
CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope


 ,
,  , and
, and 
Abstract
:1. Introduction
- This review assists readers in making sound decisions about their research work in the area of CNN for computer vision;
- This manuscript includes existing CNN architectures and their architectural limitations, leading it to design new architecture. Furthermore, it clearly explains the merits and demerits of almost all popular CNN variants;
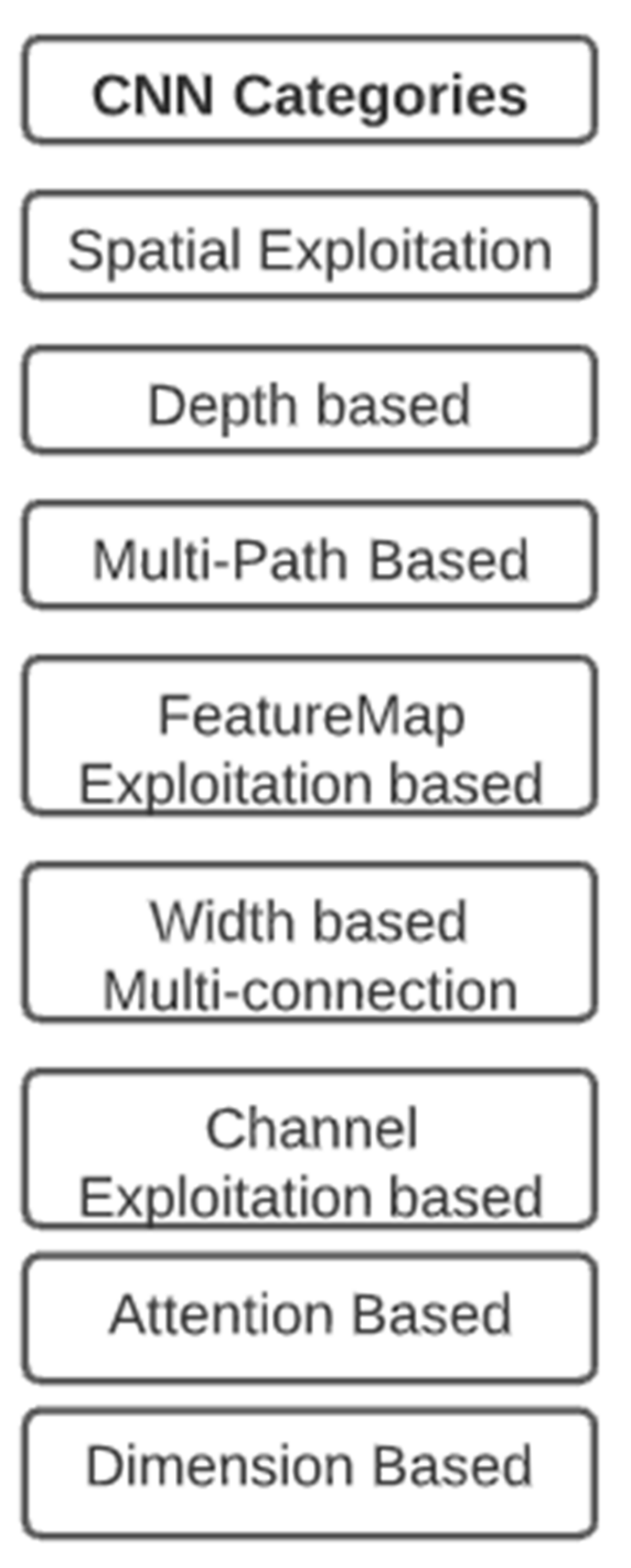
- It divides the CNN architecture into eight categories based on their implementation criteria, which is an exciting part of this survey paper;
- Various applications of CNN are also explained so that readers can also take on any other application area of CNN other than computer vision;
