1. Introduction
Structured prediction aims to solve problems, where the output set is not a linear space but rather a set of structured objects such as sequences, trees, or graphs [
1,
2]. Structured prediction has played a key role in the area of natural language processing (NLP). In many NLP tasks, the outputs are structures that can take the form of sequences (e.g., named entity recognition and semantic role labeling), trees (e.g., constituency parsing and syntactic dependency parsing), or general labeled graphs (e.g., relation extraction, semantic dependency parsing, and abstract meaning representation (AMR) parsing).
Recent works of structured prediction show that graph neural networks (GNNs) can provide a scalable and highly performant means of incorporating linguistic information and other structural biases into NLP models. They have been applied to various kinds of representations (e.g., syntactic trees, semantic graphs, and co-reference structures) and show effectiveness on a range of tasks, including named entity recognition [
3,
4], semantic role labeling [
5], relation extraction [
6,
7,
8], and syntactic and semantic dependency parsing [
9,
10,
11,
12].
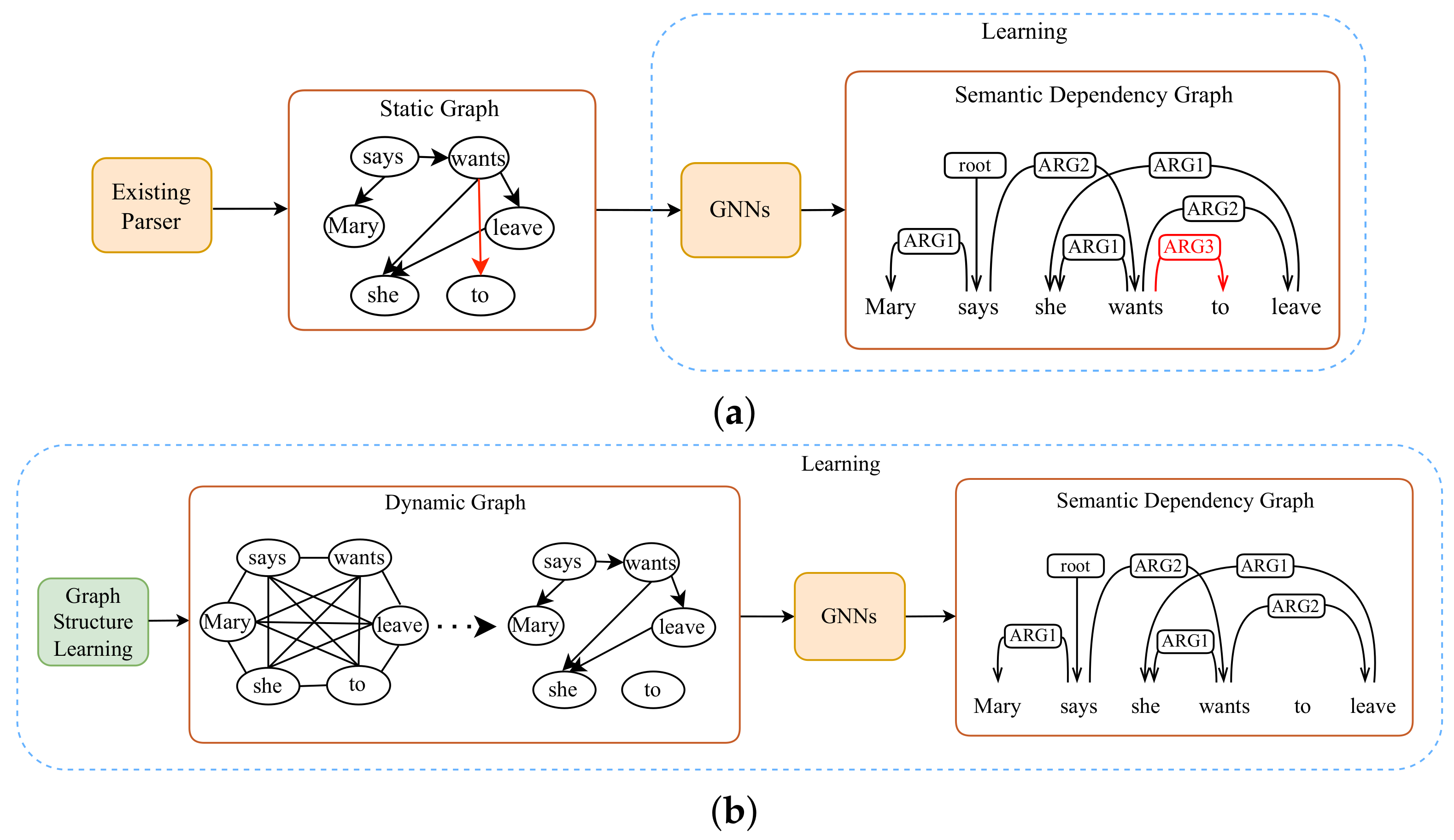
Most of these models utilize an existing parser to construct an initial static graph (e.g., constituency tree, dependency tree, or dependency graph), and then use GNNs to learn node embeddings based on the static graph to predict an objective graph. A static graph-based learning example for semantic dependency parsing is shown as
Figure 1. These models have made significant accuracy improvements in the corresponding tasks, owing to the powerful ability of GNNs in learning expressive graph representations.
Despite the promising performance, there are still two drawbacks in these models: (1) the static graph might be error-prone (e.g., noisy or incomplete), and the errors introduced in the static graph cannot be corrected and might accumulate in later stages, and (2) the graph construction stage and graph representation learning stage are disjoined, which negatively affects the model’s running speed.
Recently, several dynamic graph learning approaches have been presented to tackle the above two drawbacks [
13,
14,
15,
