1. Introduction
Social media platforms are typical places for misinformation to spread. Social media platforms are frequently used by rumor-makers to spread false information. Rumors are spread by rumor mongers to manipulate public events, which can lead to negative consequences. For instance, in politics, rumors have influenced opinions on crucial matters, such as Brexit [
1] and the 2016 US presidential election [
2]. The “information pandemic” [
3] brought on by rumors (in the context of the recent new crown outbreak) has resulted in significant opposition to the suppression of the disease. Therefore, it is crucial to identify and control rumors.
Many research studies have invested in rumor detection. The most direct and efficient approaches involve fact-checking, which involves using known facts to validate the veracity of the news. Known facts come from domain experts, authoritative media, popular science websites, etc. By building a library of known facts, the news to be predicted is searched for in the library, and if there is no similar content in the library, it is considered a rumor. However, there are huge costs involved in building a library of known facts, so the coverage of the library of known facts is often extremely limited [
4].
The two primary categories of automated rumor detection techniques, aside from fact-checking-based techniques, are content feature-based methods and propagation structure-based methods. Most content feature-based methods take advantage of textual content, such as user retweets and source tweets [
5,
6]. To extract text features, the majority of them employ pre-trained models, such as word2vec [
7], Glove [
8], BERT [
9], etc. BERT (bidirectional encoder representation from transformers) is the encoder of a bidirectional transformer. The model uses two methods, masked LM and next sentence prediction, to capture the representation of words and sentences, respectively. However, methods solely based on text content cannot fit all rumor detection methods, mainly due to the following reasons. Firstly, some rumors are created by imitating the sentence patterns and word patterns of normal text. Secondly, adding real information to rumors makes it more difficult for the classifier to judge.
Recently, researchers found that the propagation structures of rumors and truth are significantly different. According to Vosoughi et al. [
10,
11], rumors spread more quickly, deeply, and widely than the truth. As a result, recent research studies [
12,
13,
14,
15] have presented high-level representations from propagation structures to identify rumors. With regard to encoders, deep learning algorithms are widely adopted due to their excellent performances [
16,
17,
18].
Methods based on propagation structures usually represent the spread of rumors as graph or tree structures, with tweets acting as nodes and the interactions formed by retweets and comments acting as edges. To extract features from the graph structure, existing research studies are mainly divided into two types—RNN-based methods and CNN-based methods. RNN-based techniques can capture sequential features from rumor propagation structures [
13], including long short-term memory (LSTM), gated recurrent unit (GRU), and recurrent neural network (RvNN). However, RNN-based approaches ignore the correlation between rumors and instead primarily concentrate on the sequential propagation patterns of rumors. As a result, some researchers use convolutional neural networks (CNNs) to extract the connection features of rumors [
15]. However, the global propagation structural relationships of graphs cannot be handled by CNN-based algorithms, although they can capture relevant features of local neighbors [
