
Key Information Extraction and Talk Pattern Analysis Based on Big Data Technology: A Case Study on YiXi Talks

Abstract
:1. Introduction
2. Related Work
2.1. Text Feature Extraction
- (1)
- Keyword Extraction Technology. In 1957, Luhn first proposed an automatic keyword extraction method based on word frequency. The automatic method for keywords extraction has derived a variety of categories, and scholars have systematically combined them in practical applications [5,6,7,8]. Some scholars have used visual methods to reveal the co-occurrence relationship between extracted keywords with the help of CiteSpace [9]. In terms of classification, keyword extraction algorithms can be divided into two categories: supervised and unsupervised learning algorithms. The former extracts the candidate words in the text in advance, delimits labels in accordance with whether the candidate words are keywords or not, and trains classifier as a training set. When extracting keywords for a new document, the classifier first extracts all candidate words, matches the words in keyword vocabulary, and uses candidate words where their tags are designated as keywords to be keywords from a document. This algorithm is fast but requires many annotated data to improve the accuracy. Compared with a supervised learning method, an unsupervised algorithm has the characteristic of early appearance and multiple types. Its key steps mainly include text preprocessing, determining the set of candidate words, sorting the list of candidate words, and evaluating effect of keyword extraction. Unsupervised learning methods can be divided into simple statistics-based methods, graph-based methods, and language model-based methods [10]. The basic principle of its work is to statistically classify some specific indicators of candidate words that characterize the text and then sort in accordance with the statistical results, such as N-gram [11], term frequency-inverse document frequency (TF-IDF) [12], word frequency [13], word co-occurrence [14], and other algorithms to evaluate the importance of extracted candidate words in a document. The unsupervised algorithm does not need to maintain word lists, nor does it rely on manually labeled corpus to train the classifier. Among unsupervised learning algorithms, TF-IDF can consider word frequency and freshness to filter words that can represent key information of documents and always with simpler and more convenient operation process and better accuracy. Therefore, our work uses TF-IDF algorithm to extract key information from documents (namely YiXi transcripts).
- (2)
