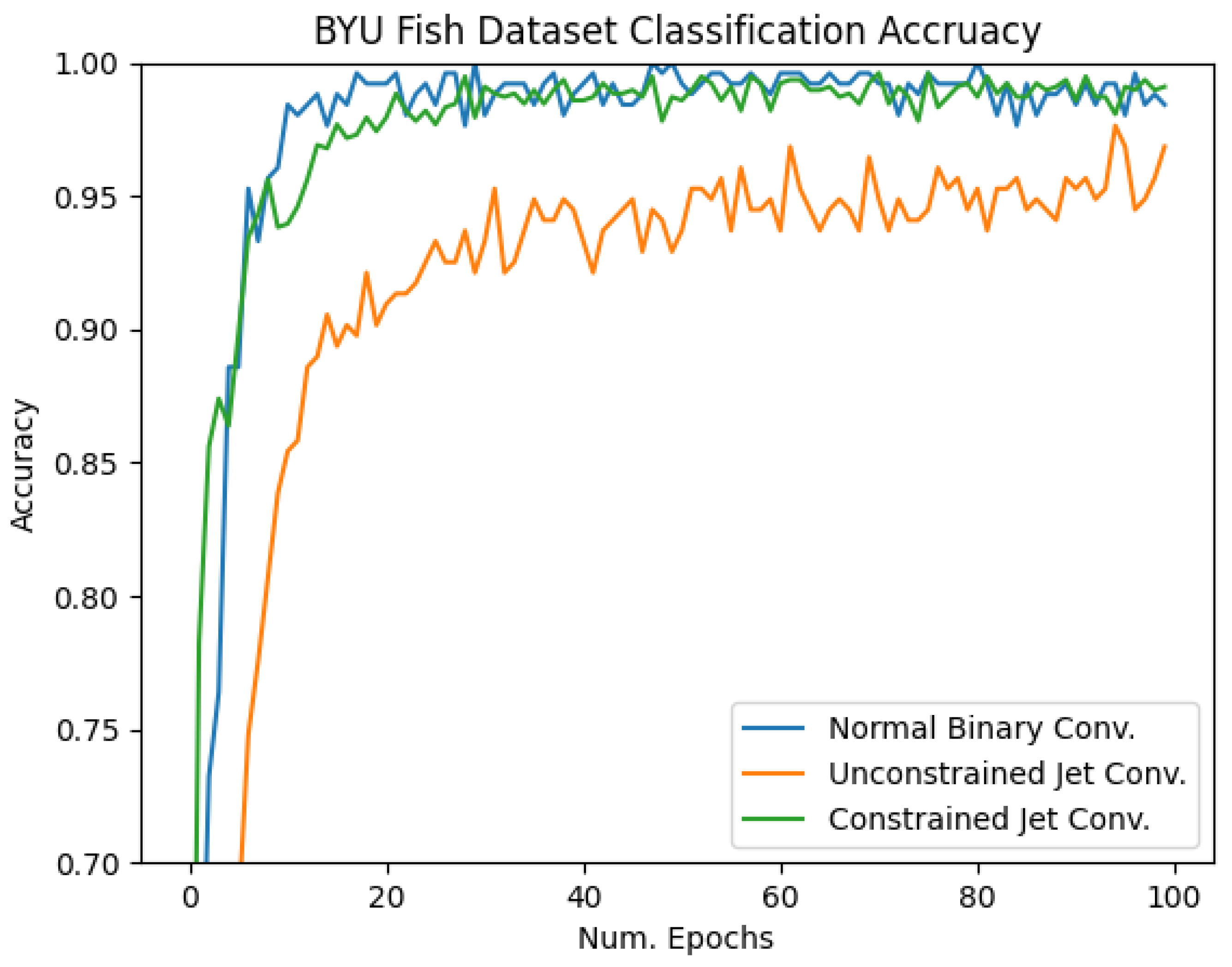
4.2. BYU Fish Dataset
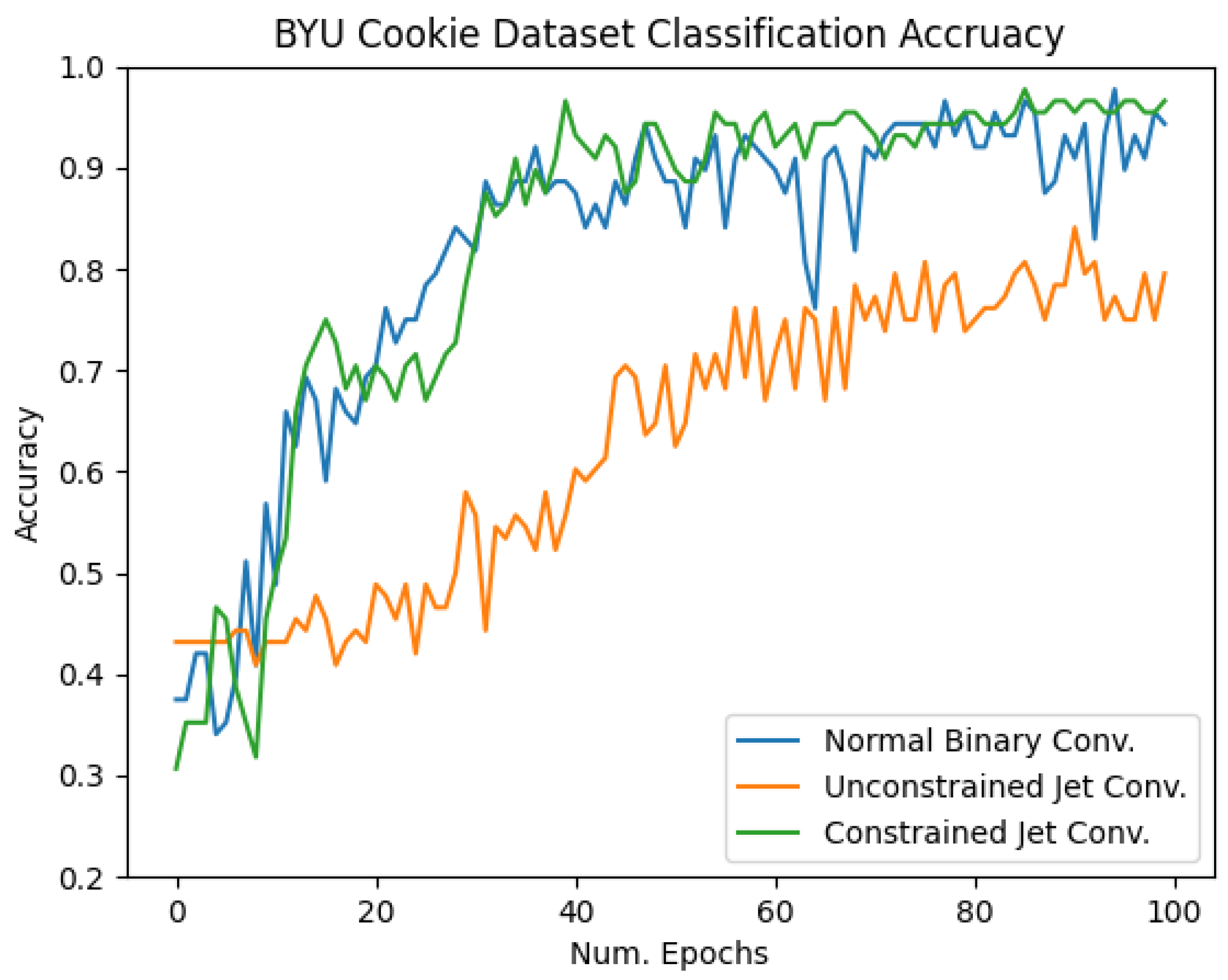
4.3. BYU Cookie Dataset
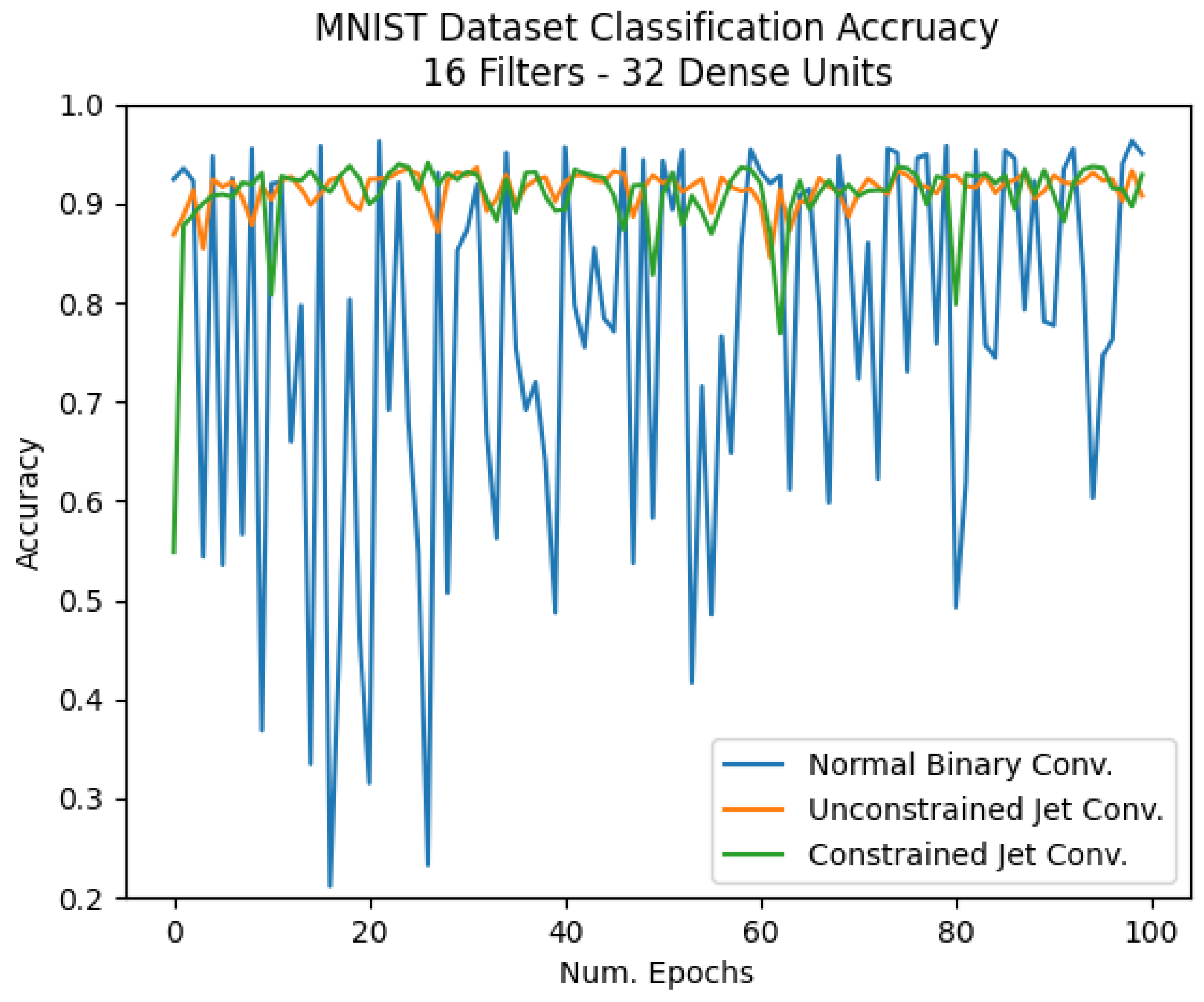
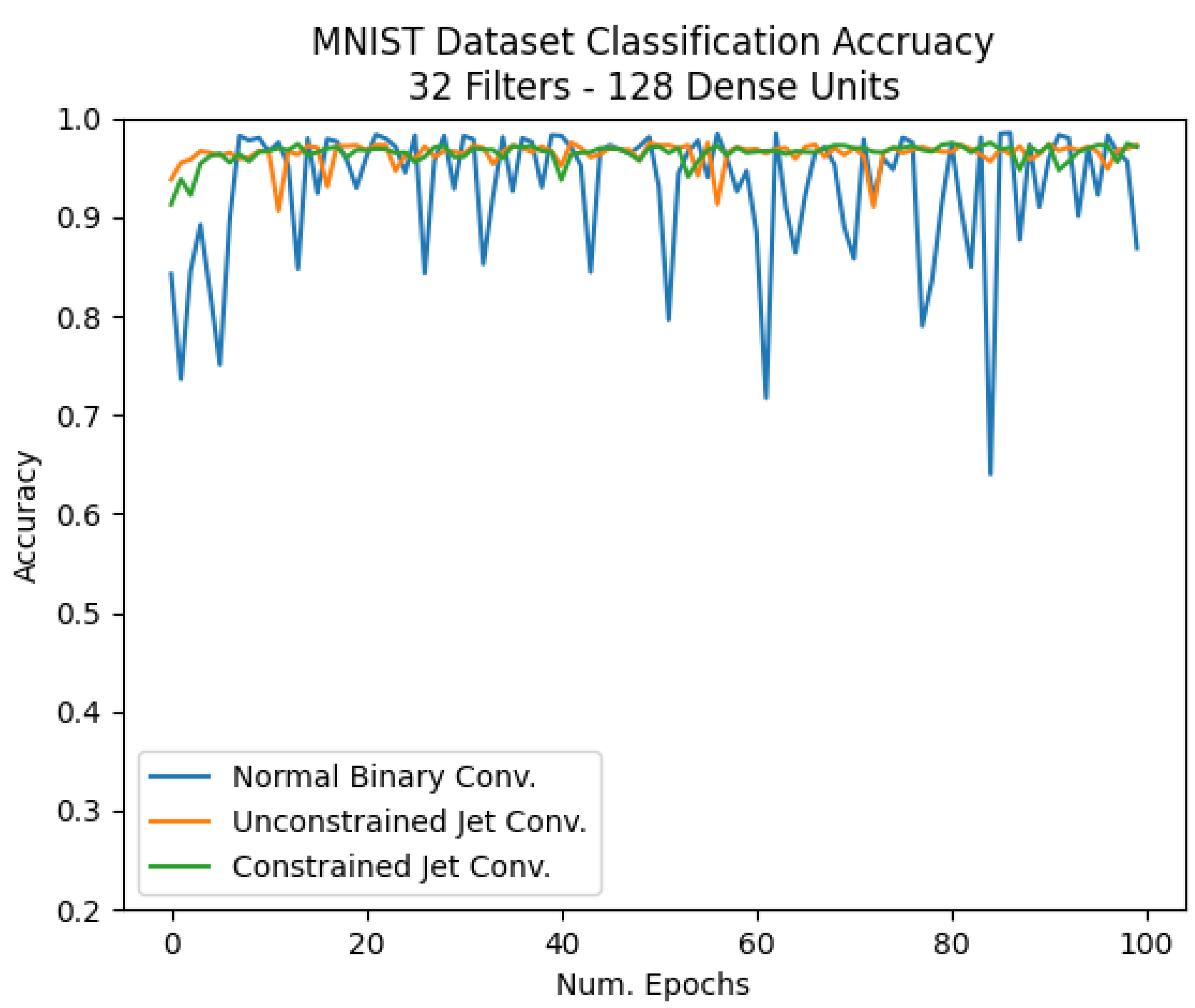
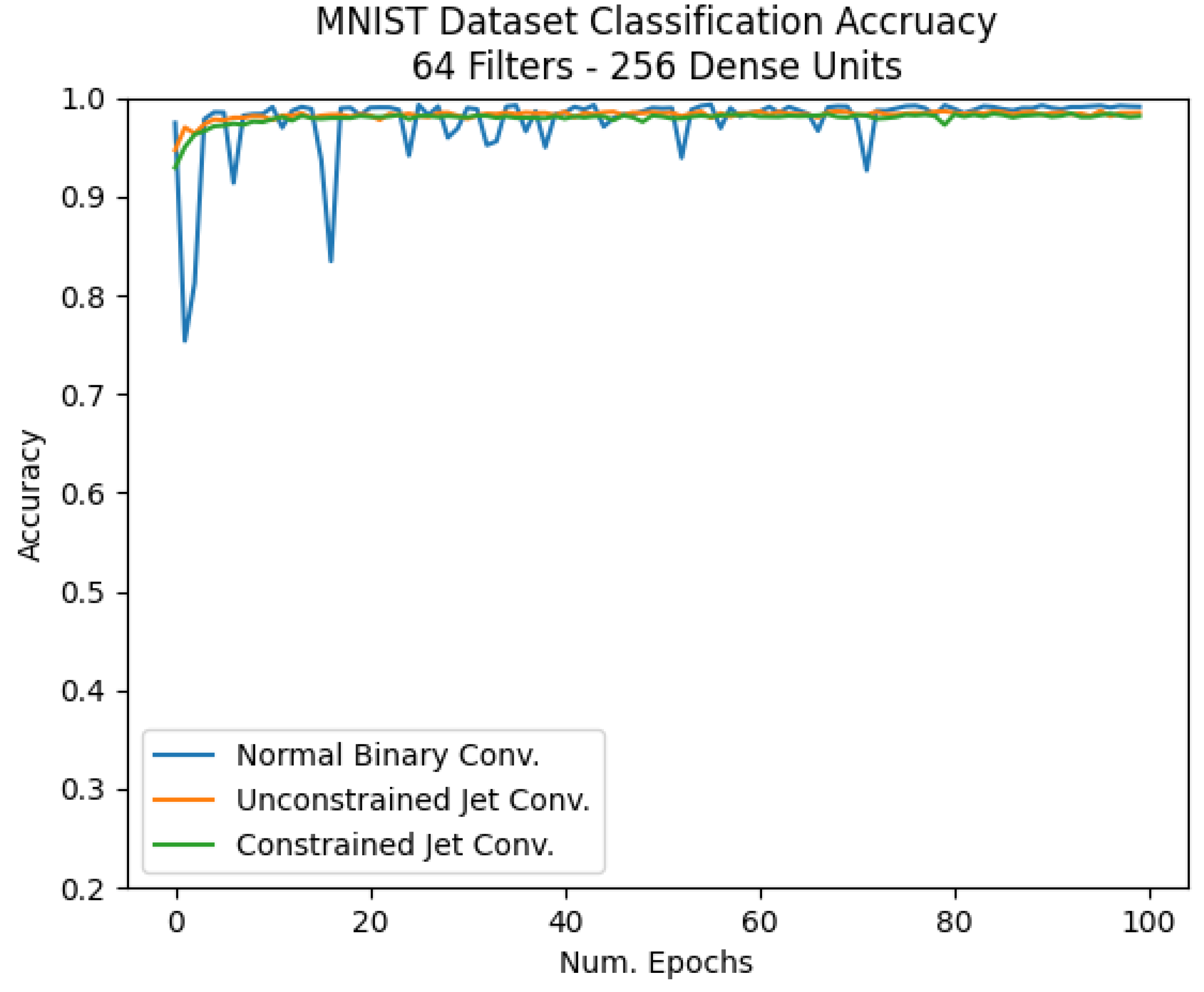
4.4. MNIST Dataset
4.5. Comparison and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Hanson, S.J.; Pratt, L. Comparing Biases for Minimal Network Construction with Back-propagation. In