19].
Therefore, some researchers [
20,
21,
22] have attempted to extract high-dimensional feature representations of rumor propagation structures using graph convolutional networks (GCNs). A GCN is a graph-data version of CNN that can successfully capture global graph features by aggregating node neighborhood data.
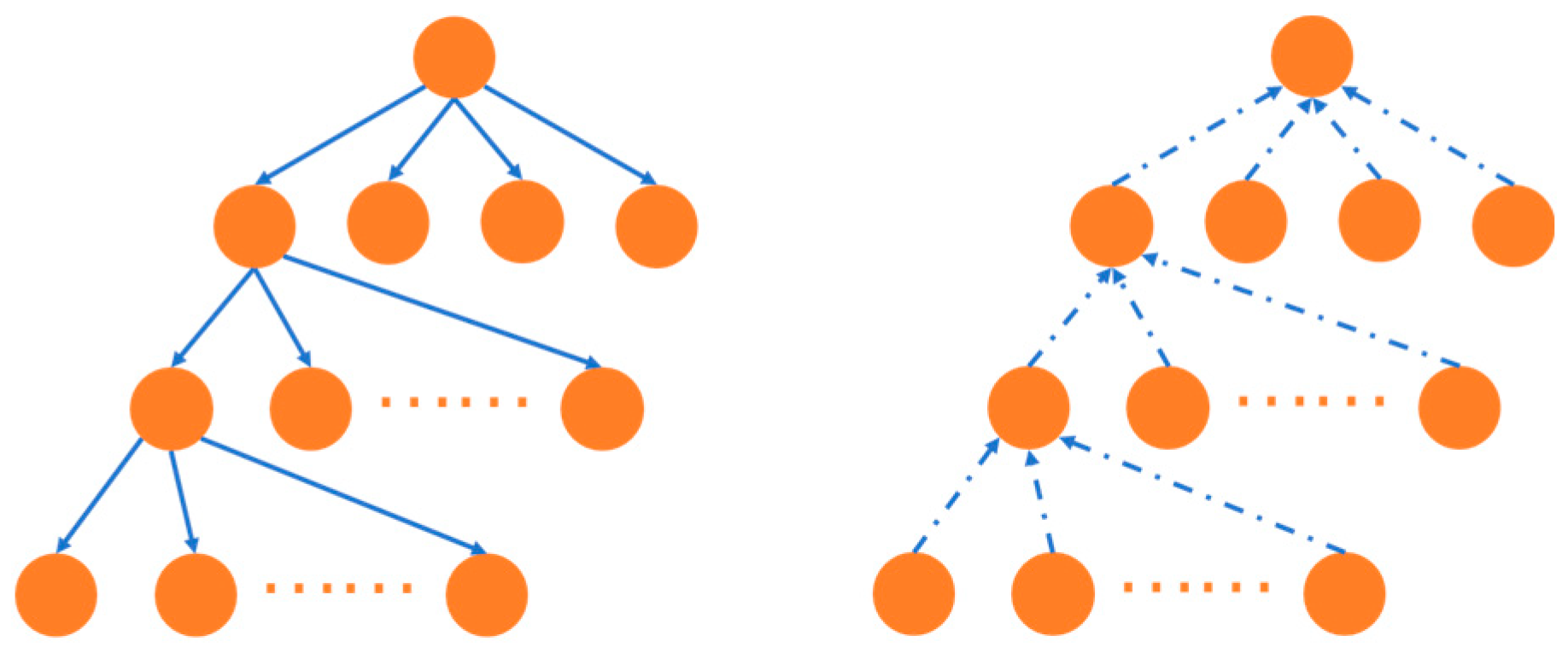
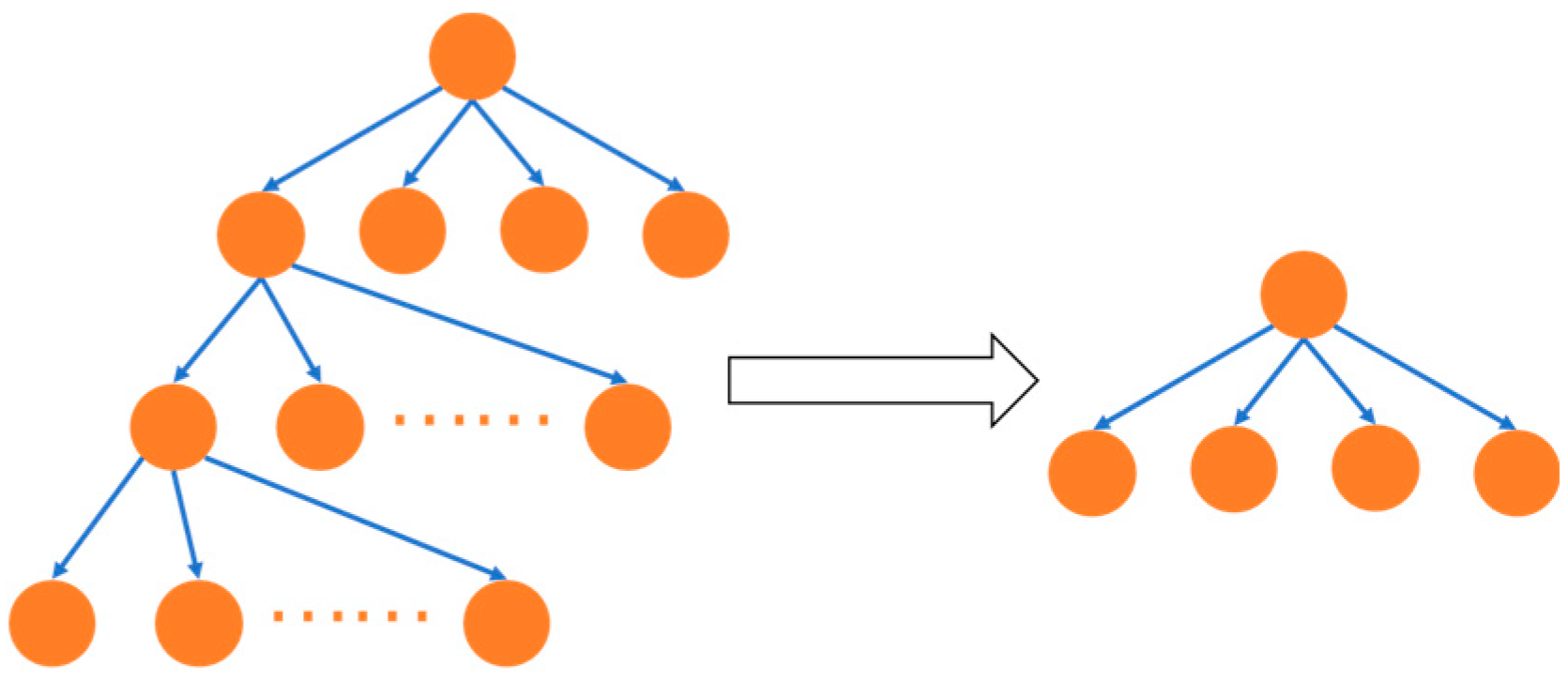
However, existing propagation-structure-based methods typically only consider the top-to-bottom propagation of rumors when constructing a graph model, ignoring the bottom-to-top aggregation of public opinions during the rumor-spreading process. Starting with the source tweet, a top-to-bottom propagation network is built between tweets through retweets or comments, as seen in the left part of
Figure 1. On the other hand, all comments or retweets are the public’s opinions on the previous tweet, and opinions are continuously gathered from the bottom to the top, as shown in the right picture of
Figure 1. Existing methods often only consider the top-to-bottom propagation of rumors, which is not comprehensive. By considering the aggregation structure of a rumor, we can capture more discriminative rumor features. Considering the aggregation structure is helpful for the enhancement of rumor features, especially in the early stage of rumor propagation, when there are few tweets in the propagation network.
Additionally, the methods based on the propagation structure cannot effectively utilize the text features of the rumors, even though some existing methods use the text features of tweets as the initialization features of the nodes and then use the graph convolutional network method to extract the propagation structure features. However, the initialized text features gradually fade away during the training process as the iterations increase.
This paper suggests a rumor detection method based on multimodal information fusion that fully considers rumor text features, propagation structure features, and aggregate structure features. First, we used the BERT pre-training model to extract the source tweet text features of the event. Next, we built two graphs for the propagation structure and aggregation structure, and the bidirectional graph convolutional network (Bi-GCN) [
21] to extract the propagation and aggregation structure features. Finally, we chose a multilayer perceptron (MLP) to obtain the final result. MLP is a forward-structured artificial neural network. The main contributions of this paper are as follows:
We introduce an attention mechanism and suggest a multimodal information fusion-based rumor detection method that fully integrates the text features and propagation–aggregation structure features of rumors.
We improved the rumor propagation network by including the aggregation structure, which can more accurately distinguish rumors from the truth, particularly in the early stages of rumors with an incomplete propagation structure.
Two real-world Twitter datasets were used in the experiments, and the results show that our method can identify rumors more accurately.
This paper is a continuation of previous work [
22] presented at the Fifth ICET conference. The previous version did not discuss the early detection of rumors. This paper supplements the experiments of early detections of rumors, adds related work chapters, and elaborates on the methodology and experimental process.
2. Related Work
Rumor detection methods are mainly divided into two categories—content feature-based methods and propagation structure-based methods. The methods based on content features mainly use the text content, picture content, video content, etc., of the original tweet as the model input to detect fake news.
