1. Introduction
With a sharp increase in data and large amounts of connection, communication networks are under unprecedented pressure. The fifth-generation mobile communication system (5G) is expected to support higher requirements and more scenarios [
1].
Among all the technologies of 5G, novel multiple-access methods allow multiple users to transmit signals over the same time-frequency resource, which greatly improves the spectral efficiency [
2]. Sparse code multiple access (SCMA) is a non-orthogonal multiple-access (NOMA) technology in the code domain that combines symbol mapping and spreading using multi-dimensional codebooks. Benefiting from its sparsity, the detection of multiple users becomes possible in massive machine type of communication (mMTC) [
3,
4].
For SCMA, a message-passing algorithm (MPA) is thought of as a basic detection method. It is an improvement on the maximum a posteriori (MAP), which iterates the edge probability without exhaustion of all combinations of codewords [
5]. Now, more superior methods have been proposed. The authors of [
6] proposed a (RRL) detector, which updates the function nodes only within a restricted search region and reduces the targeting points. In [
7], a novel fixed low-complexity detector for an uplink SCMA system was proposed based on partial marginalization. Ref. [
8] studied an improved sphere decoding for SCMA that achieves the optimal maximum likelihood detector for any arbitrary regular or irregular constellations. In [
9], a generalized sphere-coding SCMA was proposed where sorted QR decomposition and Schnorr–Euchner enumeration are applied. Ref. [
10] compared MAX-Log-MPA and Log-MPA, which aim to reduce the exponential operations. A deterministic message-passing algorithm in [
11] utilized algorithmic simplifications for SCMA decoding, such as domain changing and probability approximation. The authors in [
12] proved that serial scheduling-based MPA can reach a faster convergence by updating information with newly updated information in the same iteration.
The methods mentioned above mainly focus on a synchronous SCMA scheme, in which all signals are considered to arrive at the base station at the same time. However, in a real uplink channel, signals come from users in different directions or with different distances, resulting in different delays of transmission. Moreover, a grant scheme produces significant signaling cost, so grant-free transmission is introduced as a competitive alternative in 3rd Generation Partnership Project (3GPP) Release 16 [
13]. That means delays of signals are completely random, adding great difficulty for uplink detection. Thus, exploring useful asynchronous detection algorithms is essential.
Some research paid attention to asynchronous detection. Ref. [
14] devised a message-passing receiver for the uplink SCMA that uses expectation propagation to tackle the intractable distributions. Ref. [
15] estimated a channel based on both received short pilot and data sequences and introduces auxiliary active-state indicators in joint detection. Ref. [
16] proposed a blind detection algorithm for detecting user signals without the knowledge of a user codebook. Ref. [
17] performed signal detection using deep learning with unknown channel information and system sparsity. Ref. [
18] investigated an algorithm based on belief propagation and equal gain combining under asynchronous circumstances and effectively improves the system performance.
It is noted that delays can be various when connections of users are massive, which means the contents of the mixed signal received can be too various to decode in one scheme. Although the algorithms above perform well in an asynchronous system, few of them consider the problem caused by the variety of delays. Thus, making a detection rule is very important to relieve the bad effects brought by interference between symbols.
To further improve system performance, the multiple-input multiple-output (MIMO) technique is used to increase system reliability through diversity gain. Ref. [
19] made a selection of receive antennas that minimizes the signal-to-interference ratio of the observed signal during the MPA calculations. Ref. [
20] developed low-complexity iterative detection algorithms based on an expectation propagation algorithm. Ref. [
21] studied spatial multiplexing (SMX), spatial modulation (SM) and space shift keying (SSK) techniques for the MIMO-SCMA systems. Ref. [
22] proposed a partially active message passing based on the Gaussian approximation principle and a sliding window is introduced to determine what user stays active during each detection. The combination of MIMO and SCMA can enhance the performance greatly but it also adds computing complexity at the same time. Ref. [
23] proposed a multi-dimensional space-time block code (MSTBC)-aided downlink MIMO-SCMA, which has almost the same complexity but better performance. In [
24], a low-complexity codebook design algorithm based on the cross-entropy method and low-complexity MIMO-SCMA codeword detectors based on depth-first and breadth-first tree-search algorithms was proposed. Ref. [
25] proposed a new scheme, named spatial modulation sparse code multiple access (SM-SCMA). At the receiver, a low-complexity joint message-passing algorithm is proposed.
Targeting the problems above, this paper constructs a grouped-detection scheme, in which users with similar delays are grouped together for the ease of joint detection. First, we assume that the scheme in the same group is perfect synchronization, which is to say that the delays of users’ information in the same group are exactly the same and delays are different between different groups. A message-passing algorithm based on serial propagation (SP-MPA) is proposed and utilized to propagate the updated information to the next symbol as the initial information. This method can effectively cut down the bit error rate because it sufficiently utilizes the same information without recalculation. Then, we consider the imperfect synchronization of users in the same group. In this scheme, performance undergoes a sharp degradation because of the interference of the delayed symbols. Therefore, we propose a partial Gaussian approximation-aided (PGA) algorithm to compensate the error and improve the transmission accuracy when ensuring lower complexity compared to original SP-MPA in the MIMO-SCMA system.
The contents of this paper are outlined as follows.
Section 2 represents the asynchronous SCMA system model.
Section 3 describes the detailed process of asynchronous detection using SP-MPA. The imperfect scheme in the same group and the process of PGA are illustrated in
Section 4.
Section 5 shows the final results of these algorithms, such as bit error rate and complexity. Finally, conclusions are drawn in
Section 6.
