1. Introduction
Applications such as the Internet of Vehicles [
1], cloud computing and flow media bring tremendous challenges to optical networks, especially in terms of bandwidth and flexibility [
2]. To tackle these challenges, optical networks are evolving from traditional fixed wavelength grid architectures to flexible and adaptive architectures [
3]. For the evolution of optical networks, elastic optical networks (EONs) are widely accepted as the critical solution for next-generation optical networks due to their flexible, heterogeneous, low-cost, and reconfigurable characteristics. In EONs, multiple modulation formats exist to match different data rates and bandwidth requirements. Therefore, modulation format identification (MFI) algorithms need to be deployed in digital receivers for correct reception and demodulation.
Furthermore, the digital signal processing (DSP) flow of optical fiber communication digital receivers includes multiple steps to compensate for different signal impairments. Some of these steps, such as carrier frequency offset estimation and phase recovery, require a priori information on the modulation format to work properly or achieve excellent results. Therefore, it is necessary to determine the modulation format of signals before performing these steps to compensate for the signal.
Overall, MFI is an important issue in the field of optical communications, both from the perspective of correct reception and high-performance compensation. In order to satisfy the mentioned signal identification demands of digital receivers in EONs, various MFI methods have recently been proposed [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]. According to technical characteristics, these methods can be classified into the following categories.
Based on aided data, such as training sequence and radio frequency (RF), various MFI methods have recently been proposed [
4,
5,
6]. For example, an RF-pilot aided MFI method is proposed in [
4] to enable a hitless flexible transceiver. Additionally aided by RF data, MFI based on frequency offset loading are proposed in [
5,
6]. These methods often achieve excellent modulation format independence identify performance. However, they require additional cost to aid identification, which results in a reduction in the effective rate or bandwidth utilization.
To avoid the loss of efficiency, a large number of MFI methods are based on statistical features such as signal cumulants, amplitude histograms or peak-to-average power ratio (PAPR) [
7,
8,
9,
10,
11,
12,
13,
14,
15]. These methods classify different modulation formats by setting the threshold of the statistical variable. For example, the fourth order cumulants of received signals are calculated in the literature [
7] for the distinction of on-off keying (OOK), binary phase shift keying (BPSK), quadrature phase-shift keying (QPSK) and 16 Quadrature amplitude modulation (QAM). As for the amplitude features, a scheme based on the intensity profile is proposed in [
8] to identify QPSK and 8/16/32/64QAM. For the identify of QPSK and 16/32/64QAM, a method based on the information entropy is proposed in [
9], which is calculated from the amplitude distribution. In [
10], the asynchronous amplitude histograms are used to distinguish OOK, differential QPSK (DQPSK) and 16QAM. As for the MFI methods based on the PAPR features, a simple method based on the evaluation of PAPR under the particular optical signal-to-noise ratio (OSNR) is proposed in [
11]. Moreover, by using some transformations, more hidden features can be obtained. These transformations could be fourth-power [
12], nonlinear power transformation [
13] or others [
14,
15]. MFI methods based on statistical features utilize the properties of the received signals and avoid additional overhead. However, the identification performance in the presence of multiple PSK modulation formats needs to be improved because the PSK signals have the same amplitude histograms.
