
P1OVD: Patch-Based 1-Day Out-of-Bounds Vulnerabilities Detection Tool for Downstream Binaries




Abstract
:1. Introduction
- We design an out-of-bounds vulnerability signature that mainly contains patch information and vulnerability information.
- We propose a matching algorithm that can accurately and robustly find the patch signatures in downstream binaries.
- We propose a patch-based out-of-bounds vulnerability detection method, P1OVD. P1OVD can accurately locate 1-day out-of-bounds vulnerabilities in downstream binaries even if code variants exist. We evaluate its performance on 620 binaries of 30 real-world patches in Linux Kernel [21].
2. Motivation
2.1. Vulnerability Signature
2.2. Patch Signature Matching
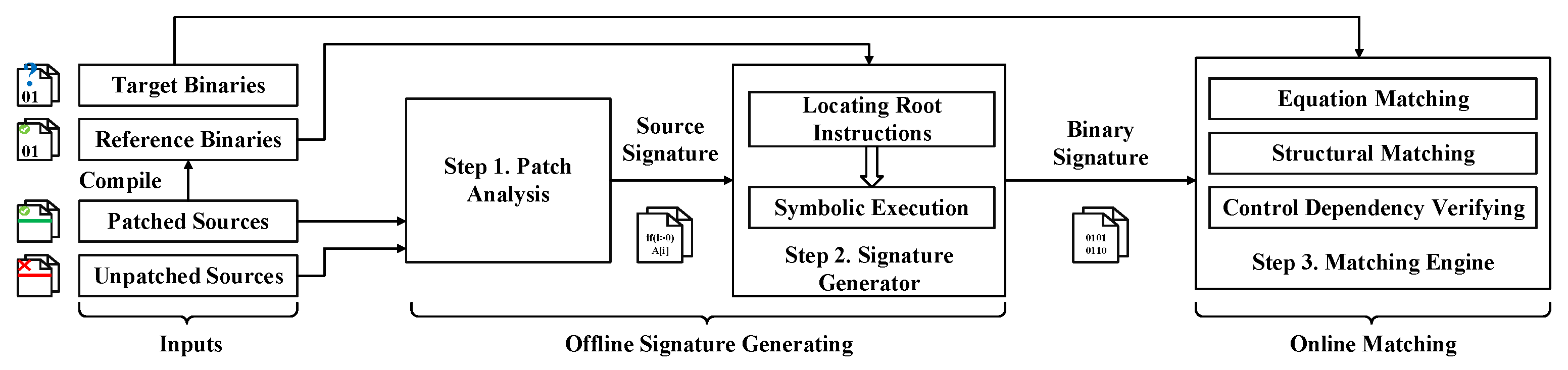
3. Design of P1OVD
3.1. System Architecture
3.2. Patch Analysis
3.3. Binary Signature Generator
3.3.1. Root Instructions Locating
3.3.2. Symbolic Execution
3.4. Matching Engine
3.4.1. Structural Matching
3.4.2. Equation Matching
3.4.3. Verify Control Dependency
- A is a loop statement. The loop structure is often reordered by optimization, and P1OVD requires every trace that passes the B twice or more to contain an A between every neighbor B.
- A is an if statement. Since the if statement may be in a loop, P1OVD requires each trace that reaches the B from the function entry to pass A.
4. Evaluation
4.1. Datasets
4.1.1. Source Codes
4.1.2. Reference Binaries
4.1.3. Target Binaries
4.2. Accuracy
4.2.1. Function Inline
4.2.2. Conditional Execution Instructions
4.2.3. Simplified Expression
4.2.4. Structure Dissimilar
4.3. Performance
4.4. Accuracy Comparison with Vulnerability Detection Tools
4.5. Effectiveness of Vulnerability Signatures
4.6. Effectiveness of Two-Step AST Matching Algorithm
4.7. Limitation
5. Related Work
5.1. Function-Level 1-Day Vulnerability Detection
5.2. Patch-Level 1-Day Vulnerability Detection
5.3. Patch Presence Test
5.4. Patch Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AST | Abstract Syntax Tree |
| PDG | Program Dependency Graph |
| PSW | Program Status Word |
| CFG | Control Flow Graph |
| POC | Proof of Concepts |
References
- Peng, J.; Li, F.; Liu, B.; Xu, L.; Liu, B.; Chen, K.; Huo, W. 1dVul: Discovering 1-Day Vulnerabilities through Binary Patches. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 605–616. [Google Scholar] [CrossRef]
- Insights into the 2.3 Billion Android Smartphones in Use Around the World. Available online: https://newzoo.com/insights/articles/insights-into-the-2-3-billion-android-smartphones-in-use-around-the-world/ (accessed on 12 December 2021).
