
Facial Emotion Recognition Using Transfer Learning in the Deep CNN

 , ,
, ,  and
and
Abstract
:1. Introduction
- (i)
- Development of an efficient FER method using DCNN models handling the challenges through TL.
- (ii)
- Introduction of a pipeline training strategy for gradual fine-tuning of the model up to high recognition accuracy.
- (iii)
- Investigation of the model with eight popular pre-trained DCNN models on benchmark facial images with the frontal view and profile view (where only one eye, ear, and one side of the face is visible).
- (iv)
- Comparison of the emotion recognition accuracy of the proposed method with the existing methods and explore the proficiency of the method, especially with profile views that is important for practical use.
2. Related Works
2.1. Machine Learning-Based FER Approaches
2.2. Deep Learning-Based FER Approaches
3. Overview of CNN, Deep CNN Models and Transfer Learning (TL)
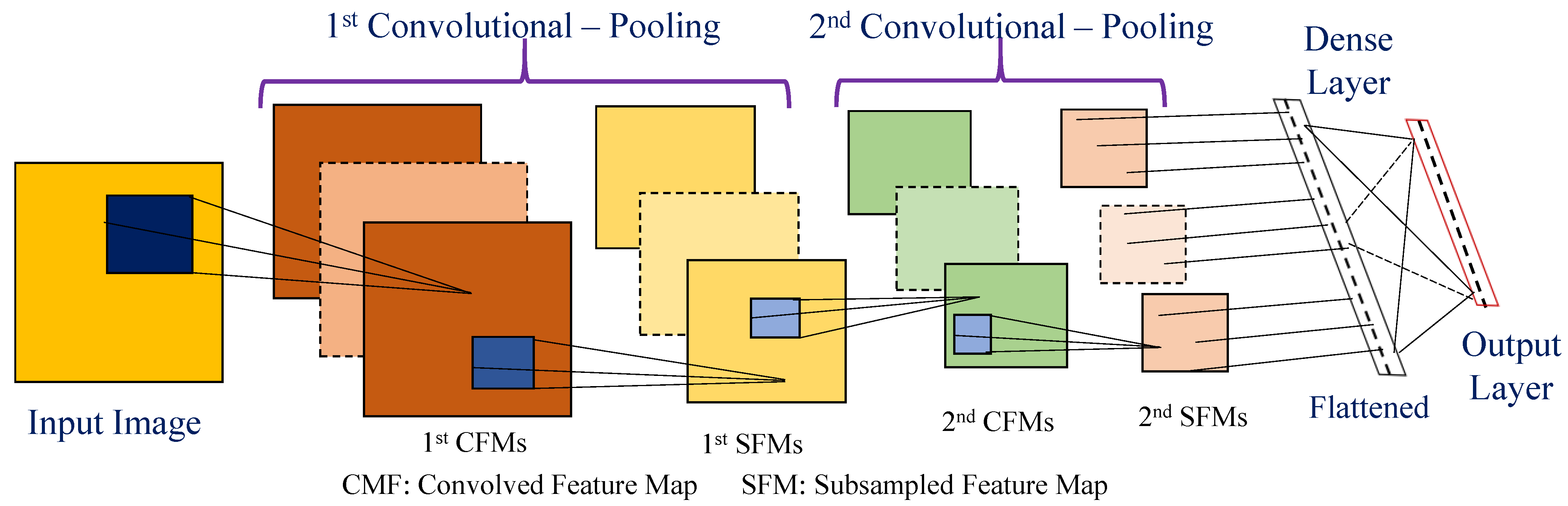
3.1. Convolutional Neural Network (CNN)
3.2. DCNN Models and TL Motivation
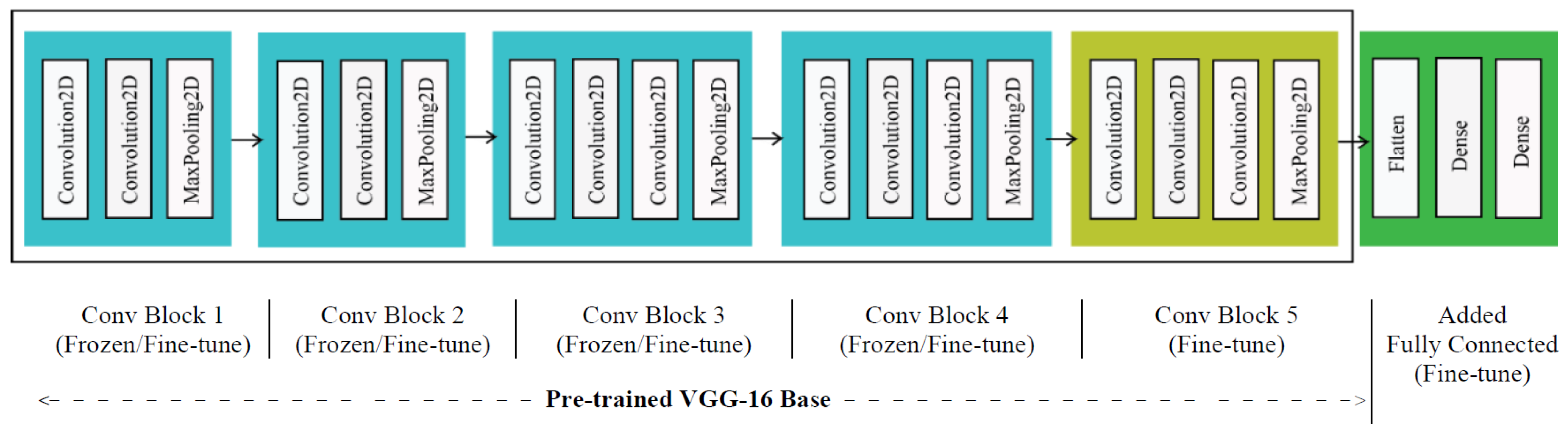
4. Facial Emotion Recognition (FER) Using TL in Deep CNNs
5. Experimental Studies
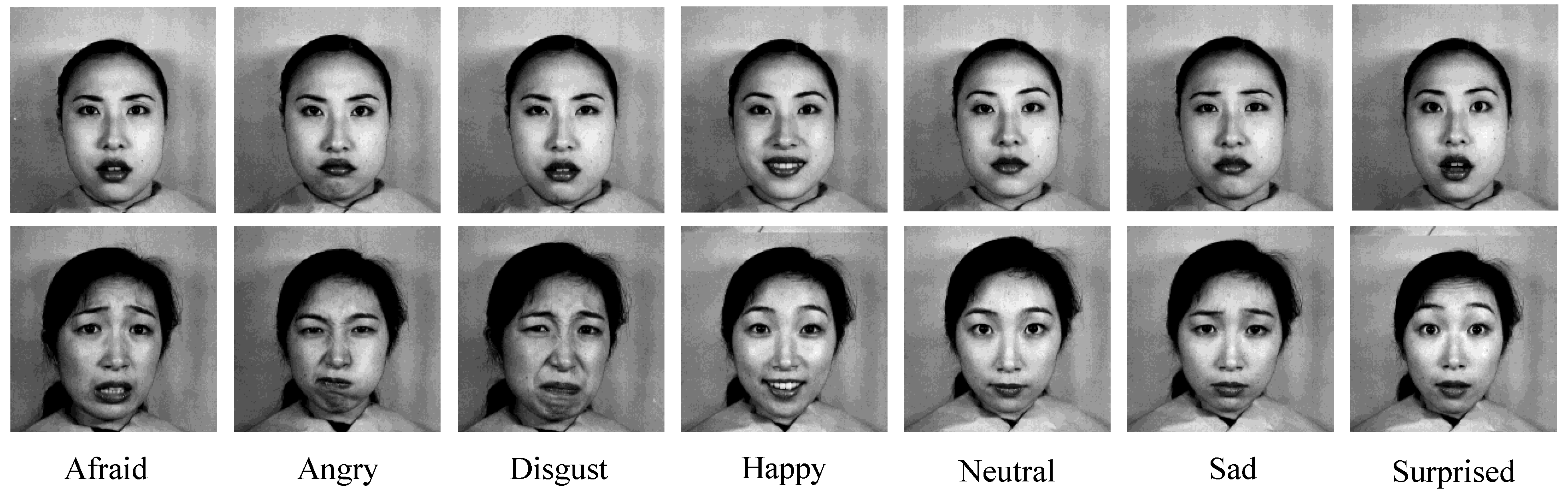
5.1. Benchmark Datasets
5.2. Experimental Setup
5.3. Experimental Results and Analysis
5.4. Results Comparison with Existing Methods
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ekman, P. Cross-Cultural Studies of Facial Expression. Darwin and Facial Expression; Malor Books: Los Altos, CA, USA, 2006; pp. 169–220. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Pers. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [Green Version]
- Avila, A.R.; Akhtar, Z.; Santos, J.F.; O’Shaughnessy, D.; Falk, T.H. Feature Pooling of Modulation Spectrum Features for Improved Speech Emotion Recognition in the Wild. IEEE Trans. Affect. Comput. 2021, 12, 177–188. [Google Scholar] [CrossRef]
- Fridlund, A.J. Human facial expression: An evolutionary view. Nature 1995, 373, 569. [Google Scholar]
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal Emotion Recognition in Response to Videos. IEEE Trans. Affect. Comput. 2012, 3, 211–223. [Google Scholar] [CrossRef] [Green Version]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-Visual Emotion Recognition in Video Clips. IEEE Trans. Affect. Comput. 2019, 10, 60–75. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Measuring facial movement. Environ. Psychol. Nonverbal Behav. 1976, 1, 56–75. [Google Scholar] [CrossRef]
- Ekman, P. Universal Facial Expressions of Emotion. Calif. Ment. Health 1970, 8, 151–158. [Google Scholar]