2. System Model
In this paper, the uplink MIMO-SCMA system is constructed with one base station, frequency resources and users. Each user is equipped with one antenna and the base station has antennas . The distance from each user to the base station is . In this system, users are located in various directions and distances and send their information at any time. Users within the coverage of the base station are divided into different groups according to different delays.
2.1. Grouping Rule
As shown in
Figure 1, different delays of the asynchronous multi-users would lead to various symbol detection cases. It is hard to perform signal sampling and detection algorithms without grouping. Therefore, a grouping rule will help improve the system performance through categorizing similar delays into one group.
Assuming that all users are in the same environment but only with different distances to the base station in the system model, we can divide the users with similar distances into one group.
For example, there are two groups in the system model. The users with the distances similar to the
could be grouped as
and the users with the distances similar to the
could be grouped as
. The users in both groups are defined as
and
. The transmitting power of these users is normalized to
and
as the identity. The modulation order is
. The delay of two different user groups to the base station is
and
respectively and the arrows mean the transmitting direction, as
Figure 2 illustrates.
2.2. Codebook
First, the mother codebook for each user group is designed, divided into diversity groups and assigned to users shared on each resource block. Each user maps their bit stream to its own codebook and transmits the mapped symbols to the base station.
The SCMA encoder maps
bits to a
codebook,
,
. In this model, each user occupies
resource blocks and each resource block accommodates
users.
Two mother codebooks,
and
, are constructed with
assigned to near users and
assigned to far users. The radius of
is bigger than
and there is a rotated angle between them for distinction. In the uplink system, near users have better channel states, which are easier to be decoded. Thus,
is set bigger than
to obtain a more accurate result because of the joint detection. The mother codebooks are divided into
diversities, respectively, to distinct users shared on the same resource block.
Figure 3 shows the codeword distribution on the same resource block and users in these two groups both adopt QPSK modulation. The power of signals is normalized and the radius means the transmitting power of users in two groups. Constellation points in each group are
in
Figure 3.
2.3. Asynchronous Transmission Model
In the uplink, multiple users transmit data to the base station. Due to the different locations, the channel conditions are different and the fading and loss are also different. Users with similar distances to the base station are divided into one group, so that delays of the users in the same group could be assumed as the same value if the perfect detection scheme is used and the total delay of two different user groups to the base station is
and
, respectively. The symbol ‘+’ means that the noise is additive and ‘
’ means addition operation, as shown in
Figure 4.
In the asynchronous scheme, the superimposed signal received at the base station can be expressed as
,
. The resource blocks are orthogonal to each other, where OFDM is conducted, so that separate detection of frequency resource blocks can be performed. The superimposed signal on the same resource block is shown as below, where
means the set of users on the
resource block,
.
can be written as 0, which is chosen as the reference. However, it is still marked in the following figures in order to be clearer. In addition, due to the similarity of delays in one group, we use rectangles with different colors to represent
and
. The ratio of
and
is defined as
, where
means the lasting time of one symbol. Classification discussion of
is listed below and
Figure 5 shows the transmission situations with different
.
: the delay is within a symbol duration.
: the delay is equal to an integer multiple of the symbol duration.
: the delay is shifted symbol durations backward.
As shown in the diagram, situation 2 can be seen as a special case of situation 3, which is categorized into 3. The main difference between 1 and 3 is the first symbol where there is no interference of group 2 to group 1. However, if the first symbol is decoded, detection methods of the left symbols can be the same as 1. Without loss of generality, the following research is only discussed in light of situation 1.
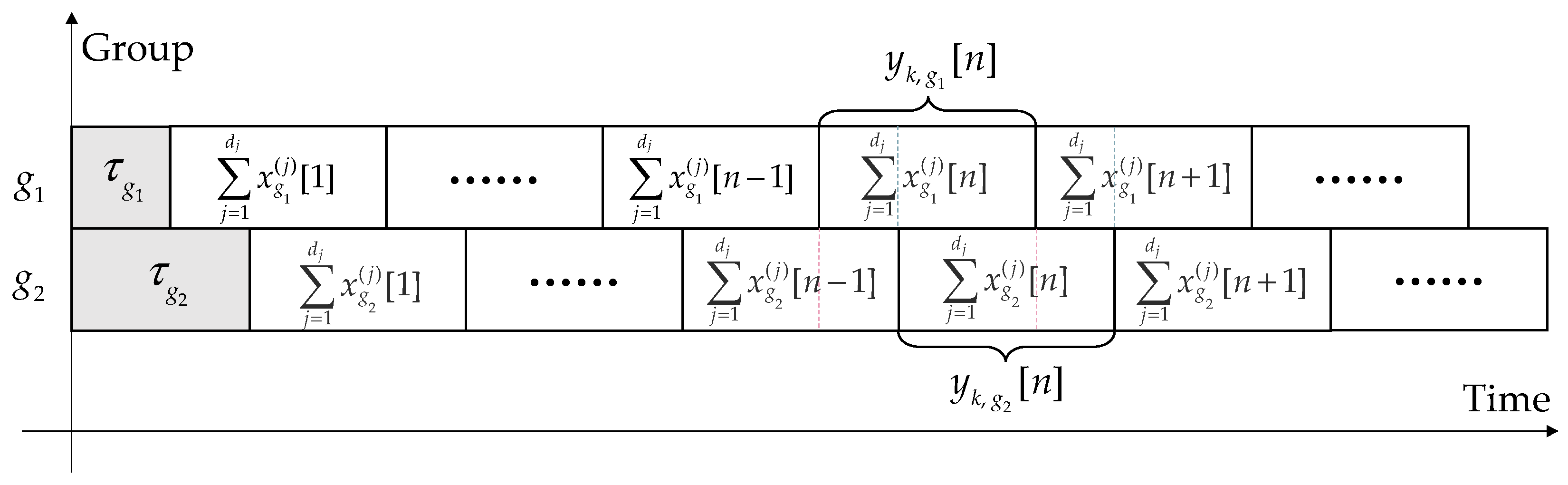
Figure 6 shows the complete transmission process.
