
Improved YOLOv3 Model for Workpiece Stud Leakage Detection
Abstract
:1. Introduction
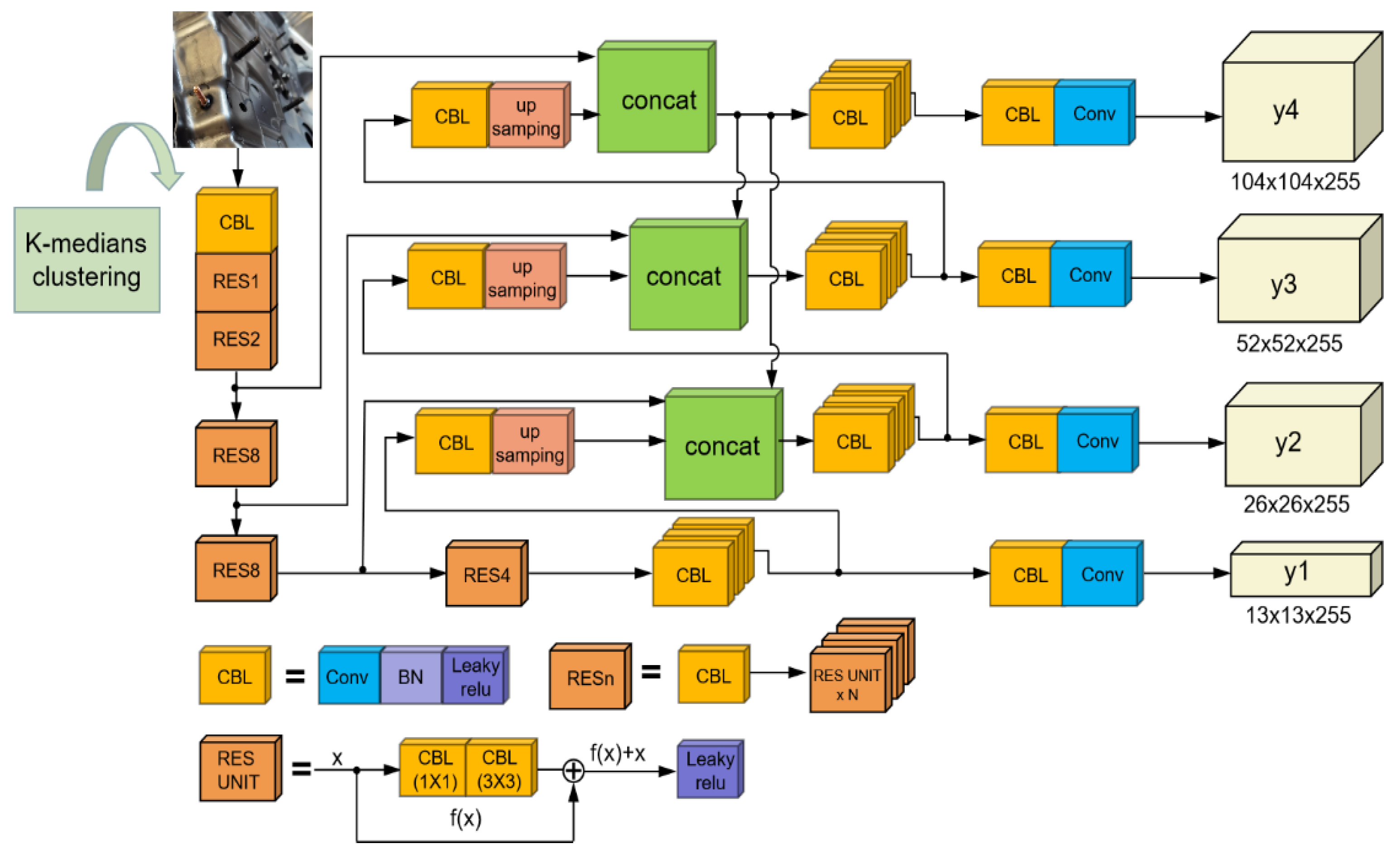
- In this study, the layer in the prediction model are increased from three to four to more precisely anticipate the workpiece location of the stud. The image pyramid structure is employed to gather stud feature information at various scales, and shallow feature fusion is trained at different sizes to obtain additional stud contour details.
- The positive and negative sample imbalance problem will reduce the model’s training efficiency and detection accuracy, and it is resolved in this study using the focal loss function. The focal loss function can decrease the weight of the straightforward background classes, allowing the algorithm to concentrate more on detecting the foreground classes and increasing the detection accuracy of studs.
