
NUMA-Aware DGEMM Based on 64-Bit ARMv8 Multicore Processors Architecture


Abstract
:1. Introduction
- After constructing a comprehensive empirical characterization design on Kunpeng920 about how NUMA impact DGEMM, we discover the scalability issues and settle the problem from the root;
- We propose a NUMA-aware DGEMM method and design details to reduce cross-die cross-chip memory access caused by NUMA architecture. NUMA-aware DGEMM is a two-level parallelized multi-solver design based on NUMA, used to accelerate DGEMM in 64-bit ARMv8 multicore processor architectures;
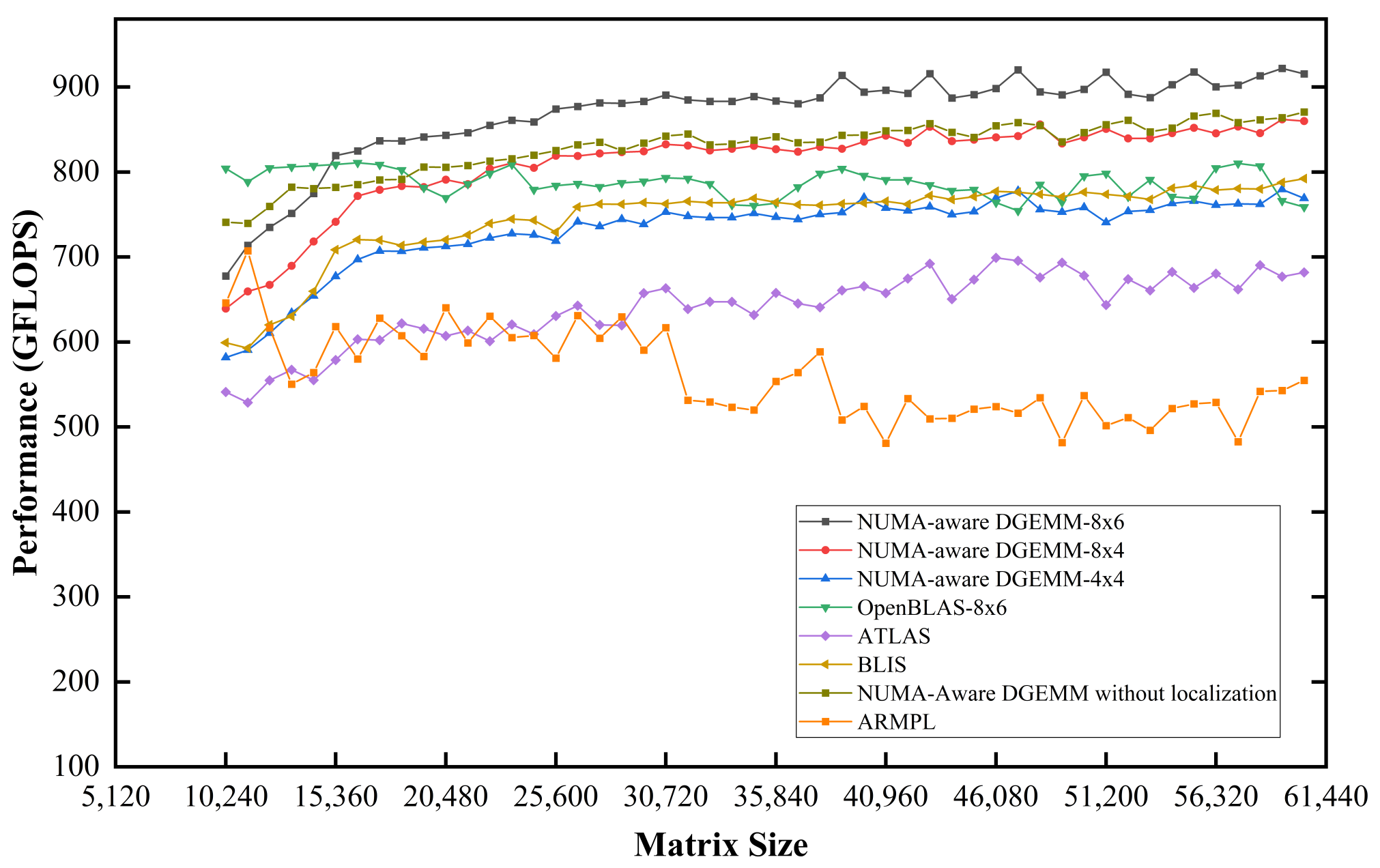
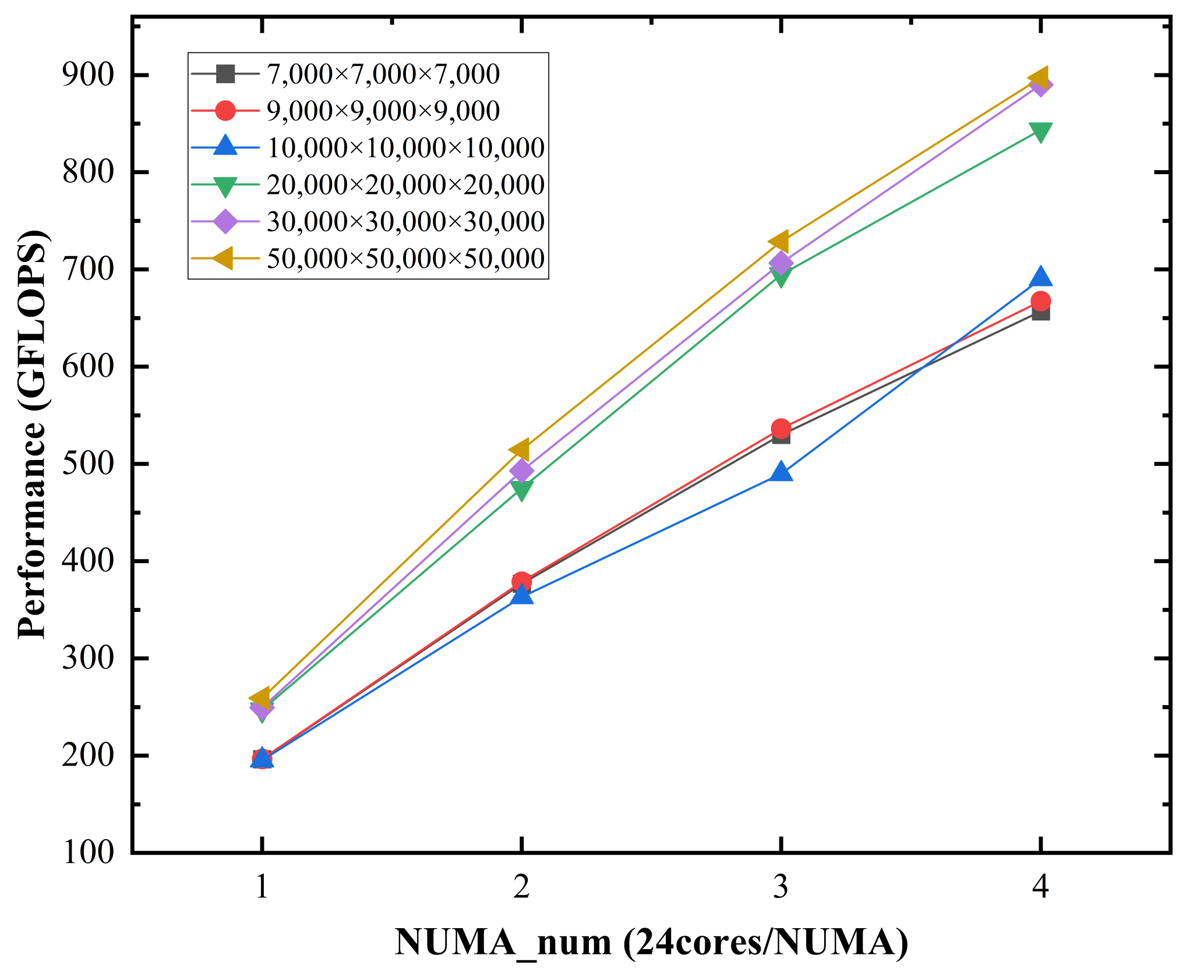
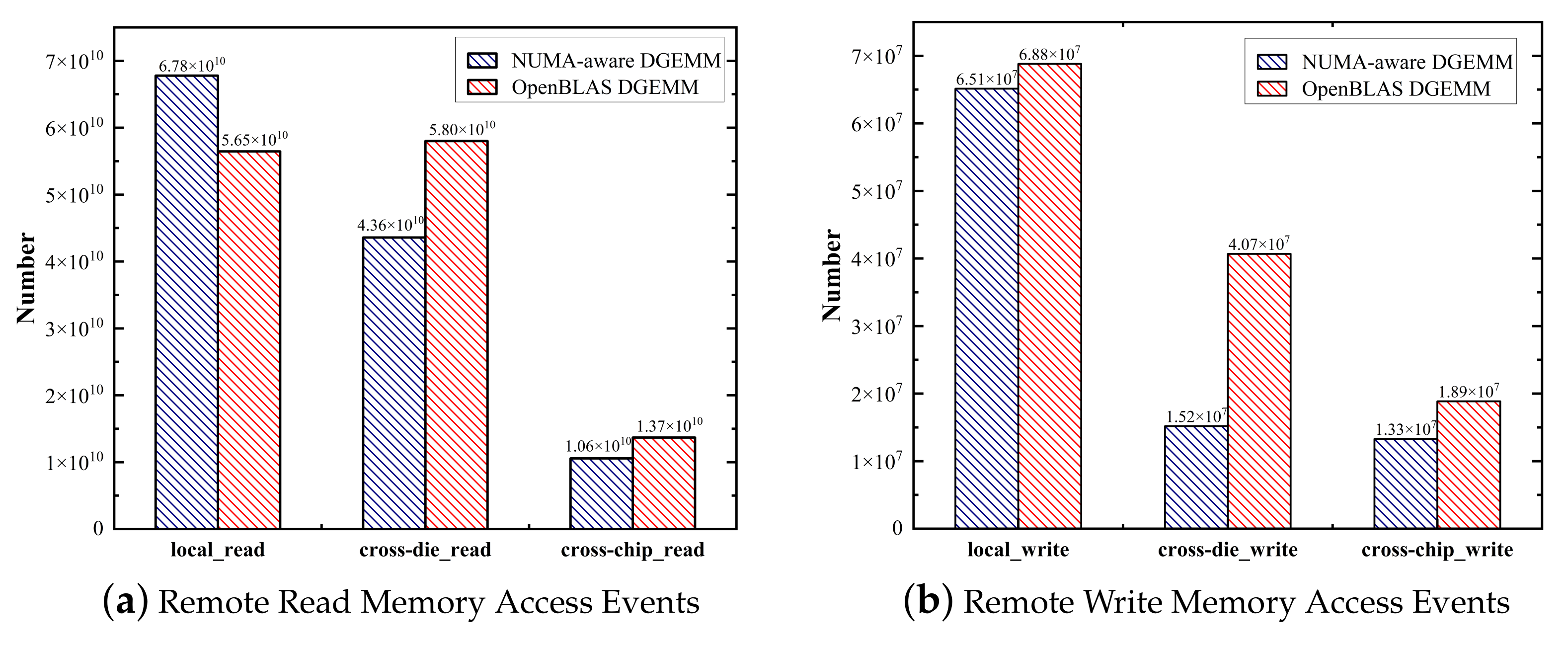
- We have implemented this method on dual-socket servers with 48-core processors. The results show that DGEMM performance is improved by 17.1% on average, with the highest rate being 21.9%. Furthermore, the scalability speed-up ratio is increased by 71% if expanding from one