The mathematical expression of the received signal in symbol-related form is represented below and the receiving structure is shown in
Figure 7. Because of asynchronization, each symbol not only affects the current symbol but also affects the adjacent symbols [
26]. For example, the second symbol of users in group 1 can be affected by the first and second symbol of users in group 2.
means the symbol, represents the subscript difference of adjacent symbols, which is 0 (current symbol), −1 (last symbol) or 1 (next symbol). and are functions of and . and represent the Rayleigh channel gain of user on the resource block in group 1 and group 2. and mean the codeword sent by user and is the additive white Gaussian noise (AWGN), .
3. Asynchronous Detection Algorithm
This section describes two methods to detect information of users in two groups jointly. First, the traditional MPA method is revised and represented as the asynchronous scheme. Then, the SP-MPA method is proposed to improve the system performance.
3.1. MIMO-SCMA Scheme
Because the multi-user grouping model increases the number of accessed users, the number of interference terms will also increase, resulting in a high bit error rate in the system. In order to solve this problem, the multi-antenna-diversity effect can be used to increase transmission reliability and accuracy.
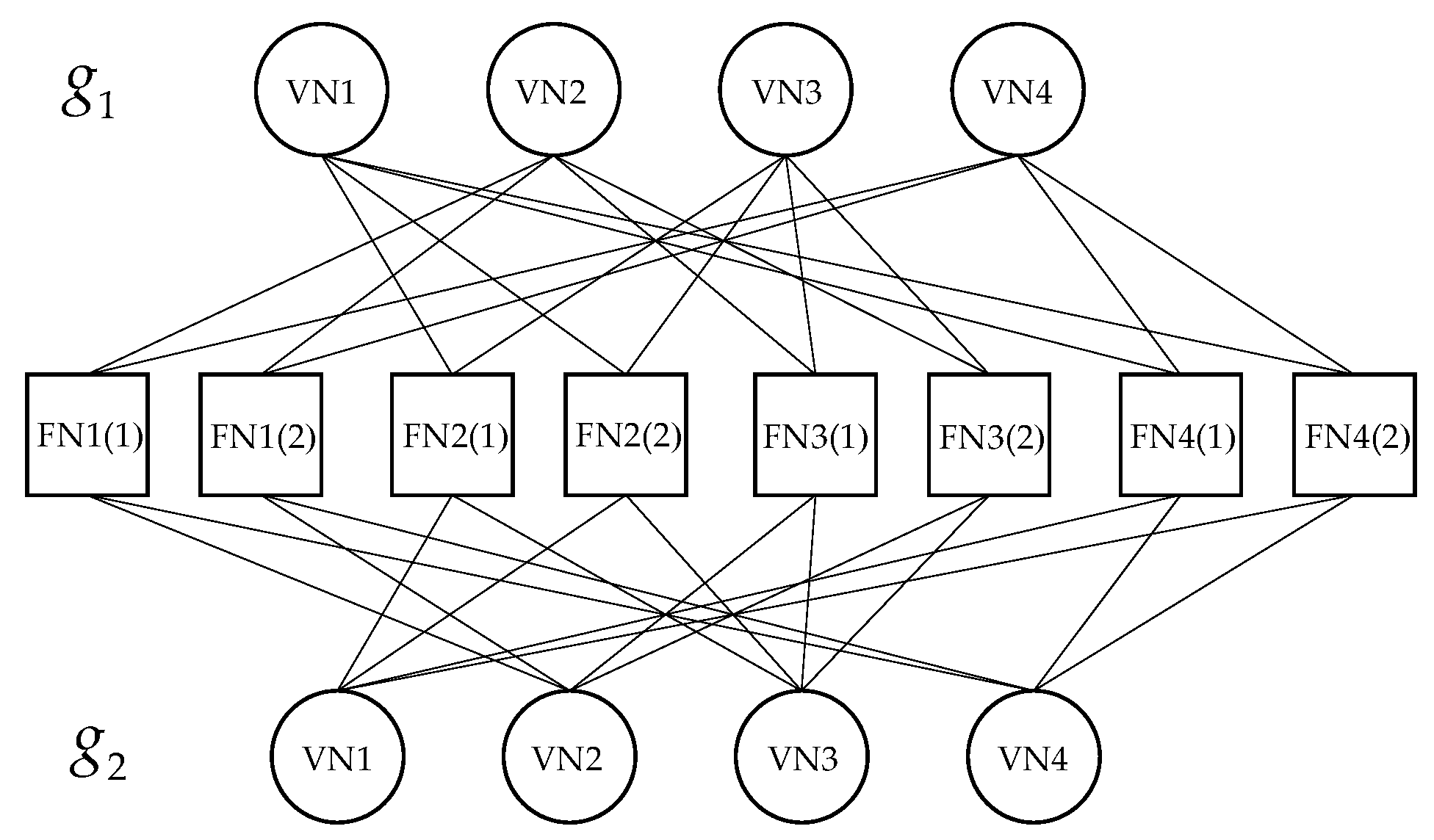
In the multi-antenna system, each antenna in the base station receives the same superimposed signal from the users. The joint factor graph is constructed, as in
Figure 8. Each antenna can be converted into a virtual function node [
27] and there are
function nodes in one group, which corresponded to
rows. Each resource block accommodates
users, which corresponded to
columns. The corresponding joint factor matrix is in
Figure 9. It can be seen from the factor graph that the amount of information propagation increases as the number of antennas increases, which can improve system performance.