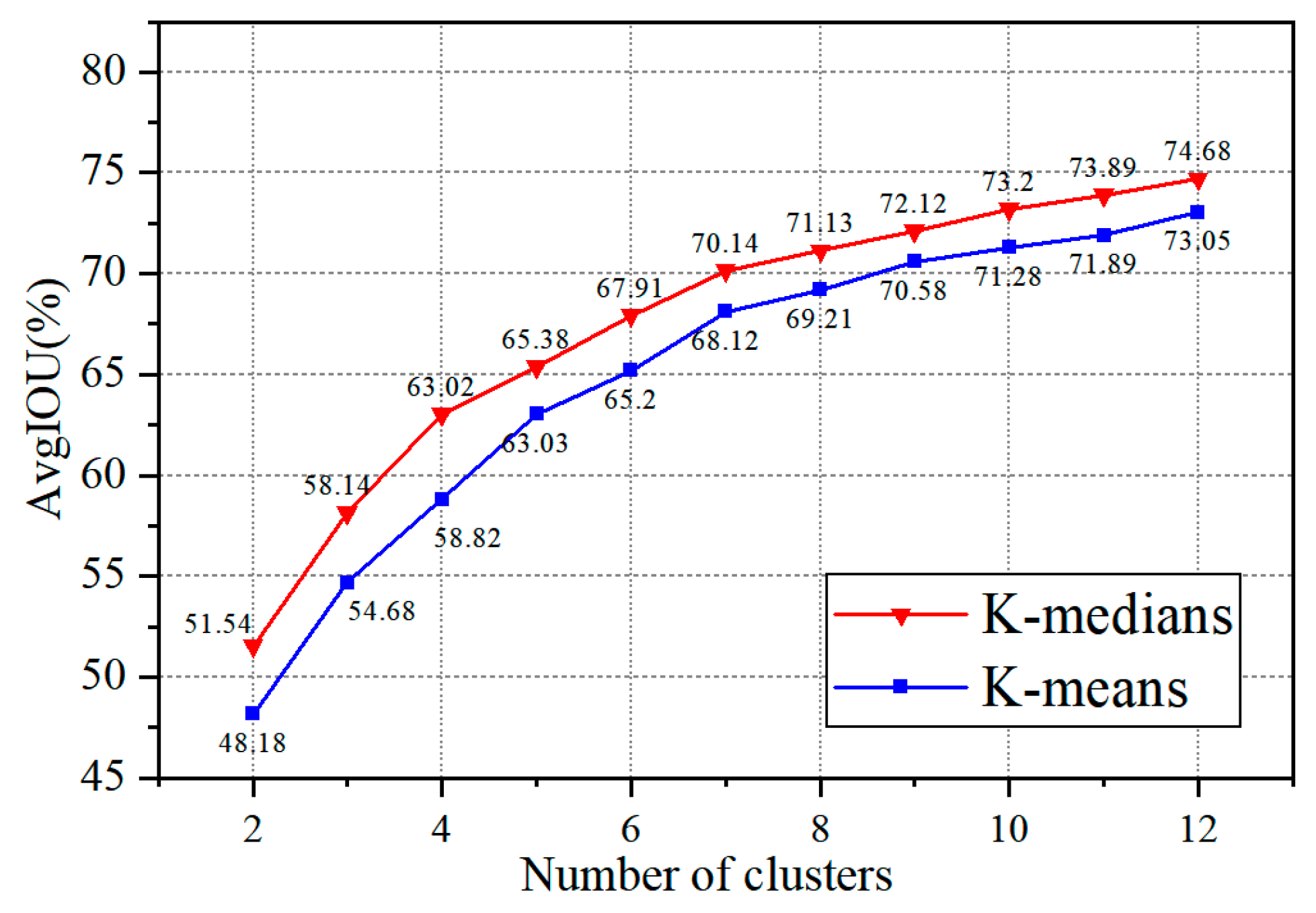
- A median-based approach is used to solve the problem that the model’s K-means clustering algorithm [18] is sensitive to the initial cluster centers and outliers. The K-medians approach is robust to noisy points or outliers, avoiding the model falling into a local optimum and thus improving the accuracy of the model for stud detection.
