



LASNet: A Light-Weight Asymmetric Spatial Feature Network for Real-Time Semantic Segmentation


Abstract
:1. Introduction
- The semantic segmentation accuracy is high, but the network model parameters are large.
- The semantic segmentation network is lightweight, but the segmentation accuracy is insufficient.
- The semantic segmentation network cannot fully use context information.
- We propose a novel deep convolution neural network called LASNet, which adopts an asymmetric encoder-decoder architecture. Through ablation study, the optimal parameters such as module structure, dilation rate, and dropout rate are obtained, which is helpful to build a high-precision and real-time semantic segmentation network.
- To preserve and utilize spatial information, we propose the LAS module, which adopts asymmetric convolution, group convolution, and dual-stream structure to balance inference speed and segmentation accuracy. However, the LAS module’s computational complexity is much lower. In the encoding part of LASNet, which uses the LAS module to process downsampling features, reduce the number of network parameters, and maintain strong feature extraction ability.
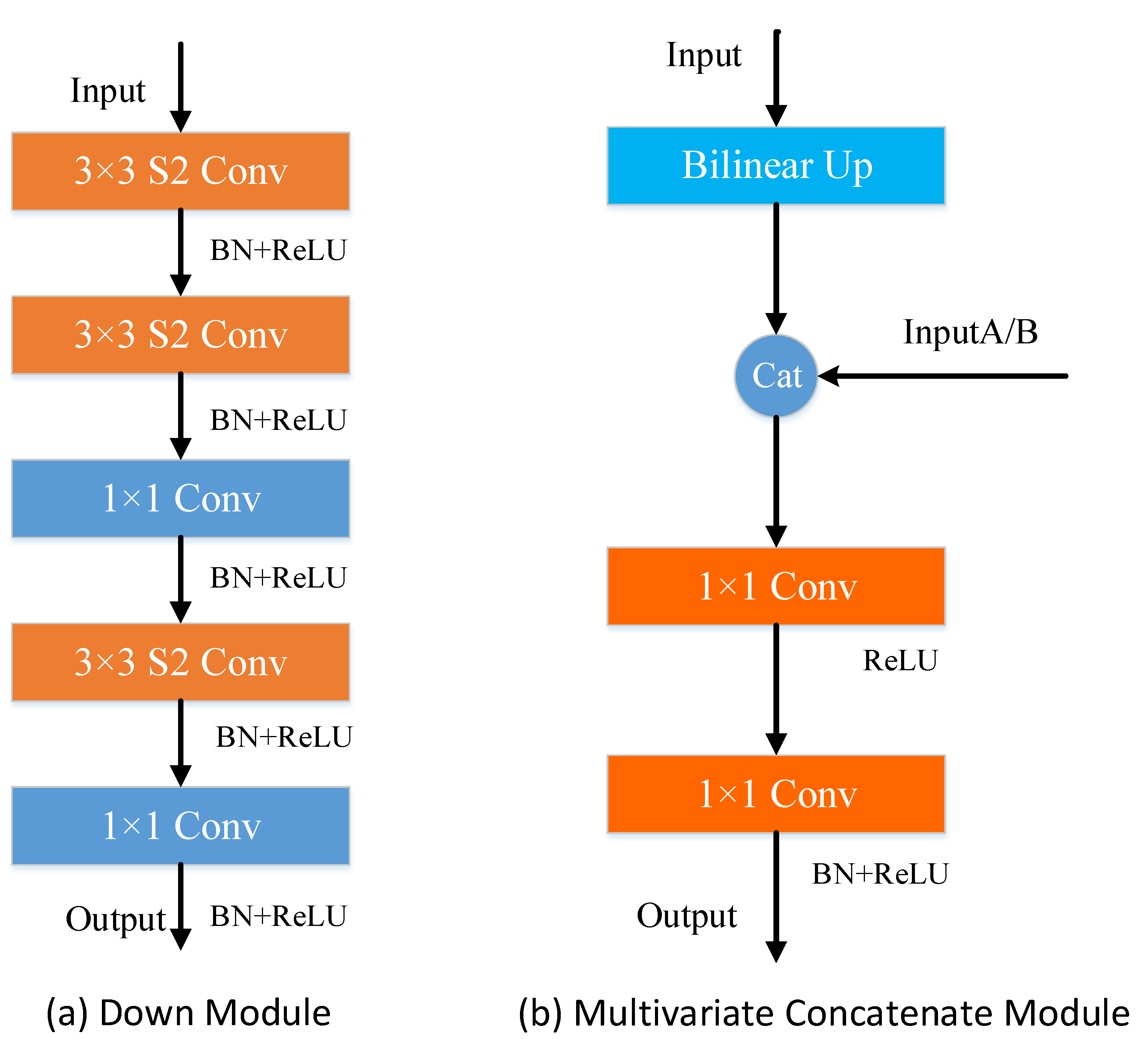
- We propose a multivariate concatenate module, which is used by the decoder of LASNet for upsampling. The module can reuse shallow features of images, which helps to improve the segmentation accuracy and maintain a high inference speed.