3.2. Asynchronous Log-MPA Method
MPA is an iterative algorithm based on factor graph. Through the calculation and propagation of edge probability between resource nodes and user nodes, the probability of each codeword is finally obtained. The final estimated bit stream is obtained by log likelihood ratio (LLR) decision.
In the synchronous detection method, each user obtains the codeword probability of each symbol through message transmission and the detection of each symbol is independent from each other. The traditional synchronization model can obtain more accurate results through the MPA algorithm. The model in this paper can also be detected by MPA. In order to reduce the exponential operation, log-MPA is used here.
First, the user codeword probability is initialized and then the message is passing according to the factor graph in
Figure 8. Group 1 and Group 2 use the same factor graph, where FN refers to the frequency resource node and VN is the user node. The process of asynchronous log-MPA is illustrated as follows.
In the formulas,
means the user set on the
resource block and
means the resource set where the
user occupies.
means the information passing from the
resource block to the
user node and
means the information passing from the
user node to the
resource block. The updating process of
is normalized and the definition of
is listed in (9) [
10]. Then, the LLR is conducted to recover the bit stream of users. Since the decision process is the same for each user group, the codeword probability
and
of users in two groups are represented in the same way. The whole process is listed in Algorithm 1.
| Algorithm 1. Asynchronous Log-MPA |
Input: , , , ,
Initialize: , ,
1: forn = 1:N do
2: for t = 1: do
3: for do
4: use (7) to update
5: end for
6: for do
7: use (8) to update
8: end for
9: end for
10: for do
11: use (10) to calculate the probability of codewords
12: end for
13: use (11) to conduct LLR decision
14: end for |
| Output: |
3.3. SP-MPA Method
In the above asynchronous Log-MPA method, each time the iteration is performed, the prior probability starts from . The probability information of the preceding signal is not involved in the calculation; that is, the asynchronous Log-MPA does not make good use of the previous decision information. Therefore, a message-passing algorithm based on Serial Propagation (SP-MPA) is proposed to fully utilize the known information to improve the system performance. The whole process is listed in Algorithm 2.
The received signal is detected according to the asynchronous transmission structure and formula of the received signal. The asynchronous transmission process reveals that and contain common information, which can be detected, respectively, to obtain more accurate information values. First, we perform MPA on and then perform MPA on . Because there exists the same symbol in and , the decoded information can be utilized for each other. For example, the final probability of the first symbol of users in Group 1 in the detection of can be used as the initial probability in the detection of .
Messages are passed between nodes and the node graph of the propagation process is shown in
Figure 10. For clarity, only one user node shared on the first resource block is listed in the figure because each user on the same resource block has the same information updating mode.
represents the likelihood probability of group
observed on the
resource block.
and
represent the output probability of codewords in Group 1 and Group 2 at the end of the iteration.
The propagation formulas are listed as follows. When detecting the first symbol, the initial probability has no reference, so that its value equals
. Then, the initial probability can be obtained from the last detection, which is propagated forward.
Through the above algorithm, the previous information can be transmitted but the maximum number of iterations set by the traditional algorithm is not that accurate. Therefore, a precision is set to achieve a better convergence. If the difference between the codeword probability obtained by the previous iteration and the current iteration is smaller than the precision, the iteration is determined to be over. When the precision is bigger, it is easier for the difference in codewords to meet the precision and the iteration will end in advance, which reduces the complexity, but the accuracy will be reduced too.
| Algorithm 2. SP-MPA |
Input: , , , , ,
Initialize: , ,
conduct asynchronous Log-MPA to obtain the final probability of code-words
1: fordo
2: while
3: use (14) and (15) to obtain the initial probability
4: fordo
5: use (16) to update
6: end for
7: fordo
8: use (17) to update
9: end for
10: end while
11: fordo
12: use (10) to calculate the probability of codewords
13: end for
14: use (11) to conduct LLR decision
15: end for |
| Output: |
4. Partial Gaussian Approximation with Imperfect Synchronization in Group
The previous section described the asynchronous detection algorithms based on the model in
Section 2. The delays in one group are assumed to be almost the same, which is the perfect synchronization. However, this hypothesis is ideal, which is hard to realize. Although we put the users with similar delays in one group, there still exists a difference between these users and the synchronization in one group is imperfect. The transmission process should be revised to
Figure 11.
4.1. Imperfect Scheme
In
Figure 11, the delays of users in the same set have a slight gap:
in
and
in
, remarked with oblique lines, which will affect the detection of subsequent symbols. For example, the second symbol of
and the first symbol of
and
will be interfered by the first symbol of
. Given that the users in the same group have similar delays,
and
are much smaller than
.
Figure 12 illustrates the constellation distances of the two groups. For simplicity, only one point in Group 1 is drawn and the average distance between points in Group 1 and Group 2 is described as
. In addition, the value of
is considered similar in one group to show constellations clearly. The pink squares are the first superimposed symbol of group 1 which should be detected, the green circles are the first superimposed symbol of group 2 which should be detected and the green squares are the final superimposed symbols of all users.
