
Poisonous Plants Species Prediction Using a Convolutional Neural Network and Support Vector Machine Hybrid Model




Abstract
:1. Introduction
- To the best of our knowledge, this work is the first that focuses on the issue of Arabic plant species classification and poisonous prediction.
- Create our own database for Arabic plants that includes 2500 different images of 50 types of plant species, some of which are poisonous, and others are non-poisonous.
- Study and analysis of Arabic plants to identify them with high accuracy using more than one classifier.
- Integration between different classifiers as a result of comparing the classifications, each separately.
- The outcome of our experiments for the convolutional neural network approach in conjunction with SVM was favorable and was achieved where the integration scored 0.92 in accuracy.
2. Literature Review
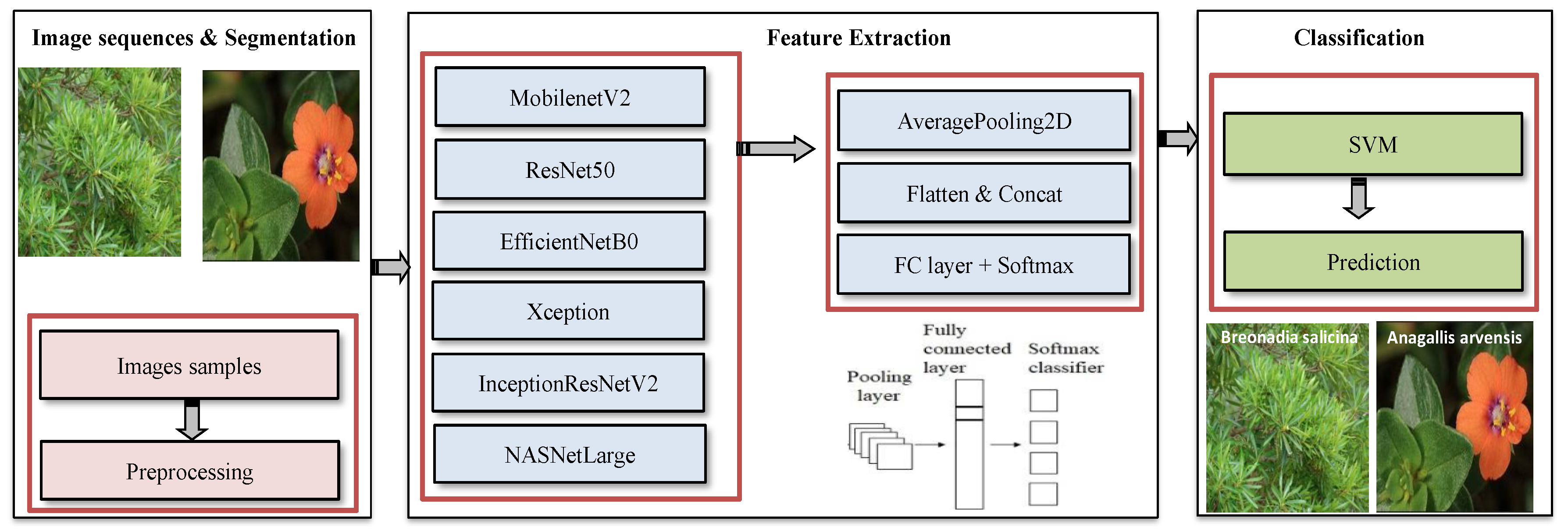
