1. Introduction
Artificial intelligence (AI) is one of the greatest technologies in the 21st century. In recent years, with the rapid development of the new generation of AI technology, the research and application of intelligent unmanned systems have received widespread attention. Intelligent unmanned systems can not only complete simple and repetitive tasks but also complex tasks that are difficult for humans. The core advantage of intelligent unmanned systems lies in achieving high performance while having extremely low costs. Multi-agent collaboration is one of the most important technologies in intelligent unmanned systems; it is more effective than single-agent technology when facing complex task requirements. Multi-agent collaboration technology describes the coordination of multiple agents to achieve stronger performance, better efficiency, and higher adaptability than simple addition. The application of multi-agent systems will be more and more extensive with the progress of AI technology, which will have a profound influence on future daily life and industrial production.
Task allocation is one of the most important problems in multi-agent collaboration; it has been a very important research topic in recent years. Task allocation mainly solves the problem of allocating tasks to intelligent agents with reasonable strategies in complex environments, so that the performance and efficiency of task completion are as high as possible. The specific goal of task allocation is to ensure the constraint conditions and to maximize the optimization of completion time and resource consumption. At present, the technologies of multi-agent task allocation are not good enough, so improving and innovating methods and algorithms is crucial.
The task allocation problem is usually represented as a combinatorial optimization problem (COP). The traveling salesman problem (TSP) is a common single-agent task allocation problem which is classical in the combinatorial optimization area. The TSP describes how a travel merchant (agent) can visit multiple cities and return to the original city of departure with the minimum path. It only needs to consider the order of task execution of a single agent. Multi-agent task allocation problems are more complex as they need to consider not only the execution order but also the executor of each task. Multiple traveling salesman problems (MTSPs) [
1] and vehicle routing problems (VRPs) [
2] are well-known for multi-agent task allocation. The MTSP expands the TSP to the multi-agent scenario. Multiple agents start from the same starting point and finally return to this point after completing a series of tasks. The goal of this problem is to obtain a set of task execution plans that have the shortest total path. VRP is a kind of problem that adds constraints on the basis of MTSP, such as the capacitated vehicle routing problem (CVRP) with capacity constraints and the split delivery vehicle routing problem (SDVRP) with split constraints [
3]. It is noteworthy that these kind of multi-agent task allocation problems require that all agents must start from and return to the same point. The complexity and difficulty of solving the multi-agent task allocation problem are far greater than the single-agent task allocation problem. In recent years, many scholars have focused on this kind of multi-agent task allocation problem, and have developed a number of solutions [
4].
For the concerned multi-agent task allocation problem with multiple depots, the initial positions of all agents need to be taken into account. This kind of problem can be occasionally confronted in real life, and has important applications in many fields, such as multiple unmanned aerial vehicles (UAVs), multiple unmanned ground vehicles (UGVs), and multiple unmanned surface vessels (USVs). When the environment is dynamic and changes during task execution, the subsequent allocation of agents can be regarded as a new task allocation problem with multiple depots. Similarly, in the process of multi-agent collaboration, if there is an emergency of some agent failures, a new solution can be obtained immediately to handle the emergency. However, the multi-agent task allocation problem with multiple depots is more difficult than the single-agent or the single-depot problem due to the diverse locations of the agents. So far, there are few satisfactory solutions in terms of accuracy and efficiency.
For the NP-hard task allocation problem, there are two types of classical algorithms: optimization algorithms [
5] and heuristic algorithms [
6]. The optimization algorithm can yield an optimal solution, but the computational burden will increase exponentially, often becoming too great to be accepted. Typical optimization algorithms for task allocation problems are simplex algorithm, branch and bound, etc. In contrast, heuristic algorithms are more practically useful. Although a heuristic algorithm can only yield an approximate solution, its computational efficiency is much higher than the optimization method. Usually, heuristic algorithms can be modified by changing the associated basis so as to achieve better results or higher efficiency. However, heuristic algorithms usually require formulating rules which may be highly dependent on human expertise and experience. The commonly used heuristic algorithms in task allocation include the genetic algorithm (GA) [
6], ant colony optimization (ACO) [
7], particle swarm optimization (PSO) [
8], immune algorithm (IA) [
9], tabu search (TS) [
10], simulated annealing (SA) [
11], etc.
After heuristic algorithms had been widely used for decades, deep learning methods for task allocation began to rapidly develop [
12]. The encoding method, based on the attention mechanism [
13], and the decoding method, based on the pointer network [
14], are two important parts of the deep learning method of task allocation.