If the algorithms based on perfect asynchronization in a group are applied in this model, the symbols delayed will not be taken into consideration, causing a big performance loss. However, if all symbols are added into the iteration, the computing complexity will be raised to a higher level. Therefore, new algorithms should be proposed to balance the performance and the complexity.
Consider the received signal in symbol-related form in (3). The whole formula should be revised and written as (19). means the difference in subscript difference of adjacent symbols. There are three kinds of delays: the first user in and , the second user in and the second user in , so there are three kinds of : , and .
Further, the formula can be represented with signals needed and signals that are considered as Gaussian noise. Take
, for example. In
, the last symbol of user 2 in Group 1 is the interference, which should be separated as the Gaussian noise. The last item in (22) includes the original Gaussian noise and the product of the last symbol of user 2 in Group 1 and its corresponding channel gain [
28]. The formula of
is derived in the same way, so only the process of
is outlined.
is modeled as where and are the mean and variance of , respectively, which are represented as follows. means the codeword of user 2 on the resource block in group 1. means the probability of the codeword of user 2 on the resource block in Group 1, which is obtained from the last symbol detection.
Therefore, the message passing from the function node to the user node can be written as (25) and (26). The codeword probability
and
are the same as (10) and (11).
However, if the Gaussian approximation (GA) method is conducted on each resource block, the accuracy of detection will experience large degradation. To balance the detection performance and complexity, a partial Gaussian approximation (PGA) method [
29] will be applied, in which only parts of resource blocks adopt the GA method with other blocks using Log-MPA. In
Figure 13, for example, three resource blocks adopt PGA, which are marked with blue lines.
From the above PGA process, the imperfect synchronization in the group can be solved by regarding the interference as the Gaussian noise on resource blocks. At the same time, the complexity is reduced because the delayed symbol in one group is not computed in the iteration. The whole algorithm is listed in Algorithm 3.
| Algorithm 3. PGA-MPA |
Input: , , , , ,
Initialize: , ,
conduct asynchronous Log-MPA to obtain the final probability of code-words
1: fordo
2: while
3: use (14) and (15) to obtain the initial probability
4: use (23) and (24) to compute and
5: for do
6: use (25) to update
7: end for
8: for do
9: use (26) to update
10: end for
11: end while
12: for do
13: use (10) to calculate the probability of codewords
14: end for
15: use (11) to conduct LLR decision
16: end for |
| Output: |
4.2. Complexity Analysis
The complexity of the three algorithms mentioned before is listed in
Table 1. Log-MPA and SP-MPA almost share the same complexity in the perfect scheme; the only difference is the number of iterations. From the simulation, the convergence ability is almost the same so the number of iterations is almost the same too.
In the imperfect scheme, SP-MPA (interference ignored) (SP-MPA (II)) has the lowest complexity, for it does not consider the interference and SP-MPA has the highest complexity, for it considers all symbols into iterations. In PGA-MPA, the complexity is reduced from to exponentially.
In the perfect scheme, is smaller than that in the imperfect scheme, so the computing operations of these algorithms are also fewer than that in the imperfect scheme.
5. Simulation Results
In this section, simulation and numerical analysis are conducted in different schemes. The superiority of SP-MPA and PGA-MPA is verified in the grouped system. The parameters in this paper are listed in
Table 2. The transmitting signal power is normalized to 1 in this paper.