16]. Most approaches for constructing dynamic graphs aim to learn the graph structure (i.e., a weighted adjacency matrix) in a dynamic fashion, allowing the graph to evolve over time. The graph construction module can be jointly optimized with subsequent graph representation learning modules towards a downstream task in an end-to-end manner.
Inspired by the ideas of these works, we propose a concise and effective dynamic graph learning framework (DynGL) to address the drawbacks of the static graph-based disjoint learning, as shown in
Figure 1b, to generate an objective graph from a word sequence rather than an initial static graph. A graph structure learning module is utilized to learn a dynamic graph, and then the learned dynamic graph is fed into the GNNs to learn graph representations. The graph structure learning module and the graph representation learning module are integrated with a joint learning paradigm. Two GNN variants, graph convolutional network (GCN) [
17] and graph attention network (GAT), [
18] are investigated in the proposed framework.
The DynGL is evaluated on two typical structured prediction tasks: syntactic dependency parsing and semantic dependency parsing. Experiments are conducted on four datasets: the Universal Dependencies (UD) 2.2, the Chinese Treebank (CTB) 5.1, the English Penn Treebank (PTB) 3.0 in 13 languages for syntactic dependency parsing, and the SemEval-2015 Task 18 dataset in three languages for semantic dependency parsing. The experimental results show that our best-performing model outperforms the previous best models by a 0.40% averaged LAS on the UD 2.2, a 0.22% labeled attachment score (LAS) on the PTB 3.0, and a 0.29% averaged Labeled F-measure score (LF1) on the SemEval-2015 Task 18 dataset, respectively, achieving a new state-of-the-art (SOTA) performance on most language sets in syntactic dependency parsing and semantic dependency parsing. In addition, the DynGL shows more advantages with respect to the running speed over the static graph-based learning model. Our code is publicly available at
https://github.com/LiBinNLP/DynGL (accessed on 5 April 2023).
The rest of this article is organized as follows. The related works are summarized in
Section 2, and the proposed method is described in detail in
Section 3. Then, the experiments of syntactic and semantic dependency parsing are presented in
Section 4. Next, the analysis of the experimental results is presented in
Section 5. Finally, our work is concluded in
Section 6.
