
HA-Unet: A Modified Unet Based on Hybrid Attention for Urban Water Extraction in SAR Images

 , ,
, , 
Abstract
:1. Introduction
2. Related Work
2.1. Unet for Water Segmentation
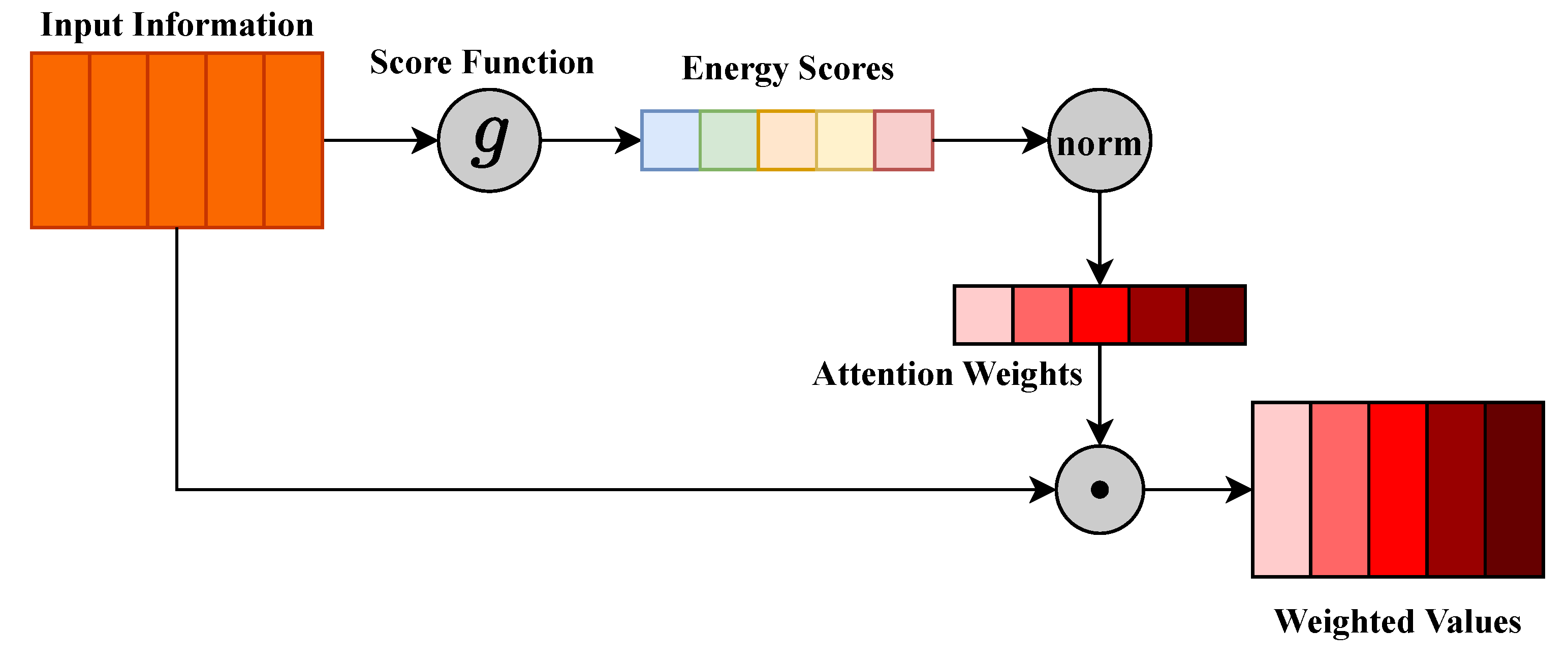
2.2. Attention Mechanisms
3. Materials
3.1. Study Area
3.2. Dataset
4. Methodology
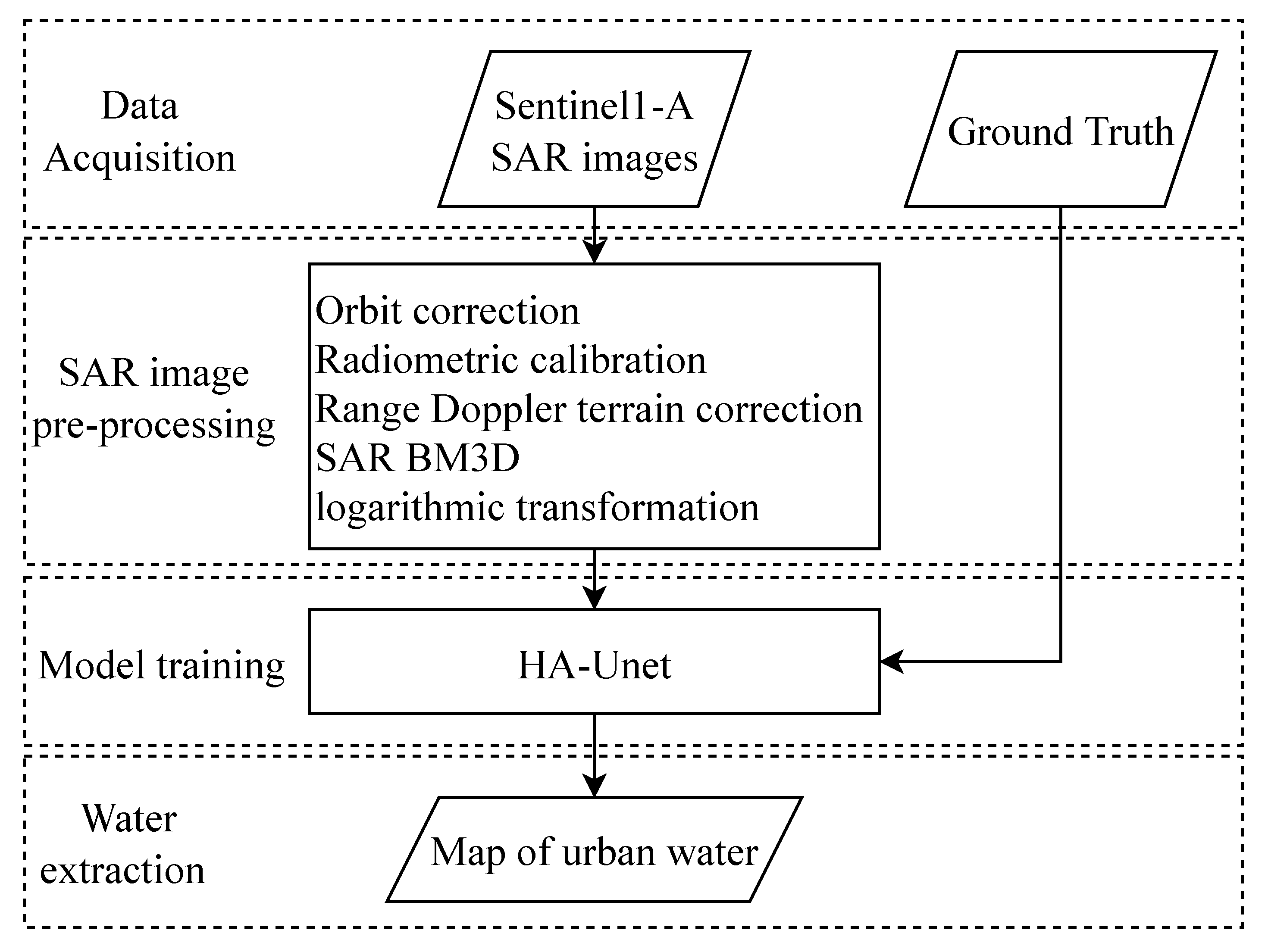
4.1. Overview
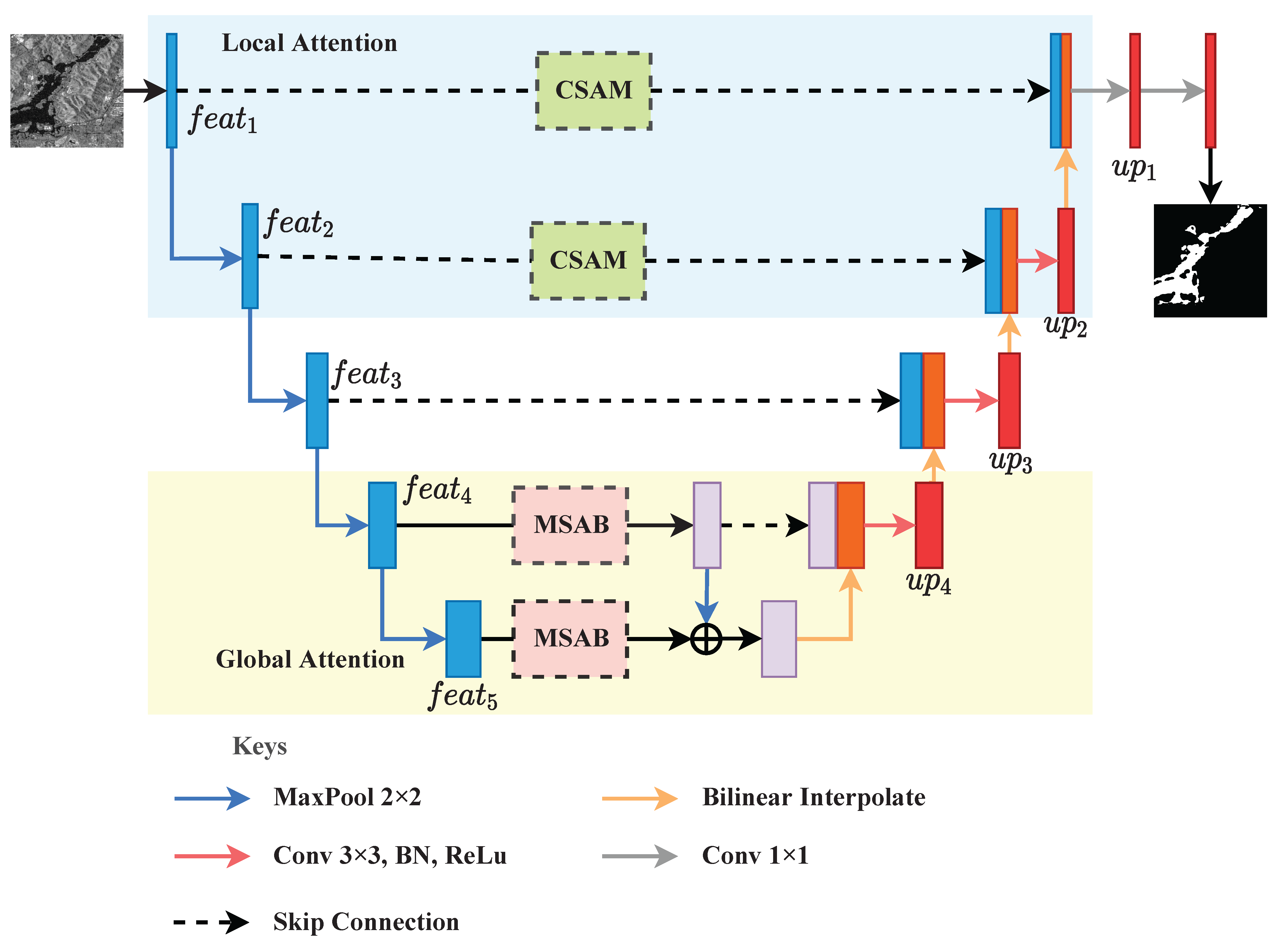
4.2. Overall Structure of the Proposed HA-Unet
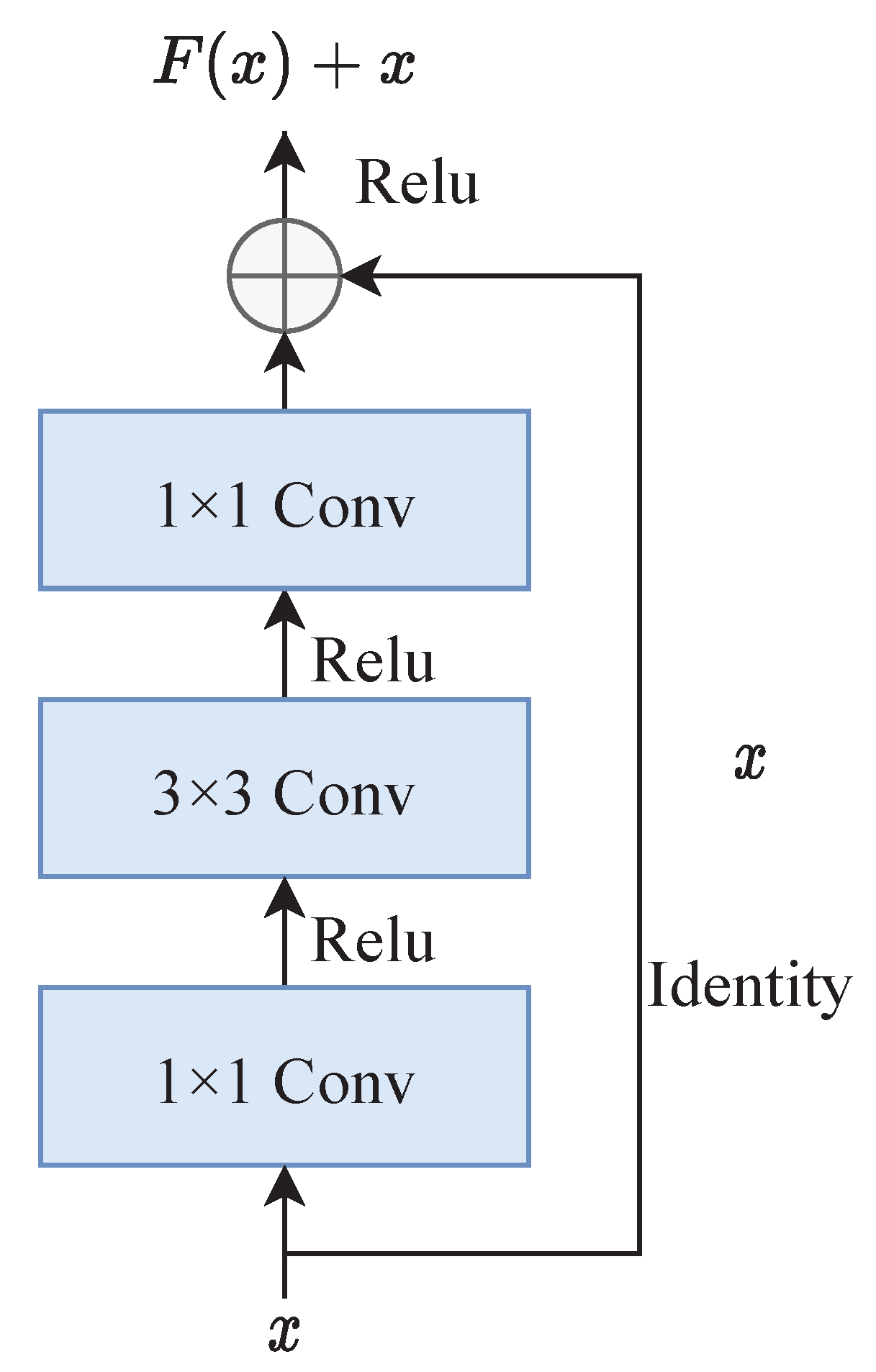
4.2.1. Backbone
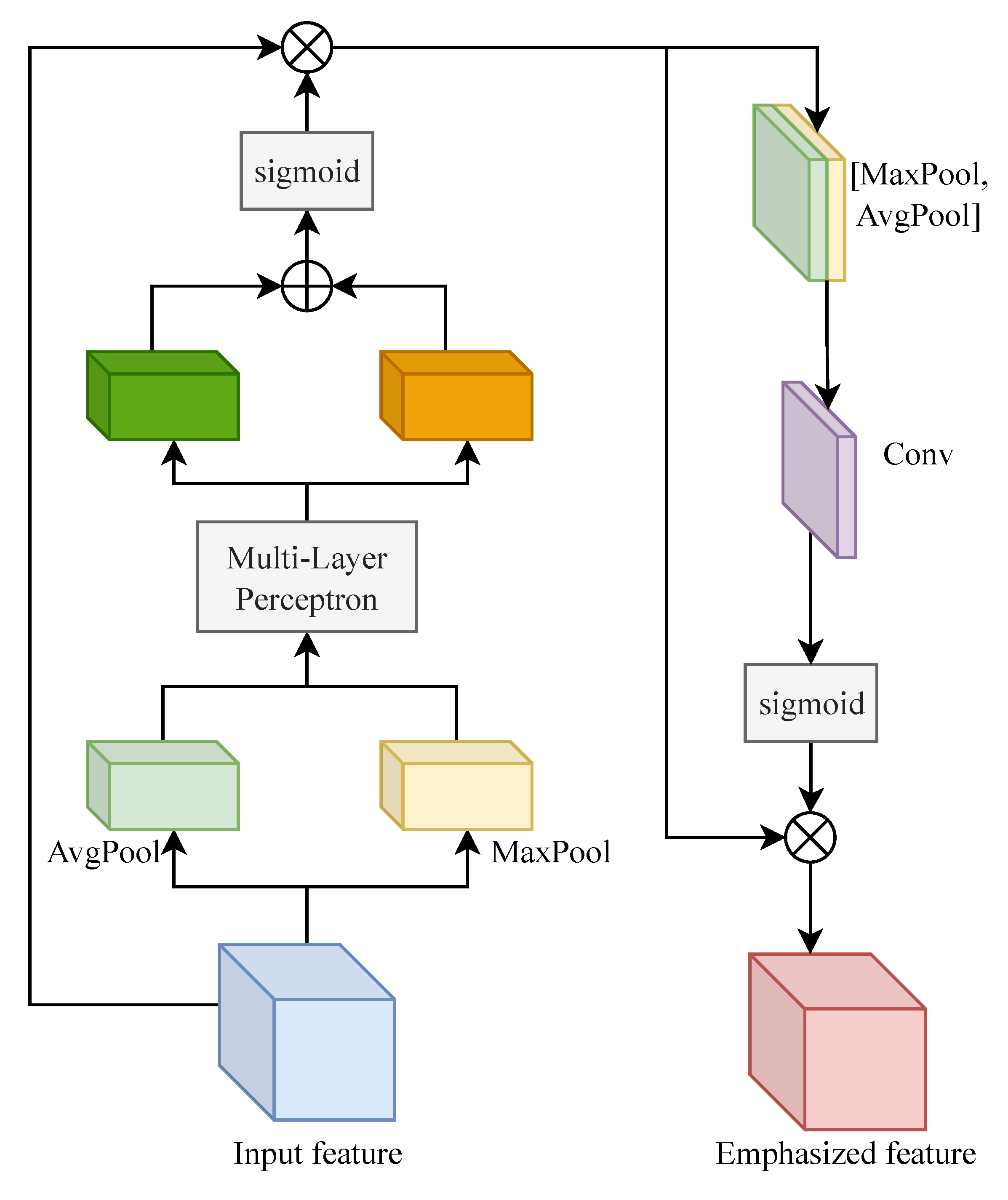
4.2.2. CSAM
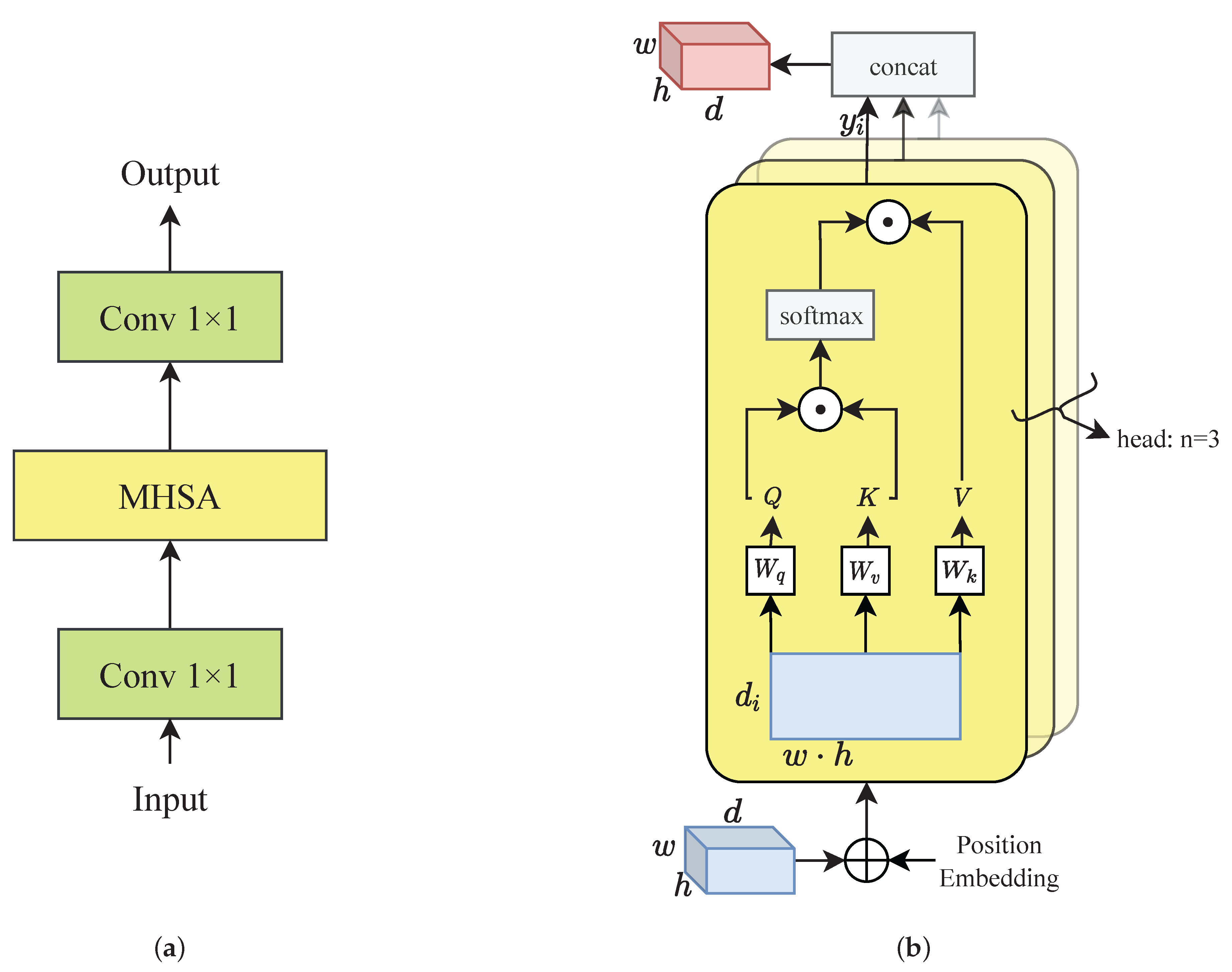
4.2.3. MSAB
5. Experimental Results
5.1. Training
5.2. Results
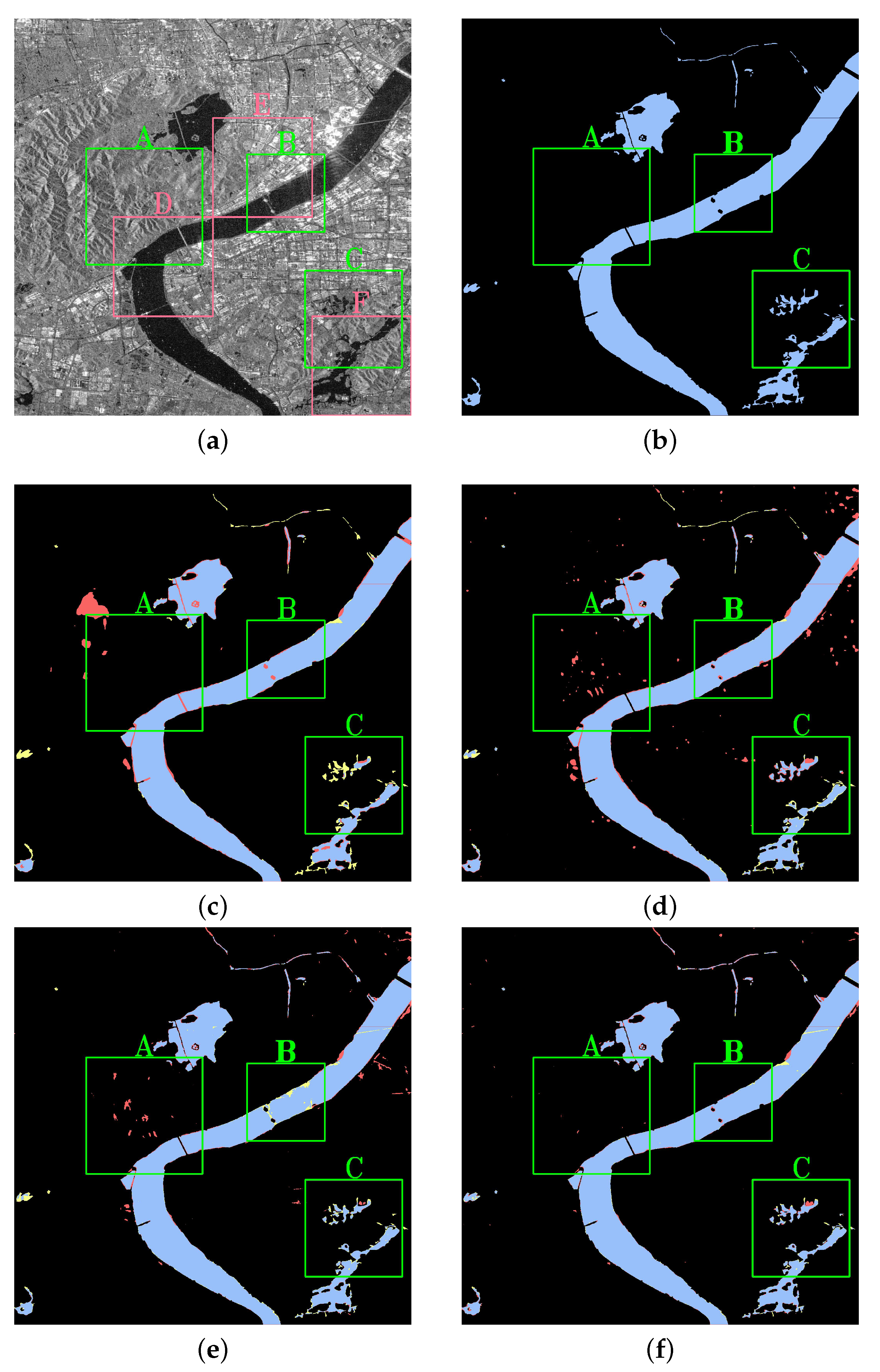
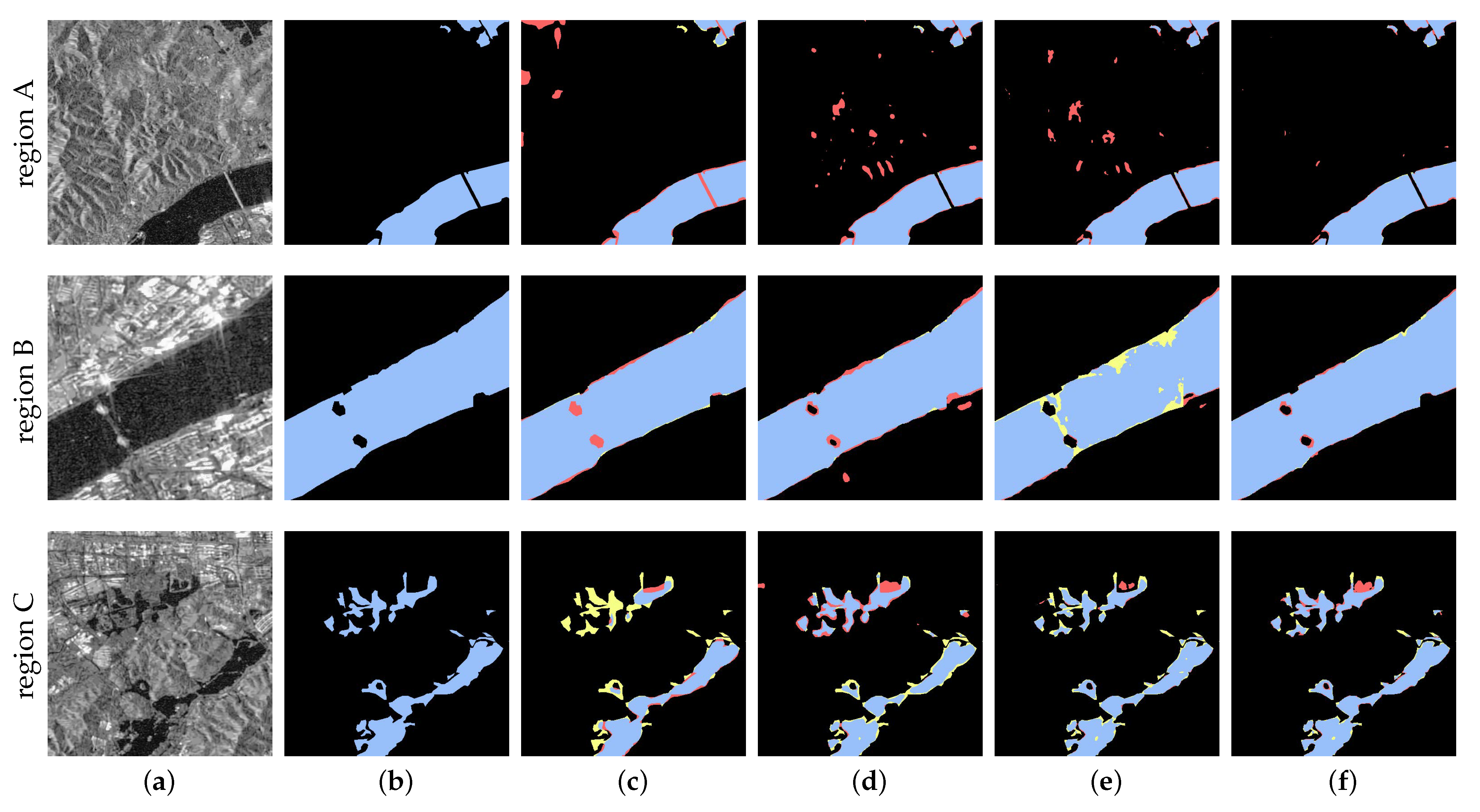
5.3. Visualization
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ai, J.; Tian, R.; Luo, Q.; Jin, J.; Tang, B. Multi-Scale Rotation-Invariant Haar-Like Feature Integrated CNN-Based Ship Detection Algorithm of Multiple-Target Environment in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10070–10087. [Google Scholar] [CrossRef]
- Ai, J.; Mao, Y.; Luo, Q.; Xing, M.; Jiang, K.; Jia, L.; Yang, X. Robust CFAR Ship Detector Based on Bilateral-Trimmed-Statistics of Complex Ocean Scenes in SAR Imagery: A Closed-Form Solution. IEEE Trans. Aerosp. Electron. Syst. 2021, 57, 1872–1890. [Google Scholar] [CrossRef]