2. Improved YOLOv3 Model
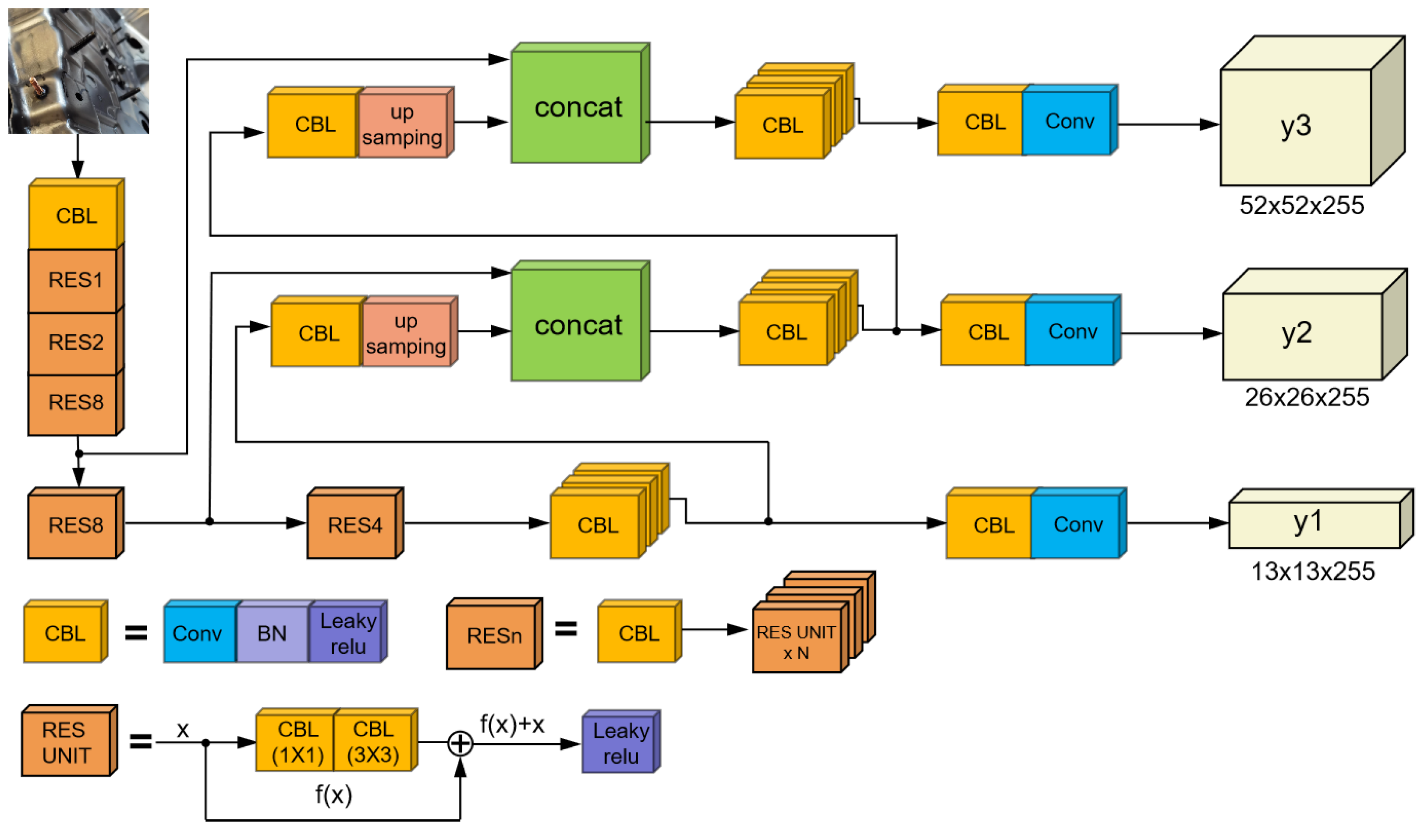
2.1. Framework of the YOLOv3 Model
2.1.1. Backbone Network of YOLOv3
2.1.2. FPN
2.1.3. Residual Networks
2.2. Methods for Improving the YOLOv3 Model
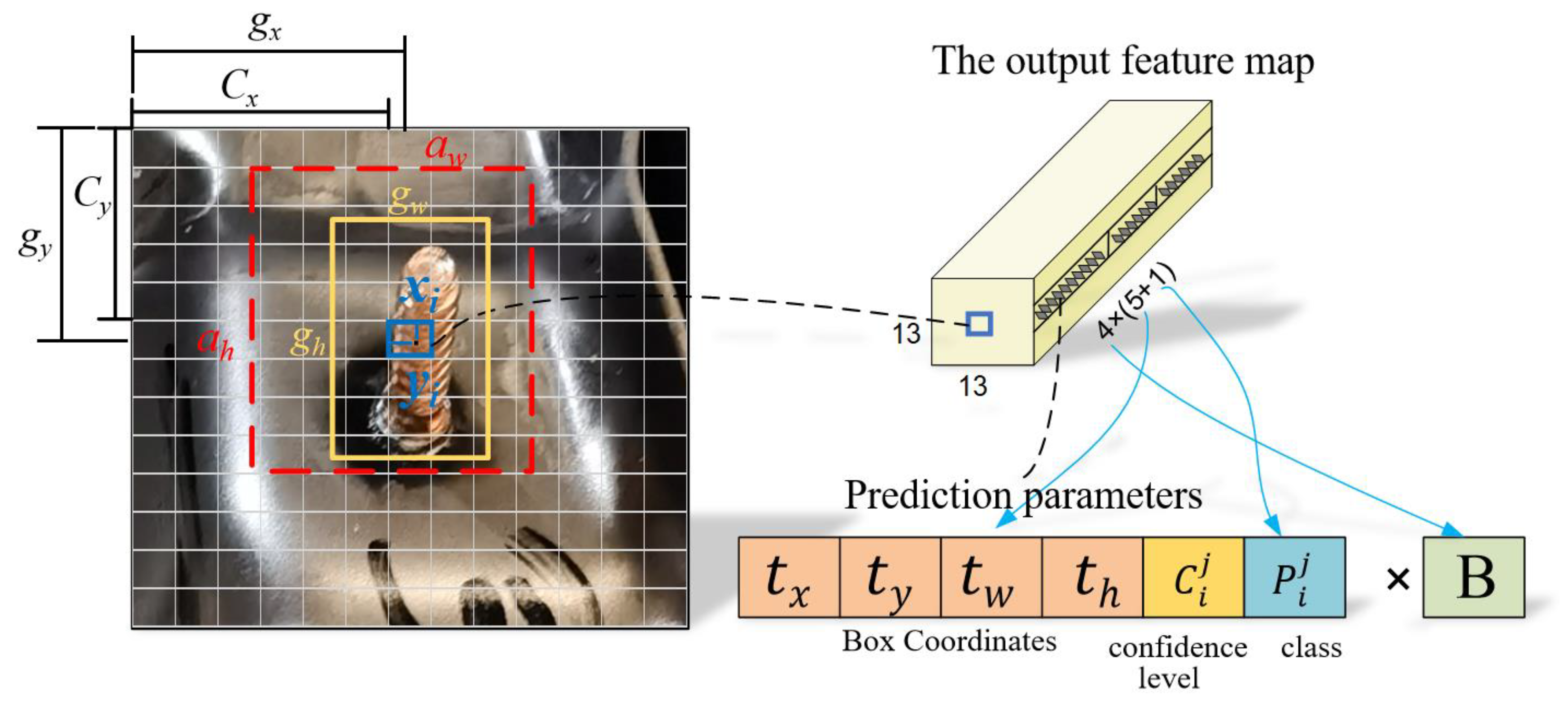
2.2.1. Multiscale Training and Multiscale Prediction
2.2.2. Improving the Loss Function of YOLOv3
2.2.3. Improved Clustering Algorithm
2.2.4. Optimized Convolution Units
3. Experiments and Results
3.1. Stud Dataset
3.2. Details of the Implementation
3.3. Evaluation Methods
3.4. Experimental Results and Analysis
3.4.1. Anchor Box Optimization Experiments
3.4.2. Ablation Experiments
3.4.3. Experimental Analysis of Different Models
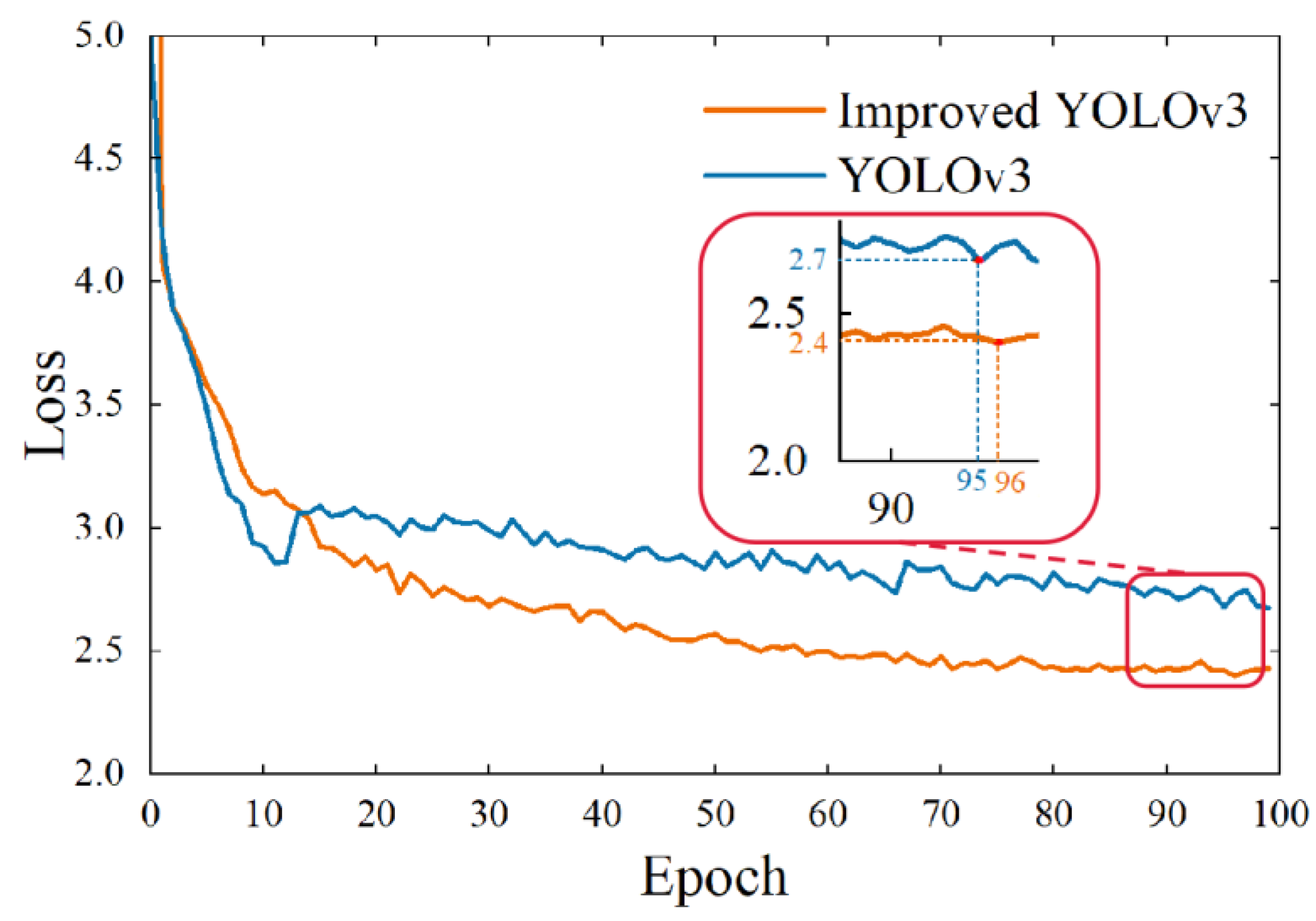
3.4.4. Analysis of the Experimental Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmad, H.M.; Rahimi, A. Deep learning methods for object detection in smart manufacturing: A survey. J. Manuf. Syst. 2022, 64, 181–196. [Google Scholar] [CrossRef]
- Auerswald, M.M.; von Freyberg, A.; Fischer, A. Laser line triangulation for fast 3D measurements on large gears. Int. J. Adv. Manuf. Technol. 2019, 100, 2423–2433. [Google Scholar] [CrossRef]
- Li, J.; Zhou, Q.; Li, X.; Chen, R.; Ni, K. An improved low-noise processing methodology combined with PCL for industry inspection based on laser line scanner. Sensors 2019, 19, 3398. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Xu, C.; Hao, J.; Xiao, D.; Yang, W. Ultrasonic non-destructive testing system of semi-enclosed workpiece with dual-robot testing system. Sensors 2019, 19, 3359. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.; Chang, L.-M.; Skibniewski, M. Automated recognition of surface defects using digital color image processing. Autom. Constr. 2006, 15, 540–549. [Google Scholar] [CrossRef]
