
A Compression-Based Multiple Subword Segmentation for Neural Machine Translation

 ,
, 
Abstract
:1. Introduction
1.1. Motivation
1.2. Related Works
1.3. Our Contribution
2. Background
2.1. SentencePiece
2.2. BPE and BPE-Dropout
2.3. LCP
- Randomly assign a label to each .
- According to , compute the sequence .
- Merge all bigram provided .
- Set and repeat the above process.
3. Our Approach: LCP-Dropout
3.1. Algorithm Description
| Algorithm 1 LCP-dropout. |
|
| Algorithm 2 %subroutine of LCP-dropout. |
|
3.2. Example Run
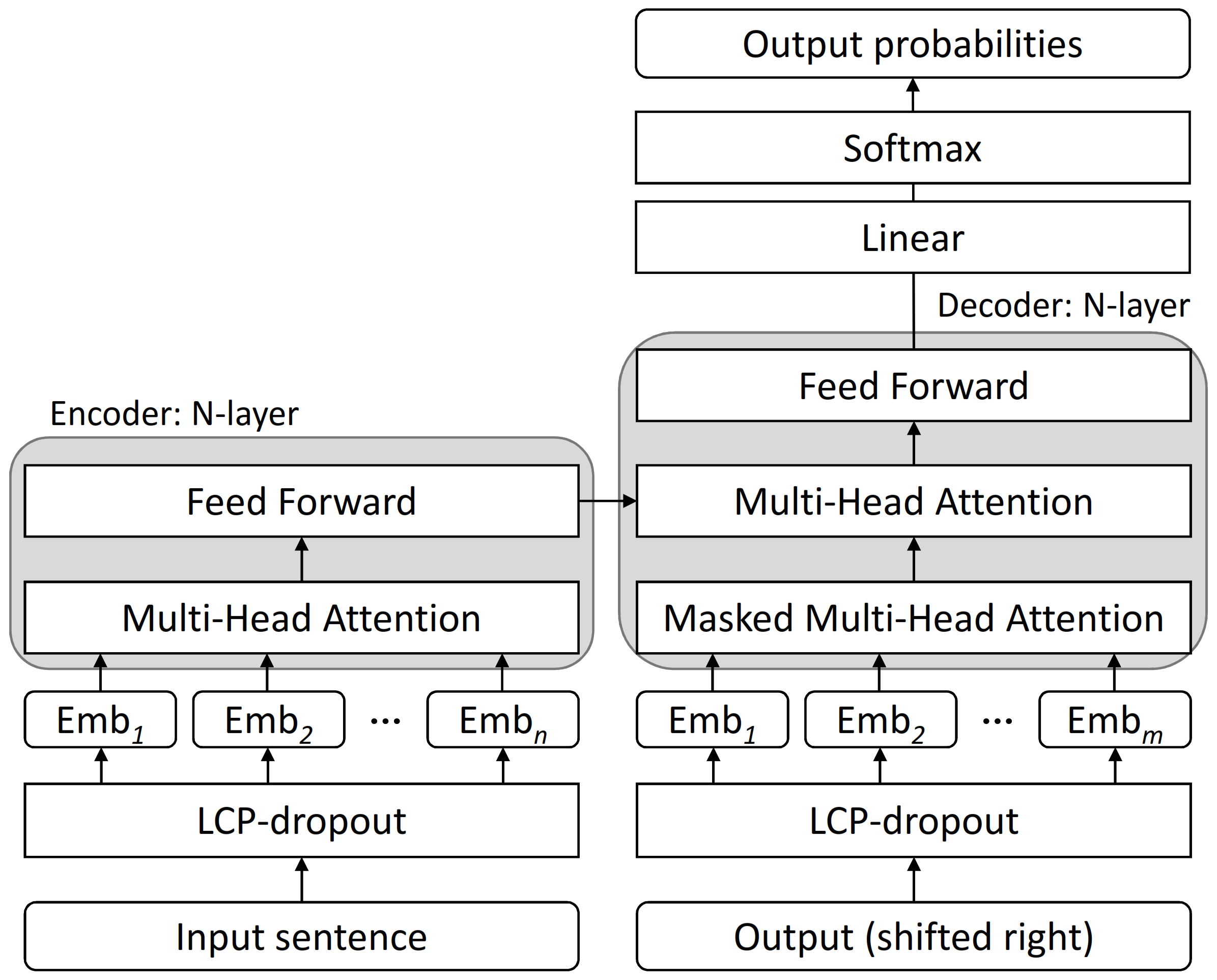
3.3. Framework of Neural Machine Translation
4. Experimental Setup
4.1. Baseline Algorithms
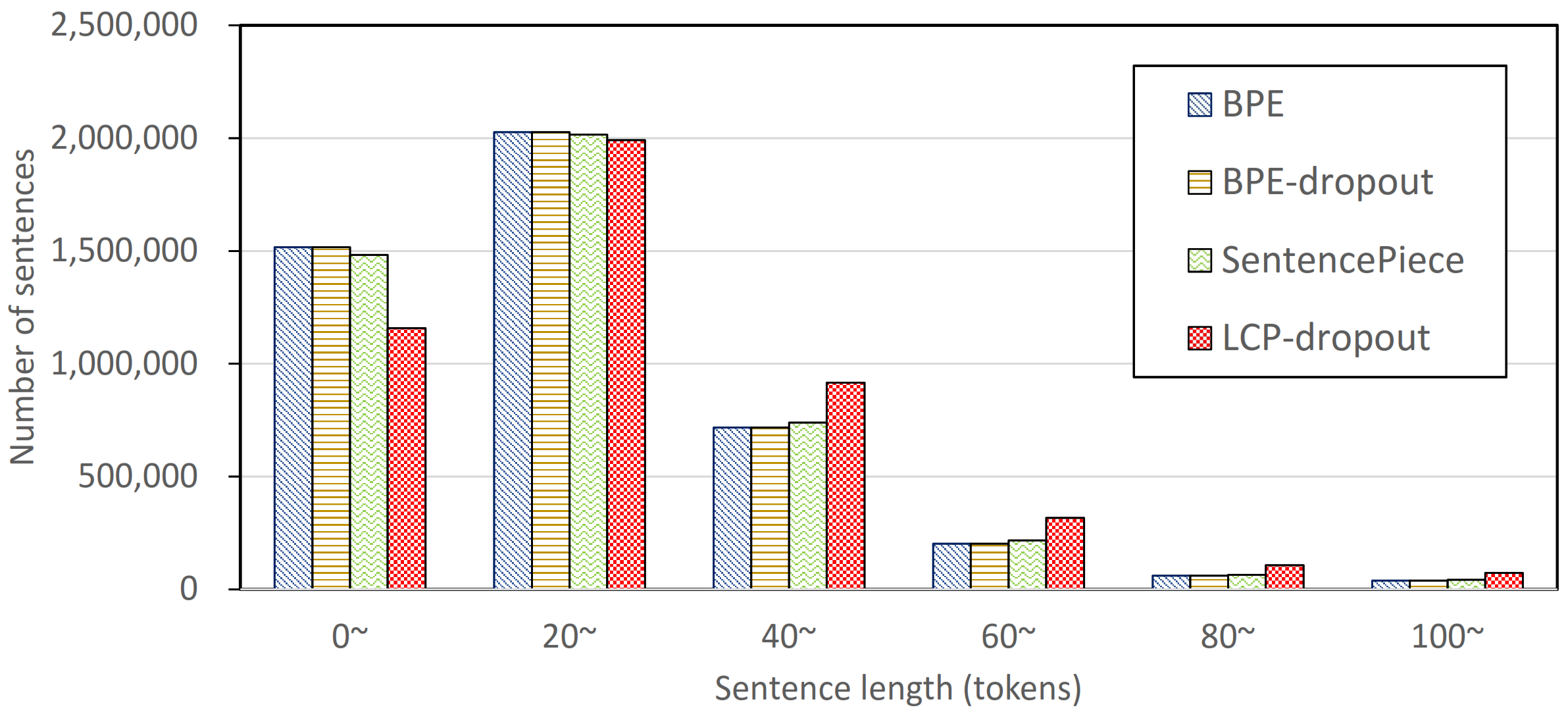
4.2. Data Sets, Preprocessing, and Vocabulary Size
4.3. Model, Optimizer, and Evaluation
5. Experiments and Analysis
5.1. Estimation of Hyperparameters for LCP-Dropout
5.2. Comparison with Baselines
6. Conclusions, Limitations, and Future Research
6.1. Conclusions and Limitations
6.2. Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barrault, L.; Bojar, O.; Costa-jussà, M.R.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Huck, M.; Koehn, P.; Malmasi, S.; et al. Findings of the 2019 Conference on Machine Translation (WMT19). In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 1–2 August 2019; pp. 1–61. [Google Scholar]
- Bojar, O.; Federmann, C.; Fishel, M.; Graham, Y.; Haddow, B.; Koehn, P.; Monz, C. Findings of the 2018 Conference on Machine Translation (WMT18). In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Belgium, Brussels, 31 October–1 November 2018; pp. 272–303. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Provilkov, I.; Emelianenko, D.; Voita, E. BPE-Dropout: Simple and Effective Subword Regularization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1882–1892. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Jeff Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Socher, R.; Bauer, J.; Manning, C.; Ng, A. Parsing with compositional vector grammars. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 455–465. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Creutz, M.; Lagus, K. Unsupervised models for morpheme segmentation and morphology learning. ACM Trans. Speech Lang. Process. 2007, 4, 1–34. [Google Scholar] [CrossRef]
- Schuster, M.; Nakajima, K. Japanese and Korean Voice Search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar]
- Chitnis, R.; DeNero, J. Variablelength word encodings for neural translation models. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2088–2093. [Google Scholar]