- It provides a clear listing of future research trends in the area of CNN for computer vision.
2. Literature Review
2.1. CNN Fundamentals
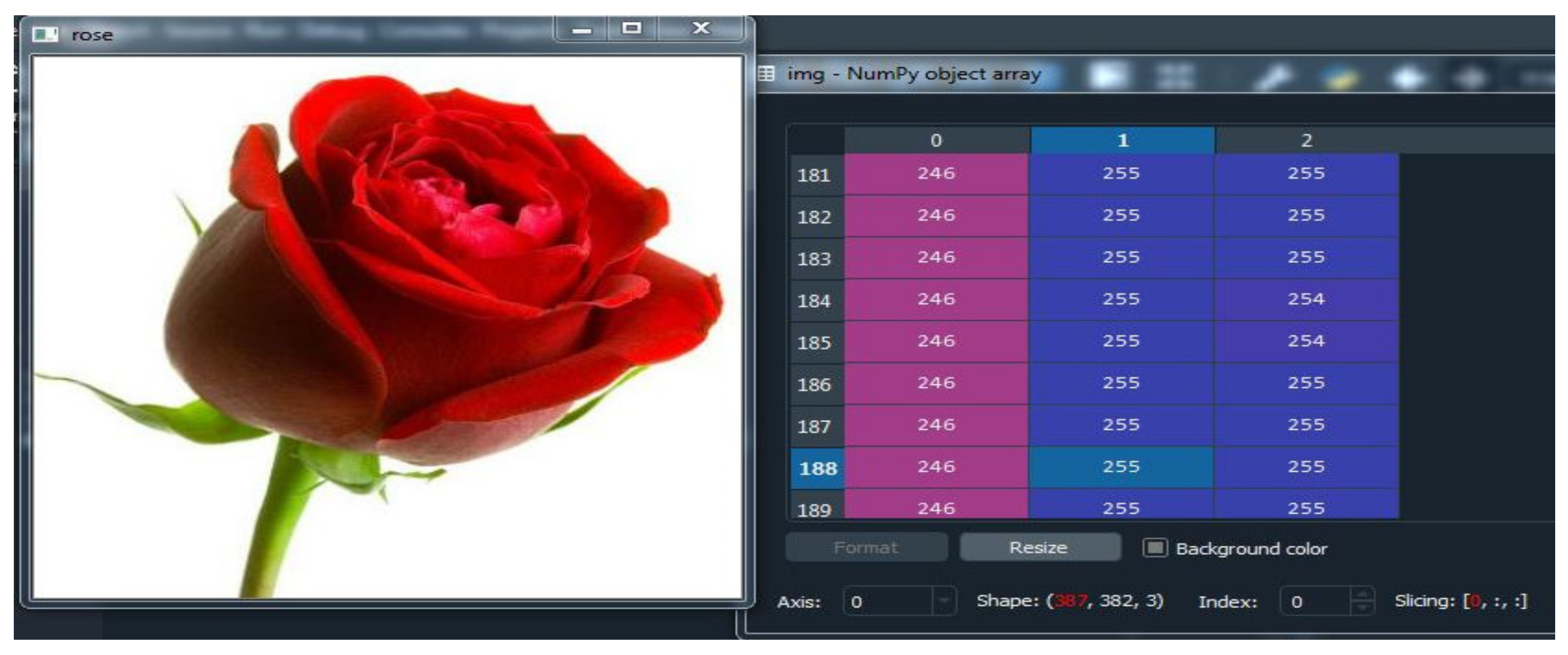
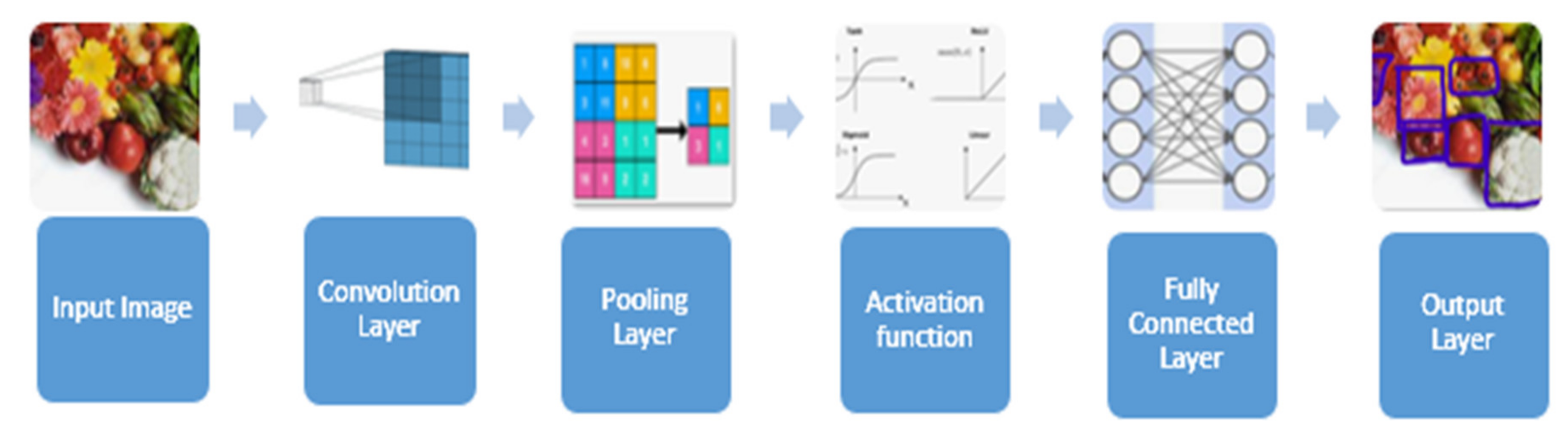
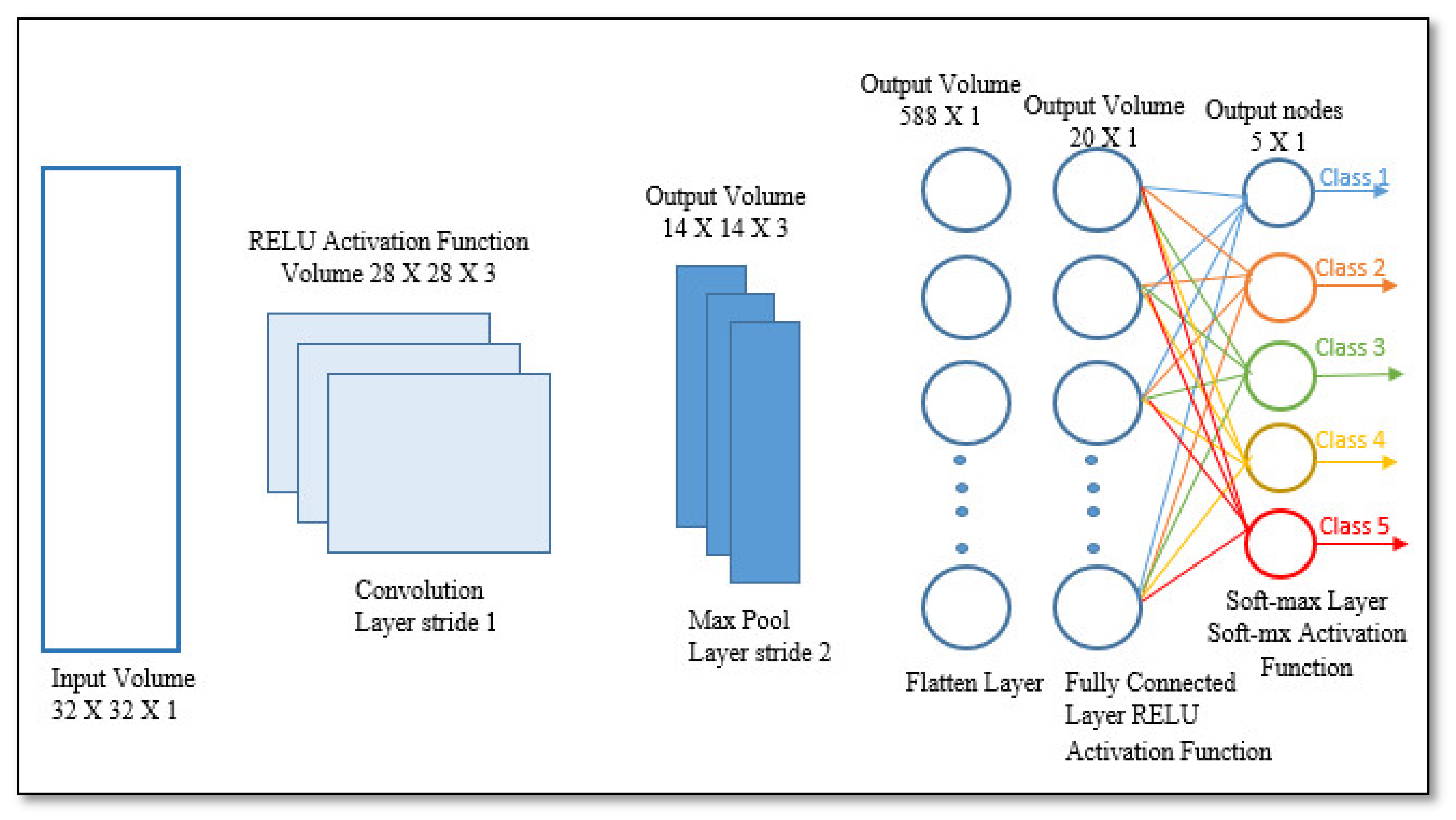
2.1.1. Input Image
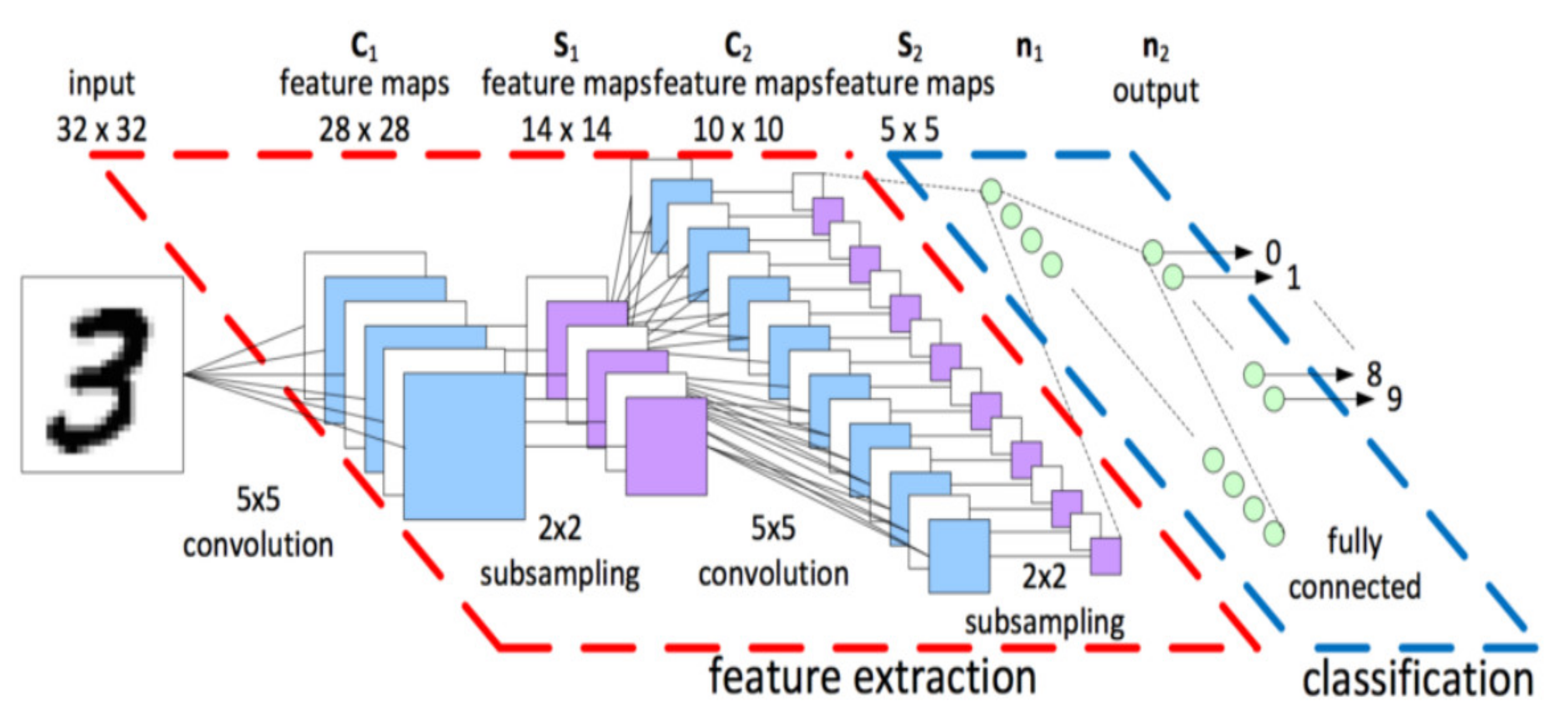
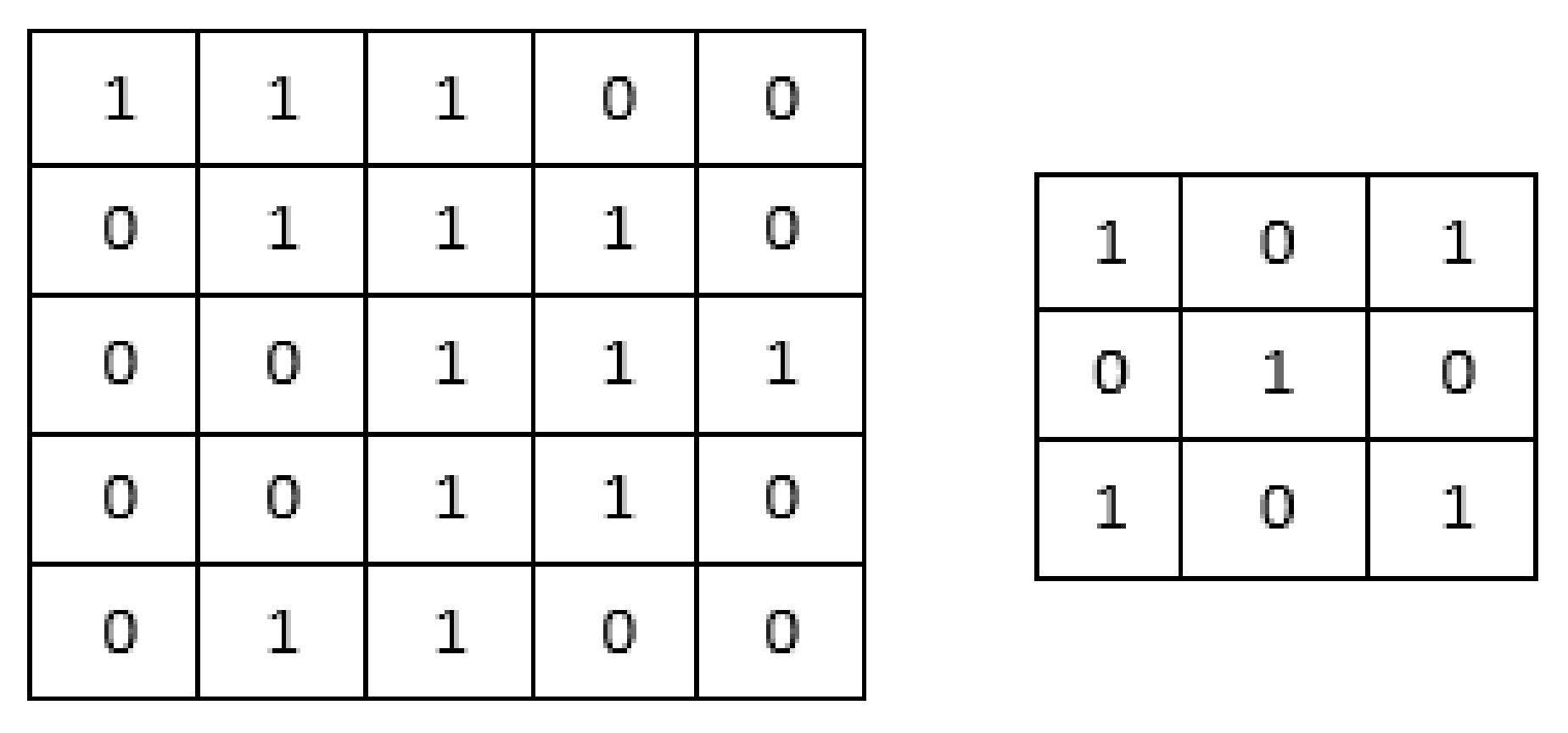
