



Anomaly-PTG: A Time Series Data-Anomaly-Detection Transformer Framework in Multiple Scenarios


Abstract
:1. Introduction
2. Related Works
2.1. Multivariable Exception Detection
2.2. Transformer Models for Time Series
3. Methodology
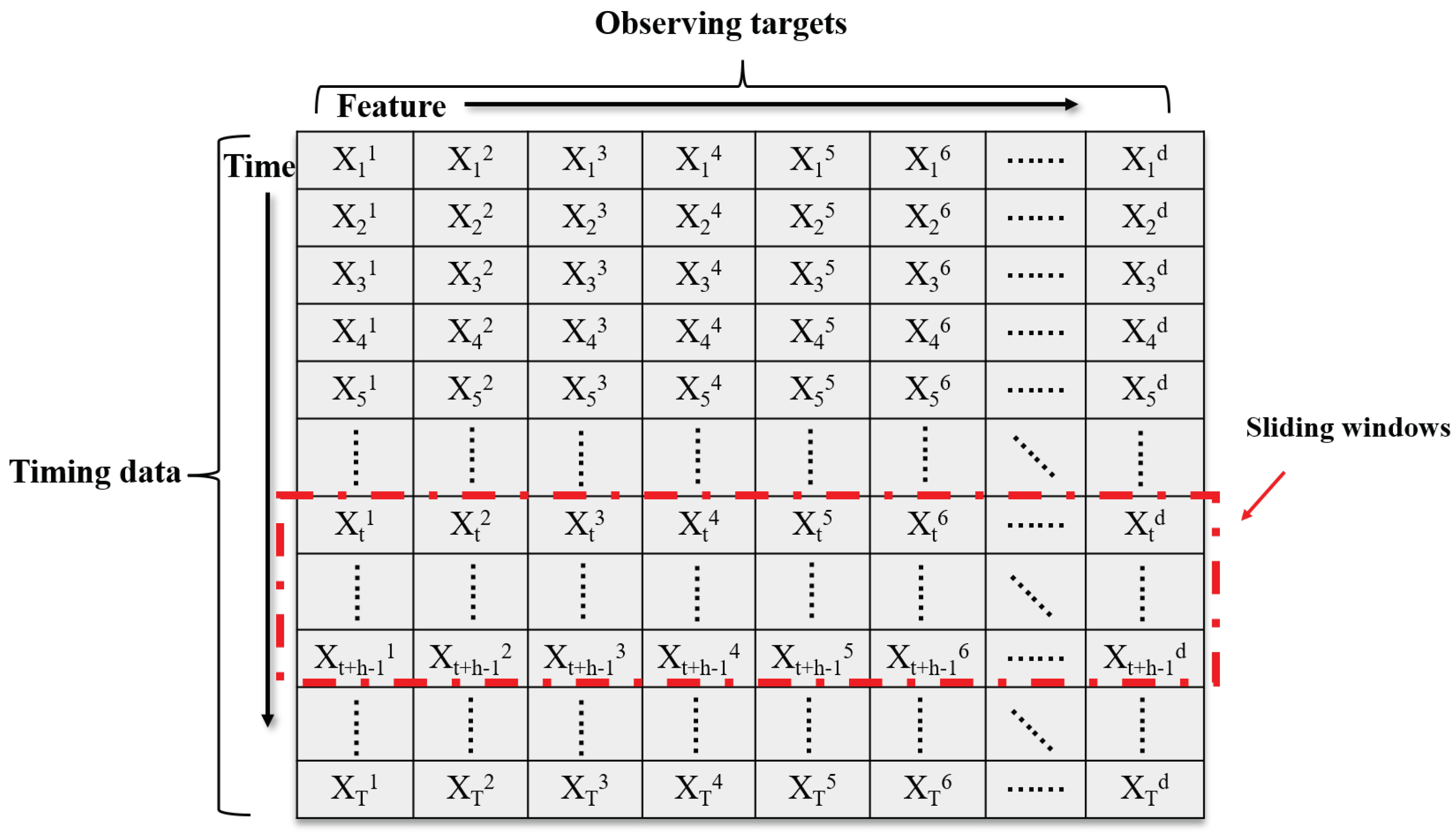
3.1. Problem Statement
3.2. Data Preprocessing
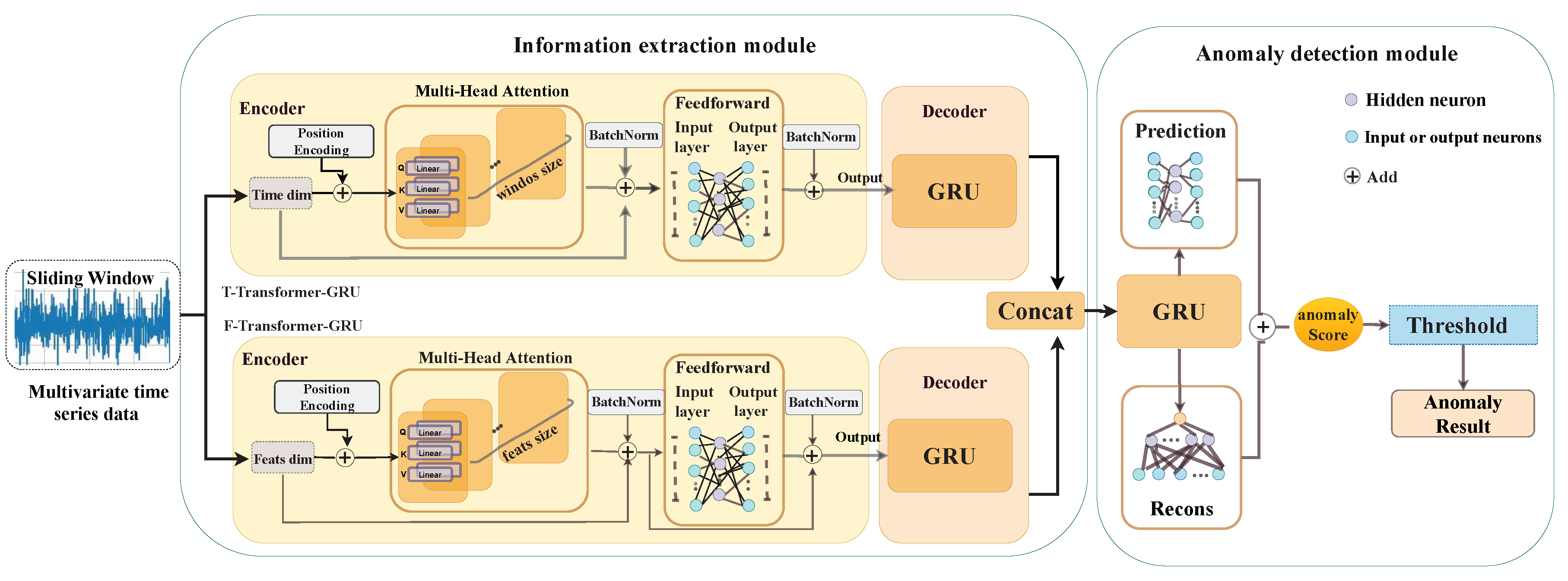
3.3. Anomaly-PTG Network
| Algorithm 1 Anomaly-PTG model training algorithm: |
| Input: Train Datasets; |
| , parameter and ; |
| Output: Trained Anomaly-PTG model; |
| EPOCH ← 1; Labels y = {y1, y2 … yt … yt+k}; |
| for t in range (t + k) do: |
| ; |
| end for |
| epoch ← epoch + 1 |
| UNTIL epoch = end; |
| Test Anomaly-PTG model; |
| Threshold bf = Brute-force Algorithm; |
| for j = (t + k + 1) in range T |
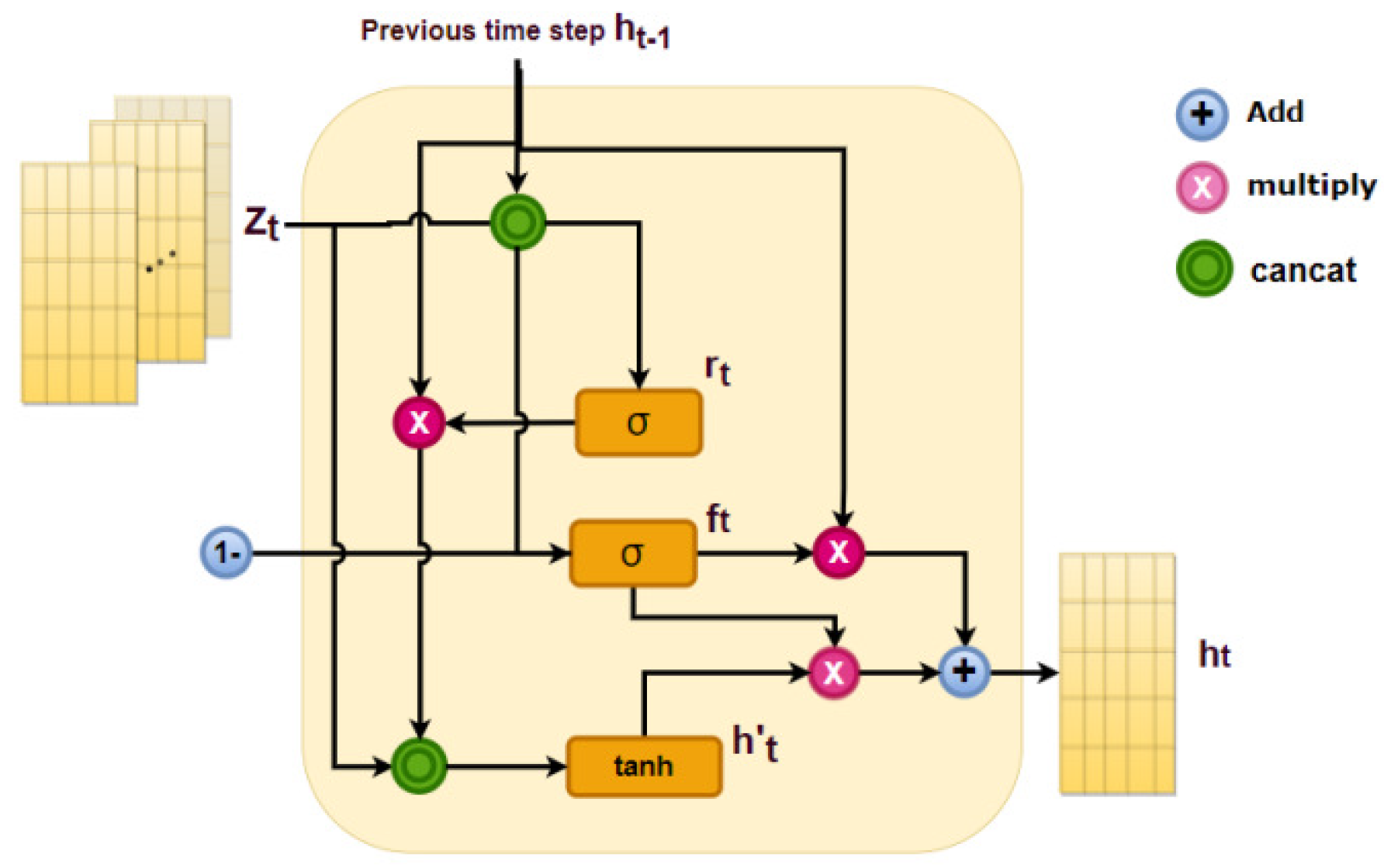
3.4. Information Extraction Module
Transformer-GRU
3.5. Anomaly Detection Module
3.5.1. Reconstruction Network
3.5.2. Threshold Selection
| Algorithm 2 Brute-force Algorithm: |
| Input: |
| anomaly_scores, true_anomalies, start = 0.01, end = 2, step_num = 100; |
| Output: |
| Finding best f1 = bf; |
| search_step, search_range, search_lower_bound = step_num, end-start, start; |
| threshold = search_lower_bound; |
