1. Introduction
One of the primary insightful ways to store and compute big data is via distributed and parallel processing. A large number of data are being assembled every day from web authoring, digital media, scientific instruments, etc. However, this is complicated by limitations, with regard to the software and in the research community, when it comes to the effectiveness with which the big data are stored, queried, analyzed and forecasted. An important computational framework for large-scale data processing is known as MapReduce. Existing applications of MapReduce aid in data locality along with robustness.
Previously, a novel Map Task Data Locality-based Scheduler (MTDLS) was presented [
1] with the prime objective of allocating input data blocks to nodes based on their processing capabilities. Depending on their computing capabilities in the heterogeneous Hadoop Cluster, the map scheduling and reduction tasks were performed to the corresponding nodes. The nodes with fast processing capabilities were comparatively allocated to more tasks than the nodes with slow processing capabilities.
This scheduler has been evaluated using different workloads from the high benchmark suite. With this process, the scheduler also reduces the job execution time with improved data locality. Though the job execution time is reduced with improved data locality, the average processing time is high. Thus, in this work, to reduce the average processing time, first, tasks were deliberately chosen for the assignment, and then, the best available machine was selected in an energy-efficient manner. In this way, the average processing time should be reduced in a large heterogeneous environment, which in turn should enhance the MapReduce performance.
Several methods have been presented to implement the Apriori algorithm on the MapReduce framework. The Apriori algorithm performs the frequent item set mining and association rule learning over databases. However, only a few methods have attained its performance enhancement. Thus, improved MapReduce-based Apriori algorithms called Variable Fixed Passes Combined-counting (VFPC) and Elapsed Time-based Dynamic Passes Combined-counting (ETDPC) were previously proposed [
2]. In addition, the number of passes is reduced by skipping the pruning step in certain passes by designing the Optimized-VFPC and Optimized-ETDPC algorithms.
A quantitative analysis revealed that despite the increased number of candidates, the execution time is notably less and is also scalable with an increasing number of nodes. In addition, the energy consumed during the optimization process is less concentrated [
2]. To address this issue, in this work, an energy efficiency-aware greedy scheduling algorithm is designed, which focuses not only on the energy being consumed but also on the scheduling overhead involved.
Distributed parallel methods and mechanisms are frequently used to achieve the performance and scalability requirement for clustering large datasets. In a previous study [
3], a parallel k-means algorithm with the MapReduce programming model was used in document clustering to minimize the processing time [
4]. Recently, the utilization of big data has increased due to the fact that it has performed very efficiently in several fields, including social media and E-commerce transactions. A comprehensive overview of big data is provided in another study [
5], with a brief analysis of the comparative study of job-scheduling algorithms.
Currently, serverless computing and Functions as a Service (FaaS) have evolved as an execution pattern wherein the user does not manage the servers. Previously [
6], a high-performance serverless architecture was created to execute MapReduce jobs as the storage backend, therefore reducing the execution time involved. However, the storage overhead was high. Thus, to address this issue, a dynamically adaptable block IO(Input/Output) scheduling scheme was presented [
7]. This, in turn, reduced the MapReduce workloads without compromising the Service Level Agreements (SLA).
The extensive use of new materials and methods results in the generation of a large data volume. With the inception of the “4Vs”, i.e., volume, velocity, variety and veracity, which specialize in the complexity involved in big data, good performance is said to be ensured based on the volume of transactions being handled. In a previous study [
8], a fine-grained parallelization model for Data Warehouse (DW) was designed, which provided several means of parallelization at both the functionality and elementary levels.
However, the resources required in a heterogeneous environment are higher with the nature and type of job involved. A Dynamic Grouping Integrated Neighboring Search [
9] provides a means for a balanced resource utilization and also improves the data locality involved in the heterogeneous environment. In addition, another decision tree classification algorithm was introduced [
10], which is based on the programming framework of MapReduce, with the objective of improving accuracy in a big data environment.
Recently, research on big data using MapReduce in a heterogeneous environment has become increasingly popular. Certain notable issues that still need to be solved are the type of heterogeneity, enhancing the MapReduce performance, the storage distribution, the retrieval performance and the time factor evaluation. As far as the big data retrieval system is concerned, designing effective algorithms to swiftly and precisely acquire the necessitated content with a minimum energy consumption has become a salient issue. In addition, users might desire obtaining different types of information, such as those that consider their query objectives and necessitate a cross-type of information characterization, with the minimum job execution time involved. Moreover, due to the scalable nature of data, is important to determine how to minimize the time cost evaluation in a heterogeneous environment, in addition to reducing the scheduling overhead.