In the rapid development process of deep learning, the sequence generative model is one of the most representative and most developed models [
15]. It is now relatively mature in machine translation [
16] and speech recognition [
17]. The attention mechanism and the transformer model [
18] are the most important achievements in sequence generation. In traditional recurrent neural network (RNN) [
19], it is difficult to summarize all the context details in the sequence encoding process, and attention mechanisms can select more important information from a large number of contexts. The attention mechanism determines the correlation of context details that do not rely on time sequence in order to extract more valuable detail segments from the input sequence. Specifically, the attention mechanism calculates a variable context vector by weighted averaging and then adds the context vector as additional information into the RNN to output the final sequence. The transformer model [
18] is a new attention mechanism proposed in 2017. The transformer attention mechanism no longer relies on the traditional RNN model, but only uses attention mechanisms to build the encoder and decoder. A self-attention mechanism was proposed in the transformer model, which completes parallel encoding of all input segments to greatly reduce training time. In addition, a multi-head attention mechanism was proposed to extract different features through multiple independent single-head attention layers, further improving the performance of the model.
The pointer network (Ptr-Net) [
14] is an important application of the attention mechanism in task allocation problems which solved the TSP using a deep learning method. Ptr-Net combines a sequence generative model and the graph attention network (GAT) [
20]. The encoder of Ptr-Net completes feature extraction of task points using the attention mechanism to obtain graph embeddings, and the decoder outputs the generation of task sequences. The output of Ptr-Net is a pointer to an input element, which is then sorted in a new order. Specifically, Ptr-Net calculates the state vector of the current moment by the pointer and the state vector of the previous moment, then uses the attention mechanism to calculate the weight of all input elements corresponding to the current state, and finally outputs the pointer according to the weight value. In Ptr-Net, all elements of the input sequence are calculated independently of each other, so changing the order of the input sequence will not change the final result. Ptr-Net contributes enormously in the task allocation area, which greatly improves the computational speed while ensuring task completion accuracy.
On the basis of Ptr-Net, the reinforcement learning method [
21] was proposed to overcome the difficulty of label collection in COPs. The attention model [
4] extended the pointer network to multiple agents, effectively solving several VRP problems. The relational attention model [
22] modified the attention model and improved the performance and computational efficiency. However, the above mentioned methods cannot handle complex multi-agent COPs, and only a few studies have explored the multi-agent task allocation problem with multiple depots [
23,
24].
Based on the above literature review, a multi-agent task allocation method with multiple depots is proposed, where an improved encoder–decoder architecture is developed. A full-graph encoder with multi-head attention mechanism and a two-way selection decoder based on a pointer network are built. The encoder is an improved graph attention network, which uses the multi-head attention mechanism to calculate the features of all agents and tasks. The decoder is an improved pointer network which outputs the orders of task execution in parallel by a two-way selected model. The proposed method can yield several sequences which correspond to the task execution orders of multiple agents. This encoder–decoder architecture is trained and tested using the reinforcement learning method with baseline, which can calculate the selection probability of each agent and each task, and output the final routes of multiple agents in parallel.
The main contributions are as follows.
A full-graph encoder is built to enhance the correlation between agents and tasks by calculating the features of the agents, tasks, and the current state.
A two-way selection network of agents and tasks is proposed to ensure the performance of task allocation.
A parallel pointer network is designed to output all the routes at the same time, which enables effective cooperation among multiple agents.
The experimental results show that the proposed task allocation algorithm outperforms traditional heuristic algorithms in terms of effectiveness and efficiency.
This paper is organized as follows.
Section 2 formulates the multi-agent task allocation problem with multiple depots.
Section 3 builds an end-to-end model with a full-graph encoder and a two-way selection decoder.
Section 4 shows the performance of our proposed model in the multi-agent task allocation problem with multiple depots.
Section 5 provides conclusions and future work.
2. Problem Description
For the concerned multi-agent task allocation problem with multiple depots, there are multiple agents and multiple tasks. Each agent is able to execute multiple tasks, and each task only needs one agent to execute once. All agents need to start from their respective depots and cooperate to complete all tasks. The goal of this problem is to obtain a set of task execution plans with the shortest total path.
For a problem setting s, there are m agents and n tasks . The depot coordinates of the agents and the task coordinates are represented by and , respectively. and are the position vectors in 2D or 3D space.
The execution plan of the problem setting
s can be represented as:
where
is the set of all
m agents’ task execution sequences and the
is the task execution sequence of the
j-th agent. For the sequence
,
represents the first task in the sequence and
represents the last task, and
is the task sequence length of the
j-th agent.
The multi-agent task allocation problem is formulated as:
subject to
Equation (
3) is the objective function to minimize the sum of the path lengths of all routes. Equation (
4) provides an expression for the path length of the route
. Finally, Equations (
5) and (
6) are the constraints that all tasks need to be completed, and each task must be completed by only one agent.