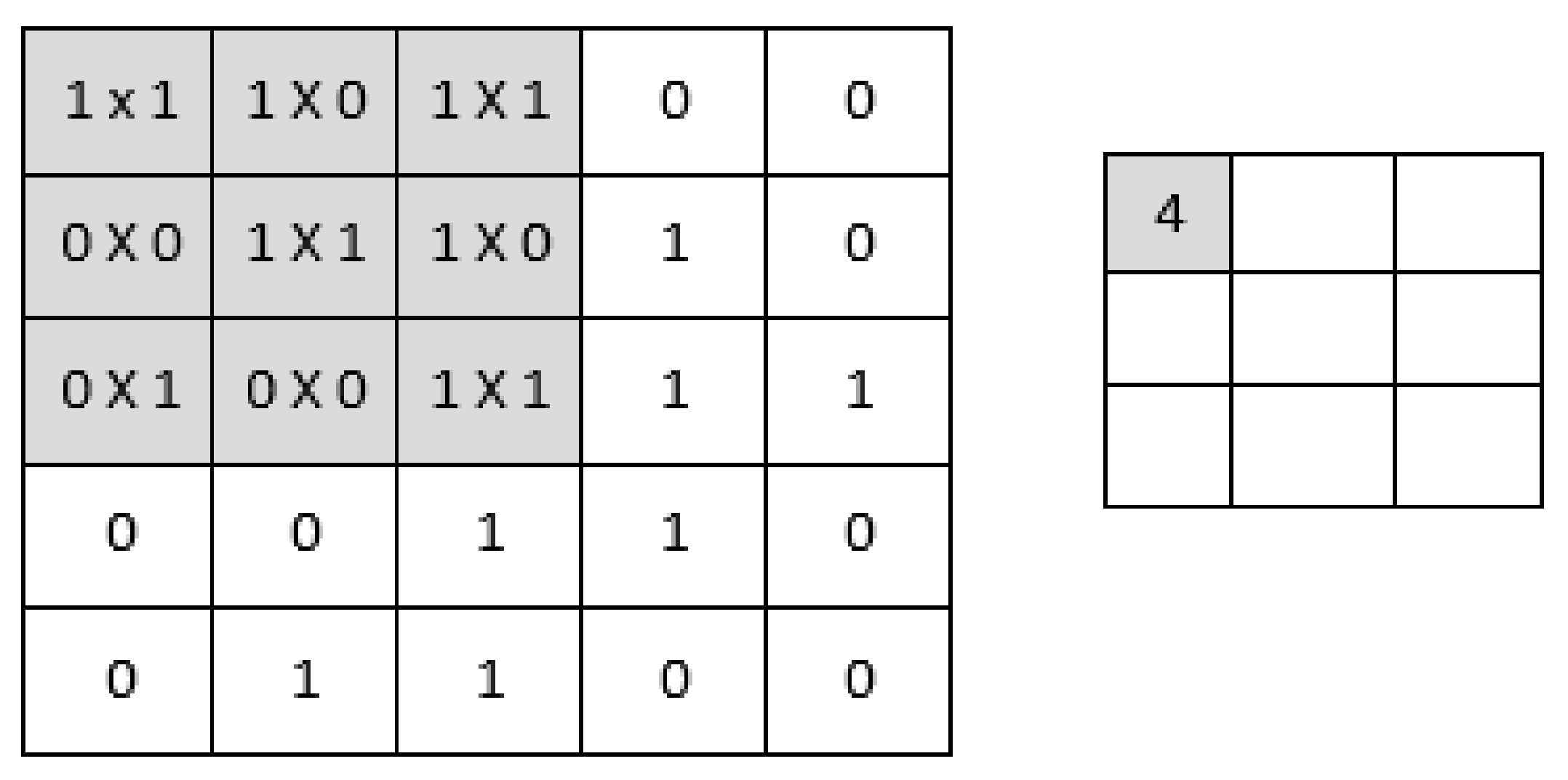
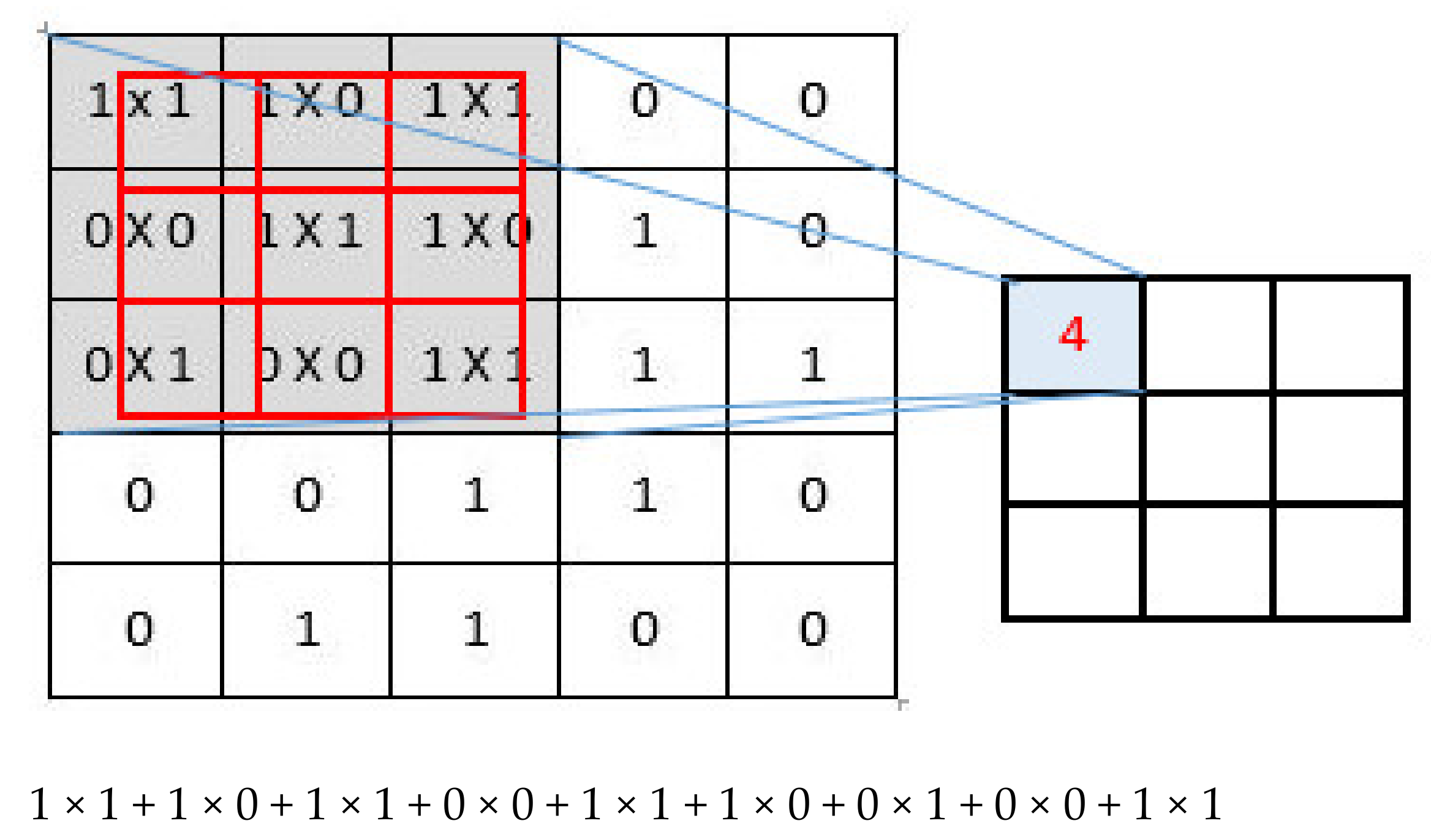
2.1.2. Convolution Layer
Feature Extraction
- A type in which the dimensionality of the convoluted feature is reduced in comparison to the input;
- A type in which the dimensionality is not reduced but is either enhanced or maintained. Padding is used to satisfy this task.