2. Contribution
To solve the problems described above, we built an optimized linear weighted regression with MapReduce algorithm to reduce the average processing time for a heterogeneous environment. Then, an energy efficiency-aware greedy scheduling algorithm was designed with the objective of reducing the energy that was consumed during the selection of the best available machine.
The major contributions of this paper include the following:
Algorithms that support big data in a heterogeneous environment are presented. Any type of big data can be retrieved based on linear weighted regression with MapReduce algorithms.
The intermediate key-value pairs are stored via metadata together with the map tasks and the reduce tasks and do not straightforwardly process large-sized big data.
The energy-efficiency-aware greedy scheduling algorithm, together with the MapReduce framework, is designed to parallel store data and process the retrieval for big data applications in heterogeneous environments.
This is a proposal of the scheduling model for reducing energy consumption during the scheduling of the machine by improving the scheduling overhead and also minimizing the job execution time. Thus, the proposed approach enhances the MapReduce performance in heterogeneous environments in an energy-aware manner.
The remainder of this paper is organized as follows.
Section 2 explains the work related to the heterogeneous data retrieval and the big data processing methods.
Section 3 describes the system model and background description.
Section 4 presents the solution to the problem, the algorithm description and the complexity analysis with a detailed mathematical model. A performance evaluation is provided in
Section 5, which presents detailed experimental results. The conclusions are provided in
Section 6.
3. Related Work
Over the past few years, one of the effective platforms for processing large unstructured data has been via system logs that implement Extract Transform Load models and measuring web indexes. Because big data analytics necessitate distributed computing at a higher rate, specifically involving thousands to millions of machines, one of the most extensive barriers is the practice of accessing big data processing in small and medium business establishments.
Even though MapReduce is cost-effective, with a heterogeneous nature, it has evolved to present a significant limitation when it comes to performance. To address this issue, a self-adaptive task pruning approach was previously presented [
11] to reduce the average job completion time and to also minimize the Input Output (IO) rate by applying the k-means clustering algorithm.
In the method, the search intentions of the users are conveyed via semantic means, and this model has thus become a paramount tool for information retrieval. To assist the semantic-based multimedia retrieval in a big data environment, an optimized Semantic Ontology Retrieval (SOR) algorithm was previously presented [
12], which utilized big data processing tools with the purpose of storing and retrieving heterogeneous multimedia data. For example, a large number of multi-dimensional data have been generated via geoscience observations. However, it is cumbersome for geoscientists to perform these tasks, because the processing of a massive number of data requires a lot of time. In addition, due to the data-intensive nature, the data analytics require complicated mechanisms and several tools.
To address the above-mentioned issues, a scientific workflow framework was proposed [
13] by leveraging cloud computing, MapReduce and Service-Oriented Architecture (SOA). With this framework, the data processing time was minimized. In addition, another MapReduce Task Scheduler using Dynamic Calibration was designed [
14] in a heterogeneous MapReduce environment.
Thus, heterogeneous architectures have transpired with encouraging results to improve the energy efficiency by providing each user with the chance to run on a core that equates resource requirements more efficiently compared to the size-fits-all processing node. In a previous study [
15], k-means, K Nearest Neighbor, Support Vector Machine and Naive Bayes were examined to measure the power efficiency and energy efficiency of the system. However, guaranteeing the Quality of Service (QoS) with a minimum resource cost is now one of the new issues in computation-intensive MapReduce computations that also involve dynamic changes. To address this issue, a new event-driven framework was developed that aimed to reduce the running cost involved in the MapReduce computation [
16]. In addition, to cope with the increasing size of datasets and minimal analysis time, Hadoop MapReduce utilized parallel computations on large, distributed clusters that comprised several machines involved in the design. Furthermore, another study focused on measuring the data replication factor on the MapReduce job completion time with the aid of regression analysis, and the total job completion time was exponentially reduced [
17].
Due to the challenges involved in big data and analytical methods, a brief critical analysis was conducted [
18]. However, the analysis was not very rigorous. To address this issue, parallelizing the Back Propagation Neural Network using MapReduce was performed in another study [
19], with the objective of not only improving the efficiency in terms of precision but also refining the classification results. In addition, the heterogeneous architecture in big data processing using the MapReduce paradigm was also presented [
20].