The main method is based on text content. For example, Ma et al. [
12] applied deep learning techniques to fake news detection. This method inputs each sentence of the text into the recurrent neural network, uses the hidden layer vector of the recurrent neural network to represent the news information, and inputs the hidden layer features into the classifier to obtain the classification result. Yu et al. [
14] used a convolutional neural network to extract text features, and input the obtained embedding vector into the classifier to obtain the final classification result. Vaibhav et al. [
23] modeled news articles as graphs with sentences as nodes and inter-sentence similarities as edges; they transformed the fake news detection problem into a graph classification problem. Cheng et al. [
24] used a variational autoencoder (VAE) to self-encode text information to obtain the embedding representation of news text, and multi-task learning of the obtained news vector to improve the effectiveness of the model.
News or tweets contain textual as well as visual information, such as pictures and videos. Traditional statistics-based methods use the number of attached images, image popularity, and image type to detect fake news. However, these statistics-based features cannot describe the semantic features of images.
With the rise of deep learning, a large number of works [
25,
26,
27,
28] are using convolutional neural networks, such as VGG [
29] or ResNet [
30], to extract features from pictures; researchers are using the extracted features to detect fake news. However, the existing image forgery technology can change the semantic information of the image. The traditional CNN-based model can only extract the pixel-level information of the image, and cannot identify whether the image has been forged.
However, existing rumor makers often write fake news in the same way as real news. Therefore, it is not enough to distinguish fake news based on its content. Sociological studies [
10,
11] have shown that the propagation of real news and fake news in social networks is often different. Therefore, more researchers are using the propagation structure of news to detect fake news.
For example, Liu et al. [
31] regarded the spread of rumors and comment information as a time series; they used RNN and CNN to model the sequence, splice two latent vectors together, and input them into the classification layer to obtain the classification result. Ma et al. [
13] modeled the propagation process of rumors as a tree structure. This work constructed a bottom-up propagation tree and a top-down propagation tree, and used recurrent neural networks to extract node features in the tree to classify fake news. Song et al. [
32] modeled the news propagation graph as a dynamic graph. Considering the dynamic changes of the news propagation process, the dynamic graph embedding vector was obtained by using the dynamic graph neural network, which was input into the classifier to obtain the classification result.
However, the existing methods did not consider the aggregation features of rumors, which will lead to the loss of information. In addition, the existing methods cannot aggregate the multimodal rumor features well.
3. Problem Statement
The definition of the dataset for rumor detection is , where is the -th event and is the total number of events. , where is the number of posts in event , is the source post, is the -th relevant responsive post, and is defined as a graph, where represents the set of nodes, and represents a forwarding or replying relationship between two nodes.
For instance, there is a directed edge
, if
is a retweet of
, which is represented as
. The adjacency matrix is defined as
.
represents the corresponding element value of the
-th row and
-th column of matrix
, i.e.:
We define as the feature matrix composed of all tweets in event , where is the feature vector of the source tweet and is the feature vector of other responded tweets . In this paper, we used the BERT pre-trained model to extract the feature vector of each tweet’s content. Furthermore, a ground-truth label was connected to each event . In this paper, , stands for non-rumor, false rumor, true rumor, and unverified rumor, respectively.
The objective of rumor detection is to learn a classifier from the dataset, i.e.:
where
C and
Y, respectively, stand for the sets of events and labels.
4. Materials and Methods
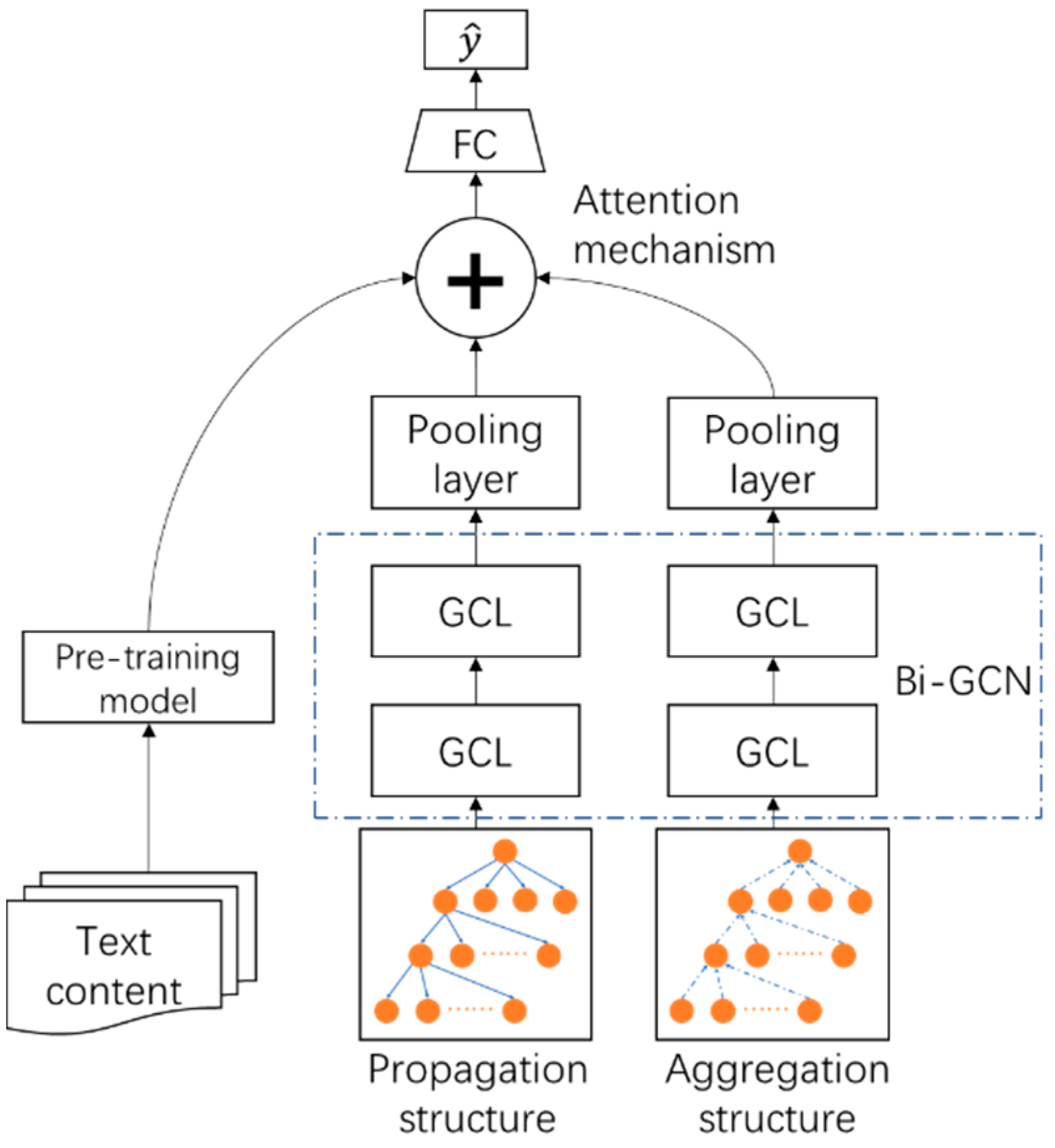
Figure 2 depicts the general workflow of the model employed in this article. We first extracted the text features from tweets using the BERT pre-training model, then we extracted the propagation and aggregation features from rumors using Bi-GCN, and finally we utilized a fully-connected neural network to obtain the result.