2. Related Work
In this section, the related studies of structured prediction and dynamic graph learning are summarized as follows.
2.1. Structured Prediction
Structured prediction aims to predict the structured outputs such as sequences, trees, and graphs [
1,
2]. Many NLP tasks can be viewed as the structured prediction in which the outputs are sequences (e.g., named entity recognition and semantic role labeling), trees (e.g., constituency parsing and syntactic dependency parsing), or general labeled graphs (e.g., relation extraction, semantic dependency parsing, and AMR parsing).
Recent efforts in structured prediction show that GNNs can provide a scalable and highly performant means of incorporating linguistic information and other structural biases into NLP models. GNNs have been applied to learn expressive representations from various kinds of structures (e.g., syntactic trees, semantic graphs, and co-reference structures) and have shown effectiveness on a range of tasks.
Marcheggiani and Titov [
5] utilized an existing syntactic dependency parser to construct a dependency tree and then used GCNs to encode it as additional structural knowledge to improve the performance of semantic role labeling. Zhang et al. [
19] extended GCNs to make it tailored for pooling information over arbitrary dependency structures produced by an existing parser efficiently in parallel. They applied a novel pruning strategy to the input dependency trees to remove the irrelevant subtrees and incorporated the encoded relevant information into relation extraction to improve it. Guo et al. [
8] developed a novel model called attention-guided GCN, which directly takes full dependency trees yielded by an existing parser to improve the relation extraction. Their model can be understood as a soft-pruning approach that automatically learns how to selectively attend to the relevant substructures useful for the relation extraction task. Tang et al. [
4] employed GCNs to simultaneously process the word–character-directed acyclic graphs of two directions to produce graph node representations and then incorporated them into the Chinese NER model to enhance it. Zhou et al. [
20] integrated syntactic dependency structure information encoded by GCNs with AMR parsing to improve the robustness and generalization ability of models. Jiang and Cohn [
21] applied heterogeneous graph attention networks to incorporate the syntactic dependency tree structure and semantic role labeling features of a sentence into co-reference resolutions to build a strong model. Mohammadshahi and Henderson [
11] presented a recursive non-autoregressive graph-to-graph transformer architecture and applied it to syntactic dependency parsing. This model used an initialized model to compute an initial graph and then took the initial graph as input and predicted the target graph. Li et al. [
12] utilized GNNs to encode an initial semantic dependency graph output by an existing parser to build an effective semantic dependency parser. The higher-order information encoded by GNNs is exceedingly beneficial for improving semantic dependency parsing.
Most of these models utilized an existing parser to construct an initial static structure (e.g., dependency tree and semantic graph) and then used GNNs to learn node embeddings based on the static structure to predict objective structures. These models made significant accuracy improvements in the corresponding tasks and multiple languages, owing to the powerful ability of GNNs in learning expressive graph representations.
Even though these models have achieved promising performance, since the graph construction stage and the graph representation learning stage are disjoined, the errors introduced in the static graph cannot be corrected and might accumulate in later stages. In addition, the disjoined learning paradigm negatively affects the model’s running speed.
2.2. Dynamic Graph Learning
Recent years have witnessed a significantly growing amount of interest in graph learning. Graph learning is the process of learning the representations of a graph; GNNs are the most prominent approaches for graph learning. GNNs take in the original feature and adjacency matrix and output node embeddings as graph representations [
17,
18,
22]. Due to the powerful ability in learning graph representations, GNNs have been applied to various downstream tasks, including node prediction [
22], link prediction [
23], and graph classification [
24].
Despite GNNs’ powerful ability in graph learning, unfortunately, they can only be used when graph-structured data are available. Many NLP tasks may only have sequential data, and there is no graph structure available. To address this limitation, several dynamic graph learning frameworks have been presented, for jointly learning graph structure and graph representations [
25].