- Text Feature Recognition Technology. Another key technique is feature recognition of talk transcripts, which is a form of extractive automatic abstract of text mining [15]. Machine learning techniques are used in several areas of practice, such as disease prediction [16] and detection [17], stock trend prediction [18], judicial case decisions [19], etc. Different from automatic abstract, our research focuses on the start and ending forms, narrative angle, and the object of YiXi talks rather than summarizing documents by sentences from documents. In our work, classical generative methods need to combine linguistic and domain knowledge for reasoning and judgment. High-quality abstracts are usually generated after text analysis, representation transformation, and abstract synthesis. However, the shortcoming is that they are domain-constrained and rely on large-scale real corpora and professional domain knowledge. Traditional methods and technologies in automatic summarization have been developing slowly, while the use deep learning methods in automatic summarization has shown promising [20].
2.2. Analysis for Talk Transcripts
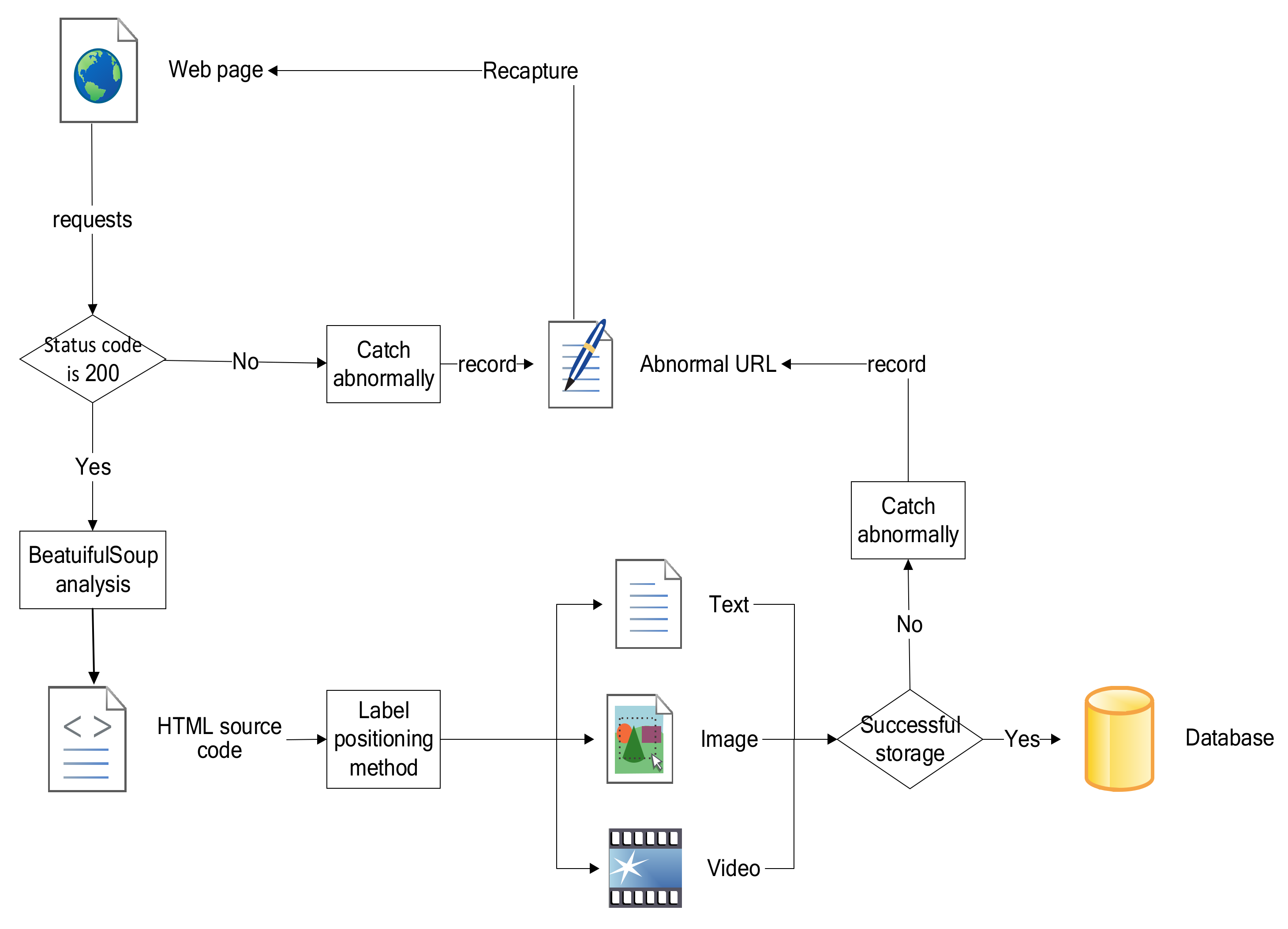
3. Data Sources and Methods
4. Keyword Extraction of YiXi Transcripts
4.1. Word Segmentation of Transcripts
4.2. Removal of Stop Words
4.3. Keyword Extraction from Yixi Transcripts
| Algorithm 1. Keyword extraction algorithm. |
| Input: original speech draft set SD |
| Output: keyword list KL |
Procedure:
|
4.4. Word Cloud Drawing and Interpretation
5. Talk Pattern Recognition and Analysis
5.1. YiXi Talk Patterns Recognition
5.2. YiXi Talk Pattern Automatic Recognition
| Algorithm 2. Talk pattern recognition algorithm. |
| Input: original speech data set DataSet |
| Output: opening form set OpenForm, ending form set EndForm, main narrative objects set NaObj, main narrative angle set NaAng of speech set |
Procedure:
|
- Algorithm 3 provides a method to identify the opening from of YiXi talks. First extract the first sentence of transcript and perform Chinese word segmentation. This process is performed to match the title segment word list for determining whether the word segmentation result contains the opening feature word or the word in talk name. If included, mark the corresponding opening form.
- Extract the last three sentences in the clause set, perform Chinese word segmentation, and determine whether the word segmentation result contains the ending feature word or words from title. If included, mark the corresponding ending form. The details of this procedure are shown in Algorithm 4.
- Perform Chinese word segmentation for all clauses, and count the number of pronouns “he/them”, “she/them”, and “it/them”, and mark the main narrative angle in accordance with the numerical comparison results. This procedure is shown in Algorithm 5.