We will go into more detail about the model in this section. We exclude the subscript i from the following part in order to better illustrate our methodology.
4.1. Text Feature Extraction
To extract the content features of rumor texts, the BERT [
9] pre-training model was used in this part. BERT can more effectively address the issue of polysemy, i.e., the output of the model for the same word in different contexts is also different (in contrast to the standard word2vec, Glove, and other approaches).
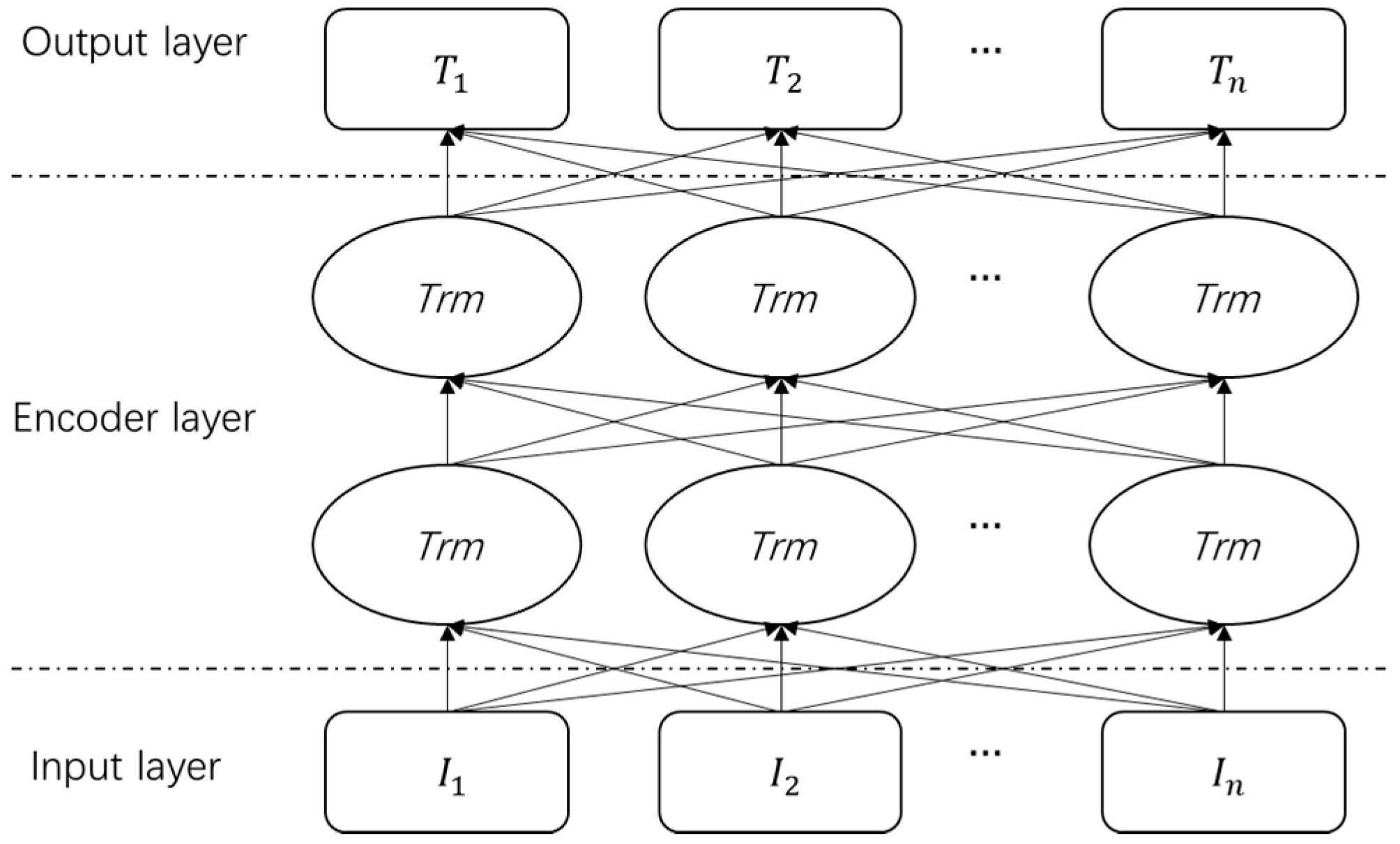
Figure 3 shows the pre-training model architecture of BERT. Each word’s embedding, which is divided into three parts by the input layer (token embedding, segment embedding, and position embedding) is one of them. Token embedding is a traditional word-embedding method, such as the one-hot method. There are two embedded special tokens, [CLS] and [SEP], at the start and end of the sentence, respectively. The sentence number to which the word belongs to is labeled using segmentation embeddings. Positional embeddings are used to represent the input sequence’s sequential features. The bidirectional transformer allows the BERT pre-training model to learn how the context word affects the current word, which improves the extraction of semantic deep features.
We utilized the BERT pre-training model to extract the content features of each tweet text in each event, which is represented as . We then used an additional two layers of fully-connected layers to convert it into a -dimensional vector , in order to keep its dimensions consistent with the dimensions of the propagation structure feature and aggregation structure feature, which will be introduced later.
4.2. Structure Feature Extraction
By using a bidirectional graph convolutional network (Bi-GCN), we extracted event propagation and aggregation structure features. Compared with traditional GCN, Bi-GCN can capture bidirectional neighbor features in the graph model. Based on the retweet and respond relationship, we built a propagation structure graph for each event. Meanwhile, we denoted the adjacency matrix and feature matrix as and X, respectively. A and X were the inputs of the model.
