
Lane-Merging Strategy for a Self-Driving Car in Dense Traffic Using the Stackelberg Game Approach



Abstract
:1. Introduction
- The complex vehicle interactions in dense traffic are effectively modeled using the Stackelberg game approach with manageable computation;
- To establish reliable and verifiable test environments, we propose the modified car-following model that can change the target leading car depending on varying circumstances;
- The intentions of the surrounding vehicles are effectively estimated in real time by monitoring the speed variations of the interacting vehicles.
2. Problem Statement
3. Vehicle Model and Action Space
3.1. Vehicle Dynamics
3.2. Action Set
- “Maintain”: Maintain the speed.
- “Accelerate”: Constant acceleration with until vehicle speed reaches to the maximum speed .
- “Decelerate”: Constant deceleration with until vehicle speed drops to zero.
- “Lane-merge”: Changing lane with , i.e., movement in a lateral direction.
3.3. Intelligent Driver Model
| Algorithm 1: IDM with Politeness |
 |
4. Game Theoretic Lane-Merging Strategy
4.1. Utility Function
4.2. Stackelberg Game
4.3. Real Time Politeness Estimation
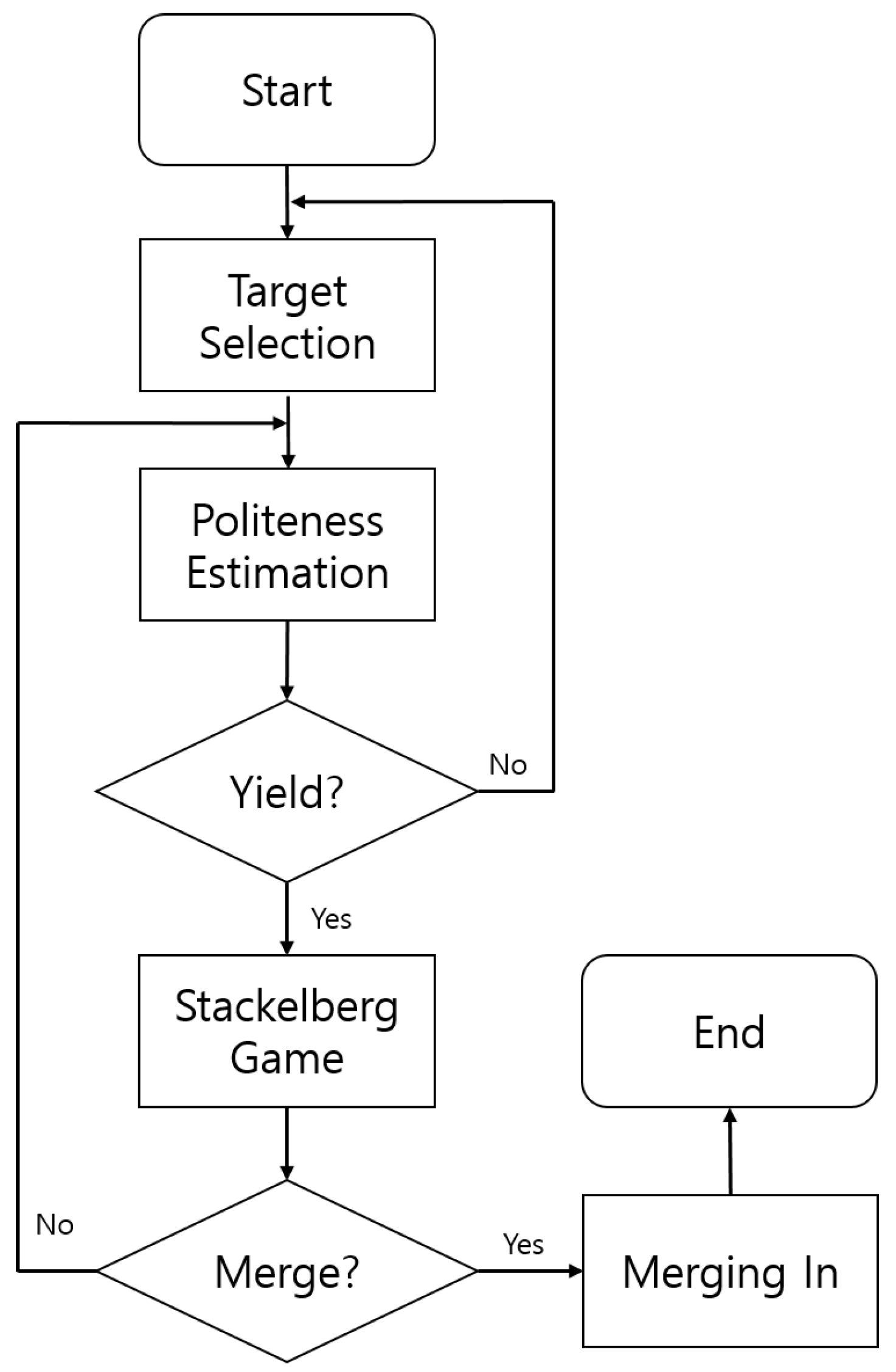
4.4. Game Process
5. Case Studies
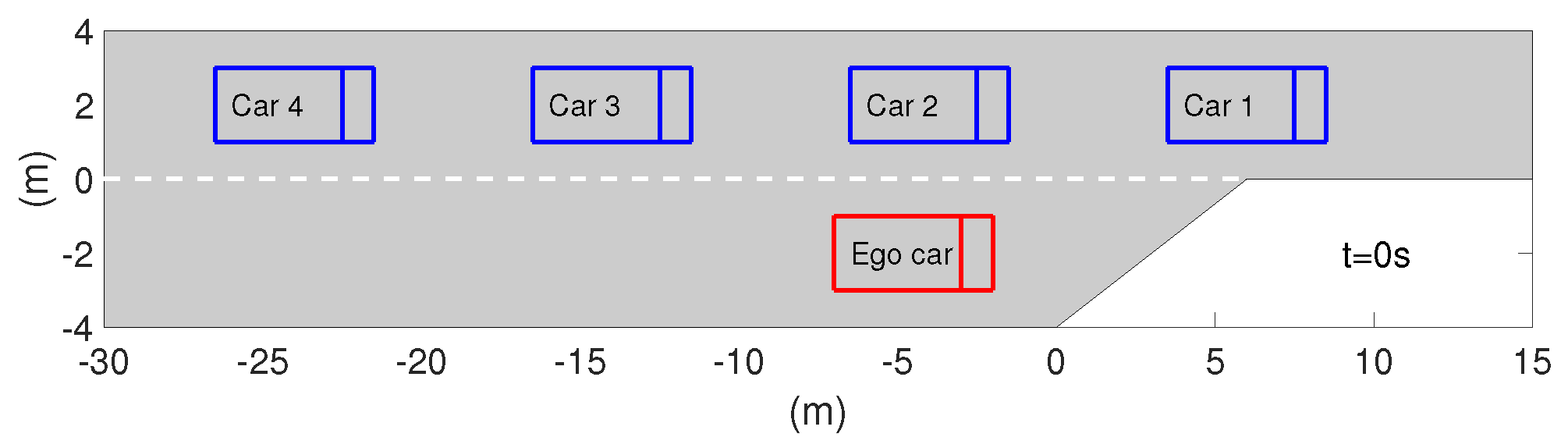
5.1. Test Environment Setup
5.2. Rule-Based Lane Merging
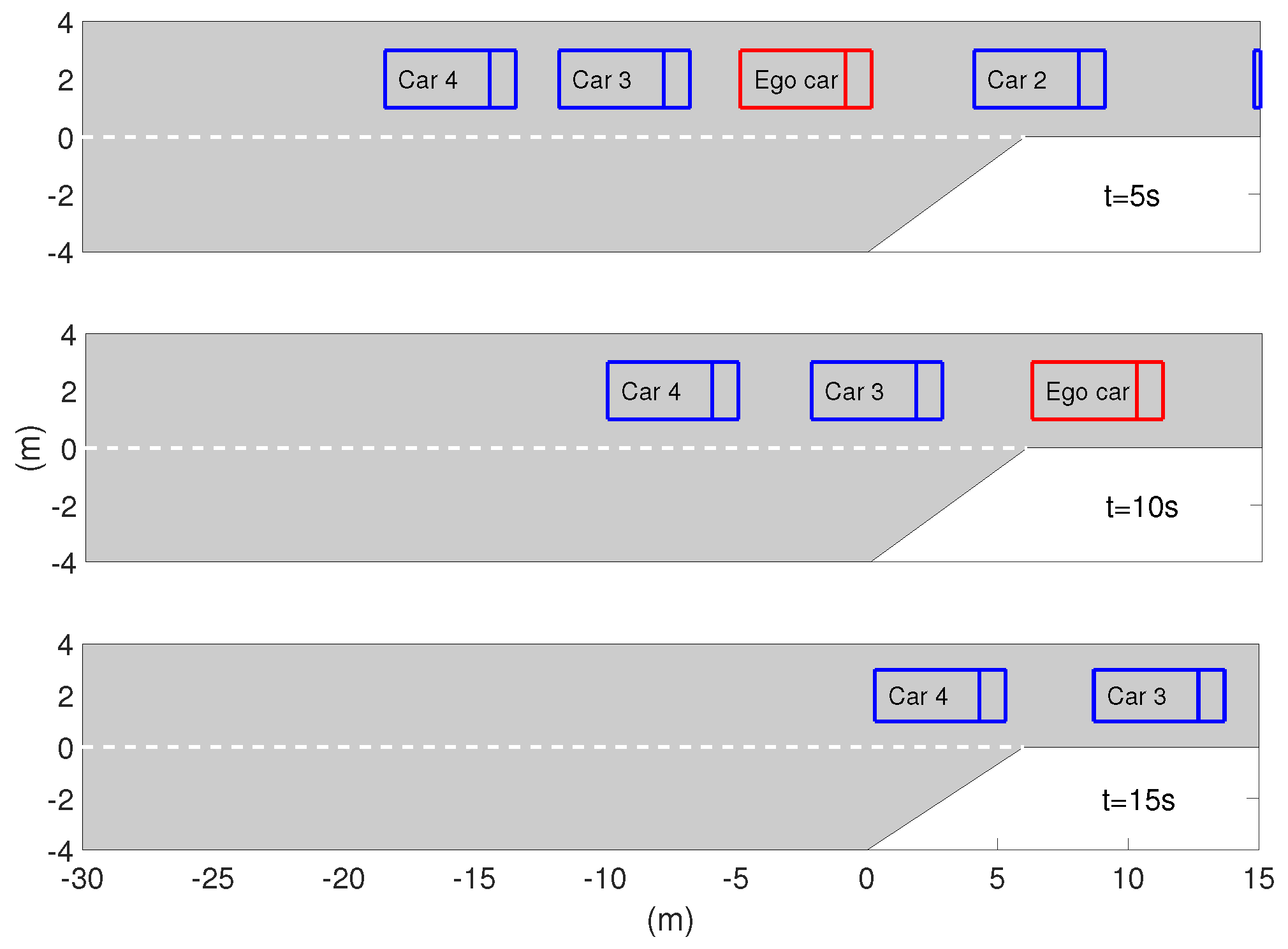
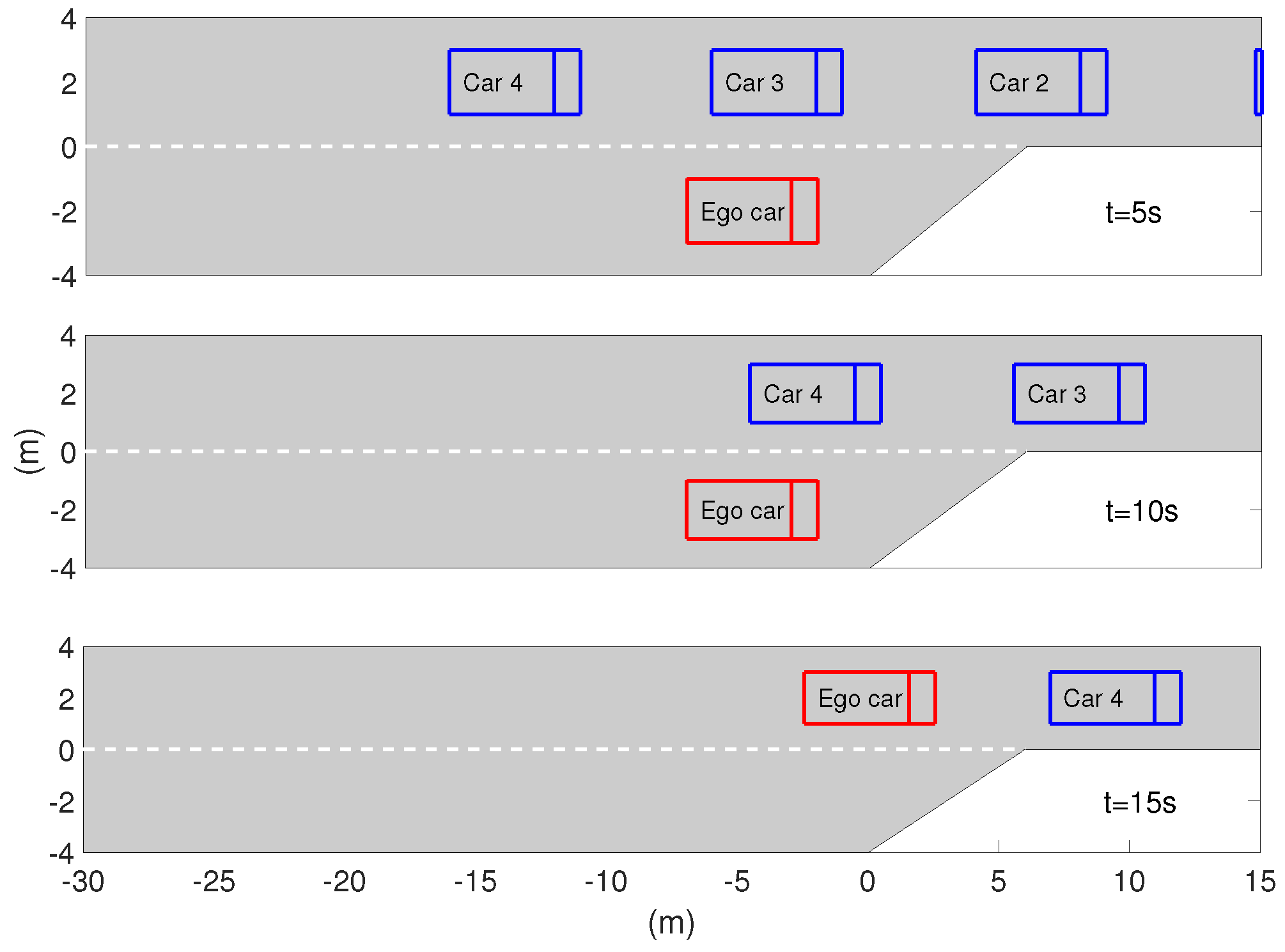
5.3. Case Studies
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- An, H.; Jung, J.I. Decision-making system for lane change using deep reinforcement learning in connected and automated driving. Electronics 2019, 8, 543. [Google Scholar] [CrossRef] [Green Version]