- Kunchukuttan, A.; Bhattacharyya, P. Orthographic syllable as basic unit for SMT between related languages. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1912–1917. [Google Scholar]
- Banerjee, T.; Bhattacharyya, P. Meaningless yet meaningful: Morphology grounded subword-level NMT. In Proceedings of the Second Workshop on Subword/Character Level Models, New Orleans, LA, USA, 5 June 2018; pp. 55–60. [Google Scholar]
- Kudo, T. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 66–75. [Google Scholar]
- Gage, P. A new algorithm for data compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Larsson, N.J.; Moffat, A. Off-line dictionary-based compression. Proc. IEEE 2000, 88, 1722–1732. [Google Scholar] [CrossRef] [Green Version]
- Karpinski, M.; Rytter, W.; Shinohara, A. An Efficient Pattern-Matching Algorithm for Strings with Short Descriptions. Nord. J. Comput. 1997, 4, 172–186. [Google Scholar]
- Kida, T.; Matsumoto, T.; Shibata, Y.; Takeda, M.; Shinohara, A.; Arikawa, S. Collage system: A unifying framework for compressed pattern matching. Theor. Comput. Sci. 2003, 298, 253–272. [Google Scholar] [CrossRef] [Green Version]
- Cormod, G.; Muthukrishnan, S. The string edit distance matching problem with moves. ACM Trans. Algorithms 2007, 3, 1–19. [Google Scholar] [CrossRef]
- Jeż, A. A really simple approximation of smallest grammar. Theor. Comput. Sci. 2016, 616, 141–150. [Google Scholar] [CrossRef]
- Takabatake, Y.; I, T.; Sakamoto, H. A Space-Optimal Grammar Compression. In Proceedings of the 25th Annual European Symposium on Algorithms, Vienna, Austria, 6–9 September 2017; pp. 1–15. [Google Scholar]
- Gańczorz, M.; Gawrychowski, P.; Jeż, A.; Kociumaka, T. Edit Distance with Block Operations. In Proceedings of the 26th Annual European Symposium on Algorithms, Helsinki, Finland, 20–22 August 2018; pp. 33:1–33:14. [Google Scholar]
- Lehman, E.; Shelat, A. Approximation algorithms for grammar-based compression. In Proceedings of the Thirteenth Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 6–8 January 2002; pp. 205–212. [Google Scholar]
- Lehman, E. Approximation Algorithms for Grammar-Based Data Compression. Ph.D. Thesis, MIT, Cambridge, MA, USA, 1 February 2002. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, V.Q. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2 December 2014; pp. 3104–3112. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A. OpenNMT: Open-source toolkit for neural machine translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 67–72. [Google Scholar]
- Post, M. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation, Brussels, Belgium, 31 October–1 November 2018; pp. 186–191. [Google Scholar]