The Bi-GCN was made up of two components: a bottom-to-up graph convolutional network (BU-GCN) and a top-to-down graph convolutional network (TD-GCN). Even though their model structures were relatively similar, they had different adjacency matrices. The adjacency matrix in TD-GCN is represented as , whereas in BU-GCN, it is represented as , which is the transposition of A. The feature matrix X is the same for TD-GCN and BU-GCN.
The features of an event’s propagation structure and aggregation structure were extracted based on TD-GCN and BU-GCN, respectively. To extract features in TD-GCN, we utilized two graph convolutional layers (GCL); the calculation formula is as follows:
where
,
is the output of the first layer and second layer GCL of TD-GCN, known as the hidden states; the total number of nodes is
, the first layer’s output dimension is
, the second layer’s output dimension is
.
and
are parameter matrices in TD-GCN. For the activation function,
, we employed the ReLU function. As shown in (3) and (4), the calculations of
and
in BU-GCN are the same as
,
.
The pooling layer’s input was made up of
and
. The propagation structure feature and aggregation structures were read-out in the pooling layer using the average pooling approach, as illustrated in (5) and (6):
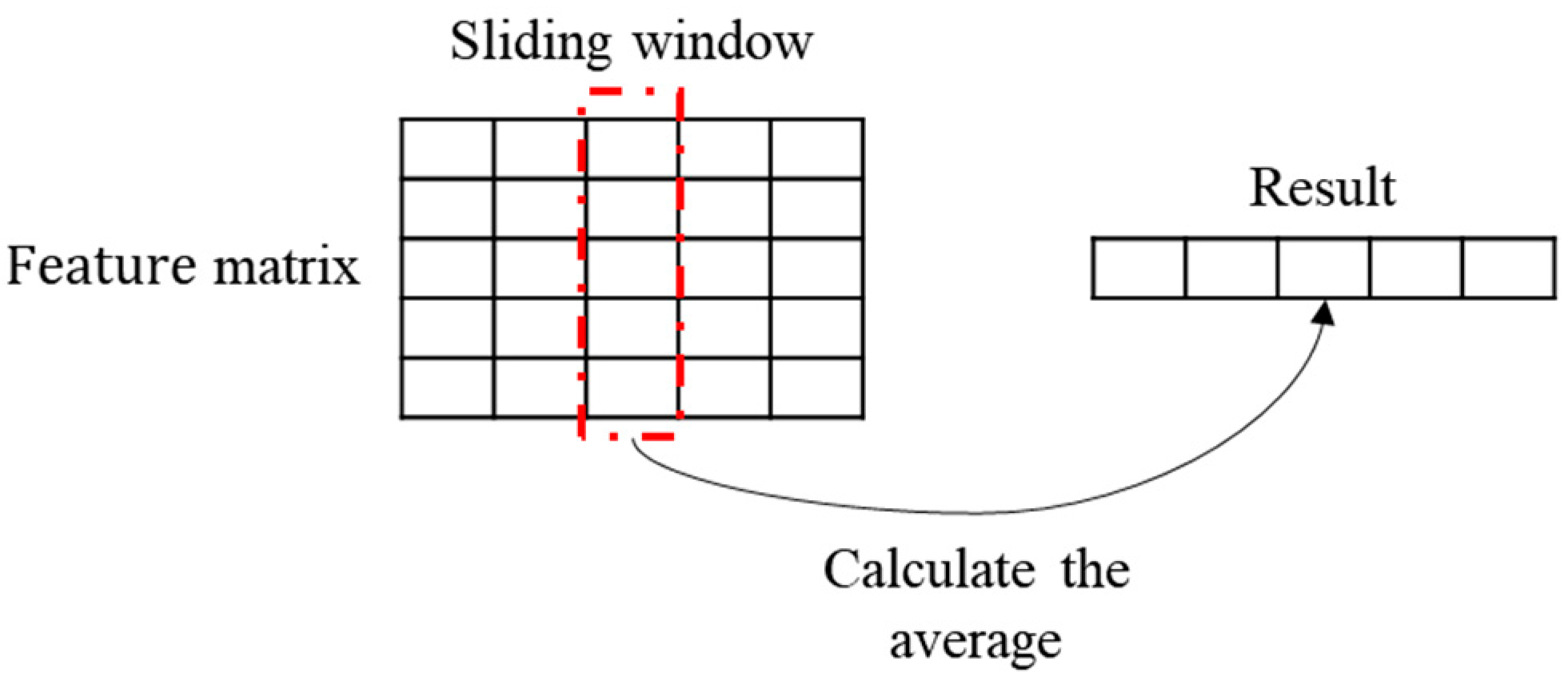
The operation of
in (5) and (6) is shown in
Figure 4, where the feature matrix was
or
, a sliding window of size
was set (shown by the dotted line in
Figure 4). The average of the elements in the window was calculated from the first column, and the window was moved backward in turn; finally, a pooling result of size
was made, i.e., the propagation structure feature
and the aggregation structure feature
.
4.3. Attention Mechanism
The attention mechanism allows the model to focus on the key points, rather than treating them equally. Many sequence-based [
33] or image-based [
34] tasks have shown the effectiveness of attention mechanisms. In this paper, we faced the multimodal features of text content, propagation structure, and aggregation structure, and we integrated them by introducing an attention mechanism. In the learning procedure, we estimated the attention coefficients adaptively for various types of information. We have:
where
is a set of the feature type; the elements in the set represent the text, propagation structure, and aggregation structure, respectively. Moreover,
, where
is a free parameter needed to be estimated. The rumor’s final feature is
.
4.4. Rumor Classification and Training
Compared with other classifiers, MLP classifiers have better recognition rates and faster classification speeds. So, the MLP classifier and a SoftMax layer were used to calculate the event’s predicted label
:
is a four-dimensional vector, with each element’s value representing the likelihood that the event belongs to the corresponding class.
During model training, we minimized the cross-entropy between predictions and ground truth for all events. Additionally, to prevent the overfitting issue, we added the
regular term throughout the training process. The definition of the loss function
is:
where
is the coefficient of the regular term and
is the total number of events. The value
and
are each element of
and
, representing the probability that the event belonged to the corresponding class.
5. Experiment Results
In this section, we show the experimental results of our approaches on two real-world datasets.