Applying the Stokes transformation, a variety of MFI methods in Stokes space have been proposed [
16,
17,
18,
19,
20]. By mapping the received signals into Stokes space and extracting the density distributions, a low complexity MFI method is proposed in [
16]. When different energy level features of different modulation formats are considered, a density peak-based MFI method is proposed in [
17]. To reduce the number of clusters in Stokes space, the scheme in [
18] executes the square operation before Stokes mapping, and with principal component analysis (PCA), achieves a better performance with lower complexity. For the features extraction, two Stokes space analysis schemes based on singular value decomposition (SVD) and radon transformation are proposed in [
19], respectively. For the clustering algorithm in Stokes space, an improved particle swarm optimization clustering algorithm combined with a two dimension Stokes plane is proposed in [
20]. Stokes space-based MFI methods are insensitive to carrier phase noise and frequency offset, which saves many MFI preprocessing procedures. The problem is that using these methods make it difficult to identify the high order modulation format because the Stokes mapping operating will greatly increase the difficulty of clustering and pattern recognition in Stokes space. This is why there is so much literature devoted to reducing the number of clustering in Stokes space [
18,
20,
34]. Recently, many MFI methods based on machine learning have been proposed [
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]. For example, an MFI method based on deep neural networks (DNNs) combined with amplitude histograms is proposed in [
21], realizing the identification of QPSK, 16QAM and 64QAM. By additionally utilizing DNNs, the identification of four modulation formats is realized in [
22], by combining the density distributions in Stokes axes. For the convolutional neural networks (CNNs), a lightweight CNNs-based MFI scheme in Stokes plane is proposed in [
23] for the identification of QPSK, 8PSK and 16/32/64QAM. Another method in [
24] is based on convolutional the neural network and asynchronous delay-tap plot, achieving the recognition of 16/32/64QAM by using image processing. More MFI method-based CNNs are proposed in [
25,
26]. For the application of the multi-task neural networks in MFI, various of MFI methods are proposed in [
27,
28,
29,
30]. Other MFI methods based on machine learning can be found in [
31,
32,
33]. These MFI methods can achieve fast and high-accuracy identification after good training. The challenge is that images often contain too many pixels, and both computation and storage are enormous projects. What is more, to enhance the tolerance of phase rotation, the machine learning MFI method based on constellation pattern recognition needs additional training of constellation patterns under different rotations.
In this paper, a blind MFI based on principal component analysis and singular value decomposition is proposed for the identification of seven modulation formats of BPSK, QPSK, 8PSK and 8/16/32/64QAM. In our methods, the square operation of received signals and PCA is used for the removal of phase noise, so that both amplitude and phase information can be available for the identification of seven modulation formats. After PCA, the density distribution matrix of the received constellation is calculated, and then SVD is applied to the matrix to achieve noise removal and trend smoothing. Finally, a support vector machine (SVM) is used for identification according to the smoothed matrix.
Without the aided data and Stokes mapping, the decreasing effectiveness of the system and increasing complexity is avoided, which would occur in data-aided-based MFI and Stokes space-based MFI, respectively. Due to the proposed correcting method based on PCA, the phase information is available to improve the accuracy of identification, and to extend our method to the scenario even with multiple PSK modulation formats, which will be unavailable in the MFI methods based on amplitude information. In order to avoid over-fitting in the machine learning-based MFI method, a distribution matrix instead of the image is utilized for identification.
The remainder of this paper is organized as follows. In
Section 2, our MFI method based on PCA and SVD is described, and the methodology is explained by mathematical equations and figures. The setup of the verification system and the performance of proposed MFI methods is discussed in
Section 3.
Section 4 outlines our conclusions and discussions about our method.
2. Principle of MFI Method Based on PCA and SVD
The receiver DSP flow used in the optical digital coherent receiver including the proposed MFI is shown in
Figure 1. All the algorithms (except MFI) in flow could be divided into a modulation format independent DSP and modulation format dependent DSP. First, the modulation format independent DSPs are used to compensate the impairment of signals. Then, based on the compensated signals, MFI is executed to get the modulation format. Lastly, the modulation format dependent DSPs are configured according to the MFI results.
During the stage of modulation format independent DSPs, the received signals are normalized to the standard power at first. Then, QI compensation is used to mitigate the mismatch within the I-branch and Q-branch signals caused by receiver. After that the chromatic dispersion (CD) compensation and the nonlinear (NL) compensation are performed to compensate for the channel impairment, and the timing recovery is used to reduce timing error. Before MFI, the constant modulus algorithm (CMA) equalization is taken to compensate for residual impairment.
After MFI, the modulation formats undergo cascaded multi-modulus algorithm (CMMA), frequency offset estimation, carrier phase recovery, decision and decoding, respectively.