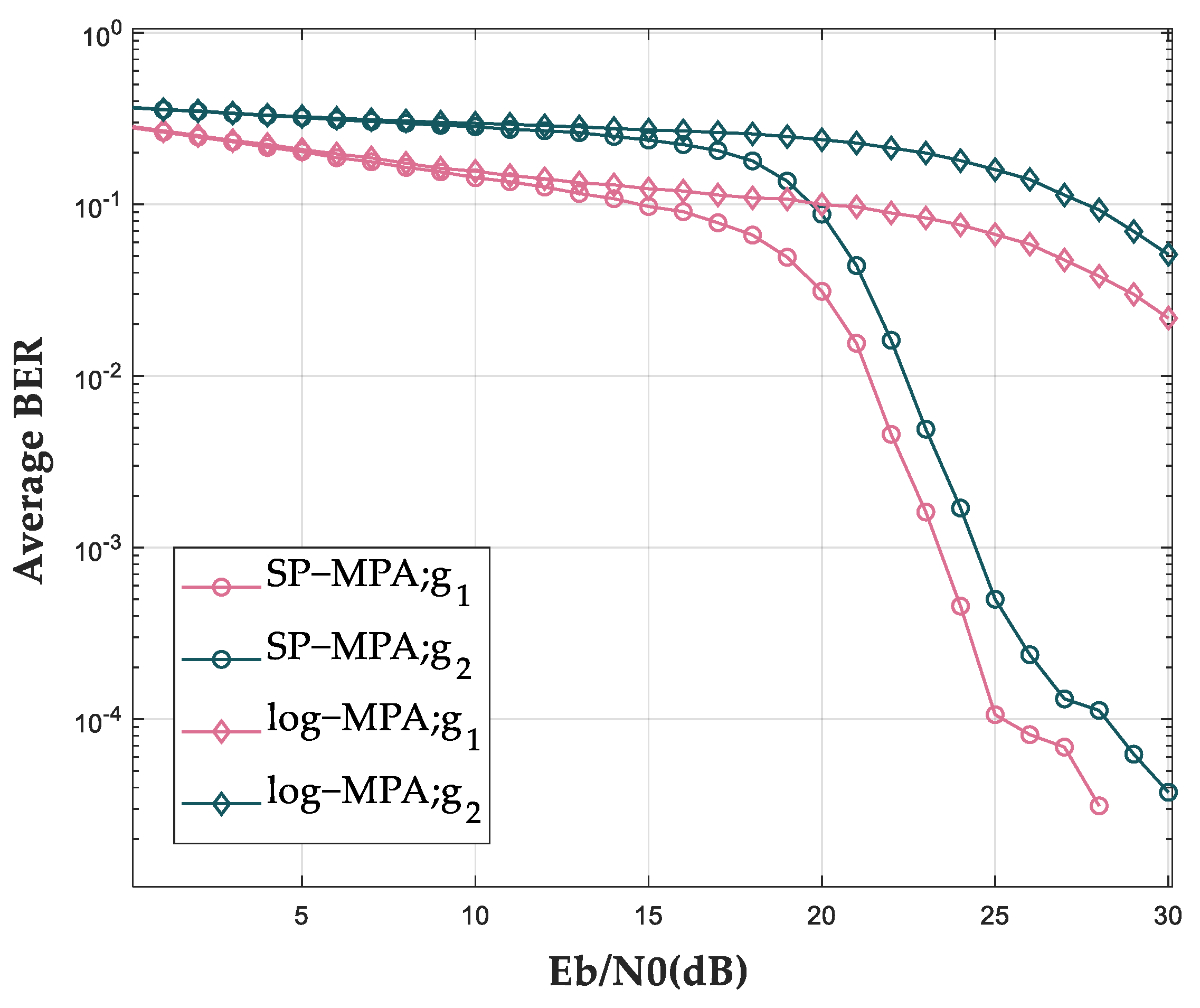
Figure 14 shows the system-average BER performance of Log-MPA and SP-MPA, in which
represents the near-user group and
represents the far-user group. Using SP-MPA can greatly reduce the bit error rate and improve the system performance, especially under the condition of high signal-to-noise ratio. It can be seen from the figure that the downward trend of Log-MPA is not obvious with the bit error rate being at a high level, while the curve of SP- MPA begins to decline rapidly when Eb/N0 is greater than 15 dB and the bit error rate is close to
when Eb/N0 is 30 dB. When Eb/N0 is smaller (less than 15 dB), the incorrect probability of codewords in the previous detection will affect the next symbols; thus, the curve of SP-MPA is closer to that of log-MPA. When Eb/N0 is higher, the correct ability will become higher; thus, the gap between these two algorithms will become larger.
The reason is that the initial codeword probability of Log-MPA starts with at each iteration, while SP-MPA retains the probability of the previous detection as the initial probability. Previous codeword probability has been fully calculated so it is not necessary to calculate from scratch in this detection.
Figure 15 illustrates the results with different numbers of users in two groups. When user activity is higher, more users share the same resource and the average BER would be increased quickly.
Figure 16 shows the bit error rate performance of the MIMO system with different numbers of receiving antennas at the base station. Increasing the number of receiving antennas is equivalent to increasing the number of virtual resource nodes. When the number of transmission paths increases, the reliability of code probability is improved. When Eb/N0 is 15 dB, the average bit error rate in Group 1 and Group 2 is 0.1079 and 0.2487, respectively, when
is 1. The average bit error rate is 0.0167 and 0.0873 when
is 2 and 0.0007 and 0.0141 when
is 4. It can be seen that the diversity effect of multiple antennas brings lower bit error rate and more reliable performance.
In the imperfect scheme, if the interference is ignored (SP-MPA (interference ignored), SP-MPA (II)), the decoding performance is too bad to obtain the correct signals sent by users. It can be seen from
Figure 17 that the SP-MPA (II) curve is almost a straight line without falling down. PGA-MPA computes the mean value and variance in the delayed symbol, so the correctability is higher than SP-MPA (II). Its correctability is lower than SP-MPA, owing to the delayed symbol is not involved in the iterations but only taken as Gaussian noise.
The antennas can be equalized to virtual function nodes, which can perform PGA-MPA. In
Figure 18, when
increases, more blocks adopt GA and the BER increases because of the approximation. However, the complexity also drops because of the reduction in nodes involved in the iterations.
Figure 19 shows the complexity and bit error rate of each algorithm in different schemes and the specific values are listed in
Table 3. In the perfect scheme, Log-MPA and SP-MPA have similar complexity. In the simulation of convergence in
Figure 20, the iterations are almost the same, which means the complexity is decided mainly by the iterations inside. The values on the y-axis in
Figure 20 are the posterior probability of codewords (QPSK modulated symbols) in log format during the soft decoding processing; thus, higher value leads to higher detection probability. Compared to SP-MPA, the complexity of PM-MPA in [
7] is lower but the bit error rate is much higher, reducing the reliability of communication. In the imperfect scheme, SP-MPA(II) has the lowest complexity with the worst performance and SP-MPA has the highest complexity with the best performance. PGA-MPA decreases some exponential operations and it balances the complexity and performance. In
Figure 19,
is set as 1. In order to eliminate unrelated factors, the operations and time are normalized.