- Perform Chinese word segmentation for all clauses, identify part of speech of the word, and calculate the amount with part of speech. The part of word includes NT (institutional groups noun and the initial of “tuan” is t), NR (name, noun, and the initial of “ren” is r), NG (nominal morpheme), NS (place name), NZ (other proper names), T (time), VN (verbal nouns), and AN (adjectival nouns). The main narrative angle is marked in accordance with the numerical comparison results. This procedure is shown in Algorithm 6.
| Algorithm 3. Talk opening form analysis. |
| Input: talk title word set WSet, sentence set SSet |
| Output: opening form set OpenForm |
Procedure:
|
| Algorithm 4. Talk ending form analysis. |
| Input: talk title word set WSet, talk sentence set SSet |
| Output: ending form set EndForm |
Procedure:
|
| Algorithm 5. Main narrative object analysis. |
| Input: Transcript sentence set SSet |
| Output: main narrative objects set NaObj |
Procedure:
|
| Algorithm 6. Main narrative angle analysis. |
| Input: Transcript sentence set SSet |
| Output: main narrative angles set NaAng |
Procedure:
|
5.3. Analysis of YiXi Talk Pattern
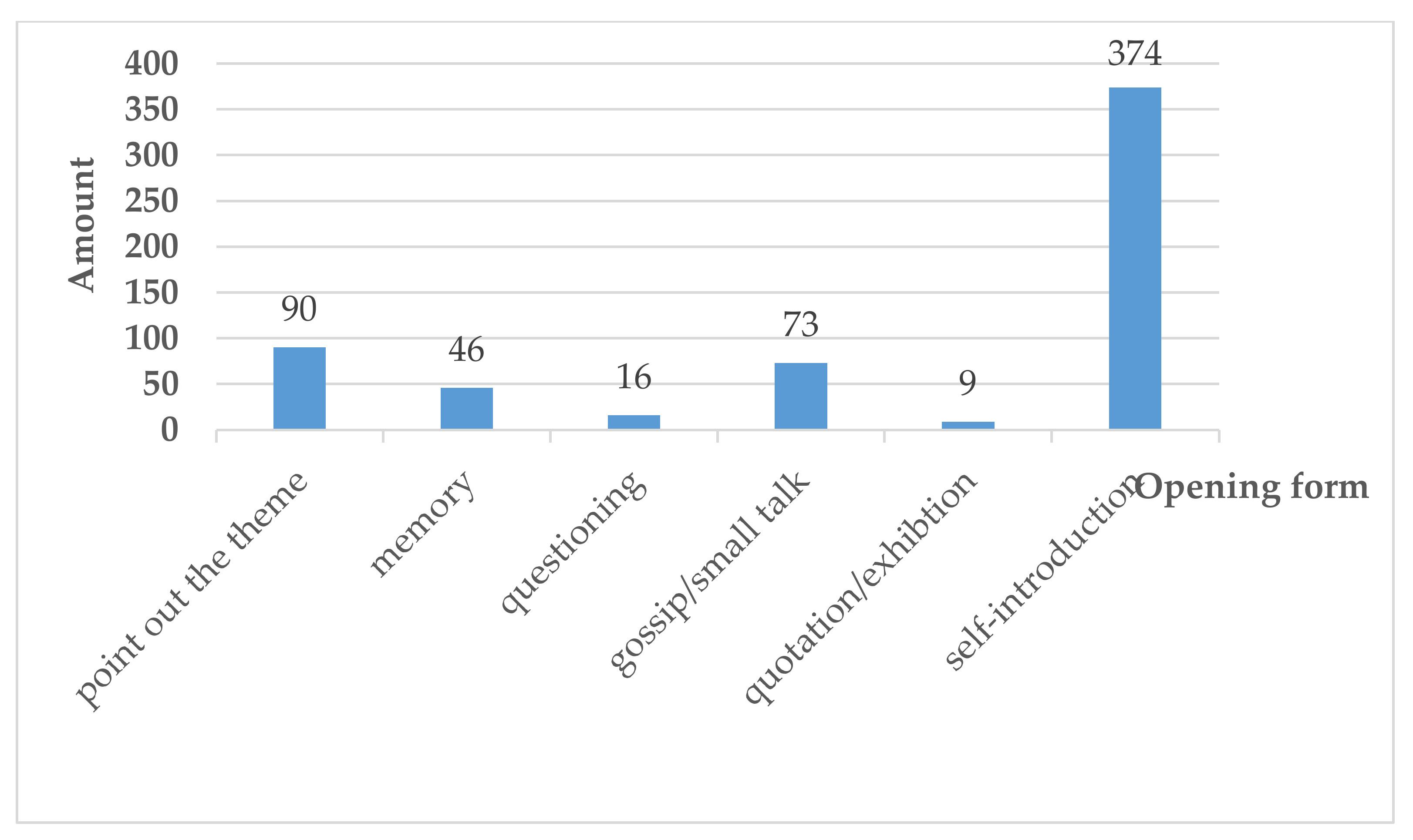
- (1)
- Clustered histogram of opening form of YiXi talk is shown in Figure 4.Figure 4 shows that opening of “self-introduction” is more popular than other types. YiXi speakers tend to introduce themselves briefly at the beginning. “Point out the theme”, “memory”, and “gossip” opening form are secondary choices for openings. From a linguistic and psychological point of view in China, “Point out the theme” helps the audience understand the main content of a talk, while “memory” and “gossip” may ease speakers’ tension through simple communication and interaction. The “questioning” and “citation” openings are the forms speakers rarely used.
- (2)
- Clustered histograms of main narrative angles and objects of YiXi are shown in Figure 5 and Figure 6.YiXi encourages sharing of insights, experiences, and imaginations about the future. Speakers usually use specific examples to share unique experiences, knowledge, and opinions. Therefore, the main content is mainly about things and contains fewer descriptions of people and of matter. Compared with the second and third person, the first person may be better which is more convenient for the elaboration and expression of the content.
- (3)
- Clustered histogram of the ending form of YiXi talk is shown in Figure 7.
6. Conclusions
- (1)
- The key information of YiXi talk transcripts can be revealed by text mining methods, which were followed by Chinese word segmentation, stop word removal, and keyword extraction. Certain category characteristics are reflected by extraction results. The technology of keyword extraction can make contributions to “strategic reading” to some degree. The research results can solve the general problem that keywords missing of transcripts, and we advocate that speakers give a summary and recommendation on the topic of talks to ensure the effect of knowledge diffusion.
- (2)