- Suchitra, P.S.; Tripathi, S. Real-time emotion recognition from facial images using Raspberry Pi II. In Proceedings of the 2016 3rd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 11–12 February 2016; pp. 666–670. [Google Scholar] [CrossRef]
- Yaddaden, Y.; Bouzouane, A.; Adda, M.; Bouchard, B. A new approach of facial expression recognition for ambient assisted living. In Proceedings of the 9th ACM International Conference on PErvasive Technologies Related to Assistive Environments —PETRA, Corfu Island, Greece, 29 June–1 July 2016; Volume 16, pp. 1–8. [Google Scholar] [CrossRef]
- Fernández-Caballero, A.; Martínez-Rodrigo, A.; Pastor, J.M.; Castillo, J.C.; Lozano-Monasor, E.; López, M.T.; Zangróniz, R.; Latorre, J.M.; Fernández-Sotos, A. Smart environment architecture for emotion detection and regulation. J. Biomed. Inf. 2016, 64, 55–73. [Google Scholar] [CrossRef]
- Wingate, M. Prevalence of Autism Spectrum Disorder among children aged 8 years-autism and developmental disabilities monitoring network, 11 sites, United States, 2010. MMWR Surveill. Summ. 2014, 63, 1–21. [Google Scholar]
- Thonse, U.; Behere, R.V.; Praharaj, S.K.; Sharma, P.S.V.N. Facial emotion recognition, socio-occupational functioning and expressed emotions in schizophrenia versus bipolar disorder. Psychiatry Res. 2018, 264, 354–360. [Google Scholar] [CrossRef]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-Based Database for Facial Expression Analysis. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; pp. 317–321. [Google Scholar] [CrossRef] [Green Version]
- Gross, R.; Matthews, I.; Cohn, J.; Kanade, T.; Baker, S. Multi-PIE. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef]
- O’Toole, A.J.; Harms, J.; Snow, S.L.; Hurst, D.R.; Pappas, M.R.; Ayyad, J.H.; Abdi, H. A video database of moving faces and people. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 812–816. [Google Scholar] [CrossRef] [PubMed]
- Liew, C.F.; Yairi, T. Facial Expression Recognition and Analysis: A Comparison Study of Feature Descriptors. IPSJ Trans. Comput. Vis. Appl. 2015, 7, 104–120. [Google Scholar] [CrossRef] [Green Version]
- Ko, B.C. A Brief Review of Facial Emotion Recognition Based on Visual Information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Sahu, M.; Dash, R. A Survey on Deep Learning: Convolution Neural Network (CNN). In Smart Innovation, Systems and Technologies; Springer: Singapore, 2021; Volume 153, pp. 317–325. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Shi, X.; Zhang, S. Facial Expression Recognition via Deep Learning. IETE Tech. Rev. 2015, 32, 347–355. [Google Scholar] [CrossRef]
