1. Introduction
Autonomous vehicles [
1] are required to identify roads and obstacles [
2] for fine-grained path planning. Among all crucial autopilot techniques, it is quite important to predict monocular depth in front of the vehicle; thus, it becomes a hot research topic in both academy and industry.
The mature solution for depth estimation is based on radar ranging [
3,
4], which requires a radar ranging device at a designated location on the vehicle to sense the road information. However, radar ranging has certain drawbacks, including high equipment costs [
5], inconvenient installation [
6], and unfavorable deployment. Therefore, this paper adopts another cost-effective solution, i.e., using a monocular image for depth estimation. Currently, there are still several limitations in monocular depth estimation, including large errors, difficulties in data acquisition, and complex model training.
Thanks to the rapid development of deep learning, the existing monocular depth estimation techniques now consist of supervised learning and unsupervised learning [
7,
8,
9]. Among them, although the supervised monocular depth prediction obtains higher accuracy, the training cost is extremely large due to the difficulty in acquiring the ground truth depth. In this paper, we propose an unsupervised learning method for monocular depth estimation.
The main problem solved in this paper is to use monocular vision to extract unsupervised depth estimation model and depth map from continuous video clips, construct point clouds to obtain complete 3D modeling and configure the system to an intelligent remote control car. Although monocular depth estimation has been widely adopted in autonomous driving, it largely relies on texture features with proper illumination; thus, it is not suitable in GPS blocked environments such as tunnels and underground parking structures.
In this paper, we leverage the geometric consistency to improve the depth prediction accuracy, and propose a lightweight 3D scene construction method via only single image. Specially, based on camera imaging principles, we reconstruct the 3D scene of the depth map, and color the 3D model by the colorful pixels from the RGB image. This colored three-dimensional color image makes the depth estimation results more intuitive and facilitate further analysis.
Our contributions include:
We propose a unsupervised deep learning method for monocular depth estimation, and design a geometric consistency loss to enhance the robustness in extreme environments (
Section 3). The method avoids the tedious steps of manual calibration and reduces the cost of manpower and material for ground truth labelling.
We devise a three-dimensional modeling approach which converts a planar image stream into a three-dimensional point cloud model, with low restrictions on the scene and few requirements for shooting (
Section 4).
We developed a prototype system for our autonomous vehicles, and conducted extensive experiments in real-world scenarios. The results show the effectiveness of our system (
Section 5).
The remainder of this article is organized as follows. In the second section, we introduce the background and technical foundation of our work, and discuss the two parts of “monocular” and “unsupervised”, respectively. In the third section, we introduce the monocular depth estimation algorithm used in our experiment, focusing on the principles and methods of introducing depth rendering and geometric consistency loss to the system. In the fourth section, we introduced the principles and methods of point cloud model transformation used in the experiment. In the fifth section, we configure the system on the ROS smart car to carry out the experiment. In this section, we present and quantify the results of depth map transformation and point cloud model generation. We summarize the experiments in the sixth section.
3. Monocular Depth Estimation
This paper proposes a monocular depth estimation algorithm which is simple, cheap and easy to deploy than traditional methods such as lidar or dual cameras.
Specially, we design an unsupervised learning model based on convolutional neural networks. The supervision of deep learning networks comes from view synthesis. Its principle comes from the fact that a photo of the same scene is found from a different camera perspective for synthesis. Thus, we composite the target view with a depth per pixel in a given image, as well as pose and visibility in nearby views. The synthesis process can be implemented in a fully differentiable manner using CNNs as geometry and pose estimation modules.
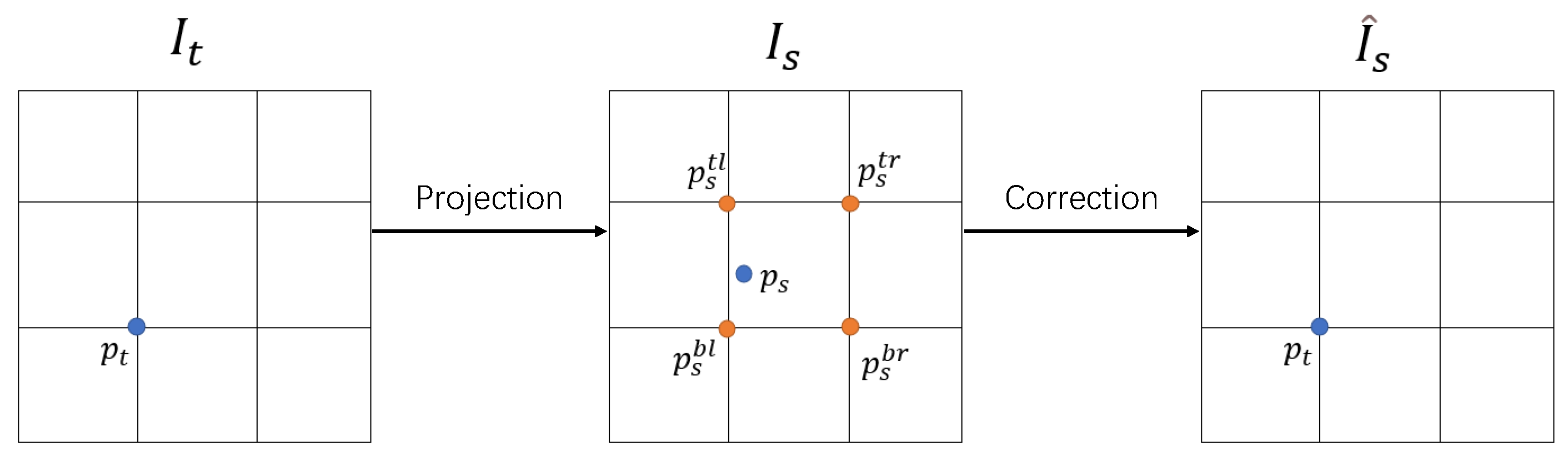
In addition, since the calculated pixels in composite view are not integer points, we explore a depth map rendering model; thus, the pixel points are weighted and averaged by four nearby pixels to fill the blanks.