5.1. Datasets
On two real-world datasets, Twitter15 and Twitter16 [
35], we evaluated our suggested methodology. The datasets came from Twitter, one of the most popular social media platforms in the world. We created a propagation graph for each event in both datasets, using nodes to represent tweets and edges to represent their relationships with retweets or comments. The labels of each event in Twitter15 and Twitter16 were annotated according to the authenticity labels of articles on rumor-debunking websites (such as snopes.com, Emer-gent.info, and so on), whereas Ma et al. [
35] refined the labels from binary classes. They have been expanded to quaternary classes: non-rumor (N), false rumor (F), true rumor (T), and unverified rumor (U).
Table 1 shows the comprehensive statistics for the two datasets.
5.2. Experimental Settings
This paper chooses the following baseline models for the comparative experiments:
DTC [
36]: A rumor detection approach that employs decision tree as a classifier and obtains credibility based on handcrafted features.
SVM-RBF [
37]: A rumor detection method that uses post statistics as features and an SVM model with an RBF kernel for classification.
SVM-TS [
38]: A linear SVM classifier used to generate time series models with hand-crafted features.
SVM-TK [
35]: A rumor propagation structure-based SVM classifier with a propagation tree kernel.
RvNN [
13]: A rumor detection approach that uses a tree-structured recurrent neural network with a GRU unit to learn rumor representation via the rumor propagation structure.
PPC_RNN+CNN [
31]: A rumor detection model that uses rumor propagation paths to learn rumor representations by combining RNN and CNN.
The features used by each model are quite different; we describe them in detail in
Table 2.
We separated the two datasets into five parts at random and performed a five-fold cross-validation. The parameters of the model suggested in this study were updated using stochastic gradient descent, and the model was optimized using the Adam method with a learning rate of 0.002. Each node in Bi-GCN had an output dimension of 196 dimensions, which was also the output dimensions of the event text features, propagation structure features, and aggregation structure features. The training process was repeated 200 times, and the training ended when the validation loss stops reduced after 10 iterations.
5.3. Confusion Matrix and Metrics
The experiment in this paper is a four-classification problem, and its confusion matrix is shown in
Table 3.
Each value in
Table 3 indicates the number of events in a category that are predicted to be a certain value. For example, A12 indicates the number of events with true labels as non-rumors (N), but were predicted to be false rumors (F).
We compare models using accuracy and F1 values of each class. The accuracy refers to the closeness of the predicted value to its “true value”, which is a commonly used and an effective evaluation indicator. The calculation formula is as follows:
The F1 value is an indicator used in statistics to measure the performance of a classification model. It takes into account both the precision and recall of the classification model.