- Li, J.; Huang, S.; Zhang, X.; Fu, X.; Chang, C.-C.; Tang, Z.; Luo, Z. Facial Expression Recognition by Transfer Learning for Small Datasets. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 895, pp. 756–770. [Google Scholar]
- Bendjillali, R.I.; Beladgham, M.; Merit, K.; Taleb-Ahmed, A. Improved Facial Expression Recognition Based on DWT Feature for Deep CNN. Electronics 2019, 8, 324. [Google Scholar] [CrossRef] [Green Version]
- Ngoc, Q.T.; Lee, S.; Song, B.C. Facial Landmark-Based Emotion Recognition via Directed Graph Neural Network. Electronics 2020, 9, 764. [Google Scholar] [CrossRef]
- Pranav, E.; Kamal, S.; Chandran, C.S.; Supriya, M. Facial emotion recognition using deep convolutional neural network. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 317–320. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Kolen, J.F.; Kremer, S.C. Gradient Flow in Recurrent Nets: The Difficulty of Learning LongTerm Dependencies. In A Field Guide to Dynamical Recurrent Networks; Wiley-IEEE Press: Hoboken, NJ, USA, 2010; pp. 237–243. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Alshamsi, H.; Kepuska, V.; Meng, H. Real time automated facial expression recognition app development on smart phones. In Proceedings of the 2017 8th IEEE Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 3–5 October 2017; pp. 384–392. [Google Scholar] [CrossRef] [Green Version]
- Alshamsi, H.; Kepuska, V.; Meng, H. Stacked deep convolutional auto-encoders for emotion recognition from facial expressions. Proc. Int. Jt. Conf. Neural Netw. 2017, 2017, 1586–1593. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1717–1724. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3320–3328. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer Learning. In Machine Learning Applications and Trends; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial Expression Recognition: A Survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.Q.; Wei, J. Application of wavelet energy feature in facial expression recognition. In Proceedings of the 2007 International Workshop on Anti-Counterfeiting, Security and Identification (ASID), Xiamen, China, 16–18 April 2007; pp. 169–174. [Google Scholar] [CrossRef]
- Zhao, L.; Zhuang, G.; Xu, X. Facial expression recognition based on PCA and NMF. In Proceedings of the 2008 7th World Congress on Intelligent Control and Automation, Chongqing, China, 25–27 June 2008; pp. 6826–6829. [Google Scholar] [CrossRef]
- Feng, X.; Pietikainen, M.; Hadid, A. Facial expression recognition based on local binary patterns. Pattern Recognit. Image Anal. 2007, 17, 592–598. [Google Scholar] [CrossRef]
