
Fake News Data Exploration and Analytics

 ,
,  , , and
, , and
Abstract
:1. Introduction
- Pre-processed and extensive data exploration are applied in our work to understand fake and real news.
- As per our knowledge, our proposed four machine learning models are more efficient than previous studies reported.
- The proposed approach could help determine fake or real news for various other types of datasets.
2. Literature Review
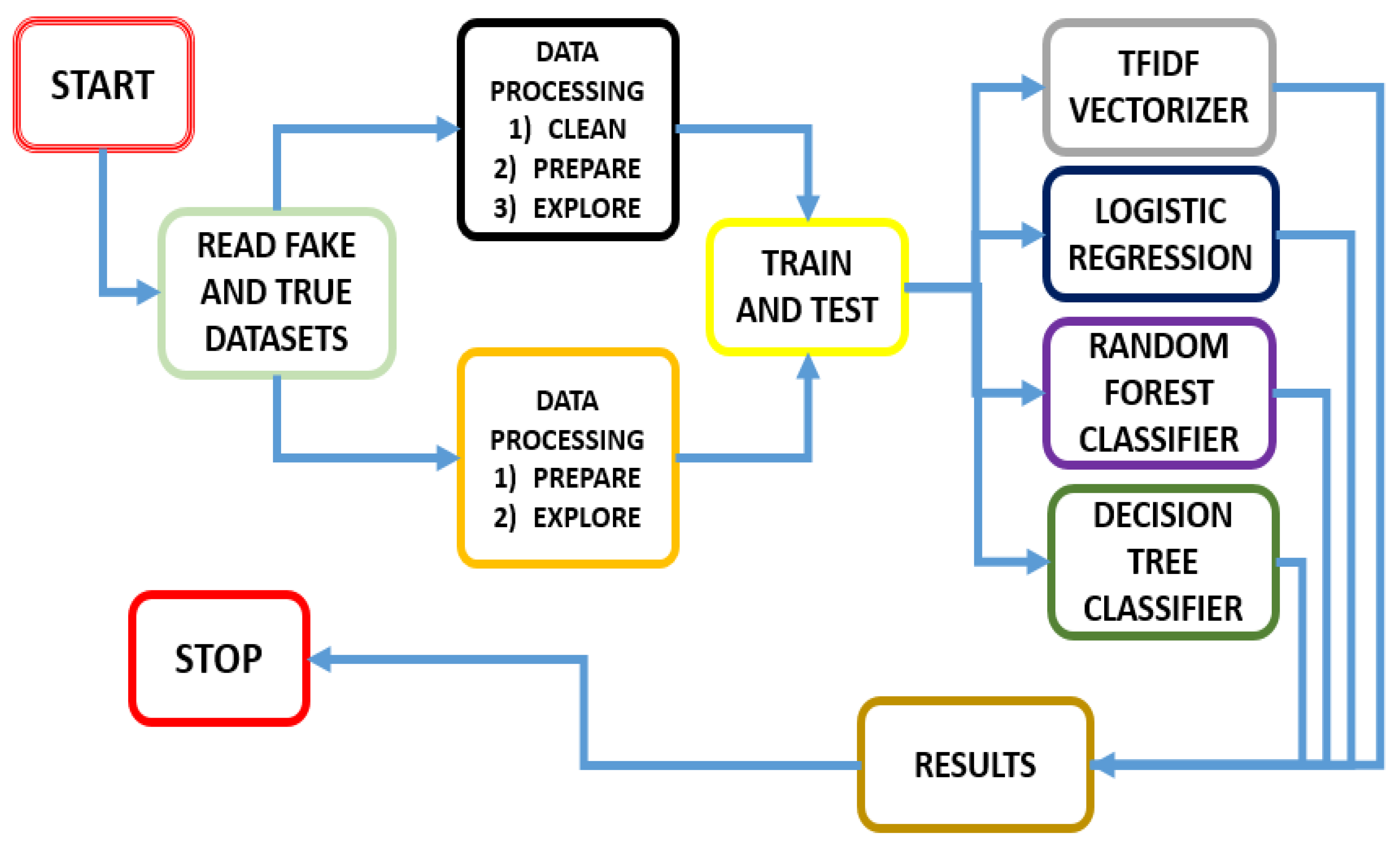
3. Dataset and Methodology
3.1. Dataset Description and Architecture
3.2. Data Pre-Processing
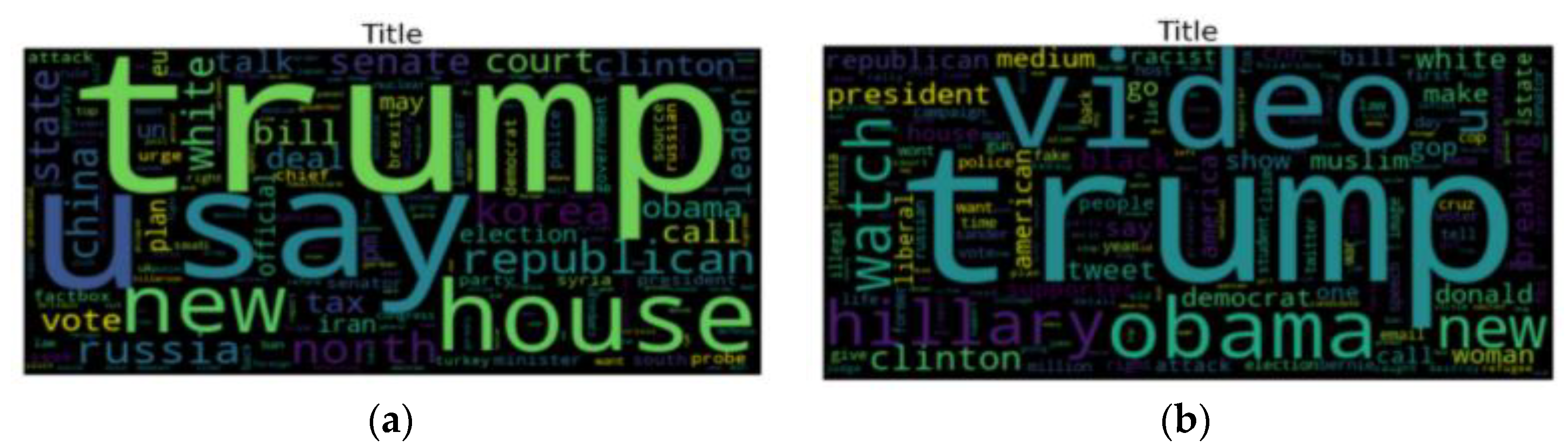
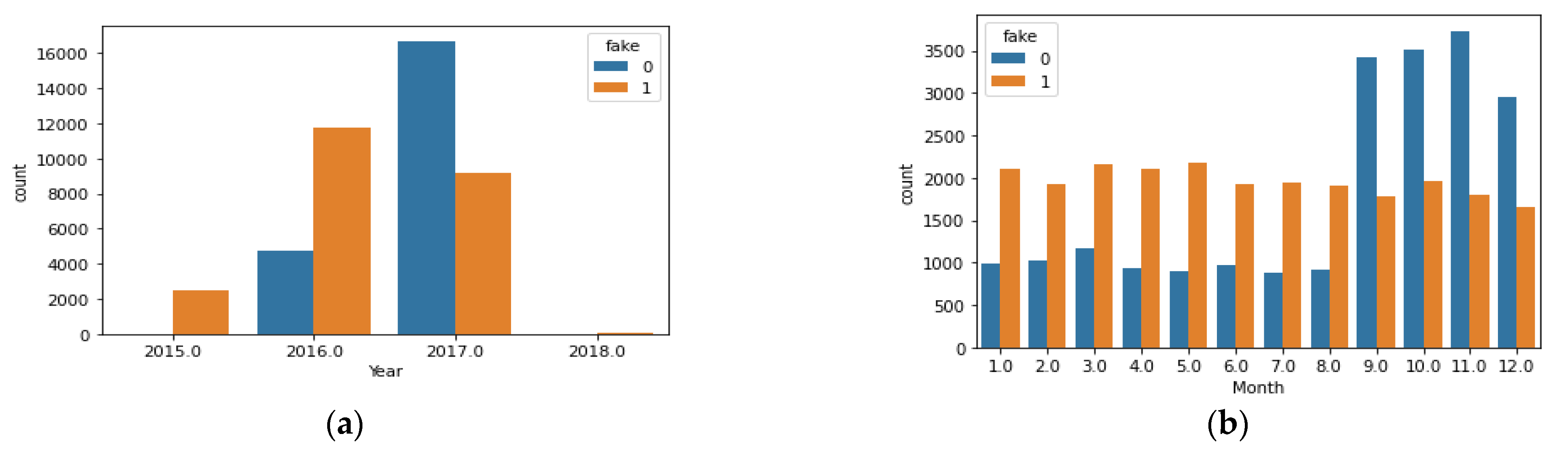
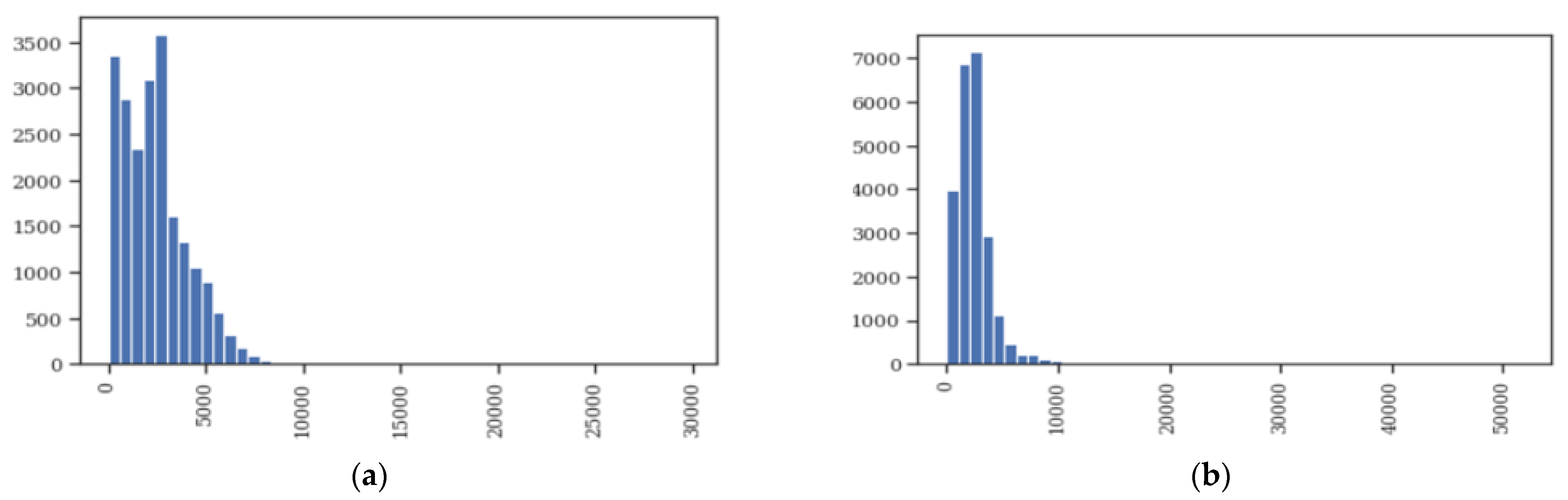
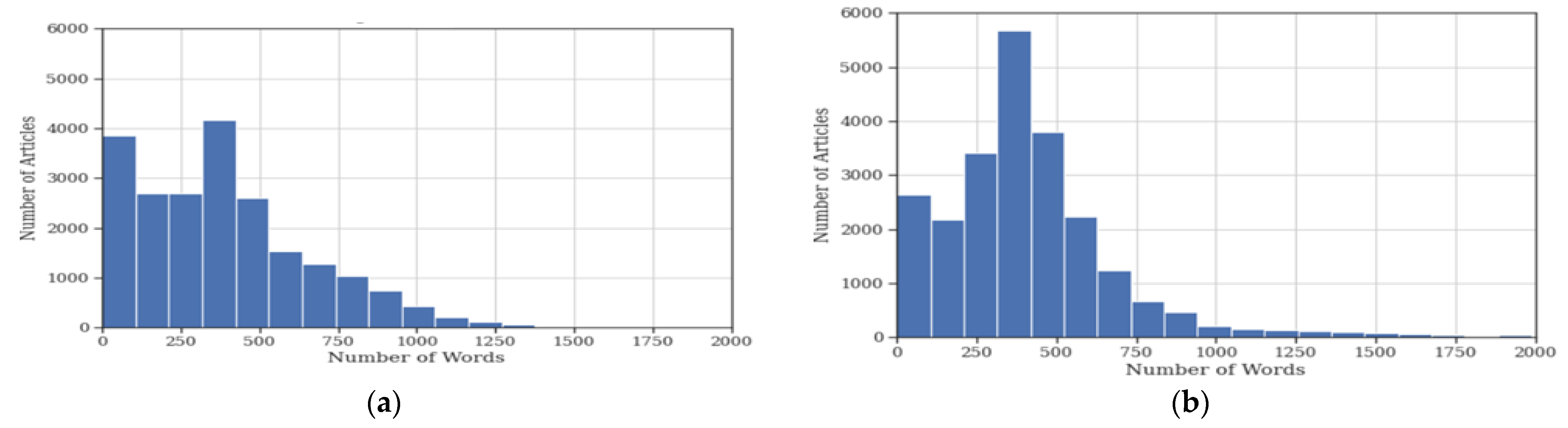
3.3. Data Exploration
3.4. Our Approach
3.4.1. TF-IDF Vectorizer
3.4.2. Logistic Regression
3.4.3. Random Forest Classifier
3.4.4. Decision Tree Classifier
4. Experimental Results
4.1. Experimental Setup
4.2. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alonso, M.; Vilares, D.; Gómez-Rodríguez, C.; Vilares, J. Sentiment Analysis for Fake News Detection. Electronics 2021, 10, 1348. [Google Scholar] [CrossRef]
- Rehma, A.A.; Awan, M.J.; Butt, I. Comparison and Evaluation of Information Retrieval Models. VFAST Trans. Softw. Eng. 2018, 13, 7–14. [Google Scholar] [CrossRef]
- Alam, T.M.; Awan, M.J. Domain analysis of information extraction techniques. Int. J. Multidiscip. Sci. Eng. 2018, 9, 1–9. [Google Scholar]
- Kim, H.; Park, J.; Cha, M.; Jeong, J. The Effect of Bad News and CEO Apology of Corporate on User Responses in Social Media. PLoS ONE 2015, 10, e0126358. [Google Scholar] [CrossRef] [Green Version]