3. Convolutional Neural Network and Support Vector Machine Hybrid Model
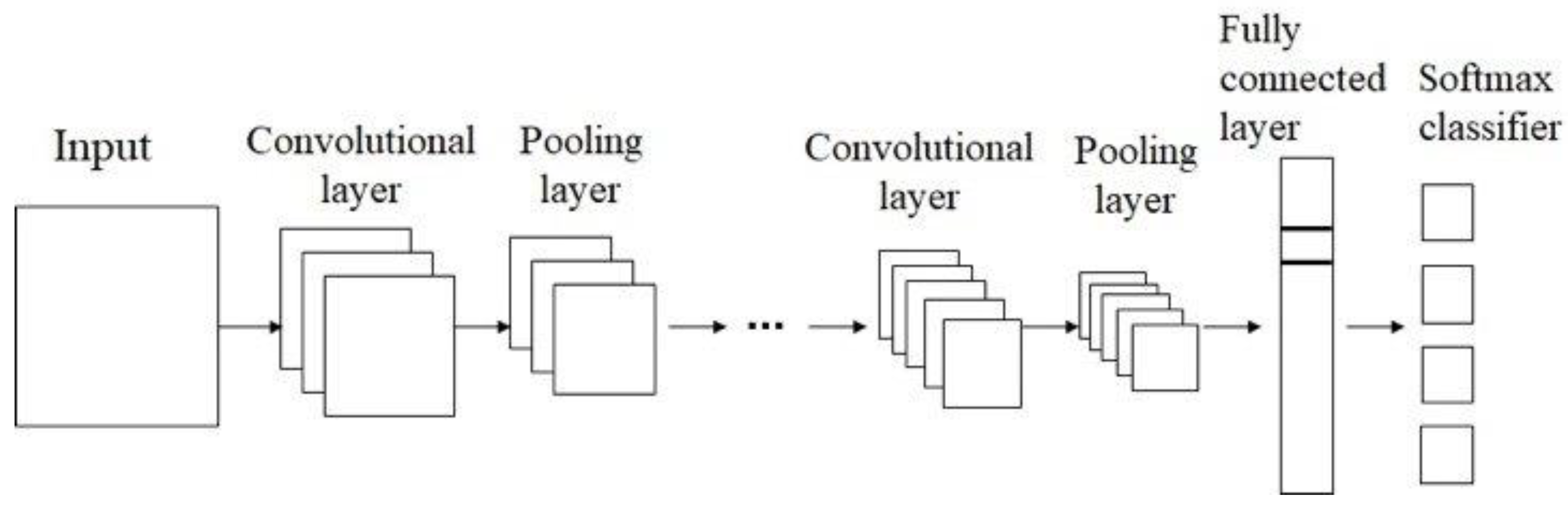
3.1. Pre-Trained Models
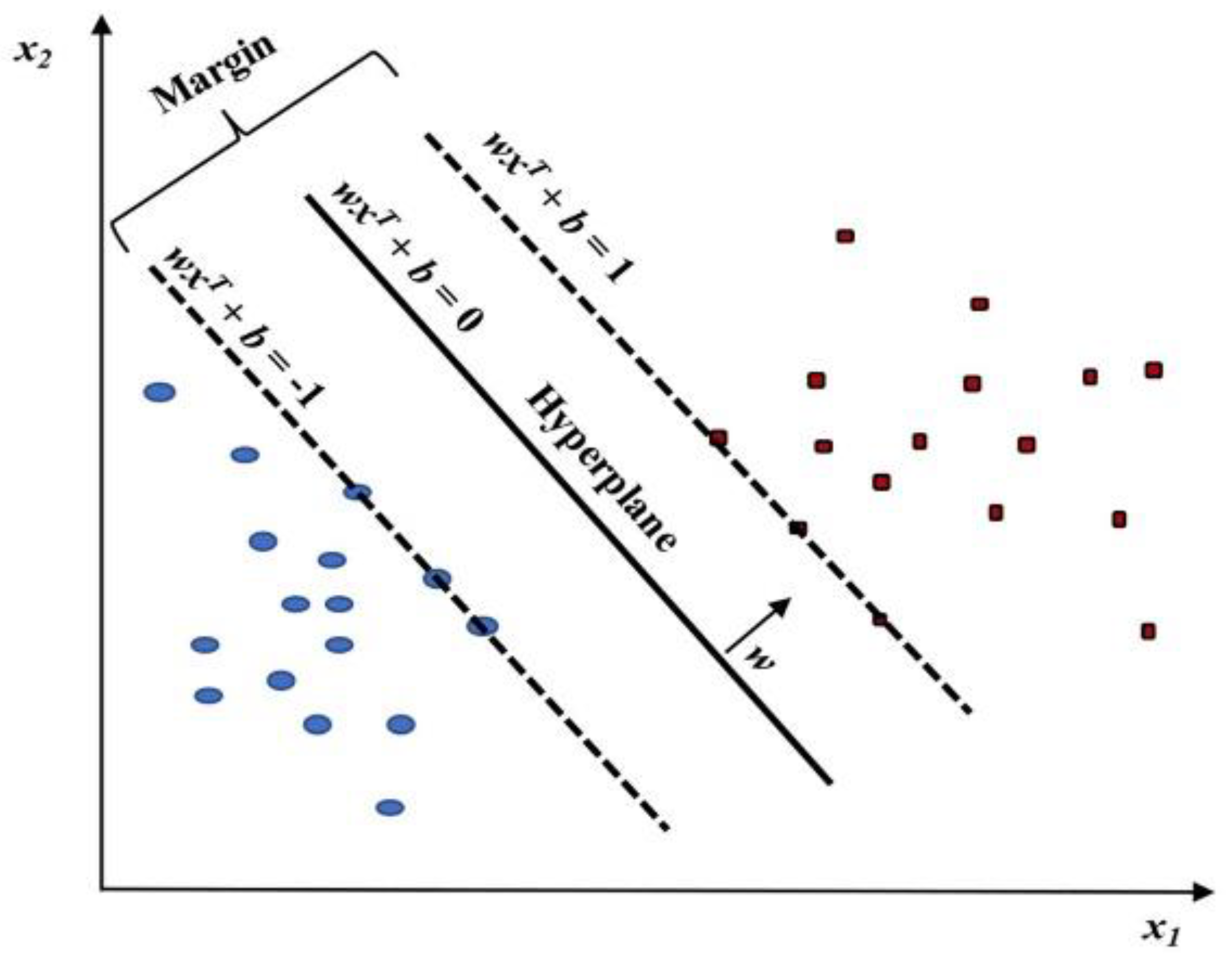
3.2. SVM Classification
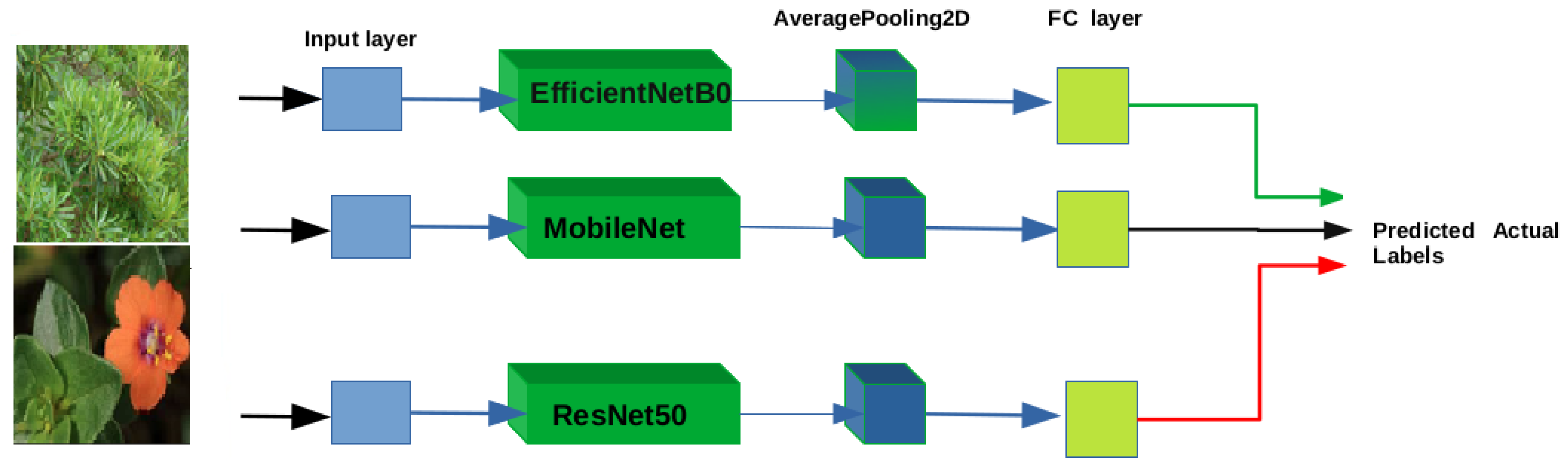
3.3. Integrating Model: CNN and SVM
4. Dataset and Experimental Results
4.1. Data Collection
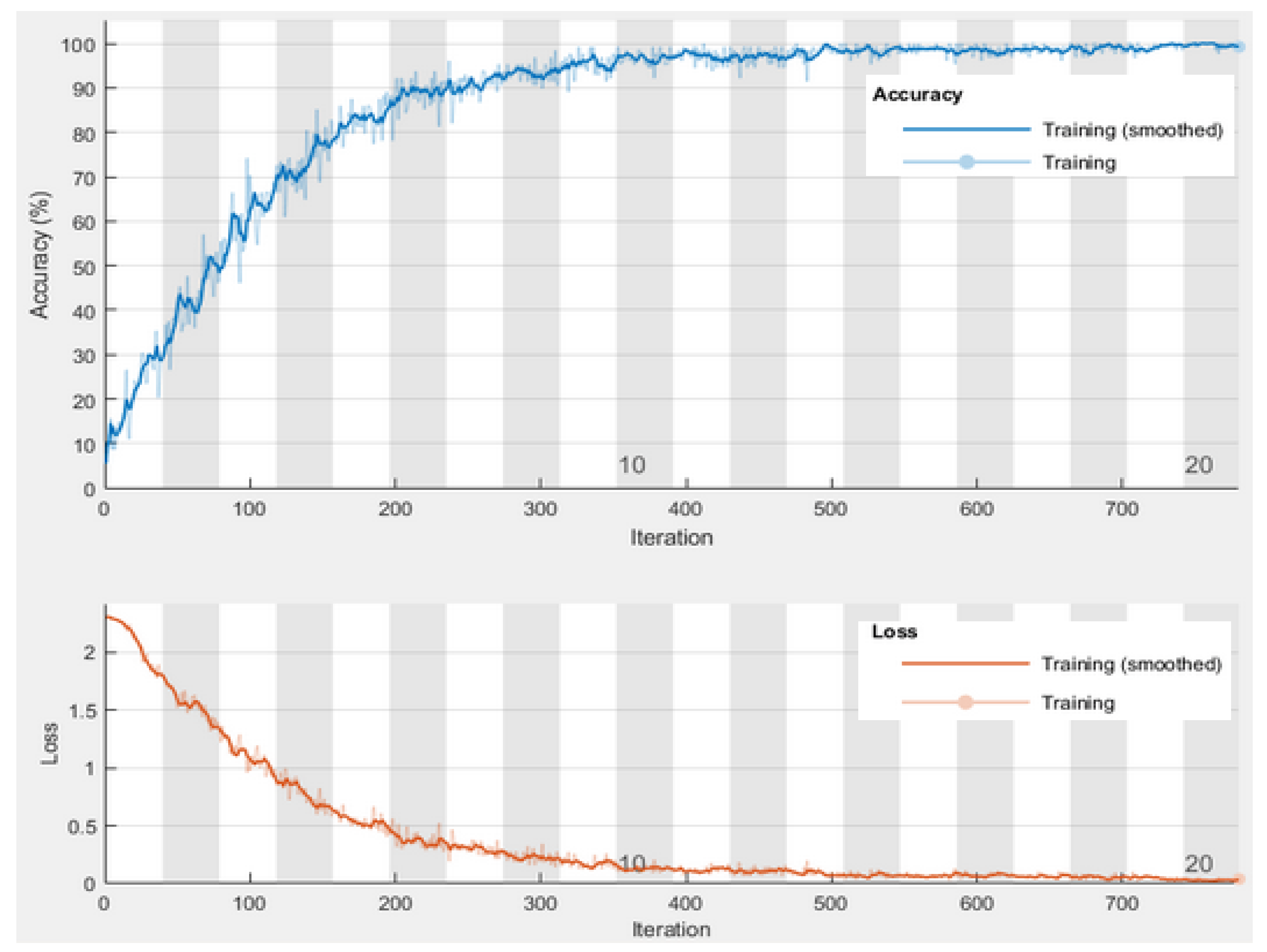
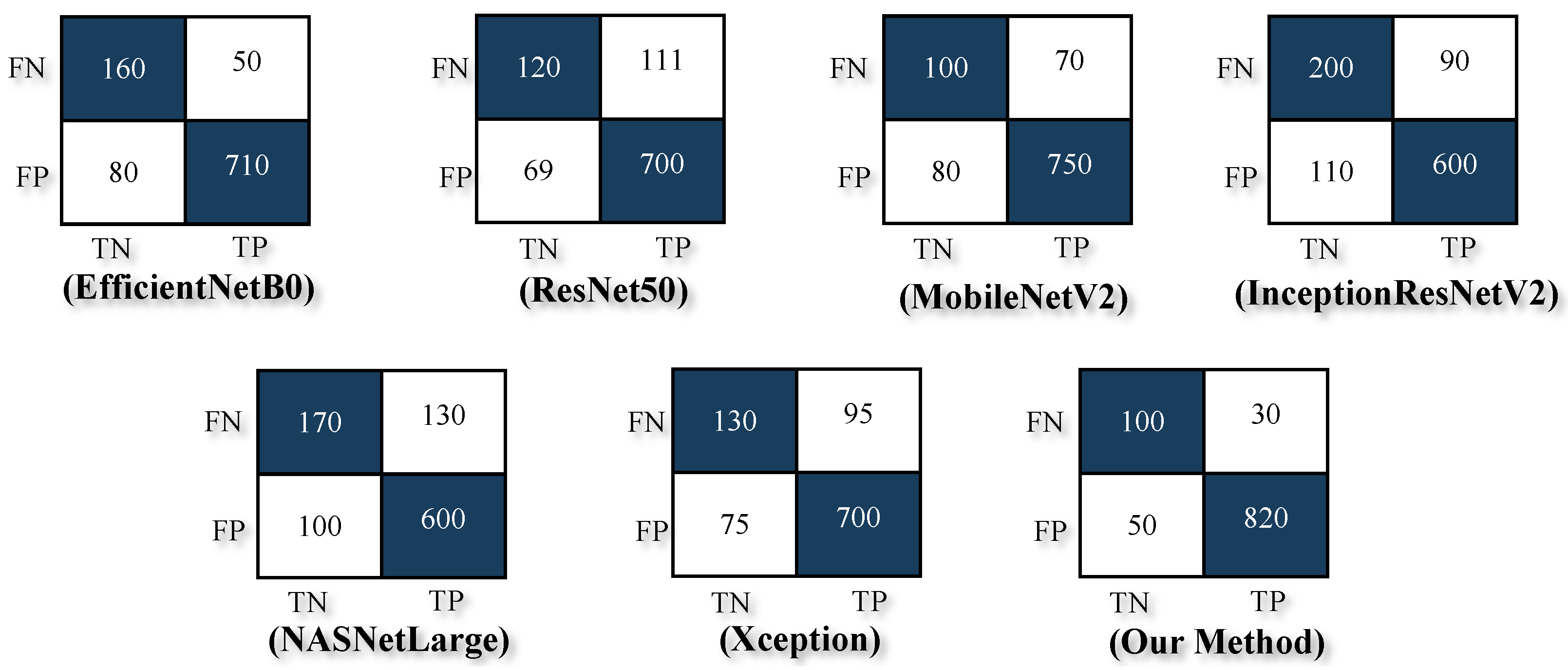
4.2. Evaluation
4.3. Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cheek, M.; Nic Lughadha, E.; Kirk, P.; Lindon, H.; Carretero, J.; Looney, B.; Douglas, B.; Haelewaters, D.; Gaya, E.; Llewellyn, T.; et al. New Scientific Discoveries: Plants and Fungi. Plants People Planet 2020, 2, 371–388. [Google Scholar] [CrossRef]
- Dasgupta, S. How Many Plant Species Are There in the World? Scientists Now Have an Answer. 2016. Available online: https://news.mongabay.com/2016/05/many-plants-world-scientists-may-now-answer/ (accessed on 15 July 2022).
- Jacob Thomas, H. Flora of Saudi Arabia. 2020. Available online: http://www.plantdiversityofsaudiarabia.info/Biodiversity-Saudi-Arabia/Flora/Flora.htm (accessed on 15 July 2022).
- Rebekah, R.; Scottie, A. Nearly 1000 of Florida’s Beloved Manatees Have Died This Year as Toxic Algae Blooms Choke Off Their Food Source. 2021. Available online: https://edition.cnn.com/2021/10/28/us/florida-manatee-deaths-starvation/index.html (accessed on 15 July 2022).
