1. Introduction
A trip is defined as a collection of interesting places to visit. It is the act of going from one location to another to have pleasure; we can learn about different cultures, make new friendships, and expand our circles. Travel can help us become more aware of ourselves and others. Personalized trip recommenders that propose consecutive locations of interest (LOIs) to tourists are gaining popularity, thanks to the fast development of applications and trip access systems. Traditional trip recommendations assess the novelty of the LOI’s audience engagement and user preferences and suggest consecutive LOIs with the best user experiences [
1,
2]. The rapid development of cities has increased the number of sites of interest (SOIs) that can be visited on a trip. These LOIs can be cafés, lodgings, seashores, occasions, films, stops coordinates, or even parks. Location-based social networks (LBSNs) are a vast field. The data sizes generated by LBSNs enable professionals to extract precise personal information to provide superior assistance in end-user apps, contrasting with solitary LOI suggestions and arrangement proposals. Two or three examinations consider LOI arrangement proposals. To display the LOI groupings, a handful of experts recommended ubiquity-based techniques for the suggestion task [
3,
4], which implies that finding a LOI succession increases the prevalence of the LOI. In these ways, all users will have the same suggestions. Moreover, other customization-based methodologies [
1,
5] have been created, with superb itineraries recommended for explorers (i.e., according to their potential benefits and tendencies). This has led to one of the earlier top travel recommenders in [
3], where scientists utilized geotagged Flickr photographs to close personal interests and propose multi-day plans via recursive unquenchable calculations. In [
6], user registration information and ’found’-based assessments were suggested to observe optimal journeys under various necessities. The dynamic value was high. In [
7], changes in metropolitan regions were proposed by using LOI plans and recommending various settings.
Of late, ref. [
8], suggested time-sensitive user premiums have shown advantages over the use of rehash-based standing criteria in trip personalizations. In [
9], re-tried itinerary items in different periods were proposed by combining text-based information and perspective data dispensed from photographs. A few specialists have considered time factors when planning trip proposal models [
10]. The outing suggestion has the following problems:
(1) LOI arrangement propositions are expected to recommend legitimately strong LOI progressions that precisely meet the benefits and tendencies of the users, as opposed to just single LOIs; (2) user tendencies might change with an event, which increases the barrier of a dynamic idea; (3) with the LOI progression proposition, it is tricky to different components (e.g., schema, transient, ridiculous, etc.). (4) Recommending specific and precise areas can make users exhausted [
11,
12,
13,
14], i.e., looking at similar sorts of LOIs repeatedly is, in some cases, aggravating and exhausting. (5) How would the trip recommendation solve the cold-start issue?
Our motivation. To deal with the difficulties in ’outing’ suggestions, we introduce a fortunate refining trip recommendation (FRTR). Previous accuracy objectives, especially assortments, oddities, and luck, have been highlighted in the literature as they allow users to track new and different trips to grow their perspectives.
Variety specifies the differentiation between an ongoing suggestion and the user’s profile. A concept of the journey indicates whether the individual is aware of it. Trips that are unknown to a user are often evaluated lower since the users frequently view renowned trips; prominence may be measured by the volume of evaluations in the framework. Good fortune comes up if the individual feels surprisingly happy when s/he sees a recommended trip [
15,
16], i.e., a trip that is not ’appropriate’ according to the individual’s preferences, and yet, is amazing, even if it was not intentionally searched for by the individual. In the new trip proposal model, the time element is emphasized [
10]. One objective is to recommend LOIs at the assigned predetermined times of a user’s history of voyaging [
17]. Existing examinations model the effects of the previous LOI with a first-request Markov model [
18,
19,
20].
The trip proposition is planned explicitly for (1) the input of action heading towards the destination and (2) the result progression, as the unique groupings of the recommended LOIs. Various assessments have been conducted to settle the succession-to-arrangement learning issue [
3,
4]. The deep neural network (DNN) has brought about unprecedented accomplishments in various fields [
21], arranging the design of the FRTR in light of the deep neural network. Our responsibilities are the following:
This innovative research presents an ever-evolving sequence of LOI idea structures, named FRTR, which suggests a fortunate grouping of LOIs progressively (according to recorded history);
FRTR finds the LOI from the trip histories of users and will suggest a trip utilizing good fortune;
To use various information from LOIs, the topographical LOI inserts quality, and the outright effects of the recorded bearings with positional encoding are commonly considered suggesting dynamic trip proposals;
This innovative research similarly presents two estimations, i.e., regulated precision (RP) and pattern precision (PP), which looks at LOI property and the voyaging request and evaluate the idea accuracy of the arrangement of LOIs;
FRTR will address the cold-start issue—that the model cannot generate enlistments regarding users or travel for whom it does not have sufficient information;
We evaluate the presentation of FRTR with a few baselines. Experimental outcomes show that FRTR is better than baselines trip proposal strategies.
Section 2 describes the associated literature.
Section 3 gives the problem statement and an outline of the model.
Section 4 describes the designed model.