NUMA node to four NUMA nodes. The cross-die and cross-chip write operations are reduced by 62.6% and 29.4%, respectively. At the same time, the cross-die and cross-chip read operations are reduced by 24.8% and 22.7%, respectively.
2. Background
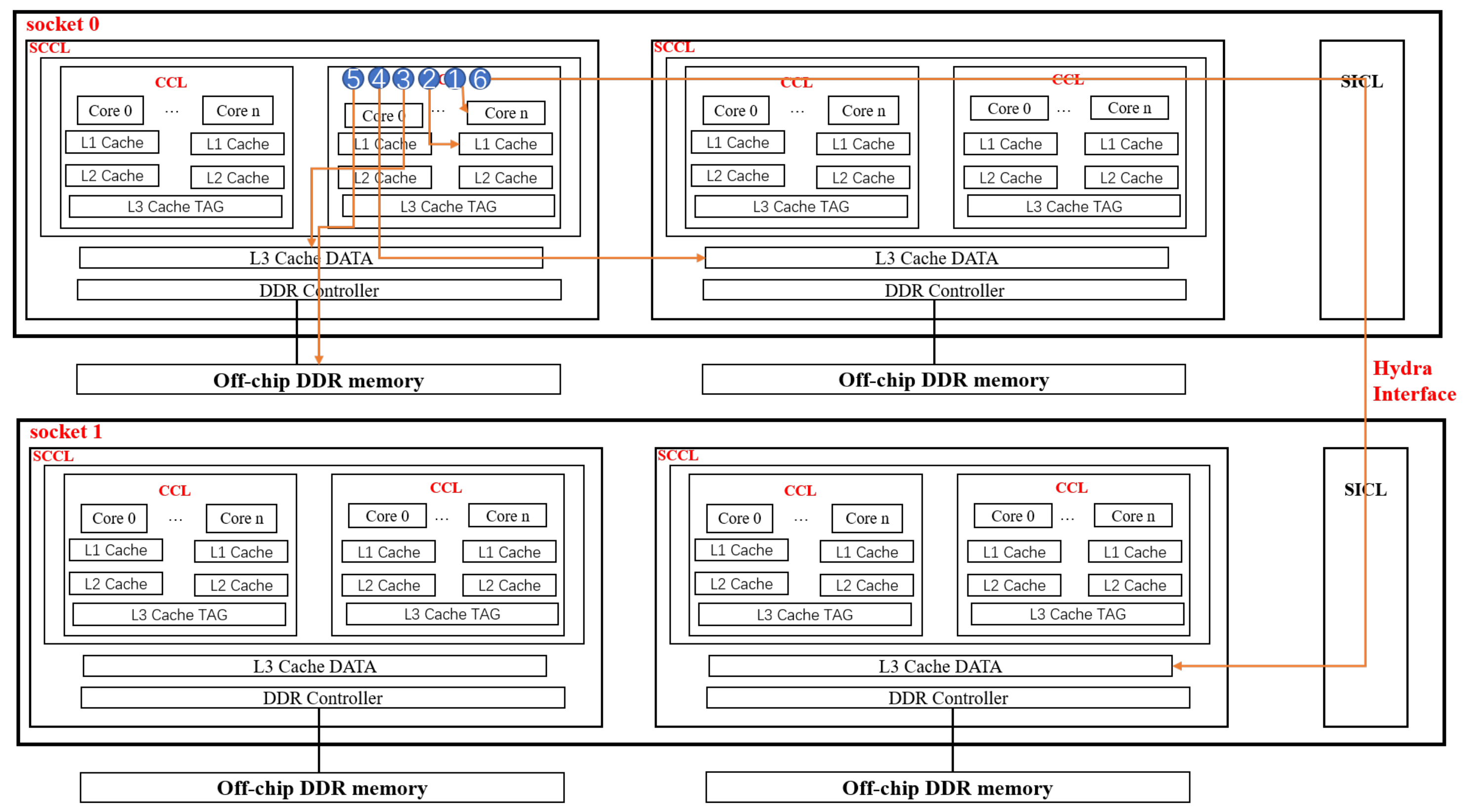
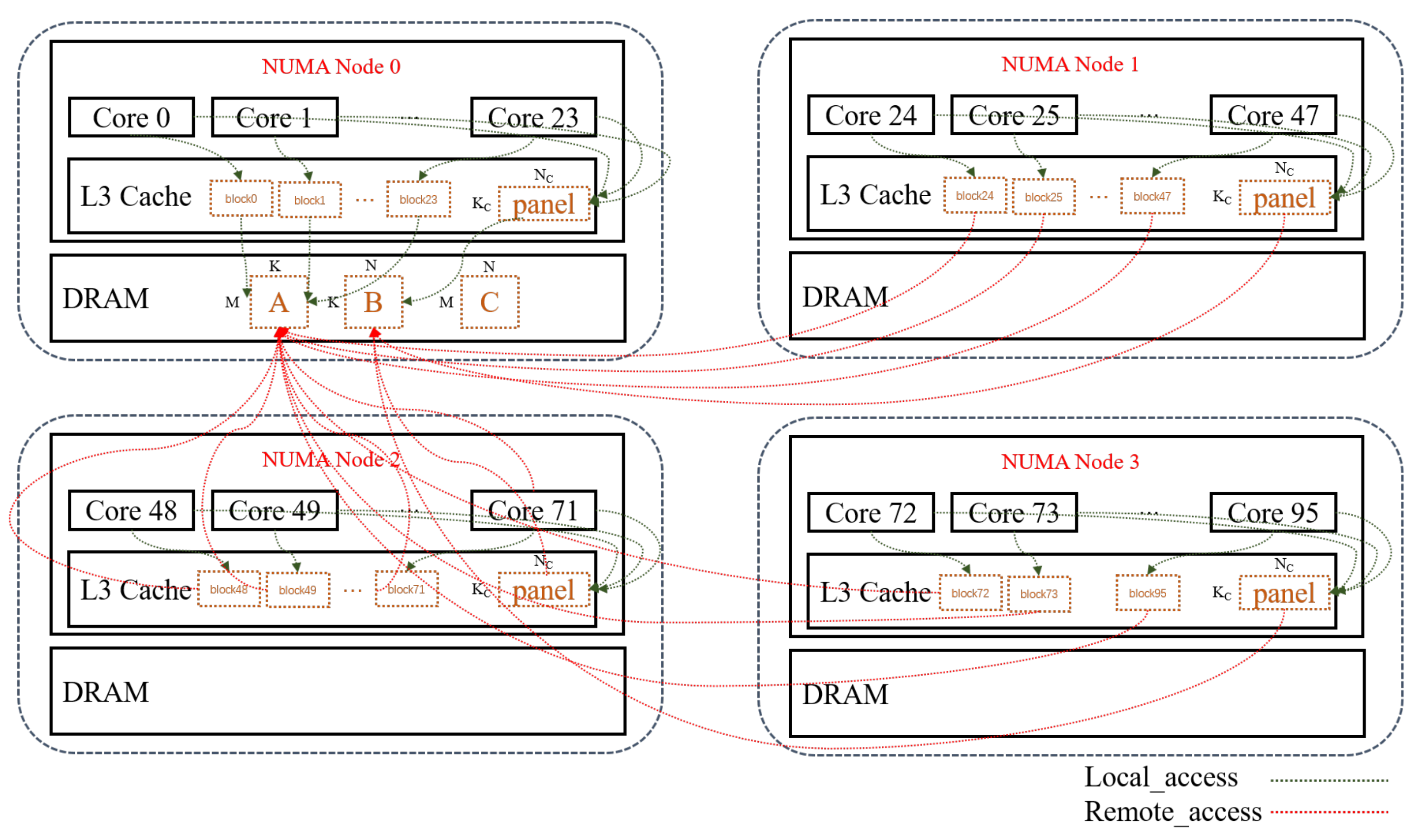
2.1. Details of Kunpeng920 Dual-Chip Processor Architecture
2.2. Non-Uniform Memory Access (NUMA)
- ①
- Access to the private L1 cache of the processor core;