- Dingus, T.A.; Klauer, S.G.; Neale, V.L.; Petersen, A.; Lee, S.E.; Sudweeks, J.; Perez, M.A.; Hankey, J.; Ramsey, D.; Gupta, S.; et al. The 100-Car Naturalistic Driving Study, Phase II-Results of the 100-Car Field Experiment; Technical Report; Department of Transportation, National Highway Traffic Safety Administration: Washington, DC, USA, 2006. [Google Scholar]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Li, G.; Cheng, J. Exploring the effects of traffic density on merging behavior. IEEE Access 2019, 7, 51608–51619. [Google Scholar] [CrossRef]
- Kalra, N.; Paddock, S.M. Driving to safety: How many miles of driving would it take to demonstrate autonomous vehicle reliability? Transp. Res. Part A Policy Pract. 2016, 94, 182–193. [Google Scholar] [CrossRef]
- Basar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory; SIAM: Philadelphia, PA, USA, 2013; ISBN 978-0-898-714-29-6. [Google Scholar]
- Myerson, R.B. Game Theory; Harvard University Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Yoo, J.; Langari, R. A Game-Theoretic Model of Human Driving and Application to Discretionary Lane-Changes. arXiv 2020, arXiv:2003.09783. [Google Scholar]
- Sadigh, D.; Sastry, S.; Seshia, S.A.; Dragan, A.D. Planning for Autonomous Cars that Leverage Effects on Human Actions; Robotics: Science and Systems: Ann Arbor, MI, USA, 2016; Volume 2. [Google Scholar]
- Backhaus, S.; Bent, R.; Bono, J.; Lee, R.; Tracey, B.; Wolpert, D.; Xie, D.; Yildiz, Y. Cyber-physical security: A game theory model of humans interacting over control systems. IEEE Trans. Smart Grid 2013, 4, 2320–2327. [Google Scholar] [CrossRef] [Green Version]