Section 5 displays the experimental outcomes. Finally,
Section 6 presents the conclusion.
2. Related Work
This will focus on the conversations of past examinations on travel recommendations and various methodologies utilized for travel recommendations. A travel recommendation is a traditional identification issue. Different strategies have been explored for development executions. Of late, deep learning methods have presented possible results for this issue. We present past voyage suggestion works.
A serendipity-oriented personalized trip recommendation model. Customized trip proposal endeavors [
22] suggest a succession of locations of interest (LOIs) to a user. The LOI’s succession proposal is difficult (contrasted and solitary to LOI suggestions). Two or three examinations focus on LOI grouping suggestions. This is a test to create a dependable succession of LOIs. Two sequential LOIs should not be comparable or from a similar classification. In fostering the arrangements of LOIs, taking into account the classes of back-to-back LOIs is essential. The main issue is that suggesting a specific area can exhaust the user. Taking a gander at similar sorts of LOIs, over and over, is sometimes bothering and monotonous. To resolve these problems, one must look for successive, pertinent, novel, and startling (with fulfillment) LOIs to design a customized trip. To create successive LOIs, they used LOI-likeness and classification contrasts among the back-to-back LOIs. In our trip idea, we include good fortune. To manage the difficulties in finding and assessing user fulfillment, they suggested a serendipity-oriented personalized trip recommendation (SOTR). A persuasive suggestion calculation should not just endorse what we are likely to appreciate but also recommend unusual (yet essential) features to preserve an open window to distinct worlds and revelations. This empirically affirms that sound fortune impacts the user’s fulfillment and social objectives. We have taken a look at the effects of good fortune on expanding the ’exactness’ by removing the examination. Some previous accuracy objectives, especially assortment, oddity, and good fortune, have been highlighted in the literature as they focus on allowing users to track down special and different excursions to grow their perspectives. Given that, SOTR suggests travel with comprehensive user fulfillment to expand the user’s perspective. We illustrate that our calculation beats different proposal strategies by fulfilling user intrigues in the outing.
Their work is not equivalent to ours, as we execute good fortune and dynamicity in our model.
Recommending a ’reforming trip’ for group of users. A high-level radical trip suggestion method was carried out in this examination [
23]. The quick progression of adaptable applications and trip-bearing advancements, such as a trip recommender which proposes continuous locations of interest (LOIs) to pilgrims, has emerged and gained universality. It is different from other trip recommenders, suggesting departures with single LOIs. Their suggested trip recommendation method depends on the LOI-gathering recommendation. An undeniable ’level’ trip of the LOI proposition method, called RRT, was introduced, endorsing the progression of LOIs to social occasions for users. It shows the information development in a clear heading, and the outcome involves the approach of the LOI that is not a strange social event for the user. A productive course of action is implemented to manage this progression. Starting from the furthest limit ’loop of activity’, RRT can permit the commitment to modify (after a certain point) by impeccably recommending an exceptional course of action for the LOI. Furthermore, two advanced new appraisals, sequence-mindful precision (SMP) and adjusted precision (AP), are presented, recommending the exactness of a gathering of LOIs. These two estimates will guarantee the dependable arrangements of LOIs in prescribing trips to the users. The trip narratives were used from the Weeplaces dataset. In a similar manner, the exploratory results of the relative multitude of estimations above represent huge RRT advantages (in making dynamic outing suggestions for a gathering of users).
This method prescribes changing trips for a gathering of users, which is not the same as our work, as we suggest customized trips utilizing luck and dynamicity.
SNPR: a serendipity-oriented next POI recommendation model. SNPR, the serendipitous LOI proposition [
21], attempts to recommend a progression of central places (PCPs) to an individual. The problem that the location of interest (LOI) goes up against is that recommending a particular and definite region can deplete an individual. Looking at comparative LOIs, again and again, can be irritating and bleak. This work thought about a procedure and arranged the serendipitous LOI recommendation model. The suggested fortunate LOI recommendation method deals with the troubles of disclosure and evaluating individual satisfaction. A persuasion strategy estimation should not just support what we are likely to enjoy but also support unpredictably reliable elements that aid in maintaining an open window to diverse cities and countries; it should evaluate the computation using information secured from a certified data set and individual travel narratives eliminated from a Foursquare dataset. The authors observationally attested the weakness impacts on growing personal satisfaction and social points. Considering that, the authors recommended a LOI with high individual satisfaction to enhance the unique experience. At this point, the computation outflanks different proposition methods by satisfying an individual’s advantages in the trip.
This work suggests only a solitary following LOI contrasted with this work. We offer a complete trip utilizing luck and dynamicity. The trip comprises a dependable grouping of LOIs. It is a method to create a trustworthy arrangement of LOIs. The two consecutive LOIs in the collection should not be comparable or from the same class.
The referenced trip suggestion systems use aggregation methodologies to prescribe exciting areas to visit. By correlation, our strategy suggests the fortunate grouping of LOIs dynamically.
