
Facial Action Unit Recognition by Prior and Adaptive Attention


Abstract
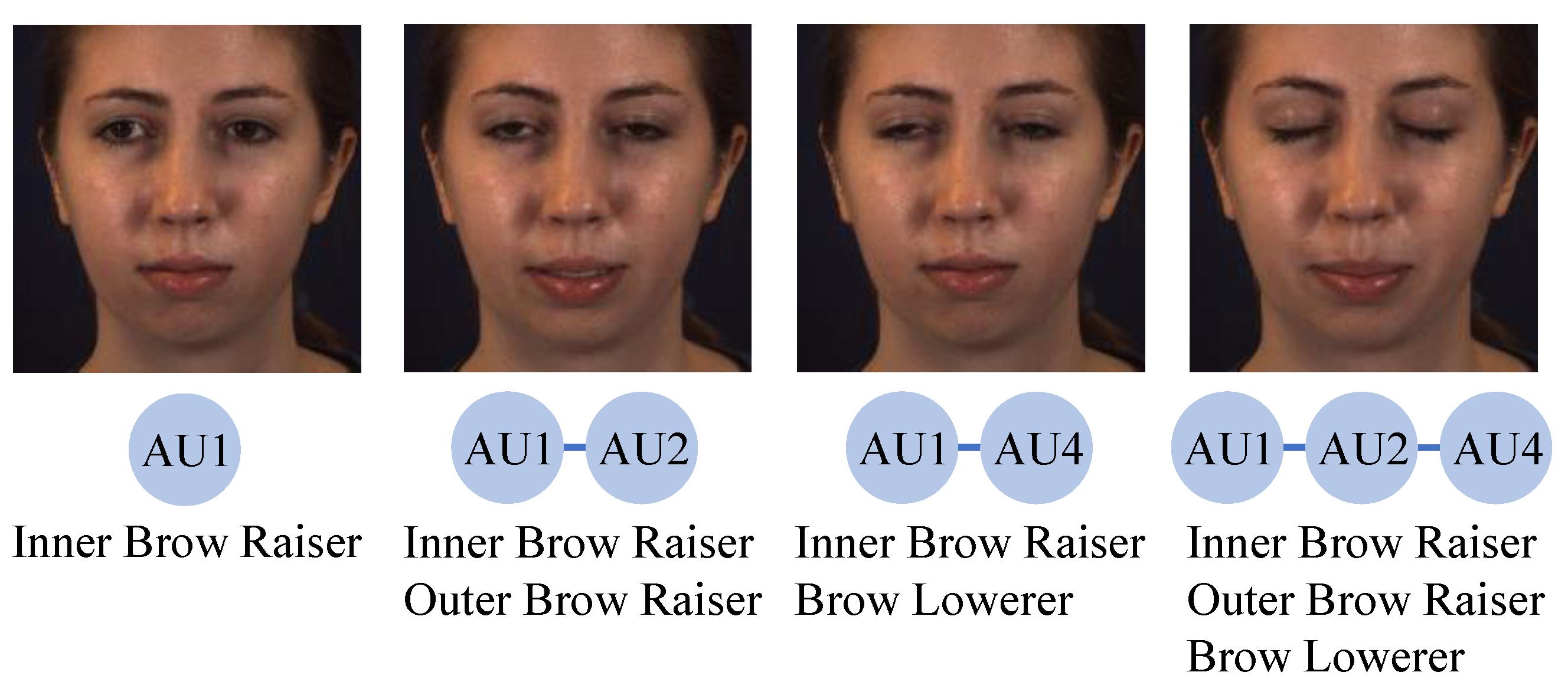
:1. Introduction
- We propose to combine the constraint of prior knowledge and the supervision of AU recognition to adaptively learn the regional attention distribution of each AU.
- We propose a learnable parameter to adaptively control the importance of different positions in the predefined mask, which is beneficial for choosing an appropriate constraint of prior knowledge.
- We conduct extensive experiments on challenging benchmark datasets, which demonstrate that our method outperforms the state-of-the-art AU recognition approaches, and can precisely learn the attention map of each AU.
