1. Introduction
With the advancement of the Internet and information systems, various data have been generated and shared on the web, and information search has become increasingly important [
1,
2]. When entering search terms into a web search engine, users hope that the results that they want are shown at the top of the list, allowing them to quickly find the desired web pages [
3,
4,
5]. However, the traditional web search engine determines the importance of each web document that contains the search term through ranking algorithms to provide search results to users [
6,
7,
8]. Therefore, most web search results do not provide customized search results because they determine common results to all users [
9,
10,
11,
12]. This problem arises because the method considers only the query form for the content-based document search without accurately understanding the search intentions of web users. That is, the traditional web searches do not provide search results suitable for the user’s major preferences because they do not sufficiently reflect the user’s query intention [
13,
14,
15,
16].
When the term ‘Liverpool’ is entered for a web search, results for ‘Liverpool Football Club’ and ‘Liverpool City’ are provided. In general, ‘Liverpool Football Club’ is at the top of the list, and a large number of related webpages are displayed. Such results are provided because the search engine seeks to show the results that users look for by considering the ambiguity and lexical ambiguity of the word. Because users often click on web pages associated with ‘Liverpool Football Club’, there are many web pages shown for it. Thus, the need for personalized search that provides results according to the individual users’ preferences is increasing [
17,
18,
19,
20]. The personalized search can present the documents that the user wants at the top of the search results according to the user’s preference [
21,
22,
23]. The traditional web search methods do not show the results that the user wants at the top, and additional user effort is needed for obtaining the desired information or avoiding unwanted information in many web search results. To solve this problem, a search method that provides documents containing the information that the user wants and places them at the top of the results is required. To provide a personalized search method that satisfies users, it is necessary to identify the exact meaning of the query that the user enters and determine what information the user needs according to his/her preference [
24,
25]. Therefore, for a personalized search, it is necessary to determine the meaning of the query using the user’s preference.
To provide personalized search results, it is important to identify the preferences of the users. With the recent advancement of Internet technology and mobile devices, communication among users has become more active, and social media services have evolved as forums of communication. Internet technology allows users to access social media services quickly through mobile devices or the web and creates and accesses information quickly and conveniently [
26,
27]. The advancement of mobile devices has allowed users to access services anytime and anywhere. Social media services have been actively developed as a means of producing, consuming, and sharing information, and the number of users employing these services has increased rapidly [
28,
29,
30,
31,
32,
33,
34]. Social media services involve two-way communication, in which a user becomes an information provider and a consumer simultaneously, whereas traditional media, such as newspapers, magazines, television, and radio, are one-way media, in which information producers deliver information to information consumers [
35,
36,
37,
38]. Social media are characterized by the rapid spread of information because users can produce, process, and share information themselves, and the processes are simple and convenient. Because of these characteristics, social media services have many users [
39,
40,
41]. The amount of social data is rapidly increasing because of the increase in social media activity, and these data can be used to obtain user preferences that are useful for personalized search [
42,
43,
44]. A user’s social media activities can be analyzed to determine his/her fields of interest, and this information can be used to place the search results that reflect the user’s preference at the top [
45,
46,
47,
48,
49,
50].
Studies have been performed on personalized search methods considering the preferences of social media users [
51,
52,
53,
54]. In [
55], a method was proposed in which a query is accepted after identifying the user’s preferences and a personalized search is executed using the social media analysis strategy. In [
56], a method of classifying users’ preferences by time was proposed, along with a personalized search method considering the network characteristics of social media. In previous studies, user preferences and social media network characteristics were employed to provide information that can satisfy users. However, except for [
56], in which user preferences were classified by time, the user preferences were not updated. Furthermore, the method of [
56] does not use time-based weights. Thus, different weights are not assigned for recent preferences and past preferences. Therefore, it is difficult to calculate the recent preferences of social media users accurately in the existing personalized search methods.
In this paper, we propose a personalized search method considering the user’s recent preferences and similar users’ preferences in social media environments. The recent preferences of users are considered to expose the information that the user wants at the top of the search results. The user’s activities on social media are analyzed to determine his/her recent preferences, to which time-based weights are assigned for emphasizing the recent preferences. Furthermore, the preferences of similar users on social media are taken into account to consider new information, unknown information, and the case where the user information is unclear. Search results are provided considering the recent preferences of the user and the preferences of other users with high degrees of similarity, including users who are professionally active in the field where the user has recently shown interest and users who are linked as friends on social media. We propose a ranking method in which the user’s recent preferences obtained from social media activities and the preferences of similar users are employed to provide results. Our objective is to develop a personalized search method that improves the satisfaction and accuracy of the search results by updating user preferences via the determination of the user’s recent preferences and considering the preferences of similar users.
The remainder of this paper is organized as follows.
Section 2 introduces related works and presents the research problems.
Section 3 describes the characteristics of the proposed personalized search method.
Section 4 presents the experimental validation of the proposed method. Finally,
Section 5 presents the conclusions.
2. Related Works
Studies have been actively conducted to increase the efficiency of web search, including personalized search. In particular, studies have been conducted on methods that use search record analysis to identify the user’s preferences and then reflect it in search results to provide the user with desired information efficiently. Moreover, studies have been actively performed on search methods that use preferences of related users, such as similar users, users who engage in professional activities in a particular field, and users linked as friends. In [
57], a method for finding experts on queries was proposed to obtain better answers compared with the traditional method of obtaining information. When a user sends a query, the proposed social query/answer system analyzes the user’s social media and determines the user’s ranking to deliver questions. However, it is difficult to identify the user’s recent preferences, because the results for the current user’s query are provided by aggregating all the activities of the user. In [
58], a search algorithm was proposed that reflects the answerer’s recent preferences to search for potential answerers who can best answer the question. It uses the bookmarking information provided by del.icio.us to obtain the user’s recent preferences and considers the similarity between the user’s query and preference to provide search results. However, when the degree of similarity between the user’s query and the social annotation is low, appropriate search results cannot be provided. Furthermore, the proposed method cannot be applied to regular webpages, because the categories of the documents are unknown.
