
Semi-Supervised Machine Condition Monitoring by Learning Deep Discriminative Audio Features




Abstract
:1. Introduction
- We formulate a novel method for semi-supervised audio-driven AD, which is solely based on deep neural networks. The proposed method exploits data from distinct sources using a modified objective function to train deeper neural networks;
- We demonstrate the effectiveness of one-dimensional deep convolutional neural networks to learn useful descriptions of real-world machine equipment from their emitted sound by processing raw audio directly;
- We explore the use of multi-channel audio recordings to exploit spatial audio information and propose a naive front-end training strategy that enables the network to effectively learn spatial and spectro-temporal audio features;
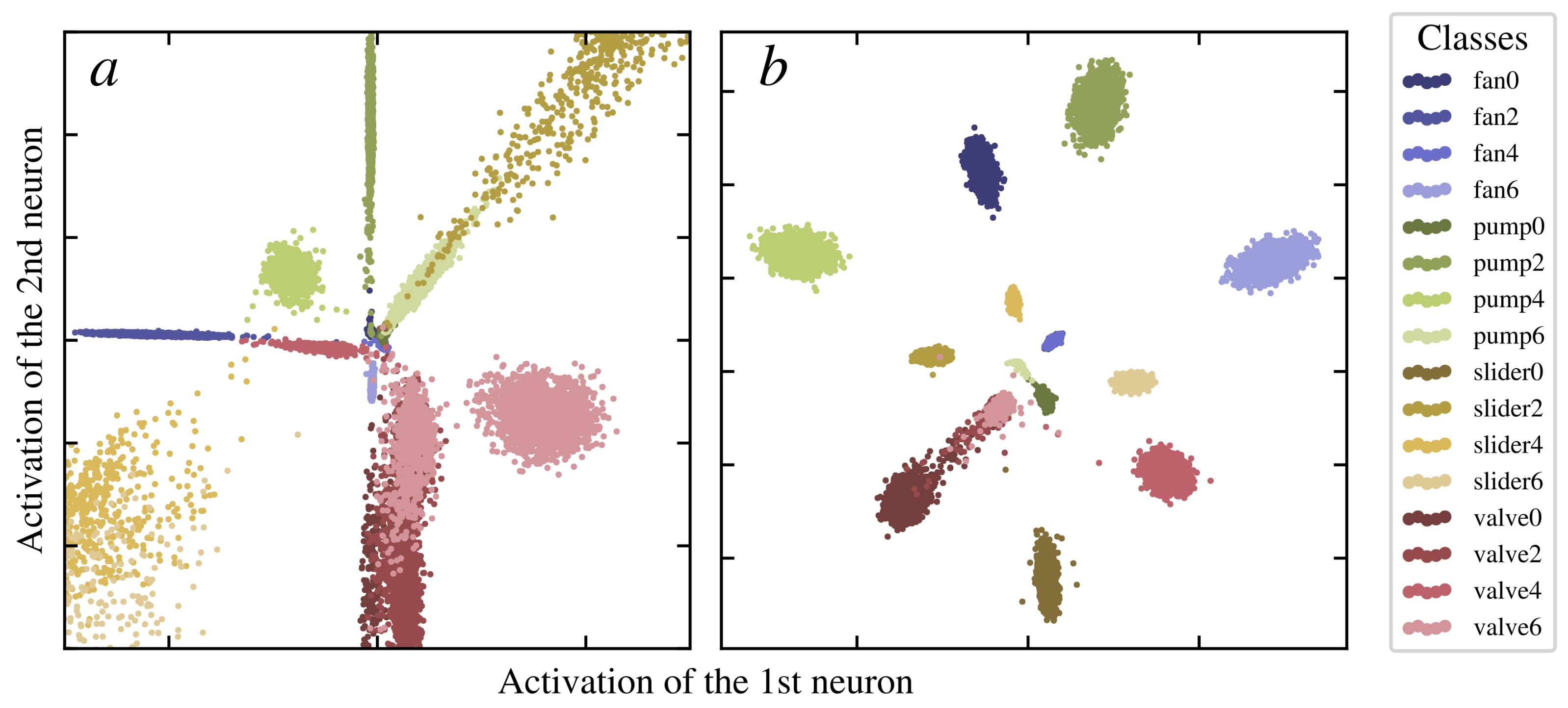
- We show that by jointly supervising a latent state of the deep convolutional neural network and the corresponding classification output, the model elicits highly discriminative features. This approach is applicable to a wide range of audio recognition tasks in the context of transfer learning.