2. Related Works
2.1. Facial Landmark-Aided AU Recognition
2.2. Attention Learning-Based AU Recognition
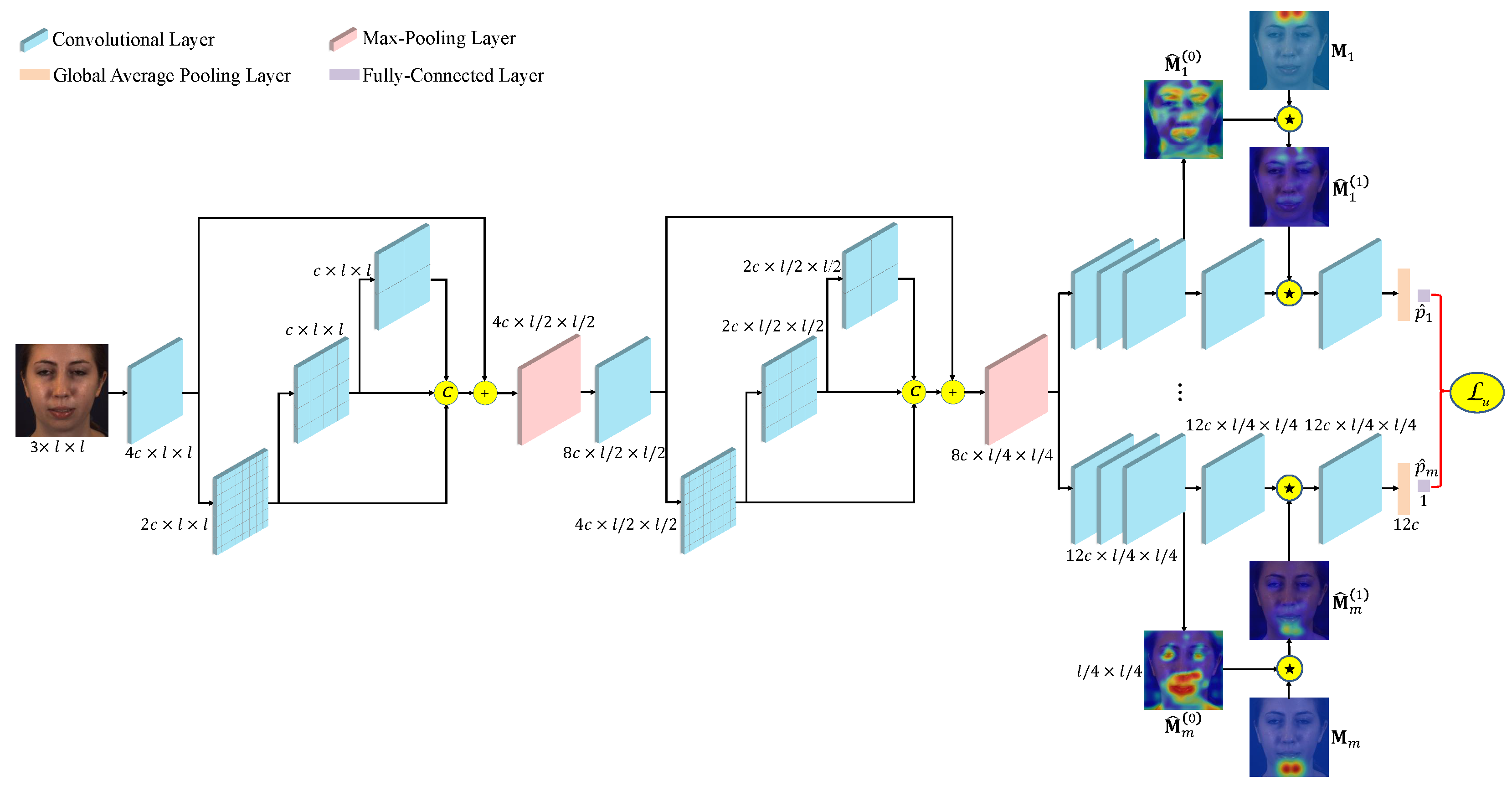
3. PAA for Facial AU Recognition
3.1. Overview
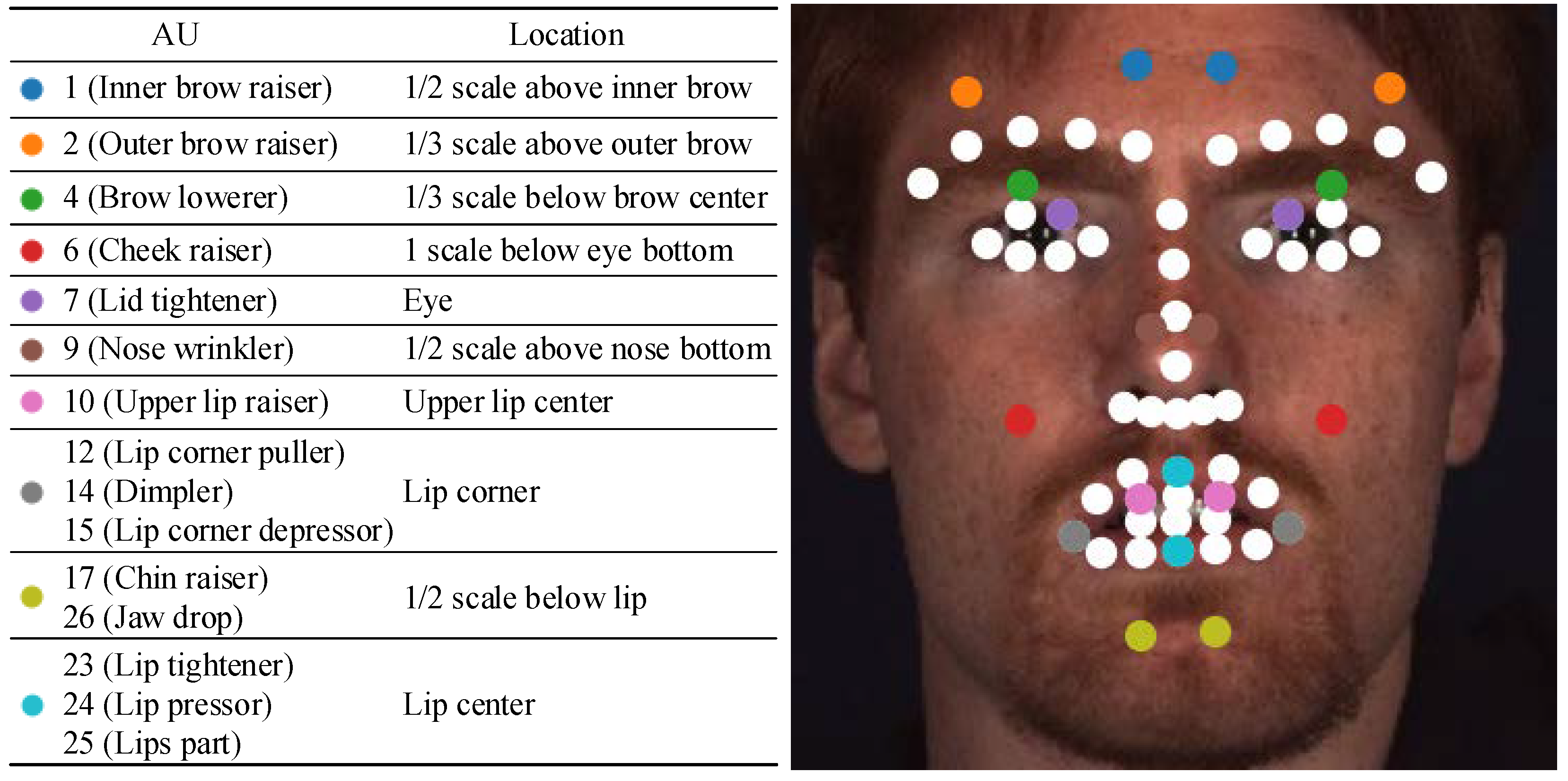
3.2. Constraint of Attention Predefinition
Supervision of AU Recognition
4. Experiments
4.1. Datasets and Settings
4.1.1. Datasets
- Binghamton-Pittsburgh 4D (BP4D) [18] includes 41 subjects, including 23 women and 18 men, in which 328 videos with about frames are captured in total by placing each subject into 8 sessions. Each frame is labeled with the AUs of occurrence or non-occurrence. Similar to the previous approaches [1,2,3], we conduct subject-exclusive three-fold cross-validation with two folds for training and the remaining one for testing on 12 AUs. Our method uses the same partitions of subjects as the previous works [1,2,3].