The view synthesis process is shown in
Figure 1. First, we specify an image as the target view, and the other images as the source view. The depth information of the source view is obtained through the depth prediction model, and then the pixel correspondence to the target view is calculated according to the camera motion and camera internal parameters. Next, we use the source view as input to obtain the composite view of the synthesized target image. Finally, the pixel difference between the target view and the composite view is used as the loss function of the deep learning model. During our experiment, the training video is treated as a collection of RGB images
, one of them serves as the target view
, and the rest serves as the source view
.
The composite view is represented as:
In this equation, p refers to the pixel in the image, and comes from the source view . After passes the depth prediction model and generates the depth map, according to the camera’s internal parameters and camera motion process, it is converted to the composite view under the coordinate system of the target view. Such a transformation is based on a depth map rendering model. is the difference between the two views. That is, the loss function of the deep learning model.
In addition, this is a differentiable depth map-based rendering model; thus, it can reconstruct the target view by sampling from the source view based on the depth map and relative position pose .
We further calculate the coordinates corresponding to the source view through the following equation:
where we use
to represent the coordinates of one pixel in the target view, and
K to represent the camera reference matrix.
It is worth noting that the calculated
are continuous values. Since the calculated pixel position is not necessarily an integer value and cannot be assigned directly, in order to fill the value of
with the value of
obtained, we need to adopt the following strategy. We need to obtain the RGB value of its adjacent 4 pixels (the 4 points are upper left, upper right, lower left, lower right) to approximate the pixel to be filled. The specific process is shown in
Figure 2; the approximate calculation is based on the following:
In this equation, is the linear scale of spatial proximity, and this ratio satisfies the relationship . t refers to the top, b refers to the bottom, l refers to the left, and r refers to the right.
The above deep learning model is based on three premises. First, all scenes are static and there are no moving objects. Second, in all target and source views, there is no occlusion and unblocking process. Finally, all surfaces are Lambertian surfaces. In view of the above premises, this paper proposes a supplementary term for the loss function in view composition, i.e., the geometric consistency loss. It breaks through the limitations of synthesis technology and optimize the existing model.
We use the geometric consistency of objects to constraint the depth estimated in all scenes. Precisely, we require minimal difference between
and
from the same object. This not only maintains geometric consistency between samples, but also the entire video sequence. With such a limitation, the depth inconsistency
is calculated for any frame of the video:
where
is the depth map of
calculated by using the distortion
of the relative position pose
between A and B time slots.
is a depth map interpolated from the estimated depth map
. Their differences are normalized by the sum value. This is more intuitive than using absolute distance because it treats points of different absolute depths equally in optimization. In addition, the function is symmetric and the output is naturally between 0 and 1, which contributes to numerical stability in training. With such a deep inconsistency
, we define the geometric consistency loss as:
Note that our loss function with view synthesis technology is self-supervised. We take the geometric consistency loss as a supplement to the loss value calculation, and redesigns the loss computation process. In practice, minimizing the depth of predictions between each successive pair makes them geometrically consistent.
4. 3D Point Cloud Conversion
This paper proposes a method of converting a single depth map into a point cloud array and presenting it as a three-dimensional model, which have the advantage of being intuitive and figurative. We generate a point cloud array through the following three steps. First, calibrate the camera parameters to obtain the parameters of the camera. Then, we calculate 3D coordinates of each point in the point cloud map according to the camera’s internal parameters, images’ color information, and depth information. Finally, we output the point cloud with color.