2. Related Work
3. Materials and Methods
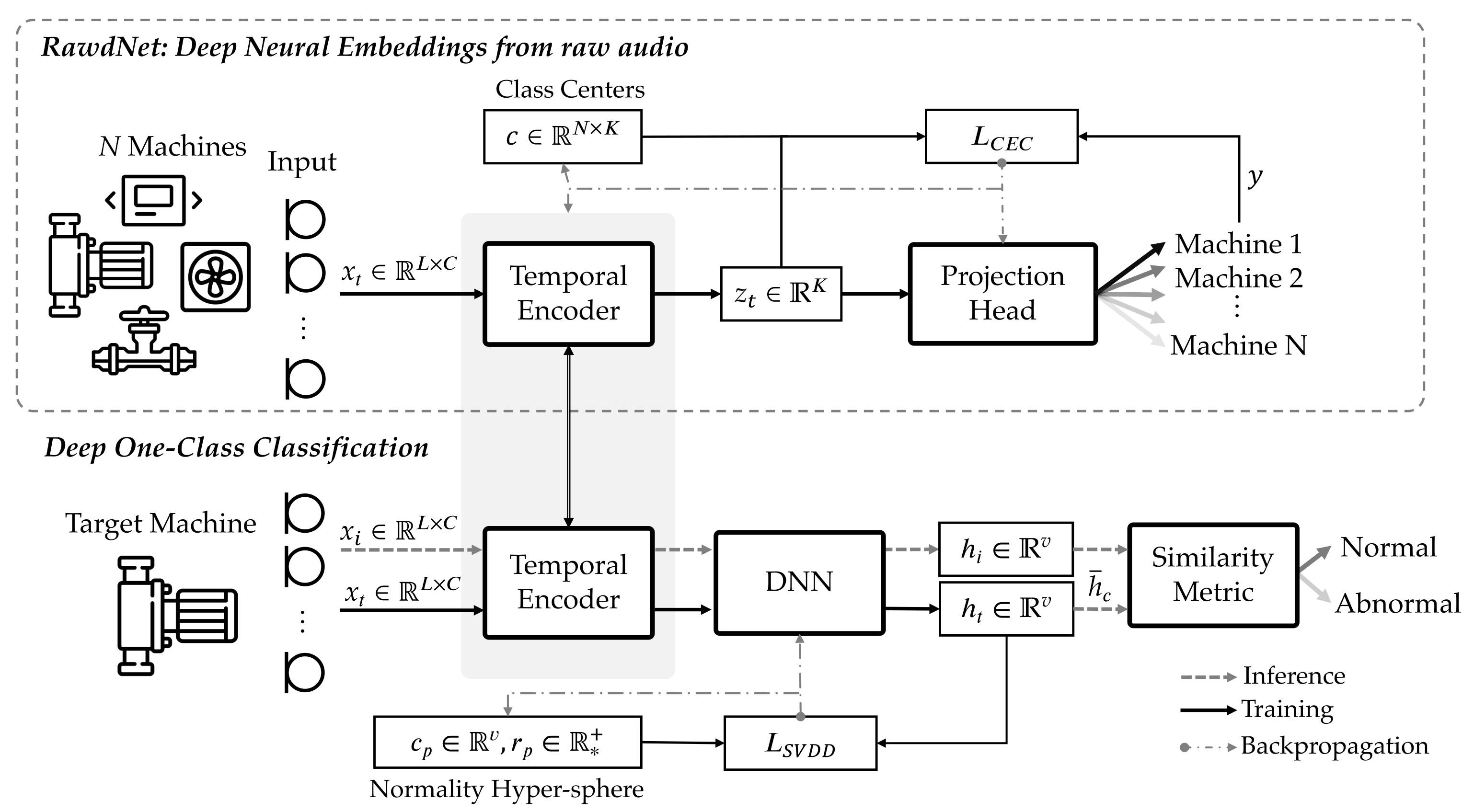
3.1. Overview and Motivation
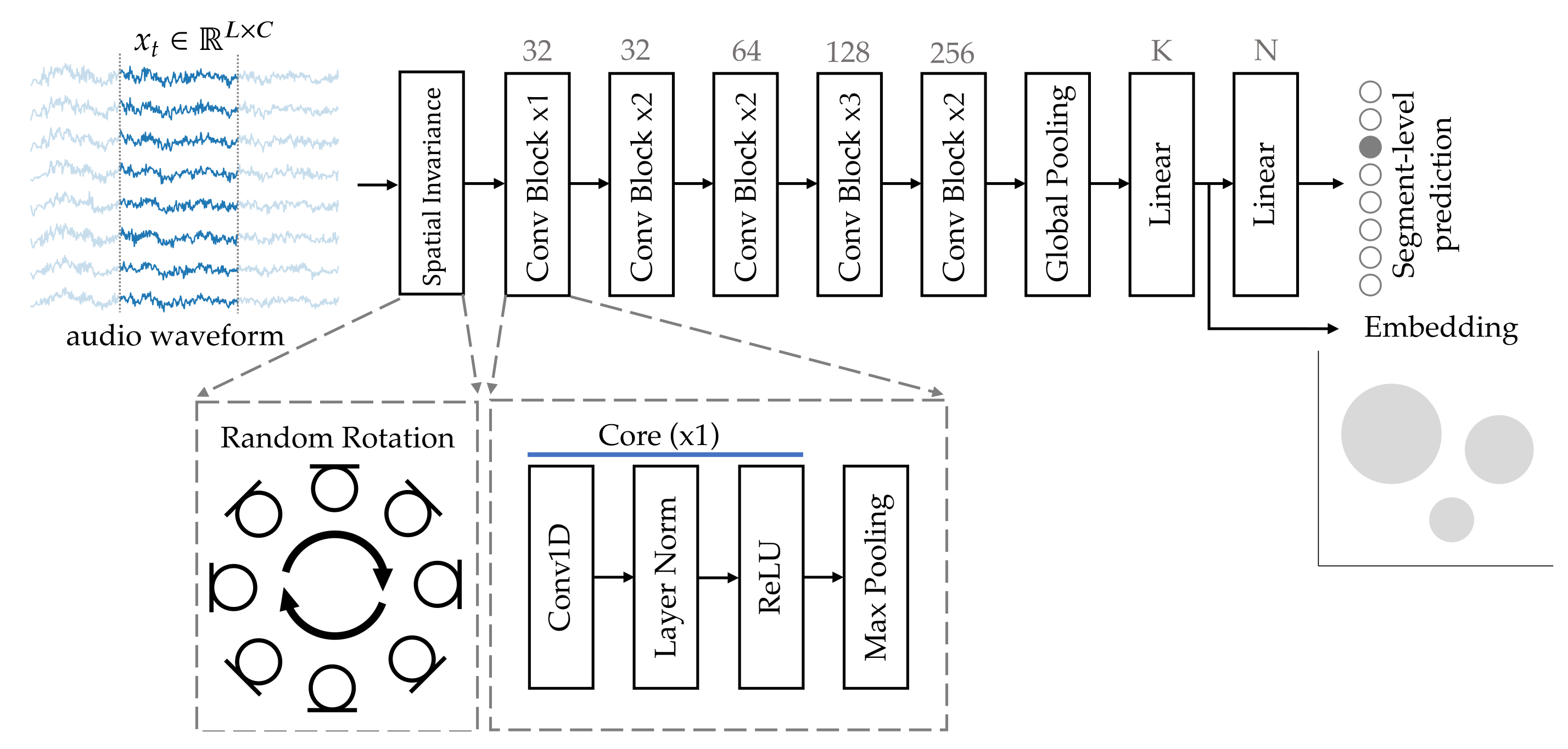
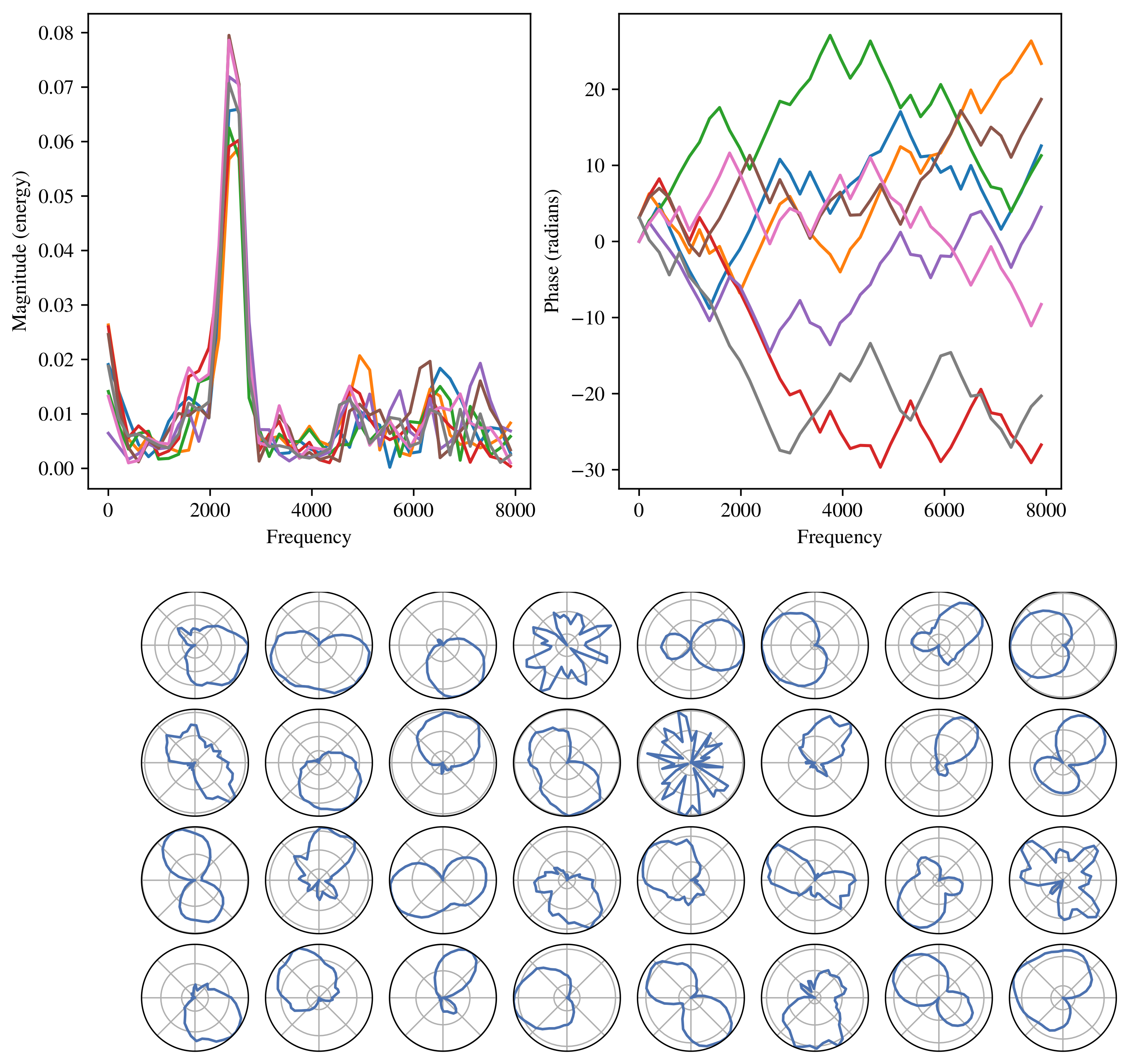
3.2. Discriminative Features from Multi-Channel Raw Audio
3.2.1. Training Objective
3.2.2. Data Augmentation for Spatial Invariance
3.3. Deep One-Class Classification
3.4. Experimental Setup
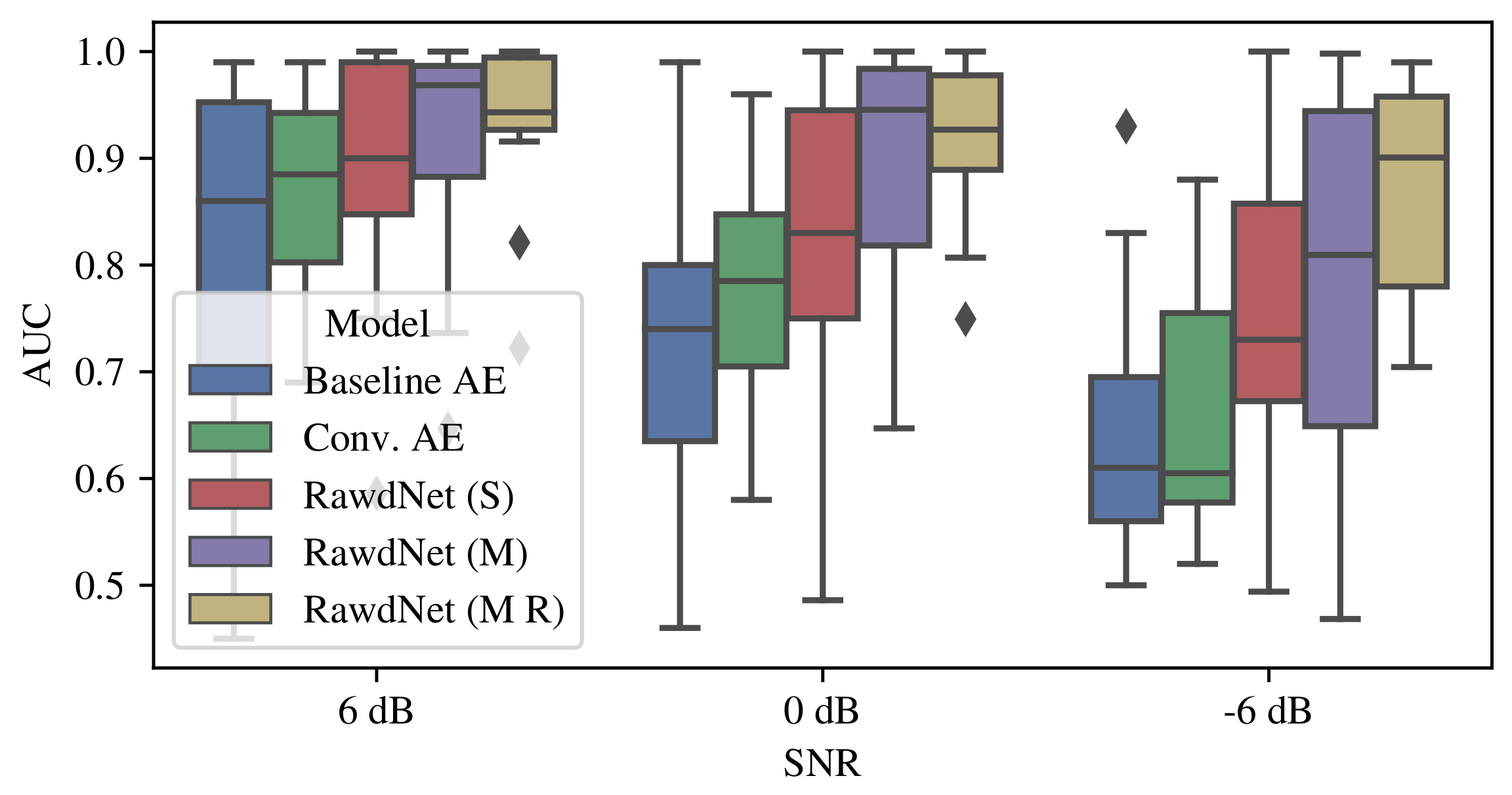
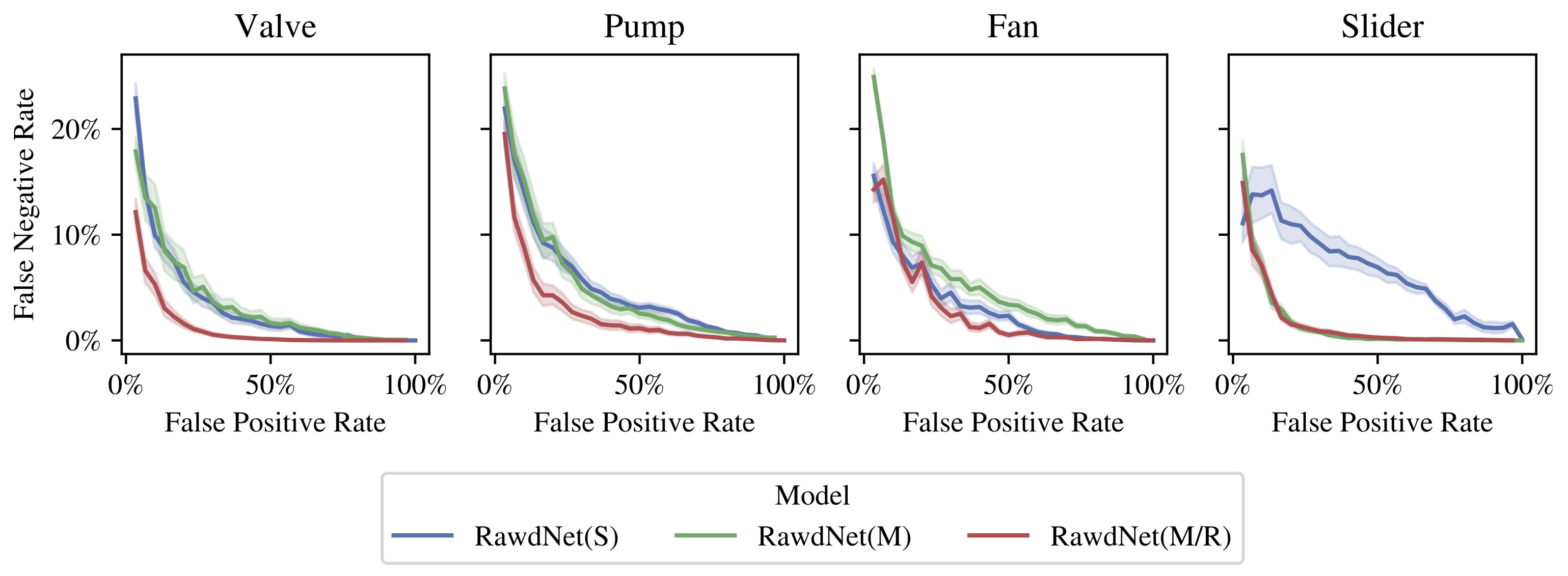
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Anomaly detection | AD |
| Condition monitoring | CM |
| Convolutional neural network | CNN |
| Support vector machine | SVMs |
| Support vector data description | SVDD |
References
- Singh, G.K. Induction machine drive condition monitoring and diagnostic research—A survey. Electr. Power Syst. Res. 2003, 64, 145–158. [Google Scholar] [CrossRef]
- Hamamoto, A.H.; Carvalho, L.F.; Sampaio, L.D.H.; Abrão, T.; Proença, M.L., Jr. Network anomaly detection system using genetic algorithm and fuzzy logic. Expert Syst. Appl. 2018, 92, 390–402. [Google Scholar] [CrossRef]
- Liu, J.; Djurdjanovic, D.; Marko, K.A.; Ni, J. A divide and conquer approach to anomaly detection, localization and diagnosis. Mech. Syst. Signal Process. 2009, 23, 2488–2499. [Google Scholar] [CrossRef]
- Purarjomandlangrudi, A.; Ghapanchi, A.H.; Esmalifalak, M. A data mining approach for fault diagnosis: An application of anomaly detection algorithm. Measurement 2014, 55, 343–352. [Google Scholar] [CrossRef]
- Henriquez, P.; Alonso, J.B.; Ferrer, M.A.; Travieso, C.M. Review of automatic fault diagnosis systems using audio and vibration signals. IEEE Trans. Syst. Man, Cybern. Syst. 2013, 44, 642–652. [Google Scholar] [CrossRef]
- Urbanek, J.; Barszcz, T.; Antoni, J. Integrated modulation intensity distribution as a practical tool for condition monitoring. Appl. Acoust. 2014, 77, 184–194. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tyagi, K.; Shah, B.; Kalra, P.K. Audio signature-based condition monitoring of internal combustion engine using FFT and correlation approach. IEEE Trans. Instrum. Meas. 2010, 60, 1217–1226. [Google Scholar] [CrossRef]