Recently, studies have been conducted on search methods employing social media, in which users exchange opinions or views with others. In [
55], SonetRank was proposed, which provides web search results based on the preferences and feedback of users in a similar group. SonetRank accepts the user preference information in the form of a profile in advance as an input and then forms a group of similar users based on this information. The Social-Aware Search (SAS) was proposed, which analyzes the keywords searched and webpages viewed by the users belonging to the formed group to reflect the information related to the trends and fields of interest of the users in the group in the search results. It analyzes the preference for the documents that the user is typically interested in and places the user in a group of users with similar preferences. Then, when the user performs a search, the document viewing trend of the users in the group is given as a weight. In [
59], a method was proposed in which fields of interest are identified according to the preferences of social media users and the user preferences are matched to the web search results to provide search results. After the user’s preferences are identified in social media, the query is accepted, and a personalized search is executed according to the social media analysis strategy. However, most users’ preferences change over time, and accordingly, their search preferences also change. Furthermore, traditional search methods provide limited results because they do not consider the preferences of similar users. In [
60], a recommender system framework comprising a robust set of techniques was designed to provide mobile application developers with a specific platform. This framework consists of domain knowledge inference, profiling and preferencing, query expansion, and recommendation and information filtration to recommend and retrieve code snippets, Q&A threads, tutorials, libraries, and other external data sources and artifacts to assist developers with their mobile application development. The domain knowledge inference provides various semantic web technologies and lightweight ontologies. The profiling and preferencing generated a new proposed time-aware multidimensional user modelling. The query expansion enhances the retrieved results by semantically augmenting users’ query.
Most users’ preferences change over time, and accordingly, so do their search preferences. Recently, studies have been conducted on search methods that use social media to identify and reflect the preferences of users that change over time. In [
56], the use of profiles to classify the recent preferences of users by time was proposed, along with a personalized search method that considers the network characteristics of social media. When a user submits a query, results reflecting the user’s preferences are provided. The user’s preferences are built through click logs of the search results. Although a profile is employed in which the field of interest changes over time, the method has the following problems: there are no time-based weights for past and recent time periods, there are no exact time periods, and the user’s preferences generated in real time on social media are not reflected. In [
61], a search method was proposed that enhances reliability through an implicit information collection method using Skyline and receives feedback on the preference information about places to reflect it in searches. This method provides search results suitable for a moving user by including the time information in the query. It collects and analyzes social media postings, including a variety of location information, and the user requests search results via a search query to the server in a mobile environment. The server that receives the request analyzes the query, generates a candidate group, and assigns scores, and according to these scores, it provides search results to the user. Furthermore, it extracts the essential keywords, the time, and the user’s current location from the user’s query. It generates appropriate candidates, calculates popularity scores, and assigns weights based on the user’s preference information. A Treatment Effect Pattern (TEP) was proposed to determine whether to take a treatment for personalized decision making [
62]. TEP uses the local causal structure for unbiased Conditional Average Causal Effect (CATE) estimation in our problem setting. TEP uses a bottom-up search approach to represent treatment effect heterogeneity in data. Because the subgroup of the TEP is small, the subgroups are merged with other subgroups to make the TEP of the merged subgroup significant. A generalized TEP created by the merge process represents the two or more most specific TEPs. The discovery process minimizes heterogeneity within each subgroup represented by a pattern. The most specific pattern matching a person’s situation is used for personalized decision making.
A study on event and topic detection has been proposed to provide context-aware services on social media. In [
63], a public psychological pressure index was proposed to measure public opinion in social networks. The public psychological pressure index represents the status of public psychological pressure in relation to specific social events or topics to measure public psychological pressure in social networks. This index considers the probability distribution under the maximum entropy constraint condition. The public psychological pressure entropy is used as an important assessment quantitative indicator for public opinion analysis. Online learning comment is not only a textual evaluation, but also reflects changes in the learner’s behavior, knowledge, and emotion. In [
64], Social–Emotional Semantic Model (SESM) was proposed to extract a comment’s social and emotional semantic meaning. SESM considers online learners’ comments as semantics-based interaction. Keywords are extracted from the complex comments by the term frequency–inverse document frequency (TF-IDF). There are three relation types such as the user–evaluate–course relation, the user–reply–comment relation, and the user–post–comment relation. Double time series emotional analysis, which considers user-based time series algorithm and topic-based time series algorithm, analyzes and detects the emotional change within the current topic and all users. A peak-detection approach using social geo-tagged data was proposed to detect local events that occur in a specific region during a given time window [
65]. This method detects events through space-time feature extraction and peak detection. Each space-time feature is then modeled as a time series. It extracts text features by considering only hashtags, which are a meaningful way to categorize messages. The entropy of the hashtags is extracted and is used as a feature to achieve textual analysis. The baseline profile is computed through a scoring mechanism based on a statistics measure. The peak detection determines each element in the time series that is significantly distant from a baseline profile as a peak. The recommendation and information filtration provide personalized services to the designated users and answer users’ queries with a minimum number of mismatches. In [
66], an online clustering method was proposed to detect interesting topics in social data streams. To detect topics through incremental clustering, this method summarizes the investigated tweets into the cluster centroids. Each centroid is represented by multiple features, such as the timestamp of cluster generation and the timestamp of the last update, along with the set of terms appearing in the tweet. When a tweet arrives on a topic that has not appeared before, a new cluster is created. The online clustering incrementally groups similar tweets into the same cluster for the incoming social data streams. To assign a tweet to the centroid, the Jaccard similarity that takes into account both the cluster age and the terms occurring in the tweet is used.
AI-based approaches are being studied to provide optimized personalization services and accurate search results. In [
67], AI search methods were analyzed for personalized cancer therapy synthesis to solve related problems occurring in clinical practice. A method to compute a safe and effective personalized treatment for Colorectal Cancer (CRC) was studied. A simulation-based, non-linear, constrained optimization problem was defined for automatically synthesizing personalized therapies. A word-distributed sensitive topic representation model, called WDS-LDA, was proposed for representing a topic in social networks [
68]. The basic concept of WDS-LDA is that the distribution of words within a topic or among different topics has a great influence on the selection of topic expression words. WDS-LDA is based on the LDA model. The topic-word distribution acquired by the Latent Dirichlet Allocation (LDA) makes the representative words more important and makes the distinction among different topic words higher by considering the distribution of words between documents within a topic and among topics. To improve the precision of the subsequent topic detection and topic evolutionary analysis using the topic model, this method introduces the human cognitive ability and cognitive models to topic representation based on Hybrid human–AI (H-AI) and improves the precision of the subsequent topic detection and topic evolutionary analysis algorithms using the topic model. In [
69], a framework for acquiring the domain of the textual content generated by users in an online social network was proposed. A Twitter mining incorporating machine learning is used for domain based classification of users and their textual content. This framework consists of three modules such as data collection and acquisition, features extraction, and machine learning. It constructs a data set by collecting the users’ historical tweets containing public user content and metadata through the Twitter API. The data cleaning and integration techniques are applied to the collected dataset to ensure the certainty of the data. The features extraction extracts a list of user features. The new users’ features are extracted in the user features extraction and the existing users’ features are extracted in tweet features extraction. The machine learning module classifies users into political and non-political categories. To implement a computationally simple but effective approach, five classifiers are used: LR, SVM, top-down derivation-based decision tree (TD-DT), random forest-based decision tree (RF-DT), and gradient boosting-based decision tree (GB-DT).