3. The Problem Statement and the Model Overview
3.1. The Problem Statement
In this part, we explain the issue we addressed. The traveling proposal has received much attention. Nonetheless, a couple of things are missing for user fulfillment. Primarily, recommender systems are capable of collaborative and content-based filtering, recommending trips by checking location and user similarity. Our luck-arranged customized trip proposal model will address the cold-start issue. Some trip suggestion frameworks prescribe trips as indicated by relativity and exactness. Recommending relative and precise areas is not always good. Users can experience exhaustion and it will ruin their enthusiasm. Thus, to resolve this issue, we present ’good fortune’ in our trip proposal framework. We characterize the fundamental ideas of a trip utilizing luck and provide a short outline of our answer. Favorable luck involves the occasion and improvement of events by chance (merrily or accommodatingly). Good fortune energizes users, leaving them effectively satisfied. The representations are summarized in
Table 1.
When suggesting the succession of LOIs, we think about the sequences of the LOIs; two continuous LOIs should not be comparable. The issue of a static LOI grouping is a subject that we address in our high-level examination. All of the past trip proposal models prescribed fixed LOI groupings to the users. Be that as it may, imagine a scenario where users need to change their arrangements for the trip. As we probably know, a trip involves a mix of a collection of LOIs. The trip suggested from the beginning is a static trip; the user cannot continue to the destination dynamically.
3.2. Problem Formulation
To deal with the difficulties in an outing suggestion, we introduce a fortunate refining trip recommendation (FRTR). Previous accuracy objectives, especially assortment, oddity, and luck, have been highlighted in the literature as they allow users to track new and different trips to grow their perspectives.
We take three information records History, LOI lkns, and Cat Diff, by stacking the dataset. From the History, we obtain the user profile . We extricate the user genre list, LOI toured, novelty, significance, and unpredictability. For every individual usr ∈ UsrP, we can obtain a trajectory gathering tended to by from individual profiles , where n is the record of the ongoing heading. Each heading contains a gathering of LOIs traveled by the individual having the consecutive organize, i.e., , (loi has a spot with Loi). In this work, we treat an individual’s registration in a solitary day as a singular direction. To create the trip, it is important to ensure that continuous LOIs not be comparable or from a similar class.
We resolved the issue of reforming by prescribing the outing progressively to a user. We inputted, in the past, a few LOIs and obtained the following POI stepwise as opposed to each of the groupings of LOIs toward the beginning. For instance, we obtained the past two LOIs of a gathering of users (LOIs = L1, L2) and afterward suggested the third POI, so the grouping was LOIs = L1, L2, L3. Then, at that point, we acquired the past succession as info LOIs = L1, L2, L3 and afterward suggested the following POI, so the grouping was LOIs = L1, L2, L3, L4.
In our travel recommendations, we leverage luck and dynamicity. We suggest a fortunate refining trip recommendation (FRTR) to address the issues of identifying and rating user pleasures. A compelling recommendation method should offer what we are likely to enjoy and provide spontaneous (yet objective) components to maintain an open doorway to new worlds and discoveries. We execute an advanced strategy named FRTR for customized trip suggestions utilizing luck and dynamicity. FRTR finds a user’s fulfillment, given significance, curiosity, and surprise. The proposal calculation was planned to design the travel and amplify the user’s experience.
3.3. Solution Outline
We describe a concise outline of the planned FRTR; the structure is presented in
Figure 1. I.
Fortunate trip. Provides a user
usr and a trip
trp; this part ascertains the fortunate factual actuality of
trp to
usr based on the model discussed in
Section 3.1. II.
Dynamicity of a trip. The user
usr and a trip
trp; this part ascertains the dynamicity reality of
trp to
usr according to the model. III.
Delicate neural network designing. To anticipate the ’fortune’ of a trip
trp; this involves a fragile neural network model. This will be described in
Section 4. IV.
Recommendation. The organization prototype was prepared to utilize the figured validity and it prescribes the active fortunate travel.
4. The Designed Model
In this part, we make sense of a carefully planned neural network model to the trip
trp suggestion.
Figure 2 addresses the architecture of FRTR. It contains nine modules. (a) Trajectory encoding encodes each LOI in every course of a user through the transformer encoder. (b) ’Create order’ shows the user; to create the grouping of LOIs to make certain sequential LOIs should no longer be the same or from identical classes for a trip
trp to
usr. (c) Novelty indicates the character, to assume the abnormality of a trip
trp to
usr. (d) Unexpectedness shows the character, to count on the unexpectedness of a trip
trp to
usr. (e) Relevance shows individuals to foresee the significance of a time-out
trp to
usr. (f) Enhancement utilizes the Adam optimizer; the user’s genre list and traveled LOIs will be improved. (g) Trip creator will obtain records from advancements, produced successions, significance, novelty, and unexpectedness to the GRU to take a fortunate trip
trp to
usr. (h) The fortunate trip proposal produces fortunate LOIs for a user as indicated by using the predicted ’good fortune’ of each competitor and the association of fortunate LOIs
to
usr. (i) The refining recommendation produces the association of dynamic LOIs for a user as indicated by using
to
usr.