Figure 1b shows the schematic of the proposed MFI method based on PCA and SVD, which consists of five crucial steps: square operation and average power detection; principal axes correction based on PCA; density distribution analysis (DDA); denoising and smoothing based on SVD; SVM classification.
2.1. Square Operation and Average Value Detection
In the proposed MFI method, the square operation is executed for the signals after CMA firstly because the symmetry of constellation will degenerate after this operation. For example, signals with a constellation rotational symmetry with a degree of 4 will only have a degree of 2 after the square operation.
To illustrate the changes after square operation, consider signals with the following form:
where
represents the
-th complex signal in the symbol sequence with the modulated amplitude of
and the modulated phase of
, and
donates the phase rotation caused by laser linewidth or initial phase difference between the laser sources at the transmitter and receiver.
Consider the rotational symmetry with the degree of
, which means:
where
is another complex signal with the same modulation format as
.
After the square operation, the complex signal in Equation (1) can be represented by:
This means that only the rotational symmetry with the degree of
is satisfied after the square operation. It should be noted that although the condition
is assumed in Equation (2), the same result can be deduced under the condition of
, where
means the modulo operation.
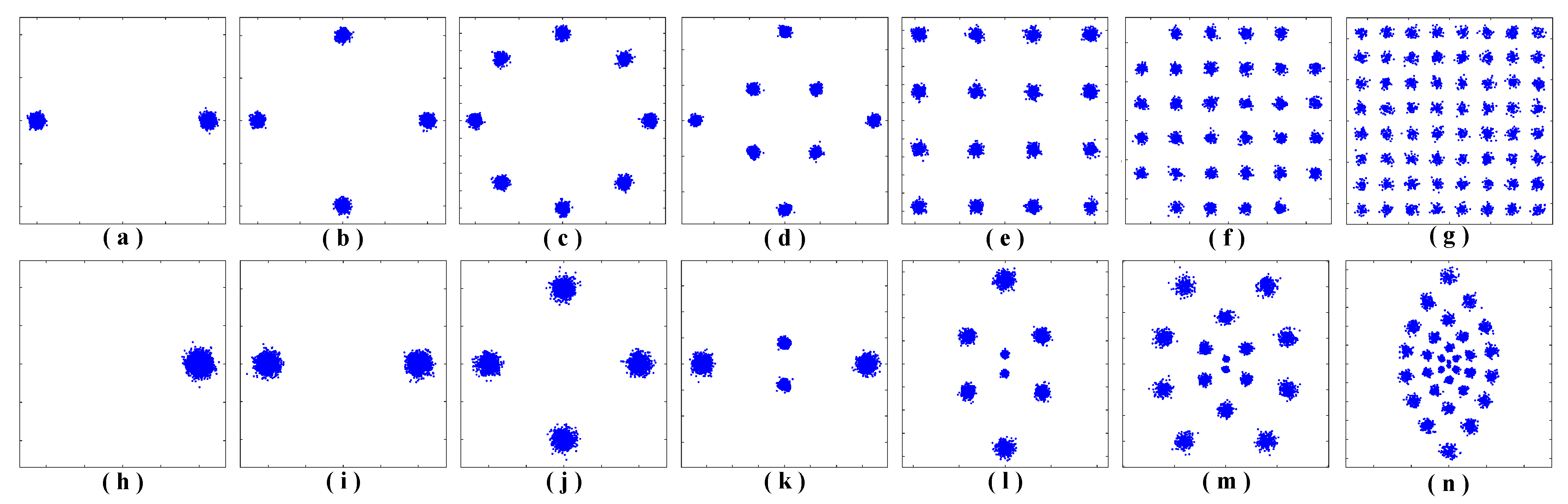
More intuitively, the changes between constellations before and after the square operation of these seven modulation formats (BPSK, QPSK, 8PSK and 8/16/32/64QAM) are shown in
Figure 2. Using this property, it is easier to find the direction with the greatest variance, which will be useful in next step of principal axes correction.