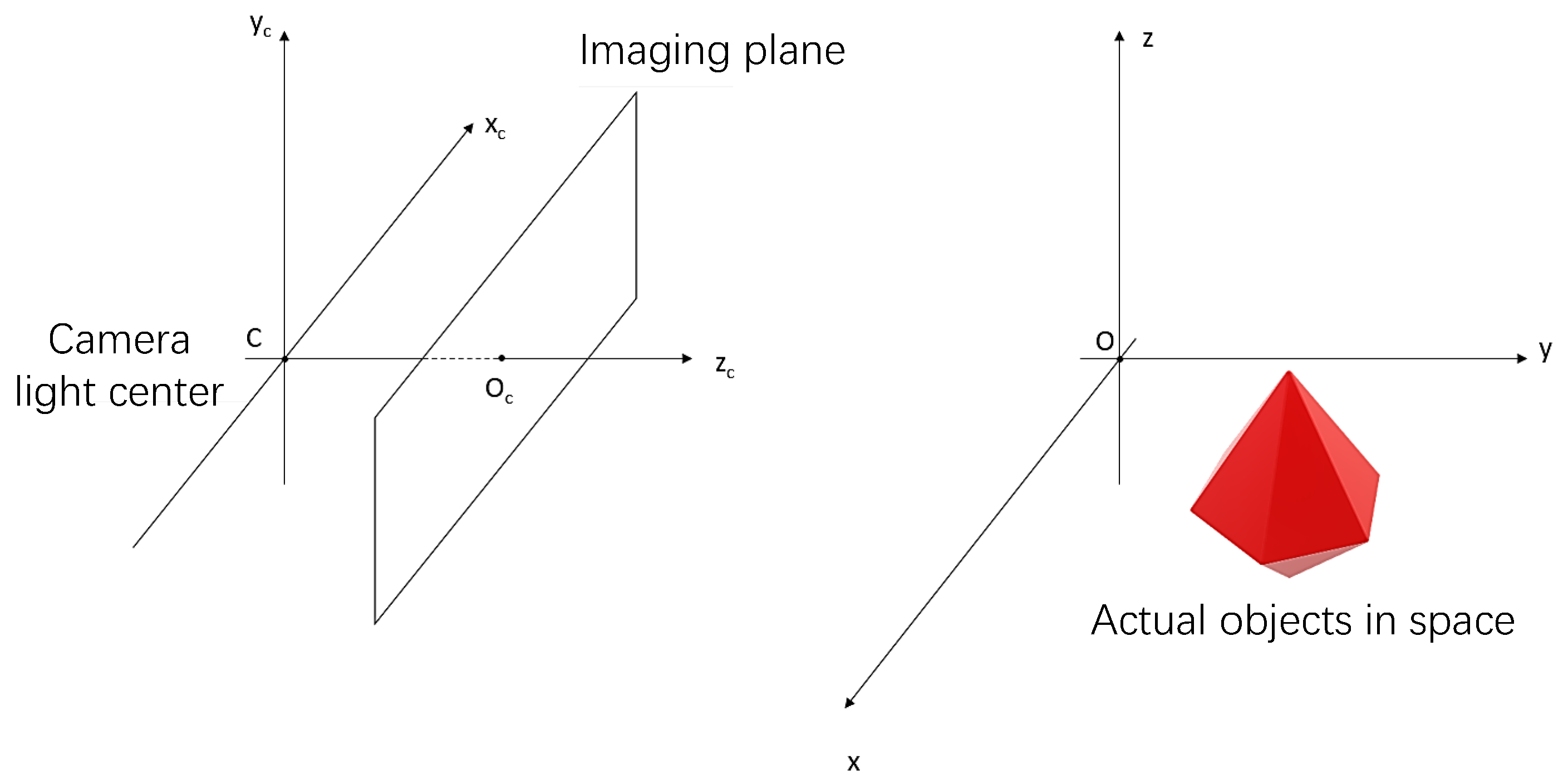
Calibrate the camera parameters is a process of converting from the world coordinate system to the camera coordinate system, and ultimately to the image coordinate system. Among the above systems, the world coordinate system is of three-dimensional space, which is used to describe the specific position of objects in the real world. The camera coordinate system is established based on the camera, which is used to describe the position of the object in the camera perspective. The image coordinate system is the coordinate system of the pixel on the image, which is used to describe the position of the pixel.
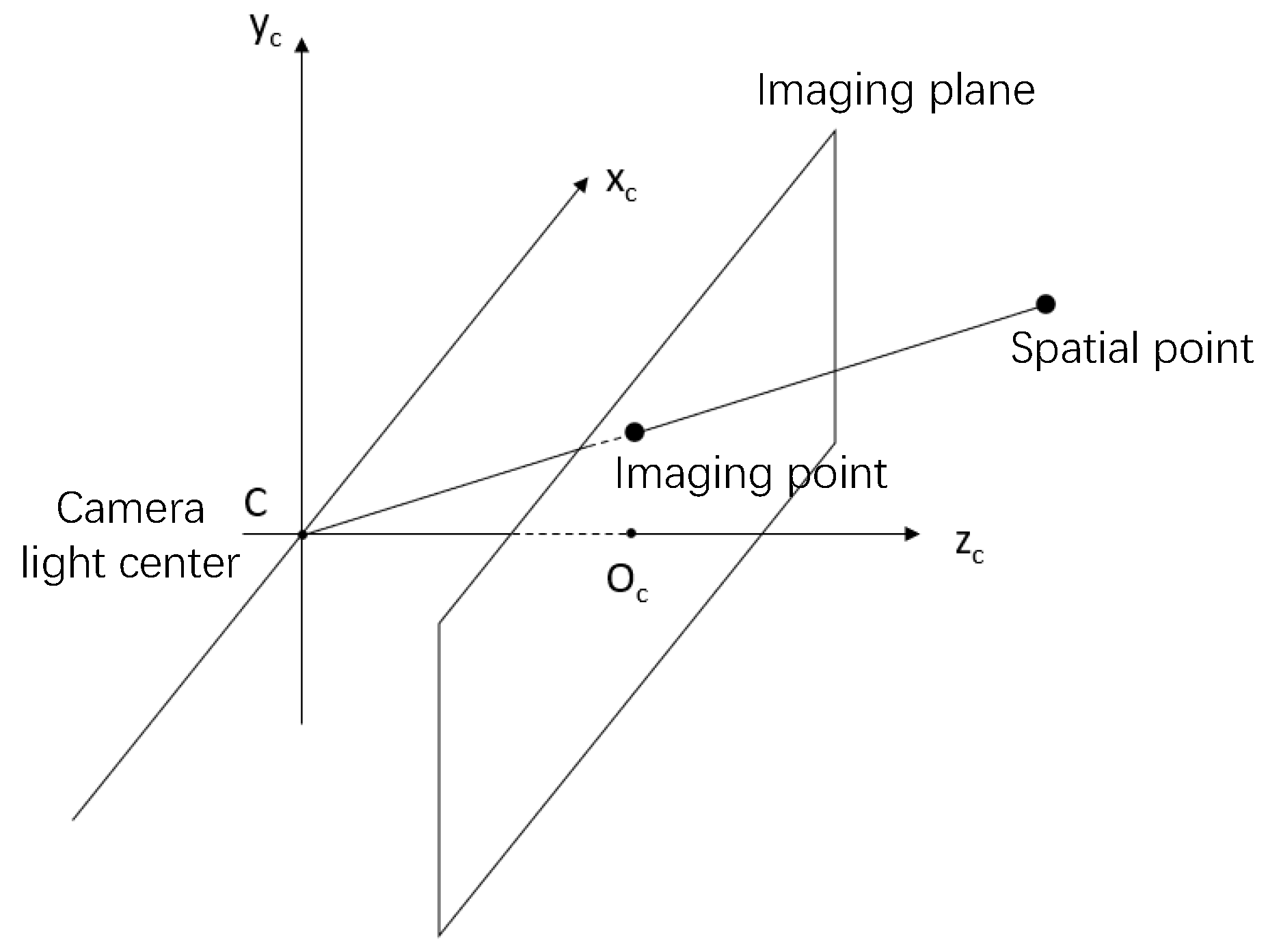
As shown in the
Figure 3 below, the camera coordinate system is on the left while the world coordinate system is on the right. We first transform the three-dimensional drawing into the camera coordinate system by translation and rotation, where the rotation matrix
R and the translation vector
t are the external parameters of the camera. The center
C of the camera coordinate system is the optical center of the camera, and the imaging plane of the camera is parallel to the
plane and in the positive direction of the
. The intersection point of the imaging plane and the
is
the main image point, and then the point in the camera coordinate system and the camera light center are connected. The intersection point of the connection and the imaging plane is the image formed by the point in the camera, as shown in the
Figure 4 below.
In general, the camera’s internal parameter matrix
K is as follows:
where
and
is the focal length of the camera in the
x and
y directions,
is the coordinate of the main image point, and
s is the tilt parameter of the coordinate axis, which is ideally 0.
The input for camera calibration is the image coordinates of all interior corner points on the calibration image, and the three-dimensional spatial coordinates of all inside corner points on the calibration image, where the default image is on the plane of . The output of the camera calibration is a matrix of internal and external parameters of the camera.