- Jang, J.; Agrawal, A.; Brumley, D. ReDeBug: Finding unpatched code clones in entire os distributions. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 48–62. [Google Scholar]
- Pham, N.H.; Nguyen, T.T.; Nguyen, H.A.; Nguyen, T.N. Detection of recurring software vulnerabilities. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering, New York, NY, USA, 20–24 September 2010; pp. 447–456. [Google Scholar]
- Yamaguchi, F.; Lottmann, M.; Rieck, K. Generalized vulnerability extrapolation using abstract syntax trees. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; pp. 359–368. [Google Scholar]
- Zou, D.; Qi, H.; Li, Z.; Wu, S.; Jin, H.; Sun, G.; Wang, S.; Zhong, Y. SCVD: A New Semantics-Based Approach for Cloned Vulnerable Code Detection. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Bonn, Germany, 6–7 July 2017; pp. 325–344. [Google Scholar]
- Kim, S.; Woo, S.; Lee, H.; Oh, H. Vuddy: A scalable approach for vulnerable code clone discovery. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 595–614. [Google Scholar]
- Pewny, J.; Schuster, F.; Bernhard, L.; Holz, T.; Rossow, C. Leveraging semantic signatures for bug search in binary programs. In Proceedings of the 30th Annual Computer Security Applications Conference, New Orleans, LA, USA, 8–12 December 2014; pp. 406–415. [Google Scholar]
- Pewny, J.; Garmany, B.; Gawlik, R.; Rossow, C.; Holz, T. Cross-architecture bug search in binary executables. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 17–21 May 2015; pp. 709–724. [Google Scholar]
- Eschweiler, S.; Yakdan, K.; Gerhards-Padilla, E. discovRE: Efficient Cross-Architecture Identification of Bugs in Binary Code. In Proceedings of the NDSS, San Diego, CA, USA, 21–24 February 2016; pp. 58–79. [Google Scholar]
- Feng, Q.; Zhou, R.; Xu, C.; Cheng, Y.; Testa, B.; Yin, H. Scalable graph-based bug search for firmware images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 480–491. [Google Scholar]
- Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; Song, D. Neural network-based graph embedding for cross-platform binary code similarity detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 363–376. [Google Scholar]
- Feng, Q.; Wang, M.; Zhang, M.; Zhou, R.; Henderson, A.; Yin, H. Extracting conditional formulas for cross-platform bug search. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 346–359. [Google Scholar]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Sun, J. VulSeeker: A semantic learning based vulnerability seeker for cross-platform binary. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 896–899. [Google Scholar]
- Liu, B.; Huo, W.; Zhang, C.; Li, W.; Li, F.; Piao, A.; Zou, W. αdiff: Cross-version binary code similarity detection with dnn. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 667–678. [Google Scholar]
- Ding, S.H.; Fung, B.C.; Charland, P. Asm2vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 472–489. [Google Scholar]
- Xu, Y.; Xu, Z.; Chen, B.; Song, F.; Liu, Y.; Liu, T. Patch based vulnerability matching for binary programs. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event, USA, 18–22 July 2020; pp. 376–387. [Google Scholar]
- Xiao, Y.; Chen, B.; Yu, C.; Xu, Z.; Yuan, Z.; Li, F.; Liu, B.; Liu, Y.; Huo, W.; Zou, W.; et al. MVP: Detecting Vulnerabilities Using Patch-Enhanced Vulnerability Signatures. Available online: https://chenbihuan.github.io/paper/sec20-xiao-mvp.pdf (accessed on 12 December 2021).
- Jiang, Z.; Zhang, Y.; Xu, J.; Wen, Q.; Wang, Z.; Zhang, X.; Xing, X.; Yang, M.; Yang, Z. PDiff: Semantic-based Patch Presence Testing for Downstream Kernels. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, USA, 9–13 November 2020; pp. 1149–1163. [Google Scholar]
- Zhang, H.; Qian, Z. Precise and accurate patch presence test for binaries. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 887–902. [Google Scholar]
- Linux Kernel. Available online: https://github.com/torvalds/linux (accessed on 12 December 2021).