- Denver Intensity of Spontaneous Facial Action (DISFA) [19] contains 12 women and 15 men, in which each subject is recorded by a video with 4845 frames. Each frame is labeled with AU intensities ranging from 0 to 5. Following the previous methods [1,2,3], we treat an AU as occurrence if its intensity is equal or larger than two, and treat it as non-occurrence otherwise. We conduct subject-exclusive three-fold cross-validation on eight AUs. Our method uses the same partitions of subjects as the previous works [1,2,3].
- Sayette Group Formation Task (GFT) [20] includes 96 subjects with each subject captured by one video, whose images are more challenging than BP4D and DISFA due to unscripted interactions in 32 three-subject teams. Each frame is labeled with AU occurrences. We adopt the official training and testing partitions of subjects [20], in which about frames of 78 subjects are used for training, and about frames of 18 subjects are used for testing.
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Comparison with State-of-the-Art Methods
4.2.1. Evaluation on BP4D
4.2.2. Evaluation on DISFA
4.2.3. Evaluation of GFT
4.3. Ablation Study
4.3.1. Weighting Strategy for Suppressing Data Imbalance
4.3.2. Supervision of AU Recognition for Attention Learning
4.3.3. Attention Predefinition
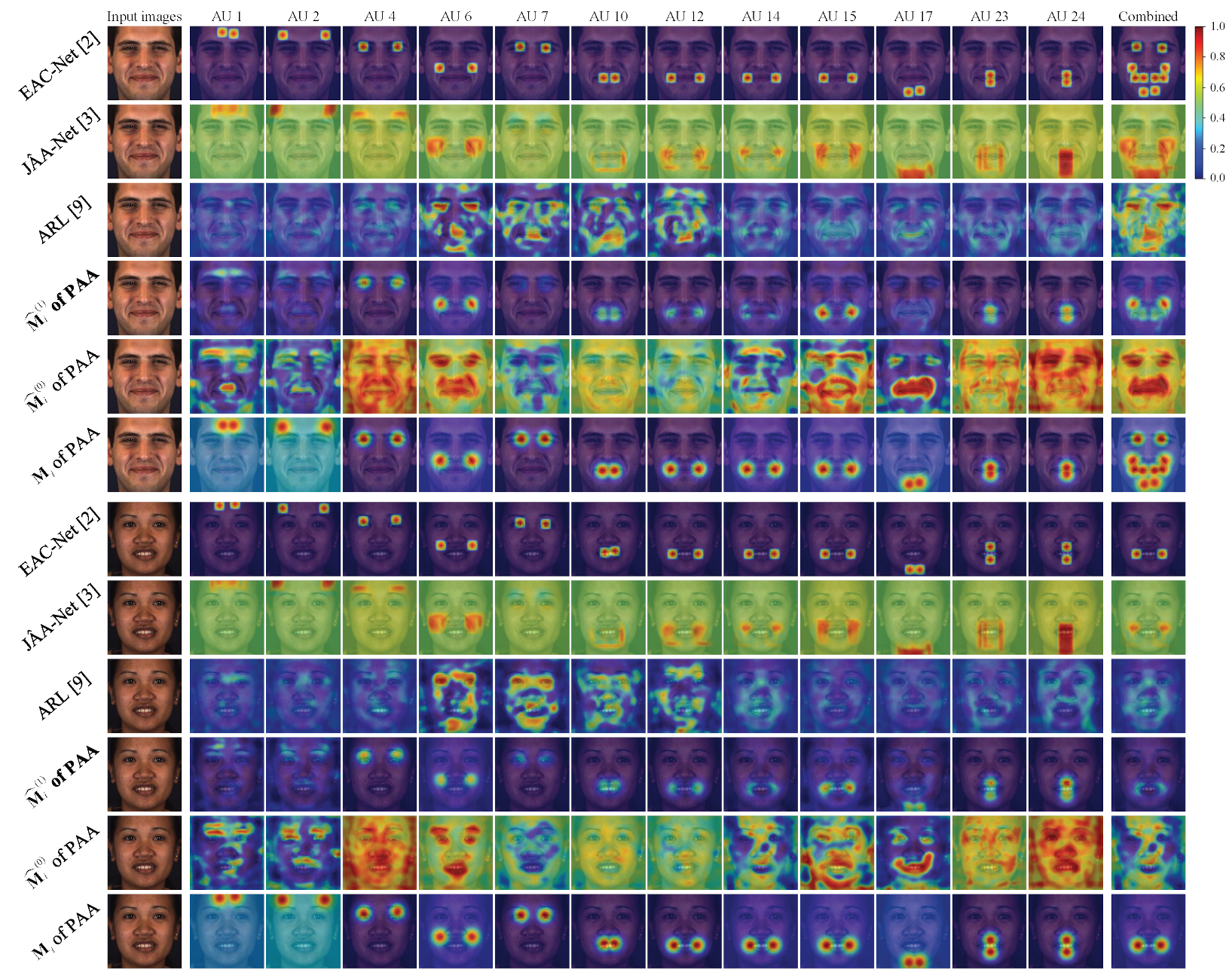
4.4. Visual Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, K.; Chu, W.S.; Zhang, H. Deep region and multi-label learning for facial action unit detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3391–3399. [Google Scholar]
- Li, W.; Abtahi, F.; Zhu, Z.; Yin, L. EAC-Net: Deep Nets with Enhancing and Cropping for Facial Action Unit Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2583–2596. [Google Scholar] [CrossRef] [PubMed]
- Shao, Z.; Liu, Z.; Cai, J.; Ma, L. JÂA-Net: Joint Facial Action Unit Detection and Face Alignment via Adaptive Attention. Int. J. Comput. Vis. 2021, 129, 321–340. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J.; Cham, T.J.; Lu, X.; Ma, L. Unconstrained facial action unit detection via latent feature domain. IEEE Trans. Affect. Comput. 2022, 13, 1111–1126. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Ekman, P.; Friesen, W.V.; Hager, J.C. Facial Action Coding System; Manual and Investigator’s Guide; Research Nexus: Salt Lake City, UT, USA, 2002. [Google Scholar]
- Li, W.; Abtahi, F.; Zhu, Z. Action unit detection with region adaptation, multi-labeling learning and optimal temporal fusing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6766–6775. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Shao, Z.; Liu, Z.; Cai, J.; Wu, Y.; Ma, L. Facial action unit detection using attention and relation learning. IEEE Trans. Affect. Comput. 2022, 13, 1274–1289. [Google Scholar] [CrossRef]