In order to complete the calibration of the internal parameters of the camera, a camera parameter calibration plate with a black and white grid needs to be prepared. The process of parameter calibration is as follows:
Set parameters for finding sub-pixel corners.
Build an array to store the position coordinates of each corner point, each coordinate contains data.
Define that the calibration plate is located on the
plane, so the z-coordinate of all points is 0. Assign a value to the
x,
y coordinates of each point in a black and white grid length, for example, the point coordinates of the first row are:
Read all captured pictures and find all sub-pixel corners.
Enter the data in the above steps as parameters, and call the function of OpenCV2 to calibrate the camera parameters.
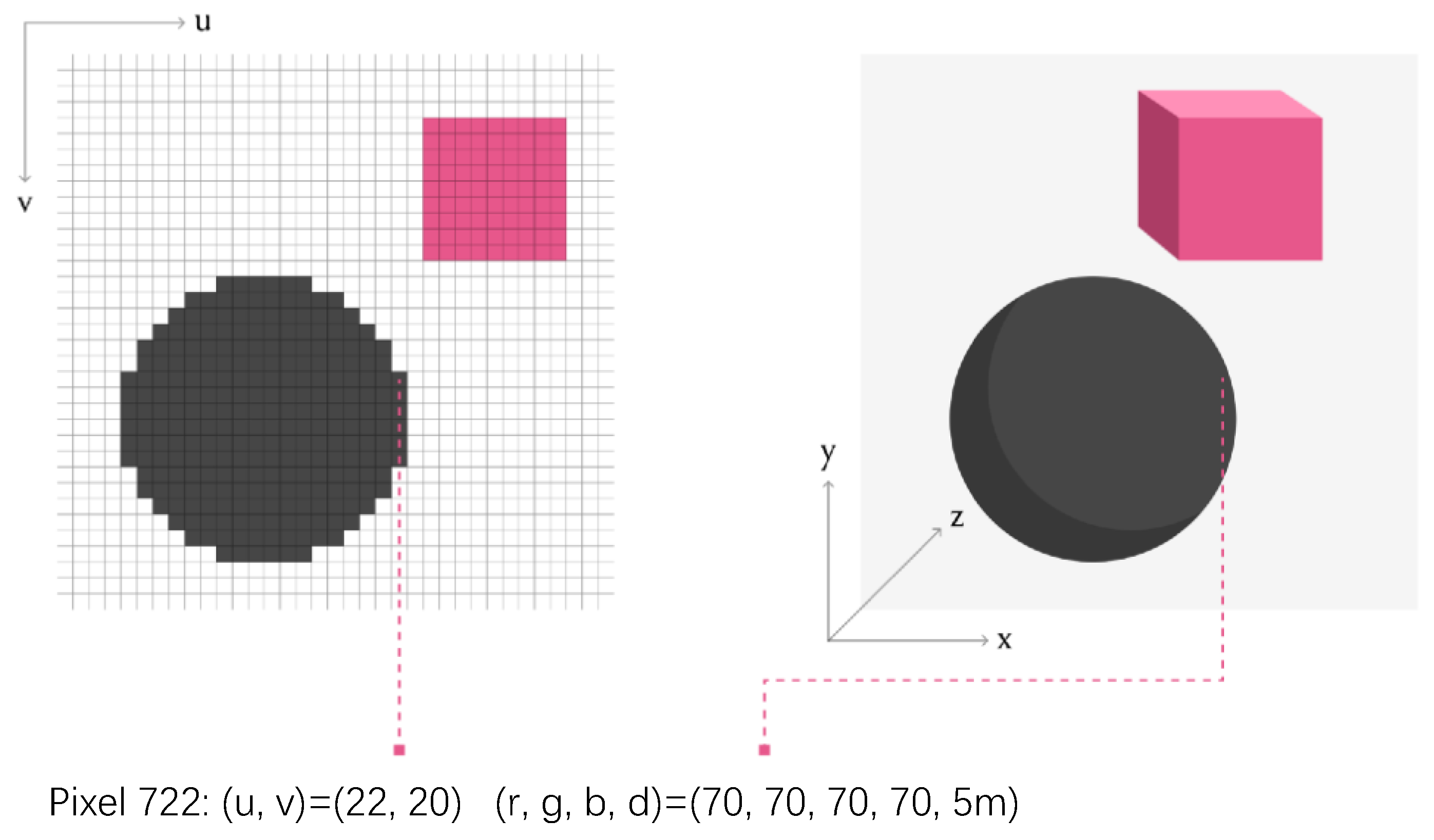
With the camera’s parameters acquired, three-dimensional modeling can be performed in combination with depth information. The core task of 3D modeling is to clarify the conversion relationship between RGB images and the 3D coordinates of the scene; thus, we need to study the camera properties. The figure below reflects the imaging principle of the camera.
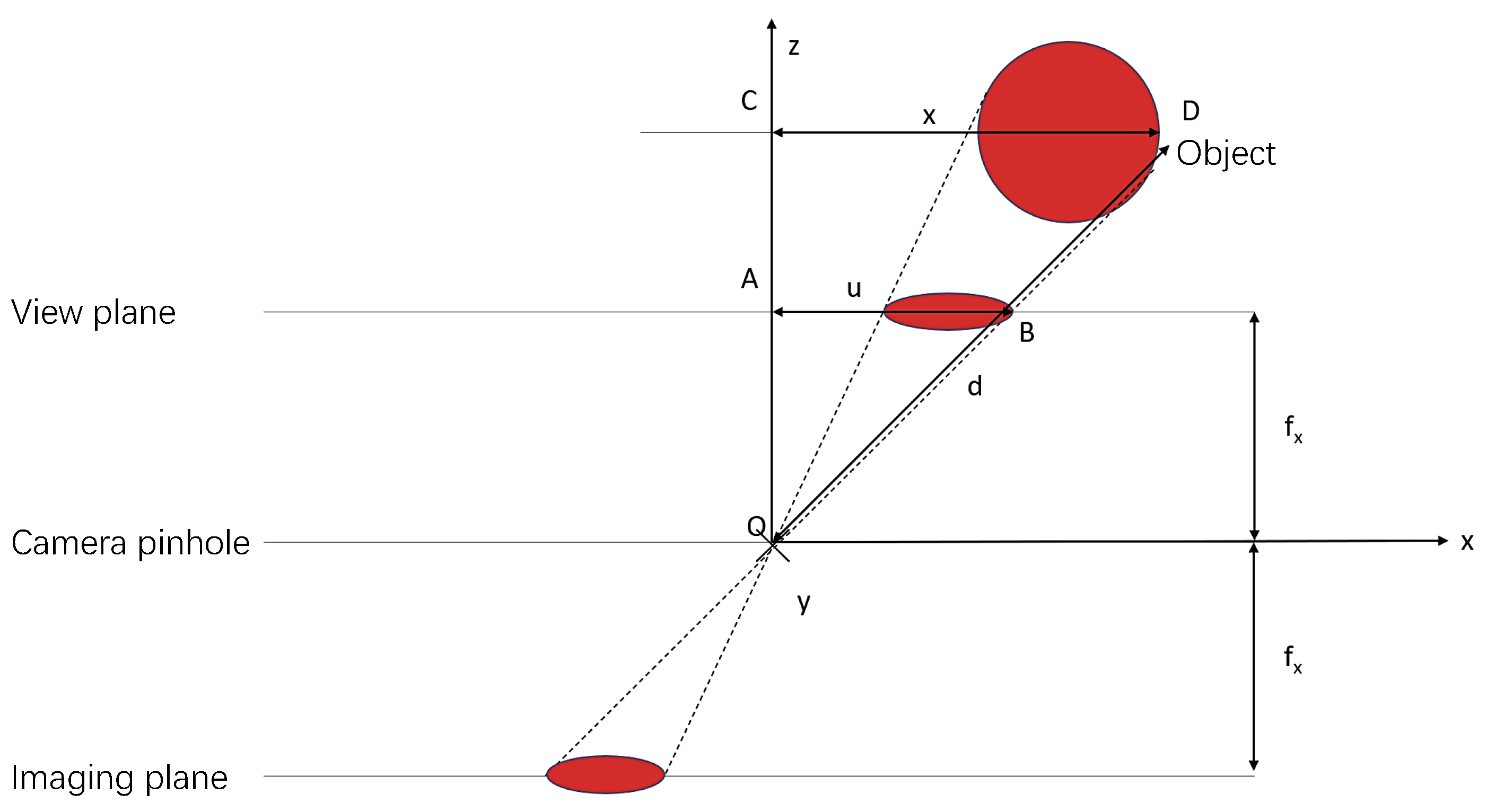
As shown in the
Figure 5, suppose there is an object in front of the camera, which is displayed as a projection of the
plane in the form of a top view. On the left, there is a pinhole camera that displays the object in front of the camera on the screen. The world coordinate system is aligned with the camera, so the z axis extends to the direction the camera sees. The world coordinate system is aligned with the camera, so the
z axis extends to the direction the camera sees. Point
D of the object is point
B in the image created by the camera. The horizontal coordinate of
D is
x, and the corresponding horizontal pixel coordinate of
B on the image is
u. The y-axis is the same, the vertical coordinate of
D is
y, and the corresponding vertical pixel coordinate of
B on the image is
v. In ordinary RGB images, there is no embodiment of the information of the z-axis coordinate of point