- Wu, Q.; He, Y.; McCamant, S.; Lu, K. Precisely characterizing security impact in a flood of patches via symbolic rule comparison. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Z3Prover/z3: The Z3 Theorem Prover. Available online: https://github.com/Z3Prover/z3 (accessed on 12 December 2021).
- Shoshitaishvili, Y.; Wang, R.; Salls, C.; Stephens, N.; Polino, M.; Dutcher, A.; Grosen, J.; Feng, S.; Hauser, C.; Kruegel, C.; et al. SoK: (State of) The Art of War: Offensive Techniques in Binary Analysis. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016. [Google Scholar]
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and discovering vulnerabilities with code property graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 590–604. [Google Scholar]
- Parsing ELF and DWARF in Python. Available online: https://github.com/eliben/pyelftools (accessed on 12 December 2021).
- Hall, C. Survey Shows Linux the Top Operating System for Internet of Things Devices. Available online: https://www.itprotoday.com/iot/survey-shows-linux-top-operating-system-internet-things-devices (accessed on 12 December 2021).
- Zhao, L.; Zhu, Y.; Ming, J.; Zhang, Y.; Zhang, H.; Yin, H. Patchscope: Memory object centric patch diffing. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, USA, 9–13 November 2020; pp. 149–165. [Google Scholar]
- Chandramohan, M.; Xue, Y.; Xu, Z.; Liu, Y.; Cho, C.Y.; Tan, H.B.K. Bingo: Cross-architecture cross-os binary search. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; pp. 678–689. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Qi, H.; Hu, J. VulPecker: An automated vulnerability detection system based on code similarity analysis. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Los Angeles, CA, USA, 5–9 December 2016; pp. 201–213. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Li, H.; Kwon, H.; Kwon, J.; Lee, H. A scalable approach for vulnerability discovery based on security patches. In Proceedings of the International Conference on Applications and Techniques in Information Security, Melbourne, Australia, 26–28 November 2014; pp. 109–122. [Google Scholar]
- Dai, J.; Zhang, Y.; Jiang, Z.; Zhou, Y.; Chen, J.; Xing, X.; Zhang, X.; Tan, X.; Yang, M.; Yang, Z. BScout: Direct Whole Patch Presence Test for Java Executables. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1147–1164. [Google Scholar]
- Sun, P.; Garcia, L.; Salles-Loustau, G.; Zonouz, S. Hybrid firmware analysis for known mobile and iot security vulnerabilities. In Proceedings of the 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Valencia, Spain, 29 June–2 July 2020; pp. 373–384. [Google Scholar]
- Corley, C.S.; Kraft, N.A.; Etzkorn, L.H.; Lukins, S.K. Recovering traceability links between source code and fixed bugs via patch analysis. In Proceedings of the 6th International Workshop on Traceability in Emerging Forms of Software Engineering, Waikiki, HI, USA, 23 May 2011; pp. 31–37. [Google Scholar]
- Xu, Z.; Chen, B.; Chandramohan, M.; Liu, Y.; Song, F. Spain: Security patch analysis for binaries towards understanding the pain and pills. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 462–472. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statement | Root Instruction Type | AST |
|---|---|---|
| Bound Check | Branching Instruction | Branching Condition |
| Memory Access (Call Function) | Function Call Instruction | Access Expression (Callee and All Function Arguments) |
| Memory Access (Index Array) | Load or Store Instruction | Access Expression (Memory Adress) |