4.1. Trajectory Encoding
In trip
trp, for each LOI
loi ∈ Loi and every characterization
c ∈ C, toward the beginning, we present their depictions through a uniform trip. At that point, we gather the hidden vector (implied by utilizing
loi) of every LOI
loi in trip
trp by connecting its base depiction and the key depiction of its arrangement. Regarding an individual,
Trj =
is the course progression. We accomplish skillability with the smoothed-out depictions of all LOIs
for all of their trajectories
as portrayed in
Figure 2.
In recent years, many works have utilized RNNs to investigate LOI portrayals for road trip
trp ideas and accomplish decent outcomes. Despite their prevalence and feasibility, we found that they lacked perceived outstanding depictions for individual conduct groupings. They can have tremendous model successive activities in the user’s registration grouping. Nonetheless, non-sequential LOIs are simultaneously settled because of the reality of certain variables, such as their geological distances. Such qualities will be tricky to trap through RNN-based methods [
24]. The transformer [
25] does not need successive information to be managed together. It can trap the events between depiction units no matter their distance in the groupings. Thus, we influence the transformer encoder to insert the LOIs.
4.2. Create Sequence
In trip trp, for each LOI loi ∈ Loi and each classification c ∈ C, we originally present their depictions via the equal acquisition. Then, we gather the successive order of LOIs . To ensure that two subsequent LOIs are no longer comparable and from the same categories, we apply LOI lkns and Cat Diff. This issue must be addressed in the travel recommendations. In a sequence of LOIs, two successive LOIs must not have ’resorted’. We verify this by generating a series. We obtain LOI lkns and Cat Diff by using the dataset. As a result, two successive LOIs must be checked, and . We will take a look at the LOIs—the use of LOI lkns and Cat Diff. For example, we must not recommend a hotel after traveling to a hotel when recommending the trip. It is essential to verify the class distinction and suggest a theater for a film after having meal at a hotel.
4.3. Novelty
Novelty estimates the stage of new recommendations that customers have not viewed before or recognized. It is processed as the degree of novel LOIs in the trip proposals. Analysts have proposed several methods to strengthen oddity measures in submission, which include the bunching of long-tailed things, development dispersion, chart-based calculations, and positioning models.
Given a user, this phase fashions the profile
to a vector
, according to
Figure 2, completely focused on anticipating a competitor’s novelty of a competitor trip;
trp to
usr.
The concept emphasizes whether the user is unfamiliar with the trip. Unforgettable trips are often unfavorable to users, as customers are regularly associated with famous trips. This can estimate the place’s reputation by using a wide variety of scores in the system.
Trip
trp 1 is new to a user
usr if s/he has not traveled it. So, we outline the LOI novelty as:
where
is the user’s traveled trip
trp. For a summary of the final discussion, we point out the novelty of the trip
trp to
usr as
.
4.4. Unexpectedness
The recommender framework contains a tremendous amount of equipment to deal with the difficulty of user fatigue; concurrently, ambitions give sudden and pleasant tips to desired users. Past proposition strategies have showcased the immediate relations between current proposals and user presumptions by presenting fantastic quality in the part arrangements, achieving a lack of accuracy measures to strengthen surprising execution.
Given a user, this phase fashions his/her profile
to a vector
according to
Figure 2, entirely purposefully when anticipating the
unexpectedness of a trip
trp to
usr.
Using Equation (
3), the LOI that is startlingly pleasant to an individual is excessive regarding the brief and topographical information of a user’s review. Similarly, we tackle each path as:
where
GELU is the initiation work,
,
,
are learnable variables. Given a user, we can collect each path portrayal
(1 ≤ I ≤ cur). Finally, we simulate the unexpectedness situated character vector (i.e.,
) for users by using their course embeddings
.
4.5. Relevance
The recommender frameworks are well-known personalization units that assist customers in examining imperative records due to the inclinations stored inside their profiles. User profiles count on large phases in accomplishing the ‘idea interplay’, considering that profiles ‘tackle’ the users’ recorded needs. Accordingly, each recommender framework requires creating or maintaining a profile or model of the user inclinations to distinguish the precious necessities of a single user. The exactness of each consumer profile influences the exhibition of the total recommender framework.
Given a user, this phase fashions the profile
to a vector
according to
Figure 2, determining the
relevance of a trip
trp to
usr.
Relevance stresses whether or not the trip applies to a user. Trips applicable to a user are comparable to the user’s factual basis. As customers are often familiar with appropriate trips, they can estimate the place’s relevance with the aid of the number of rankings given to it in the recorded history.
We concern a trip
trp 1 as applicable to a user
usr if s/he has not traveled it. So, we outline the trip
trp relevance as:
where
is the user’s traveled trip
trp. For the summary of the final discussion, we point out the relevance of the trip
trp to
usr as
.
4.6. Enhancement
We utilized the Adam analyzer to enhance the consumer classes and LOI oddity. It is a replacement improvement calculation for stochastic inclination plummet, instructing deep learning information on models. Adam joins the best calculations to supply an improvement calculation that can manage short slants on noisy issues.