In [
21,
22], a power efficiency model was proposed for measuring the power flow approach based on the S-iteration process and a robust power flow algorithm based on bulirsch–stoer method. As part of the proposed study, this paper helps to measure the power efficiency effectively. In [
23,
24], different platformers are shown to measure energy efficiency in terms of Cloud sharing environment, software-defined network and 4G/5G mobile data communication fields in terms of energy consumption and data handling, with these technologies and challenges addressed in detail. By considering these approaches evolve the proposed model in different directions by addressing all the challenges.
In summary, although the methods presented above attain a good performance, difficulties, such as the average processing time and scheduling overhead, prevent these methods from being widely applied. Our method, namely Linear Weighted Regression and Energy-aware Greedy Scheduling (LWR-EGS), provides a different approach for deliberately selecting the tasks for assignment and then selecting the best available machine (i.e., resource) for them in an energy-efficient manner. The experimental results presented here indicate the effectiveness of the proposed algorithm.
4. Methodology
This section presents the main contribution of the paper, including the design and development of the proposed method. This method bridges the gap between choosing tasks for an assignment and selecting the best available machine, improving the MapReduce performance, and providing an algorithm suite in MapReduce. In the proposed LWR-EGS method, we address the limitations of the MapReduce framework that are faced in a heterogeneous environment and propose a Linear Weighted Regression-based model for optimal resource scheduling. Furthermore, the main idea and motivation of the LWR-EGS method are to minimize the average processing time and energy consumption while selecting the best available machine by implementing them concurrently. The following sections formalize all the concepts in detail by starting a system model, followed by a problem description and an elaborate description of the proposal.
4.1. System Model
To process large-scale datasets in a distributed manner, one of the most prevalent frameworks is MapReduce. A user’s request for data processing under the MapReduce framework is referred to as a job . The job is expressed as two functions Map and Reduce . The input data for a job are split into data chunks and are stored in a distributed manner across the cluster via a distributed file system. A user submits job , and on the other hand, the MapReduce framework splits job into multiple map tasks and reduces tasks as follows.
Each data chunk from the corresponding user input data relates to one map task that studies the data chunk and relates the map function to the data chunk. Then, intermediate data are generated. The intermediate data are represented in the form of key-value pairs. These key-value
pairs are stored on local disks in machines that process the map tasks. The set of all the probable keys
of the intermediate data is split into different subsets. Each of the different subsets coincides with a reduce task. The reduce task
retrieves the intermediate key-value pairs from all the map tasks and applies to the reduce function. By doing this, the reduce task
integrates the intermediate data and generates the results. The above-mentioned representations are provided below:
From Equation (1), the MapReduce of three different key-value pairs is performed. Here, T indicates a task, indicates a key and v1 indicates a value.
4.2. Problem Description
MapReduce is an abstraction to arrange immense parallel tasks with Hadoop, and it is an open-source implementation that is a software environment specifically meant for the distributed processing of enormous data sets over several machines. The main concept behind the design of MapReduce is to map the given input data set into a group of key and value pairs and then minimize all the pairs with the same key. The MapReduce is comprised of a set of maps and reduce tasks. The MapReduce job is split into two processes, the Map process, and the Reduce process, which perform the map tasks and reduce tasks, respectively. The Reduce process is said to be initiated once the execution of the Map process is accomplished. First, the Map process (via script) obtains certain input data and maps them to the pairs. Then, it processes the intermediate data. Finally, the reduce process (via script) obtains these intermediate data as pairs and reduces the pairs with the same key into a single pair.
The problem is to first deliberately select the tasks for the assignment and then to select the best available machine (i.e., resource) for them. In this manner, the optimization of the resources takes place. Second, with the optimized resources assigned to each of them (i.e., resources), the overall energy consumption of all the tasks is reduced within the stipulated time in heterogeneous environments [
25]. Here, the resource optimization is based on prior knowledge about the projected energy consumption and the projected processing time of each task while executing each machine. In addition, assigning a task to a position here refers to positioning the data on the machine to which the position belongs and then running the corresponding script (i.e., either the map process or the reduce process).
4.3. Integer Linear Weighted Regression (ILWR) model
The Integer Linear Weighted Regression model was used to predict the time span of the map, schedule and reduce phases. The objective was to design an optimized resource scheduler that was responsible for deciding which task was to be executed at which time and on which machine by considering both the central processing unit (CPU) and the memory. The most common objective of the optimized resource scheduling was to reduce the job completion time optimally by properly allocating the tasks to the processors using [
26]. With this Integer Linear Weighted Regression (ILWR) model, the tasks were selected deliberately for assignment, and with this, the best available machine (i.e., resource) was selected for them. In this manner, resource optimization occurred.
Figure 1 shows the block diagram of the ILWR model.
