1. Introduction
Named entity recognition (NER) aims to seek and identify named entities in unstructured text into predefined entity types, such as person names, organizations, locations, etc. The extracted named entities can benefit various subsequent NLP tasks, including syntactic parsing [
1], question answering [
2] and relation extraction [
3].
NER is usually regarded as a sequence labeling problem [
4]. Neural-based conditional random fields (CRF) models, such as BiLSTM-CRF [
5], have achieved state-of-the-art performance [
6,
7]. In particular, based on the word embeddings, we can exploit a long short-term memory network (LSTM) to capture implicit token-level global information, which has been demonstrated to be effective for NER in previous studies [
6,
8].
However, the token-level features cannot capture the global-type-related semantic information in the sentence, and this problem may limit the capacity for semantic information of the feature representation.
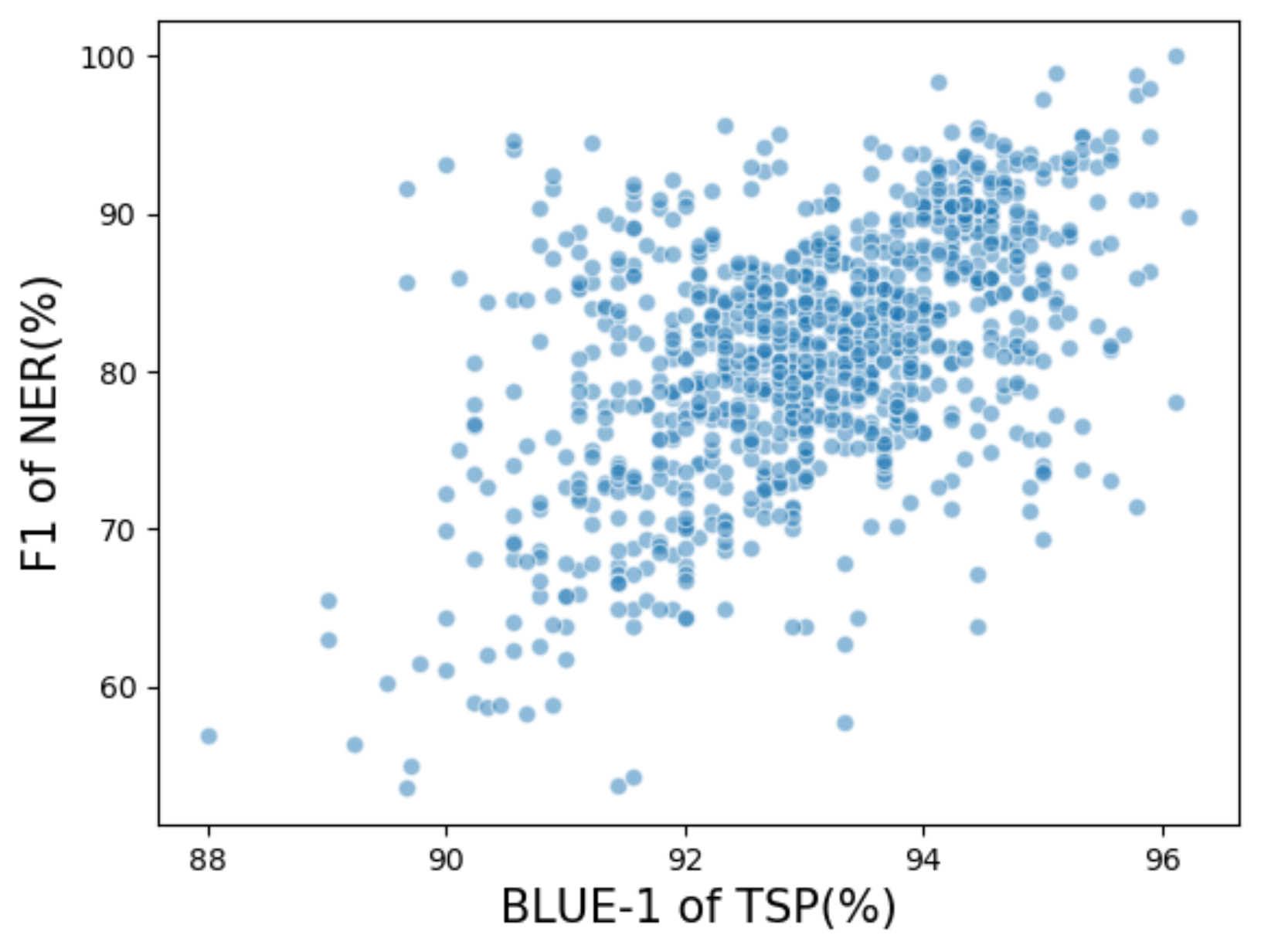
Intuitively, the entity types contain rich semantic information and the entity type sequence in a sentence can reflect the sentence-level semantics globally. For instance, as shown in
Figure 1, the type sequence
can express the semantic information of the sentence. Determining whether a sentence contains a type sequence should enable us to learn rich type-related information for the representation of the token.