- Kumar, J.; Srivastava, S.; Anand, R.S.; Arvind, P.; Bhardwaj, S.; Thakur, A. GLCM and ANN based approach for classification of radiographics weld images. In Proceedings of the 2018 IEEE 13th International Conference on Industrial and Information Systems (ICIIS), Rupnagar, India, 1–2 December 2018; pp. 168–172. [Google Scholar]
- Zhang, J.; Guo, Z.; Jiao, T.; Wang, M. Defect detection of aluminum alloy wheels in radiography images using adaptive threshold and morphological reconstruction. Appl. Sci. 2018, 8, 2365. [Google Scholar] [CrossRef] [Green Version]
- Shi, T.; Kong, J.Y.; Wang, X.D.; Liu, Z.; Zheng, G. Improved Sobel algorithm for defect detection of rail surfaces with enhanced efficiency and accuracy. J. Cent. South Univ. 2016, 23, 2867–2875. [Google Scholar] [CrossRef]
- Hazarika, A.; Sistla, P.; Venkatesh, V.; Choudhury, N. Approximating CNN computation for plant disease detection. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 1117–1122. [Google Scholar]
- Li, J.; Chen, Y.Q.; Li, W.Y.; Gu, J.A. Balanced-YOLOv3: Addressing the imbalance problem of object detection in PCB assembly scene. Electronics 2022, 11, 1183. [Google Scholar] [CrossRef]
- Liu, B.L.; Luo, H.; Wang, H.T.; Wang, S.X. YOLOv3_ReSAM: A small-target detection method. Electronics 2022, 11, 1635. [Google Scholar] [CrossRef]