| m = (0.0, 0.0), m_t = 0.0; |
| for i in range (search_step): |
| threshold += search_range / float(search_step); |
| target←Calculate the F1 of the current threshold; |
| if target[0] > m[0]: ← Compares whether the current F1 is the highest; |
| m_t = threshold; |
| m = target; |
| end for |
| gain threshold = bf; |
3.5.3. Prediction Network
3.5.4. Anomaly Scores
4. Experiment and Analysis
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Parameters and Baseline Methods
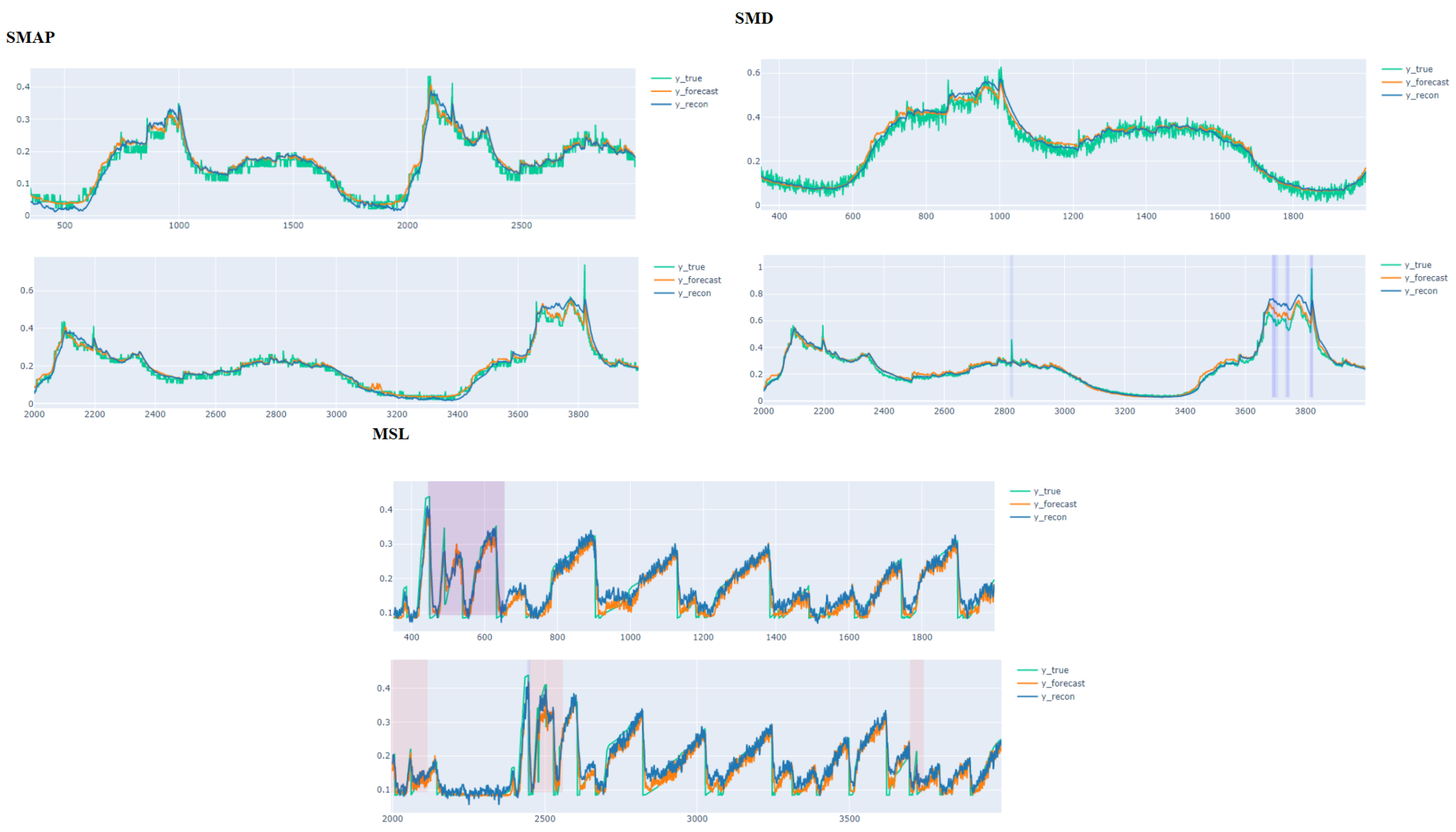
4.4. Results and Analysis
4.5. Generalization Ability Test
4.6. Ablation Study
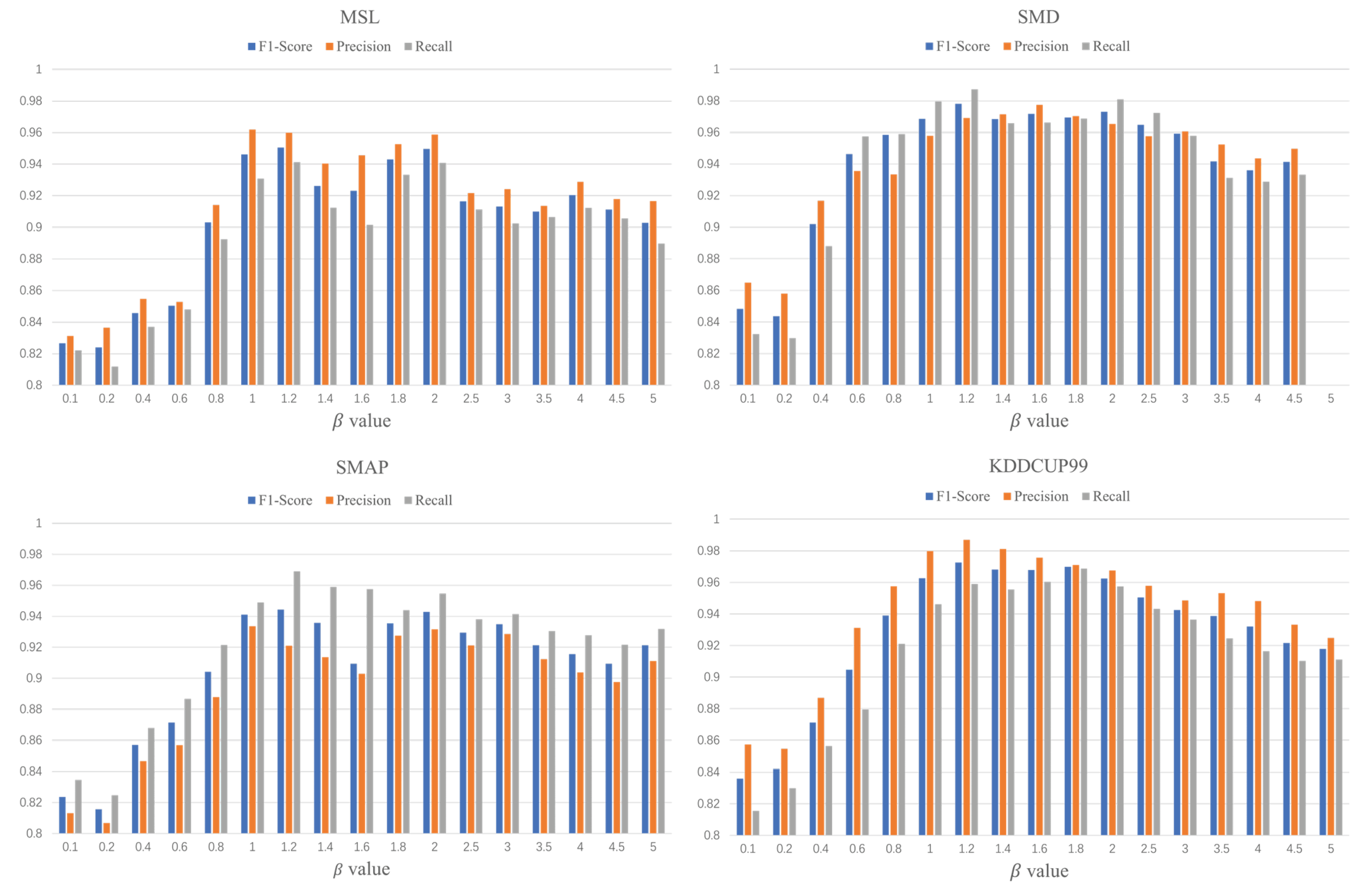
4.7. Parametric Analysis
4.8. Model Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tziolas, T.; Papageorgiou, K.; Theodosiou, T.; Papageorgiou, E.; Mastos, T.; Papadopoulos, A. Autoencoders for Anomaly Detection in an Industrial Multivariate Time Series Dataset. Eng. Proc. 2022, 18, 8023. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Tan, M.; Lee, Z.S. Anomaly Detection in Cyber Physical Systems Using Recurrent Neural Networks. In Proceedings of the 2017 IEEE 18th International Symposium on High Assurance Systems Engineering (HASE), Singapore, 12–14 January 2017; pp. 140–145. [Google Scholar] [CrossRef]