- Kolhar, S.; Jagtap, J. Plant Trait Estimation and Classification Studies in Plant Phenotyping Using Machine Vision—A Review. Inf. Process. Agric. 2021, in press. [Google Scholar] [CrossRef]
- Li, L.; Zhang, S.; Wang, B. Plant Disease Detection and Classification by Deep Learning—A Review. IEEE Access 2021, 9, 56683–56698. [Google Scholar] [CrossRef]
- Xiong, J.; Yu, D.; Liu, S.; Shu, L.; Wang, X.; Liu, Z. A Review of Plant Phenotypic Image Recognition Technology Based on Deep Learning. Electronics 2021, 10, 81. [Google Scholar] [CrossRef]
- Kaur, P.; Singh, S.K.; Singh, I.; Kumar, S. Exploring Convolutional Neural Network in Computer Vision-based Image Classification. Proceeding of the International Conference on Smart Systems and Advanced Computing (Syscom-2021), New Delhi, India, 26–27 December 2021; pp. 1–9. [Google Scholar]
- Noor, T.H. Behavior Analysis-Based IoT Services For Crowd Management. Comput. J. 2022, 65, bxac071. [Google Scholar] [CrossRef]
- Lu, J.; Tan, L.; Jiang, H. Review on Convolutional Neural Network (CNN) Applied to Plant Leaf Disease Classification. Agriculture 2021, 11, 707. [Google Scholar] [CrossRef]
- Loddo, A.; Di Ruberto, C. On The Efficacy of Handcrafted and Deep Features for Seed Image Classification. J. Imaging 2021, 7, 171. [Google Scholar] [CrossRef]
- Zahan, N.; Hasan, M.Z.; Malek, M.A.; Reya, S.S. A Deep Learning-Based Approach for Edible, Inedible and Poisonous Mushroom Classification. In Proceedings of the International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021; pp. 440–444. [Google Scholar]
- Liu, J.; Wang, X. Plant Diseases and Pests Detection Based on Deep Learning: A Review. Plant Methods 2021, 17, 1–18. [Google Scholar] [CrossRef]
- Vizcarra, G.; Bermejo, D.; Mauricio, A.; Gomez, R.Z.; Dianderas, E. The Peruvian Amazon Forestry Dataset: A Leaf Image Classification Corpus. Ecol. Inform. 2021, 62, 101268. [Google Scholar] [CrossRef]
- Prasad, M.P.S.; Senthilrajan, A. A Novel CNN-KNN based Hybrid Method for Plant Classification. J. Algebr. Stat. 2022, 13, 498–502. [Google Scholar]
- Chaki, J.; Parekh, R. Designing an Automated System for Plant Leaf Recognition. Int. J. Adv. Eng. Technol. 2012, 2, 149–158. [Google Scholar]
- Tavakoli, H.; Alirezazadeh, P.; Hedayatipour, A.; Nasib, A.B.; Landwehr, N. Leaf Image-based Classification of Some Common Bean Cultivars Using Discriminative Convolutional Neural Networks. Comput. Electron. Agric. 2021, 181, 105935. [Google Scholar] [CrossRef]
- Naeem, S.; Ali, A.; Chesneau, C.; Tahir, M.H.; Jamal, F.; Sherwani, R.A.K.; Ul Hassan, M. The Classification of Medicinal Plant Leaves Based on Multispectral and Texture Feature Using Machine Learning Approach. Agronomy 2021, 11, 263. [Google Scholar] [CrossRef]
- Sujith, A.; Neethu, R. Classification of Plant Leaf Using Shape and Texture Features. In Inventive Communication and Computational Technologies; Ranganathan, G., Chen, J., Rocha, Á., Eds.; Springer: Singapore, 2021; pp. 269–282. [Google Scholar]
- Kumar, N.; Belhumeur, P.N.; Biswas, A.; Jacobs, D.W.; Kress, W.J.; Lopez, I.C.; Soares, J.V. Leafsnap: A Computer Vision System for Automatic Plant Species Identification. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 502–516. [Google Scholar]
- Koh, J.C.; Spangenberg, G.; Kant, S. Automated Machine Learning for High-throughput Image-based Plant Phenotyping. Remote. Sens. 2021, 13, 858. [Google Scholar] [CrossRef]
- Patil, A.; Lad, K. Chili Plant Leaf Disease Detection Using SVM and KNN Classification. In Rising Threats in Expert Applications and Solutions; Rathore, V., Dey, N., Piuri, V., Babo, R., Polkowski, Z., Tavares, J., Eds.; Springer: Singapore, 2021; pp. 223–231. [Google Scholar]