- Liu, H.; Yan, Y.; Song, K.; Chen, H.; Yu, H. Efficient optical measurement of welding studs with normal maps and convolutional neural Network. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.L.; Wang, X.G.; Fieguth, P.; Chen, J.; Liu, X.W.; Pietikainen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, K.; Wang, Y.; Zhang, S.; Zhang, J.; Sun, S. Automatic label welding robot system for bundled rebars. IEEE Access 2021, 9, 160072–160084. [Google Scholar] [CrossRef]
- Zhong, S.; Xu, W.; Zhang, T.; Chen, H. Identification and depth localization of clustered pod pepper based on improved Faster R-CNN. IEEE Access 2022, 10, 93615–93625. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Chang, L.A.; Chen, Y.T.; Wang, J.H.; Chang, Y.L. Modified YOLOv3 for ship detection with visible and infrared images. Electronics 2022, 11, 739. [Google Scholar] [CrossRef]
- Li, H.; Liu, L.Z.; Du, J.; Jiang, F.; Guo, F.; Hu, Q.L.; Fan, L. An improved YOLOv3 for foreign objects detection of transmission lines. IEEE Access 2022, 10, 45620–45628. [Google Scholar] [CrossRef]
- Chen, X.; Lv, J.; Fang, Y.; Du, S. Online detection of surface defects based on improved YOLOV3. Sensors 2022, 22, 817. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digital Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Chen, L.; Xiong, W.; Yang, S.; Zhang, Z. Research on Recognition Technology of Transformer Oil Leakage Based on Improved YOLOv3. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020; pp. 454–458. [Google Scholar]
- Chen, L.; Zhou, Y.; Zhou, H.; Zu, J. Detection of Polarizer Surface Defects Based on an Improved Lightweight YOLOv3 Model. In Proceedings of the 2022 4th International Conference on Intelligent Control, Measurement and Signal Processing (ICMSP), Hangzhou, China, 8–10 July 2022; pp. 138–142. [Google Scholar]