- Serin, G.; Sener, B.; Ozbayoglu, A.M.; Unver, H.O. Review of tool condition monitoring in machining and opportunities for deep learning. Int. J. Adv. Manuf. Technol. 2020, 109, 953–974. [Google Scholar] [CrossRef]
- Coraddu, A.; Oneto, L.; Ilardi, D.; Stoumpos, S.; Theotokatos, G. Marine dual fuel engines monitoring in the wild through weakly supervised data analytics. Eng. Appl. Artif. Intell. 2021, 100, 104179. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.A.; Gornitz, N.; Binder, A.; Muller, E.; Kloft, M. Deep support vector data description for unsupervised and semi-supervised anomaly detection. In Proceedings of the ICML 2019 Workshop on Uncertainty and Robustness in Deep Learning, Long Beach, CA, USA, 14–15 June 2019; pp. 9–15. [Google Scholar]
- Davy, M.; Desobry, F.; Gretton, A.; Doncarli, C. An online support vector machine for abnormal events detection. Signal Process. 2006, 86, 2009–2025. [Google Scholar] [CrossRef]
- Thoidis, I.; Giouvanakis, M.; Papanikolaou, G. Audio-based detection of malfunctioning machines using deep convolutional autoencoders. In Audio Engineering Society Convention 148; Audio Engineering Society: New York, NY, USA, 2020. [Google Scholar]
- Vrysis, L.; Tsipas, N.; Dimoulas, C.; Papanikolaou, G. Crowdsourcing audio semantics by means of hybrid bimodal segmentation with hierarchical classification. J. Audio Eng. Soc. 2016, 64, 1042–1054. [Google Scholar] [CrossRef]
- Görnitz, N.; Kloft, M.; Rieck, K.; Brefeld, U. Toward supervised anomaly detection. J. Artif. Intell. Res. 2013, 46, 235–262. [Google Scholar] [CrossRef]
- Zhang, M.; Wu, J.; Lin, H.; Yuan, P.; Song, Y. The application of one-class classifier based on CNN in image defect detection. Procedia Comput. Sci. 2017, 114, 341–348. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Noto, K.; Brodley, C.; Slonim, D. FRaC: A feature-modeling approach for semi-supervised and unsupervised anomaly detection. Data Min. Knowl. Discov. 2012, 25, 109–133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, Q.; Yan, R.; Kong, F.; Du, R. Machine condition monitoring using principal component representations. Mech. Syst. Signal Process. 2009, 23, 446–466. [Google Scholar] [CrossRef]