- We test LASNet on the CityScapes dataset. The comprehensive experiments show that our network achieves available state-of-the-art results in terms of speed and accuracy. Specifically, LASNet achieves 70.99% mean IoU on the CityScapes dataset, with only 0.8 M model parameters and 110.93 FPS inference speed using NVIDIA Titan XP GPU.
2. Related Works
2.1. Semantic Segmentation
2.2. Convolutional Factorization
2.3. Attention Mechanism
3. LASNet
3.1. LAS Module
3.1.1. LAS-A Module
3.1.2. LAS-B Module
3.1.3. LAS-C Module
3.2. Multivariate Concatenate Module
3.3. Transform Module
3.4. LASNet Architecture
4. Experiment
4.1. Implement Details
4.2. Comparative Experiments
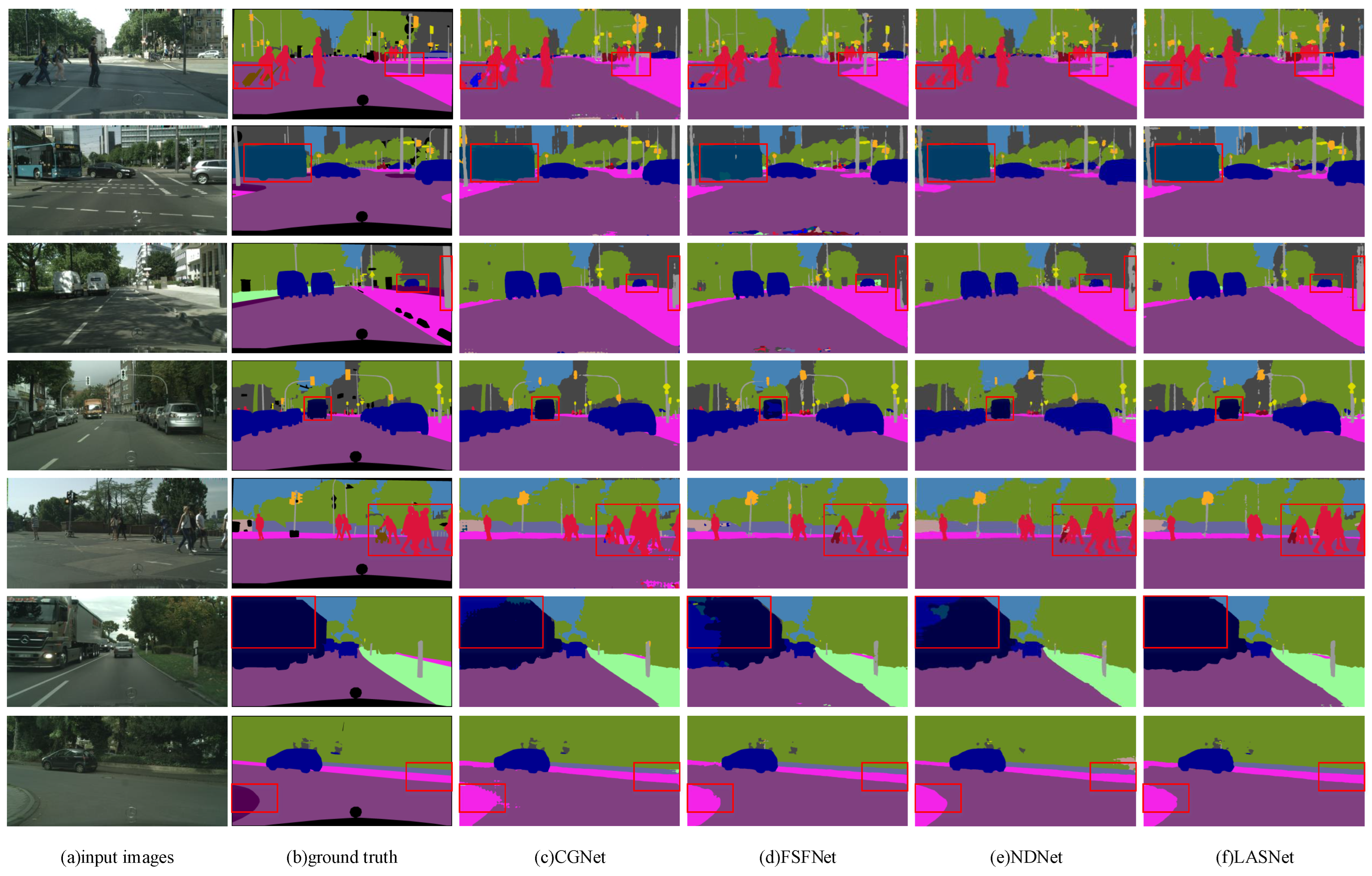
4.3. Analysis of CityScapes Evaluation Results
4.4. Ablation Study
4.4.1. LAS Module Structure
4.4.2. LAS Module Number
4.4.3. Dilation Rate
4.4.4. Dropout Rate
4.4.5. Transform Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, Y.; Liu, Y.; Zhan, W.; Zhu, D. Lightweight Dual-Stream Residual Network for Single Image Super-Resolution. IEEE Access 2021, 9, 129890–129901. [Google Scholar] [CrossRef]
- Zhu, D.; Zhan, W.; Jiang, Y.; Xu, X.; Guo, R. MIFFuse: A Multi-Level Feature Fusion Network for Infrared and Visible Images. IEEE Access 2021, 9, 130778–130792. [Google Scholar] [CrossRef]
- Zhu, D.; Zhan, W.; Jiang, Y.; Xu, X.; Guo, R. IPLF: A Novel Image Pair Learning Fusion Network for Infrared and Visible Image. IEEE Sens. J. 2022, 22, 8808–8817. [Google Scholar] [CrossRef]
- Luo, X.; Wang, G.; Song, T.; Zhang, J.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. MIDeepSeg: Minimally interactive segmentation of unseen objects from medical images using deep learning. Med. Image Anal. 2021, 72, 102102. [Google Scholar] [CrossRef]
- Feng, R.; Zheng, X.; Gao, T.; Chen, J.; Wang, W.; Chen, D.Z.; Wu, J. Interactive Few-shot Learning: Limited Supervision, Better Medical Image Segmentation. IEEE Trans. Med. Imaging 2021, 40, 2575–2588. [Google Scholar] [CrossRef]
- Cui, W.; He, X.; Yao, M.; Wang, Z.; Hao, Y.; Li, J.; Wu, W.; Zhao, H.; Xia, C.; Li, J.; et al. Knowledge and Spatial Pyramid Distance-Based Gated Graph Attention Network for Remote Sensing Semantic Segmentation. Remote Sens. 2021, 13, 1312. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Lv, Q.; Sun, X.; Chen, C.; Dong, J.; Zhou, H. Parallel complement network for real-time semantic segmentation of road scenes. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4432–4444. [Google Scholar] [CrossRef]