- Shao, Z.; Liu, Z.; Cai, J.; Ma, L. Deep Adaptive Attention for Joint Facial Action Unit Detection and Face Alignment. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 725–740. [Google Scholar]
- Benitez-Quiroz, C.F.; Srinivasan, R.; Martinez, A.M. EmotioNet: An Accurate, Real-Time Algorithm for the Automatic Annotation of a Million Facial Expressions in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5562–5570. [Google Scholar]
- Zhao, K.; Chu, W.S.; De la Torre, F.; Cohn, J.F.; Zhang, H. Joint patch and multi-label learning for facial action unit and holistic expression recognition. IEEE Trans. Image Process. 2016, 25, 3931–3946. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–25 September 1999; pp. 1150–1157. [Google Scholar]
- Niu, X.; Han, H.; Yang, S.; Huang, Y.; Shan, S. Local Relationship Learning With Person-Specific Shape Regularization for Facial Action Unit Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11917–11926. [Google Scholar]
- Ma, C.; Chen, L.; Yong, J. AU R-CNN: Encoding expert prior knowledge into R-CNN for action unit detection. Neurocomputing 2019, 355, 35–47. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Shao, Z.; Zhou, Y.; Tan, X.; Ma, L.; Liu, B.; Yao, R. Survey of Expression Action Unit Recognition Based on Deep Learning. Acta Electron. Sin. 2022, 50, 2003–2017. [Google Scholar]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M. Bp4d-spontaneous: A high-resolution spontaneous 3d dynamic facial expression database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Mavadati, S.M.; Mahoor, M.H.; Bartlett, K.; Trinh, P.; Cohn, J.F. Disfa: A spontaneous facial action intensity database. IEEE Trans. Affect. Comput. 2013, 4, 151–160. [Google Scholar] [CrossRef]
- Girard, J.M.; Chu, W.S.; Jeni, L.A.; Cohn, J.F. Sayette group formation task (gft) spontaneous facial expression database. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 581–588. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Zhong, L.; Liu, Q.; Yang, P.; Huang, J.; Metaxas, D.N. Learning multiscale active facial patches for expression analysis. IEEE Trans. Cybern. 2015, 45, 1499–1510. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Corneanu, C.A.; Madadi, M.; Escalera, S. Deep Structure Inference Network for Facial Action Unit Recognition. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 309–324. [Google Scholar]