- He, X.; Haffari, G.; Norouzi, N. Dynamic Programming Encoding for Subword Segmentation in Neural Machine Translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3042–3051. [Google Scholar]
- Deguchi, H.; Utiyama, M.; Tamura, A.; Ninomiya, T.; Sumita, E. Bilingual Subword Segmentation for Neural Machine Translation. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 4287–4297. [Google Scholar]
- Fadaee, M.; Bisazza, A.; Monz, C. Data augmentation for low-resource neural machine translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 567–573. [Google Scholar]
- Wang, X.; Pham, H.; Dai, Z.; Neubig, G. SwitchOut: An efficient data augmentation algorithm for neural machine translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 856–861. [Google Scholar]
- Ranto Sawai, R.; Paik, I.; Kuwana, A. Sentence Augmentation for Language Translation Using GPT-2. Electronics 2021, 10, 3082. [Google Scholar] [CrossRef]
- Park, C.; Yang, Y.; Park, K.; Heuiseok Lim, H. Decoding Strategies for Improving Low-Resource Machine Translation. Electronics 2020, 9, 1562. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| 1-st Trial | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| input x: depth 0 | a | b | a | b | c | a | a | c | a | b | c | b |
| L | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| depth 1 | c | a | a | c | c | b | ||||||
| L | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | |||
| : depth 2 | a | a | c | b | ||||||||
| 2-nd Trial | ||||||||||||
| same x: depth 0 | a | b | a | b | c | a | a | c | a | b | c | b |
| L | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 1 |
| depth 1 | a | b | a | b | a | b | c | b | ||||
| L | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ||
| : depth 2 | a | b | c | b |
| Corpus | Language () | #Sentences (train/dev/test) | Batch Size | Hyperparameters |
|---|---|---|---|---|
| News | En − De | 380k/2808/2906 | 3072 | 16k, 16k/8k, 0.01/0.05/0.1 |
| Commentary | En − Fr | 357k/3020/3133 | 3072 | 16k, 8k, 0.01 |
| v16 | En − Zh | 305k/2968/2936 | 3072 | 16k, 8k, 0.01 |
| KFTT | En − Ja | 440k/1166/1160 | 3072 | 16k, 8k, 0.01 |
| WMT14 | En − De | 4.5M/2737/3004 | 3072 | 32k, 32k/16k, 0.01 |
| Top-k Threshold | #Subword | BLEU | ||
|---|---|---|---|---|
| En | De | |||
| 0.01 | 21.3 | 7.7 | 39.0 | 39.7 |
| 0.05 | 4.7 | 3.7 | 39.0 | 39.4 |
| 0.1 | 3.3 | 2.0 | 38.8 | 39.4 |
| Top-k Threshold | ||||
|---|---|---|---|---|
| En | De | En | De | |
| 0.01 | 83.7 | 48.0 | 54.9 | 35.4 |
| 0.05 | 18.7 | 12.3 | 13.0 | 9.0 |
| 0.1 | 10.3 | 7.7 | 7.3 | 6.0 |
| Corpus | Language | Translation | LCP | BPE | SP | |