Setting the value to none, on the other hand, and then zero, sets the ‘grads’ to none. This will have a diminished memory impact and can decently propel execution. Regardless, it edits specific practices—for instance, (1) at the point when the user attempts to obtain an angle and conduct the careful procedure on it, a ‘none’ property will connect disparately. (2) If the individual solicitations zero_grad(set_to_none = True), seen through a retrogressive pass, “.grads” are guaranteed so as to be ‘none’ for the “params” which did not obtain hold of a slope. Three “torch.optim” streamlining agents will have assorted leads on the off chance that the inclination is zero or none.
4.7. Trip Creator
The trip creator involves enlivening the memory amount of a recurrent neural network and presenting the straightforwardness of the training of a model. We will provide the data acquired from the improvement, succession, novelty, relevance, and suddenness of the gated recurrent unit to obtain a fortunate trip. The gated recurrent unit can be utilized to work this usefulness. The secret component can furthermore solve the gradient that fades away the problems in recurrent neural networks.
4.8. Sequence of Fortunate LOIs
Most trip recommender models recommended are appropriately recognized among all users, who appear to be legitimately exhausted from seeing indistinguishable types of trips more than once. Accordingly, the user obtains hints that s/he is already familiar with, inciting low satisfaction. A recommender structure needs to recommend something novel, significant, and astounding, i.e., a good road trip to clear up this issue. We prescribe a fortunate opportunity to win over the over-specialization issue. Given an individual, we can collect the relevant delineation
,
, and
(in
Section 4.5) and suddenness outline
(in
Section 4.4). Then, at that point, given a road trip
trp, we see definitive customer representation
usr. Finally, we register the positioning rating for the trip
trp as:
where
addresses the expected ’luck’ of a trip to the individual and is displayed by utilizing the inside results of
usr and
trp. This method will suggest the trip
trp to the objective user.
Regarding training proficiency, we embrace an outstanding inspecting technique to explore the parameters of our local area model. Moreover, given a user
usr at the time step
t, we require an exclusively related road trip
trp as the great instructing example. However, we assume the trip
trp with the best suddenness and the trip
trp with the most minimal startling quality as horrendous training cases. In this research study, we set N = 12. The goal trademark was once portrayed as the recommended mean squared error (with L2 standard) regularization:
where the signified parameters have a local model;
Tr is the relationship of a user in all training events. The model used to be taught with the guidance of the Adam analyzer. Algorithm 1 portrays the training of the FRTR model, while Algorithm 2 depicts the recommending fortunate refining trip via the FRTR model.
4.9. Refining Recommendation
The user’s recorded directions diligently change for a drawn-out period, implying that the advantages and tendencies in a similar manner are substituted over an extended period. Therefore, an adaptive thought system is significantly much more prominent and attainable than a deterministic one. With this assessment, the practical method is complete (with preparation). The FRTR provides dynamic rules to empower the LOI relationship to change in time. By then, when the (up-to-this-point) entered sequence of LOIs adjusts, the FRTR dynamically catches the new tendency of the user and afterward recommends a reasonable LOI progression. Rather than various techniques requiring excessive estimation resources to re-register the characteristics of the developing information, the FRTR offers a dynamic LOI sequence plan from beginning to end.
The location of interest (LOI) suggestion draws in the rising considerations of analysts due to the fast improvements of location-based social networks (LBSNs), varying from other recommenders, who suggest the following LOI; this exploration centers around the progressive LOI succession proposal. An original LOI succession suggestion system, named the fortunate refining trip recommendation (FRTR), is proposed, which models the POI-grouping proposal as a sequence-to-sequence (Seq2Seq) learning task, or at least, the information arrangement is in a verifiable direction, and the result grouping is the same LOI grouping to be suggested.
| Algorithm 1: Training the FRTR Model. |
![Electronics 11 02459 i001]() |
| Algorithm 2: Recommending a fortunate refining trip by the FRTR model. |
![Electronics 11 02459 i002]() |
To tackle this Seq2Seq issue, successful engineering is planned in light of the deep neural network (DNN). Attributing to the start-to-finish work process, FRTR can make dynamic POI succession proposals without much of a stretch by permitting the contribution to change after some time.
5. Experiments
The reality assortment, explanation, and pre-handling required to train the model are presented in this section. It also centers on the fortunate refining trip recommendation (FRTR). We (1) describe the crucial experimental plan; (2) recognize our strategy with benchmarks displaying the updates; (3) look at the consequences of hyperparameters; (4) certify the reasonability of every single stage in the suggested method.
5.1. Experimental Setup
5.1.1. The Used Datasets and Data Preprocessing
The registration datasets of two urban areas (New York and United Kingdom) potentially from the most assigned appropriate LBSNs (i.e., Foursquare) were used in our investigation, assembling this reality from April 2012 to February 2013 [
26].