- Sankaran, N.; Mohan, D.D.; Setlur, S.; Govindaraju, V.; Fedorishin, D. Representation Learning Through Cross-Modality Supervision. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar]
- Li, G.; Zhu, X.; Zeng, Y.; Wang, Q.; Lin, L. Semantic relationships guided representation learning for facial action unit recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8594–8601. [Google Scholar]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Self-Supervised Representation Learning From Videos for Facial Action Unit Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10924–10933. [Google Scholar]
- Liu, Z.; Dong, J.; Zhang, C.; Wang, L.; Dang, J. Relation modeling with graph convolutional networks for facial action unit detection. In Proceedings of the International Conference on Multimedia Modeling, Daejeon, Korea, 5–8 January 2020; pp. 489–501. [Google Scholar]
- Ertugrul, I.O.; Cohn, J.F.; Jeni, L.A.; Zhang, Z.; Yin, L.; Ji, Q. Crossing Domains for AU Coding: Perspectives, Approaches, and Measures. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 158–171. [Google Scholar] [CrossRef] [PubMed]
- Song, T.; Chen, L.; Zheng, W.; Ji, Q. Uncertain Graph Neural Networks for Facial Action Unit Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 5993–6001. [Google Scholar]
- Song, T.; Cui, Z.; Zheng, W.; Ji, Q. Hybrid Message Passing With Performance-Driven Structures for Facial Action Unit Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 6267–6276. [Google Scholar]
- Chen, Y.; Song, G.; Shao, Z.; Cai, J.; Cham, T.J.; Zheng, J. GeoConv: Geodesic guided convolution for facial action unit recognition. Pattern Recognit. 2022, 122, 108355. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In Proceedings of the IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–13 August 1999; pp. 187–194. [Google Scholar]
- Guo, Y.; Zhang, J.; Cai, J.; Jiang, B.; Zheng, J. Cnn-based real-time dense face reconstruction with inverse-rendered photo-realistic face images. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1294–1307. [Google Scholar] [CrossRef] [PubMed] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AU | 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSVM [23] | 23.2 | 22.8 | 23.1 | 27.2 | 47.1 | 77.2 | 63.7 | 64.3 | 18.4 | 33.0 | 19.4 | 20.7 | 35.3 |
| JPML [12] | 32.6 | 25.6 | 37.4 | 42.3 | 50.5 | 72.2 | 74.1 | 65.7 | 38.1 | 40.0 | 30.4 | 42.3 | 45.9 |
| DRML [1] | 36.4 | 41.8 | 43.0 | 55.0 | 67.0 | 66.3 | 65.8 | 54.1 | 33.2 | 48.0 | 31.7 | 30.0 | 48.3 |
| EAC-Net [2] | 39.0 | 35.2 | 48.6 | 76.1 | 72.9 | 81.9 | 86.2 | 58.8 | 37.5 | 59.1 | 35.9 | 35.8 | 55.9 |