- Diaz-Rozo, J.; Bielza, C.; Larrañaga, P. Machine-tool condition monitoring with Gaussian mixture models-based dynamic probabilistic clustering. Eng. Appl. Artif. Intell. 2020, 89, 103434. [Google Scholar] [CrossRef]
- Borghesi, A.; Bartolini, A.; Lombardi, M.; Milano, M.; Benini, L. A semisupervised autoencoder-based approach for anomaly detection in high performance computing systems. Eng. Appl. Artif. Intell. 2019, 85, 634–644. [Google Scholar] [CrossRef]
- Sarmadi, H.; Karamodin, A. A novel anomaly detection method based on adaptive Mahalanobis-squared distance and one-class kNN rule for structural health monitoring under environmental effects. Mech. Syst. Signal Process. 2020, 140, 106495. [Google Scholar] [CrossRef]
- De Benito-Gorron, D.; Lozano-Diez, A.; Toledano, D.T.; Gonzalez-Rodriguez, J. Exploring convolutional, recurrent, and hybrid deep neural networks for speech and music detection in a large audio dataset. EURASIP J. Audio Speech Music Process. 2019, 2019, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Poveda-Martínez, P.; Ramis-Soriano, J. A comparison between psychoacoustic parameters and condition indicators for machinery fault diagnosis using vibration signals. Appl. Acoust. 2020, 166, 1–13. [Google Scholar] [CrossRef]
- Li, W.; Parkin, R.M.; Coy, J.; Gu, F. Acoustic based condition monitoring of a diesel engine using self-organising map networks. Appl. Acoust. 2002, 63, 699–711. [Google Scholar] [CrossRef]
- He, W.; Zi, Y.; Chen, B.; Wu, F.; He, Z. Automatic fault feature extraction of mechanical anomaly on induction motor bearing using ensemble super-wavelet transform. Mechan. Syst. Signal Process. 2015, 54–55, 457–480. [Google Scholar] [CrossRef]