- Arvind, C.S.; Aditya, K.; Keerthan, H.S.; Farhan, M.; Asha, K.N.; Patil, S.S. Non-Invasive Multistage Fruit Grading Application with User Recommendation system. In Proceedings of the 2022 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 8–10 July 2022; pp. 1–6. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 770–778. [Google Scholar]
- de Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, Honolulu, HI, USA, 22–25 July 2017; pp. 2980–2988. [Google Scholar]
- Daogang, P.; Ming, G.; Danhao, W.; Jie, H. Anomaly identification of critical power plant facilities based on YOLOX-CBAM. In Proceedings of the 2022 Power System and Green Energy Conference (PSGEC), Shanghai, China, 25–27 August 2022; pp. 649–653. [Google Scholar]
- Cuellar, A.; Mahalanobis, A. Detection of small moving targets in cluttered infra-red imagery. IEEE Trans. Aerosp. Electron. Syst. 2022, AES-1, 1–19. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Fey, M.; Lenssen, J.E. Fast graph representation learning with PyTorch Geometric. arXiv 2019, arXiv:1903.02428. [Google Scholar]
- Liu, M.; Tang, L.; Li, Z. Real-Time object detection in UAV vision based on neural processing units. In Proceedings of the 2022 IEEE 6th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 4–6 March 2022; Volume 6, pp. 1951–1955. [Google Scholar]
- Yue, X.; Li, H.; Shimizu, M.; Kawamura, S.; Meng, L. YOLO-GD: A deep learning-based object detection algorithm for rmpty-dish recycling robots. Machines 2022, 10, 294. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 21–37.