- ②
- Access to the private L2 cache of the processor core;
- ③
- Access to the L3 cache data shared within the same SCCL;
- ④
- Access to the shared L3 cache DATA in other SCCLs on the same chip;
- ⑤
- Access to off-chip DDR memory;
- ⑥
- Access to the shared L3 cache DATA of an SCCL on other chips.
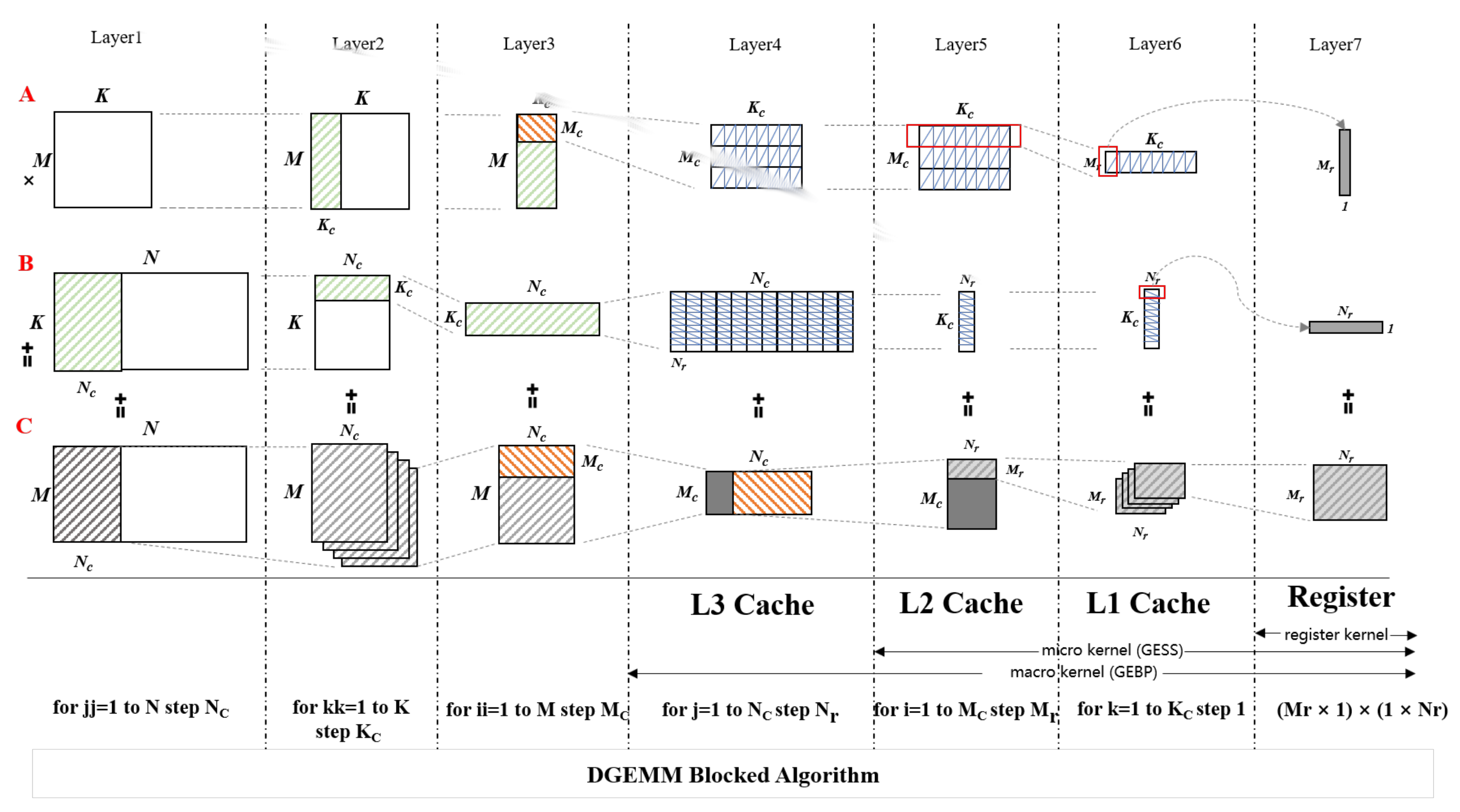
2.3. The Implementation of DGEMM in OpenBLAS
3. Challenges and Issues
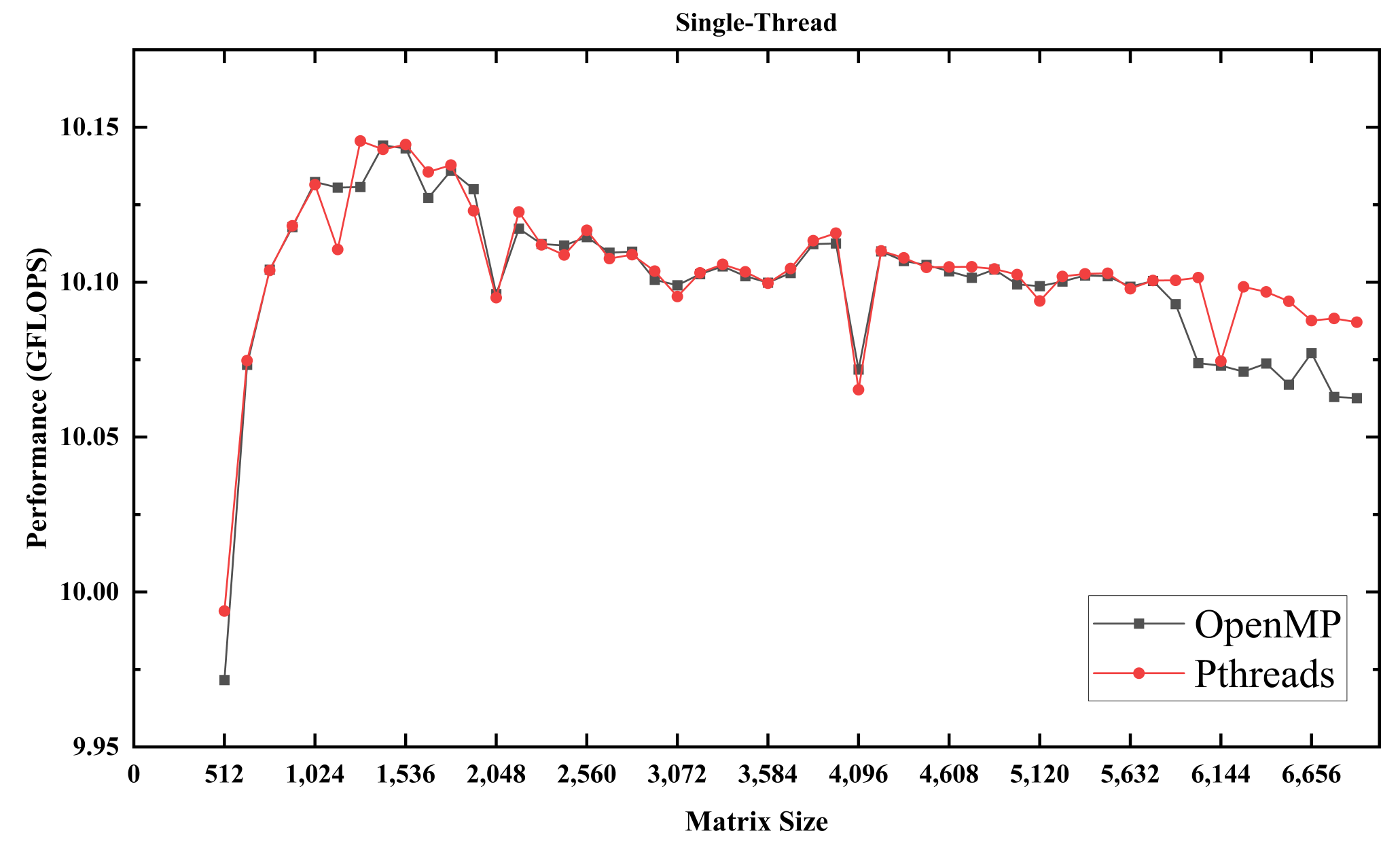
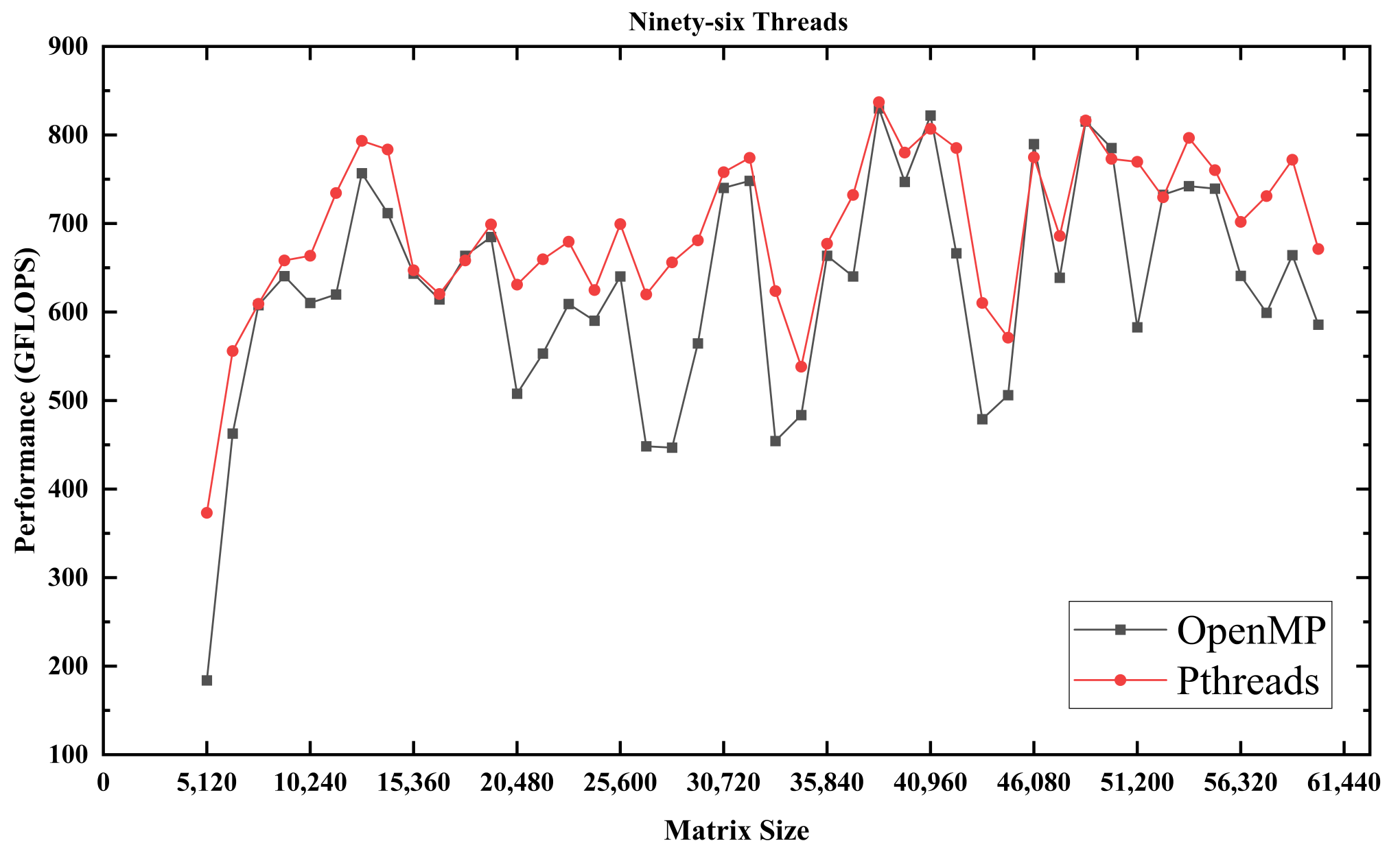