- Pulido, C.M.; Ruiz-Eugenio, L.; Redondo-Sama, G.; Villarejo-Carballido, B. A New Application of Social Impact in Social Media for Overcoming Fake News in Health. Int. J. Environ. Res. Public Health 2020, 17, 2430. [Google Scholar] [CrossRef] [Green Version]
- Hamborg, F.; Donnay, K.; Gipp, B. Automated identification of media bias in news articles: An interdisciplinary literature review. Int. J. Digit. Libr. 2018, 20, 391–415. [Google Scholar] [CrossRef] [Green Version]
- Jang, Y.; Park, C.-H.; Seo, Y.-S. Fake News Analysis Modeling Using Quote Retweet. Electronics 2019, 8, 1377. [Google Scholar] [CrossRef] [Green Version]
- Lazer, D.M.J.; Baum, M.A.; Benkler, Y.; Berinsky, A.J.; Greenhill, K.M.; Menczer, F.; Metzger, M.J.; Nyhan, B.; Pennycook, G.; Rothschild, D.; et al. The science of fake news. Science 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Kogan, S.; Moskowitz, T.J.; Niessner, M. Fake News in Financial Markets; Working Paper; Yale University: New Haven, CT, USA, 2017. [Google Scholar]
- Lai, C.-M.; Shiu, H.-J.; Chapman, J. Quantifiable Interactivity of Malicious URLs and the Social Media Ecosystem. Electronics 2020, 9, 2020. [Google Scholar] [CrossRef]
- Wang, Y.; Xia, C.; Si, C.; Zhang, C.; Wang, T. The Graph Reasoning Approach Based on the Dynamic Knowledge Auxiliary for Complex Fact Verification. Electronics 2020, 9, 1472. [Google Scholar] [CrossRef]
- Hua, J.; Shaw, R.J.I. Corona virus (Covid-19) "infodemic" and emerging issues through a data lens: The case of china. Int. J. Environ. Res. Public Health 2020, 17, 2309. [Google Scholar] [CrossRef] [Green Version]