- Ai, J.; Mao, Y.; Luo, Q.; Jia, L.; Xing, M. SAR Target Classification Using the Multikernel-Size Feature Fusion-Based Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Ai, J.; Luo, Q.; Yang, X.; Yin, Z.; Xu, H. Outliers-Robust CFAR Detector of Gaussian Clutter Based on the Truncated-Maximum-Likelihood- Estimator in SAR Imagery. IEEE Trans. Aerosp. Electron. Syst. 2020, 21, 2039–2049. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Sun, G.-C.; Chen, J.; Li, M.; Hu, Y.; Bao, Z. Water Body Detection in High-Resolution SAR Images With Cascaded Fully-Convolutional Network and Variable Focal Loss. IEEE Trans. Geosci. Remote Sens. 2021, 59, 316–332. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Z.; Zeng, C.; Xia, G.-S.; Shen, H. An Urban Water Extraction Method Combining Deep Learning and Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 769–782. [Google Scholar] [CrossRef]
- Li, Y.; Yang, Y.; Zhao, Q. Urban Riverway Extraction from High-Resolution SAR Image Based on Blocking Segmentation and Discontinuity Connection. Remote Sens. 2020, 12, 4014. [Google Scholar] [CrossRef]
- Bao, L.; Lv, X.; Yao, J. Water Extraction in SAR Images Using Features Analysis and Dual-Threshold Graph Cut Model. Remote Sens. 2021, 13, 3465. [Google Scholar] [CrossRef]
- Huang, X.; Xie, C.; Fang, X.; Zhang, L. Combining Pixel- and Object-Based Machine Learning for Identification of Water-Body Types From Urban High-Resolution Remote-Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2097–2110. [Google Scholar] [CrossRef]
- Zeng, C.; Wang, J.; Huang, X.; Bird, S.; Luce, J.J. Urban Water Body Detection from the Combination of High-Resolution Optical and SAR Images. In Proceedings of the 2015 Joint Urban Remote Sensing Event, Lausanne, Switzerland, 30 March–1 April 2015; pp. 1–4. [Google Scholar]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Liao, H.-Y.; Wen, T.-H. Extracting Urban Water Bodies from High-Resolution Radar Images: Measuring the Urban Surface Morphology to Control for Radar’s Double-Bounce Effect. Int. J. Appl. Earth Obs. Geoinf. 2020, 85, 102003. [Google Scholar] [CrossRef]
- Giustarini, L.; Hostache, R.; Matgen, P.; Schumann, G.J.-P.; Bates, P.D.; Mason, D.C. A Change Detection Approach to Flood Mapping in Urban Areas Using TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2417–2430. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Wu, L.; Huang, Y.; Guo, Z.; Zhao, J.; Li, N. Water-Body Segmentation for SAR Images: Past, Current, and Future. Remote Sens. 2022, 14, 1752. [Google Scholar] [CrossRef]
- Ai, J.; Wang, F.; Mao, Y.; Luo, Q.; Yao, B.; Yan, H.; Xing, M.; Wu, Y. A Fine PolSAR Terrain Classification Algorithm Using the Texture Feature Fusion-Based Improved Convolutional Autoencoder. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Kim, M.U.; Oh, H.; Lee, S.-J.; Choi, Y.; Han, S. Deep Learning Based Water Segmentation Using KOMPSAT-5 SAR Images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2021. [Google Scholar]
- Mason, D.C.; Giustarini, L.; Garcia-Pintado, J.; Cloke, H.L. Detection of Flooded Urban Areas in High Resolution Synthetic Aperture Radar Images Using Double Scattering. Int. J. Appl. Earth Obs. Geoinf. 2021, 28, 150–159. [Google Scholar] [CrossRef] [Green Version]
- Denbina, M.; Towfic, Z.J.; Thill, M.; Bue, B.; Kasraee, N.; Peacock, A.; Lou, Y. Flood Mapping Using UAVSAR and Convolutional Neural Networks. In Proceedings of the 2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 3247–3250. [Google Scholar]