The feature sets utilized in the ILWR model are listed below. First, the tasks are selected for assignment using an ILWR model. Then, the file size
, the number of reduces
and the number of machines involved in the processing
to denote the
sample
with
number of samples are input. The above-mentioned feature sets are expressed below.
From (2),
indicates a file size,
number of machines and
number of reduces. Next, a matrix
was defined to represent all the training data, and a vector
was used to represent the time, which correlated to the sample
. Then, the matrix
and the vector
were represented as given below.
For the prediction of
, the weight for each sample was measured to identify the most similar tasks. Then, the distance measure was used in the following expression:
In the above Equation (5),
corresponds to the sample point and
corresponds to the prediction point. Their feature values were correspondingly used to measure the distance between them. With the measured distance, selecting the best available machine with the objective of optimizing the resource was performed via the integer linear model used based on [
27]. The integer linear model was formulated as given below, where
represents the ID number of a
task and
represents the ID number of a
task. In addition,
represents the ID number of a
position, and
represents the ID number of a
position. Moreover,
represents the time limit for completing all the tasks for an assignment, with
and
representing the deadlines for the completion of all of the
tasks and
tasks, respectively.
From Equations (6) and (7) above, two sets of variables were defined for determining which position should run which tasks, and these were denoted by
and
, respectively, with the constraints as given below.
The Equation (8) above ensures that each
task is allocated to one and only one
position, and all the tasks are hence said to be allocated. Similarly, Equation (9) ensures that each
task is allocated to one and only one
position, and all the tasks are hence said to be reduced. After that, the free memory and CPU usage for every task are measured using the expressions given below.
From Equations (10) and (11),
refers to the processing capacity of the
task,
refers to the RAM capacity of the
task,
refers to the percentage of CPU used for the
task and
refers to the percentage of memory used for the
task. Finally, the prediction phase,
, of the new instance for the optimal allocation of resources process is used [
28] and is expressed as follows:
The proposed model presents an optimal resource scheduler that dynamically distributes the position and map tasks to a machine that possesses the maximum processing capacity in the heterogeneous environment, as shown in Algorithm 1.
| Algorithm 1 Proposed algorithm for optimal resource scheduling |
Input: Set of input tasks to be assigned
Output: Optimized resource scheduling
1: For each file size , reduces and machines do
2: Calculate the distance between the sample point and prediction point for input file size
3: Calculate the deadlines for completion of the task and the task , with the constraints from (8) and (9)
4: Calculate the free CPU
5: Calculate the free MEM
6: Measure the prediction phase
7: If and are available then
8: assign the MAP tasks to
9: Else
10: and are not available, then
11: Go to step (2)
12: End if
13: End for
14: End |
The above linear weighted regression with MapReduce algorithm has three main phases. The first phase is to estimate the training dataset and represent it in the form of a matrix and vector. The second phase is to estimate the map and reduce tasks and to set up queues accordingly. The final phase is to select the tasks for assignment via regression and resource availability while satisfying the available and . In this manner, the tasks for the assignments are selected optimally.