Advances in Neural Information Processing Systems 1; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1989; pp. 177–185. [Google Scholar]
- Cun, Y.L.; Denker, J.S.; Solla, S.A. Optimal Brain Damage. In Advances in Neural Information Processing Systems 2; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1990; pp. 598–605. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Network with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. 2020. Available online: https://arxiv.org/abs/1911.11907 (accessed on 17 June 2021).
- Courbariaux, M.; Bengio, Y. BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. IJCV 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Simons, T.; Lee, D.J. A Review of Binarized Neural Networks. Electronics 2019, 8, 661. [Google Scholar] [CrossRef] [Green Version]
- Qasaimeh, M.; Denolf, K.; Lo, J.; Vissers, K.; Zambreno, J.; Jones, P.H. Comparing Energy Efficiency of CPU, GPU and FPGA Implementations for Vision Kernels. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019; pp. 1–8. [Google Scholar]
- Simons, T.; Lee, D.J. Jet features: Hardware-Friendly, Learned Convolutional Kernels for High-Speed Image Classification. Electronics 2019, 8, 588. [Google Scholar] [CrossRef] [Green Version]
- Lillywhite, K.; Tippetts, B.; Lee, D.J. Self-tuned Evolution-COnstructed features for general object recognition. Pattern Recognit. 2012, 45, 241–251. [Google Scholar] [CrossRef]
- Bulat, A.; Tzimiropoulos, G. Binarized Convolutional Landmark Localizers for Human Pose Estimation and Face Alignment with Limited Resources. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3726–3734. [Google Scholar]
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. 2013. Available online: https://arxiv.org/abs/1308.3432 (accessed on 17 June 2021).