3. Proposed Personalized Search Method
3.1. Characteristics
With the advancement of information processing systems and various web services, countless pieces of information have been created, and the preferences of users are changing in a variety of ways. For identifying the fields in which the user is interested, it is important to determine the user’s recent preferences. Because traditional personalized search methods do not consider the cases of information that is new to users, information unknown to users, and unclear information, it is necessary to develop a method that considers the user’s recent preferences and similar users’ preferences. In this paper, we propose a personalized search method that uses the social media user’s recent preferences and similar users’ preferences. The proposed method categorizes keywords extracted using a text mining method from social media activity information of users and determines the preferences of users. Furthermore, it assigns time-based weights to the preferences of users, with smaller and larger weights assigned to older and newer preferences, respectively. It determines the preferences of similar users on social media, professional users of a particular field, and users linked as friends. Subsequently, it compares the extracted keywords, the user’s preferences, and similar users’ preferences to provide search results.
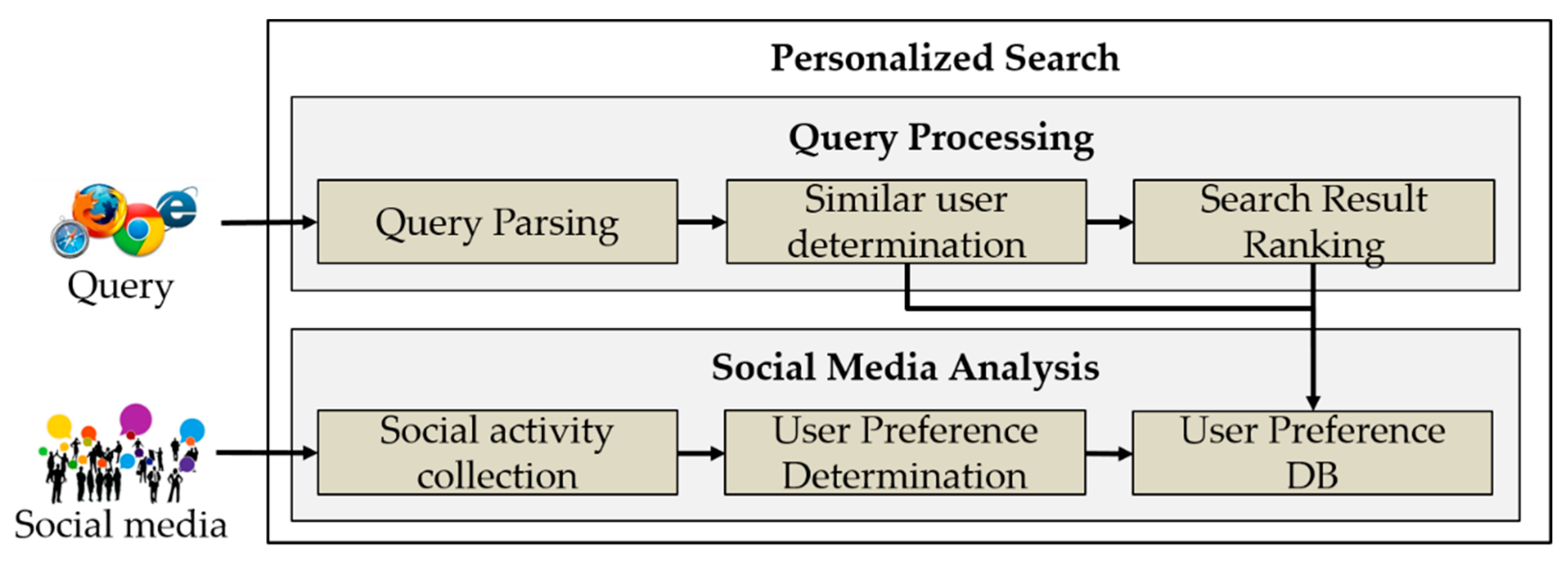
The proposed method consists of social media analysis and query processing, as shown in
Figure 1. The user preference determination is a preprocessing operation in which social activities of social media users are continuously collected and analyzed. The collected social information is used to determine the user’s preferences according to his/her social activities. Keywords are detected using a morpheme analyzer according to the user’s social activities, and the user’s preferences are determined from the detected keywords using TF-IDF. When the user submits a query, similar users are identified according to the query. For identifying similar users, the proposed method considers users who have similar preferences to the user according to the determined preferences of the user, users who are actively engaged in professional activities in a specific field according to the query, and users who are linked as friends to the user. Thus, it uses network characteristics of social media to consider users with strong social relationships. The ranking algorithm reflects the user’s preferences in the web search results of the user query and then applies the preferences of similar users to present the search results. Furthermore, it uses the fractional cascading method to provide the search results in the descending order of the preferences matched between the user and similar users.
3.2. User Preference Determination
The user preference determination is based on the postings that the user has created or shared on social media. The user’s behavior of creating and sharing postings and writing comments can reflect his/her interests.