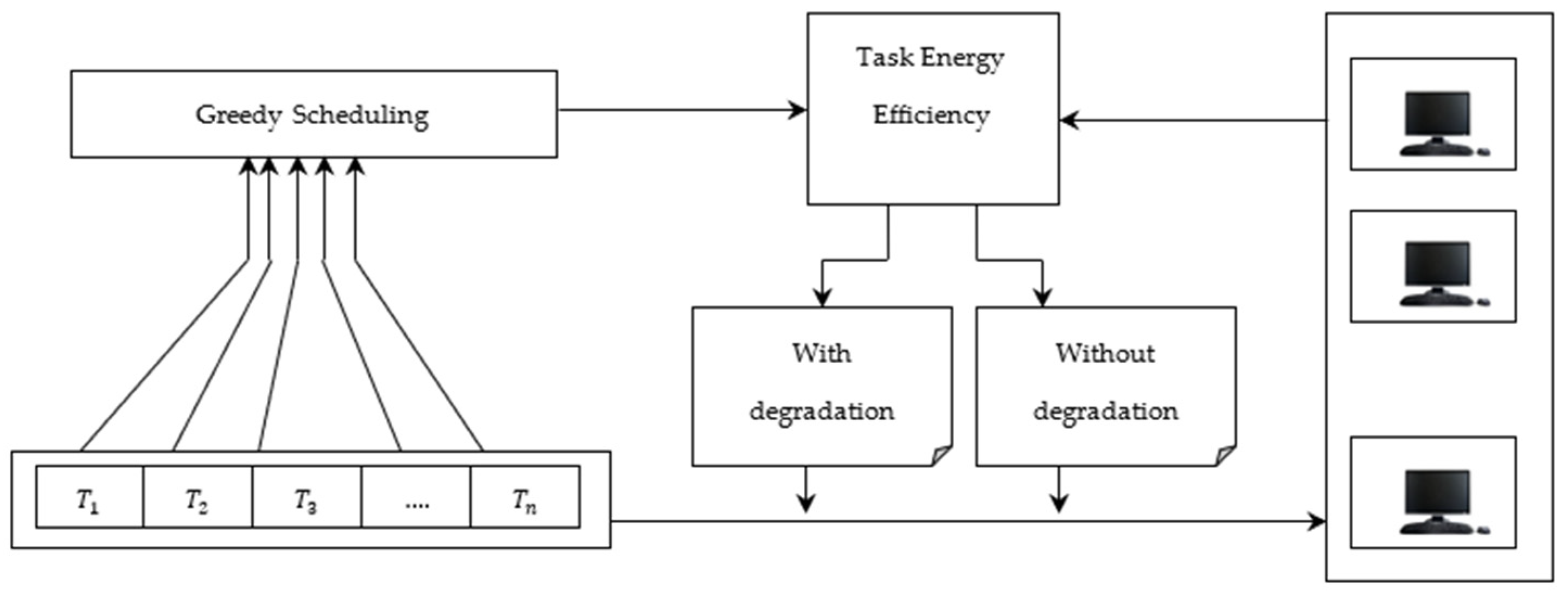
4.4. Energy-Efficiency-Aware Greedy Scheduling Algorithm
Considering the increasing significance of Hadoop MapReduce, one of the main issues faced in a heterogeneous environment while selecting the best available machine is saving energy. In this work, we present an energy-efficiency-aware greedy scheduling algorithm to choose a position for each task to minimize the total energy consumption of the MapReduce task for big data applications in heterogeneous environments without causing a significant performance loss.
Figure 2 shows the block diagram of the energy-efficiency-aware greedy scheduling model.
The energy efficiency-aware greedy scheduling is illustrated in
Figure 2 to select the best available machine. According to the definition of energy efficiency, the energy efficiency of a machine is defined by three aspects as follows:
The three aspects given in Equations (13)–(15) represent the energy efficiency of a processor , the energy efficiency of the maximum disk IO rate and the energy efficiency of the maximum transmission rate , respectively. These three aspects are obtained based on the processor performance , the disk IO rate , the transmission rate to the ratio of the energy consumption of the processor , the energy consumption of the disk IO and the energy consumption of the transmission rate , respectively, of the corresponding machine.
There are dissimilarities between the energy efficiency of a machine and its host server machine due to virtualization. Therefore, in this work, the machine degradation, with respect to the energy efficiency of the processing, the disk IO rate and the data transmission rate, is represented as
,
and
, respectively. Thus, the energy efficiency of a machine with degradation arising due to virtualization is expressed as follows:
Then, considering the task resource requirements, the machine energy features and the workload on the host machine, the energy consumption of the task run on a machine is expressed as follows:
where
From Equations (22)–(24),
represents the number of instructions to be processed,
corresponds to the total number of disk data and
refers to the data transfer rate, respectively. From the above three equations, finally, considering the task resource requirements, the overall task energy is expressed as follows:
where
,
and
represent the energy efficiency of a machine regarding several instructions to be processed, the IO rate and the data transfer rate, respectively. From Equation (25), it is inferred that allocating tasks to machines with higher energy efficiency is of great significance, which in turn minimizes the energy consumption. In addition, the workload is of high significance, since a high load results in greater performance degradation, which increases the energy consumption to complete a task.
The Algorithm 2 takes the machine energy efficiency and task demands into account and hence ensures an energy-efficient task scheduling. The energy-efficient task scheduling is achieved in three phases. In the first phase, the energy efficiency of the processor without degradation is considered. Because of the heterogeneous environment, not all the machines possess an equal capacity, and every machine possesses its own processing speed, IO rate or data transfer rate. Hence, by taking these factors into consideration in the second phase, the processor energy efficiency with degradation is also considered. Finally, the energy required for task scheduling is measured. In this way, the tasks are allocated to the best available machine by considering the energy efficiency of the machine.