- Lee, R.; Wolpert, D. Game theoretic modeling of pilot behavior during mid-air encounters. In Decision Making with Imperfect Decision Makers; Springer: Berlin/Heidelberg, Germany, 2012; pp. 75–111. [Google Scholar]
- Camerer, C.F.; Ho, T.H.; Chong, J.K. A cognitive hierarchy model of games. Q. J. Econ. 2004, 119, 861–898. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Kolmanovsky, I.; Girard, A.; Yildiz, Y. Game theoretic modeling of vehicle interactions at unsignalized intersections and application to autonomous vehicle control. In Proceedings of the 2018 Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 3215–3220. [Google Scholar]
- Tian, R.; Li, N.; Kolmanovsky, I.; Yildiz, Y.; Girard, A.R. Game-theoretic Modeling of Traffic in Unsignalized Intersection Network for Autonomous Vehicle Control Verification and Validation. IEEE Trans. Intell. Transp. Syst. 2020, 1–16. [Google Scholar] [CrossRef]
- Sankar, G.S.; Han, K. Adaptive Robust Game-Theoretic Decision Making Strategy for Autonomous Vehicles in Highway. IEEE Trans. Veh. Technol. 2020, 69, 14484–14493. [Google Scholar] [CrossRef]
- Garzón, M.; Spalanzani, A. Game theoretic decision making for autonomous vehicles’ merge manoeuvre in high traffic scenarios. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3448–3453. [Google Scholar]
- Yoo, J.H.; Langari, R. A Stackelberg game theoretic driver model for merging. In Proceedings of the Dynamic Systems and Control Conference. American Society of Mechanical Engineers, Palo Alto, CA, USA, 21–23 October 2013; Volume 56130, p. V002T30A003. [Google Scholar]