3.1. Pthreads vs. OpenMP
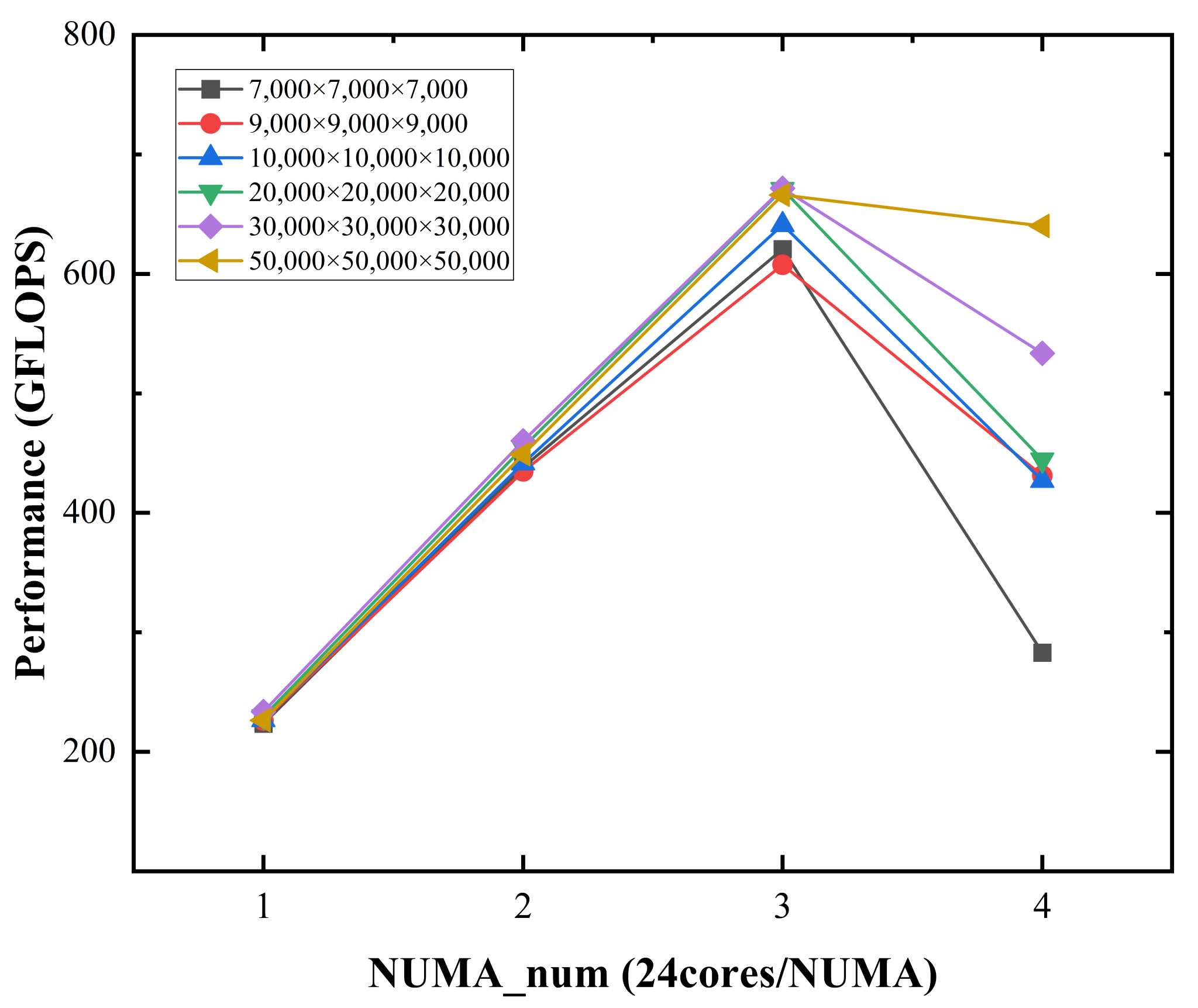
3.2. Observations on Scalability
3.3. Cause of DGEMM’s Scalability Bottleneck
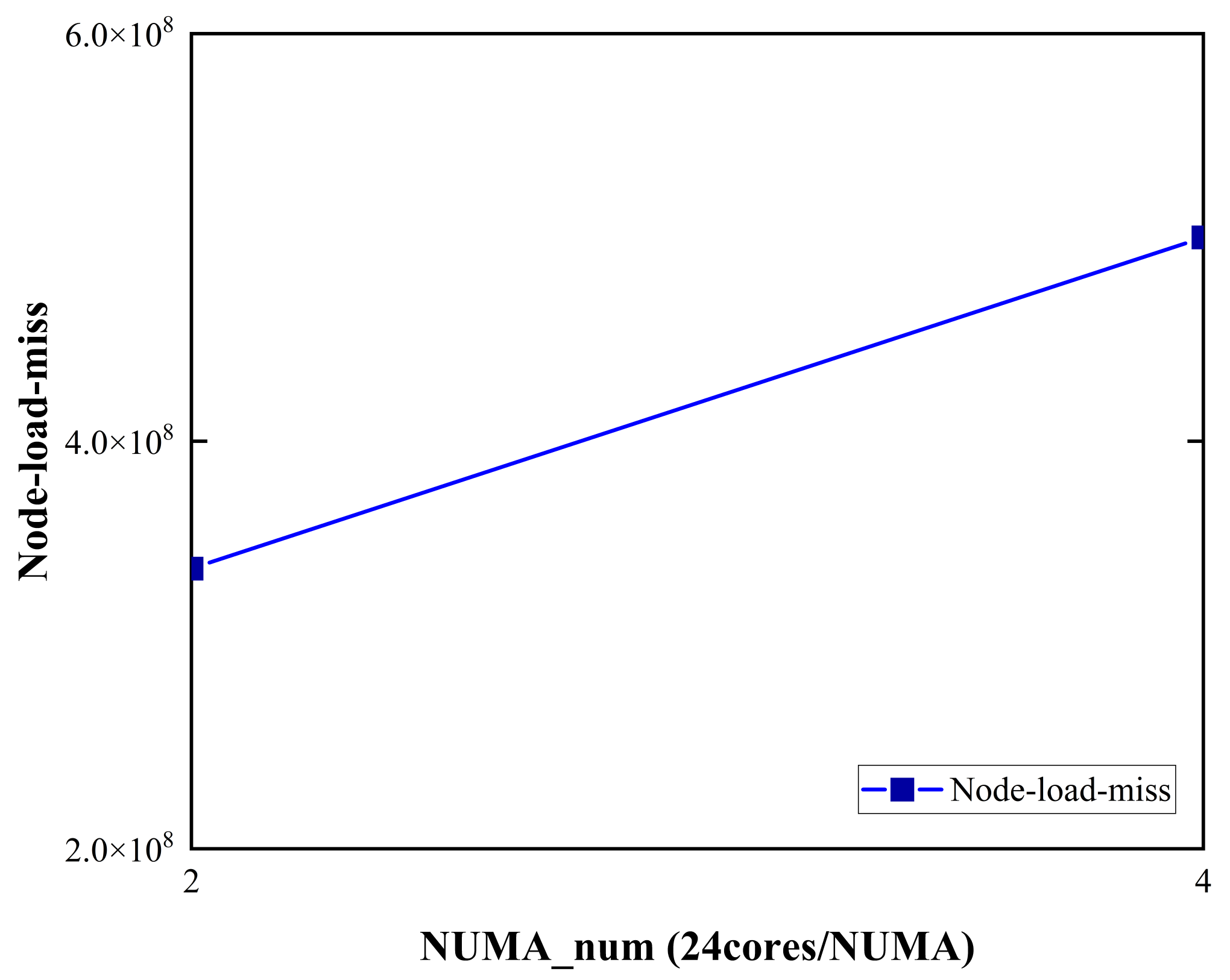
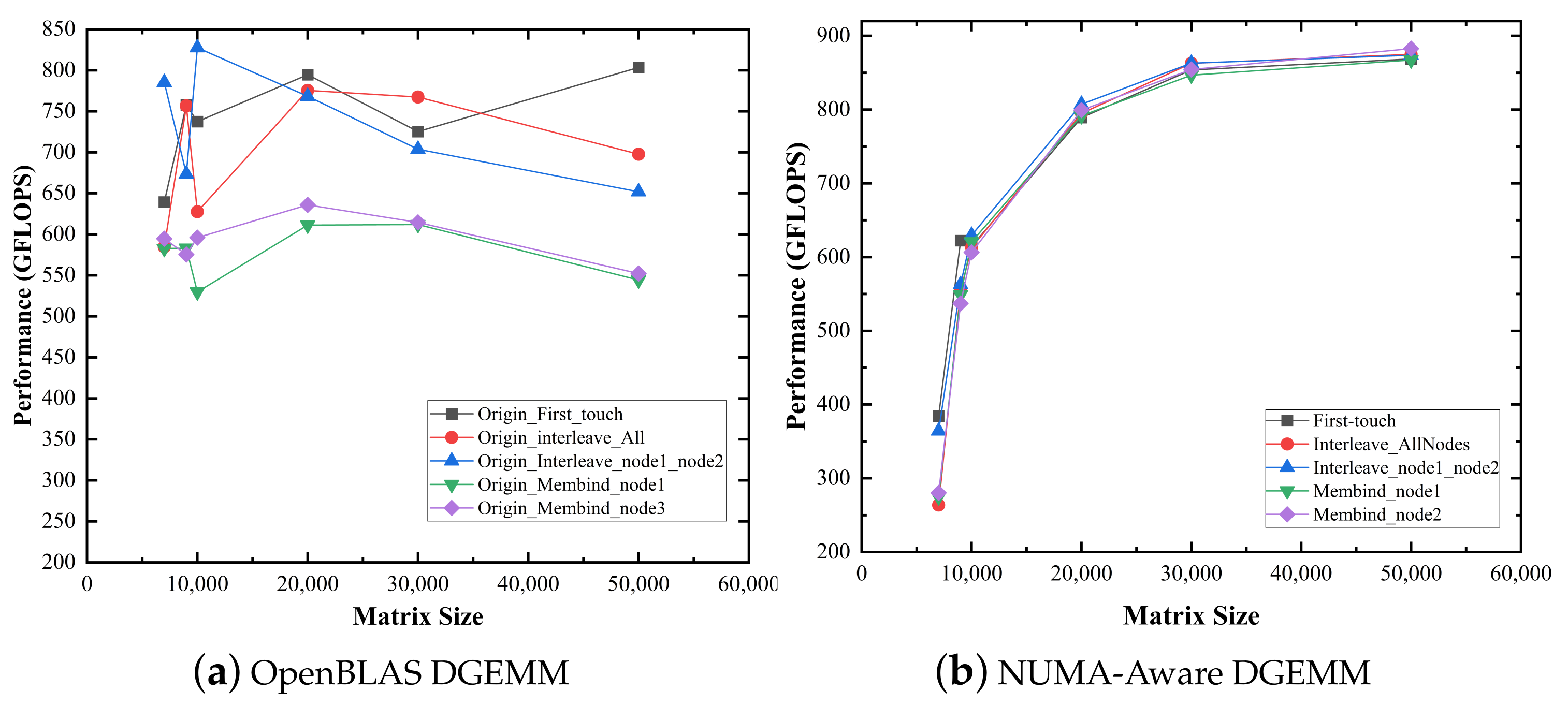
3.4. Source of NUMA Effects in DGEMM
4. Design Methodology
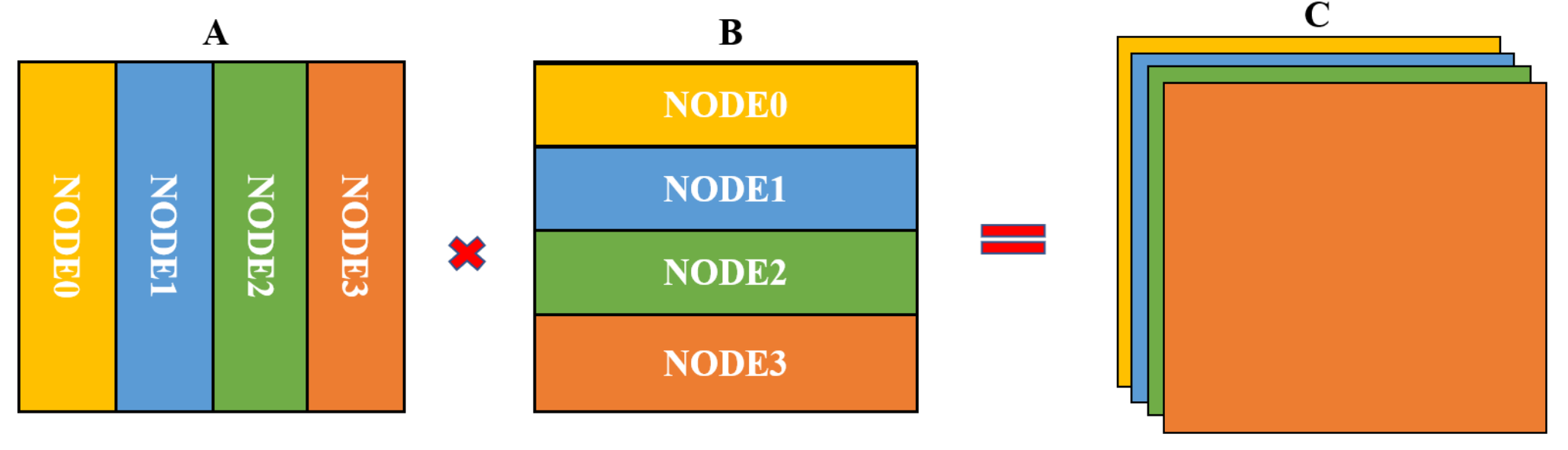
4.1. Task Distribution and Data Redeployment
4.2. NUMA-Aware DGEMM Algorithm
4.3. Two-Level Calculation and Data Mapping Method