| Algorithm 2 Proposed algorithm for energy-efficient machine selecting |
Input: Set of assigned tasks
Output: Energy-efficient machine selection
1: For each file size , reduces and machines do
2: Obtain the processor energy efficiency , the disk IO rate energy efficiency and the transmission energy efficiency using (13), (14) and (15), respectively
3: Obtain the processor energy efficiency , the disk IO rate energy efficiency and the transmission energy efficiency with degradation using (16), (17) and (18), respectively
4: Measure the energy consumption of the task run on a machine using (19) and (21)
5: Measure the overall task energy using (25)
6: End for |
5. Experiments and Results and Performance Evaluation Model
In this paper, a low energy consumption resource scheduling method was proposed for a heterogeneous environment. Therefore, the experiments were specifically designed to measure the energy consumption along with the storage overhead and the average running time of the resource scheduling of various tasks. For the experiment platform, the Hadoop Distributed File System (HDFS) was used to construct the required storage. Establishing the experimental dataset was an important step. To measure the performance, the experiments were performed using a Kaggle dataset [
29] on big city health data.
This dataset provides the status pertaining to the health of 26 of the nation’s largest and most urban cities as extracted by 34 health (and six demographics-related) indicators. These measures denote some of the paramount causes of morbidity and mortality in the United States and the leading priorities of national, state and local health agencies.
The public health data were obtained from nine different overarching categories, namely HIV/AIDS, cancer, nutrition/physical activity/obesity, food safety, infectious disease, maternal and child health, tobacco, injury/violence and behavioral health/substance abuse. The columns included are the indicator category, year, indicator, gender, race, value, place, requested methodology, source, methods and notes. To ensure a fair comparison, the proposed methods were compared with two recent methods, namely MTDLS and VFPC-ETDPC.
For the comparison, the performance evaluation model was based on the following three criteria, the energy consumption, the average processing time and storage overhead.
5.1. Energy Consumption Performance Evaluation
Energy consumption was used to evaluate the effectiveness of the LWR-EGS. In the first experiment, we assessed the energy being consumed whenever the tasks were submitted by a user in a heterogeneous environment. The LWR-EGS method estimates the energy being consumed by considering certain factors, including the number of instructions being processed, the IO rate and the data transfer rate. In addition to attaining the goal of saving energy, it was of great necessity to consider a machine’s energy efficiency. Assigning tasks to a high-performance machine may enhance the overall resource scheduling optimization, but at the same time, doing this results in extra energy consumption. Hence, in this work, the energy efficiency of both the machine and the machine degradation, with respect to the energy efficiency of the processing, the disk IO rate and data transmission rate, were also considered.
The energy consumption was measured using Equation (26) above, which was based on the tasks submitted by the user for scheduling and the overall task energy. From (25),
denotes energy consumption.
denotes the energy consumed for each task.
denotes the total number of tasks. The energy consumption was measured in terms of joules
J. A lower energy consumption ensured the efficiency of the method. On the other hand, a higher energy consumption showed that the resource was not being scheduled in an optimized manner.
Figure 3 illustrates a graphical representation of the energy consumption using the LWR-EGS, MTDLS and VFPC-ETDPC methods.
In the simulated experiments, with the same number of tasks and machines, the initial number of tasks in the training set and those in the test set were both set to twenty-five. The x-axis in
Figure 3 represents the number of tasks in the range of 25 to 250. Here, the task refers to the different indicator category obtained from a Kaggle dataset. On the other hand, the y-axis represents the different energy consumption levels obtained at the different time intervals for the different sets from the indicator categories. When considering the 75 number of tasks, the energy consumption of the LWR-EGS method, MTDLS method and VFPC-ETDPC method is 105J, 110J and 150J respectively.
A rise in energy consumption was observed with the varying numbers of tasks. By increasing the number of indicator categories or tasks, the energy being consumed for resource scheduling also increased. This was because the increase in the task being submitted by the user increased the number of resources assigned to the corresponding subsequent task, and therefore, the energy consumption also increased. However,
Figure 3 shows a comparatively lower consumption level using the proposed LWR-EGS method. This occurred because of the application of the energy-efficiency-aware greedy scheduling model. Here, both the energy efficiency and greedy scheduling model were considered as two important factors for resource scheduling. Hence, the energy consumption using the LWR-EGS method was reduced by 11% compared to the MTDLS method and 20% compared to the VFPC-ETDPC method.
5.2. Performance Evaluation of the Average Processing Time
The next experiment was performed to demonstrate the effectiveness of the processed user request (i.e., resource scheduling). After asking the user to provide the request, the average processing time was measured.
From Equation (27), the average processing time
was recorded based on the number of tasks provided by a user for the resource being scheduled
and the time consumed for scheduling
the corresponding tasks. A lower average processing time ensured the efficiency of the method. On the other hand, a higher average processing time showed that the time consumed for scheduling the resources, on average, was higher.