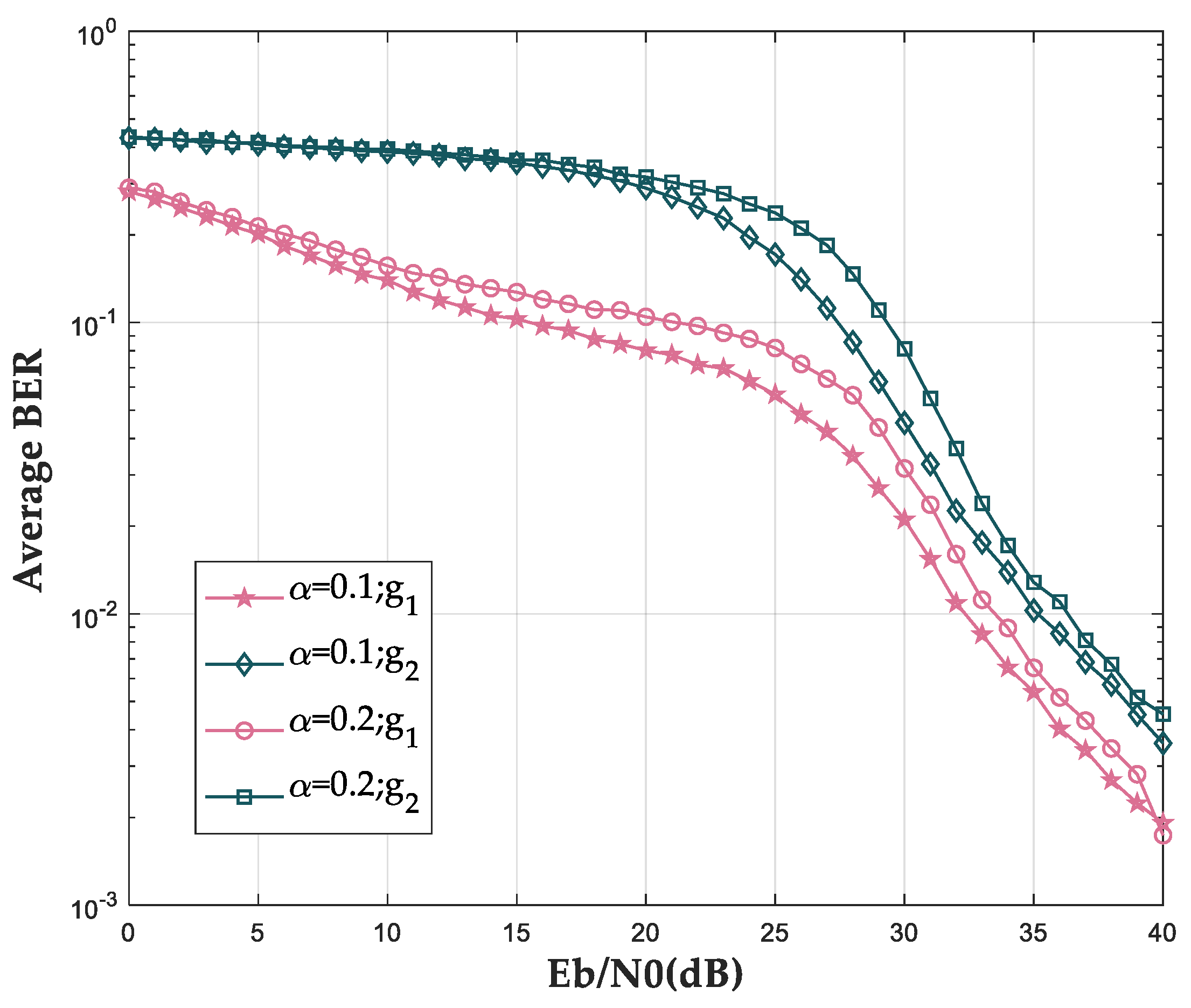
Figure 21 shows the bit error rate with groups, which have different delay gaps
in one group. Here, only
is compared, for
has the same impact. It can be seen that smaller
leads to a lower bit error rate because of the smaller interference of delayed symbol. Therefore, users