3. Methods
A graph attention pointer network is proposed for the multi-agent task allocation problem with multiple depots. Several improvements are made in both the encoder and decoder based on Kool’s encoder–decoder framework [
4], so that the model can effectively handle the multi-agent task allocation problem with multiple depots.
The proposed model consists of a full-graph encoder and a two-way selection decoder. First, the information of all depots and tasks are sent to the graph attention pointer network to seek the relationship of all points in the graph. Second, the two-way selection decoder chooses the bidirectional matching between the agent and the task, and outputs multiple sequences at the same time. Finally, the model is trained by the policy gradient deep reinforcement learning algorithm with baseline.
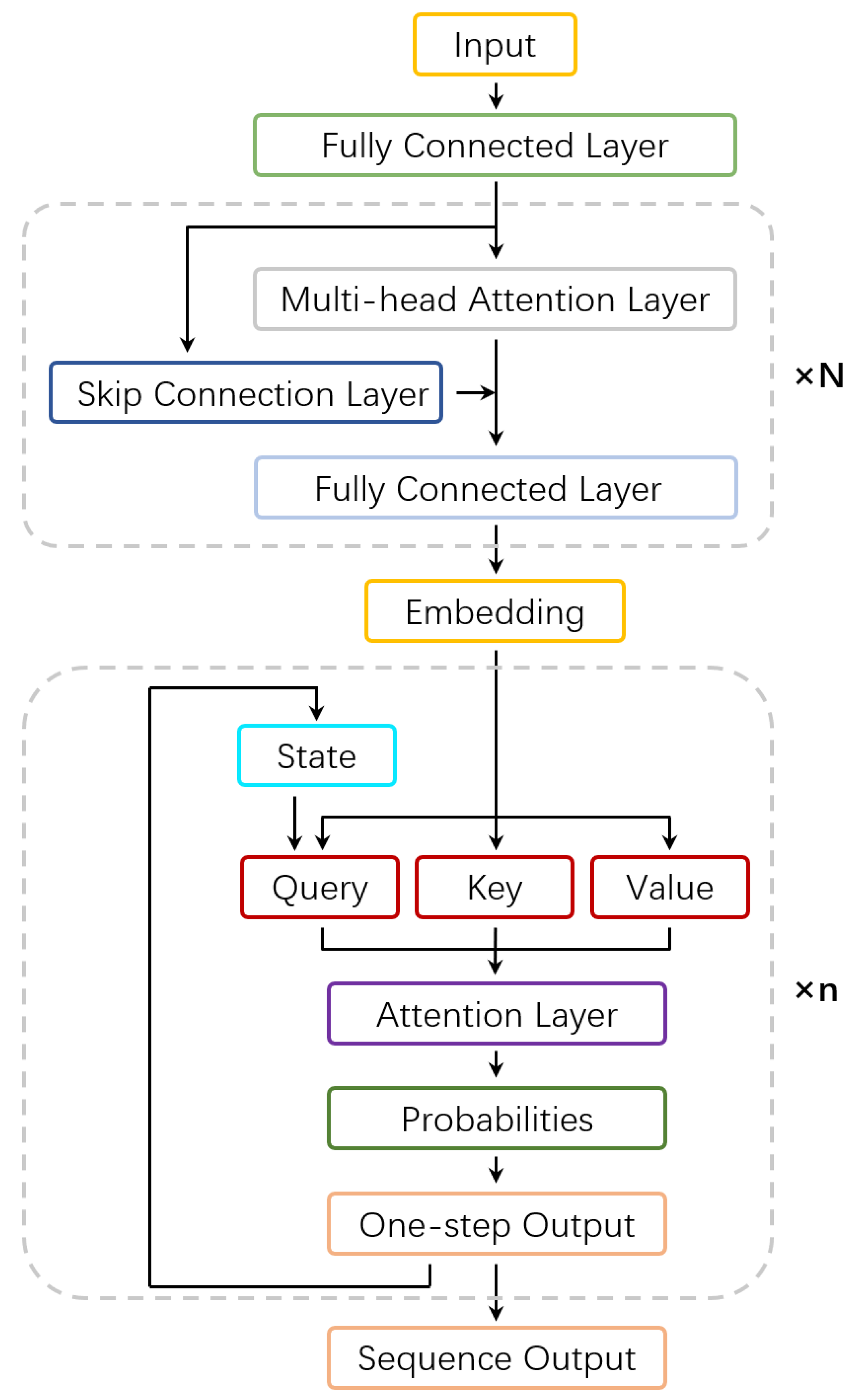
The deep learning model in this paper transforms the multi-agent task allocation problem into a node ordering problem in a graph structure. The encoder constructs the graph structure and the decoder obtains node sequencing. The details of the proposed model are shown in
Figure 1.