In the binary classification, the formula for calculating the
F1 value is:
where
TP is true positive,
FP is false positive, and
FN is false negative. In the multi-classification problem in this paper, the formula used for calculating the
F1 value of each category can be obtained by a simple derivation. The final
F1 value calculation formula is as follows:
5.4. Comparative Experiment
All approaches were tested in comparative experiments on the Twitter15 and Twitter16 datasets, and the findings are given in
Table 4 and
Table 5. The experimental results demonstrate that the approach in this work is superior to other baseline methods, with accuracies of 83.6% and 85.1%, respectively, and the influence on the F1 value is also superior among these models. It shows that our method can effectively distinguish rumor and truth by aggregating multimodal features.
Furthermore, we can see that models SVM-TK and RvNN, which considered event propagation structural features, performed significantly better than other methods that ignored propagation structures, indicating that the propagation structures of rumor events are indeed different from those of ordinary events and are sufficient in the process of rumor detection. Considering the propagation structures of rumors helps to improve detection accuracy.
In addition to traditional text content features and propagation structure features, our method also extracts aggregation structure features. The experimental results show that adding aggregation structure features can detect rumors more accurately.
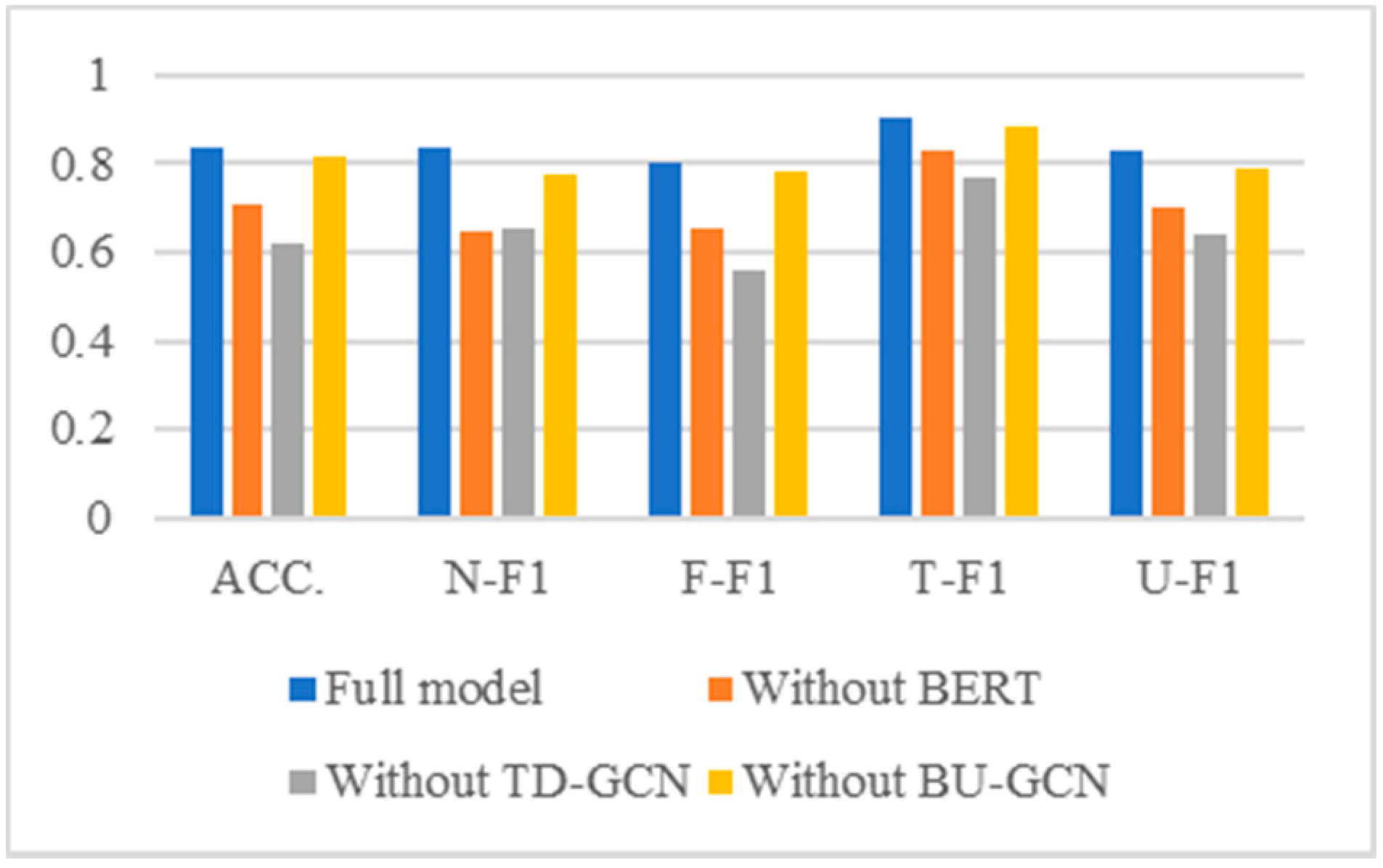
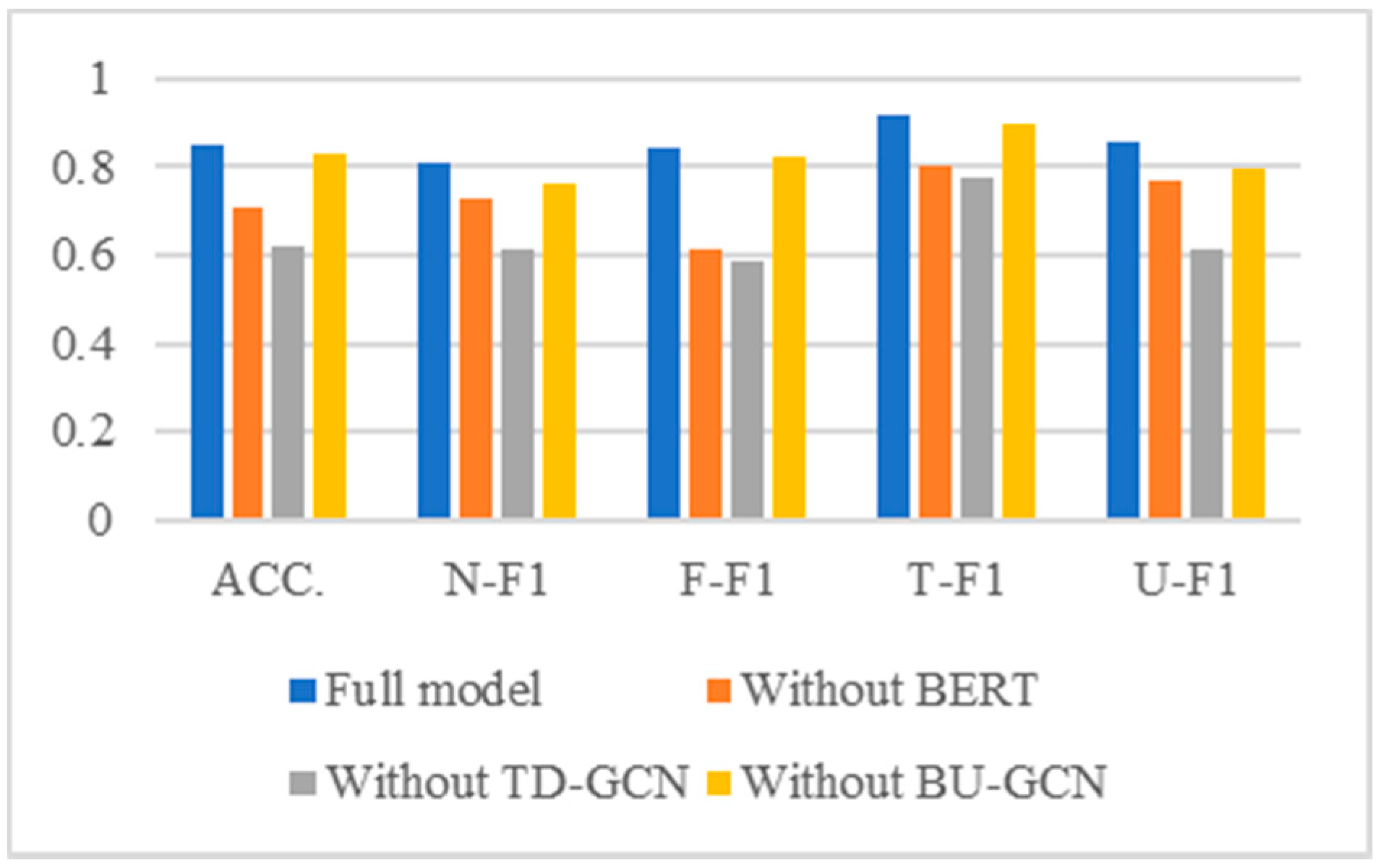
5.5. Ablation Study
We conducted an ablation study to see whether each module contributed to the model and which module contribute more. In other words, we demonstrate that text features, propagation structure features, and aggregation structure features can all benefit from rumor identification. Our proposed model’s main modules are BERT, TD-GCN, and BU-GCN, which stand for extract text features, propagation structure features, and aggregation structure features, respectively. Based on the whole model, we systematically removed the above modules and compared their changes in accuracy and the F1 value for each category.
Figure 5 and
Figure 6 show the experiment results.
The following conclusions can be drawn from the results of the ablation experiments shown in
Figure 5 and
Figure 6. After removing any module, all indicators decreased, demonstrating that each module in our model has a beneficial effect on rumor recognition results, suggesting that each feature is essential. The indicators declined the most after removing the TD-GCN module, showing that the propagation structure feature had the biggest impact on rumor detection.
The contribution ranking of the three modules in the model for the rumor detection results was: TD-GCN, BERT, and BU-GCN. That is to say, the contributions of different types of features to the results of rumor recognition are ranked from high to low as text feature, propagation structure feature, and aggregation structure feature.