- YiXi talks has fixed talk patterns and characteristics, that is, speakers tend to adopt a self-introducing opening form, tell the story and experience through the first person narrative angle, and express expectations and prospects for the future at the end. This pattern can provide a reference for newcomers. However, the talk pattern analysis implemented in our work has certain exploratory characteristics, and the angle only includes the opening mode, narrative angle, narrative object, and end form categories. The analysis perspectives are few, and the characteristic refinement of manual data labeling and the logic of program labeling still need to be optimized.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, P.P. Innovation and Improvement of the Speech Program “Yi Xi”. Radio TV J. 2018, 11, 16–18. [Google Scholar]
- Hou, Z.; Huang, C.; Wu, J.; Liu, L. Distributed Image Retrieval Base on LSH Indexing on Spark. In Big Data and Security. ICBDS 2019. Communications in Computer and Information Science; Tian, Y., Ma, T., Khan, M., Eds.; Springer: Singapore, 2020; Volume 1210, pp. 429–441. [Google Scholar]
- Turney, P.D. Learning Algorithms for Key phrase Extraction. Inf. Retr. 2000, 2, 303–336. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Huang, W.; Zheng, Y. Automatic Key Phrase Extraction via Topic Decomposition[C]. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 366–376. [Google Scholar]
- Zhang, C.Z. Review and Prospect of Automatic Indexing Research. New Technol. Libr. Inf. Serv. 2007, 2, 33–39. [Google Scholar]
- Zhao, J.S.; Zhu, Q.M.; Zhou, G.D.; Zhang, L. Review of Research in Automatic Keyword Extraction. J. Softw. 2017, 28, 2431–2449. [Google Scholar]
- Merrouni, Z.A.; Frikh, B.; Ouhbi, B. Automatic Keyphrase Extraction: A Survey and Trends. J. Intell. Inf. Syst. 2020, 54, 391–424. [Google Scholar] [CrossRef]
- Papagiannopoulou, E.; Tsoumakas, G. A Review of Keyphrase Extraction. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, 1339. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Yang, Z.; Ye, Z.; Liu, H. Research Character Analyzation of Urban Security Based on Urban Resilience Using Big Data Method. In Big Data and Security. ICBDS 2019. Communications in Computer and Information Science; Tian, Y., Ma, T., Khan, M., Eds.; Springer: Singapore, 2020; Volume 1210, pp. 371–381. [Google Scholar]
- Hu, S.H.; Zhang, Y.Y.; Zhang, C.Z. Overview of Keyword Extraction Research. Data Anal. Knowl. Discov. 2021, 3, 45–59. [Google Scholar]
- Cohen, J.D. Highlights: Language and Domain-Independent Automatic Indexing Terms for Abstracting. J. Am. Soc. Inf. Sci. 1995, 46, 162–174. [Google Scholar] [CrossRef]
- Salton, G.; Yang, C.S.; Yu, C.T. A Theory of Term Importance in Automatic Text Analysis. J. Am. Soc. Inf. Sci. 1975, 26, 33–44. [Google Scholar] [CrossRef] [Green Version]
- Luhn, H.P. A Statistical Approach to Mechanized Encoding and Searching of Literary Information. IBM J. Res. Dev. 1957, 1, 309–317. [Google Scholar] [CrossRef]
- Matsuo, Y.; Ishizuka, M. Keyword Extracyion from a Single Document Using Word Co-occurrence Statistical Information. Int. J. Artif. Intell. Tools 2008, 13, 157–169. [Google Scholar] [CrossRef]