- Anam, M.; Ponnusamy, V.A.; Hussain, M.; Nadeem, M.W.; Javed, M.; Goh, H.G.; Qadeer, S. Osteoporosis Prediction for Trabecular Bone using Machine Learning: A Review. Comput. Mater. Contin. 2021, 67, 89–105. [Google Scholar] [CrossRef]
- Gupta, M.; Jain, R.; Arora, S.; Gupta, A.; Awan, M.J.; Chaudhary, G.; Nobanee, H. AI-enabled COVID-19 outbreak analysis and prediction: Indian states vs. union territories. Comput. Mater. Contin. 2021, 67, 1–18. [Google Scholar]
- Ali, Y.; Farooq, A.; Alam, T.M.; Farooq, M.S.; Awan, M.J.; Baig, T.I. Detection of Schistosomiasis Factors Using Association Rule Mining. IEEE Access 2019, 7, 186108–186114. [Google Scholar] [CrossRef]
- Javed, R.; Saba, T.; Humdullah, S.; Jamail, N.S.M.; Awan, M.J. An Efficient Pattern Recognition Based Method for Drug-Drug Interaction Diagnosis. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 221–226. [Google Scholar]
- Nagi, A.T.; Awan, M.J.; Javed, R.; Ayesha, N. A Comparison of Two-Stage Classifier Algorithm with Ensemble Techniques on Detection of Diabetic Retinopathy. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 212–215. [Google Scholar]
- Ahmed, H.; Traore, I.; Saad, S. Detecting opinion spams and fake news using text classification. Secur. Priv. 2017, 1, e9. [Google Scholar] [CrossRef] [Green Version]
- Conroy, N.K.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. Proc. Assoc. Inf. Sci. Technol. 2015, 52, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Hussein, D.M.E.-D.M. A survey on sentiment analysis challenges. J. King Saud Univ.-Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Bali, A.P.S.; Fernandes, M.; Choubey, S.; Goel, M. Comparative performance of machine learning algorithms for fake news detection. In Proceedings of the International Conference on Advances in Computing and Data Sciences, Ghazibad, India, 12–13 April 2019; pp. 420–430. [Google Scholar]
- Faustini, P.; Covões, T. Fake news detection using one-class classification. In Proceedings of the 2019 8th Brazilian Conference on Intelligent Systems (BRACIS), Salvador, Brazil, 15–18 October 2019; pp. 592–597. [Google Scholar]
- Shaikh, J.; Patil, R. Fake News Detection using Machine Learning. In Proceedings of the 2020 IEEE International Symposium on Sustainable Energy, Signal Processing and Cyber Security (iSSSC), San Francisco, CA, USA, 16–17 December 2020; pp. 1–5. [Google Scholar]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- Hakak, S.; Alazab, M.; Khan, S.; Gadekallu, T.R.; Maddikunta, P.K.R.; Khan, W.Z. An ensemble machine learning approach through effective feature extraction to classify fake news. Futur. Gener. Comput. Syst. 2020, 117, 47–58. [Google Scholar] [CrossRef]
- Abdullah, A.; Awan, M.; Shehzad, M.; Ashraf, M. Fake news classification bimodal using convolutional neural network and long short-term memory. Int. J. Emerg. Technol. 2020, 11, 209–212. [Google Scholar]
- Sharma, D.K.; Garg, S.; Shrivastava, P. Evaluation of Tools and Extension for Fake News Detection. In Proceedings of the 2021 International Conference on Innovative Practices in Technology and Management (ICIPTM), Gautam Buddh Nagar, India, 17–19 February 2021; pp. 227–232. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.L. seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Singh, A.K.; Shashi, M. Vectorization of Text Documents for Identifying Unifiable News Articles. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef] [Green Version]