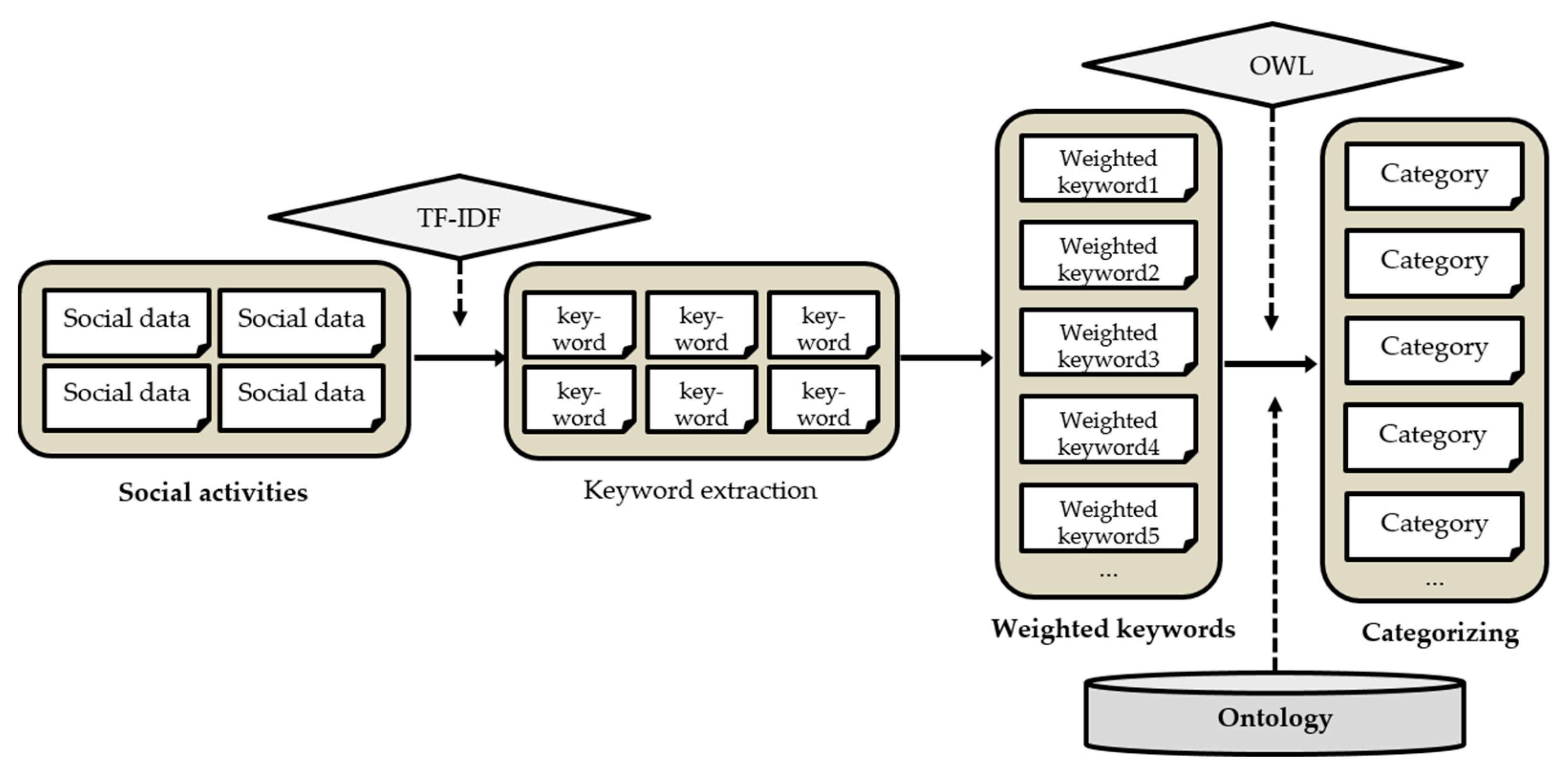
Figure 2 shows the procedure of determining the user’s preferences. The user preference determination is performed as a preprocessing task, and the activities of social media users are continuously collected and analyzed. The collected information is used to determine the user’s preferences according to the user’s social activities, and a morpheme analyzer is used to detect keywords from the user’s social activity information. TF-IDF is a technique for determining the importance of words in documents in the field of information retrieval and text mining. Social media users express their opinions and thoughts in a variety of ways. Therefore, they include meaningless words in identifying user preferences. In other words, words generally used by users on social media or words that appear in all documents are not keywords that can grasp individual preferences. The proposed method applies TF-IDF to words extracted through a morpheme analyzer to extract keywords that reflect individual preferences well among words contained in the user’s social activity records. Keywords with high TF-IDF values are extracted as words that express the user’s specific tendency well, and otherwise, they are recognized as meaningless words and removed. In TF-IDF, the term frequency (TF) indicates the frequency of a certain keyword appearing in the document and the inverse document frequency (IDF) indicates how many documents have a particular keyword among all the documents. For example, suppose that the user has engaged with 1000 documents, among which three documents contain the keyword ‘Liverpool’. If the keyword ‘Liverpool’ appears three times in a document, the TF for this document is 3, and the IDF is 2.5215. Thus, the TF-IDF has a value of 7.5645. A higher TF-IDF score indicates that the keyword is more important. It is difficult to recognize the user’s preferences according to simple keywords of interest. Therefore, a process of categorizing major keywords of interest obtained from social media activities is required. An ontology is constructed using the categories for classifying pages existing on social media [
70], and the user’s preferences are determined from the user’s major keywords of interest using the constructed ontology and Web Ontology Language (OWL) [
71].
It is difficult to identify the user’s recent preferences if the user’s profile is not updated periodically on social media. Therefore, the proposed method assigns time-based weights to the user’s preferences to reduce the proportion of old preferences and increase the proportion of recent preferences. Accordingly, recent activities are analyzed to determine recent preferences. Identifying the user’s preferences is an important element in analyzing the user’s characteristics. The user’s characteristics for determining the user’s interests and preferences are crucial for providing a personalized search. Users have different weights for their fields of interest. Accordingly, different weights are assigned to the categorized preferences.
Equation (1) is used to calculate the scores for the different fields of interest. High frequencies of a certain keyword in the field of interest and the most recent search keyword indicate that the level of interest in that keyword is high. Therefore, time-based weights are assigned to the fields that the user is interested in, and an index is assigned to the keyword frequency to minimize the weakness of the mean.
is a preference score that has categorized the extracted keyword.
is represented by the frequency of the keyword of interest and the time-based weight. Here,
is the number of keywords for the field of interest,
is the time-based weight of the keyword, as given by Equation (2), and
is the frequency of the keyword.
3.3. User Similarity Determination
Applying personalized rankings has numerous risks. Even a user who usually prefers document ‘A’ may sometimes be interested in document ‘B’. If only document ‘A’ is provided, the level of user satisfaction reduces. Similarly, although it is important to identify the user’s preferences, if only the user’s preferences are analyzed to perform a personalized search, the search results provide information that reflects the user’s preferences from a narrow viewpoint [
72]. The proposed method considers other users’ preferences to provide meaningful documents, including content that users have not yet grasped or expressed in existing social activities. In order to consider other user preferences, similar users are discriminated in consideration of user preference similarity, expertise, and friend relationships. Collaborative filtering, which is frequently used in recommendation services, can provide information that cannot be provided by methods that consider only the user’s personal preferences using similar users. Information of interest to users with similar user preferences may also be useful for a user who requests a recommendation service. Therefore, it is very important to identify users with similar preferences. There are experts among social media users who are interested in a specific field. We need to consider the user’s expertise because experts can identify useful documents that the user needs. On social media, friends are users with similar or reliable preferences. We need to consider friend relationships because the friends can share or spread user’s opinions and thoughts.
If users ‘A’ and ‘B’ are highly active in the sports, user ‘A’ can obtain information about the sports field from user ‘B’. It is important to determine the user’s preference for identifying similar users on social media. The user preference similarity between user
and user
is shown in Equation (3), where
represents the number of preference categories of the user, and
represents the number of preferences that match between the user and other users. A small score difference for a certain field indicates similar levels of interest in this field. Therefore, we calculate the difference in the preference score between the user and other users in a certain field and define the users with small differences as users with similar preferences.