| DSIN [26] | 51.7 | 40.4 | 56.0 | 76.1 | 73.5 | 79.9 | 85.4 | 62.7 | 37.3 | 62.9 | 38.8 | 41.6 | 58.9 |
| CMS [27] | 49.1 | 44.1 | 50.3 | 79.2 | 74.7 | 80.9 | 88.3 | 63.9 | 44.4 | 60.3 | 41.4 | 51.2 | 60.6 |
| LP-Net [14] | 43.4 | 38.0 | 54.2 | 77.1 | 76.7 | 83.8 | 87.2 | 63.3 | 45.3 | 60.5 | 48.1 | 54.2 | 61.0 |
| ARL [9] | 45.8 | 39.8 | 55.1 | 75.7 | 77.2 | 82.3 | 86.6 | 58.8 | 47.6 | 62.1 | 47.4 | 55.4 | 61.1 |
| SRERL [28] | 46.9 | 45.3 | 55.6 | 77.1 | 78.4 | 83.5 | 87.6 | 60.6 | 52.2 | 63.9 | 47.1 | 53.3 | 62.9 |
| AU R-CNN [15] | 50.2 | 43.7 | 57.0 | 78.5 | 78.5 | 82.6 | 87.0 | 67.7 | 49.1 | 62.4 | 50.4 | 49.3 | 63.0 |
| AU-GCN [30] | 46.8 | 38.5 | 60.1 | 80.1 | 79.5 | 84.8 | 88.0 | 67.3 | 52.0 | 63.2 | 40.9 | 52.8 | 62.8 |
| JÂA-Net [3] | 53.8 | 47.8 | 58.2 | 78.5 | 75.8 | 82.7 | 88.2 | 63.7 | 43.3 | 61.8 | 45.6 | 49.9 | 62.4 |
| UGN-B [32] | 54.2 | 46.4 | 56.8 | 76.2 | 76.7 | 82.4 | 86.1 | 64.7 | 51.2 | 63.1 | 48.5 | 53.6 | 63.3 |
| HMP-PS [33] | 53.1 | 46.1 | 56.0 | 76.5 | 76.9 | 82.1 | 86.4 | 64.8 | 51.5 | 63.0 | 49.9 | 54.5 | 63.4 |
| GeoCNN [34] | 48.4 | 44.2 | 59.9 | 78.4 | 75.6 | 83.6 | 86.7 | 65.0 | 53.0 | 64.7 | 49.5 | 54.1 | 63.6 |
| PAA | 50.1 | 47.7 | 55.0 | 74.0 | 78.9 | 82.2 | 87.2 | 63.8 | 51.4 | 62.4 | 52.1 | 55.8 | 63.4 |
| AU | 1 | 2 | 4 | 6 | 9 | 12 | 25 | 26 | Avg |
|---|---|---|---|---|---|---|---|---|---|
| LSVM [23] | 10.8 | 10.0 | 21.8 | 15.7 | 11.5 | 70.4 | 12.0 | 22.1 | 21.8 |
| APL [24] | 11.4 | 12.0 | 30.1 | 12.4 | 10.1 | 65.9 | 21.4 | 26.9 | 23.8 |
| DRML [1] | 17.3 | 17.7 | 37.4 | 29.0 | 10.7 | 37.7 | 38.5 | 20.1 | 26.7 |
| EAC-Net [2] | 41.5 | 26.4 | 66.4 | 50.7 | 8.5 | 89.3 | 88.9 | 15.6 | 48.5 |
| DSIN [26] | 42.4 | 39.0 | 68.4 | 28.6 | 46.8 | 70.8 | 90.4 | 42.2 | 53.6 |
| CMS [27] | 40.2 | 44.3 | 53.2 | 57.1 | 50.3 | 73.5 | 81.1 | 59.7 | 57.4 |
| LP-Net [14] | 29.9 | 24.7 | 72.7 | 46.8 | 49.6 | 72.9 | 93.8 | 65.0 | 56.9 |
| ARL [9] | 43.9 | 42.1 | 63.6 | 41.8 | 40.0 | 76.2 | 95.2 | 66.8 | 58.7 |
| SRERL [28] | 45.7 | 47.8 | 59.6 | 47.1 | 45.6 | 73.5 | 84.3 | 43.6 | 55.9 |
| AU R-CNN [15] | 32.1 | 25.9 | 59.8 | 55.3 | 39.8 | 67.7 | 77.4 | 52.6 | 51.3 |
| AU-GCN [30] | 32.3 | 19.5 | 55.7 | 57.9 | 61.4 | 62.7 | 90.9 | 60.0 | 55.0 |
| JÂA-Net [3] | 62.4 | 60.7 | 67.1 | 41.1 | 45.1 | 73.5 | 90.9 | 67.4 | 63.5 |
| UGN-B [32] | 43.3 | 48.1 | 63.4 | 49.5 | 48.2 | 72.9 | 90.8 | 59.0 | 60.0 |
| HMP-PS [33] | 38.0 | 45.9 | 65.2 | 50.9 | 50.8 | 76.0 | 93.3 | 67.6 | 61.0 |
| GeoCNN [34] | 65.5 | 65.8 | 67.2 | 48.6 | 51.4 | 72.6 | 80.9 | 44.9 | 62.1 |
| PAA | 56.1 | 57.0 | 59.0 | 39.7 | 49.4 | 74.6 | 95.6 | 71.9 | 62.9 |