- Dey, A.; Jenamani, M.; Thakkar, J.J. Lexical TF-IDF: An n-gram feature space for cross-domain classification of sentiment reviews. In Proceedings of the International Conference on Pattern Recognition and Machine Intelligence, Kolkata, India, 5–8 December 2017; pp. 380–386. [Google Scholar]
- Menard, S. Applied Logistic Regression Analysis; Sage: London, UK, 2002; Volume 106. [Google Scholar]
- Manzoor, S.I.; Singla, J.; Nikita. Fake News Detection Using Machine Learning approaches: A systematic Review. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 230–234. [Google Scholar]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; Kluwer Academic Publisher: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man, Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Lyu, S.; Lo, D.C.T. Fake News Detection by Decision Tree. In Proceedings of the 2020 SoutheastCon, Raleigh, NC, USA, 28–29 March 2020; pp. 1–2. [Google Scholar]
- Awan, M.J.; Rahim, M.S.M.; Nobanee, H.; Yasin, A.; Khalaf, O.I.; Ishfaq, U. A Big Data Approach to Black Friday Sales. Intell. Autom. Soft Comput. 2021, 27, 785–797. [Google Scholar] [CrossRef]
- Ahmed, H.M.; Awan, M.J.; Khan, N.S.; Yasin, A.; Faisal Shehzad, H.M. Sentiment Analysis of Online Food Reviews using Big Data Analytics. Elem. Educ. Online 2021, 20, 827–836. [Google Scholar]