- Zhi, R.; Ruan, Q. Facial expression recognition based on two-dimensional discriminant locality preserving projections. Neurocomputing 2008, 71, 1730–1734. [Google Scholar] [CrossRef]
- Lee, C.-C.; Shih, C.-Y.; Lai, W.-P.; Lin, P.-C. An improved boosting algorithm and its application to facial emotion recognition. J. Ambient. Intell. Humaniz. Comput. 2012, 3, 11–17. [Google Scholar] [CrossRef]
- Chang, C.-Y.; Huang, Y.-C. Personalized facial expression recognition in indoor environments. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Shih, F.Y.; Chuang, C.-F.; Wang, P.S.P. Performance comparisons of facial expression recognition in JAFFE database. Int. J. Pattern Recognit. Artif. Intell. 2008, 22, 445–459. [Google Scholar] [CrossRef]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on Local Binary Patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Jabid, T.; Kabir, H.; Chae, O. Robust Facial Expression Recognition Based on Local Directional Pattern. ETRI J. 2010, 32, 784–794. [Google Scholar] [CrossRef]
- Joseph, A.; Geetha, P. Facial emotion detection using modified eyemap–mouthmap algorithm on an enhanced image and classification with tensorflow. Vis. Comput. 2020, 36, 529–539. [Google Scholar] [CrossRef]
- Pons, G.; Masip, D. Supervised Committee of Convolutional Neural Networks in Automated Facial Expression Analysis. IEEE Trans. Affect. Comput. 2018, 9, 343–350. [Google Scholar] [CrossRef]
- Wen, G.; Hou, Z.; Li, H.; Li, D.; Jiang, L.; Xun, E. Ensemble of Deep Neural Networks with Probability-Based Fusion for Facial Expression Recognition. Cogn. Comput. 2017, 9, 597–610. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, S.K.; Chellappa, R. FaceNet2ExpNet: Regularizing a deep face recognition net for expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 118–126. [Google Scholar] [CrossRef] [Green Version]
- Jain, N.; Kumar, S.; Kumar, A.; Shamsolmoali, P.; Zareapoor, M. Hybrid deep neural networks for face emotion recognition. Pattern Recognit. Lett. 2018, 115, 101–106. [Google Scholar] [CrossRef]
- Shaees, S.; Naeem, H.; Arslan, M.; Naeem, M.R.; Ali, S.H.; Aldabbas, H. Facial Emotion Recognition Using Transfer Learning. In Proceedings of the 2020 International Conference on Computing and Information Technology (ICCIT-1441), Tabuk, Saudi Arabia, 9–10 September 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Liliana, D.Y. Emotion recognition from facial expression using deep convolutional neural network. J. Phys. Conf. Ser. 2019, 1193, 012004. [Google Scholar] [CrossRef] [Green Version]
- Shi, M.; Xu, L.; Chen, X. A Novel Facial Expression Intelligent Recognition Method Using Improved Convolutional Neural Network. IEEE Access 2020, 8, 57606–57614. [Google Scholar] [CrossRef]