- Xue, W.; Yang, H.; Wu, Y.; Kong, P.; Xu, H.; Wu, P.; Ma, X. Water Body Automated Extraction in Polarization SAR Images With Dense-Coordinate-Feature-Concatenate Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12073–12087. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Geng, J.; Wang, H.; Fan, J.; Ma, X. SAR Image Classification via Deep Recurrent Encoding Neural Networks. IEEE Trans. Geosci. Remote Sens. 2021, 56, 2255–2269. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, F. Comparing Methods for Segmenting Supra-Glacial Lakes and Surface Features in the Mount Everest Region of the Himalayas Using Chinese GaoFen-3 SAR Images. Remote Sens. 2021, 13, 2429. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.; Wang, F.; Zhou, Y.; Ji, J.; Xiong, Y. Flood Inundation Region Extraction Method Based on Sentinel-1 SAR Data. J. Catastrophol. 2021, 36, 214–220. [Google Scholar]
- Pai, M.; Mehrotra, V.; Aiyar, S.; Verma, U.; Pai, R. Automatic Segmentation of River and Land in SAR Images: A Deep Learning Approach. In Proceedings of the 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering, Sardinia, Italy, 3–5 June 2019; pp. 15–20. [Google Scholar]
- Lalchhanhima, R.; Saha, G.; Sur, S.; Kandar, D. Water body segmentation of Synthetic Aperture Radar image using Deep Convolutional Neural Networks. Microprocess. Microsyst. 2021, 87, 104360. [Google Scholar] [CrossRef]