- Awan, M.J.; Rahim, M.S.M.; Nobanee, H.; Munawar, A.; Yasin, A.; Azlanmz, A.M.Z. Social Media and Stock Market Prediction: A Big Data Approach. Comput. Mater. Contin. 2021, 67, 2569–2583. [Google Scholar] [CrossRef]
- Awan, M.; Khan, R.; Nobanee, H.; Yasin, A.; Anwar, S.; Naseem, U.; Singh, V. A Recommendation Engine for Predicting Movie Ratings Using a Big Data Approach. Electronics 2021, 10, 1215. [Google Scholar] [CrossRef]
- Khalil, A.; Awan, M.J.; Yasin, A.; Singh, V.P.; Shehzad, H.M.F. Flight Web Searches Analytics through Big Data. Int. J. Comput. Appl. Technol. in press.
- Awan, M.J.; Khan, M.A.; Ansari, Z.K.; Yasin, A.; Shehzad, H.M.F. Fake Profile Recognition using Big Data Analytics in Social Media Platforms. Interational J. Comput. Appl. Technol. 2021, in press. [Google Scholar]
- Awan, M.J. Acceleration of Knee MRI Cancellous bone Classification on Google Colaboratory using Convolutional Neural Network. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 83–88. [Google Scholar] [CrossRef]
- Mujahid, A.; Awan, M.; Yasin, A.; Mohammed, M.; Damaševičius, R.; Maskeliūnas, R.; Abdulkareem, K. Real-Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model. Appl. Sci. 2021, 11, 4164. [Google Scholar] [CrossRef]
- Awan, M.J.; Raza, A.; Yasin, A.; Shehzad, H.M.F.; Butt, I. The Customized Convolutional Neural Network of Face Emotion Expression Classification. Ann. Rom. Soc. Cell Biol. 2021, 25, 5296–5304. [Google Scholar]
- Awan, M.J.; Rahim, M.M.; Salim, N.; Mohammed, M.; Garcia-Zapirain, B.; Abdulkareem, K. Efficient Detection of Knee Anterior Cruciate Ligament from Magnetic Resonance Imaging Using Deep Learning Approach. Diagnostics 2021, 11, 105. [Google Scholar] [CrossRef]