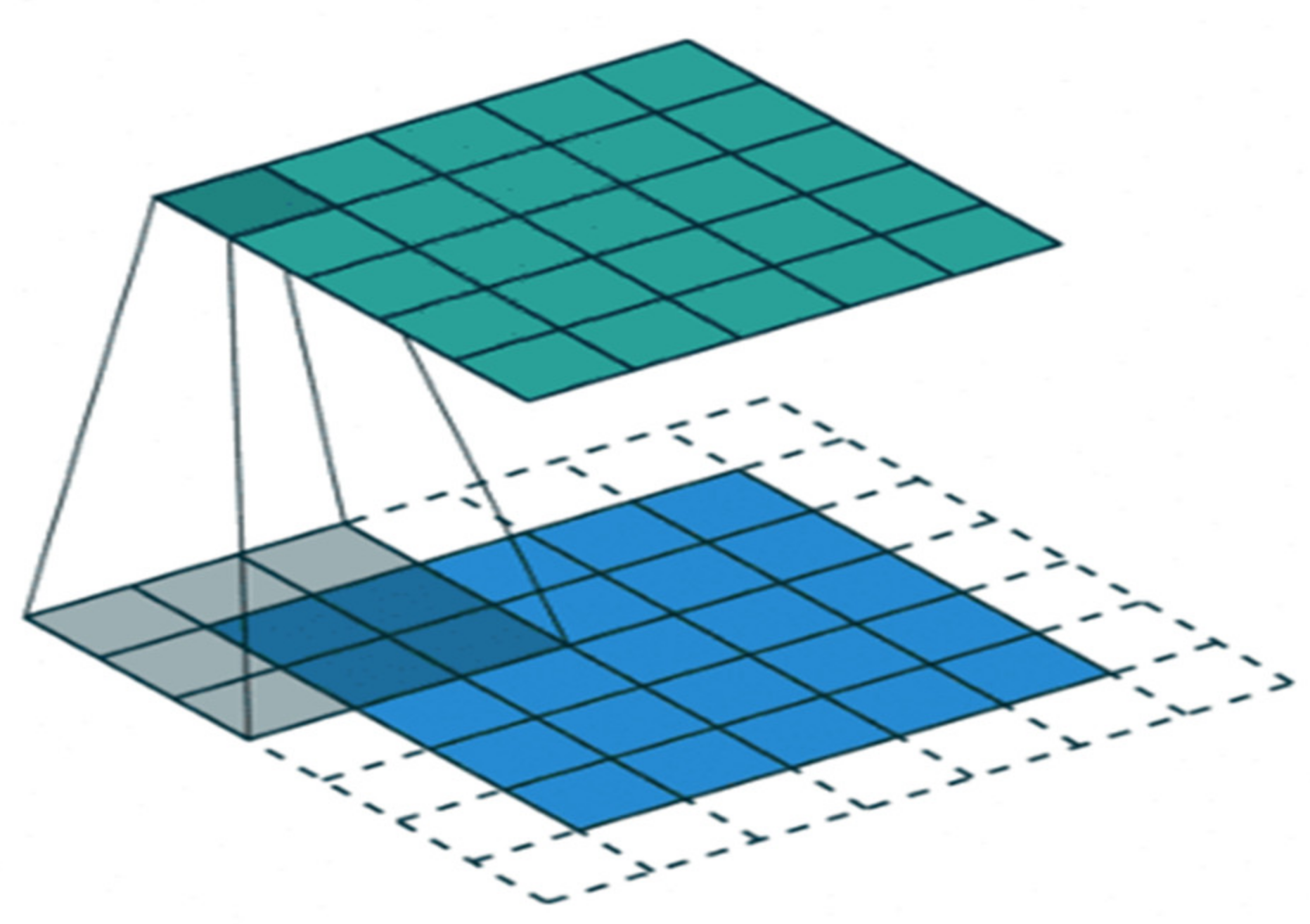
2.1.3. Pooling Layer
Maximum Pooling
Average Pooling
2.1.4. Nonlinearity Layer (Activation Function)
- Linear Activation FunctionThis uses function F(x) = CY. It takes the input and multiplies it with constant c (weight of each neuron), and produces the output signal proportional to the input. The linear function can be better than the step function, as it only give the yes or no answer and not the multiple answers.
- Non-linear Activation FunctionsIn modern neural networks, non-linear activation functions are used. They enable the model to build complicated mappings between the network’s inputs and outputs, which are critical for learning and modelling complex data, including images, video, audio, and non-linear or high-dimensional data sets.
2.1.5. Fully Connected Layer
2.2. Architectural Evolution of Deep CNNs
2.2.1. Spatial Exploitation-Based CNNs
2.2.2. CNN Based on Depth
2.2.3. CNNs with Multiple Paths
2.2.4. Feature-Map Exploitation Based CNNs
2.2.5. Multi-Connection Depending on the Width
2.2.6. Exploitation-Based Feature-Map (ChannelFMap) CNNs
2.2.7. CNNs That Are Based on Attention
2.2.8. Dimension-Based CNN
CNN Competitive Architectures
Mask R-CNN (2017)
G-RCNN (Graph Recognition Convolutional Neural Network) (2021)
MFRNet: (2021) (Multi-Level Feature Review Network)
DDGD: Disentangled Dynamic Graph Deep Generation (2021)
YOLOv4 (2020)
Net2Vis (2021)
Sketch-R2CNN (2021)
DeepThin (2021)
YOLOX: Exceeding YOLO Series in 2021 (2021)
ChebNet: Chebyshev Polynomial Based Graph Convolution (2016)
GCN: Graph Convolutional Network (2016)
FastGCN: Minibatch Training for Graph Convolutional Network (2018)
LanczosNet (2019)
SplineCNN (2018)
ECC: Edge-Conditioned Convolution (2017)
GAT: Graph Attention Network (2017) Ioffe 2013
3. CNN Application
3.1. Computer Vision and Associated Applications
3.2. Natural Language Processing (NLP)
3.3. Object Detection and Segmentation
3.4. Image Classification
3.5. Recognition of Speech
3.6. Video Processing
3.7. Images with Low Resolution
3.8. System with Limited Resources
3.9. CNN for Various Dimensional Data
3.10. Object Counting
4. CNN Challenges
- As deep CNNs are typically a black box, they may be challenging to comprehend and explain. As a result, verifying them can be challenging at times;
- According to Szegedy et al. (2013), training a CNN on noisy picture data can increase the misclassification error (Szegedy et al., 2014). Adding a small amount of random noise to the input image can deceive the network, causing the original and slightly agitated variant to be classified incorrectly;
- Each CNN layer is organized in such a manner that it extracts problem-specific information associated with the task automatically. In some of the cases, before classification, some jobs require knowledge of the behavior of features retrieved by deep CNN. Thus, the feature visualization concept in CNN may be helpful. Similarly, Hinton stated that lower levels should only pass on their knowledge to the relevant neurons of the following layer. Hinton presented an intriguing capsule network technique in this area [66];
- Deep CNNs use supervised learning processes, which require huge amount of annotated data to train the network. Humans, on the other hand, can learn from a few examples;
- The choice of hyper-parameters has a significant impact on the CNN performance. A slight change can influence the overall performance of a CNN in hyper-parameter values. As a result, selecting hyper-parameters with care is a critical design issue that must be addressed using an appropriate optimization technique;
- One of CNN’s limitations in vision-related jobs is that it rarely performs well when used to estimate an object’s pose, orientation, or location. In 2012, AlexNet attempted to address this difficulty by developing data augmentation, which solved the problem to some extent. In addition, data augmentation aids CNN in learning a variety of internal representations, potentially improving its performance.