| Algorithm 1: Parallel Optimization Algorithm of DGEMM on Kunpeng920 |
 |
4.4. Discussion
5. Results
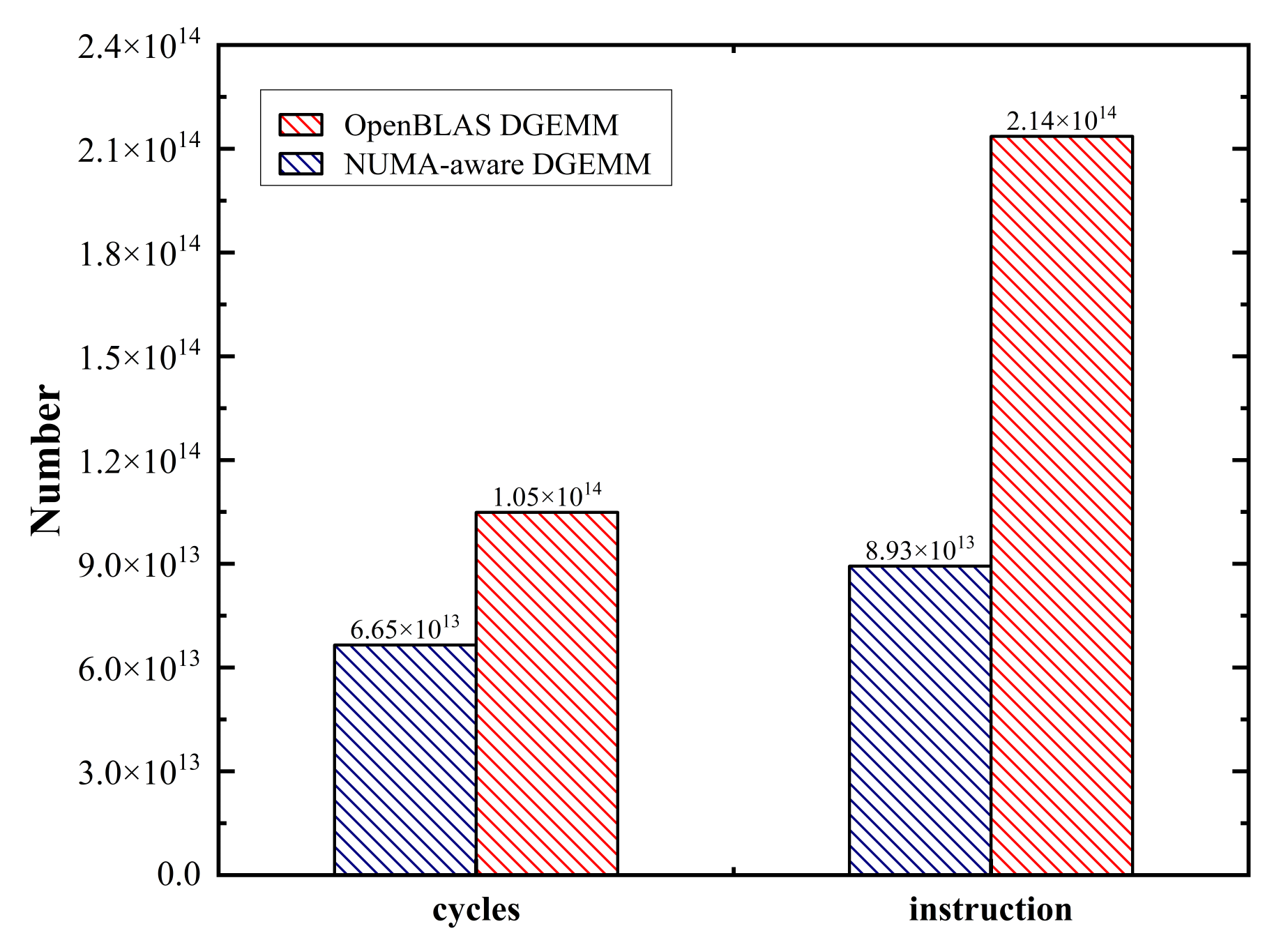
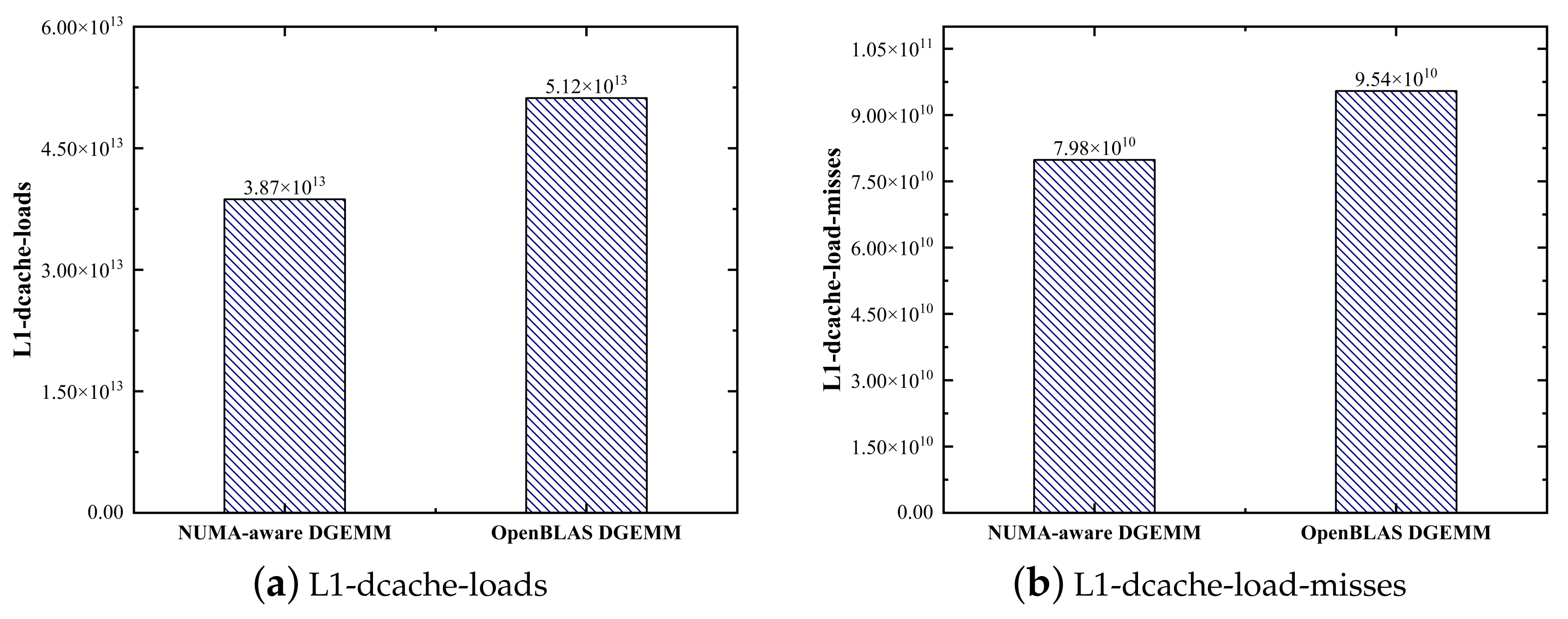
5.1. Overall Performance and Scalability
5.2. Reduced Remote and Random Accesses
6. Related Work
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Azimi, R.; Fox, T.; Gonzalez, W.; Reda, S. Scale-out vs scale-up: A study of arm-based socs on server-class workloads. ACM Trans. Model. Perform. Eval. Comput. Syst. 2018, 3, 1–23. [Google Scholar] [CrossRef]
- Top500 Supercomputer Sites. Available online: https://www.top500.org/lists/2020/6/s/ (accessed on 25 May 2021).
- Xia, J.; Cheng, C.; Zhou, X.; Hu, Y.; Chun, P. Kunpeng 920: The First 7nm Chiplet-Based 64-Core ARM SoC for Cloud Services. IEEE Micro 2021. [Google Scholar] [CrossRef]
- Arm Performance Libraries. Available online: https://www.arm.com/products/development-tools/server-and-hpc/allinea-studio/performance-libraries (accessed on 25 May 2021).