- Aftab, M.O.; Awan, M.J.; Khalid, S.; Javed, R.; Shabir, H. Executing Spark BigDL for Leukemia Detection from Microscopic Images using Transfer Learning. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 216–220. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. No. | Article Title | Frequency |
|---|---|---|
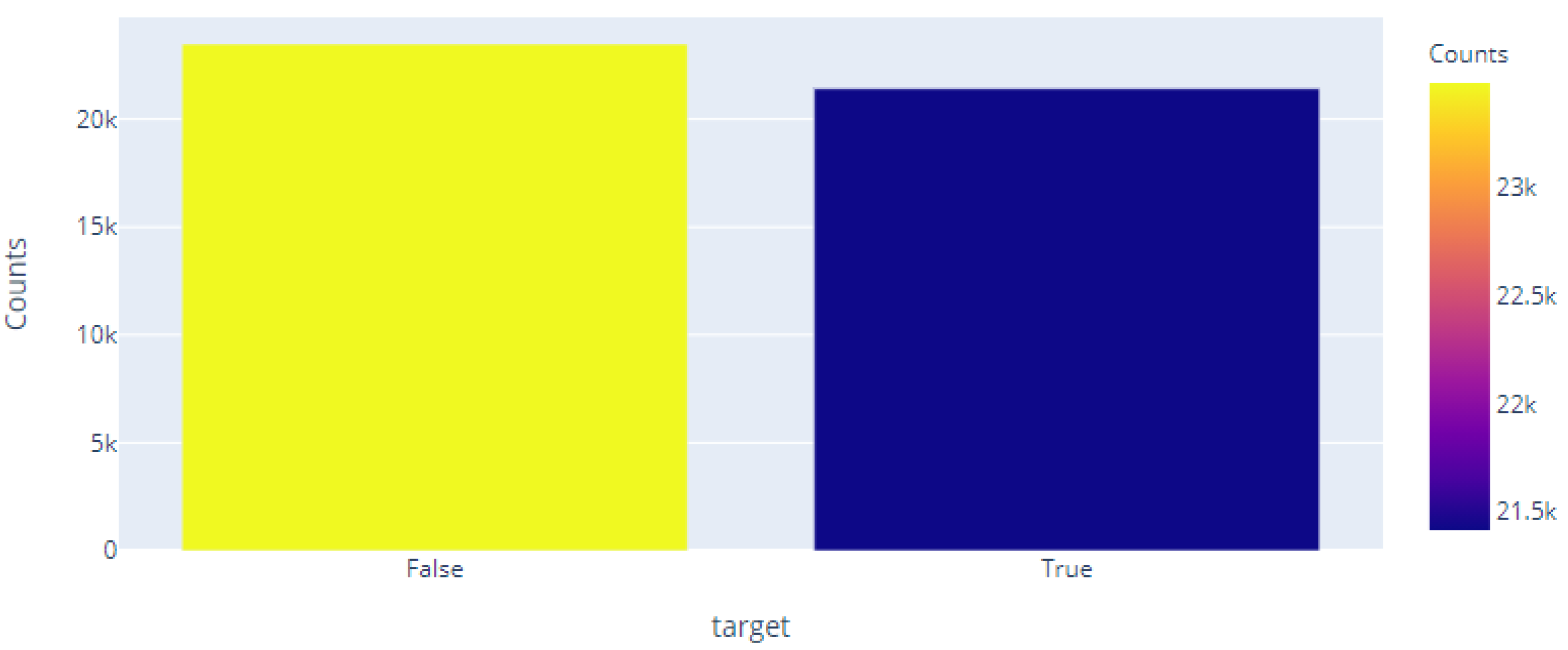
| 1 | Fake news articles | 23,481 |
| 2 | real news articles | 21,417 |
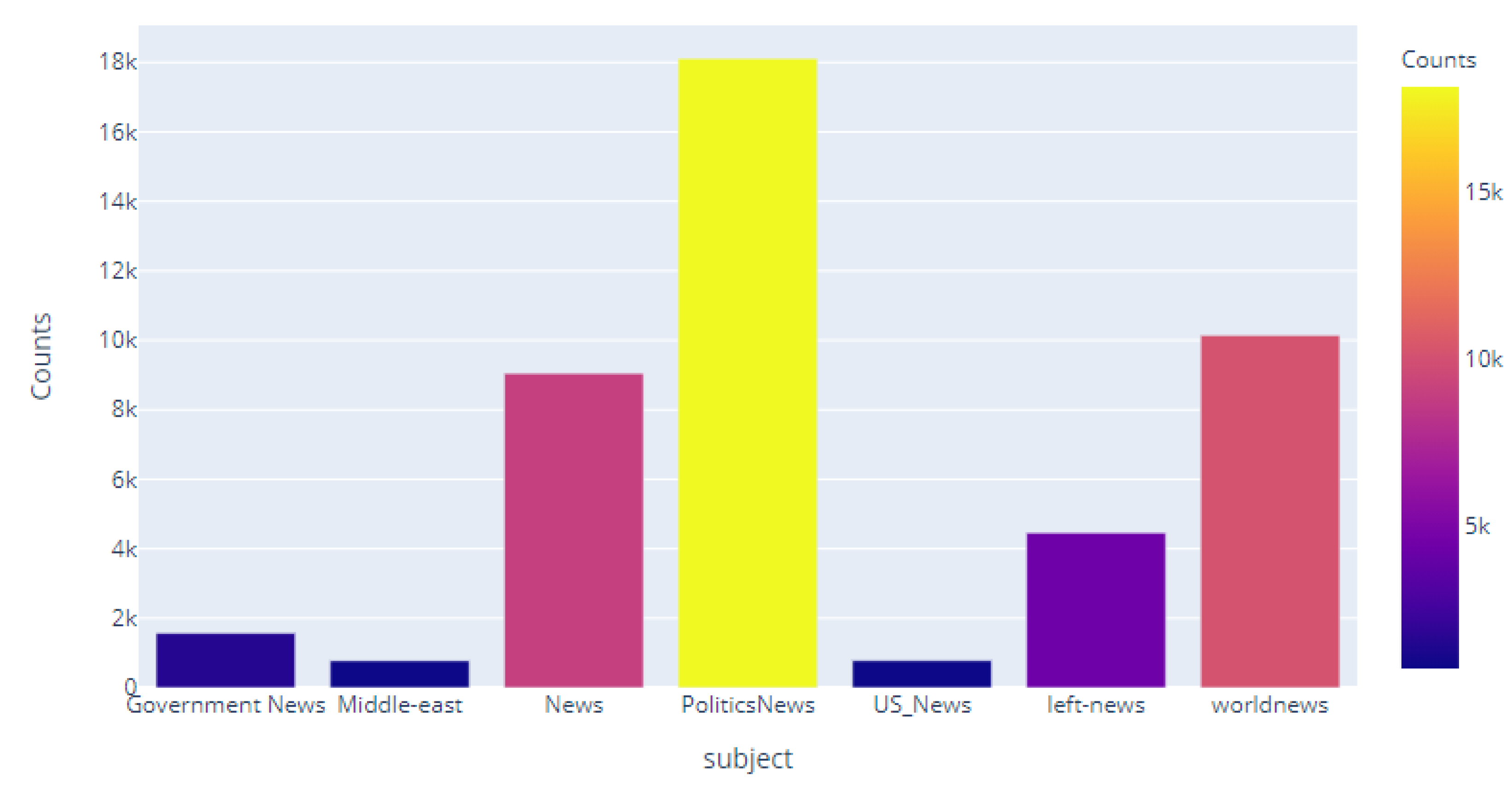
| S No. | Subject | Frequency |
|---|---|---|
| 1 | Government News | 1570 |
| 2 | Middle East | 778 |
| 3 | News | 9050 |
| 4 | US News | 783 |
| 5 | Left News | 4459 |
| 6 | Politics | 6841 |
| 7 | Politics News | 11,272 |
| 8 | World News | 10,145 |
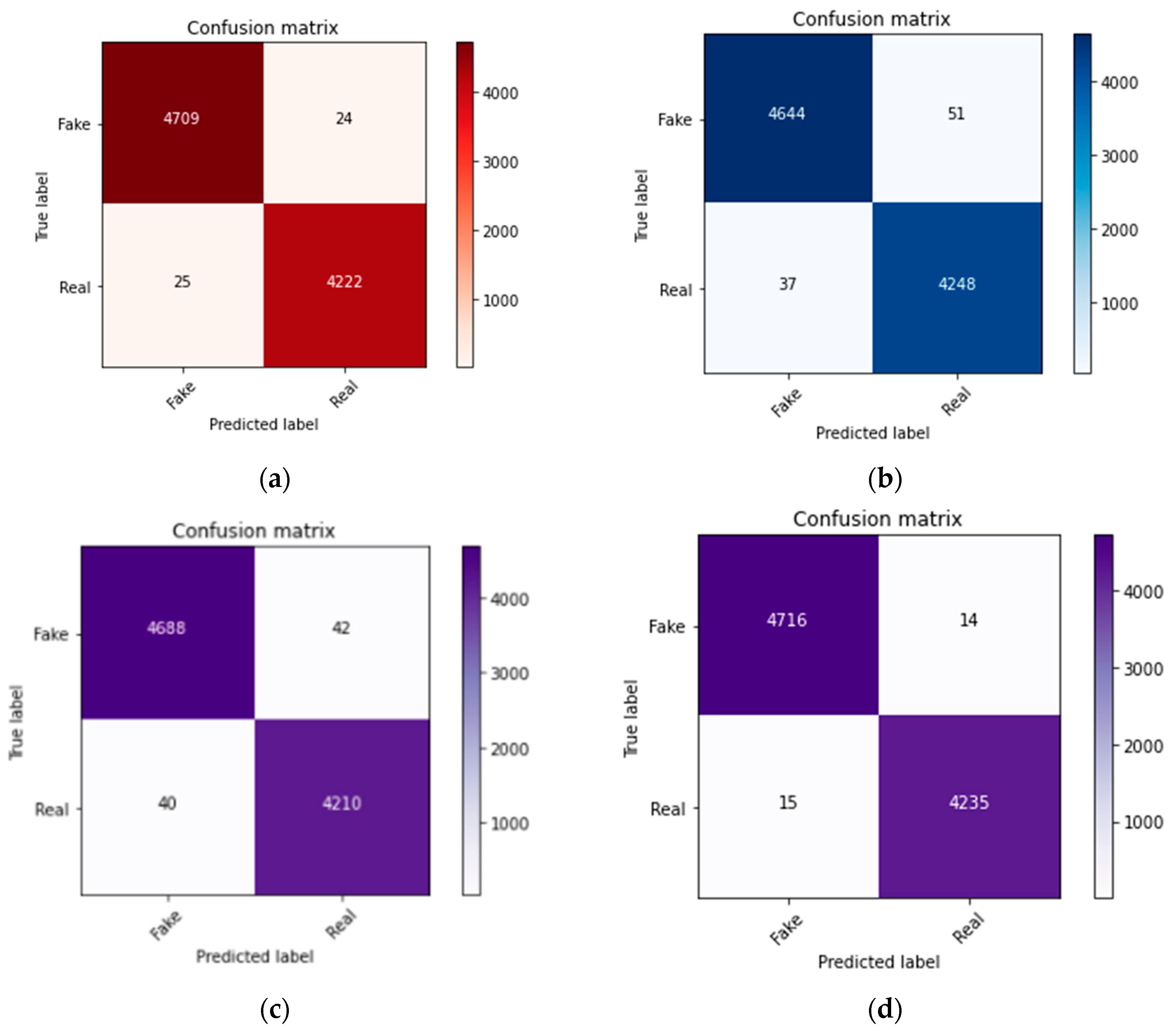
| Sr. No. | Machine Learning Model | Fake News Identified | Real News Identified | Results (Accuracies) |
|---|---|---|---|---|
| 1 | TF-IDF Vectorizer | 4708 | 4228 | 99.51% |
| 2 | Logistic Regression | 4664 | 4193 | 98.63% |
| 3 | Random Forest Classifier | 4682 | 4172 | 98.6% |
| 4 | Decision Tree Classifier | 4716 | 4235 | 99.68% |
| Sr. No. | Machine Learning Model | Fake News Identified | Real News Identified | Results (Accuracies) |
|---|---|---|---|---|
| 1 | TF-IDF Vectorizer | 4709 | 4222 | 99.52% |
| 2 | Logistic Regression | 4644 | 4248 | 98.63% |
| 3 | Random Forest Classifier | 4678 | 4173 | 99.63% |
| 4 | Decision Tree Classifier | 4716 | 4235 | 99.68% |
| Sr. No. | Machine Learning Model | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | TF-IDF Vectorizer | 0.99 | 0.99 | 0.99 |
| 2 | Logistic Regression | 0.98 | 0.99 | 0.98 |