- Dong, G.; Yan, Y.; Shen, C.; Wang, H. Real-time high-performance semantic image segmentation of urban street scenes. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3258–3274. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.T.; Li, Y.; Fan, J.H.; Wang, R. RGAM: A novel network architecture for 3D point cloud semantic segmentation in indoor scenes. Inf. Sci. 2021, 571, 87–103. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, Y.; Fan, Y.; Wu, X.; Zhang, S.; Kang, B.; Latecki, L.J. AGLNet: Towards real-time semantic segmentation of self-driving images via attention-guided lightweight network. Appl. Soft Comput. 2020, 96, 106682. [Google Scholar] [CrossRef]
- Wu, T.; Lu, Y.; Zhu, Y.; Zhang, C.; Wu, M.; Ma, Z.; Guo, G. GINet: Graph interaction network for scene parsing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 34–51. [Google Scholar]
- Elhassan, M.A.; Huang, C.; Yang, C.; Munea, T.L. DSANet: Dilated spatial attention for real-time semantic segmentation in urban street scenes. Expert Syst. Appl. 2021, 183, 115090. [Google Scholar] [CrossRef]
- Zhuang, M.; Zhong, X.; Gu, D.; Feng, L.; Zhong, X.; Hu, H. LRDNet: A lightweight and efficient network with refined dual attention decorder for real-time semantic segmentation. Neurocomputing 2021, 459, 349–360. [Google Scholar] [CrossRef]
- Kim, M.; Park, B.; Chi, S. Accelerator-aware fast spatial feature network for real-time semantic segmentation. IEEE Access 2020, 8, 226524–226537. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef]
- Shi, M.; Shen, J.; Yi, Q.; Weng, J.; Huang, Z.; Luo, A.; Zhou, Y. LMFFNet: A Well-Balanced Lightweight Network for Fast and Accurate Semantic Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–5. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y.; Hong, R.; Cheng, J.; Wang, M. Real-Time Semantic Segmentation via Spatial-Detail Guided Context Propagation. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Lv, T.; Zhang, Y.; Luo, L.; Gao, X. MAFFNet: Real-time multi-level attention feature fusion network with RGB-D semantic segmentation for autonomous driving. Appl. Opt. 2022, 61, 2219–2229. [Google Scholar] [CrossRef]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. Espnetv2: A light-weight, power efficient, and general purpose convolutional neural network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 9190–9200. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhou, Z.; Zhou, Y.; Wang, D.; Mu, J.; Zhou, H. Self-attention feature fusion network for semantic segmentation. Neurocomputing 2021, 453, 50–59. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 3139–3148. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357. [Google Scholar]
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502. [Google Scholar]
- Liu, M.; Yin, H. Feature pyramid encoding network for real-time semantic segmentation. arXiv 2019, arXiv:1909.08599. [Google Scholar]
- Yang, Z.; Yu, H.; Fu, Q.; Sun, W.; Jia, W.; Sun, M.; Mao, Z.H. Ndnet: Narrow while deep network for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5508–5519. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Layer | Type | Out_Channel | Out_Size |
|---|---|---|---|---|
| Encoder | 0 | Input Image | 3 | 1024 × 2048 |
| 1 | Down Module | 64 | 128 × 256 | |
| 2 | LAS_A | 64 | 128 × 256 | |
| 3 | LAS_A | 64 | 128 × 256 | |
| 4 | LAS_A | 64 | 128 × 256 | |
| 5 | LAS_A | 64 | 128 × 256 | |
| 6 | Bilinear Down | 64 | 64 × 128 | |
| 7 | Convolution 1 × 1 | 96 | 64 × 128 | |
| 8 | LAS_B | 96 | 64 × 128 | |
| 9 | LAS_B | 96 | 64 × 128 | |
| 10 | LAS_B | 96 | 64 × 128 | |
| 11 | LAS_B | 96 | 64 × 128 | |
| 12 | Bilinear Down | 96 | 32 × 64 | |
| 13 | Convolution 1 × 1 | 128 | 32 × 64 | |
| 14 | LAS_C | 128 | 32 × 64 | |
| 15 | LAS_C | 128 | 32 × 64 | |
| 16 | LAS_C | 128 | 32 × 64 | |
| 17 | LAS_C | 128 | 32 × 64 | |
| Transform Module | 18 | Triplet Attention | 128 | 32 × 64 |
| Decoder | 19 | Convolution 1 × 1 | 32 | 32 × 64 |
| 20 | Bilinear Up(×2) | 32 | 64 × 128 | |
| 21 | Concat | 128 | 64 × 128 | |
| 22 | Convolution 1 × 1 | 32 | 64 × 128 | |
| 23 | Convolution 1 × 1 | 48 | 64 × 128 | |
| 24 | Bilinear Up(×2) | 48 | 128 × 256 | |
| 25 | Concat | 112 | 128 × 256 | |
| 26 | Convolution 1 × 1 | 32 | 128 × 256 | |
| 27 | Convolution 1 × 1 | 19 | 128 × 256 | |
| 28 | Bilinear Up(×8) | 19 | 1024 × 2048 |
| Method | Input Size | Params (M) | FPS | FLOPs (G) | mIoU (%) |
|---|---|---|---|---|---|
| SegNet | 512 × 1024 | 29.45 | 4.50 | 326.26 | 57.00 |
| ENet | 1024 × 2048 | 0.35 | 21.42 | 21.76 | 58.30 |
| ICNet | 1024 × 2048 | 26.72 | 24.61 | 87.83 | 68.50 |