- Li, J.; Wang, C.; Xu, L.; Wu, F.; Zhang, H.; Zhang, B. Multitemporal Water Extraction of Dongting Lake and Poyang Lake Based on an Automatic Water Extraction and Dynamic Monitoring Framework. Remote Sens. 2021, 13, 865. [Google Scholar] [CrossRef]
- Ren, Y.; Li, X.; Yang, X.; Xu, H. Development of a Dual-Attention U-Net Model for Sea Ice and Open Water Classification on SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shamshiri, R.; Nahavandchi, H.; Motagh, M. Persistent Scatterer Analysis Using Dual-Polarization Sentinel-1 Data: Contribution From VH Channel. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3105–3112. [Google Scholar] [CrossRef]
- Di Martino, G.; Di Simone, A.; Iodice, A.; Poggi, G.; Riccio, D.; Verdoliva, L. Scattering-Based SARBM3D. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2131–2144. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A Survey of Visual Transformers. arXiv 2022, arXiv:2111.06091. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Zheng, Z.; Yang, C.; Zhao, J.; Feng, Y. Remote Sensing Geological Classification of Sea Islands and Reefs Based on Deeplabv3+. In Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing, Shenzhen, China, 27–29 May 2022; pp. 1907–1910. [Google Scholar]
- Qiu, J.; Chen, C.; Liu, S.; Zeng, B. SlimConv: Reducing Channel Redundancy in Convolutional Neural Networks by Weights Flipping. IEEE Trans. Image Process. 2021, 30, 6434–6445. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 2018 European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sentinel-1A | Parameter |
|---|---|
| Product format | GRD |
| Product level | Level-1 |
| Beam mode | Interferometric Wide swath |
| Polarization | VH |
| Resolution | 20 × 22 m |
| Band | C |
| Number of looks | 5 × 1 |
| Size | 2048 × 2048 pixels |
| Layer Name | Operator | Output Name | Output Size | Output Dimension |
|---|---|---|---|---|
| conv1 | 7 × 7 Conv, stride = 2, padding = 3 | 256 × 256 | 64 | |
| conv2x | 3 × 3 Pool, stride = 2 | 128 × 128 | 64 | |
| conv3x | 64 × 64 | 512 | ||
| conv4x | 32 × 32 | 1024 | ||
| conv5x | 16 × 16 | 2048 |
| Prediction | |||
|---|---|---|---|
| Flood | Background | ||
| Ground Truth | flood | TP | FN |
| background | FP | TN | |
| DeeplabV3+ | Unet | HA-Unet | |
|---|---|---|---|
| IoU(%) | 88.56 | 87.04 | 93.06 |
| PA(%) | 90.05 | 87.71 | 95.35 |