Inspired by the end-to-end neural translation method [
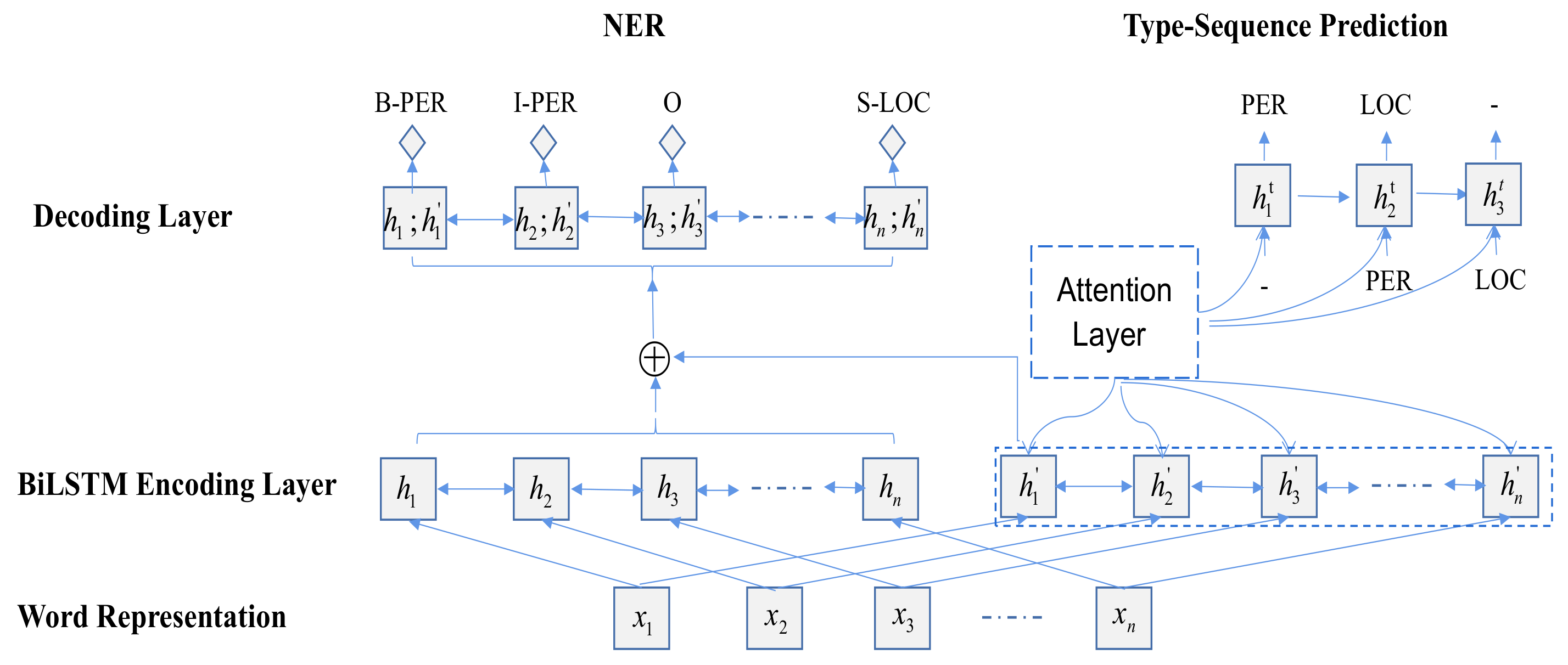
9], we propose a new end-to-end entity type sequence prediction task (TSP) at the sentence level. The input of the task is the sentence and the output is the entity type sequence in the sentence. To incorporate the information learned from the TSP into the NER model, we employ a multitask learning strategy. The architecture of the joint model is shown in
Figure 2. For NER, we use the standard BiLSTM-CRF model as a baseline [
5], where the input could be either a word embedding or Bidirectional Encoder Representations from Transformers (BERT). For the TSP, an auxiliary task, we exploit the end-to-end translation model to generate possible type sequences. The two tasks share the same word representation. We combine the encoder representation of BiLSTM between NER and TSP as the final encoding representation for the NER model. In essence, the TSP enhances the semantic feature representation of the token and provides type constraint information for NER. Noticeably, the auxiliary TSP task does not require any extra training data, thus there is no additional annotation cost to achieve our final goal.