|---|---|---|---|---|---|---|
| (Multiplicity) | Direction | |||||
| News | En–De | De → En | 39.7 | 35.7 | 39.1 | 38.9 |
| Commentary | (21.3–7.7) | En → De | 28.4 | 27.4 | 27.4 | 27.5 |
| v16 | En–Fr | Fr → En | 35.1 | 34.9 | 34.9 | 34.2 |
| (small) | (23.0–19.3) | En → Fr | 29.5 | 28.2 | 28.3 | |
| En–Zh | Zh → En | 24.2 | 24.2 | 24.6 | 24.2 | |
| (26.0–8.7) | En → Zh | 6.5 | 2.1 | |||
| KFTT | En–Ja | Ja → En | 20.0 | 19.6 | 19.6 | 19.2 |
| (small) | (17.7–10.0) | En → Ja | 8.5 | 3.6 | ||
| WMT14 | En–De | De → En | 28.7 | 28.9 | 32.2 | 32.2 |
| (large) | (9.3–5.3) |
| Top-k Threshold | ||||
|---|---|---|---|---|
| En | De | En | De | |
| 0.01 | 24.0 | 18.0 | 17.1 | 14.2 |
| Reference: | ‘Even if his victory remains unlikely, Bayrou must | BLEU |
| (ave./word = 5.00) | now be taken seriously.’ | |
| LCP-dropout: | ‘While his victory remains unlikely, Bayrou must | 84.5 |
| now be taken seriously.’ | ||
| BPE-dropout: | ‘Although his victory remains unlikely, he needs to | 30.8 |
| take Bayrou seriously now.’ | ||
| Reference: | ‘In addition, companies will be forced to restructure | BLEU |
| (ave./word = 5.38) | in order to cut costs and increase competitiveness.’ | |
| LCP-dropout: | ‘In addition, restructuring will force rms to save costs | 12.4 |
| and boost competitiveness.’ | ||
| BPE-dropout: | ‘In addition, businesses will be forced to restructure | 66.8 |
| in order to save costs and increase competitiveness.’ | ||
| ave./subword | 4.01 (LCP-dropout): 4.31 (BPE-dropout) | |
| SD of BLEU | 21.98 (LCP-dropout): 21.59 (BPE-dropout) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nonaka, K.; Yamanouchi, K.; I, T.; Okita, T.; Shimada, K.; Sakamoto, H. A Compression-Based Multiple Subword Segmentation for Neural Machine Translation. Electronics 2022, 11, 1014. https://doi.org/10.3390/electronics11071014
Nonaka K, Yamanouchi K, I T, Okita T, Shimada K, Sakamoto H. A Compression-Based Multiple Subword Segmentation for Neural Machine Translation. Electronics. 2022; 11(7):1014. https://doi.org/10.3390/electronics11071014
Chicago/Turabian StyleNonaka, Keita, Kazutaka Yamanouchi, Tomohiro I, Tsuyoshi Okita, Kazutaka Shimada, and Hiroshi Sakamoto. 2022. "A Compression-Based Multiple Subword Segmentation for Neural Machine Translation" Electronics 11, no. 7: 1014. https://doi.org/10.3390/electronics11071014
APA StyleNonaka, K., Yamanouchi, K., I, T., Okita, T., Shimada, K., & Sakamoto, H. (2022). A Compression-Based Multiple Subword Segmentation for Neural Machine Translation. Electronics, 11(7), 1014. https://doi.org/10.3390/electronics11071014