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 525–542. [Google Scholar]
- Zhou, S.; Ni, Z.; Zhou, X.; Wen, H.; Wu, Y.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Lin, X.; Zhao, C.; Pan, W. Towards Accurate Binary Convolutional Neural Network. NIPS. 2017. Available online: https://arxiv.org/abs/1711.11294 (accessed on 17 June 2021).
- Zhao, R.; Song, W.; Zhang, W.; Xing, T.; Lin, J.H.; Srivastava, M.; Gupta, R.; Zhang, Z. Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays—FPGA ’17; ACM Press: New York, NY, USA, 2017; pp. 15–24. [Google Scholar]
- Guo, P.; Ma, H.; Chen, R.; Li, P.; Xie, S.; Wang, D. FBNA: A Fully Binarized Neural Network Accelerator. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 51–513. [Google Scholar]
- Fraser, N.J.; Umuroglu, Y.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. Scaling Binarized Neural Networks on Reconfigurable Logic. In Proceedings of the 8th Workshop and 6th Workshop on Parallel Programming and Run-Time Management Techniques for Many-core Architectures and Design Tools and Architectures for Multicore Embedded Computing Platforms—PARMA-DITAM ’17; ACM Press: New York, NY, USA, 2017; pp. 25–30. [Google Scholar]
- Ghasemzadeh, M.; Samragh, M.; Koushanfar, F. ReBNet: Residual Binarized Neural Network. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; pp. 57–64. [Google Scholar]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays—FPGA ’17; ACM Press: New York, NY, USA, 2017; pp. 65–74. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Florack, L.; Ter Haar Romeny, B.; Viergever, M.; Koenderink, J. The Gaussian Scale-space Paradigm and the Multiscale Local Jet. Int. J. Comput. Vision 1996, 18, 61–75. [Google Scholar] [CrossRef]
- Lillholm, M.; Pedersen, K.S. Jet based feature classification. In Proceedings of the 17th International Conference on Pattern Recognition ICPR 2004, Cambridge, UK, 26 August 2004; Volume 2, pp. 787–790. [Google Scholar]
- Larsen, A.B.L.; Darkner, S.; Dahl, A.L.; Pedersen, K.S. Jet-Based Local Image Descriptors. In Computer Vision—ECCV 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 638–650. [Google Scholar]
- Manzanera, A. Local jet feature Space Framework for Image Processing and Representation. In Proceedings of the 2011 Seventh International Conference on Signal Image Technology Internet-Based Systems, Dijon, France, 28 November–1 December 2011; pp. 261–268. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Conv. Filters | Fully Connected Units |
|---|---|---|
| BYU Fish | 8 | 16 |
| BYU Cookie | 8 | 8 |
| MNIST | 16 | 32 |
| MNIST | 32 | 128 |
| MNIST | 64 | 256 |
| Dataset | Normal Binary Conv. | Unconstrained Jet Conv. | Constrained Jet Conv. |
|---|---|---|---|
| BYU Fish | 99.8% | 95% | 99.8% |
| BYU Cookie | 95% | 77.5% | 96% |
| MNIST 16 Filters | 93% | 92% | 92% |
| MNIST 32 Filters | 92% | 97% | 97% |
| MNIST 64 filters | 99% | 98% | 98% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simons, T.; Lee, D.-J. Efficient Binarized Convolutional Layers for Visual Inspection Applications on Resource-Limited FPGAs and ASICs. Electronics 2021, 10, 1511. https://doi.org/10.3390/electronics10131511
Simons T, Lee D-J. Efficient Binarized Convolutional Layers for Visual Inspection Applications on Resource-Limited FPGAs and ASICs. Electronics. 2021; 10(13):1511. https://doi.org/10.3390/electronics10131511
Chicago/Turabian StyleSimons, Taylor, and Dah-Jye Lee. 2021. "Efficient Binarized Convolutional Layers for Visual Inspection Applications on Resource-Limited FPGAs and ASICs" Electronics 10, no. 13: 1511. https://doi.org/10.3390/electronics10131511
APA StyleSimons, T., & Lee, D. -J. (2021). Efficient Binarized Convolutional Layers for Visual Inspection Applications on Resource-Limited FPGAs and ASICs. Electronics, 10(13), 1511. https://doi.org/10.3390/electronics10131511