- Jin, X.; Sun, W.; Jin, Z. A discriminative deep association learning for facial expression recognition. Int. J. Mach. Learn. Cybern. 2019, 11, 779–793. [Google Scholar] [CrossRef]
- Porcu, S.; Floris, A.; Atzori, L. Evaluation of Data Augmentation Techniques for Facial Expression Recognition Systems. Electronics 2020, 9, 1892. [Google Scholar] [CrossRef]
- Akhand, M.A.H.; Ahmed, M.; Rahman, M.M.H.; Islam, M. Convolutional Neural Network Training incorporating Rotation-Based Generated Patterns and Handwritten Numeral Recognition of Major Indian Scripts. IETE J. Res. 2018, 64, 176–194. [Google Scholar] [CrossRef] [Green Version]
- Antonellis, G.; Gavras, A.G.; Panagiotou, M.; Kutter, B.L.; Guerrini, G.; Sander, A.C.; Fox, P.J. Shake Table Test of Large-Scale Bridge Columns Supported on Rocking Shallow Foundations. J. Geotech. Geoenviron. Eng. 2015, 141, 04015009. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Roos, P.C.; Schuttelaars, H.M. Resonance properties of tidal channels with multiple retention basins: Role of adjacent sea. Ocean. Dyn. 2015, 65, 311–324. [Google Scholar] [CrossRef] [Green Version]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar] [CrossRef] [Green Version]
- Bukar, A.M.; Ugail, H. Automatic age estimation from facial profile view. IET Comput. Vis. 2017, 11, 650–655. [Google Scholar] [CrossRef] [Green Version]
- Mahendran, A.; Vedaldi, A. Visualizing Deep Convolutional Neural Networks Using Natural Pre-images. Int. J. Comput. Vis. 2016, 120, 233–255. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y. Earning Deep Architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Marcelino, P. Solve any Image Classification Problem Quickly and Easily. 2018. Available online: https://www.kdnuggets.com/2018/12/solve-image-classification-problem-quickly-easily.html (accessed on 1 April 2021).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bartlett, P.L.; Hazan, E.; Rakhlin, A. Adaptive Online Gradient Descent. Adv. Neural Inf. Process. Syst. 2007, 20, 1–8. [Google Scholar]
- Tieleman, T.; Hinton, G.E.; Srivastava, N.; Swersky, K. RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Calvo, M.G.; Lundqvist, D. Facial expressions of emotion (KDEF): Identification under different display-duration conditions. Behav. Res. Methods 2008, 40, 109–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lyons, M.J.; Akamatsu, S.; Kamachi, M.; Gyoba, J.; Budynek, J. The Japanese Female Facial Expression (JAFFE) Database. Available online: http://www.kasrl.org/jaffe_download.html (accessed on 1 February 2021).