- Glowacz, A. Acoustic based fault diagnosis of three-phase induction motor. Appl. Acoust. 2018, 137, 82–89. [Google Scholar] [CrossRef]
- Zhou, F.; Han, J.; Yang, X. Multivariate hierarchical multiscale fluctuation dispersion entropy: Applications to fault diagnosis of rotating machinery. Appl. Acoust. 2021, 182, 108271. [Google Scholar] [CrossRef]
- Yao, J.; Liu, C.; Song, K.; Feng, C.; Jiang, D. Fault diagnosis of planetary gearbox based on acoustic signals. Appl. Acoust. 2021, 181, 108151. [Google Scholar] [CrossRef]
- Loutas, T.H.; Sotiriades, G.; Kalaitzoglou, I.; Kostopoulos, V. Condition monitoring of a single-stage gearbox with artificially induced gear cracks utilizing on-line vibration and acoustic emission measurements. Appl. Acoust. 2009, 70, 1148–1159. [Google Scholar] [CrossRef]
- Kumar, A.; Gandhi, C.P.; Zhou, Y.; Kumar, R.; Xiang, J. Improved deep convolution neural network (CNN) for the identification of defects in the centrifugal pump using acoustic images. Appl. Acoust. 2020, 167, 107399. [Google Scholar] [CrossRef]
- Xia, S.; Zhang, J.; Ye, S.; Xu, B.; Xiang, J.; Tang, H. A mechanical fault detection strategy based on the doubly iterative empirical mode decomposition. Appl. Acoust. 2019, 155, 346–357. [Google Scholar] [CrossRef]
- Gowid, S.; Dixon, R.; Ghani, S. A novel robust automated FFT-based segmentation and features selection algorithm for acoustic emission condition based monitoring systems. Appl. Acoust. 2015, 88, 66–74. [Google Scholar] [CrossRef]
- Li, Z.; Li, J.; Wang, Y.; Wang, K. A deep learning approach for anomaly detection based on SAE and LSTM in mechanical equipment. Int. J. Adv. Manuf. Technol. 2019, 103, 499–510. [Google Scholar] [CrossRef]
- Potočnik, P.; Olmos, B.; Vodopivec, L.; Susič, E.; Govekar, E. Condition classification of heating systems valves based on acoustic features and machine learning. Appl. Acoust. 2021, 174, 107736. [Google Scholar] [CrossRef]