We conducted statistics of each dataset. For LOIs, we disposed of the less-evaluated ones traveled by utilizing under five users. For users, we took care of their registrations as solitary trajectories made in a single day, as presented in
Section 4.1. Then, at that point, we removed the trajectories from underneath three registrations and filtered through the new users underneath the three check-ins. The fundamental estimations of datasets after pre-dealing with them are shown in
Table 2.
Following [
24,
27], we retained the first 80% of directions for the train set and involved the remaining test for every user.
5.1.2. Evaluation Metrics
This assesses everything of good fortune in various ways. We first procured three generally used measurements for importance assessments: precision, recall, along with normalized discounted cumulative gain (NG), which suggests the highest levels of succession of the LOIs for travel.
The most-used dimensions for assessing trips are
precision,
recall, and
F1 score [
28,
29,
30,
31]. Nonetheless, the central drawback of these actions is that they all neglect the sequence for the LOI in the trip. Interestingly, the sequence is a fundamental part of the LOI arrangement guidance for a venture. We place (into impact) a summation of the
precision,
recall,
uxp,
ng,
ru,
rp, and
pp. We think about dynamic LOI successions to propose the trip. We append the
precision,
recall,
uxp,
ng,
ru,
rp, and
pp of every trip and gap them with the assortment of LOI arrangements.
An assortment of peaks assessed the fortunate LOI successions to support a road trip for the individual
usr, addressed as
, and the actual traveled LOIs in the investigated set, signified as
. The initial two measurements are registered by:
The sum of
precision for
k the LOI sequence is calculated as:
The
Sum of recall for the
k LOI sequence is calculated as:
Instinctively,
precision indicates which level of the suggested trip is genuinely traveled by users and
note signifies which level of users’ who truly travel the LOIs will come in the most suggested catalog. The
NG is characterized as:
The
Sum of NG for the
k LOI sequence is calculated as:
where
is a marker approaching 1, assuming the trip at rank
i-th is genuinely traveled through
usr; zero in any case.
The
precision and
recall do not think about the thought of the sequence in the guidance list. In contrast,
NG is a complete position-careful metric that better assigns hundreds on more prominent levels, indicating unique components of the quality of the suggestion significance. More prominent measurement attributes for each of them spread attention to the higher rating quality. We address a metric
UXP for the unexpectedness assessment, as follows.
The
Sum of UXP for the
k LOI sequence is calculated as:
where
is the suddenness for the
i-th trip of a user and is chosen through Equation (
3).
Concerning the ’luck’ measure, a broad measurement is required, considering the objectives of the excellent fortune proposal are both pertinence and surprise, and the combination between them. It is related to the
F-measure from the record recovery issue, which is often used to analyze the compromising exhibitions between two impact measurements. Hence, we depict a metric
RU by embracing the
F-measure to strengthen its significance and startling quality.
The
Sum of RU for the
k LOI sequence is calculated as:
where
precision and
UXP are mentioned for relevance as well as unexpectedness, correspondingly.
To check the dynamic order of the LOI sequence, the
regulated precision is given as:
where
and
represent the ground truth and the suggestion at location
chk. The sum of the
regulated precision for the
k LOI sequence is calculated as:
To check the dynamic order of the LOI sequence for the trip,
pattern precision is given as:
where
estimates the phase of “getting over” in the exhorted LOI progression
T and ground reality
E (and stresses the sequence), while
computes the sequence precision of the safe trip,
A is the degree of all LOI units in the covered progression, and
N means the wide assortment of units in good shape. The complete
pattern precision for the LOI arrangement is processed as:
5.1.3. Baselines
We picked these seven recommendation models to analyze the planned method’s public exhibition.
Location recommendation (LORE) [
31]. This first mines the progressive instances of the positive LOI arrangements and addresses the progressive models as location–location transition graph(s) (LLTG). Regarding the LLTG and the topographical impact, LORE would be in a situation to predict the user’s likelihood of venturing out to every single LOI.
Additive Markov chain (AMC) [
32]. This recommends LOI arrangements via back-to-back effects. Specifically, given a genuine course of the customer, while proposing the LOI at the area, AMC initially offers potential figures of the user’s trip to every LOI in light of the full arrangement of LOIs sooner than placing. This ‘proposes’ the LOI with a serious chance at the locale.
POP. The prevalence-based recommendation technique produces results according to LOIs, where we obtain the volume of check-ins that LOIs require to measure their notoriety.
RAND. The irregular-based approach for arbitrary reasons proposes LOIs among the possibilities to which the objective customer has not voyaged.
LSTM-Seq2Seq [
33]. This involves a long short-term memory (LSTM) to diagram the ‘enter gathering’ to a vector, having a steady estimation, and sometimes utilizing some other significant LSTM to decipher the objective progression from the vector.
KFN [
34]. This is a vanilla serendipitously-situated suggestion strategy. Starting with the central idea of KNN and turning KNN lower, back to the front, this approach makes neighbors of maximally disparate users. Later, it proposes ventures that a user’s neighbors are pleasantly headed to scorn.