- Gopali, S.; Siami Namin, A. Deep Learning-Based Time-Series Analysis for Detecting Anomalies in Internet of Things. Electronics 2022, 11, 3205. [Google Scholar] [CrossRef]
- Zheng, X.; Cai, Z. Privacy-Preserved Data Sharing Towards Multiple Parties in Industrial IoTs. IEEE J. Sel. Areas Commun. 2020, 38, 968–979. [Google Scholar] [CrossRef]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep Learning for IoT Big Data and Streaming Analytics: A Survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef] [Green Version]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. Sigkdd Explor. 2018, 382–390. [Google Scholar]
- Ren, H.; Xu, B.; Wang, Y.; Yi, C.; Huang, C.; Kou, X.; Xing, T.; Yang, M.; Tong, J.; Zhang, Q. Time-Series Anomaly Detection Service at Microsoft. In Proceedings of the Kdd’19: 25th ACM SIGKDD International Conferencce on Knowledge Discovery and Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019; pp. 3009–3017. [Google Scholar] [CrossRef] [Green Version]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A review on outlier/anomaly detection in time series data. ACM Comput. Surv. 2020, 54, 1–33. [Google Scholar] [CrossRef]
- Salahuddin, M.A.; Bari, M.F.; Alameddine, H.A.; Pourahmadi, V.; Boutaba, R. Time-based Anomaly Detection using Autoencoder. In Proceedings of the 16th International Conference on Network and Service Management, CNSM 2020, Izmir, Turkey, 2–6 November 2020; pp. 1–9. [Google Scholar]
- Zhao, H.; Wang, Y.; Duan, J.; Huang, C.; Cao, D.; Tong, Y.; Xu, B.; Bai, J.; Tong, J.; Zhang, Q. Multivariate Time-Series Anomaly Detection via Graph Attention Network. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 841–850. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the 23rd European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2015, Bruges, Belgium, 22–24 April 2015. [Google Scholar]
- Song, Q. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Park, D.; Hoshi, Y.; Kemp, C.C. A Multimodal Anomaly Detector for Robot-Assisted Feeding Using an LSTM-Based Variational Autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef]
- Ghanbari, R.; Borna, K. Multivariate Time-Series Prediction Using LSTM Neural Networks. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network. SIGKDD Explor. 2019, 2828–2837. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Guan, S.; Zhao, B.; Dong, Z.; Gao, M.; He, Z. GTAD: Graph and Temporal Neural Network for Multivariate Time Series Anomaly Detection. Entropy 2022, 24, 759. [Google Scholar] [CrossRef] [PubMed]