- Zhang, Q.; Langari, R.; Tseng, H.E.; Filev, D.; Szwabowski, S.; Coskun, S. A Game Theoretic Model Predictive Controller With Aggressiveness Estimation for Mandatory Lane Change. IEEE Trans. Intell. Veh. 2019, 5, 75–89. [Google Scholar] [CrossRef]
- Yu, H.; Tseng, H.E.; Langari, R. A human-like game theory-based controller for automatic lane changing. Transp. Res. Part C Emerg. Technol. 2018, 88, 140–158. [Google Scholar] [CrossRef]
- Li, N.; Yao, Y.; Kolmanovsky, I.; Atkins, E.; Girard, A.R. Game-theoretic modeling of multi-vehicle interactions at uncontrolled intersections. IEEE Trans. Intell. Transp. Syst. 2020, 1–15. [Google Scholar] [CrossRef]
- Dong, C.; Dolan, J.M.; Litkouhi, B. Intention estimation for ramp merging control in autonomous driving. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1584–1589. [Google Scholar]
- Bae, S.; Saxena, D.; Nakhaei, A.; Choi, C.; Fujimura, K.; Moura, S. Cooperation-aware lane change maneuver in dense traffic based on model predictive control with recurrent neural network. In Proceedings of the 2020 American Control Conference (ACC), Denver, CO, USA, 1–3 July 2020; pp. 1209–1216. [Google Scholar]
- Kesting, A.; Treiber, M.; Helbing, D. General lane-changing model MOBIL for car-following models. Transp. Res. Rec. 2007, 1999, 86–94. [Google Scholar] [CrossRef] [Green Version]
- Chandra, R.; Selvaraj, Y.; Brännström, M.; Kianfar, R.; Murgovski, N. Safe autonomous lane changes in dense traffic. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Evestedt, N.; Ward, E.; Folkesson, J.; Axehill, D. Interaction aware trajectory planning for merge scenarios in congested traffic situations. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 465–472. [Google Scholar]