Another property that should be noted is the average power after transformation. When considering the modulation format of BPSK in Equation (2), the average power of 1 is obtained according to , since and .
Focusing on
Figure 2h, the average power of BPSK signals after the square operation is approximately 1, while others with an average power is approximately 0. Thus, the BPSK signals can be identified by detecting the average power after the square operation.
2.2. Principal Axes Correcting Based on PCA
Affected by the non-homogeneity of the laser sources at the transmitting end and receiving end, the overall phase rotation of the receiving constellation occurs. In the previous MFI methods based on constellation diagrams, constellation diagrams with different rotation angles need to be trained, which greatly increases the complexity of implementation. In this paper, principal axes correcting based on PCA is proposed to correct the constellations of different phase rotation angles to a unified datum. Thus, the phase rotation invariant properties to the constellation diagram are obtained without additional training on the phase rotation.
In contrast to the application of PCA in data dimension reduction, the usage of PCA in this paper is to find the direction with the greatest variance. Furthermore, the phase rotation is removed by correcting this direction. For convenience, the coordinate axis composed of the direction with the largest variance and one of its orthogonal vectors is called the principal axis.
As shown in
Figure 2b–g, the distributions of the signals before the square operation are uniform, without any direction showing prominent variance. However, the distributions after the square operation exist in the desired directions, which is extracted and corrected through the process as follows.
For the received signals of length
N after the square operation, a
N 2 matrix donated as
is obtained:
where
and
means to take the real and imaginary parts of the signal, respectively. The values of real and imaginary parts are the projections of complex signals to the real axis (the magenta line
Figure 3a) and imaginary axis (the red line in
Figure 3a), respectively. It should be noted that here our signals suffer from phase rotation.
At first the mean values of
is subtracted to obtain the zero-mean matrix
, and the element
in
is calculated as follows:
Next, the covariance matrix for the real and imaginary parts are calculated:
The largest eigenvector of the covariance matrix points in the direction of the greatest variance and the second largest eigenvector is always orthogonal to the largest one. The principal axes as shown in
Figure 3b can be attained by eigenvalue decomposition or singular value decomposition of the matrix.
The eigenvalue decomposition of covariance matrix can be expressed as:
where
denotes the eigenvector matrix and
is the diagonal matrix of eigenvalues. The eigenvectors
and
form the desired principal axes, which is shown in
Figure 3b. The eigenvector with larger eigenvalue is the direction with the greatest variance (the red line in
Figure 3b).
Looking further at
Figure 2i–n, for original QPSK, 8PSK and 8QAM, the constellations after the square operation have the greatest variance in the real axis, and in the imaginary axis for 16/32/64QAM. Since the modulation formats of received signals are unknown during the MFI process, the direction with the greatest variance is corrected to the imaginary axis consistently. The direction with greatest variance is given by the following equation:
The angle
of phase rotation after the square operation shown in
Figure 3c is calculated as follows:
Note that this angle is between the direction with the greatest variance and the imaginary axis, so it is
instead of
in the arc-cosine function.
Equation (3) shows that the phase rotation after the square operation is twice as much as before. Therefore, the angle of phase rotation before the square operation can be attained by halving the .
Finally, the received data is projected onto the principal axes in
Figure 3d to obtain the data without phase rotation as shown in
Figure 3e.
In addition, the above method can also be applied to the BPSK signals without square operation, thus, restoring its phase.
After the principal axes correcting based on PCA, the signals without phase rotation is obtained, which is shown in
Figure 4. Furthermore, according to the final MFI results, the constellations of QPSK and 8QAM can be rotated by 45 degrees, so as to realize the rough phase recovery of all modulated signals and reduce the complexity of the subsequent carrier phase recovery algorithm.
2.3. Density Distribution Analysis
Based on the signals like
Figure 4, the density distribution analysis is employed to obtain the distribution of constellations.