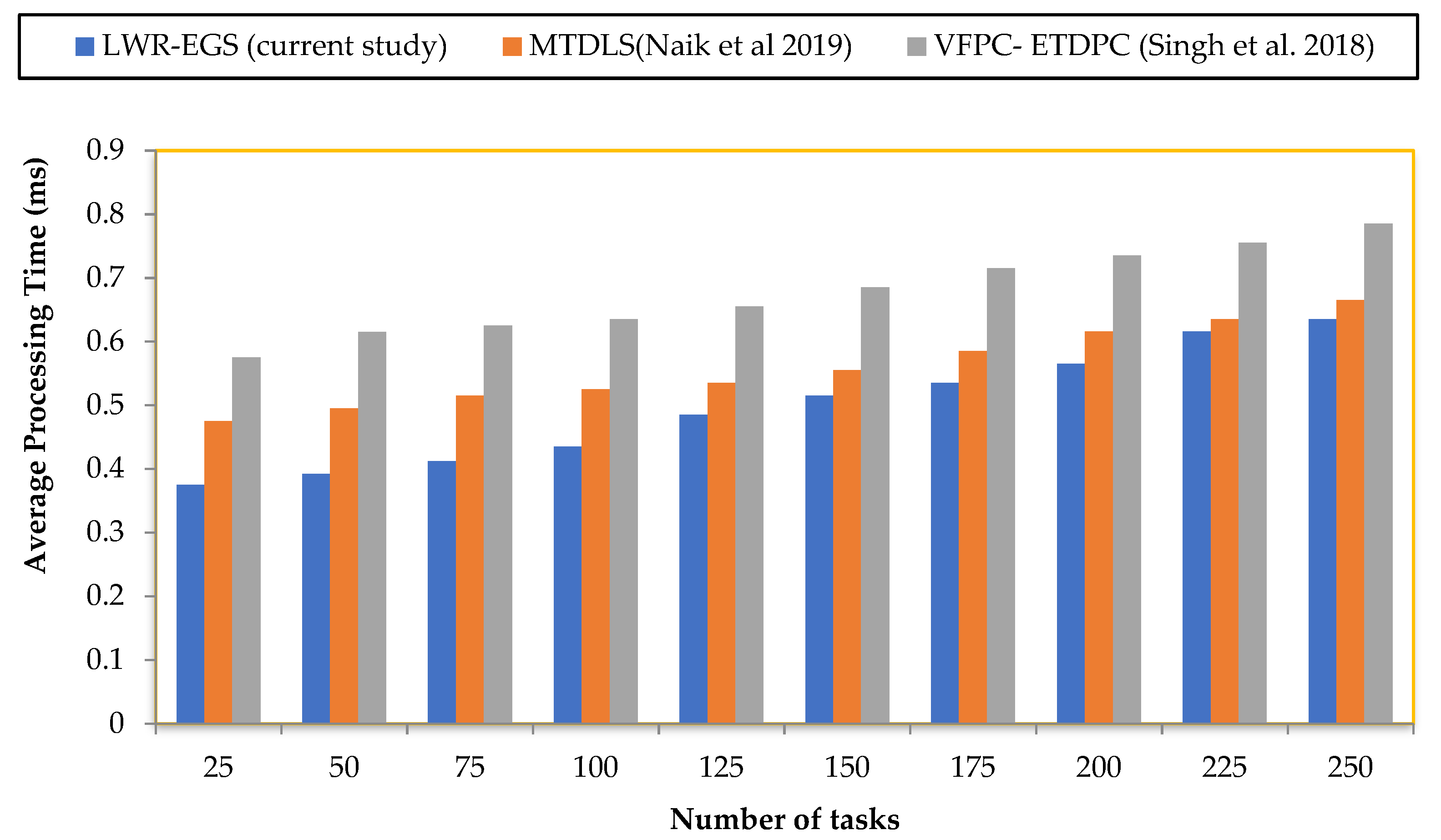
Figure 4 illustrates a graphical representation of the average processing time using the LWR-EGS, MTDLS and VFPC-ETDPC methods.
In
Figure 4, the x-axis corresponds to the number of tasks. Here, a task refers to the indicator category. Different indicator category ranges were obtained at different time intervals. The average processing time here refers to the time taken to process the scheduling of the different tasks or jobs. From the figure, it was inferred that number of tasks was directly proportional to the average processing time. In other words, the higher the number of tasks for the assignment being provided by the user requests, the higher the time consumed in processing the subsequent user requests. However, a direct proportionality was found using the three methods. The average processing time was lower compared to MTDLS and VFPC-ETDPC, and this was evident from a simple representation.