- Saxena, D.M.; Bae, S.; Nakhaei, A.; Fujimura, K.; Likhachev, M. Driving in dense traffic with model-free reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 5385–5392. [Google Scholar]
- Han, K.; Nguyen, T.W.; Nam, K. Battery Energy Management of Autonomous Electric Vehicles Using Computationally Inexpensive Model Predictive Control. Electronics 2020, 9, 1277. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Q. Stackelberg game for utility-based cooperative cognitiveradio networks. In Proceedings of the Tenth ACM International Symposium on Mobile ad hoc Networking and Computing, New Orleans, LA, USA, 18–21 May 2009; pp. 23–32. [Google Scholar]
- Jin, I.G.; Schürmann, B.; Murray, R.M.; Althoff, M. Risk-aware motion planning for automated vehicle among human-driven cars. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 3987–3993. [Google Scholar]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ayres, T.; Li, L.; Schleuning, D.; Young, D. Preferred time-headway of highway drivers. ITSC 2001. In Proceedings of the 2001 IEEE Intelligent Transportation Systems. (Cat. No. 01TH8585), Oakland, CA, USA, 25–29 August 2001; pp. 826–829. [Google Scholar]
- Li, N.; Oyler, D.W.; Zhang, M.; Yildiz, Y.; Kolmanovsky, I.; Girard, A.R. Game theoretic modeling of driver and vehicle interactions for verification and validation of autonomous vehicle control systems. IEEE Trans. Control. Syst. Technol. 2017, 26, 1782–1797. [Google Scholar] [CrossRef] [Green Version]
- Arbis, D.; Dixit, V.V. Game theoretic model for lane changing: Incorporating conflict risks. Accid. Anal. Prev. 2019, 125, 158–164. [Google Scholar] [CrossRef] [PubMed]