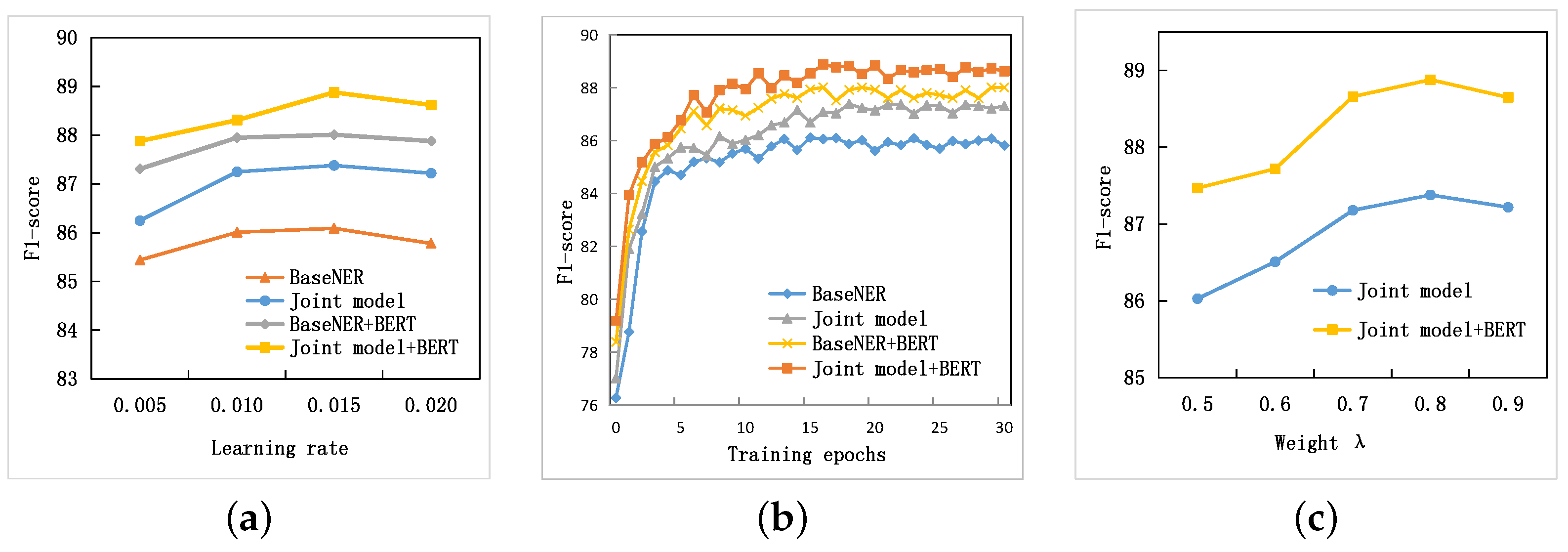
We conduct experiments on the four benchmark datasets in different languages (English, Chinese and Spanish) and different domains (general and biomedical) to show the effectiveness of our approach. Experimental results demonstrate our model is highly effective, resulting in improvements and leading to state-of-the-art performance on the CoNLL-2003 German NER and JNLPBA datasets without any extra cost. Furthermore, our model can almost achieve the same energy efficiency and latency as the baseline on embedded platforms. Our main contributions can be summarized as follows:
(1) We propose a multitask learning (MTL) approach for NER to exploit the global-type-related semantic information.