Chen et al. [
13] presented an end-to-end graph learning framework for jointly and iteratively learning the graph structure and graph embedding. The key rationale of their model was to learn a better graph structure based on better node embeddings and, at the same time, to learn better node embeddings based on a better graph structure. Their framework can cope with both transductive and inductive graph learning. Jin et al. [
14] presented a general framework that can jointly learn a structural graph and a robust graph neural network model from the perturbed graph based on the fact that adversarial attacks are likely to violate some intrinsic properties (e.g., many real-world graphs are low-rank and sparse, and the features of two adjacent nodes tend to be similar) of a graph. Zhao et al. [
15] studied graph data augmentation for GNNs in the context of improving semi-supervised node-classification. They modeled edge weights by taking the inner product of the embeddings of two end nodes with no additional parameters introduced. Sun et al. [
16] proposed a novel Variational-Information-Bottleneck-guided graph structure learning framework, namely VIB-GSL, from the perspective of information theory. VIB-GSL is the first attempt to advance the Information Bottleneck principle for graph structure learning, providing a more elegant and universal framework for mining underlying task-relevant relations. The VIB-GSL learns an informative and compressive graph structure to distill the actionable information for specific downstream tasks.
Inspired by the ideas of these works, we propose a dynamic graph learning framework to address the drawbacks of the static graph-based disjoined learning in structured prediction, to generate an objective graph from the word sequence rather than an initial static graph.
3. Methodology
DynGL is a dynamic graph learning model for structured prediction. An overview of DynGL is shown as
Figure 2. Given a sentence
s with
n words
, there are four stages to predict its objective graph:
Contextualized representation learning—a text encoder is used to learn the contextualized representation of each word. Bidirectional long short-term memory network (BiLSTM) and Transformer were explored as the text encoder in our model.
Graph structure learning—a graph structure learning module is used to learn the adjacency matrix of a potential graph.
Graph representation learning—the contextualized representations and the learned adjacency matrix are fed into the GNNs to learn expressive node embeddings.
Edge and label learning—the concatenation of node embeddings and contextualized representations are fed into a biaffine attention-based model to predict the edges and labels.
Figure 2.
The overall architecture of the proposed DynGL. The input sentence is first encoded by a text encoder to obtain the contextualized representation. Then, the contextualized representation is input into the graph structure learning module to learn the adjacency matrix. Next, the contextualized representation and the learned adjacency matrix are fed into graph neural networks to obtain the graph node representation. Finally, the contextualized representation and graph node representation are concatenated as the final representation to predict the edge and label by the edge and label prediction components, respectively.
Figure 2.
The overall architecture of the proposed DynGL. The input sentence is first encoded by a text encoder to obtain the contextualized representation. Then, the contextualized representation is input into the graph structure learning module to learn the adjacency matrix. Next, the contextualized representation and the learned adjacency matrix are fed into graph neural networks to obtain the graph node representation. Finally, the contextualized representation and graph node representation are concatenated as the final representation to predict the edge and label by the edge and label prediction components, respectively.
3.1. Contextualized Representation Learning
We concatenated the word and feature embeddings and fed them into a text encoder (BiLSTM or Transformer) to obtain contextualized representations.
where
is the concatenation (⊕) of the word and feature embeddings of the word
, and
is the contextualized representation of
.
3.1.1. Word Embedding
One-hundred-dimensional word embeddings from GloVe [
26] were used for English; three-hundred-dimensional word embeddings from fasttext [
27] were used for the other languages.
3.1.2. Feature Embedding
Five types of feature embeddings were used: (1) Part-of-speech (POS) tag: POS tag embedding
was randomly generated,
, where
n is the number of POS tags; (2) lemma: lemma embedding
was also randomly generated.
, where
l is the number of lemmas; (3) character: character embedding was generated using CharLSTM that convolved over three-character embeddings at each time step; (4) BERT: BERT embedding was extracted from the pretrained BERT model [
28]; and (5) RoBERTa: RoBERTa embedding was extracted from the pretrained RoBERTa model [
29].
