
LDPC Decoder Design Using Compensation Scheme of Group Comparison for 5G Communication Systems



Abstract
:1. Introduction
2. Low-Density Parity-Check Codes
2.1. Quasi-Cyclic (QC) LDPC Codes
2.2. Parity Check Matrices for 5G NR Standard
3. LDPC Decoding Algorithms
3.1. NMSA
3.2. NPMSA
3.3. rExMin Algorithm
3.4. SMA-MSA
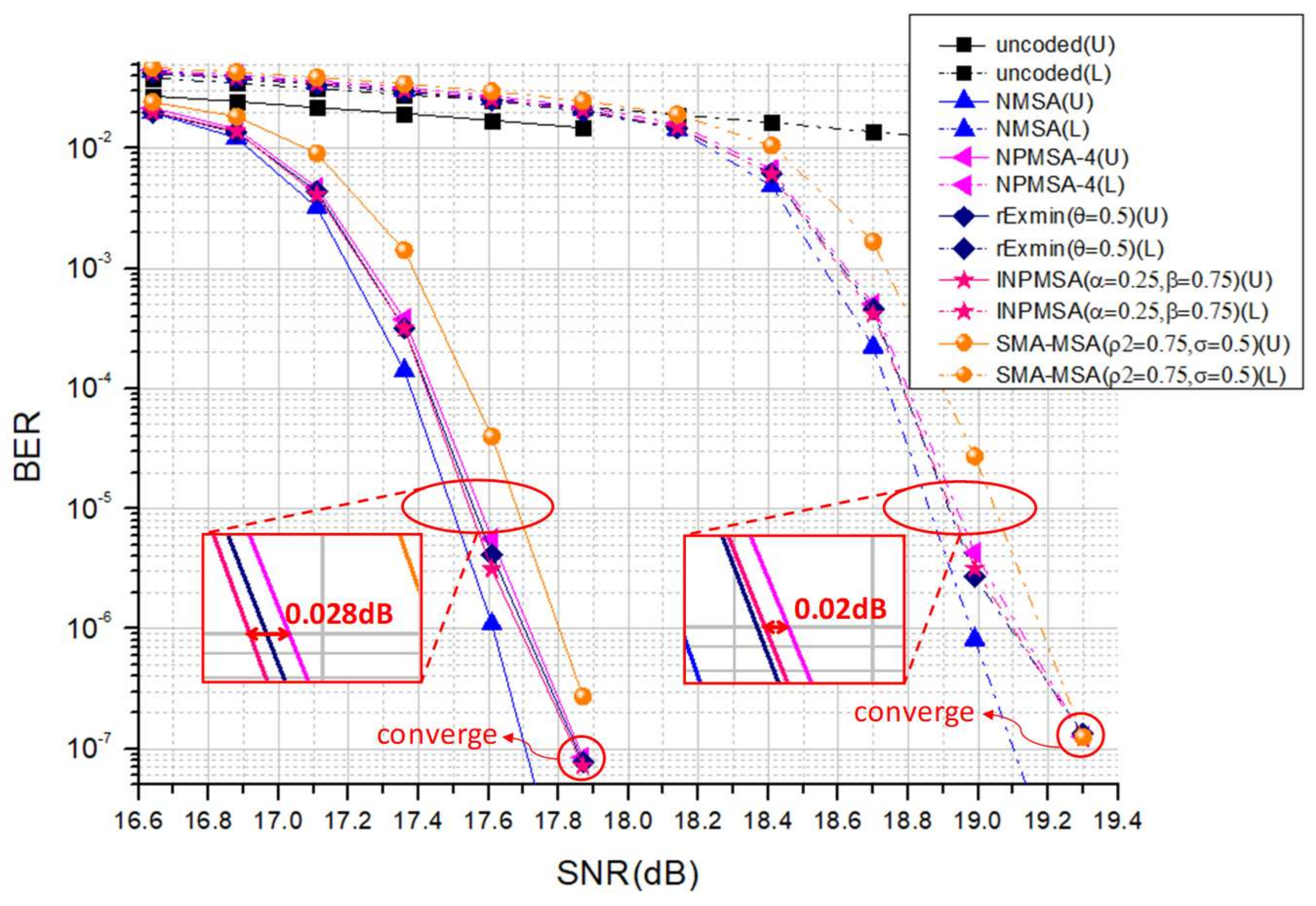
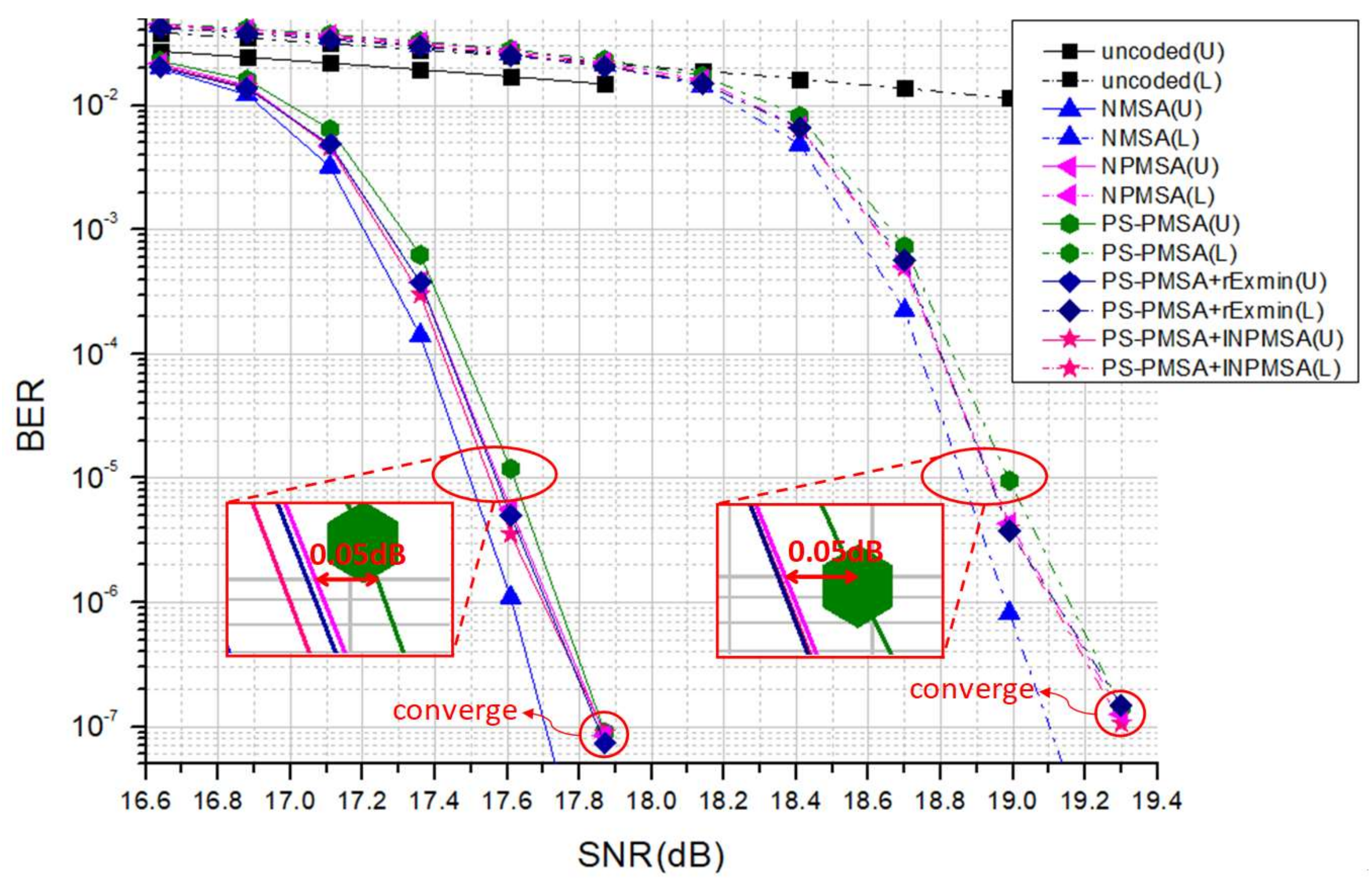
4. Proposed Compensation Scheme for NPMSA
4.1. Difference in Extrinsic Messages
4.2. INPMSA with Compensation Scheme
4.3. Simulation Results
5. VLSI Implementation of Dual-Mode LDPC Decoder for 5G NR Systems
5.1. Architecture of Dual-Mode LDPC Decoder
5.2. CNU Using Compensation Scheme of Group Comparison
5.3. Post-Layout Implementation Results
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Technical Specification Group Radio Access Network. Multiplexing Channel Coding. (3GPP TS 38.212 Version 15.2.0 Release 15). 2018. Available online: https://www.etsi.org/deliver/etsi_ts/138200_138299/138212/15.02.00_60/ts_138212v150200p.pdf (accessed on 16 October 2019).