- Deng, A.; Hooi, B. Graph Neural Network-Based Anomaly Detection in Multivariate Time Series. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, virtually, 2–9 February 2021; pp. 4027–4035. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2 (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In Proceedings of the Information Processing in Medical Imaging; Niethammer, M., Styner, M., Aylward, S., Zhu, H., Oguz, I., Yap, P.T., Shen, D., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 146–157. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate Anomaly Detection for Time Series Data with Generative Adversarial Networks. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2019: Text and Time Series; Tetko, I.V., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 703–716. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. USAD: UnSupervised Anomaly Detection on Multivariate Time Series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery (KDD ’20), Data Mining, Virtual Event, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 3395–3404. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; (Long and Short Papers). Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Online, 6–12 December 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Li, M.; Chen, Q.; Li, G.; Han, D. Umformer: A Transformer Dedicated to Univariate Multistep Prediction. IEEE Access 2022, 10, 101347–101361. [Google Scholar] [CrossRef]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 5244–5254. [Google Scholar]
- Xu, L.; Xu, K.; Qin, Y.; Li, Y.; Huang, X.; Lin, Z.; Ye, N.; Ji, X. TGAN-AD: Transformer-Based GAN for Anomaly Detection of Time Series Data. Appl. Sci. 2022, 12, 8085. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. Natl. Conf. Artif. Intell. 2020, 35, 11106–11115. [Google Scholar] [CrossRef]
- Tuli, S.; Casale, G.; Jennings, N.R. TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data. CoRR 2022. Available online: http://xxx.lanl.gov/abs/2201.07284 (accessed on 1 November 2022). [CrossRef]
- Chen, Z.; Chen, D.; Yuan, Z.; Cheng, X.; Zhang, X. Learning Graph Structures with Transformer for Multivariate Time Series Anomaly Detection in IoT. CoRR 2021. Available online: http://xxx.lanl.gov/abs/2104.03466 (accessed on 1 November 2022).