D, so depth information
d is also essential in the work of three-dimensional coordinate reconstruction. There are many references when estimating depth, the most important of which is the focal length, which marks how pixel coordinates are converted to length, which is the actual distance between the lens and the film or sensor.
So far, we have preliminarily clarified the conversion relationship from the world coordinate system to the camera coordinate system. In order to further explore the transformation of the camera coordinate system to the world coordinate system, an RGB map and the corresponding depth map are introduced for analysis.
As shown in the
Figure 6, on the left is a two-dimensional plan, take the sample point with pixel coordinates
, each pixel has an RGB color value and corresponding depth. On the right is a schematic of two objects in a three-dimensional coordinate system. Depending on the imaging principle of the camera, the position
x can be easily derived from the lateral pixel coordinates
u and depth information
d of each pixel. In addition, do the same for
y and
v. It should be noted that for pinhole camera models, the focal length in the
x and
y directions is the same, but this is not always the case in reality for cameras with lenses, so the focal length in the
x and
y directions needs to be calibrated when parameterizing in the camera. Only then can the correct coordinate calculation be carried out. It is not difficult to calculate the corresponding relationship between pixel coordinates and three-dimensional spatial coordinates as follows:
where
is the camera’s internal parameter matrix,
is the camera’s external parameter matrix,
R is the rotation matrix, and
is the translation vector.
The specific process of this module is as follows:
Input RGB diagram, depth map, depth map scale factor, camera internal parameter matrix K and camera external parameter matrix.
Create an array of floating-point numbers u, and a shape [1] of length RGB matrix.
Create an array of floating-point numbers v, and a shape [0] of length RGB matrix.