Considering the signals are normalized to the average energy of 1, the maximum level of the in-phase component and quadrate component is approximately 1. Thus, a range for analysis is set, and any signal outside this range is treated as noise.
This range is then divided into several intervals, both in real and imaginary axes, and these intervals are used to divide a constellation into several blocks. The number of signals in each block is then calculated.
Finally, the density is calculated according to the number of signals in each block and then a matrix of density distribution is obtained.
2.4. Denoising and Smoothing Based on SVD
Since the received signal contains noise, there are many noise spots on the constellation diagram. To reduce the impact of noise on the accuracy of identification, the density matrix based on SVD is denoised, and the low-value zeroing method is used to highlight the main features.
The principle of it is to make use of the characteristic in which the large singular value of the density matrix contains the main information, while small singular values contain more noise. By SVD of the matrix, the part with large eigenvalues are extracted, and the denoised matrix is obtained.
For the density distribution matrix,
, SVD is applied:
where
and
are the left and right singular matrices, respectively.
is the singular value matrix of the following form:
where
is the singular value. Selecting the first
larger singular values, the density distribution matrix is reconstructed as:
where
and
are the first
columns of
and
with
rows, respectively.
is the submatrix consisting of the first
rows and the first
columns of
.
After SVD, the density for blocks with low density is set to 0:
Here,
is the threshold of low density.
2.5. SVM Classfication
Since BPSK was identified in the previous process, only the remaining modulation formats of QPSK, 8PSK and 8/16/32/64QAM need to be classified in the SVM classifier. In order to apply SVM classifier, the density distribution matrix is reshaped into a vector as the feature vector.
4. Conclusions
In this work, a novel blind MFI method based on principal component analysis and singular value decomposition is proposed. Without any priori information, the proposed MFI can achieve accurate identification of seven modulation formats over a large OSNR range from 5 to 35 dB. In the proposed method, PCA is used to determine and correct the direction of the maximum variance of the received signals after square operation. Through this process, the effect of phase rotation can be removed and there is no need to train constellations under different rotations like the previous method based on constellation image processing, so the complexity of training is greatly reduced. The density distribution matrix instead of image is used to count the amplitude and phase information of the received signal constellation to prevent over-fitting caused by too many pixels in the image. SVD is employed to extract the main features of the density distribution matrix, and then the matrix is reconstructed by using the main features to achieve denoising and smoothing. Finally, a SVM classifier is used for the identification based on the matrix.
The performance of the proposed MFI method is evaluated in a 28-GBaud dual-polarization optical fiber communication system. Results shows that the minimum OSNR values required to achieve 100% accurate identification of BPSK, QPSK, 8PSK, 8QAM, 16QAM, 32QAM and 64QAM are 5 dB, 7 dB, 8 dB, 11 dB, 14 dB, 14 dB and 15 dB, respectively. Compared with the other six proposed methods, more types of modulation formats are identified in our method, with a total number of seven. More importantly, among these modulation formats, the best identification performance is achieved in our method, with the advantages up to 5 dB, 5 dB, 6 dB, 4 dB, 5.5 dB, 7.5 dB and 8dB. Additionally, in the identification of BPSK, QPSK, 8PSK and 8/16/32/64QAM, the OSNR gains of 5 dB, 5.04 dB, 9.38 dB, 6.14 dB, 4.75 dB, 8 dB and 9 dB relative to the 7% FEC threshold are obtained, respectively.
Furthermore, the influence of the number of samples on the performance is investigated. As the number of samples decreases, the accuracy of identification degrades. The results show that the proposed method still holds the advantage even under the number of samples of 4096, 2048, 1024 and 512, which is beneficial for low-complexity implementation.
For the further study, the challenge that needs to be faced is how to alleviate the influence on the phase caused by factors such as frequency offset and linewidth of laser source. After all, phase information has a prominent contribution in the identification of modulation formats, especially in the identification of multiple PSK modulation formats.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