5. Future Directions
- Ensemble learning is an upcoming research area in CNN. By extracting distinct semantic representations, the model can improve the generalization and resilience of many categories of images by combining multiple and diverse designs;
- In picture segmentation tasks, although it performs well, a CNN’s ability as a “generative learner” is limited. The use of CNNs’ generative learning capabilities throughout feature extraction phases can improve the model’s representational power. At the intermediate phases of CNN, fresh examples can be incorporated to improve the learning capability by using auxiliary learners (Khan et al., 2018a);
- Attention is a crucial process in the human visual system for acquiring information from images. Furthermore, the attention mechanism collects the crucial information from the image and stores its context in relation to the other visual components. In the future, the research could be conducted to preserve the spatial importance of objects and their distinguishing characteristics during subsequent stages of learning;
- It is observed that the learning capability of a CNN is mainly increased by increasing the network’s size, and this may be achieved by modern advanced hardware technologies, such as the Nvidia DGX-2 supercomputer. Nonetheless, training more deep and high-capacity CNN architectures consumes a substantial amount of memory and computing resources [68,69];
- The fundamental disadvantage of CNNs is their inability to be applied in real-time. Furthermore, the CNN is delayed in compact hardware due to its high computational cost, particularly in mobile systems. Therefore, various hardware accelerators are necessary for this scenario to reduce the execution time and power consumption. Thus far, numerous highly interesting accelerators have been presented in this field. Examples include Eyeriss, FPGA, and application-specific integrated circuits (Moons and Verhelst 2017);
- The activation function (e.g., RELU, sigmoid, etc.), number of neurons per layer, kernel size, layer organization, and other hyper-parameters of deep CNN are critical. There is a trade-off between the selection of hyper-parameters and the evaluation time. Hyper-parameter tuning is a time-consuming and intuitive process that cannot be specified explicitly. In this case, genetic algorithms can be used to automatically enhance hyper-parameters by conducting searches both at random and by directing searches based on previous results (Khan et al., 2019);
- Deep and broad CNN poses a significant difficulty in developing and executing them on devices with limited resources;
- Pipeline parallelism can be utilized to scale up in-depth CNN training to overcome hardware limitations. The Google group has presented GPipe, a distributed machine learning library that includes a model parallelism option for training. Pipelining could be utilized in the future to speed up the training of big models and scale performance without having to tune hyper parameters;
- Cloud-based platforms’ promise in creating computationally expensive CNN applications is projected to be fully realized in the future. Cloud computing helps the user to deal with large amounts of data and provides them with an exceptional computational efficiency at a reasonable cost. Amazon, Microsoft, Google, and IBM, among others, provide public cloud computing resources with superb scalability, speed, and flexibility for training-resource-intensive CNN designs. Furthermore, the cloud environment makes it simple for researchers and new practitioners to set up libraries;
- As CNN primarily uses image processing, implementing state-of-the-art CNN architectures on sequential data necessitates transforming 1D data to 2D data. The trend of using 1D-CNNs for sequential data is being advocated because of their excellent feature extraction capabilities and efficient computations with a small number of parameters [70];
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Liu, X. Recent progress in semantic image segmentation. Artifical Intell. Rev. 2019, 52, 1089–1106. [Google Scholar] [CrossRef] [Green Version]
- Deng, L.; Dong, Y. Deep Learning: Methods and Applications. In Foundations and Trends R in Signal Process; Now Publishers Inc.: Boston, MA, USA, 2013. [Google Scholar]
- LeCun, Y. Convolutional networks and applications. ISCAS IEEE 2010, 253–256. [Google Scholar] [CrossRef] [Green Version]
- Najafabadi, M.M. Deep learning applications and. J. Big Data 2015, 2, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y. Deep learning for visual understanding: A review. Neurocomupting 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Towards Datascience. Available online: https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6 (accessed on 27 July 2021).
- Towards Datascience. Available online: https://towardsdatascience.com/convolutional-neural-networks-explained-9cc5188c4939 (accessed on 29 July 2021).
- Bengio, Y. Deep learning of representations: Looking forward. In Proceedings of the International Conference on Statistical Language and Speech Processing, Tarragona, Spain, 29–31 July 2013; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Balázs, C.C. Approximation with Artificial Neural Networks. Master’s Thesis, Eötvös Loránd University, Budapest, Hungary, 2001. [Google Scholar]
- Delalleau, O. Shallow vs. deep sum-product networks. Adv. Neural Inf. Process. Syst. 2011, 666–674. [Google Scholar] [CrossRef]
- Szegedy, C. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:160207261v2. [Google Scholar]
- Ioffe, S. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Szegedy, C. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2015; IEEE: New York, NY, USA, 2016. [Google Scholar]
- Szegedy, C. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Simonyan, K. Very deep convolutional networks for large-scale image recognition. ILCR 2014, 75, 398–406. [Google Scholar]
- Dong, C. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Tong, T. Image super-resolution using dense skip connections. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hu, J. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kawaguchi, K. Effect of depth and width on local minima in deep learning. Neural Comput. 2019, 31, 1462–1498. [Google Scholar] [CrossRef]
- Hanin, B. Approximating Continuous Functions by ReLU Nets of Minimal width. arXiv 2017, arXiv:171011278. [Google Scholar]
- Nguyen, Q. Neural Networks Should Be Wide Enough to Learn Disconnected Decision Regions. arXiv 2018, arXiv:180300094. [Google Scholar]