- Amarnath, M. Local fault assessment in a helical geared system via sound and vibration parameters using multiclass SVM Classifiers. Arch. Acoust. 2016, 41, 559–571. [Google Scholar] [CrossRef] [Green Version]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. Continuous Speech Emotion Recognition with Convolutional Neural Networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Amiriparian, S.; Gerczuk, M.; Ottl, S.; Stappen, L.; Baird, A.; Koebe, L.; Schuller, B. Towards cross-modal pre-training and learning tempo-spatial characteristics for audio recognition with convolutional and recurrent neural networks. EURASIP J. Audio Speech Music Process. 2020, 2020, 19. [Google Scholar] [CrossRef]
- Vrysis, L.; Tsipas, N.; Thoidis, I.; Dimoulas, C. 1D/2D Deep CNNs vs. Temporal Feature Integration for General Audio Classification. J. Audio Eng. Soc. 2020, 68, 66–77. [Google Scholar] [CrossRef]
- Oh, D.Y.; Yun, I.D. Residual error based anomaly detection using auto-encoder in SMD machine sound. Sensors 2018, 18, 1308. [Google Scholar] [CrossRef] [Green Version]
- Koizumi, Y.; Saito, S.; Uematsu, H.; Kawachi, Y.; Harada, N. Unsupervised Detection of Anomalous Sound Based on Deep Learning and the Neyman-Pearson Lemma. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 212–224. [Google Scholar] [CrossRef] [Green Version]
- Vrysis, L.; Tsipas, N.; Dimoulas, C.; Papanikolaou, G. Extending Temporal Feature Integration for Semantic Audio Analysis. In Audio Engineering Society Convention 142; Audio Engineering Society: New York, NY, USA, 2017. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep one-class classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Zgarni, S.; Keskes, H.; Braham, A. Nested SVDD in DAG SVM for induction motor condition monitoring. Eng. Appl. Artif. Intell. 2018, 71, 210–215. [Google Scholar] [CrossRef]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Olson, C.C.; Judd, K.P.; Nichols, J.M. Manifold learning techniques for unsupervised anomaly detection. Expert Syst. Appl. 2018, 91, 374–385. [Google Scholar] [CrossRef]