- Xu, J.; Wu, H.; Wang, J.; Long, M. Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A Transformer-Based Framework for Multivariate Time Series Representation Learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, Singapore, 14–18 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2114–2124. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 1 November 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | SMAP | MSL | SMD | KDDCUP99 |
|---|---|---|---|---|
| Entity | 55 | 27 | 28 | - |
| Dimension | 25 | 55 | 38 | 41 |
| Train data | 135,183 | 58,317 | 708,405 | 311,028 |
| Test data | 427,617 | 73,729 | 708,420 | 494,020 |
| Abnormal rate | 13.13% | 10.72% | 4.16% | 19.69% |
| Parameters | Value |
|---|---|
| window size | 100 |
| batch_size | 128 |
| Number of layers in GRU | 1 |
| Number of layers in Recon network | 1 |
| Fully-connected layers | 4 |
| Number of layers in transformer GRU | 1 |
| GRU hidden dimension | 300 |
| Forecast hidden dimension | 300 |
| Recon network hidden dimension | 300 |
| 1.2 | |
| 0.7 | |
| epochs | 100 |
| Datasets | Methods | P | R | F1 | AUC | R* |
|---|---|---|---|---|---|---|
| SMD | DAGAMM | 0.8872 | 0.9752 | 0.9291 | 0.9838 | 0.9602 |
| USAD | 0.9059 | 0.9814 | 0.9421 | 0.9857 | 0.9842 | |
| OmniAnomaly | 0.8784 | 0.9485 | 0.9120 | 0.9780 | 0.9138 | |
| MAD−GAN | 0.9994 | 0.7270 | 0.8417 | 0.9843 | 0.8279 | |
| GDN | 0.7469 | 0.9618 | 0.8408 | 0.9799 | 0.9063 | |
| TranAD | 0.9072 | 0.9973 | 0.9501 | 0.9862 | 0.9978 | |
| MTAD−GAT | 0.8412 | 0.9417 | 0.8886 | 0.9831 | 0.8947 | |
| Anomaly−PTG | 0.9692 | 0.9873 | 0.9781 | 0.9907 | 0.9988 | |
| MSL | DAGAMM | 0.7363 | 0.9648 | 0.8352 | 0.9618 | 0.7883 |
| USAD | 0.8048 | 0.9810 | 0.8842 | 0.9736 | 0.8965 | |
| OmniAnomaly | 0.7942 | 0.9897 | 0.8825 | 0.9697 | 0.9076 | |
| MAD−GAN | 0.8516 | 0.9921 | 0.9164 | 0.9733 | 0.9412 | |
| GDN | 0.8908 | 0.9917 | 0.9385 | 0.9789 | 0.9846 | |
| TranAD | 0.9037 | 0.9999 | 0.9494 | 0.9807 | 0.9995 | |
| MTAD−GAT | 0.8189 | 0.9888 | 0.8958 | 0.9874 | 0.9243 | |
| Anomaly−PTG | 0.9599 | 0.9412 | 0.9505 | 0.9846 | 0.9909 | |
| SMAP | DAGAMM | 0.8069 | 0.9912 | 0.8896 | 0.9722 | 0.9172 |
| USAD | 0.7998 | 0.9627 | 0.8737 | 0.9796 | 0.8779 | |
| OmniAnomaly | 0.8008 | 0.9638 | 0.8747 | 0.9748 | 0.8934 | |
| MAD−GAN | 0.8257 | 0.9579 | 0.8869 | 0.9807 | 0.8846 | |