- He, K. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Lin, C. GRCNN: Graph Recognition Convolutional Neural Network for Synthesizing Programs from Flow Charts. arXiv 2020, arXiv:2011.05980. [Google Scholar]
- Ma, D. MFRNet: A New CNN Architecture for Post-Processing and In-loop Filtering. arXiv 2020, arXiv:2007.07099v2. [Google Scholar]
- Zhang, W. Disentangled Dynamic Graph Deep Generation. arXiv 2021, arXiv:2010.07276v2. [Google Scholar]
- Alexey, B. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Aex, B. Net2Vis—A Visual Grammar for Automatically Generating Publication-Tailored CNN Architecture Visualizations. arXiv 2021, arXiv:1902.04394v6. [Google Scholar]
- Zou, C.; Zheng, Y.; Su, Q.; Fu, H. Chiew-Lan Tai Sketch-R2CNN: An Attentive Network for Vector Sketch Recognition. arXiv 2018, arXiv:1811.08170v1. [Google Scholar]
- Haque, W.A. DeepThin: A novel lightweight CNN architecture for traffic sign recognition without GPU requirements. In Expert Systems with Applications; Elseveir: Amsterdam, The Netherlands, 2021; Volume 168. [Google Scholar]
- Zheng, G. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430v2. [Google Scholar]
- Defferrard, M. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 3844–3852. [Google Scholar]
- Kipf, T.N. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Chen, J. Fastgcn: Fast learning with graph convolutional networks via importance sampling. arXiv 2018, arXiv:1801.10247. [Google Scholar]
- Liao, R. Lanczosnet: Multiscale deep graph convolutional networks. arXiv 2019, arXiv:1901.01484. [Google Scholar]
- Fey, M. Splinecnn: Ffast geometric deep learning with continuous b-spline kernels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–26 June 2018; pp. 869–877. [Google Scholar]
- Simonovsky, M. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 3693–3702. [Google Scholar]
- Velickovic, P. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Chouhan, N.; Khan, A.; Khan, H.-R. Network anomaly detection using channel boosted and residual learning based deep convolutional neural network. Appl. Soft Comput. 2019, 83, 105612. [Google Scholar] [CrossRef]
- Farfade, S.S. Multi-view Face Detection Using Deep Convolutional Neural Network. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval—ICMR ’15, Shanghai, China, 23–26 June 2015; ACM Press: New York, NY, USA, 2015; pp. 643–650. [Google Scholar]
- Zhang, K. Joint face detection and alignment using multitask cascaded convolutional networks. IeeexploreIeeeOrg 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Bulat, A.; Tzimiropoulos, G. Human Pose Estimation via Convolutional Part Heatmap Regression BT. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 717–732. [Google Scholar]
- Wang, X. Beyond Frame-level CNN: Saliency-Aware 3-D CNN With LSTM for Video Action Recognition. IEEE Signal Process. Lett. 2016, 24, 510–514. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. ICML Int. Conf. Mach. Learn. 2010, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:14042188. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation aware U model. In Proceedings of the IEEE International Conference On Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Kendall, A.; Cipolla, R.; Badrinarayanan, V. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A dataset for breast cancer histopathological image classification. IEEE Trans. Biomed. Eng. 2016, 63, 1455–1462. [Google Scholar] [CrossRef]
- Abdel-Hamid, O. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 4277–4280. [Google Scholar]
- Huang, K.Y. Speech Emotion Recognition Using Deep Neural Network Considering Verbal and Nonverbal Speech Sounds. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Lu, Z. The expressive power of neural networks: A view from the width. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6231–6239. [Google Scholar]
- Frizzi, S. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016-42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 877–882. [Google Scholar]
- Shi, Y. Sequential deep trajectory descriptor for action recognition with three-stream CNN. IEEE Trans. Multimed. 2017, 19, 1510–1520. [Google Scholar] [CrossRef] [Green Version]
- Ullah, A. Action recognition in video sequences using deep bi-directional LSTM with CNN features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Chevalier, M. LR-CNN for fine-grained classification with varying resolution. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3101–3105. [Google Scholar]
- Peng, X. Fine-to-coarse knowledge transfer for low-res image classification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3683–3687. [Google Scholar]
- Kawashima, T. Action recognition from extremely low-resolution thermal image sequence. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance, AVSS 2017, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Lee, S. Car Plate Recognition Based on CNN Using Embedded System with GPU. In Proceedings of the 2017 10th International Conference on Human System Interactions (HSI), Ulsan, Korea, 17–19 July 2017; pp. 239–241. [Google Scholar]
- Xie, W. An Energy-Efficient FPGA-Based Embedded System for CNN Application. In Proceedings of the IEEE International Conference on Electron Devices and Solid State Circuits (EDSSC), Shenzhen, China, 6–8 June 2018; pp. 1–2. [Google Scholar]
- Zhang, X. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Shakeel, M.F. Detecting Driver Drowsiness in Real Time through Deep Learning Based Object Detection. In Lecture Notes in Computer Science in Artificial Intelligence and Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Vinayakumar, R. Applying convolutional neural network for network intrusion detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics, ICACCI 2017, Udupi, India, 13–16 September 2017. [Google Scholar]
- Yıldırım, Ö. Arrhythmia detection using deep convolutional neural network with long duration ECG signals. Comput. Biol. Med. 2018, 102, 411–420. [Google Scholar] [CrossRef]
- De Vries, H. Deep learning vector quantization. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Hinton, G. Matrix capsules with EM routing. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Justus, D. Predicting the Computational Cost of Deep Learning Models. In Proceedings of the 2018 IEEE International Conference on Big Data Big Data, Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Sze, V. Efficient Processing of Deep Neural Networks: A Tutorial and Survey; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Madrazo, C.F. Application of a Convolutional Neural Network for image classification for the analysis of collisions in High Energy. EPJ Web Conf. 2019, 214, 06017. [Google Scholar] [CrossRef]