| Extra Branching Satement | Branching Instruction | PSW Write Arguments |
| Compilation Environment | Recall | Precision | F-1 Score | Accuracy | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NV | V | P | NV | V | P | NV | V | P | |||
| O0 | aarch64 | 100.00% | 84.09% | 86.00% | 45.45% | 100.00% | 97.73% | 0.62 | 0.91 | 0.91 | 86.54% |
| x86_64 | 80.00% | 95.45% | 100.00% | 88.89% | 95.45% | 98.00% | 0.84 | 0.95 | 0.99 | 96.12% | |
| x86_32 | 80.00% | 63.64% | 79.59% | 80.00% | 100.00% | 97.50% | 0.80 | 0.78 | 0.88 | 72.82% | |
| O2 | aarch64 | 100.00% | 84.09% | 80.00% | 47.62% | 90.24% | 97.56% | 0.65 | 0.87 | 0.88 | 83.65% |
| x86_64 | 80.00% | 86.36% | 95.92% | 80.00% | 97.44% | 97.92% | 0.80 | 0.92 | 0.97 | 90.29% | |
| x86_32 | 80.00% | 61.36% | 73.47% | 66.67% | 93.10% | 97.30% | 0.73 | 0.74 | 0.84 | 68.93% | |
| All | 86.67% | 79.17% | 85.81% | 61.90% | 95.87% | 97.69% | 0.72 | 0.87 | 0.91 | 83.06% | |
| Step | Total Time | Number | Average | |
|---|---|---|---|---|
| Offline | Patch Analyze | 470.68 s | 30 | 15.69 s |
| Signature Generate | 99.90 s | 30 | 3.33 s | |
| Online | Match | 108.07 s | 30 | 3.60 s |
| Tool | Compilation Environment | Recall | Precision | F1-score | Accuracy | ||||
|---|---|---|---|---|---|---|---|---|---|
| Not Vulnerable | Vulnerable | Not Vulnerable | Vulnerable | Not Vulnerable | Vulnerable | ||||
| P1OVD (Graph Similarity) | O0 | aarch64 | 60.00% | 84.09% | 83.72% | 61.67% | 0.70 | 0.71 | 70.19% |
| x86_64 | 50.85% | 95.45% | 93.75% | 59.15% | 0.66 | 0.73 | 69.90% | ||
| x86_32 | 52.54% | 63.64% | 93.94% | 62.22% | 0.67 | 0.63 | 57.28% | ||
| O2 | aarch64 | 56.67% | 84.09% | 85.00% | 58.73% | 0.68 | 0.69 | 68.27% | |
| x86_64 | 49.15% | 86.36% | 93.55% | 57.58% | 0.64 | 0.69 | 65.05% | ||
| x86_32 | 50.85% | 61.36% | 90.91% | 60.00% | 0.65 | 0.61 | 55.34% | ||
| P1OVD (Two Step) | O0 | aarch64 | 98.33% | 84.09% | 89.39% | 100.00% | 0.94 | 0.91 | 92.31% |
| x86_64 | 96.61% | 95.45% | 96.61% | 95.45% | 0.97 | 0.95 | 96.12% | ||
| x86_32 | 81.36% | 63.64% | 96.00% | 100.00% | 0.88 | 0.78 | 73.79% | ||
| O2 | aarch64 | 93.33% | 84.09% | 90.32% | 90.24% | 0.92 | 0.87 | 89.42% | |
| x86_64 | 94.92% | 86.36% | 96.55% | 97.44% | 0.96 | 0.92 | 91.26% | ||
| x86_32 | 77.97% | 61.36% | 93.88% | 93.10% | 0.85 | 0.74 | 70.87% | ||
| BinXray | O0 | x86_64 | 81.36% | 95.45% | 100.00% | 84.00% | 0.90 | 0.89 | 87.38% |
| Asm2Vec | O0 | x86_64 | 5.08% | 95.45% | 60.00% | 42.86% | 0.09 | 0.59 | 43.69% |
| O2 | x86_64 | 16.95% | 79.55% | 52.63% | 41.67% | 0.26 | 0.55 | 43.69% | |
| P1OVD | ReDeBug | |
|---|---|---|
| Bound Check Coverage | 100% | 100% |
| Memory Access Coverage | 100% | 50.94% |
| Used Lines | 2.80 | 6.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; He, D.; Zhu, X.; Chan, S. P1OVD: Patch-Based 1-Day Out-of-Bounds Vulnerabilities Detection Tool for Downstream Binaries. Electronics 2022, 11, 260. https://doi.org/10.3390/electronics11020260
Li H, He D, Zhu X, Chan S. P1OVD: Patch-Based 1-Day Out-of-Bounds Vulnerabilities Detection Tool for Downstream Binaries. Electronics. 2022; 11(2):260. https://doi.org/10.3390/electronics11020260
Chicago/Turabian StyleLi, Hongyi, Daojing He, Xiaogang Zhu, and Sammy Chan. 2022. "P1OVD: Patch-Based 1-Day Out-of-Bounds Vulnerabilities Detection Tool for Downstream Binaries" Electronics 11, no. 2: 260. https://doi.org/10.3390/electronics11020260
APA StyleLi, H., He, D., Zhu, X., & Chan, S. (2022). P1OVD: Patch-Based 1-Day Out-of-Bounds Vulnerabilities Detection Tool for Downstream Binaries. Electronics, 11(2), 260. https://doi.org/10.3390/electronics11020260