with similar delays have to be grouped in the same collection.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
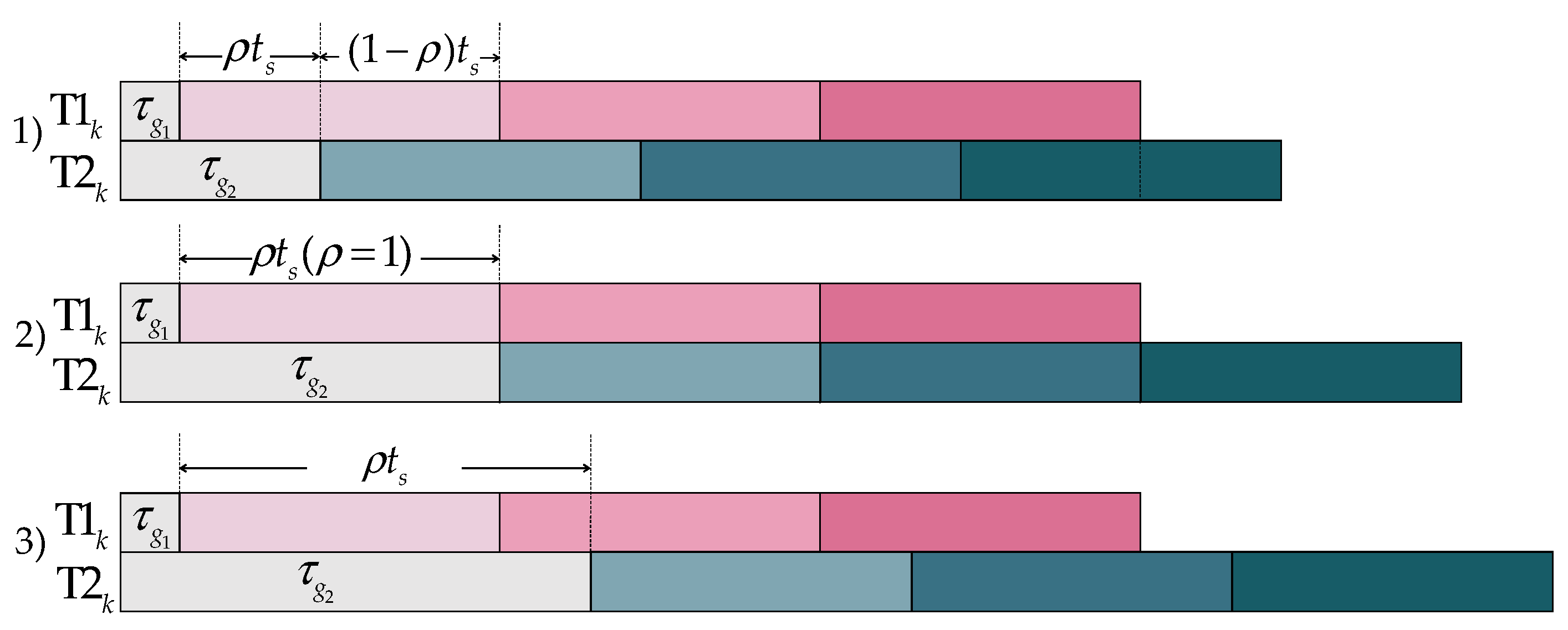{kind=link}
{kind=link}
{kind=link}
{kind=link}
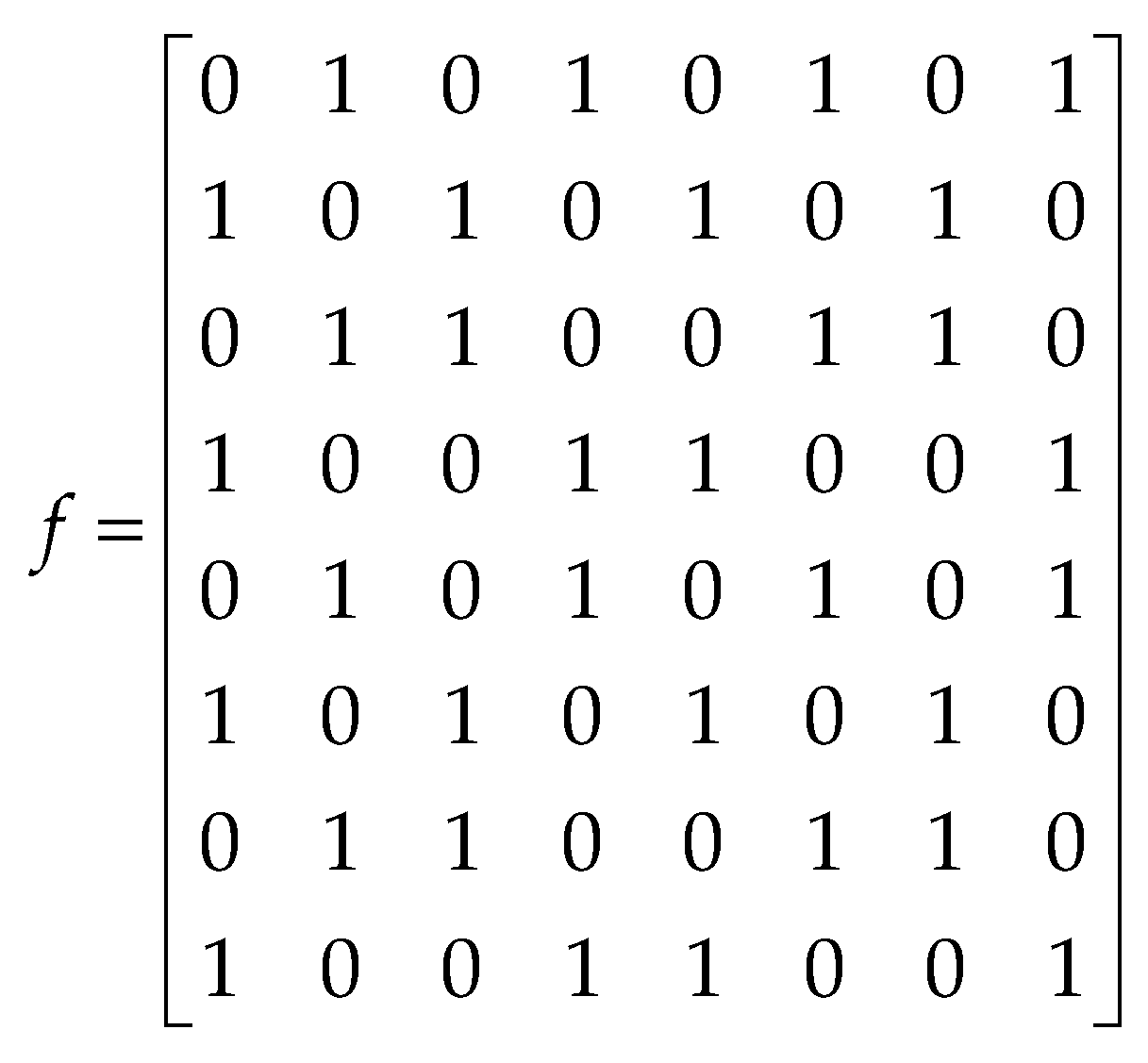{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}