(2) We introduce a new auxiliary task, namely the sentence-level entity type sequence prediction (TSP), which enhances the semantic feature representation of tokens and provides type constraint information for NER.
(3) Experimental results demonstrate our MTL model is highly effective, resulting in consistent improvements and leading to state-of-the-art results on the CoNLL-2003 German NER and JNLPBA datasets without any external resource.
3. Methodology
In this section, we describe the proposed joint model in detail. Our model focuses on two tasks, NER and TSP, where the TSP is the secondary task, and it is exploited as an auxiliary for NER. First, we introduce the word representation used in our model, then we describe the NER and TSP. Finally, we introduce the multitask learning, which combines the NER and TSP by concatenating the hidden layer. Our final goal is to enhance the performance of NER via the TSP.
Figure 2 shows the overall architecture, where the left part is for NER and the right part is for the TSP.
3.1. Word Representation
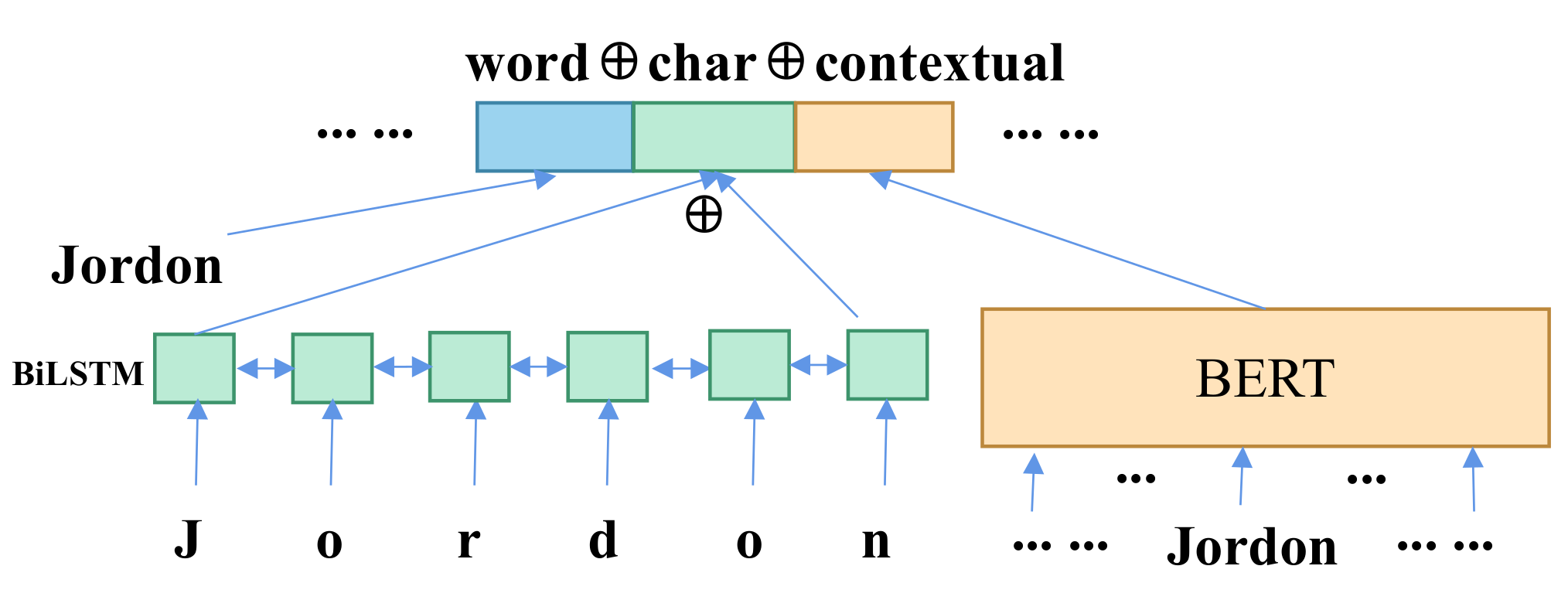
For a given word sequence , where is the ith word, the first step was to obtain the word representations of each token. Here, we exploited two kinds of word representations: embeddings and BERT.