| GDN | 0.8192 | 0.9452 | 0.8777 | 0.9812 | 0.8667 | |
| TranAD | 0.8043 | 0.9999 | 0.8915 | 0.9842 | 0.9265 | |
| MTAD−GAT | 0.8666 | 0.9406 | 0.9021 | 0.9776 | 0.9138 | |
| Anomaly−PTG | 0.9210 | 0.9690 | 0.9443 | 0.9894 | 0.9743 |
| Datasets | Methods | P | R | F1 | AUC | R* |
|---|---|---|---|---|---|---|
| KDDCUP99 | DAGAMM | 0.8872 | 0.9973 | 0.9390 | 0.8790 | 0.9780 |
| USAD | 0.9845 | 0.9465 | 0.9651 | 0.8846 | 0.9927 | |
| OmniAnomaly | 0.9015 | 0.8329 | 0.8658 | 0.8613 | 0.8554 | |
| MAD−GAN | 0.8963 | 0.7465 | 0.8145 | 0.8778 | 0.7368 | |
| GDN | 0.9124 | 0.9673 | 0.9345 | 0.8565 | 0.9781 | |
| TranAD | 0.9518 | 0.9814 | 0.9664 | 0.9068 | 0.9999 | |
| MTAD−GAT | 0.9109 | 0.9862 | 0.9471 | 0.8779 | 0.9974 | |
| Anomaly−PTG | 0.9869 | 0.9590 | 0.9727 | 0.9112 | 0.9999 |
| Technology | Time | Feats | SMD | MSL | SMAP | KDDCUP99 | AVGF1 |
|---|---|---|---|---|---|---|---|
| Transformer | — | w/o | 0.9189 | 0.8742 | 0.8727 | 0.8923 | 0.8895 |
| w/o | — | 0.8812 | 0.9031 | 0.8881 | 0.9299 | 0.9005 | |
| — | — | 0.9578 | 0.9253 | 0.9163 | 0.9518 | 0.9378 | |
| Parallel Transformer-GRU | — | — | 0.9781 | 0.9505 | 0.9443 | 0.9727 | 0.9614 |
| Technology | Recon | Predicet | SMD | MSL | SMAP | KDDCUP99 | AVGF1 |
|---|---|---|---|---|---|---|---|
| — | w/o | 0.9553 t | 0.8961 | 0.9284 | 0.9583 | 0.9345 | |
| Parallel Transformer-GRU | w/o | — | 0.9665 | 0.8366 | 0.8657 | 0.9023 | 0.8927 |
| — | — | 0.9781 | 0.9505 | 0.9443 | 0.9727 | 0.9614 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, G.; Yang, Z.; Wan, H.; Li, M. Anomaly-PTG: A Time Series Data-Anomaly-Detection Transformer Framework in Multiple Scenarios. Electronics 2022, 11, 3955. https://doi.org/10.3390/electronics11233955
Li G, Yang Z, Wan H, Li M. Anomaly-PTG: A Time Series Data-Anomaly-Detection Transformer Framework in Multiple Scenarios. Electronics. 2022; 11(23):3955. https://doi.org/10.3390/electronics11233955
Chicago/Turabian StyleLi, Gang, Zeyu Yang, Honglin Wan, and Min Li. 2022. "Anomaly-PTG: A Time Series Data-Anomaly-Detection Transformer Framework in Multiple Scenarios" Electronics 11, no. 23: 3955. https://doi.org/10.3390/electronics11233955
APA StyleLi, G., Yang, Z., Wan, H., & Li, M. (2022). Anomaly-PTG: A Time Series Data-Anomaly-Detection Transformer Framework in Multiple Scenarios. Electronics, 11(23), 3955. https://doi.org/10.3390/electronics11233955