- Aurisano, A. A convolutional neural network neutrino event classifier. J. Instrum. 2016, 11, P09001. [Google Scholar] [CrossRef] [Green Version]
- Liu, W. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Patel, C.I.; Labana, D.; Pandya, S.; Modi, K.; Ghayvat, H.; Awais, M. Histogram of Oriented Gradient-Based Fusion of Features for Human Action Recognition in Action Video Sequences. Sensors 2020, 20, 7299. [Google Scholar] [CrossRef]
- Patel, C.I.; Garg, S.; Zaveri, T.; Banerjee, A.; Patel, R. Human action recognition using fusion of features for unconstrained video sequences. Comput. Electr. Eng. 2018, 70, 284–301. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
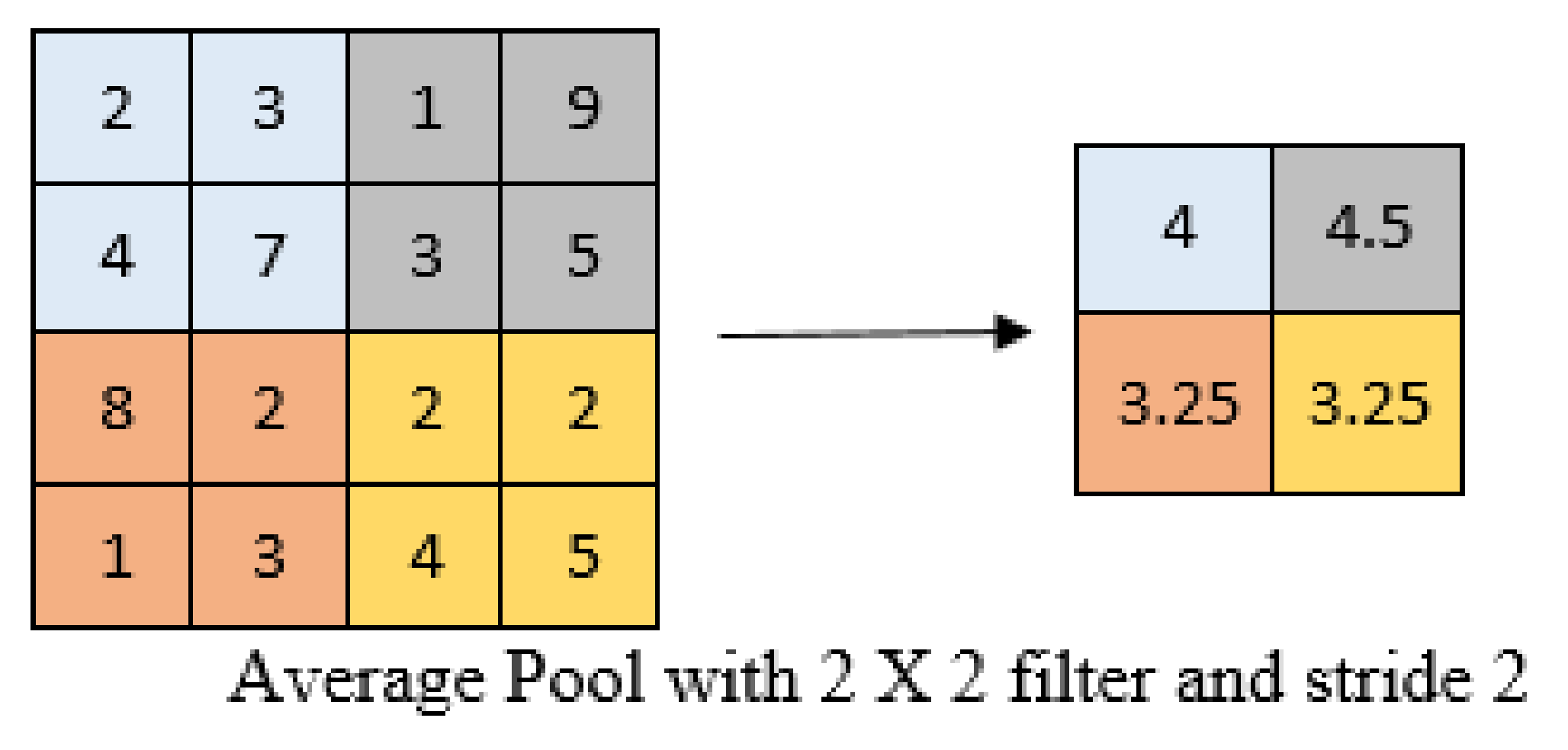{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture Name | Year | Category | Main Role | Parameter | Error Rate |
|---|---|---|---|---|---|
| LeNet | 1998 | Spatial Exploitation | It was the first prevalent CNN architecture | 0.060 M | dist]MNIST: 0.8 MNIST: 0.95 |
| AlexNet | 2012 | Spatial Exploitation |
GPUs NVIDIA GTX 580 | 60 M | ImageNet: 16.4 |
| ZfNet | 2014 | Spatial Exploitation | Provided visualization of intermediate layers | 60 M | ImageNet: 11.7 |
| VGG | 2014 | Spatial Exploitation | It used small-sized kernels and had homogeneous topology | 138 M | ImageNet: 7.3 |
| GoogleNet | 2015 | Spatial Exploitation | It was first architecture to introduce block concept. It used split transform and then merge idea | 4 M | ImageNet: 6.7 |
| InceptionV-3 | 2015 | Depth + Width | It was able to handle bottleneck issue and applied small filters rather than using large filters | 23.6 M | ImageNet: 3.5 Multi-Crop: 3.58 Single-Crop: 5.6 |
| Highway Network | 2015 | Depth + Multi-Path | First architecture to introduce the idea of multi path | 2.3 M | CIFAR-10: 7.76 |
| Inception V-4 | 2016 | Depth + Width | It used asymmetric filters with split transform and merge concept | 35 M | ImageNet: 4.01 |
| Inception ResNet | 2016 | Depth + Width + Multi-Path | It used residual link with split transform and merge concept | 55.8 M | ImageNet: 3.52 |
| ResNet | 2016 | Depth + Multi-Path | Identified mapping-based skip connections with residual learning | 25.6 M 1.7 M | ImageNet: 3.6 CIFAR-10: 6.43 |
| Deluge Net | 2016 | Multi-path | Allowed cross layer information flow in deep networks | 20.2 M | CIFAR-10: 3.76 CIFAR-100: 19.02 |
| Fractal Net | 2016 | Multi-path | Various path lengths interacted with each other without any residual connection | 38.6 M | CIFAR-10: 7.27 CIFAR-10+: 4.60 CIFAR-10++: 4.59 CIFAR-100: 28.20 CIFAR-100+: 22.49 CIFAR100++: 21.49 |
| WideResNet | 2016 | Width | Width was increased in comparison to depth | 36.5 M | CIFAR-10: 3.89 CIFAR-100: 18.85 |
| Xception | 2017 | Width | Depth-based convolution was followed by point-based convolution | 22.8 M | ImageNet: 0.055 |
| Residual Attention Neural Network | 2017 | Attention | First architecture to introduce attention mechanism | 8.6 M | CIFAR-10: 3.90 CIFAR-100: 20.4 ImageNet: 4.8 |
| ResNext | 2017 | Width | Introduced cardinality, homogeneous topology and grouped convolution | 68.1 M | CIFAR-10: 3.58 CIFAR-100: 17.31 ImageNet: 4.4 |
| Squeeze and Excittation Network | 2017 | Feature-Map Exploitation | Modeled interdependencies between feature maps | 27.5 M | ImageNet 2.3 |
| DenseNet | 2017 | Multi-Path | Crosslayer information flow | 25.6 M 25.6 M 15.3 M 15.3 M | CIFAR-10+: 3.46 CIFAR100+: 17.18 CIFAR-10: 5.19 CIFAR-100: 19.64 |
| PolyNet | 2017 | Width | Implemented structural diversity and poly-inception module and generalized residual unit | 92 M | ImageNet: Single: 4.25 Multi: 3.45 |
| PyramidalNet | 2017 | Width | Increased width gradually per unit | 116.4 M 27.0 M 27.0 M | ImageNet: 4.7 CIFAR-10: 3.48 CIFAR-100: 17.01 |
| Convolutional Block Attention Module (ResNeXt101 (32x4d) + CBAM) | 2018 | Attention | It exploited both spatial and feature map information | 48.96 M | ImageNet: 5.59 |
| Concurrent Spatial and Channel Excitation Mechanism | 2018 | Attention | Implemented spatial attention, feature-map attention, and concurrent placement of spatial and channel attention | - | MALC: 0.12 Visceral: 0.09 |
| Channel Boosted CNN | 2018 | Channel Boosting | Boosted original channels with additional information by artificial channels | - | - |
| Competitive Squeeze and Excitation Network CMPE_SE_WRN_28 | 2018 | Feature-Map Exploitation | Identity mapping and residual mapping were both used | 36.92 M 36.90 M | CIFAR-10: 3.58 CIFAR-100: 18.47 |
| EdgeNet | 2019 | Dimension Based | Introduced concept of visual intelligence at the edge. | - | - |
| ESPNetV2 | 2019 | Dimension Based | Used light-weight and power-efficient general purpose CNN | - | 68% accuracy |
| DiceNET | 2021 | Dimension Based | Introduced dimension-based CNN, including height, width, and depth | - | 75.1% Accuracy |
| Architecture | Merits | Demerits |
|---|---|---|
| LeNet |
|
|
| AlexNet |
|
|
| ZfNet |
|
|
| VGG |
|
|
| GoogleNet |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Inception-V3 |
|
|
| Highway Networks |
|
|
| Inception-ResNet |
| |
| Inception-V4 |
|
|
| ResNet |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Highway Networks | By introducing cross-layer connectivity, it mitigates the constraints of deep networks. | Because gates are data dependent, they may become expensive. |
| Resent |
|
|
| DenseNet |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Wide ResNet |
|
|
| Pyramidal Net |
|
|
| Xception |
|
|
| Inception |
|
|
| ResNeXt |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Squeeze and Excitation Network |
|
|
| Competitive Squeeze and Excitation Networks |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Channel Boosted CNN using Transfer Learning |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Residual Attention Neural Network |
|
|
| Convolutional Block Attention Module |
|
|
| Architecture | Merits | Demerits |
|---|---|---|
| Dice-Net |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. https://doi.org/10.3390/electronics10202470
Bhatt D, Patel C, Talsania H, Patel J, Vaghela R, Pandya S, Modi K, Ghayvat H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics. 2021; 10(20):2470. https://doi.org/10.3390/electronics10202470
Chicago/Turabian StyleBhatt, Dulari, Chirag Patel, Hardik Talsania, Jigar Patel, Rasmika Vaghela, Sharnil Pandya, Kirit Modi, and Hemant Ghayvat. 2021. "CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope" Electronics 10, no. 20: 2470. https://doi.org/10.3390/electronics10202470
APA StyleBhatt, D., Patel, C., Talsania, H., Patel, J., Vaghela, R., Pandya, S., Modi, K., & Ghayvat, H. (2021). CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics, 10(20), 2470. https://doi.org/10.3390/electronics10202470