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar] [CrossRef]
- François, C. Keras: The Python Deep Learning Library. Available online: https://keras.io (accessed on 15 November 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Image Size | KDEF | JAFFE |
|---|---|---|
| 360 × 360 | 73.87% | 91.67% |
| 224 × 224 | 73.46% | 87.50% |
| 128 × 128 | 80.81% | 91.67% |
| 64 × 64 | 69.39% | 83.33% |
| 48 × 48 | 61.63% | 79.17% |
| Training Mode | KDEF | JAFFE |
|---|---|---|
| Dense Layers only | 77.55% | 91.67% |
| Dense Layers + VGG-16 Block 5 | 91.83% | 95.83% |
| Entire Model (Dense Layers + Full VGG-16 Base) | 93.47% | 100.0% |
| Whole Model from Scratch | 23.35% | 37.82% |
| Pre-Trained Deep CNN Model | KDEF in Selected 10% Test Samples | KDEF in 10-Fold CV | JAFFE in Selected 10% Test Samples | JAFFE in 10-Fold CV |
|---|---|---|---|---|
| VGG-16 | 93.47% | 93.02 ± 1.48% | 100.0% | 97.62 ± 4.05% |
| VGG-19 | 96.73% | 95.29 ± 1.12% | 100.0% | 98.41 ± 3.37% |
| ResNet-18 | 94.29% | 93.98 ± 0.84% | 100.0% | 98.09 ± 3.33% |
| ResNet-34 | 96.33% | 94.83 ± 0.88% | 100.0% | 98.57 ± 3.22% |
| ResNet-50 | 97.55% | 95.20 ± 0.89% | 100.0% | 99.05 ± 3.01% |
| ResNet-152 | 96.73% | 96.18 ± 1.28% | 100.0% | 99.52 ± 1.51% |
| Inception-v3 | 97.55% | 95.10 ± 0.91% | 100.0% | 99.05 ± 2.01% |
| DenseNet-161 | 98.78% | 96.51 ± 1.08% | 100.0% | 99.52 ± 1.51% |
| AF | AN | DI | HA | NE | SA | SU | |
|---|---|---|---|---|---|---|---|
| Afraid (AF) | 67 | 0 | 0 | 0 | 0 | 0 | 3 |
| Angry (AN) | 0 | 70 | 0 | 0 | 0 | 0 | 0 |
| Disgusted (DI) | 0 | 0 | 70 | 0 | 0 | 0 | 0 |
| Happy (HA) | 0 | 0 | 0 | 70 | 0 | 0 | 0 |
| Neutral (NE) | 0 | 0 | 0 | 0 | 70 | 0 | 0 |
| Sad (SA) | 0 | 0 | 1 | 0 | 0 | 69 | 0 |
| Surprised (SU) | 2 | 0 | 0 | 0 | 0 | 0 | 68 |
| Misclassified Image: True Class → Predicted Class | ||||||
|---|---|---|---|---|---|---|
| Samples from KDEF |  |  |  |  |  |  |
| 1. Afraid → Surprised | 2. Afraid → Surprised | 3. Sad → Disgust | 4. Afraid → Surprised | 5. Surprised → Afraid | 6. Surprised → Afraid | |
| Sample from JAFFE |  | |||||
| 7. Afraid → Surprised | ||||||
| Work [Ref.], Year | Total Samples: Training and Test Division | Test Set Accuracy (%) | Method’s Significance in Feature Selection and Classification | |
|---|---|---|---|---|
| KDEF | JAFFE | |||
| Zhi and Ruan [46], 2008 | 213: 30-Fold CV | 95.91 | Derived feature vector from 2D discriminant locality preserving projections | |
| Shih el al. [49], 2008 | 213: 10-Fold CV | 95.70 | Feature representation using DWT with 2D-LDA and classification using SVM | |
| Shan et al. [50], 2009 | 213: 10-Fold CV | 81.00 | Feature extraction using statistical local features and LBPs; classification with different variants of SVM | |