We identify experts among social media users who can identify and provide useful documents. For example, if a certain user is highly engaged in professional activities for the sports, it can be assumed that he/she has considerable expertise in sports. If the preferences of users who have high levels of expertise are considered, useful information can be provided to the user. Equation (4) is used to calculate the expertise of users who are highly active for a specific preference, where
is the number of webpages that other users have engaged with,
is the number of participants for the webpage
,
is the number of recommendations,
is the number of times the webpage has been shared, and
is the number of comments. When the level of participation of other users in a document of a certain field is high, this indicates that the level of expertise of the user who created the document is high. Therefore, the recommendations, sharing, and comments are considered according to the number of participants in the postings for the social media activities of users to determine their levels expertise and identify users with expertise.
It is necessary to consider the preferences of users who are linked to the user as friends on social media. For example, if users ‘A’ and ‘B’ are linked as friends on social media, they may have a common preference. Therefore, if the preferences of close users are considered, useful information can be provided to the user. Equation (5) is used to calculate the scores of users who have strong social relationships with the user on social media, where
j is the number of hops connected by a friendship. Because users close to the user can provide satisfactory information to the user, we apply six degrees of Kevin Bacon to assign larger weights to closer users on social media. If the social relationship exceeds seven hops,
is set to 0.
User similarity is calculated by weighting
,
, and
calculated in Equations (3)–(5). By assigning appropriate weights to the equations for determining the users who have similar preferences, users who are professionally active in a specific field, and users linked as friends, we can examine which element has a larger impact on the user. Here,
. Users with high user similarity may influence determining necessary documents. Similar users’ preferences are reflected when ranking search results.
Assuming that the preferences and social activities of users are shown in
Table 1, let us determine the similarity of users A and B, and the similarity of users A and C. First, for the user similarity, we use the
, which is the score for the category of interest to calculate
. The
score of users ‘A’ and ‘B’ is 0.5, and that of users A and C is 0.5. For experts of a certain category, we can use the social activity information to calculate
. The
scores of users B and C are 0.42 and 0.7, respectively. Suppose that the social relationships of users A, B, and C are 1 hop and that the values of the weights
,
, and
are 0.45, 0.45, and 0.1, respectively. Then, the similarity score of users ‘A’ and ‘B’ and that of users ‘A’ and ‘C’ are 0.514 and 0.64, respectively. Therefore, user ‘C’ is the most similar user to user ‘A’.
The proposed method considers the preferences of the user and similar users to determine the fields of interest of other users in addition to the user’s preferences. It can identify the user’s preferences and similar users’ preferences, whereby the user can get search results based on the preferences of other users in the field of interest. As discussed previously in this section, it is important to determine the preferences of other users. In the personalized search, however, the user’s preferences are more important than other users’ preferences. The user’s preferences should have larger weights than similar users’ preferences. Therefore, the ranking algorithm prioritizes the user’s preferences over other users’ preferences.
3.4. Search Result Ranking
The ranking algorithm is the most important element in determining the quality of the search. Users desire more accurate information, and, therefore, the ranking is determined by combining the preferences of the user, similar users, professional users in a specific field, and users linked as friends to present social search results that reflect the user’s interests. The proposed method employs the ranking algorithm to provide appropriate search results to the user according to the preferences of users collected continuously. The ranking algorithm involves a three-step process.
First, the user’s search query is analyzed to determine the field of the query. For personalized search, the field of the query should be determined according to the preferences of users, and the field of the search query submitted by the user is determined to reflect the preferences of users who are similar or have relevant expertise. In the next step, the search results reflecting the user’s preferences are sorted. For example, when a regular web search is performed using the keyword ‘Liverpool’, results for ‘Liverpool Football Club’ and ‘Liverpool City’ are provided. If the user has a stronger preference for the sports field, the search results for ‘Liverpool Football Club’ will be presented at the top. Lastly, search results reflecting the preferences of similar users are sorted once more. A user who typically prefers ‘Liverpool Football Club’ may sometimes have an interest in ‘Liverpool City’. If search results are provided only for ‘Liverpool Football Club’, this may result in poor user satisfaction. Similarly, although it is important to identify the user’s preferences, if only the user’s preferences are analyzed to perform the personalized search, the search results will provide information that reflects the user’s preferences from a narrow viewpoint. The search results that reflect the preferences of similar users are sorted to consider information that users have not found yet and the case where the user’s information is unclear.
Algorithm 1 shows the ranking algorithm. First, keywords are extracted from the user’s search query to determine the field of the search query. Then, web search results for the user query are fetched. Subsequently, keywords related to the user’s preferences are matched via the fractional-cascading method [
73]. A keyword related to the user’s preferences is ranked higher if its number of matches is larger. Next, the keywords related to the preferences of similar users are matched via the fractional cascading method to determine the rankings once more, and the web search results are sorted again. The ranking algorithm considers the preferences of similar users after considering the user’s preferences, and this is a constraint on the preferences of other users. When keywords related to the preferences of other users are matched in the ranking algorithm, they must be accompanied by keywords related to the user’s preferences and then reflected in the search results. This is because the user’s preferences should have larger weights than the preferences of similar users. If the keywords related to the preferences of similar users are not related to the user’s preferences, results that are inappropriate for the user may be provided.