Following [
7], the embedding representation of one word was created by concatenating its word embedding and its character embeddings, as follows:
where
denotes a word embedding lookup table and
denotes the character-level embeddings. We used BiLSTM to encode character-level embeddings. Assuming
where
denotes the
jth character in the
ith word (
), each
is represented using
, where
denotes a character embedding lookup table. The word-level output
denotes the output of the character-level encoding.
BERT has shown great potentials in NLP [
14], which is one kind of contextualized word representations. Thus, we also exploited BERT to enhance word representations. We took the outputs of the last layer of a pretrained BERT model as word representations:
Finally, we concatenated the BERT representations and the embedding representations above together to obtain boosted word representations,
, as shown in
Figure 3.
3.2. NER
We employed the BiLSTM-CRF baseline [
5] as an NER model in this work. We exploited a bidirectional LSTM network to capture high-level feature representations for NER, which was widely used in previous work [
5]. Concretely, the word embedding sequence
of each input was taken as the input to a BiLSTM network in each step, then the output sequence of hidden states of the forward LSTM network and the corresponding output sequence of the backward LSTM network were combined according to the position to obtain the complete sequence of hidden states
:
Finally, a standard CRF layer was used to score the candidate output sequences, which could capture the dependencies between successive labels. Formally, we took the above sequence of hidden states
as our input to the CRF layer, and its output was our final prediction tag sequence
, which could be computed as follows:
where
is any one of the candidate outputs,
(emission matrix) and
(transition matrix) are two model parameters of CRF and
indicates indexing.
The first-order Viterbi algorithm was used to find the highest scored label sequence during decoding. To train the model, the cross-entropy objective function was exploited. Assuming that the GOLD standard tag sequence for sentence
was
, the loss function for this single training instance was defined as:
where all model parameters were optimized to minimize the loss in an online manner.
3.3. TSP
We followed the neural machine translation architecture proposed by [
9], which was constructed as a composite of an encoder network, an attention module and a decoder network. The word representation
was shared with the NER model as the input, and the output was a possible type sequence
.
The encoder was also a bidirectional LSTM network that read the same input sequence
as the NER model and calculated a forward sequence of hidden states and a backward sequence. Then, we concatenated the forward and backward hidden states to form a context set :
Then, the decoder computed the conditional distribution over all possible type sequences based on this context set. This was done by first rewriting the conditional probability of a predicted type sequence:
For each conditional term in the summation, the decoder BiLSTM network updated its hidden state by
where is the activation function and
is the continuous embedding of a target entity type.
is a context vector computed by an attention mechanism:
The attention mechanism
weighted each vector in the context set
C according to its relevance to the entity type generated by the decoder. Note that the attention submodule was self-supervised, and the query of attention was the previous generated type. The weight of each vector
was computed by
where
is a parametric function returning an unnormalized score for
given
,
. We used a feedforward network with a single hidden layer in this paper.
Z was a normalization constant:
This procedure can be understood as computing the potential relationship between the
target type and
source word.
The hidden state
, together with the previous target type
and the context vector
, was fed into a feedforward neural network to generate the conditional distribution:
For training, the model parameters were learned by minimizing the negative log-likelihood, where the loss function for a single input sentence was defined as follows:
3.4. Multitask Learning
In order to integrate the TSP task into our baseline model and create full interactions between the NER and auxiliary TSP task at the same time, we used the multitask learning method to integrate the type information into the NER model. We concatenated the hidden embedding of the two tasks in the BiLSTM encoder layers and obtained basic feature inputs for the decoding layer of the NER model.
For NER in the MTL model, we added a sequence of new features from the TSP task to enhance NER. Concretely, we combined the newly obtained hidden word representations from the TSP encoder with the original BiLSTM outputs to get the final feature representations for NER:
where simple concatenations were adopted for the combination, and
was used in our final joint model for NER.
The multitask learning model had two kinds of losses and we combine them by a dynamic weight
as follows:
where the
is a hyperparameter assigned to control the degree of importance for each task.