Default camera coordinate system as the world coordinate system. Create an array of point clouds that store the coordinates and color data for each point. The array length is shape [1] × shape [0] of the RGB matrix. That is, each pixel corresponds to a point in the point cloud.
Iterate through each pixel.
According to the formula above, the coordinates corresponding to each pixel are generated, and the values of , and B are maintained for the values of the pixels.
Save the point cloud array as a “.ply” file.
The rgb entered in the code is an RGB image, consisting of a two-dimensional matrix of elements as tuples of . Depth map is composed of a two-dimensional matrix based on the depth information of a single point. Depth map scale factor may be different for different cameras, such as the scale factor of the camera used in the common TUM dataset is 5000. Since the depth map in this paper is not obtained by the depth camera, but by the depth prediction deep learning network, there is no camera parameter that can be referenced, and this parameter needs to be manually calibrated. This scale factor is the ratio of the values stored in the depth map to the true depth.
K is the 3 × 3 camera internal parameter matrix, and camera external parameter matrix is the transformation matrix of 4 × 4 under the Cartesian coordinate system of the camera coordinate system to the world coordinate system. If no external parameter matrix is entered, then the matrix defaults to:
So far, we have obtained the array of point clouds corresponding to the RGB color image. Next, the array of point clouds is stitched together into a 3D model. In this paper, the ICP (Iterative Closest Point) algorithm is used for implementation. Considering the differences between real scenarios and ideal scenarios, the basic ideas of algorithms discussed in this article will be divided into reasoning in ideal situations and methods for applying them to real situations. First, we discuss the reasoning of ideal situation. Suppose that the two point cloud arrays entered are P and Q, where: , .
and are the points in the point cloud, .