| 3 | Random Forest Classifier | 0.98 | 0.99 | 0.98 |
| 4 | Decision Tree Classifier | 0.98 | 0.99 | 0.99 |
| Sr. No. | Machine Learning Models | Accuracy | Studies |
|---|---|---|---|
| 1 | TF-IDF-Vectorizer, Logistic Regression, Random Forest Classifier, Decision Tree Classifier | 99.45% | Proposed study |
| 3 | Random forest algorithm, Perez-LSVM, Linear SVM, multilayer perceptron, bagging classifiers, boosting classifiers, KNN | 99%, 99%,98%, 98%, 98%, 88% | [25] |
| 4 | LSTM and BI-LSTM Classifier | 91.51% | [28] |
| 5 | Term Frequency-Inverted Document Frequency (TF-IDF) and Support Vector Machine (SVM) | 95.05% | [24] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awan, M.J.; Yasin, A.; Nobanee, H.; Ali, A.A.; Shahzad, Z.; Nabeel, M.; Zain, A.M.; Shahzad, H.M.F. Fake News Data Exploration and Analytics. Electronics 2021, 10, 2326. https://doi.org/10.3390/electronics10192326
Awan MJ, Yasin A, Nobanee H, Ali AA, Shahzad Z, Nabeel M, Zain AM, Shahzad HMF. Fake News Data Exploration and Analytics. Electronics. 2021; 10(19):2326. https://doi.org/10.3390/electronics10192326
Chicago/Turabian StyleAwan, Mazhar Javed, Awais Yasin, Haitham Nobanee, Ahmed Abid Ali, Zain Shahzad, Muhammad Nabeel, Azlan Mohd Zain, and Hafiz Muhammad Faisal Shahzad. 2021. "Fake News Data Exploration and Analytics" Electronics 10, no. 19: 2326. https://doi.org/10.3390/electronics10192326
APA StyleAwan, M. J., Yasin, A., Nobanee, H., Ali, A. A., Shahzad, Z., Nabeel, M., Zain, A. M., & Shahzad, H. M. F. (2021). Fake News Data Exploration and Analytics. Electronics, 10(19), 2326. https://doi.org/10.3390/electronics10192326