- Kerin, R.A.; Varadarajan, P.R.; Peterson, R.A. First-mover advantage: A synthesis, conceptual framework, and research propositions. J. Mark. 1992, 56, 33–52. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Given Value |
|---|---|
| Desired velocity | 2.5 |
| Safe time headway T | 1.2 |
| Maximum acceleration | 0.97 |
| Desired deceleration b | 1.67 |
| Acceleration exponent | 4 |
| Jam distance | 1 |
| Car 1 | 6 | 2 | 2.5 |
| Car 2 | −4 | 2 | 2.5 |
| Car 3 | −14 | 2 | 2.5 |
| Car 4 | −24 | 2 | 2.5 |
| Ego car | −4.5 | −2 | 0 |
| Scenario 1 | Scenario 2 | Scenario 3 | |
|---|---|---|---|
| Car 1 | 0.9 | 0.1 | 0.9 |
| Car 2 | 0.1 | 0.9 | 0.1 |
| Car 3 | 0.9 | 0.1 | 0.1 |
| Car 4 | 0.9 | 0.9 | 0.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, K.; Orsag, M.; Han, K. Lane-Merging Strategy for a Self-Driving Car in Dense Traffic Using the Stackelberg Game Approach. Electronics 2021, 10, 894. https://doi.org/10.3390/electronics10080894
Ji K, Orsag M, Han K. Lane-Merging Strategy for a Self-Driving Car in Dense Traffic Using the Stackelberg Game Approach. Electronics. 2021; 10(8):894. https://doi.org/10.3390/electronics10080894
Chicago/Turabian StyleJi, Kyoungtae, Matko Orsag, and Kyoungseok Han. 2021. "Lane-Merging Strategy for a Self-Driving Car in Dense Traffic Using the Stackelberg Game Approach" Electronics 10, no. 8: 894. https://doi.org/10.3390/electronics10080894
APA StyleJi, K., Orsag, M., & Han, K. (2021). Lane-Merging Strategy for a Self-Driving Car in Dense Traffic Using the Stackelberg Game Approach. Electronics, 10(8), 894. https://doi.org/10.3390/electronics10080894