3.2. Graph Structure Learning
The purpose of the graph structure learning module is to learn the adjacency matrix
A of a potential graph from a complete graph. The distance between two nodes is used to determine whether there is a directed edge between them. The distance between two nodes is usually measured by the metric learning function
. In this work, the metric learning function
was implemented with the attention-based approach. Its architecture is shown as
Figure 3.
Two multilayer perceptrons (MLP) were used to capture the representations of the start node and end node, as Equations (
3) and (
4):
where
and
are two representations of the word
in the start node and the end node computed by
and
, respectively.
The biaffine attention network (as Equation (
5)) was used to compute the score of a possible edge between
and
, as Equation (
6):
where
U,
W, and
b are learned parameters, and
denotes the score of a possible edge between the words
and
.
A directed edge from
to
exists when
is 1.
in
is computed as Equation (
7):
where
is the estimated adjacency matrix, and
is a member of
.
3.3. Graph Representation Learning
The graph representation learning module utilizes GNNs to learn each word’s representation (i.e., node embedding) that contains graph structure information. GNNs encode node embeddings in a similar incremental manner: one GNN layer encodes information about the immediate neighbors, and the K layers encode K-order neighborhoods (i.e., information about the nodes at most K hops aways).
K-layer GNNs were employed, which take in the contextualized representations and the learned adjacency matrix
A and output the embedding matrix of the final layer as node embeddings
R.
in the
kth-layer is computed as Equation (
8):
where
is the graph node representation in the
kth-layer of the GNNs.
When the
GNNLayer is implemented in the
GCN, the representation of node
i in the
kth layer
is computed as Equation (
9):
When the
GNNLayer is implemented in the
GAT,
is computed as Equation (
10):
where
is the attention coefficient of node
i to its neighbor
j at the
th layer,
W and
B are learned parameters,
are neighbors of node
i,
is an active function, and
.
3.4. Edge and Label Learning
The edge and label learning module follows the biaffine attention-based model [
30], which is shown as
Figure 4. There were two components: the edge prediction (shown as
Figure 4a) and the label prediction (shown as
Figure 4b).
For each word
, the graph node representation and the contextualized representation were concatenated to represent it, as shown in Equation (
11). For each of the two components, we used MLP to split the final word representation
into two parts: a start node representation and an end node representation, as shown in Equations (
12)–(
15):
where
and
are the graph node representation and the contextualized representation for the word
, respectively,
and
are the two representations of
in the edge start node and the edge end node computed by
and
, respectively, and
and
are the two representations of
in the label start node and the label end node computed by
and
, respectively.
Two biaffine classifiers were used to predict the edges and labels, as Equations (
16) and (
17):
where
and
are the scores of the edge and label between the words
and
, respectively.
For the edge prediction component, is a scalar. An edge between and exists, where is positive. For the label prediction component, is a vector that represents the probability distribution of each label. The most probable label will be assigned to the edge between and .
Specifically, the Minimum Spanning Tree (MST) algorithm from Dozat and Manning [
31] was adopted to avoid generating invalid trees in the syntactic dependency parsing.
where
and
are the outputs of the edge and the label prediction components, respectively.
3.5. Learning
We can train the system by summing the losses from three modules, backpropagating the error to the parser. The cross-entropy function is used as the loss function, which is computed as Equation (
20):
We define the loss function of the graph structure learning module (as Equation (
21)), the edge prediction module (as Equation (
22)), and the label prediction module (as Equation (
23)):
where
,
, and
are the learned parameters of the three modules, respectively.
Then the Adaptive Moment Estimation (Adam) method is used to optimize the summed loss function
:
where
and
are two tunable interpolation constants, where
.
5. Analysis
5.1. Performance on Different Sentence Lengths
Figure 5 shows the performances of the DynGL(GAT) and GNNSDP(GAT) (the previous best one in semantic dependency parsing) on different sentence lengths. We split the English ID and OOD testing sets of DM formalism into six and seven groups (one group withten tokens) and evaluated the DynGL and GNNSDP on them.