SNPR [
21]. A serendipity-oriented next LOI recommendation model suggests—for the ensuing LOI—the utilization of serendipity to acquire the user’s fulfillment.
5.2. Overall Comparison
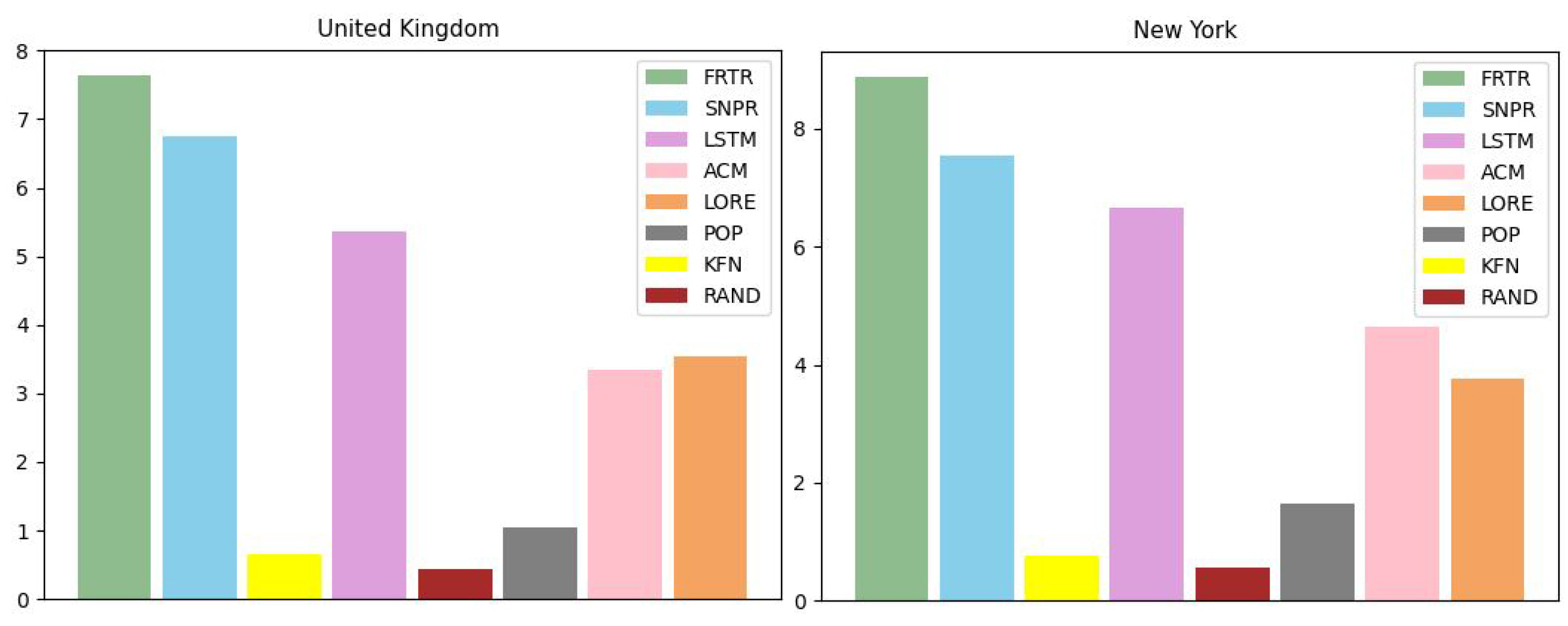
The above settings provide an assortment of examinations; the unique fortunate trip counsel technique, expressed as the sum of
precision, the sum of
recall, the sum of
NG, the sum of
UXP, the sum of
RU, the sum of
RP, and the sum of
PP, are shown in
Table 3 and
Table 4.
Table 3 addresses the outcomes for the United Kingdom, and
Table 4 shows the consequences for New York. It is clear in
Table 3 and
Table 4 that FRTR outflanks the various baselines when estimated with the sum of
precision, the sum of
recall, the sum of
NG, the sum of
UXP, the sum of
RU, the sum of
RP, and the sum of
PP in every urban community. To successfully decide the proposed procedure’s execution, every output is rehashed multiple times and the suggestions and changes of several impacts are utilized to evaluate the general presentation of the model.
The RAND technique offers the trip counsel with random determination without accurate data, so its correctness is weak but, of course, consistent. The ‘POP’ popularity-based trip thought approach produces progression results according to the standard LOI. Regarding the LOIs to which individuals have presently not traveled, we named them non-well known. For these LOIs, we can situate by utilizing the number of scores provided to them in the dataset. Assuming that the number of scores assigned to LOI A is significantly smaller than the wide assortment allocated to LOI B, we can foresee that LOI B is more renowned than LOI A. The KFN initiates with the central idea of KNN and turns KNN again to the front. This procedure makes neighbors of the topmost users and some time afterward proposes trips that an individual’s neighbor most dislikes. The RAND has the simplest sum of UXP. By examination, AMC and LORE achieve comparable execution. If the fluctuation of entering is drawn out and the resulting change is additionally restricted. AMC mostly outperforms LORE. On the other hand, we do not know if the potential gains of the pattern precision are continually higher than those of regulated accuracy. That is, what affirms, as referred to in the past examination; regulated precision is more prominent than pattern precision. SNPR is generally alluring to LSTM-Seq2Seq most of the time. In the following tables, we will see the public exhibitions of these baselines and assess the general presentation with FRTR.