- Haixia, M.; Zhongxing, L.; Na, S.; Zhe, Z. Research on defect identification of key components of transmission line based on deep learning. In Proceedings of the 2022 Power System and Green Energy Conference (PSGEC), Shanghai, China, 25–27 August 2022; pp. 969–973. [Google Scholar]
- Liu, C.Y.; Wu, Y.Q.; Liu, J.J.; Sun, Z. Improved YOLOv3 network for insulator detection in aerial images with diverse background interference. Electronics 2021, 10, 771. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| CPU | Intel Core 10,900 |
| GPU | NVIDIA RTX 3090 ti 24 G |
| RAM | 32 G |
| Operating system | Windows 10 |
| Algorithm | Image Size | Batch Size | Momentum | Learning Rate | Decay |
|---|---|---|---|---|---|
| Improved YOLOv3 | 608 × 608 | 16 | 0.9 | 0.001 | 0.0005 |
| Algorithm | K | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | |
| K-means | 48.18 | 54.68 | 58.85 | 63.03 | 65.20 | 68.12 | 69.21 | 70.58 | 71.28 | 71.89 | 73.05 |
| K-medians | 51.34 | 58.14 | 63.02 | 65.38 | 67.91 | 70.14 | 71.13 | 72.12 | 73.20 | 73.89 | 74.68 |
| Model | Multiscale | K-Medians | Focal Loss | Average Precision (AP @ 0.5) (%) | mAP (%) | |
|---|---|---|---|---|---|---|
| Hexagonal Stud | Headless Stud | |||||
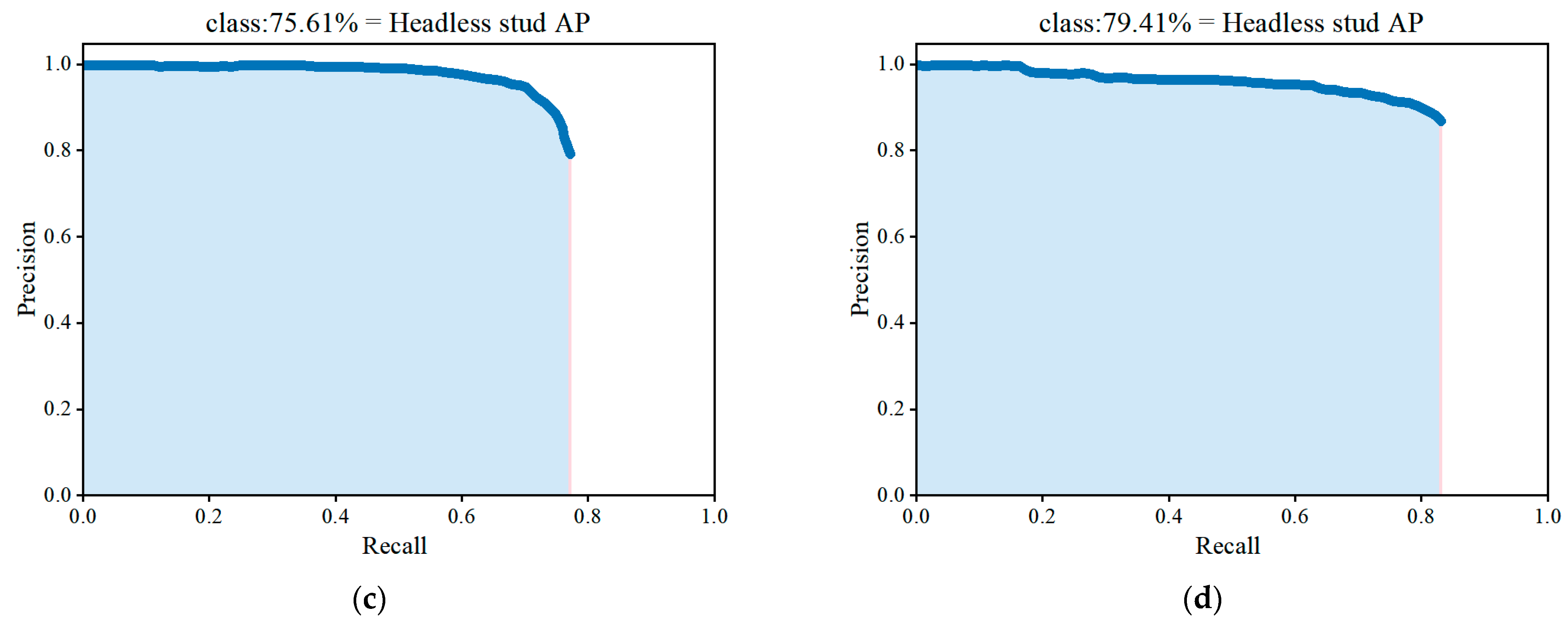
| YOLOv3 | × | × | × | 78.70 | 75.61 | 77.16 |
| YOLOv3 + S | √ | × | × | 79.91 | 78.65 | 79.28 |
| YOLOv3 + K | × | √ | × | 79.52 | 75.91 | 77.72 |
| YOLOv3 + F | × | × | √ | 79.72 | 76.64 | 78.18 |
| YOLOv3 + S + K | √ | √ | × | 80.51 | 79.01 | 79.76 |
| YOLOv3 + S +F | √ | × | √ | 80.76 | 79.24 | 80.00 |