| ESPNet | 1024 × 2048 | 0.20 | 46.68 | 16.65 | 60.30 |
| CGNet | 1024 × 2048 | 0.49 | 18.82 | 27.73 | 64.80 |
| ERFNet | 1024 × 2048 | 2.06 | 14.63 | 120.22 | 68.00 |
| DABNet | 1024 × 2048 | 0.75 | 30.51 | 41.50 | 68.10 |
| FSCNN | 1024 × 2048 | 1.14 | 72.25 | 6.94 | 62.80 |
| FPENet | 1024 × 2048 | 0.12 | 34.64 | 6.17 | 55.20 |
| FSFNet | 1024 × 2048 | 0.83 | 110.61 | 13.47 | 69.10 |
| NDNet | 1024 × 2048 | 0.38 | 120.00 | 2.01 | 60.60 |
| LASNet(Ours) | 1024 × 2048 | 0.80 | 110.93 | 11.90 | 70.99 |
| Method | Roa | Sid | Bui | Wal | Fen | Pol | Lig | Sig | Veg | Ter |
|---|---|---|---|---|---|---|---|---|---|---|
| ENet | 96.30 | 74.20 | 85.00 | 32.10 | 33.20 | 43.40 | 34.10 | 44.00 | 88.60 | 61.40 |
| ERFNet | 97.71 | 81.00 | 89.80 | 42.50 | 48.00 | 56.20 | 59.80 | 65.31 | 91.40 | 68.20 |
| CGNet | 95.90 | 73.90 | 89.90 | 43.90 | 46.00 | 52.90 | 55.90 | 63.80 | 91.70 | 68.30 |
| ESPNet | 95.70 | 73.30 | 86.60 | 32.80 | 36.40 | 47.00 | 46.90 | 55.40 | 89.80 | 66.00 |
| FSFNet | 97.70 | 81.10 | 90.20 | 41.70 | 47.00 | 54.10 | 61.10 | 65.30 | 91.80 | 69.40 |
| NDNet | 96.60 | 75.20 | 87.20 | 44.20 | 46.10 | 29.60 | 40.40 | 53.30 | 87.40 | 57.90 |
| LASNet | 97.18 | 80.34 | 89.15 | 64.59 | 58.89 | 48.62 | 48.54 | 62.60 | 89.95 | 62.05 |
| Method | Sky | Per | Rid | Car | Tru | Bus | Tra | Mot | Bic | mIoU |
| ENet | 90.60 | 65.50 | 38.40 | 90.60 | 36.90 | 50.50 | 48.10 | 38.80 | 55.40 | 58.30 |
| ERFNet | 94.21 | 76.80 | 57.10 | 92.82 | 50.80 | 60.10 | 51.80 | 47.30 | 61.70 | 68.00 |
| CGNet | 94.10 | 76.70 | 54.20 | 91.30 | 41.30 | 55.90 | 32.80 | 41.10 | 60.90 | 64.80 |
| ESPNet | 92.50 | 68.50 | 45.90 | 89.90 | 40.00 | 47.70 | 40.70 | 36.40 | 54.90 | 60.30 |
| FSFNet | 94.20 | 77.80 | 57.80 | 92.80 | 47.30 | 64.40 | 59.40 | 53.10 | 66.20 | 69.10 |
| NDNet | 90.20 | 62.60 | 41.60 | 88.50 | 57.80 | 67.30 | 35.10 | 31.90 | 59.40 | 60.60 |
| LASNet | 91.84 | 70.83 | 51.38 | 91.10 | 77.39 | 81.72 | 69.22 | 48.02 | 65.84 | 70.99 |
| Module Structure | FPS | Params (M) | FLOPs (G) | mIoU (%) |
|---|---|---|---|---|
| Structure1:base·base·base | 79.06 | 2.27 | 13.36 | 69.65 |
| Structure2:base·LAS-B·LAS-C | 111.58 | 0.85 | 12.15 | 69.86 |
| Structure3:LAS-A·base·LAS-C | 95.03 | 1.24 | 12.65 | 67.51 |
| Structure4:LAS-A·LAS-B·base | 111.54 | 1.78 | 12.36 | 71.39 |
| Structure5:LAS-A·LAS-B·LAS-C | 110.93 | 0.80 | 11.90 | 70.99 |