- Zhao, H. A Survey of Deep Learning Methods for Abstractive Text Summarization. J. China Soc. Sci. Tech. Inf. 2020, 39, 330–344. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, A.; Jain, S.; Miranda, R.; Patil, S.; Pandya, S.; Kotecha, K. Deep learning based respiratory sound analysis for detection of chronic obstructive pulmonary disease. PeerJ Comput. Sci. 2021, 5, 1–22. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Rahman, F.; Kundi, F.M.; Ahmad, S. Development of stock market trend prediction system using multiple regression. Comput. Math. Organ. Theory 2019, 25, 271–301. [Google Scholar] [CrossRef]
- Ullah, A.; Asghar, M.Z.; Habib, A.; Aleem, S.; Kundi, F.M.; Khattak, A.M. Optimizing the Efficiency of Machine Learning Techniques. In Big Data and Security. ICBDS 2019. Communications in Computer and Information Science; Tian, Y., Ma, T., Khan, M., Eds.; Springer: Singapore, 2020; Volume 1210, pp. 429–441. [Google Scholar]
- Zhao, H.; Wang, F.; Wang, X.Y.; Zhang, W.C.; Yang, J. Research on Construction and Application of a Knowledge Discovery System Based on Intelligent Processing of Large-scale Governmental Documents. J. China Soc. Sci. Tech. Inf. 2018, 37, 805–812. [Google Scholar]
- Kavita, S.O.; Poornima, G.N. Prediction of Online Lectures Popularity: A Text Mining Approach. Procedia Comput. Sci. 2016, 92, 468–474. [Google Scholar]
- Zhou, H.Y. Finely crafted live-speaking documentaries -text analysis of Under the Dome[C]. In A Collection of Papers from the 7th Graduate Forum on Journalism and Communication in Anhui Province; School of Journalism and Communication, Anhui University: Hefei, China, 2015; pp. 346–365. [Google Scholar]
- Min, Y.; Lao, Q.; Ding, X.J. Enlightenment of Text Data mining Technology on Shorthand Teaching and Corpus Construction-Taking Konosuke Matsushita’s Speech Data Analysis as an Example. J. Shaoguan Univ. 2015, 7, 170–174. [Google Scholar]
- Liu, H. Word Frequency Analysis on the Construction of British National Image-Taking the Speech of Former British Prime Minister Theresa May as an Example. Overseas Engl. 2020, 1, 215–216, 245. [Google Scholar]
- Chen, Y.; Wang, L.; Qi, D.; Zhang, W. Community Detection Based on DeepWalk in Large Scale Networks. In Big Data and Security: First International Conference, ICBDS 2019 [C]; Tian, Y., Ma, T.H., Khan, M.K., Eds.; Springer: New York, NY, USA, 2020; pp. 568–583. [Google Scholar]
- Shan, X.Q. Analysis of New Media Communication Characteristics of YiXi Speech. Res. Transm. Competence 2020, 4, 79–80. [Google Scholar]
- Zhao, Z.Q. Let “Hero Dreams” Come into the Eyes of More People-Analysis of the Market Operation of the Network Speech Program “YiXi”. J. News Res. 2017, 8, 229. [Google Scholar]
- Alwabel, A. Privacy Issues in Big Data from Collection to Use. In Big Data and Security. ICBDS 2019. Communications in Computer and Information Science; Tian, Y., Ma, T., Khan, M., Eds.; Springer: Singapore, 2020; Volume 1210, pp. 382–391. [Google Scholar]