| AU | 1 | 2 | 4 | 6 | 10 | 12 | 14 | 15 | 23 | 24 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| LSVM [23] | 38 | 32 | 13 | 67 | 64 | 78 | 15 | 29 | 49 | 44 | 42.9 |
| AlexNet [25] | 44 | 46 | 2 | 73 | 72 | 82 | 5 | 19 | 43 | 42 | 42.8 |
| EAC-Net [2] | 15.5 | 56.6 | 0.1 | 81.0 | 76.1 | 84.0 | 0.1 | 38.5 | 57.8 | 51.2 | 46.1 |
| TCAE [29] | 43.9 | 49.5 | 6.3 | 71.0 | 76.2 | 79.5 | 10.7 | 28.5 | 34.5 | 41.7 | 44.2 |
| ARL [9] | 51.9 | 45.9 | 13.7 | 79.2 | 75.5 | 82.8 | 0.1 | 44.9 | 59.2 | 47.5 | 50.1 |
| Ertugrul et al. [31] | 43.7 | 44.9 | 19.8 | 74.6 | 76.5 | 79.8 | 50.0 | 33.9 | 16.8 | 12.9 | 45.3 |
| JÂA-Net [3] | 46.5 | 49.3 | 19.2 | 79.0 | 75.0 | 84.8 | 44.1 | 33.5 | 54.9 | 50.7 | 53.7 |
| PAA | 64.6 | 45.4 | 9.8 | 77.9 | 74.8 | 82.8 | 45.4 | 53.3 | 58.9 | 45.0 | 55.8 |
| Method | HM | C | |||||
|---|---|---|---|---|---|---|---|
| Baseline | √ | √ | √ | ||||
| Baseline+ | √ | √ | √ | √ | |||
| AA | √ | √ | √ | √ | √ | ||
| PA | √ | √ | √ | √ | √ | ||
| PAA | √ | √ | √ | √ | √ | √ | |
| PAA | √ | √ | √ | √ | √ | √ |
| AU | 1 | 2 | 4 | 6 | 7 | 10 | 12 | 14 | 15 | 17 | 23 | 24 | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | 47.8 | 42.1 | 51.4 | 72.6 | 73.4 | 79.5 | 85.6 | 58.3 | 45.3 | 59.9 | 40.8 | 48.8 | 58.8 |
| Baseline+ | 49.0 | 44.2 | 52.9 | 73.9 | 74.9 | 79.3 | 84.5 | 59.1 | 48.0 | 61.1 | 41.8 | 50.4 | 59.9 |
| AA | 50.5 | 41.8 | 55.0 | 75.1 | 75.6 | 80.4 | 86.0 | 60.6 | 50.0 | 61.1 | 50.5 | 51.3 | 61.5 |
| PA | 48.8 | 50.1 | 48.9 | 75.3 | 77.6 | 81.6 | 85.7 | 62.5 | 52.5 | 61.9 | 44.8 | 53.3 | 61.9 |
| PAA | 46.7 | 45.6 | 53.9 | 75.5 | 78.9 | 82.0 | 86.9 | 60.2 | 52.0 | 61.6 | 48.2 | 52.5 | 62.0 |
| PAA | 50.1 | 47.7 | 55.0 | 74.0 | 78.9 | 82.2 | 87.2 | 63.8 | 51.4 | 62.4 | 52.1 | 55.8 | 63.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Z.; Zhou, Y.; Zhu, H.; Du, W.-L.; Yao, R.; Chen, H. Facial Action Unit Recognition by Prior and Adaptive Attention. Electronics 2022, 11, 3047. https://doi.org/10.3390/electronics11193047
Shao Z, Zhou Y, Zhu H, Du W-L, Yao R, Chen H. Facial Action Unit Recognition by Prior and Adaptive Attention. Electronics. 2022; 11(19):3047. https://doi.org/10.3390/electronics11193047
Chicago/Turabian StyleShao, Zhiwen, Yong Zhou, Hancheng Zhu, Wen-Liang Du, Rui Yao, and Hao Chen. 2022. "Facial Action Unit Recognition by Prior and Adaptive Attention" Electronics 11, no. 19: 3047. https://doi.org/10.3390/electronics11193047
APA StyleShao, Z., Zhou, Y., Zhu, H., Du, W. -L., Yao, R., & Chen, H. (2022). Facial Action Unit Recognition by Prior and Adaptive Attention. Electronics, 11(19), 3047. https://doi.org/10.3390/electronics11193047