5.6. Early Detection
We found that the early detection of rumors is significantly improved by fusing aggregated structures. Fake news is easily forwarded and spread by a large number of users on social media, causing serious impacts in a short period of time. Therefore, the earlier it is detected, the more the negative impacts can be avoided. However, in the early days of rumor spreading, the available spread of data is limited. In order to verify that the method in this paper improved the effect of the early detection of rumors, we used a small number of early rumor data, as shown in
Figure 7, to compare the two methods: (1) The method using only the propagation structure (PS); (2) the method to fuse the propagation and aggregation structures (PS+AS). The results are shown in
Table 6 and
Table 7. The ratio column in the table indicates the ratio of the propagation structure used during training.
From the experimental results of early detection, it can be seen that the method considering the aggregated structure is significantly better than the method that only considers the propagation structure. Moreover, the lower the ratio, the more obvious the performance differences. This shows that considering the aggregation structure can effectively enhance rumor features and improve the distinction between real information and rumor features.
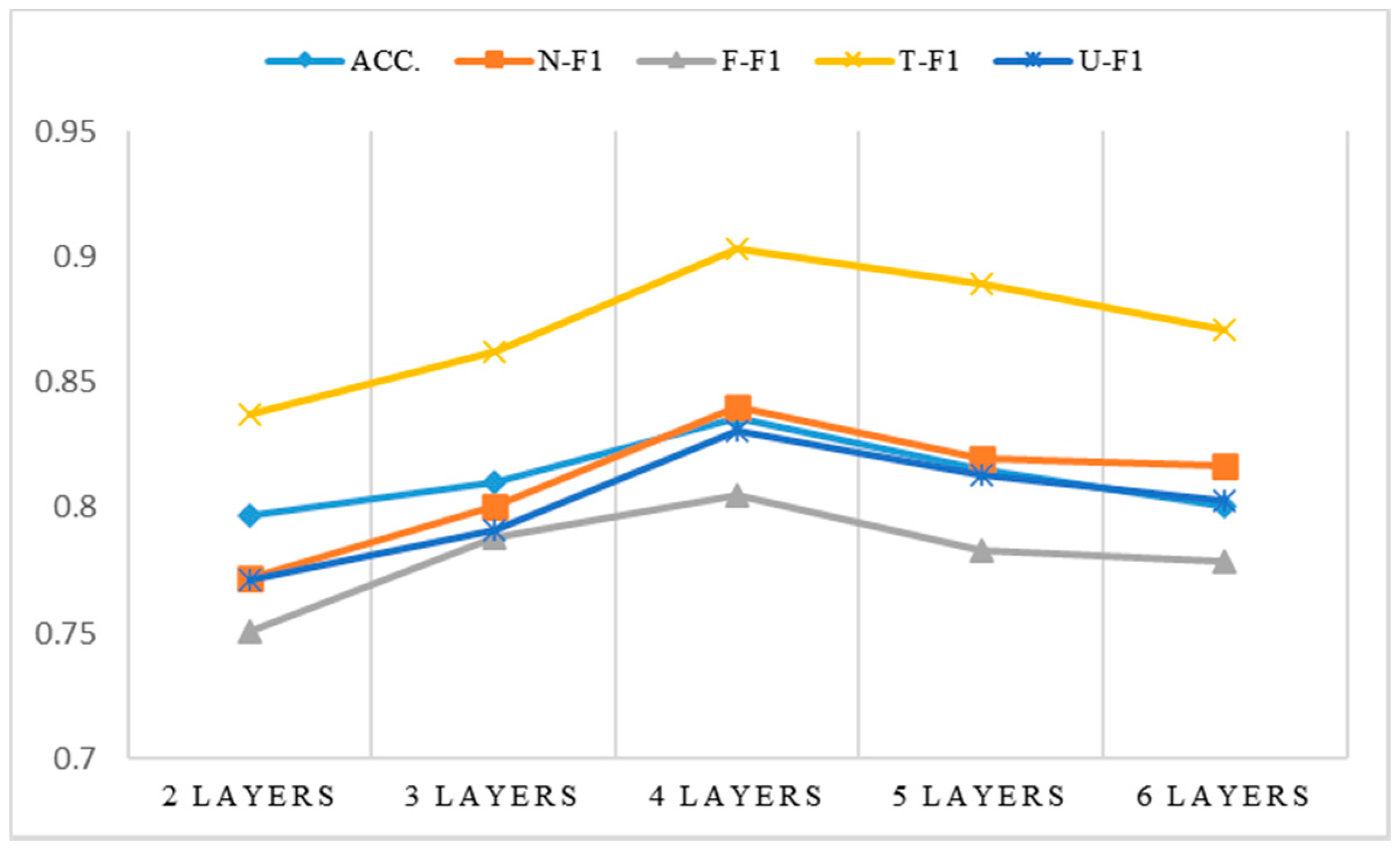
5.7. Classifier
In this paper, a fully-connected neural network with four layers was chosen as the classifier, and the model structure was 192 × 96 × 48 × 4. In this section, we evaluate the effects of different model topologies on the performance of rumor detection through experiments. Layers 2, 3, 5, and 6 had the following model structures, as illustrated in
Figure 8: 192 × 4, 192 × 96 × 4, 192 × 96 × 48 × 24 × 4, 192 × 96 × 48 × 24 × 12 × 4. Each evaluation indicator was the most effective when the model structure had four layers. This is because when the model structure is too simple, the model under-fits, and when the model structure is too complex, the model slightly over-fits. All of them contributed to a decline in the model performance.
6. Conclusions
In this paper, we propose a new rumor detection method and compared it with existing methods; we fully considered the aggregation structures of rumors when extracting rumor features. Moreover, through the attention mechanism, the content features of rumor text, propagation structure, and aggregation structure were integrated. More discriminative rumor features were obtained by this method. Among them, we used the BERT pre-training model to extract text features, TD-GCN to extract propagation structural features, and BU-GCN to extract aggregation structural features. The comparative experimental results show that the proposed method can detect rumors more accurately than the existing methods. The ablation study results show that each module of our method has a positive effect on the detection results. The experiments of early detection show that the method considering the aggregation structure can deal with the early detection of rumors more effectively.
Rumor detection is currently a research hotspot in academia, and there are still many problems that need to be solved, for example, (1) how to detect false information in visual information (considering that social media tweets contain a large number of visual information); (2) how to accurately detect rumors in the early stages of a rumor (so as to cut off the spread of the rumor as soon as possible); (3) how to establish an effective mechanism so that the model can provide reasons for making judgments while giving the rumor detection results (so that the detection results are more convincing). In future work, we will conduct more in-depth research on the above issues.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}