- Whaley, R.C.; Dongarra, J.J. Automatically tuned linear algebra software. In Proceedings of the 1998 ACM/IEEE Conference on Supercomputing, San Jose, CA, USA, 7–13 November 1998; p. 38. [Google Scholar]
- Goto, K.; Geijn, R.A.V.D. Anatomy of high-performance matrix multiplication. ACM Trans. Math. Softw. 2008, 34, 1–25. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Q.; Zhang, Y. Model-driven level 3 BLAS performance optimization on Loongson 3A processor. In Proceedings of the 2012 IEEE 18th International Conference on Parallel and Distributed Systems, Singapore, 17–19 December 2012; pp. 684–691. [Google Scholar]
- Van Zee, F.G.; Van De Geijn, R.A. BLIS: A framework for rapidly instantiating BLAS functionality. ACM Trans. Math. Softw. 2015, 41, 1–33. [Google Scholar] [CrossRef]
- Liu, J.; Chi, L.; Gong, C.; Xu, H.; Jiang, J.; Yan, Y.; Hu, Q. High-performance matrix multiply on a massively multithreaded Fiteng1000 processor. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Fukuoka, Japan, 4–7 September 2012; pp. 166–176. [Google Scholar]
- Wang, F.; Jiang, H.; Zuo, K.; Su, X.; Xue, J.; Yang, C. Design and implementation of a highly efficient DGEMM for 64-Bit ARMv8 multi-core processors. In Proceedings of the 2015 44th International Conference on Parallel Processing, Beijing, China, 1–4 September 2015; pp. 200–209. [Google Scholar]
- Cui, H.; Wang, L.; Xue, J.; Yang, Y.; Feng, X. Automatic library generation for BLAS3 on GPUs. In Proceedings of the 2011 IEEE International Parallel & Distributed Processing Symposium, Anchorage, AK, USA, 16–20 May 2011; pp. 255–265. [Google Scholar]
- Smith, T.M.; Van De Geijn, R.; Smelyanskiy, M.; Hammond, J.R.; Van Zee, F.G. Anatomy of high-performance many-threaded matrix multiplication. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 1049–1059. [Google Scholar]
- Su, X.; Lei, F. Hybrid-Grained Dynamic Load Balanced GEMM on NUMA Architectures. Electronics 2018, 7, 359. [Google Scholar] [CrossRef] [Green Version]
- Alkowaileet, W.Y.; Carrillo-Cisneros, D.; Lim, R.V.; Scherson, I.D. NUMA-aware multicore matrix multiplication. Parallel Process. Lett. 2014, 24, 1450006. [Google Scholar] [CrossRef] [Green Version]
- Dai, Z.; Liu, J. Architecture and Programming of Kunpeng Processor; Tsinghua University Press: Beijing, China, 2020. [Google Scholar]
- McCormick, P.S.; Braithwaite, R.K.; Feng, W.C. Empirical Memory-Access Cost Models in Multicore Numa Architectures; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM, USA, 2011. [Google Scholar]
- Yasin, A. A top-down method for performance analysis and counters architecture. In Proceedings of the 2014 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Monterey, CA, USA, 23–25 March 2014; pp. 35–44. [Google Scholar]
- Chen, S.; Zhang, Y.; Zhang, X.; Cheng, H. Performance Testing and Analysis of BLAS Libraries on Multi-Core CPUs. J. Softw. 2010, 21, 214–223. [Google Scholar]
- Kågström, B.; Ling, P.; Van Loan, C. GEMM-based level 3 BLAS: High-performance model implementations and performance evaluation benchmark. ACM Trans. Math. Softw. 1998, 24, 268–302. [Google Scholar] [CrossRef]
- Available online: https://support.huawei.com/enterprise/zh/doc/EDOC1100172781/426cffd9 (accessed on 26 May 2021).
- Kågström, B.; Van Loan, C. Algorithm 784: GEMM-based level 3 BLAS: Portability and optimization issues. ACM Trans. Math. Softw. 1998, 24, 303–316. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, J.; Yoshii, K.; Li, S.; Zhang, Y.; Balaji, P. Analyzing MPI-3.0 process-level shared memory: A case study with stencil computations. In Proceedings of the 2015 15th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, Shenzhen, China, 4–7 May 2015; pp. 1099–1106. [Google Scholar]
- ATLAS. Automatically Tuned Linear Algebra Software. Available online: http://math-atlas.sourceforge.net/ (accessed on 26 May 2021).
- Wang, Q.; Zhang, X.; Zhang, Y.; Yi, Q. AUGEM: Automatically generate high performance dense linear algebra kernels on x86 CPUs. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–22 November 2013; pp. 1–12. [Google Scholar]
- Yi, Q. Automated programmable control and parameterization of compiler optimizations. In Proceedings of the International Symposium on Code Generation and Optimization (CGO 2011), Seoul, Korea, 12–16 February 2011; pp. 97–106. [Google Scholar]
- Li, Y.; Dongarra, J.; Tomov, S. A note on auto-tuning GEMM for GPUs. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 884–892. [Google Scholar]
- Nath, R.; Tomov, S.; Dongarra, J. Accelerating GPU kernels for dense linear algebra. In Proceedings of the International Conference on High Performance Computing for Computational Science, Berkeley, CA, USA, 22–25 June 2010; pp. 83–92. [Google Scholar]
- Moss, D.J.; Krishnan, S.; Nurvitadhi, E.; Ratuszniak, P.; Johnson, C.; Sim, J.; Mishra, A.; Marr, D.; Subhaschandra, S.; Leong, P.H. A customizable matrix multiplication framework for the intel harpv2 xeon+ fpga platform: A deep learning case study. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 107–116. [Google Scholar]
- Alonso, P.; Dolz, M.F.; Igual, F.D.; Mayo, R.; Quintana-Orti, E.S. Reducing energy consumption of dense linear algebra operations on hybrid CPU-GPU platforms. In Proceedings of the 2012 IEEE 10th International Symposium on Parallel and Distributed Processing with Applications, Madrid, Spain, 10–12 July 2012; pp. 56–62. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Experiment Settings | Node 0 | Node 0, 1 | Node 0, 2 | Node 0, 3 | Node 0, 1, 2 | Node 0, 1, 2, 3 |
| local_write_count | 4.63 × 10 | 7.17 × 10 | 7.25 × 10 | 7.33 × 10 | 7.06 × 10 | 6.88 × 10 |
| cross-die_write_count | 4.26 × 10 | 1.92 × 10 | 2.14 × 10 | 2.09 × 10 | 3.26 × 10 | 4.07 × 10 |
| cross-chip_write_count | 3.21 × 10 | 4.56 × 10 | 1.80 × 10 | 1.80 × 10 | 1.66 × 10 | 1.89 × 10 |
| local_read_count | 4.66 × 10 | 6.10 × 10 | 6.10 × 10 | 6.09 × 10 | 5.91 × 10 | 5.65 × 10 |
| cross-die_read_count | 1.23 × 10 | 4.03 × 10 | 4.13 × 10 | 4.17 × 10 | 4.96 × 10 | 5.80 × 10 |
| cross-chip_read_count | 4.57 × 10 | 5.24 × 10 | 9.89 × 10 | 1.09 × 10 | 1.20 × 10 | 1.37 × 10 |
| Feature | Description | |
|---|---|---|
| Hardware | Architecture | AArch64 (Arm64) |
| Number of Core | 96, no hyper-threading support | |
| Frequency | 2600 MHz | |
| SIMD | AArch64 Neon instructions (128-bit) | |
| SIMD pipelines | 1 | |
| FLOPS/cycle | 4 | |
| Register File | 32 128-bit vector registers | |
| L1 Data Cache | 64 KB, 4-way set associative, 64 B cache line, LRU | |
| L2 Data Cache | 512 KB, 4-way set associative, 64 B cache line, LRU | |
| L3 Data Cache | 96 MB, 1 MB per core | |
| Memory | 256 GB | |
| NUMA Nodes | 4 NUMA Nodes | |
| Software | Operating System | GNU/Linux 4.19.0 AArch64 |
| Compiler | GNU/GCC 9.2.0 | |
| Thread Model | Pthreads | |
| BLAS | OpenBLAS 0.3.13 version |
| Efficiencies | NUMA-Aware DGEMM | OpenBLAS | ATLAS | BLIS | ||
|---|---|---|---|---|---|---|
| 8 × 6 | 8 × 4 | 4 × 4 | 8 × 6 | |||
| Peak | 92.34% | 86.33% | 78.11% | 80.70% | 70% | 79.33% |
| Average | 86.97% | 81.20% | 73.23% | 78.12% | 64% | 74.61% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Jiang, Z.; Chen, Z.; Xiao, N.; Ou, Y. NUMA-Aware DGEMM Based on 64-Bit ARMv8 Multicore Processors Architecture. Electronics 2021, 10, 1984. https://doi.org/10.3390/electronics10161984
Zhang W, Jiang Z, Chen Z, Xiao N, Ou Y. NUMA-Aware DGEMM Based on 64-Bit ARMv8 Multicore Processors Architecture. Electronics. 2021; 10(16):1984. https://doi.org/10.3390/electronics10161984
Chicago/Turabian StyleZhang, Wei, Zihao Jiang, Zhiguang Chen, Nong Xiao, and Yang Ou. 2021. "NUMA-Aware DGEMM Based on 64-Bit ARMv8 Multicore Processors Architecture" Electronics 10, no. 16: 1984. https://doi.org/10.3390/electronics10161984
APA StyleZhang, W., Jiang, Z., Chen, Z., Xiao, N., & Ou, Y. (2021). NUMA-Aware DGEMM Based on 64-Bit ARMv8 Multicore Processors Architecture. Electronics, 10(16), 1984. https://doi.org/10.3390/electronics10161984