| Module Numbers | FPS | Params (M) | FLOPs (G) | mIoU (%) |
|---|---|---|---|---|
| LAS-A:2·LAS-B:2·LAS-C:2 | 123.44 | 0.33 | 9.27 | 66.32 |
| LAS-A:3·LAS-B:3·LAS-C:3 | 120.89 | 0.57 | 10.36 | 68.45 |
| LAS-A:5·LAS-B:5·LAS-C:5 | 101.78 | 2.25 | 13.25 | 71.86 |
| LAS-A:6·LAS-B:6·LAS-C:6 | 90.22 | 2.85 | 14.50 | 71.46 |
| LAS-A:3·LAS-B:4·LAS-C:5 | 98.13 | 1.31 | 12.56 | 69.31 |
| LAS-A:5·LAS-B:4·LAS-C:3 | 101.24 | 1.48 | 12.33 | 70.32 |
| LAS-A:4·LAS-B:4·LAS-C:4 | 110.93 | 0.80 | 11.90 | 70.99 |
| Dilation Rates | mIoU (%) |
|---|---|
| Dilation1:LAS-A:(1,1,1,1) LAS-B:(1,1,1,1) LAS-C:(1,1,1,1) | 67.92 |
| Dilation2:LAS-A:(1,2,3,4) LAS-B:(1,2,3,4) LAS-C:(1,2,3,4) | 70.59 |
| Dilation3:LAS-A:(1,2,5,9) LAS-B:(1,2,5,9) LAS-C:(1,2,5,9) | 70.54 |
| Dilation4:LAS-A:(1,2,4,8) LAS-B:(1,2,4,8) LAS-C:(1,2,4,8) | 70.99 |
| Dropout Rates | mIoU (%) |
|---|---|
| Dropout1:LAS-A:(0.00,0.00,0.00,0.00) LAS-B:(0.00,0.00,0.00,0.00) LAS-C:(0.00,0.00,0.00,0.00) | 70.85 |
| Dropout2:LAS-A:(0.01,0.01,0.01,0.01) LAS-B:(0.01,0.01,0.01,0.01) LAS-C:(0.01,0.01,0.01,0.01) | 70.91 |
| Dropout3:LAS-A:(0.01,0.02,0.03,0.04) LAS-B:(0.01,0.02,0.03,0.04) LAS-C:(0.01,0.02,0.03,0.04) | 70.50 |
| Dropout4:LAS-A:(0.01,0.02,0.03,0.04) LAS-B:(0.05,0.06,0.07,0.08) LAS-C:(0.05,0.06,0.07,0.08) | 70.99 |
| Transform | mIoU (%) |
|---|---|
| Not use | 70.84 |
| CBAM | 70.63 |
| Coordinate | 70.47 |
| Triplet | 70.99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Zhan, W.; Jiang, Y.; Zhu, D.; Guo, R.; Xu, X. LASNet: A Light-Weight Asymmetric Spatial Feature Network for Real-Time Semantic Segmentation. Electronics 2022, 11, 3238. https://doi.org/10.3390/electronics11193238
Chen Y, Zhan W, Jiang Y, Zhu D, Guo R, Xu X. LASNet: A Light-Weight Asymmetric Spatial Feature Network for Real-Time Semantic Segmentation. Electronics. 2022; 11(19):3238. https://doi.org/10.3390/electronics11193238
Chicago/Turabian StyleChen, Yu, Weida Zhan, Yichun Jiang, Depeng Zhu, Renzhong Guo, and Xiaoyu Xu. 2022. "LASNet: A Light-Weight Asymmetric Spatial Feature Network for Real-Time Semantic Segmentation" Electronics 11, no. 19: 3238. https://doi.org/10.3390/electronics11193238
APA StyleChen, Y., Zhan, W., Jiang, Y., Zhu, D., Guo, R., & Xu, X. (2022). LASNet: A Light-Weight Asymmetric Spatial Feature Network for Real-Time Semantic Segmentation. Electronics, 11(19), 3238. https://doi.org/10.3390/electronics11193238