- Liu, Y.; He, L.; Liu, J.; Johnson, M.T. Introducing phonetic information to speaker embedding for speaker verification. EURASIP J. Audio Speech Music Process. 2019, 2019, 19. [Google Scholar] [CrossRef] [Green Version]
- Hershey, J.R.; Chen, Z.; Le Roux, J.; Watanabe, S. Deep clustering: Discriminative embeddings for segmentation and separation. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 31–35. [Google Scholar]
- Koizumi, Y.; Yasuda, M.; Murata, S.; Saito, S.; Uematsu, H.; Harada, N. Spidernet: Attention network for one-shot anomaly detection in sounds. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 281–285. [Google Scholar]
- Perera, P.; Patel, V.M. Learning deep features for one-class classification. IEEE Trans. Image Process. 2019, 28, 5450–5463. [Google Scholar] [CrossRef] [Green Version]
- Kwak, B.I.; Han, M.L.; Kim, H.K. Cosine similarity based anomaly detection methodology for the CAN bus. Expert Syst. Appl. 2021, 166, 114066. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Ranzato, M.; Boureau, Y.L.; LeCun, Y. Sparse feature learning for deep belief networks. Adv. Neural Inf. Process. Syst. 2007, 20, 1185–1192. [Google Scholar]
- Vrysis, L.; Hadjileontiadis, L.; Thoidis, I.; Dimoulas, C.; Papanikolaou, G. Enhanced Temporal Feature Integration in Audio Semantics. J. Audio Eng. Soc. 2021, 68, 66–77. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Qi, C.; Su, F. Contrastive-center loss for deep neural networks. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 2851–2855. [Google Scholar]
- Yang, J.; Xu, L.; Ren, B.; Ji, Y. Discriminative features based on modified log magnitude spectrum for playback speech detection. EURASIP J. Audio Speech Music Process. 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 499–515. [Google Scholar]
- Li, N.; Tuo, D.; Su, D.; Li, Z.; Yu, D.; Tencent, A.; Deep Discriminative Embeddings for Duration Robust Speaker Verification. Interspeech. 2018, pp. 2262–2266. Available online: https://ai.tencent.com/ailab/media/publications/DeepDiscriminativeEmbeddingsforDurationRobustSpeakerVeri%EF%AC%81cation.pdf (accessed on 30 September 2021).