- Monali, B.; Saroj, K.B. Keyword Extraction from Micro-Blogs Using Collective Weight; Springer: Vienna, Austria, 2018; Volume 8, p. 429. [Google Scholar]
- Saroj, K.B.; Monali, B.B.; Jacob, S. A graph based keyword extraction model using collective node weight. Expert Syst. Appl. 2018, 97, 51–59. [Google Scholar]
- Ou, Y.Y.; Ta, W.K.; Anand, P.; Wang, J.F.; Tsai, A.C. Spoken dialog summarization system with happiness/suffering factor recognition. Front. Comput. Sci. 2017, 11, 15. [Google Scholar] [CrossRef]
- Tang, L.; Guo, C.H.; Chen, J.F. Summary of Research on Chinese Word Segmentation Technology. Data Anal. Knowl. Discov. 2020, 4, 1–17. [Google Scholar]
- Yu, H.; Li, Z.X.; Jiang, Y. Using GitHub Open Sources and Database Methods Designed to Auto-Generate Chinese Tang Dynasty Poetry. In Big Data and Security. ICBDS 2019. Communications in Computer and Information Science; Tian, Y., Ma, T., Khan, M., Eds.; Springer: Singapore, 2020; Volume 1210, pp. 417–428. [Google Scholar]
- Zheng, J.H.; Zhang, J.F.; Tan, H.Y. Strategies for Segmentation of Ambiguity in Chinese Word Segmentation. J. Shanxi Univ. (Nat. Sci. Ed.) 2016, 47, 228–232. [Google Scholar]
- Passing, F.; Moehrle, M.G. Measuring technological convergence in the field of smart grids: A semantic patent analysis approach using textual corpora of technologies. In Proceedings of the 2015 Portland International Conference on Management of Engineering and Technology (PICMET), Portland, OR, USA, 2–6 August 2015; pp. 559–570. [Google Scholar]
- Qaiser, S.; Ali, R. Text Mining: Use of TF-IDF to Examine the Relevance of Words to Documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Hu, Q.; Hao, X.Y.; Zhang, X.Z.; Chen, Y.W. Keyword Extraction Strategy Research. J. Taiyuan Univ. Technol. 2016, 47, 228–232. [Google Scholar]
- Hu, X.G.; Li, X.H.; Xie, F.; Wu, X.D. Keyword Extraction Method of Chinese News Web Pages based on Vocabulary Chain. Pattern Recognit. Artif. Intell. 2010, 23, 45–51. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Keywords | TF-IDF Value |
|---|---|---|
| 1 | rubbish | 1.201 |
| 2 | government | 0.199 |
| 3 | classification | 0.178 |
| 4 | trash can | 0.134 |
| 5 | waste incineration | 0.121 |
| 6 | house | 0.114 |
| 7 | culture | 0.111 |
| No. | Keywords | TF-IDF Value |
|---|---|---|
| 1 | animal | 0.097 |
| 2 | zoo | 0.085 |
| 3 | universe | 0.054 |
| 4 | plant | 0.050 |
| 5 | local | 0.048 |
| 6 | ant | 0.047 |
| 7 | first name | 0.046 |
| Speech_ID | Opening Form | Feature Words, e.g. | Ending Form | Feature Words, e.g. | Narrative Object | Narrative Angle |
|---|---|---|---|---|---|---|
| S_031_20121201 | Self-introduction | I’m | Thoughts | Feel | Thing | First person |
| S_032_20130112 | Memory | More than 70 years ago, when | Hope | Hope | People | First person |
| S_034_20130330 | Small talk | just saw | Quote | : “” | Thing | First person |
| S_035_20130330 | Questioning | ? | Outlook | Future | Matter | Third person |
| S_042_20130818 | Self-introduction | My name is | Thoughts | Feel | Thing | First person |
| S_055_20170219 | Self-introduction | My name | Hope | If, I want | Matter | Third person |