- Ahmad, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U.; Anwar, S.; Anjum, M.R. Leaf Image-based Plant Disease Identification Using Color and Texture Features. Wirel. Pers. Commun. 2021, 121, 1139–1168. [Google Scholar] [CrossRef]
- Negi, A.; Kumar, K.; Chauhan, P. Deep Neural Network-Based Multi-Class Image Classification for Plant Diseases. In Agricultural Informatics: Automation Using the IoT and Machine Learning; Amitava, C., Arindam, B., Manish, P., Amlan, C., Eds.; Wiley Online Library: Hoboken, NJ, USA, 2021; pp. 117–129. [Google Scholar]
- Thakur, S.; Patil, D.; Sarse, R.; Bharambe, M. Plant Disease Detection and Solution Using Image Classification. Int. J. Sci. Res. Eng. Trends 2021, 7, 1534–1540. [Google Scholar]
- Granwehr, A.; Hofer, V. Analysis on Digital Image Processing for Plant Health Monitoring. J. Comput. Nat. Sci. 2021, 1, 1–8. [Google Scholar] [CrossRef]
- Atila, Ü.; Uçar, M.; Akyol, K.; Uçar, E. Plant Leaf Disease Classification Using EfficientNet Deep Learning Model. Ecol. Inform. 2021, 61, 101182. [Google Scholar] [CrossRef]
- Emine Cengil, A.C. Multiple Classification of Flower Images Using Transfer Learning. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019. [Google Scholar] [CrossRef]
- Hark, C.; Uçkan, T.; Seyyarer, E.; Karci, A. Extractive Text Summarization via Graph Entropy Çizge Entropi ile Çıkarıcı Metin Özetleme. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; ACM Press: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Harjoseputro, Y.; Yuda, I.P.; Danukusumo, K.P. MobileNets: Efficient Convolutional Neural Network for Identification of Protected Birds. Int. J. Adv. Sci. Eng. Inf. Technol. 2020, 10, 2290. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. Proceedings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research, 97:6105–6114. 2019. Available online: https://proceedings.mlr.press/v97/tan19a.html (accessed on 15 July 2022).
- Tripathi, K.; Gupta, A.K.; Vyas, R.G. Deep Residual Learning for Image Classification using Cross Validation. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 1525–1530. [Google Scholar] [CrossRef]
- Radhika, K.; Devika, K.; Aswathi, T.; Sreevidya, P.; Sowmya, V.; Soman, K.P. Performance Analysis of NASNet on Unconstrained Ear Recognition. In Nature Inspired Computing for Data Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 57–82. [Google Scholar] [CrossRef]
- Cleetus, L.; Sukumar, A.R.; Hemalatha, N. Computational Prediction of Disease Detection and Insect Identification using Xception model. bioRxiv 2021. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, C.; Zhang, Z.; Xing, Y.; Liu, X.; Dong, R.; He, Y.; Xia, L.; Liu, F. Recurrence Plot-Based Approach for Cardiac Arrhythmia Classification Using Inception-ResNet-v2. Front. Physiol. 2021, 12, 648950. [Google Scholar] [CrossRef] [PubMed]
- Eroğlu, Y.; Yildirim, M.; Çinar, A. Convolutional Neural Networks based classification of breast ultrasonography images by hybrid method with respect to benign, malignant, and normal using mRMR. Comput. Biol. Med. 2021, 133, 104407. [Google Scholar] [CrossRef] [PubMed]
- Redi, M.; Merialdo, B. A Multimedia Retrieval Framework Based on Automatic Graded Relevance Judgments. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 300–311. [Google Scholar] [CrossRef]
- Elmezain, M.; Al-Hamadi, A.; Rashid, O.; Michaelis, B. Posture and Gesture Recognition for Human-Computer Interaction. In Advanced Technologies; InTech: London, UK, 2009. [Google Scholar] [CrossRef] [Green Version]