With the number of tasks set to 25 for the experiment, the average processing time for the resource being scheduled for a single task was using LWR-EGS, using MTDLS and using VFPC-ETDPC. In addition, the overall average processing time using MTDLS and VFPC-ETDPC were observed to be , and 0.575 ms, respectively. Thus, it was inferred that the average processing time using LWR-EGS was lower than MTDLS and VFPC-ETDPC. This was because of the application of the integer linear model. By applying the integer linear model, the distance between the sample point and the predicted points was used to obtain the distance, such that more similar tasks were first identified considering the CPU and memory constraints. Only after identifying the tasks were the best available machines identified for scheduling. Hence, the average processing time was 12% lower using the LWR-EGS method compared to MTDLS and was 27% lower when compared to VFPC-ETDPC.
5.3. Performance Evaluation of the Scheduling Overhead
Finally, the third set of experiments conducted aimed to measure the effectiveness and efficiency of the method for the scheduling overhead. The scheduling overhead corresponds to the overhead incurred while scheduling the resources for the corresponding user requests that are made.
From Equation (28), the scheduling overhead
was measured based on the number of tasks requested by the user for the resource to be scheduled
and the memory consumed for the corresponding task to be scheduled
. The results of the scheduling overhead are described in
Figure 5. The total scheduling overhead for each number of tasks was measured. The data size, along with the number of machines to be allocated, was maintained throughout the experiment, and the tasks were added and removed after each test. The effect of the task scheduling was also measured by changing the task volume. With a constant task size at a certain threshold, the performance of the task scheduling improved by increasing the number of tasks as shown in
Figure 5. In this case, when the number of tasks was
, the overall scheduling overhead using LWR-EGS was 125 KB. In contrast, by applying MTDLS, the scheduling overhead was
, and by applying VFPC-ETDPC, it was
.
Figure 5 illustrates a graphical representation of the scheduling overhead using the LWR-EGS, MTDLS and VFPC-ETDPC methods. When considering the 225 number of tasks, the scheduling overhead using MTDLS and VFPC-ETDPC methods were 390 KB, 410 KB and 365 KB, respectively.
Based on the data, it was inferred that the scheduling overhead was comparatively lower using the LWR-EGS method compared to using MTDLS and VFPC-ETDPC. The reason for the enhancement was the application of the integrated linear weighted regression with MapReduce algorithm and the energy efficiency-aware greedy scheduling algorithm. By applying these two algorithms, not only was there a deliberate selection of the tasks for the assignment, but also the best available machine was then assigned in a heterogeneous environment. In addition, when selecting the tasks for the assignment, followed by the selection of the best available machine, two factors, namely, the CPU and MEM required and available, were also taken into consideration for the optimal resource scheduling. The comparative result analysis of the scheduling overhead is reduced by 14% and 30% using LWR-EGS method compared to existing MTDLS and VFPC-ETDPC methods.3
6. Conclusions and Future Work
Here, a low energy consumption resource scheduling method is proposed. This method is based on careful analyses of the structure of a MapReduce framework, the operating mechanism and the energy consumption problems while scheduling tasks in a heterogeneous environment. By designing an integer linear regression model, with the addition of MapReduce functionalities, the tasks to be assigned are first selected in a deliberate manner and the resources are optimally scheduled. Therefore, the indicator category from the Kaggle dataset is split into various tasks associated with different time periods, and they are processed separately. Next, by selecting the tasks to be assigned, the scheduling of the machines or resources is done by applying a greedy scheduling algorithm. In this way, by designing a resource schedule for all the tasks, the operation state of the tasks is that storage nodes are efficiently controlled to achieve energy saving. The development of creating the resource scheduling for heterogeneous big data via the MapReduce framework and an operation strategy for low energy consumption scheduling method are described in detail in this paper. The performance of the method was estimated from the energy consumption, the scheduling overhead, and the average processing time. The experimental results illustrate that compared with the state-of-the-art methods, the average processing time was drastically decreased by 20%. In addition, the results also proved that the scheduling overhead and energy consumption decreased with the LWR-EGS method compared to the state-of-the-art methods. Some limitations in the proposed LWR-EGS framework are also worth addressing in the future. (1) The integrated energy-efficient framework will be further researched considering energy-efficient scheduling, data distribution and replication dependencies factors. (2) The parts of scheduler and node management are considered in this paper, but the data distribution and replication dependencies are not considered.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