| S_056_20160520 | Point out the theme | Title | Outlook | Future, today | People | Third person |
| S_072_20120826 | Small talk | Today, originally | Thoughts | Think, dream | Thing | First person |
| S_079_20160306 | Memory | 1998, at that time | Quote | There is a sentence, “” | Thing | First person |
| S_094_20121028 | Point out the theme | Title | Summarize | So, today | People | Third person |
| Analysis Perspective | Analysis Scope | Pattern Category e.g., | Feature Information e.g., |
|---|---|---|---|
| Opening form | First sentence | Point out the theme | The title of one talk |
| Memory | That year, then, some certain year, some certain time | ||
| Questioning | ? | ||
| Gossip/small talk | Today, just now, now | ||
| Quotation/Exhibition | “”, :, photos, poems | ||
| Self-introduction | I am, I come from, my name is | ||
| Main Narrative Object | Full text | People | count(nt+nr+he+her)>=count(ns+t+he+her) count(nt+nr+him+her)>=count(an+t+ng+ns+nz+vn+it) |
| Thing | count(ns+t+he+her)>=count(nt+nr+he+her) count(ns+t+him+her)>=count (an+t+ng+ns+nz+vn+it) | ||
| Matter | count(an+t+ng+ns+nz+vn+it)>=count(nt+nr+he+her) count(an+t+ng+ns+nz+vn+it)>=count(ns+t+he+her) | ||
| MainNarrative angle | Full text | First person | count(me)>=count(you+everyone) count(me)>=count(he+she+it) |
| Second person | count(you+everyone)>=count(me) count(you+everyone)>=count(he/she/it) | ||
| Third person | count(he+she+it)>=count(me) count(he+she+it)>=count(you+everyone) | ||
| Ending form | last three sentences | Summary | Title, fact, is, reason, meaning |
| Hope | Hope, future, if | ||
| Feel/Thoughts | Feel, think, understand | ||
| Quote | One sentence, one song,: , “”, “” | ||
| Questioning | ?, What, ask, how |
| Labeled Content | Number of Matches | Total Number of Samples | Accuracy (%) |
|---|---|---|---|
| Opening form | 77 | 118 | 65.25 |
| Main narrative angle | 83 | 118 | 70.34 |
| Main narrative object | 63 | 118 | 53.39 |
| Ending form | 58 | 118 | 49.15 |
| Total | 281 | 472 | 59.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Jiang, C.; Huang, C.; Chen, Y.; Yi, M.; Zhu, Z. Key Information Extraction and Talk Pattern Analysis Based on Big Data Technology: A Case Study on YiXi Talks. Electronics 2022, 11, 640. https://doi.org/10.3390/electronics11040640
Xu H, Jiang C, Huang C, Chen Y, Yi M, Zhu Z. Key Information Extraction and Talk Pattern Analysis Based on Big Data Technology: A Case Study on YiXi Talks. Electronics. 2022; 11(4):640. https://doi.org/10.3390/electronics11040640
Chicago/Turabian StyleXu, Hao, Chengzhi Jiang, Chuanfeng Huang, Yiyang Chen, Mengxue Yi, and Zhentao Zhu. 2022. "Key Information Extraction and Talk Pattern Analysis Based on Big Data Technology: A Case Study on YiXi Talks" Electronics 11, no. 4: 640. https://doi.org/10.3390/electronics11040640
APA StyleXu, H., Jiang, C., Huang, C., Chen, Y., Yi, M., & Zhu, Z. (2022). Key Information Extraction and Talk Pattern Analysis Based on Big Data Technology: A Case Study on YiXi Talks. Electronics, 11(4), 640. https://doi.org/10.3390/electronics11040640