| Improved YOLOv3 | √ | √ | √ | 81.42 | 79.41 | 80.42 |
| Model | Average Precision (AP @ 0.5) (%) | mAP (%) | Detection Speed (s) | |
|---|---|---|---|---|
| Hexagonal Stud | Headless Stud | |||
| DPM | 70.53 | 54.62 | 62.58 | 0.61 |
| R-CNN | 50.25 | 39.06 | 44.67 | - - |
| Faster R-CNN | 73.51 | 70.39 | 71.95 | 0.86 |
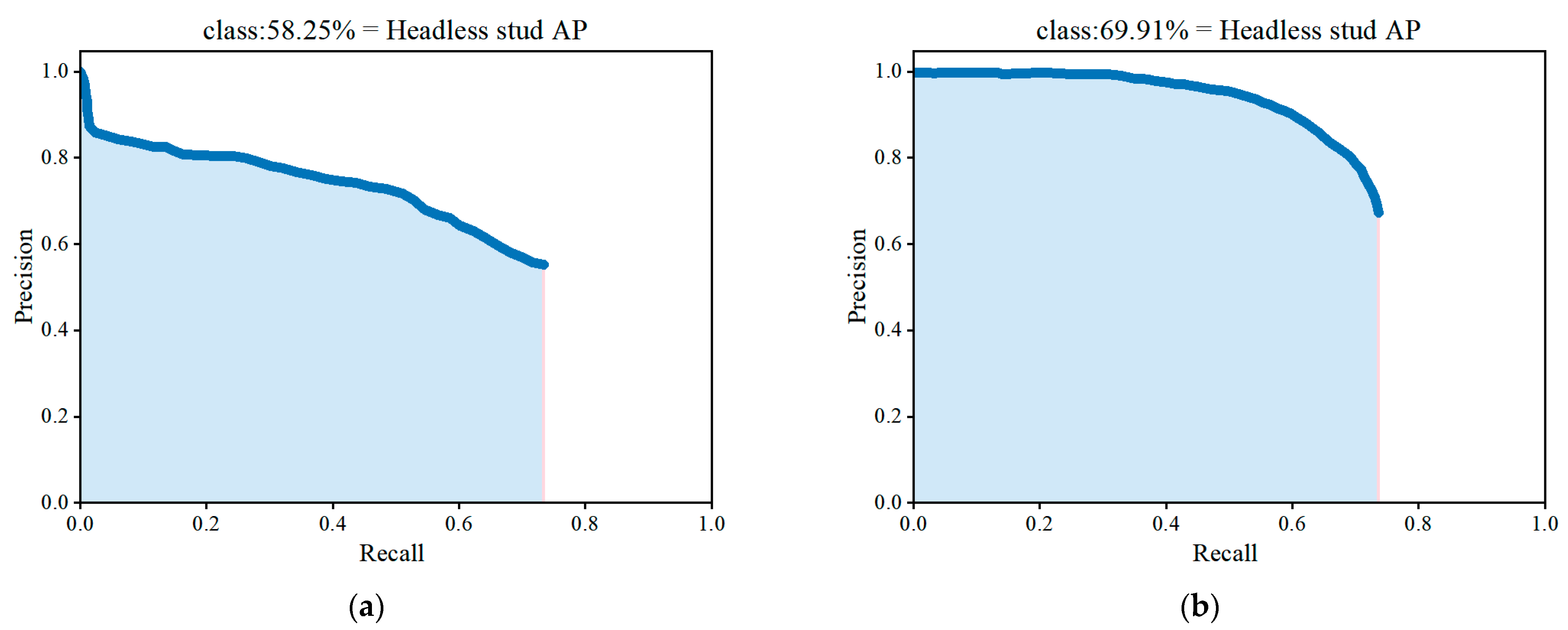
| SSD | 67.21 | 58.25 | 62.73 | 0.42 |
| YOLOv3 | 78.70 | 75.61 | 77.16 | 0.27 |
| Improved YOLOv3 | 81.42 | 79.41 | 80.42 | 0.32 |
| Model | Precision (%) | Recall (%) | AP (%) | F1 (%) |
|---|---|---|---|---|
| Faster R-CNN | 81.24 | 68.32 | 70.39 | 74.22 |
| SSD | 55.18 | 67.65 | 58.25 | 60.78 |
| YOLOv3 | 88.34 | 74.91 | 75.61 | 81.07 |
| Improved YOLOv3 | 89.20 | 81.07 | 79.41 | 84.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cong, P.; Lv, K.; Feng, H.; Zhou, J. Improved YOLOv3 Model for Workpiece Stud Leakage Detection. Electronics 2022, 11, 3430. https://doi.org/10.3390/electronics11213430
Cong P, Lv K, Feng H, Zhou J. Improved YOLOv3 Model for Workpiece Stud Leakage Detection. Electronics. 2022; 11(21):3430. https://doi.org/10.3390/electronics11213430
Chicago/Turabian StyleCong, Peichao, Kunfeng Lv, Hao Feng, and Jiachao Zhou. 2022. "Improved YOLOv3 Model for Workpiece Stud Leakage Detection" Electronics 11, no. 21: 3430. https://doi.org/10.3390/electronics11213430
APA StyleCong, P., Lv, K., Feng, H., & Zhou, J. (2022). Improved YOLOv3 Model for Workpiece Stud Leakage Detection. Electronics, 11(21), 3430. https://doi.org/10.3390/electronics11213430