- Gallager, R. Low-Density Parity-Check Codes. IEEE Trans. Inform. Theory 1962, 8, 21–28. [Google Scholar] [CrossRef] [Green Version]
- Morello, A.; Mignone, V. DVB-S2: The Second Generation Standard for Satellite Broad-Band Services. Proc. IEEE 2006, 94, 210–227. [Google Scholar] [CrossRef]
- IEEE Standards Association. IEEE Standard for Information Technology—Local and Metropolitan Area Networks—Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications Amendment 5: Enhancements for Higher Throughput; IEEE Standards Association: Piscataway, NJ, USA, 2008. [Google Scholar]
- IEEE Standards Association. IEEE Standard for Local and Metropolitan area Networks Part 16: Air Interface for Fixed and Mobile Broadband Wireless Access Systems. Amendment 2: Physical and Medium Access Control Layers for Combined Fixed and Mobile Operation in Licensed Bands, and Corrigendum 1; IEEE Standards Association: Piscataway, NJ, USA, 2006. [Google Scholar]
- Korkotsides, S.; Bikas, G.; Eftaxiadis, E.; Antonakopoulos, T. BER Analysis of MLC NAND Flash Memories Based on an Asymmetric PAM Model. In Proceedings of the 6th International Symposium on Communications, Control and Signal Processing (ISCCSP), Athens, Greece, 21–23 May 2014; pp. 558–561. [Google Scholar]
- Chen, J.; Fossorier, M.P.C. Near Optimum Universal Belief Propagation Based Decoding of Low-Density Parity Check Codes. IEEE Trans. Commun. 2002, 50, 406–414. [Google Scholar] [CrossRef]
- Chen, J.; Fossorier, M.P.C. Density Evolution for Two Improved BP-Based Decoding Algorithms of LDPC Codes. IEEE Commun. Lett. 2002, 6, 208–210. [Google Scholar] [CrossRef]
- Cheng, C.-C.; Yang, J.-D.; Lee, H.-C.; Yang, C.-H.; Ueng, Y.-L. A Fully Parallel LDPC Decoder Architecture Using Probabilistic Min-Sum Algorithm for High-Throughput Applications. IEEE Trans. Circuits Syst. I 2014, 61, 2738–2746. [Google Scholar] [CrossRef]
- Wang, C.-X.; Lin, C.-H. Improved normalized probabilistic minimum summation algorithm for LDPC decoding. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taoyuan, Taiwan, 28–30 September 2020; pp. 1–2. [Google Scholar]
- Zhang, Z.; Zhou, L.; Zhou, Z.H. Design of A Parallel Decoding Method for LDPC Code Generated via Primitive Polynomial. Electronics 2021, 10, 425. [Google Scholar] [CrossRef]
- Tanner, R. A Recursive Approach to Low Complexity Codes. IEEE Trans. Inform. Theory 1981, 27, 533–547. [Google Scholar] [CrossRef] [Green Version]
- Richardson, T.J.; Urbanke, R.L. Efficient Encoding of Low-Density Parity-Check Codes. IEEE Trans. Inform. Theory 2001, 47, 638–656. [Google Scholar] [CrossRef] [Green Version]
- Thi Bao Nguyen, T.; Nguyen Tan, T.; Lee, H. Efficient QC-LDPC Encoder for 5G New Radio. Electronics 2019, 8, 668. [Google Scholar] [CrossRef] [Green Version]
- Petrović, V.L.; El Mezeni, D.M.; Radošević, A. Flexible 5G New Radio LDPC Encoder Optimized for High Hardware Usage Efficiency. Electronics 2021, 10, 1106. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Good Error-Correcting Codes Based on Very Sparse Matrices. IEEE Trans. Inform. Theory 1999, 45, 399–431. [Google Scholar] [CrossRef] [Green Version]
- Tsatsaragkos, I.; Paliouras, V. Approximate Algorithms for Identifying Minima on Min-Sum LDPC Decoders and Their Hardware Implementation. IEEE Trans. Circuits Syst. II 2015, 62, 766–770. [Google Scholar] [CrossRef]
- Català-Pérez, J.M.; Lacruz, J.O.; García-Herrero, F.; Valls, J.; Declercq, D. Second Minimum Approximation for Min-Sum Decoders Suitable for High-Rate LDPC Codes. Circuits Syst. Signal Process. 2019, 38, 5068–5080. [Google Scholar] [CrossRef]
- Angarita, F.; Valls, J.; Almenar, V.; Torres, V. Reduced-Complexity Min-Sum Algorithm for Decoding LDPC Codes With Low Error-Floor. IEEE Trans. Circuits Syst. I 2014, 61, 2150–2158. [Google Scholar] [CrossRef]