- Politis, A.; Vilkamo, J.; Pulkki, V. Sector-Based Parametric Sound Field Reproduction in the Spherical Harmonic Domain. IEEE J. Sel. Top. Signal Process. 2015, 9, 852–866. [Google Scholar] [CrossRef]
- Chen, J.C.; Yao, K.; Hudson, R.E. Source localization and beamforming. IEEE Signal Process. Mag. 2002, 19, 30–39. [Google Scholar] [CrossRef] [Green Version]
- Vryzas, N.; Dimoulas, C.A.; Papanikolaou, G.V. Embedding sound localization and spatial audio interaction through coincident microphones arrays. In Proceedings of the Audio Mostly 2015 on Interaction With Sound, Thessaloniki, Greece, 7–9 October 2015; pp. 1–8. [Google Scholar]
- Vryzas, N.; Kotsakis, R.; Dimoulas, C.A.; Kalliris, G. Investigating Multimodal Audiovisual Event Detection and Localization. In Proceedings of the Audio Mostly 2016, Norrkoping, Sweden, 4–6 October 2016; pp. 97–104. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Madden, M.G. One-class support vector machine calibration using particle swarm optimisation. In Proceedings of the 18th Irish Conference on Artificial Intelligence, Dublin, Ireland, 29–31 August 2007; pp. 9–100. [Google Scholar]
- Purohit, H.; Tanabe, R.; Ichige, K.; Endo, T.; Nikaido, Y.; Suefusa, K.; Kawaguchi, Y. MIMII dataset: Sound dataset for malfunctioning industrial machine investigation and inspection. In Proceedings of the Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019; p. 209. [Google Scholar]
- Koizumi, Y.; Murata, S.; Harada, N.; Saito, S.; Uematsu, H. SNIPER: Few-shot learning for anomaly detection to minimize false-negative rate with ensured true-positive rate. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 915–919. [Google Scholar]
- Pons, J.; Serrà, J.; Serra, X. Training neural audio classifiers with few data. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 16–20. [Google Scholar]
- Politis, A.; Laitinen, M.V.; Ahonen, J.; Pulkki, V. Parametric spatial audio processing of spaced microphone array recordings for multichannel reproduction. J. Audio Eng. Soc. 2015, 63, 216–227. [Google Scholar] [CrossRef]
- Vrysis, L.; Thoidis, I.; Dimoulas, C.; Papanikolaou, G. Experimenting with 1D CNN Architectures for Generic Audio Classification. In Audio Engineering Society Convention 148; Audio Engineering Society: New York, NY, USA, 2020. [Google Scholar]
- Chakrabarty, D.; Elhilali, M. Abnormal sound event detection using temporal trajectories mixtures. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 216–220. [Google Scholar]
- Thoidis, I.; Vrysis, L.; Pastiadis, K.; Markou, K.; Papanikolaou, G. Investigation of an Encoder-Decoder LSTM model on the enhancement of speech intelligibility in noise for hearing impaired listeners. In Proceedings of the AES 146th International Convention, Dublin, Ireland, 20–23 March 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine | Valve | Pump | Fan | Slider | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SNR (dB) | 6 | 0 | −6 | 6 | 0 | −6 | 6 | 0 | −6 | 6 | 0 | −6 |
| AE [66] | 67.0 | 61.3 | 55.5 | 80.5 | 70.5 | 66.0 | 91.3 | 82.0 | 68.8 | 87.8 | 78.0 | 70.0 |
| Conv. AE [12] | 75.3 | 67.8 | 57.5 | 88.3 | 79.8 | 69.3 | 95.5 | 84.3 | 69.8 | 88.8 | 80.5 | 69.0 |
| RawdNet(S)-OCSVM | 90.6 | 87.7 | 85.8 | 89.2 | 86.7 | 71.4 | 89.2 | 80.9 | 60.0 | 74.4 | 74.0 | 62.3 |
| RawdNet(S)-DOC | 89.3 | 85.8 | 85.0 | 92.0 | 83.8 | 76.0 | 91.5 | 86.3 | 74.5 | 83.2 | 76.4 | 65.4 |
| RawdNet(M)-OCSVM | 80.4 | 77.8 | 59.3 | 87.5 | 78.9 | 71.8 | 82.5 | 75.2 | 78.7 | 85.5 | 84.2 | 83.7 |
| RawdNet(M)-DOC | 88.8 | 84.6 | 83.6 | 90.5 | 89.6 | 71.3 | 86.4 | 84.4 | 75.5 | 99.2 | 98.3 | 88.4 |
| RawdNet(M/R)-OCSVM | 75.8 | 65.8 | 66.7 | 73.5 | 63.8 | 55.9 | 81.9 | 83.3 | 86.9 | 98.0 | 95.3 | 85.7 |
| RawdNet(M/R)-DOC | 96.7 | 94.0 | 90.5 | 90.3 | 87.9 | 80.5 | 90.1 | 88.4 | 83.8 | 97.8 | 97.5 | 94.3 |
| Machine (Type-ID) | Fan-02 | Pump-06 | Slider-02 | |
|---|---|---|---|---|
| Koizumi et al. [48] | AE [40] | 52.8 | 40.3 | 85.9 |
| MSE [67] | 91.2 | 43.8 | 94.7 | |
| PROTOnet [68] | 68.3 | 46.0 | 91.1 | |
| SPIDERnet | 95.8 | 88.0 | 92.5 | |
| Ours | RawdNet(S)-DOC | 75.0 | 90.0 | 79.0 |
| RawdNet(M)-DOC | 83.4 | 95.0 | 94.1 | |
| RawdNet(M/R)-DOC | 80.7 | 95.0 | 100.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thoidis, I.; Giouvanakis, M.; Papanikolaou, G. Semi-Supervised Machine Condition Monitoring by Learning Deep Discriminative Audio Features. Electronics 2021, 10, 2471. https://doi.org/10.3390/electronics10202471
Thoidis I, Giouvanakis M, Papanikolaou G. Semi-Supervised Machine Condition Monitoring by Learning Deep Discriminative Audio Features. Electronics. 2021; 10(20):2471. https://doi.org/10.3390/electronics10202471
Chicago/Turabian StyleThoidis, Iordanis, Marios Giouvanakis, and George Papanikolaou. 2021. "Semi-Supervised Machine Condition Monitoring by Learning Deep Discriminative Audio Features" Electronics 10, no. 20: 2471. https://doi.org/10.3390/electronics10202471
APA StyleThoidis, I., Giouvanakis, M., & Papanikolaou, G. (2021). Semi-Supervised Machine Condition Monitoring by Learning Deep Discriminative Audio Features. Electronics, 10(20), 2471. https://doi.org/10.3390/electronics10202471