- Elmezain, M.; Al-Hamadi, A.; Michaelis, B. Discriminative Models-Based Hand Gesture Recognition. In Proceedings of the 2009 Second International Conference on Machine Vision, Dubai, United Arab Emirates, 28–30 December 2009. [Google Scholar] [CrossRef]
- Elmezain, M.; Malki, A.; Gad, I.; Atlam, E.S. Hybrid Deep Learning Model–Based Prediction of Images Related to Cyberbullying. Int. J. Appl. Math. Comput. Sci. 2022, 32, 323–334. [Google Scholar] [CrossRef]
- Elmezain, M.; Mahmoud, A.; Mosa, D.T.; Said, W. Brain Tumor Segmentation Using Deep Capsule Network and Latent-Dynamic Conditional Random Fields. J. Imaging 2022, 8, 190. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Plant Scientific Name | Plant Type |
|---|---|
| prickly pear | Not poisonous |
| Artemisia | Not poisonous |
| Rhanterium epapposum | Not poisonous |
| Urtica | Not poisonous |
| African loan tree | Not poisonous |
| Toxicodendron radicans | Poisonous |
| Haplophyllum tuberculatum | Not poisonous |
| Dum tree (Hyphaene Thebaica ) | Not poisonous |
| Prosopis | Not poisonous |
| Abutilon pannosum | Not Poisonous |
| Calligonum comosum | Not Poisonous |
| Halocnemum strobilaceum | Not Poisonous |
| Rumex vesicarius | Not Poisonous |
| Vachellia nilotica | Not Poisonous |
| Adenium obesum | Poisonous |
| Retama raetam | Not Poisonous |
| Breonadia salicina | Not Poisonous |
| Jasminum grandiflorum | Not Poisonous |
| Besham | Not Poisonous |
| common nim | Not Poisonous |
| fiery muffler | Not Poisonous |
| Handy | Poisonous |
| Harmel | Not Poisonous |
| Henna | Not Poisonous |
| Infernal | Not Poisonous |
| Oatmeal | Not Poisonous |
| Sidr | Not Poisonous |
| Anagallis arvensis | Poisonous |
| Salvadora persica | Not Poisonous |
| Alashker | Poisonous |
| Albang | Poisonous |
| alkhnsor | Not poisonous |
| alHalafa | Not poisonous |
| Ricinus | Poisonous |
| Echinops spinosissimus | Not poisonous |
| Rhanterium epapposum | Not poisonous |
| Clover | Not poisonous |
| AlRamram | Poisonous |
| Boswellia sacra | Not poisonous |
| Breonadia salicina | Not poisonous |
| Solanum incanum | Poisonous |
| Olea algirus | Not poisonous |
| Euclea | Not poisonous |
| Narcissus | Poisonous |
| Scadoxus multiflorus | Not poisonous |
| Nerium oleander | Poisonous |
| Sectarian roses | Not poisonous |
| Rabbit hair | Not poisonous |
| Reichardia tingitana | Not poisonous |
| A poisonous or sperm-like | Poisonous |
| Precision | Recall | F1-Score | Accuracy | |
|---|---|---|---|---|
| NASNetLarge | 0.86 | 0.82 | 0.84 | 0.77 |
| InceptionResNetV2 | 0.85 | 0.86 | 0.85 | 0.80 |
| ResNet50 | 0.91 | 0.86 | 0.89 | 0.82 |
| Xception | 0.90 | 0.88 | 0.89 | 0.83 |
| MobilenetV2 | 0.90 | 0.91 | 0.91 | 0.85 |
| EfficientNetB0 | 0.90 | 0.93 | 0.92 | 0.87 |
| Our Method (CNN-SVM) | 0.94 | 0.96 | 0.95 | 0.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noor, T.H.; Noor, A.; Elmezain, M. Poisonous Plants Species Prediction Using a Convolutional Neural Network and Support Vector Machine Hybrid Model. Electronics 2022, 11, 3690. https://doi.org/10.3390/electronics11223690
Noor TH, Noor A, Elmezain M. Poisonous Plants Species Prediction Using a Convolutional Neural Network and Support Vector Machine Hybrid Model. Electronics. 2022; 11(22):3690. https://doi.org/10.3390/electronics11223690
Chicago/Turabian StyleNoor, Talal H., Ayman Noor, and Mahmoud Elmezain. 2022. "Poisonous Plants Species Prediction Using a Convolutional Neural Network and Support Vector Machine Hybrid Model" Electronics 11, no. 22: 3690. https://doi.org/10.3390/electronics11223690
APA StyleNoor, T. H., Noor, A., & Elmezain, M. (2022). Poisonous Plants Species Prediction Using a Convolutional Neural Network and Support Vector Machine Hybrid Model. Electronics, 11(22), 3690. https://doi.org/10.3390/electronics11223690