| Jabid et al. [51], 2010 | 213: 7-Fold CV | 82.60 | Feature extraction using appearance-based technique and classification with different variants of SVM | |
| Chang and Huang [48], 2010 | 210: 105 + 105 | 98.98 | Incorporated face recognition and used RBF for classification | |
| Lee et al. [47], 2011 | 210: 30-Fold CV | 96.43 | Contourlet Transform for feature extraction and Boosting algorithm for classification | |
| Liew and Yairi, [17], 2015 | KDEF# 980 frontal images: 90% + 10% JAFFE# 213:90% + 10% | 82.40 | 89.50 | feature extracted employing Gabor, Haar, LBP etc. and classify using SVM, KNN, LDA, etc. |
| Alshami el al. [35], 2017 | KDEF# 980 frontal images: 70% + 30% JAFFE# 213: 70% + 30% | 90.80 | 91.90 | Used Facial Landmarks descriptor and Center of Gravity descriptor with SVM |
| Joseph and Geetha [52], 2019 | Selected 478 images: 10-Fold CV | 31.20 | Facial geometry-based feature extraction with different classification methods including SVM, KNN | |
| Standard CNN (Self Implemented) | KDEF# 4900: 90% + 10% JAFFE# 213: 90% + 10% | 80.81 | 91.67 | Standard CNN with fully connected layer for classification |
| Zhao and Zhang [22], 2015 | 213: 10-Fold CV | 90.95 | DBN is used for unsupervised feature learning and NN is used for classification | |
| Ruiz-Garcia et al. [36], 2017 | 980 frontal images: 70% + 30% | 92.52 | Stacked Convolutional Auto-Encoder (SCAE) is used to initialize weights of CNN. | |
| Jain et al. [56], 2018 | 213: 70% + 30% | 94.91 | Hybrid deep learing architecture with CNN and RNN | |
| Bendjillali et al. [24], 2019 | 213: 70% + 30% | 98.63 | Image enhancement, feature extration and classification using CNN | |
| Proposed Method with DenseNet-161 | KDEF# 4900: 90% + 10% JAFFE# 213: 90% + 10% | 98.78 | 100.00 | Transfer leaning on pre-trained Deep CNN model employing a pipeline strategy in fine-tuning |
| KDEF# 4900: 10-Fold CV JAFFE# 213: 10-Fold CV | 96.51 | 99.52 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. https://doi.org/10.3390/electronics10091036
Akhand MAH, Roy S, Siddique N, Kamal MAS, Shimamura T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics. 2021; 10(9):1036. https://doi.org/10.3390/electronics10091036
Chicago/Turabian StyleAkhand, M. A. H., Shuvendu Roy, Nazmul Siddique, Md Abdus Samad Kamal, and Tetsuya Shimamura. 2021. "Facial Emotion Recognition Using Transfer Learning in the Deep CNN" Electronics 10, no. 9: 1036. https://doi.org/10.3390/electronics10091036
APA StyleAkhand, M. A. H., Roy, S., Siddique, N., Kamal, M. A. S., & Shimamura, T. (2021). Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics, 10(9), 1036. https://doi.org/10.3390/electronics10091036