From the result, we can see that the DynGL outperformed the GNNSDP in different groups without and with BERT augmentation. Furthermore, the performances of both parsers degraded as the sentence length became longer, highly suggesting that parsing longer sentences remains a challenge.
5.2. Performance on Different Dependency Lengths
Figure 6 shows the performance of the DynGL(GAT) and GNNSDP(GAT) on different dependency lengths. The length of a dependency from word
to word
is defined as equal to
. We split the English ID and OOD testing sets of DM formalism into eight groups and evaluated the DynGL and GNNSDP on them.
From the result, we observed that our model was better than the GNNSDP at predicting the dependencies on various dependency lengths, which demonstrates the ability of our model to capture long-range dependencies.
5.3. Running Speed
The parsing speed directly represents the running speed of a parser. Not only the accuracy but also the parsing speed determine whether a parser can be applied to downstream tasks. Therefore we compared the DynGL, Biaffine, and GNNSDP in syntactic dependency parsing and semantic dependency parsing with respect to the parsing speed on an Nvidia GeForce RTX2080Ti server.
To avoid the influence of the preprocessing stage, the annotated tokens, POS tags, and lemmas in the dataset were directly used without preprocessing. The result is shown in
Table 5.
From the result, we can see that the DynGL performed better than the GNNSDP with respect to the parsing speed and was slightly slower than the Biaffine. It shows that incorporating the GNN and Biaffine with dynamic graph-based joint learning mechanism is more effective in terms of the accuracy and parsing speed.
5.4. Significance Test
In the experiment of syntactic dependency parsing, the DynGL and Biaffine were trained with five different random seeds on the UD 2.2, PTB 3.0, and CTB 5.1. In the experiment of semantic dependency parsing, the DynGL and GNNSDP were also trained with five different random seeds on the SemEval-2015 Task 18 dataset. The paired student’s t-test showed that the DynGL outperformed the Biaffine and GNNSDP in syntactic and semantic dependency parsing with a significant p-value 0.005.
5.5. Case Study
We provide a parsing example to show why the DynGL can outperform the GNNSDP using dynamic graph learning.
Figure 7a,b represent the adjacency matrices fed into the GNNSDP and DynGL.
Figure 7c,d show the parsing results of the GNNSDP and DynGL for the English sentence “
They serve cracked wheat, oats or cornmeal.” (sent_id = 40504062, in the OOD testing set of PSD formalism). The two parsers were implemented with the GCN and trained without BERT augmentation.
From
Figure 7a, we can see that there are two erroneous values (red square) in this adjacency matrix, indicating that the graph structure input into the GNNSDP was noisy. Using learned node embeddings based on the noisy graph led to two erroneous dependent edges in the semantic dependency graph parsed by the GNNSDP (red edge labeled RSTR).
Benefiting from the dynamic graph learning framework, the learned graph structure input into the DynGL was correct. Therefore, the DynGL produced a correct semantic dependency graph.
5.6. Discussion
In this study, we proposed a joint-learning-based dynamic graph learning framework to address the drawbacks of static graph-based learning approaches. From the above results and analysis, the conclusion can be reached that the proposed framework is capable of jointly learning the graph structure and graph representations and can generate an objective graph from a word sequence, rather than relying on an initial static graph. The outstanding performance has demonstrated that the proposed framework is effective in structured prediction. The trained syntactic and semantic dependency parser with the proposed framework could be applied in many downstream tasks, such as machine translation, abstract meaning representation, semantic role labeling, and so on. Although there are important discoveries revealed by this study, there are also limitations. First, the tokens in the input sequence must correspond to the nodes in the objective graph. Second, training the graph structure learning and graph representation learning modules requires a large amount of labeled data. Therefore, there are two areas for further research. The first limitation may be addressed by adding a graph node alignment module. The second limitation may be alleviated by graph self-supervised learning.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