| Algorithm 1: Fractional-cascading method-based ranking algorithm. |
| Q: user query |
| D: number of search results |
| U: set of users |
| US: user similarity |
| UK: set of user preference keywords |
| SK: set of preference keywords for similar users |
| counter [1. . . D] ← 0 |
| determine a category related to Q based on U |
| determine similar users based on US |
| for each web search result R |
| for each user preference keyword UK |
| if (UK matches R) |
| counter[UK] ++ |
| else |
| break |
| RR ← ranked search results |
| for each ranked search result RR |
| for each similar user preference keyword SK |
| if (SK matches RR) |
| counter[SK] ++ |
| else |
| break |
| return personalized search results PR |
5. Conclusions
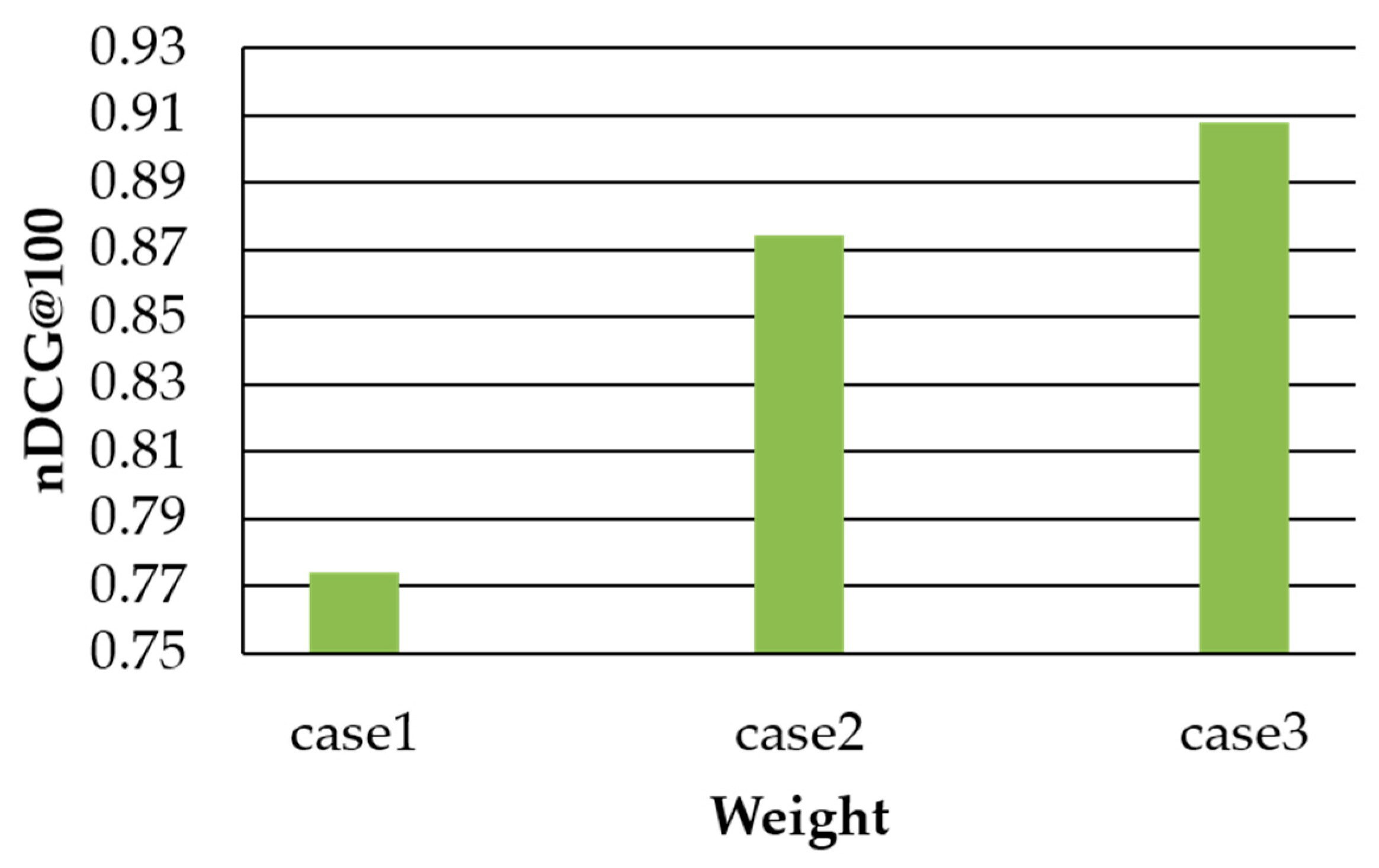
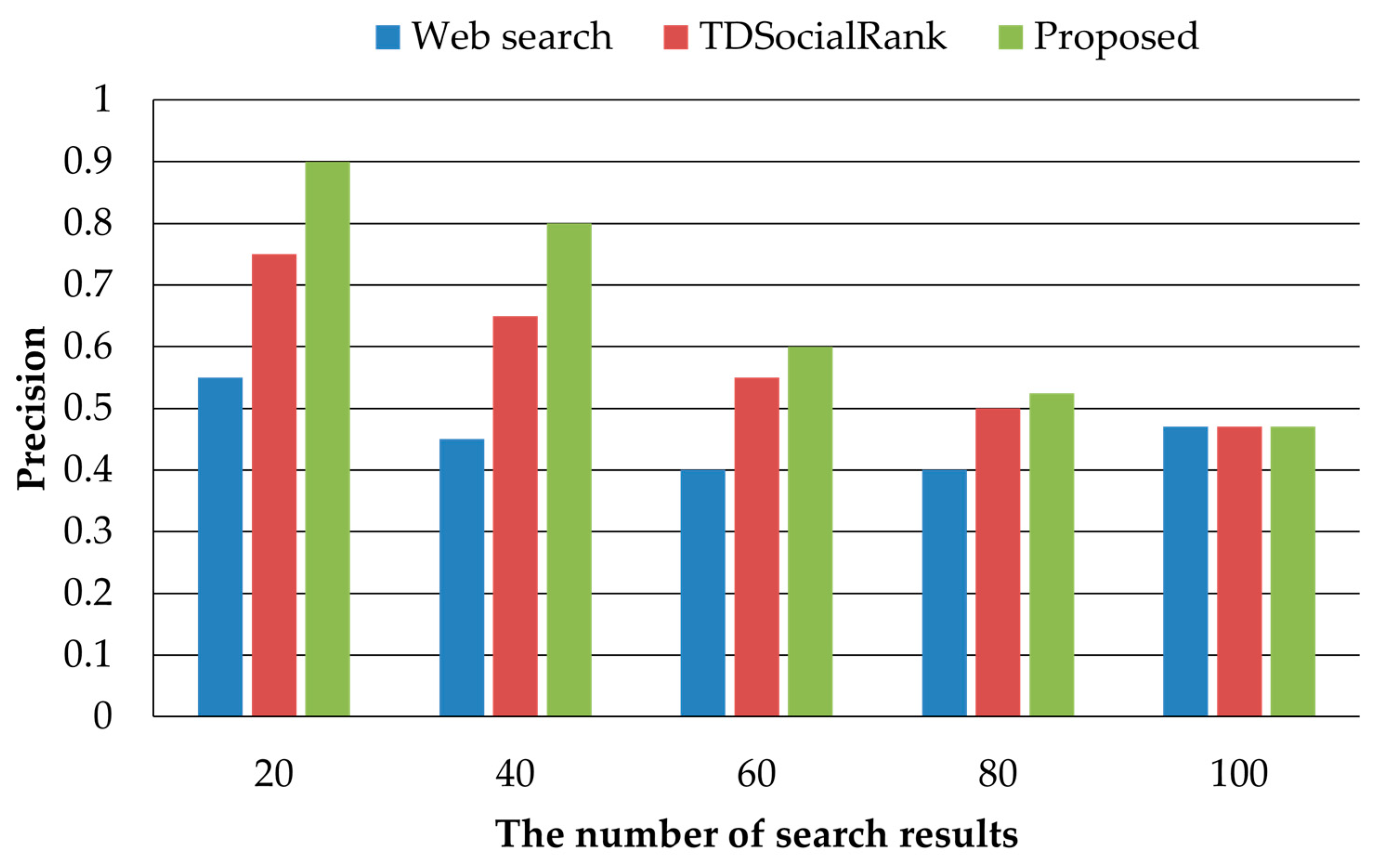
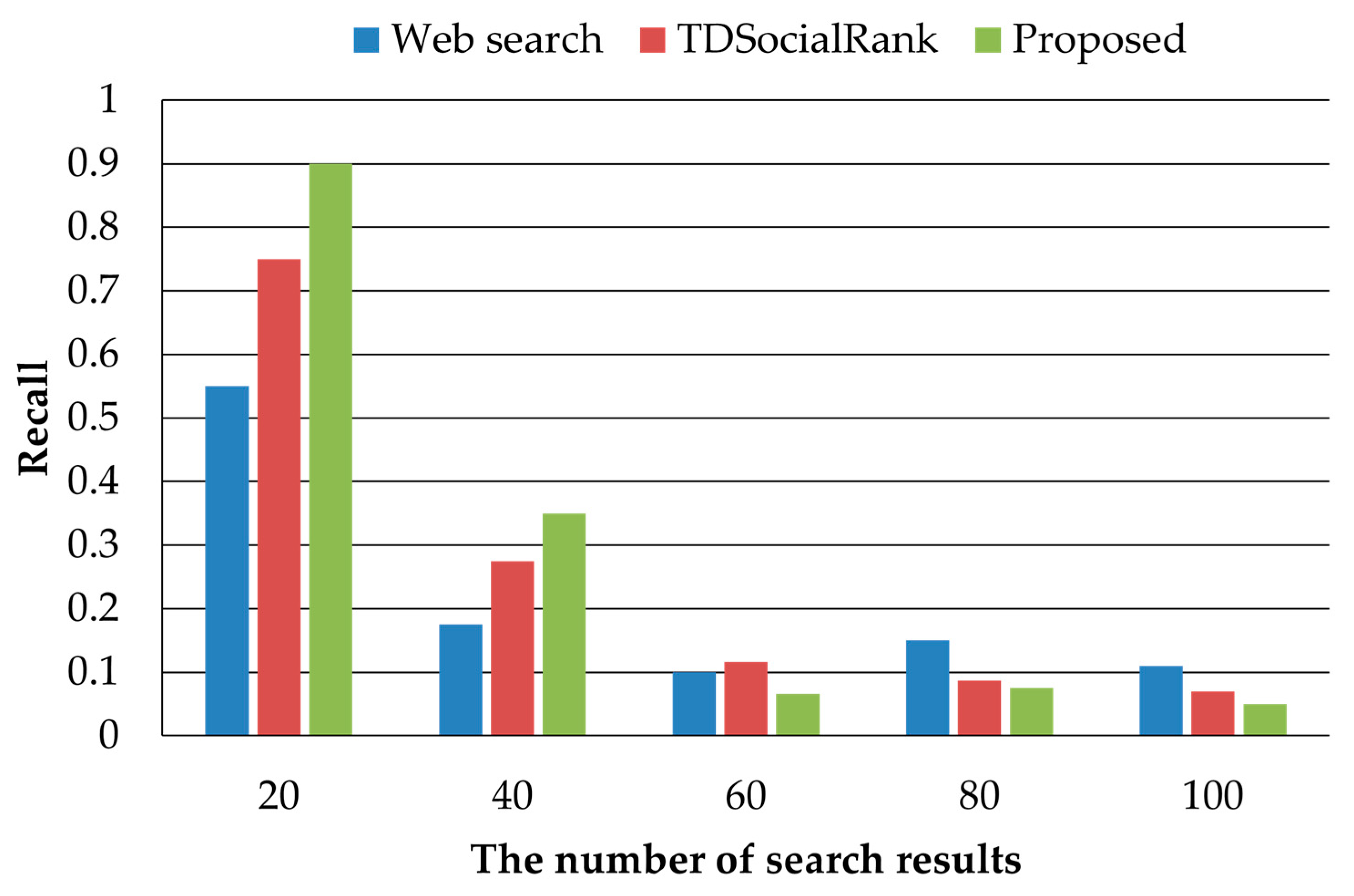
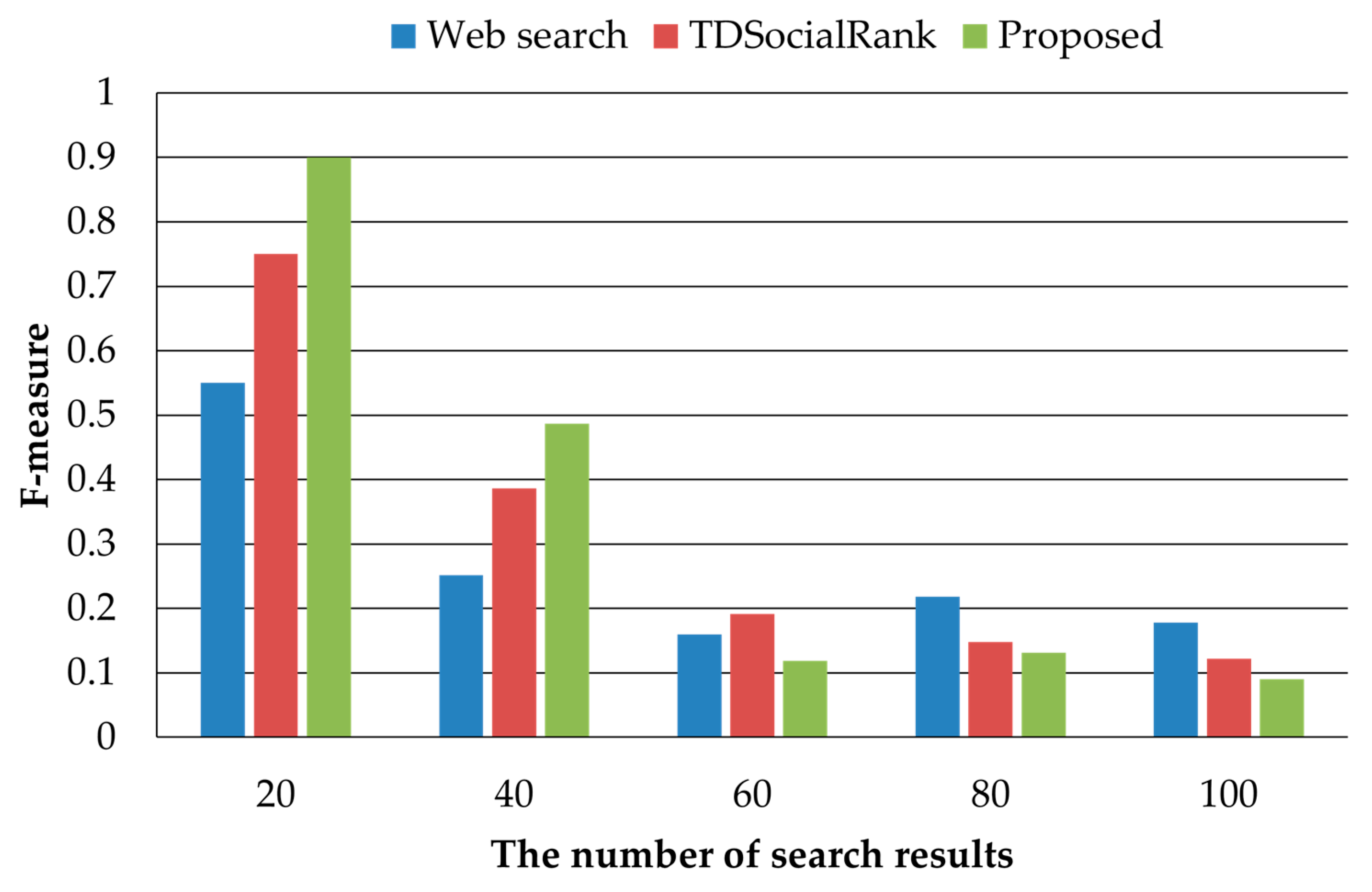
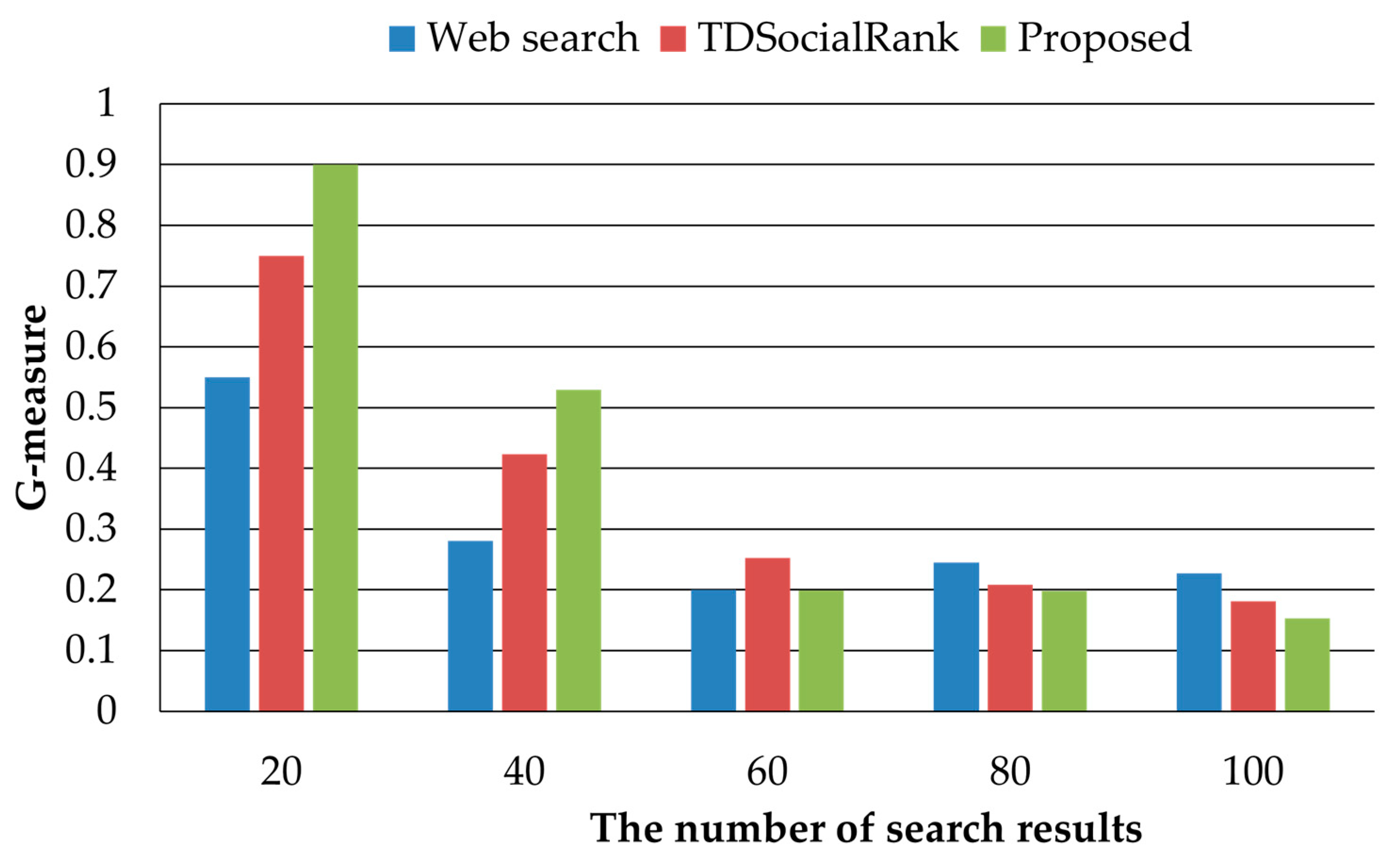
In this paper, we proposed a personalized search method considering user preferences and similar user preferences. It is very important to consider user preferences for personalized searches. On social media, users can express their opinions and share or spread various opinions among users. In order to figure out the user preference considering the characteristics of social media, the user’s activity records are collected on social media and the user’s interest keywords are extracted using TF-IDF. Since user preferences change continuously over time, we assign time weights to keywords of interest, giving many high values to state-of-the-art user preferences. Providing personalized search results that only consider user preferences is useful for users, but it does not provide search results related to keywords that are not interested. The proposed method discriminates users with similar preferences and provides search results reflecting similar users’ preferences. To demonstrate the superiority of the proposed method, we performed performance comparisons with a general web search method and TDSocialRank, a representative personalized search method. In a performance evaluation, the proposed method achieved excellent performance with regard to precision, but in some cases, the recall decreased as the number of search results provided increased. Therefore, research is needed to improve the recall of personalized search. Recently, studies on event and topic determination techniques and studies to apply AI technology to achieve accuracy have been conducted for context awareness. In future research, we will conduct research to apply user preference and context identified through AI technology to personalized search. In addition, we will demonstrate the superiority of the proposed method through performance comparisons with recent works in various experimental environments.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}