There is a set of correspondences between the points in these two point clouds:
Such a correspondence indicates that the point cloud
from
P corresponds to the point cloud
from
Q. The output of the ICP algorithm is a translation vector
t and a rotation matrix
R, satisfying that the difference between the two point clouds is minimized after this translation and rotation on the point cloud
P. This difference is calculated by the following formula:
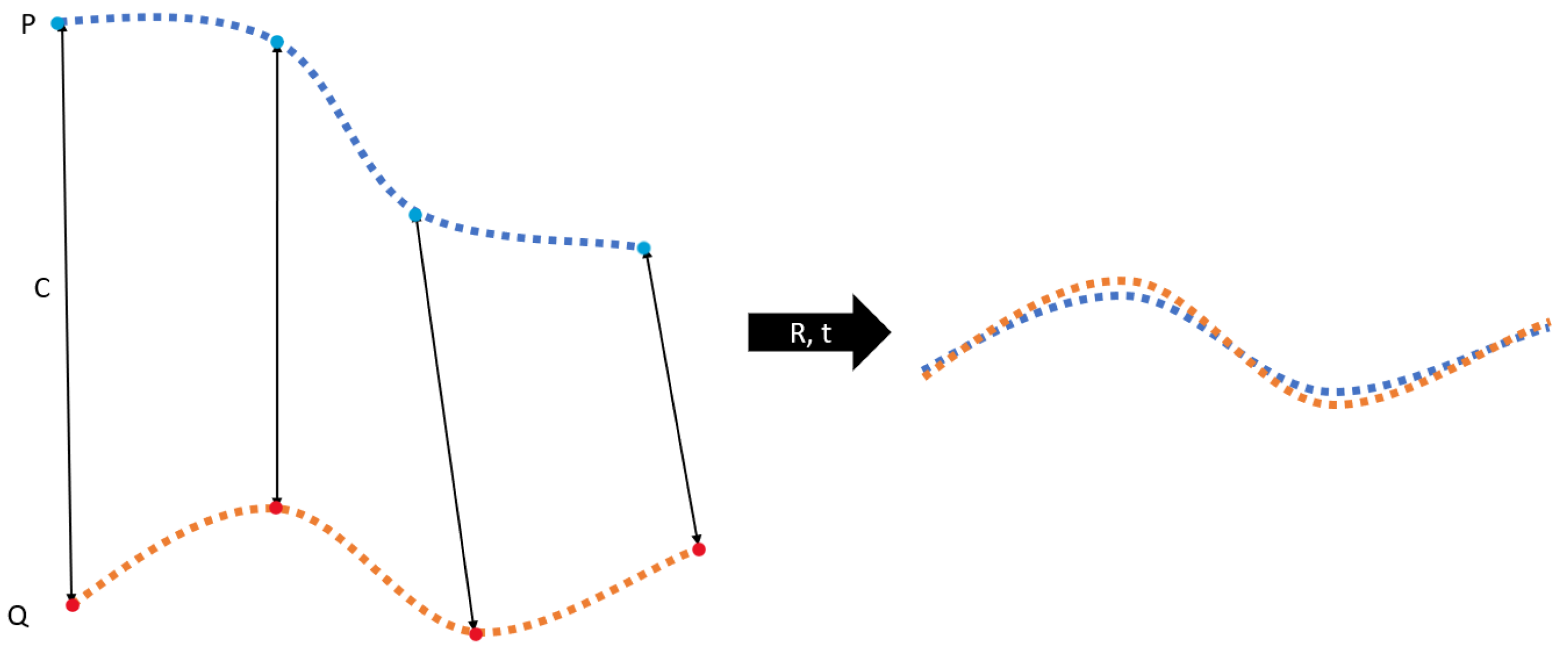
The core idea of ICP is that assuming that we know the correspondence
C between point cloud
P and point cloud
Q, and assuming that this relationship is correct, then ICP needs to minimize the sum of distances between the corresponding points through the rotation and translation operation of the point cloud
P, as shown in the following
Figure 7:
The blue part on the left side of the figure is the point cloud P, the red part is the point cloud Q, and the black double-headed arrow indicates the correspondence between the points in the point cloud. After the point cloud P is translated and rotated , the resultant point cloud is shown on the right side of the figure. The ICP algorithm calculates such a rotation matrix R and translation vectort based on the coordinates of the points in the point cloud P and Q, and the correspondence C.
The method is to first calculate the center of gravity of the two point clouds, and then subtract the geometric center coordinate of
P from the geometric center coordinate of
Q, and the resulting vector is the translation vector
t, and after such a translation of
P, the geometric center of the two will overlap. The calculation formula is:
where the center of gravity of
P and the center of gravity of point cloud
Q are
and
.
indicates the number of point pairs in the corresponding relationship.
Next, two new point clouds
and
can be generated, with the same center of gravity at the same point. The resulting method is to subtract the corresponding center of gravity coordinates for each point in point cloud
P and point cloud
Q, and the calculation formula is:
Therefore, the expression of the original error function becomes the following expression, in which case the error function is only related to the rotation matrix, satisfying the following expression:
Solving such a matrix R is called an orthogonal procrustes problem, and such a problem can be solved by singular value decomposition. The solution process of matrix R is as follows:
First, calculate the cross covariance matrix:
Next, the transpose of the matrix
U and
D matrices is obtained using singular value decomposition. In addition, obtain the transpose of the
V matrix:
where
U,
V is the rotation matrix of 3 × 3.
D is the diagonal matrix.