As indicated by the outcomes, FRTR can work significantly higher from each baseline when assessed with the sum of precision, the sum of recall, the sum of NG, the sum of UXP, the sum of RU, the sum of RP, and the sum of PP on the United Kingdom and New York. It proposes that FRTR is conclusive for the good trip suggestion.
5.3. Hyperparameters Effects
In this part, we will check the effects of the hyperparameters. The first hyperparameter involves the wide assortment of LOIs created on the trip with the guide of using ‘good fortune’ highlights, such as unexpectedness and relevance Sru. The second hyperparameter is the wide assortment of LOIs created in the trip using a 1/3 of the quality of luck, a novelty Sn. The third hyperparameter involves the help of novel LOIs in the trip, which Ns portrays. That is the number of scores taken to LOIs in the framework.
The most Ns of a LOI in the United Kingdom is 9493, and the most Ns of a LOI in New York is 496. We know how many special LOIs are famous from the assortment of evaluations. For novel LOIs, we pick the less-rated LOIs because of the reality that most users are not generally identical to new LOIs. Thus, we recommend them as novel LOIs.
This ‘stage’ focuses on investigating the eventual outcomes of everything about hyperparameters regarding the results of the tests. In particular, we exchange the costs of these hyperparameters individually to disclose the effects of the related hyperparameters. The test findings are shown in
Table 5 and
Table 6, respectively.
As per the results presented in
Table 5, when the value of
Sru diminishes,
Sn expands and
Ns increments. The sum of
precision, the sum of
PP, and the sum of
RU relatively obtain more prominent qualities, while the sum of
recall, the sum of
NG, the sum of
RP, and the sum of
UXP nearly have declined values. As indicated by the impacts provided in
Table 6, when the value of
Sru diminishes,
Sn will build and
Ns diminishes. The sum of
precision, the sum of
PP, and the sum of
RU nearly have more noteworthy qualities, while the sum of
recall, the sum of
NG, the sum of
RP, and
UXP similarly obtain declining values. LOIs
Sru and
Sn are the most cherished trademarks in the fortunate trip suggestion. In the interim,
Ns is more extensive at enhancing the tremendous method execution.
Figure 3 shows the total accuracy of the United Kingdom and New York.
Cold-Start Scenario: The “cold-start” capacity is that the occurrence is presently not yet fitting for the trip suggestion application to outfit the conceivable outcomes. Trip recommendation systems relentlessly face the cold-start issue. To determine that issue, we added an oddity to our model.
Fundamentally, good fortune comprises relevance, novelty, and suddenness. We proactively characterized the significance and startling qualities of the above trial results. In novelty, we investigate the users’ data (that have no captured histories) and propose LOIs that will be novel to them. Novelty pertains to whether the trip is unusual to the user. Trips new to an individual are usually less rated. Users are commonly familiar with well-known trips. The wide assortment of scores in the framework can assess spot acknowledgment. Essentially, we can handle the cold-start issue of utilizing novelty to underwrite novel trips to current users. The outcomes of all baselines as substitutes for RAND—experiencing the same thing—are insufficient. Notwithstanding, FRTR is, in any case, strikingly worthier than the various baselines. The after-effects of tending to the cold-start issue are introduced in
Table 7 for the United Kingdom and
Table 8 for New York.
6. Conclusions
We executed an advanced strategy named FRTR for customized trip suggestions, utilizing luck and dynamicity. FRTR finds user fulfillment, given significance, curiosity, and surprise. We planned the proposal calculation to design the travel and amplify the user’s experience proficiently. Trip suggestion issues (in designing customized trips) lie in looking for the important, novel, and unforeseen (with significant fulfillment) LOIs. To manage the difficulties in finding and assessing user fulfillment, we propose a fortunate refining trip recommendation (FRTR). From the end of the work cycle, FRTR can, without a doubt, provide a dynamic arrangement of LOI suggestions by allowing the contributions to adjust over a significant stretch. A convincing proposal calculation should not only provide what we can recommend but also suggest arbitrary yet true aspects to assist, keeping an ‘unlocked window’ to various cities and countries. The registration datasets of two urban towns (i.e., New York and the United Kingdom) from perhaps the greatest assigned LBSN (i.e., Foursquare) were used in our trial. We suggest that our methodology outflanks different benchmarks by fulfilling personal trip interests.
In the future, we will incorporate the gathering of users. We will look at the connections of the gatherings and suggest trips in light of dynamicity and good fortune. The effective arrangement of the LOI model suggests reforming the serendipitous trip (RRST) model and proposes fortunate, interactive travel for gatherings of users.


 ,
, 







{kind=link}
{kind=link}
{kind=link}