- Wey, C.-H.; Shieh, M.-D.; Lin, S.-Y. Algorithms of Finding the First Two Minimum Values and Their Hardware Implementation. IEEE Trans. Circuits Syst. I Reg. Pap. 2008, 55, 3430–3437. [Google Scholar]
- Mohsenin, T.; Truong, D.N.; Baas, B.M. A Low-Complexity Message-Passing Algorithm for Reduced Routing Congestion in LDPC Decoders. IEEE Trans. Circuits Syst. I 2010, 57, 1048–1061. [Google Scholar] [CrossRef]
- Song, C.-P.; Lin, C.-H.; Lin, S.-Y. Partially-Stopped Probabilistic Min-Sum Algorithm for LDPC Decoding. In Proceedings of the IEEE 5th Global Conference on Consumer Electronics (GCCE), Kyoto, Japan, 11–14 October 2016; pp. 1–2. [Google Scholar]
- Thi Bao Nguyen, T.; Nguyen Tan, T.; Lee, H. Low-Complexity High-Throughput QC-LDPC Decoder for 5G New Radio Wireless Communication. Electronics 2021, 10, 516. [Google Scholar] [CrossRef]
- Lin, C.-Y.; Liu, L.-W.; Liao, Y.-C.; Chang, H.-C. A 33.2 Gbps/iter. Reconfigurable LDPC Decoder Fully Compliant with 5G NR Applications. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Lin, C.-H.; Hsieh, C.-W. Low-Routing-Complexity Convolutional/Turbo Decoder Design for Iterative Detection and Decoding Receivers. IEEE Trans. Circuits Syst. I 2019, 66, 4476–4489. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | NMSA [7] | SRTA [21] | NPMSA [9] |
|---|---|---|---|
| Architecture of minimum finder | [20] | [21] | Group comparison [9] |
| # of two-input comparisons in a check node process | 23,424 (100%) | 18,432 (78.69%) | 11,904 (50.82%) |
| Error rate loss @ BER = 10−6 | 0 dB | 0.2 dB | 0.05 dB |
| Group G | 2 | 4 | 8 | 16 | |
|---|---|---|---|---|---|
| Input Q (# of row weight in a layer) | 8 | 42.9% | 14.3% | 0% | 0% |
| 16 | 46.7% | 20% | 6.7% | 0% | |
| 19 | 47.2% | 20.8% | 7.6% | 1% | |
| 32 | 48.3% | 22.6% | 9.7% | 3.2% | |
| 64 | 49.2% | 23.8% | 11.1% | 4.8% | |
| Decoders | This Study | [24] | [23] | ||
|---|---|---|---|---|---|
| Implementation | Post-layout | Post-layout | Post-synthesis | ||
| Standard | 5G NR | 5G NR | 5G NR | ||
| Technology S (nm) | 40 | 28 | 65 | ||
| Voltage U (v) | 0.9 | 0.9 | 1.0 | ||
| Algorithm | INPMSA | NMSA | CMSA | ||
| Decoding schedule | Layered | Layered | Layered | ||
| Parallelism | 64 | N/A | 56 | ||
| Quantization (bit) | 8 | 5 | 4 | ||
| Core area (mm2) | 3.24 | 1.97 | 1.49 | ||
| Frequency (MHz) | 294.1 | 556 | 750 | ||
| Code rate | 11/13 (BG 1) | 5/7 (BG 2) | 1/3 (BG 1) | 1/2 (BG 2) | 1/3 (BG 1) |
| Max. code length (bit) | 9984 | 5376 | 25,344 | 19,200 | 3808 |
| Iteration | 6 (Max.) | 6 (Max.) | 5 (Avg. %) | 4.92 (Avg. %) | 10 (Max.) |
| Throughput (Gb/s) | 10.86 | 5.84 | 6.64 | 7.92 | 3.04 |
| Avg. power (mW) | 313.3 | - | 232 | - | 259 |
| NAE & (bits/mm2) | 11.40 | 6.13 | 2.97 | 3.54 | 7.18 |
| NEE $ (pJ/bit) | 28.85 | - | 49.91 | - | 42.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-H.; Wang, C.-X.; Lu, C.-K. LDPC Decoder Design Using Compensation Scheme of Group Comparison for 5G Communication Systems. Electronics 2021, 10, 2010. https://doi.org/10.3390/electronics10162010
Lin C-H, Wang C-X, Lu C-K. LDPC Decoder Design Using Compensation Scheme of Group Comparison for 5G Communication Systems. Electronics. 2021; 10(16):2010. https://doi.org/10.3390/electronics10162010
Chicago/Turabian StyleLin, Cheng-Hung, Chen-Xuan Wang, and Cheng-Kai Lu. 2021. "LDPC Decoder Design Using Compensation Scheme of Group Comparison for 5G Communication Systems" Electronics 10, no. 16: 2010. https://doi.org/10.3390/electronics10162010
APA StyleLin, C.-H., Wang, C.-X., & Lu, C.-K. (2021). LDPC Decoder Design Using Compensation Scheme of Group Comparison for 5G Communication Systems. Electronics, 10(16), 2010. https://doi.org/10.3390/electronics10162010