| Unet | CSAM+Unet | MSAB+Unet | HA-Unet | |
|---|---|---|---|---|
| IoU(%) | 87.04 | 90.77 | 87.87 | 93.06 |
| PA(%) | 87.71 | 91.89 | 90.55 | 95.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.; Wu, H.; Huang, J.; Zhong, H.; He, M.; Su, M.; Yu, G.; Wang, M.; Zhang, J. HA-Unet: A Modified Unet Based on Hybrid Attention for Urban Water Extraction in SAR Images. Electronics 2022, 11, 3787. https://doi.org/10.3390/electronics11223787
Song H, Wu H, Huang J, Zhong H, He M, Su M, Yu G, Wang M, Zhang J. HA-Unet: A Modified Unet Based on Hybrid Attention for Urban Water Extraction in SAR Images. Electronics. 2022; 11(22):3787. https://doi.org/10.3390/electronics11223787
Chicago/Turabian StyleSong, Huina, Han Wu, Jianhua Huang, Hua Zhong, Meilin He, Mingkun Su, Gaohang Yu, Mengyuan Wang, and Jianwu Zhang. 2022. "HA-Unet: A Modified Unet Based on Hybrid Attention for Urban Water Extraction in SAR Images" Electronics 11, no. 22: 3787. https://doi.org/10.3390/electronics11223787
APA StyleSong, H., Wu, H., Huang, J., Zhong, H., He, M., Su, M., Yu, G., Wang, M., & Zhang, J. (2022). HA-Unet: A Modified Unet Based on Hybrid Attention for Urban Water Extraction in SAR Images. Electronics, 11(22), 3787. https://doi.org/10.3390/electronics11223787