Finally, the rotation matrix
R is calculated using
U,
V:
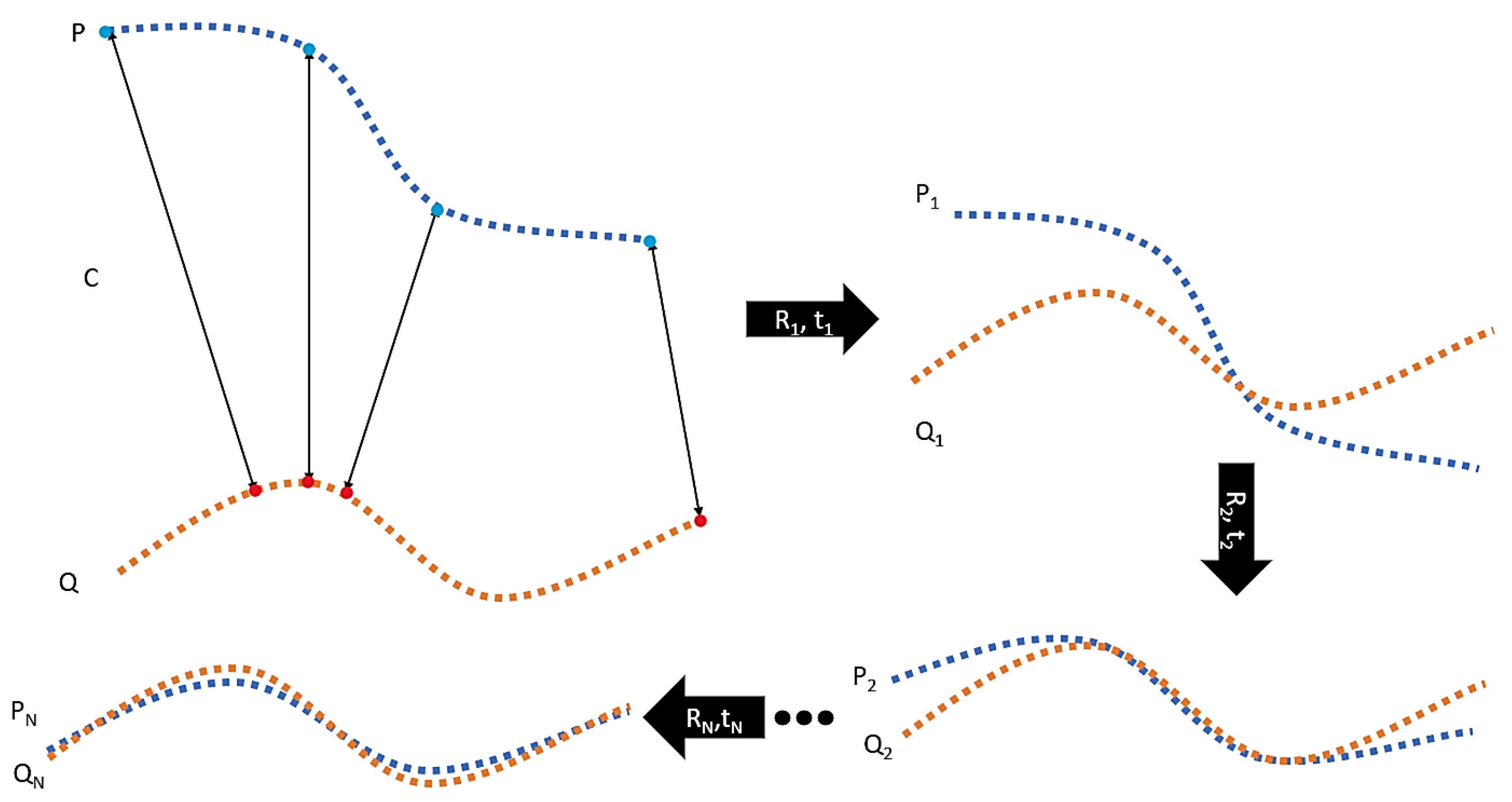
From the above calculation, we can obtain the rotation matrix R and the translation vector t. However, this is in the ideal situation of knowing the correspondence C in point cloud P and point cloud Q, but in reality there is often no such correspondence C. The ICP algorithm needs to iterate to find its correspondence. It is basically impossible to find the rotation matrix R and the translation matrix t in one step, ICP will guess such a correspondence , and then use this correspondence to calculate the , and apply it to the point cloud P to obtain the , and then do the same for and Q, and so on. The more iterations, the smaller the error function.
Take the following
Figure 8 as an example of two point clouds:
The blue point cloud P and the red point cloud Q have no corresponding relationship C. We assume that the point on Q corresponding to a point on P is the point on Q closest to that point. Thus, the correspondence is established, through which and can be calculated, and such translations and rotations can be applied. Obtain new point cloud and . This operation is repeated until the error function of the two is small enough to obtain a spliced point cloud.
In this paper, the coordinate system transformation relationship under different coordinate systems is combined with independent experiments on cameras to obtain the internal and external parameter information of cameras. We adopt the imaging principle of the camera and the parameters of the camera to reconstruct the 3D scene of the depth map, and extracts the color value of each pixel from the RGB map to color the 3D model, and finally converts the video stream into a 3D model, making the results of depth estimation more intuitive and facilitates analysis.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}