In our tests, we only predicted named entities and did not execute the TSP task. Therefore, there was only a very slight efficiency decrease during decoding compared with the BiLSTM-CRF baseline.
5. Conclusions
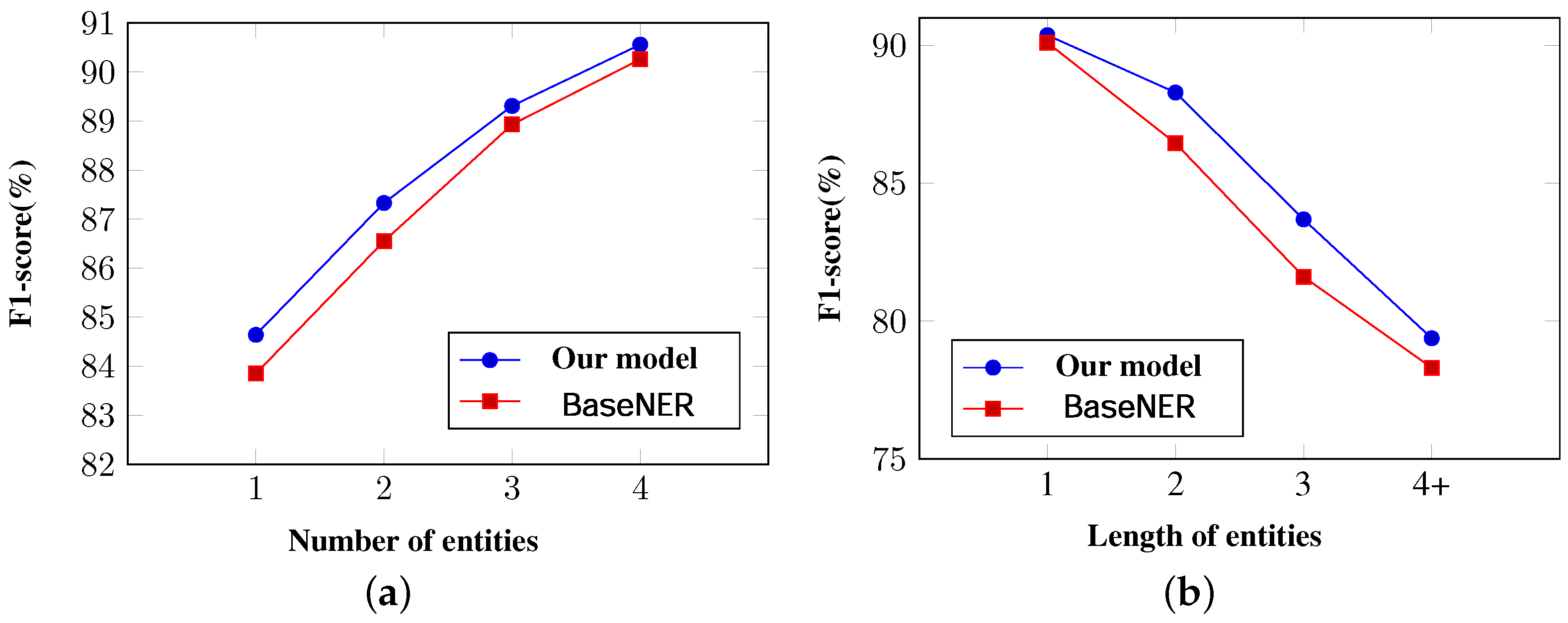
In this paper, we proposed a multitask learning framework that incorporated the entity type-related information for NER. To achieve this goal, we investigated the auxiliary TSP task. The TSP task had a positive correlation and could capture potential type-related information at the sentence level. Noticeably, the TSP task shared the same input with the NER, and the type labels for TSP could be directly obtained from the NER training corpus. Thus, the TSP task did not require any extra training data, and there was no additional annotation cost in our framework. Experimental results demonstrated our MTL model was highly effective, resulting in consistent improvements and leading to state-of-the-art results on the CoNLL-2003 German NER and JNLPBA datasets without any external resource.
This article demonstrated the effectiveness of TSP on named entity recognition and our joint model did not depend on any additional annotation data. Therefore, we will explore the TSP task on other more challenging NLP tasks, such as relation extraction and reading comprehension, in the future.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}