3.1. Full-Graph Encoder
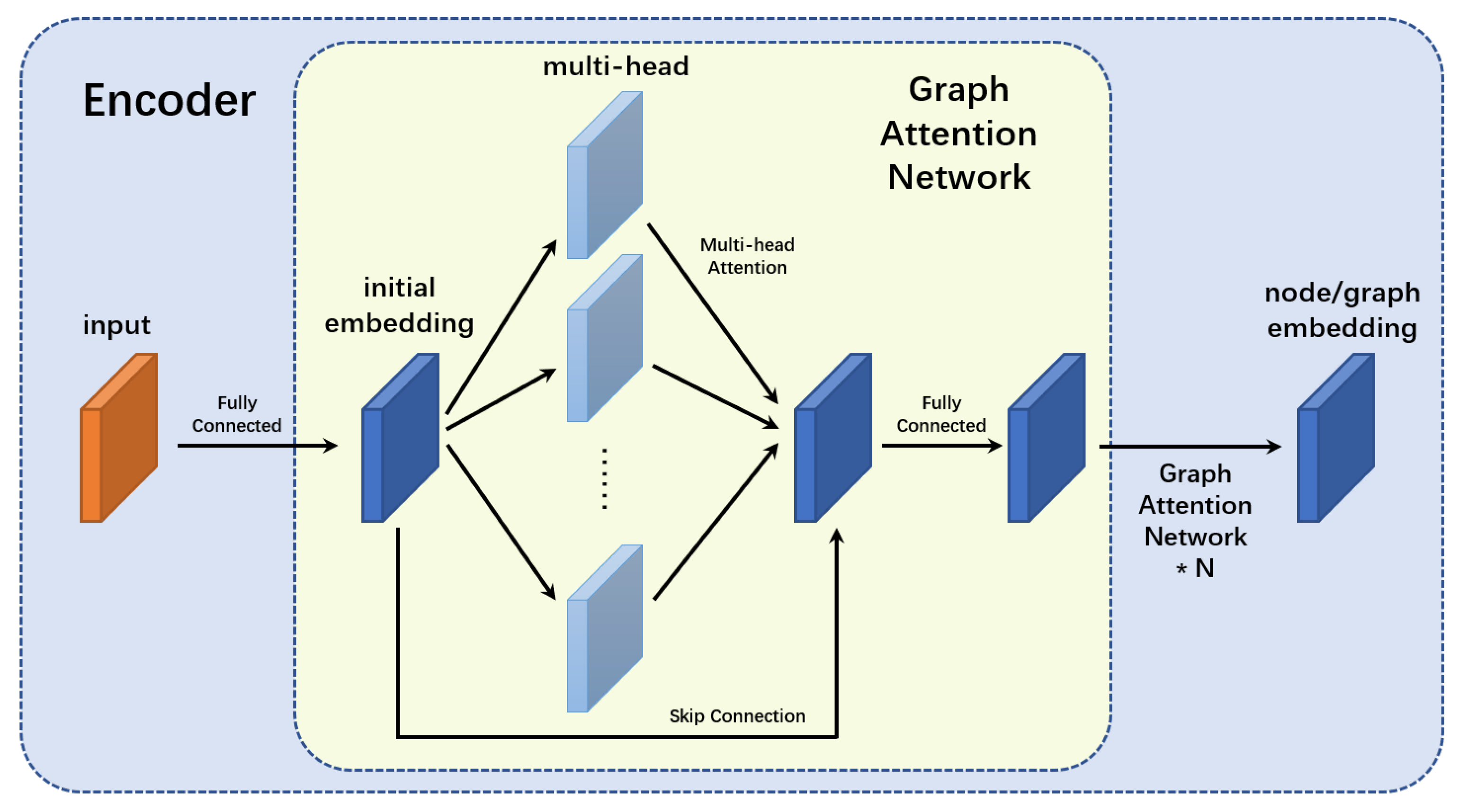
This part studies the structure of the full-graph encoder. The full-graph encoder constructs the graph structure to transform real-world problems into graph problems. It extracts features from individual nodes and outputs the node embeddings.
The full-graph encoder builds a graph and transforms the information of each point in real life (depots and tasks) into a feature vector that can be recognized by the machine. Then, the encoder calculates the correlation among nodes using the multi-head attention mechanism and outputs the node embeddings and graph embedding. The “full-graph” attribute of the encoder is reflected in the unified processing of all depots and all tasks. The structure of the encoder is shown in
Figure 2.
Firstly, the full-graph encoder constructs an undirected fully connected graph. The points in the real-world problem are mapped to the graph nodes one by one. In this multi-depot problem, there are m depots and n tasks , so a graph with nodes can be built. In this graph, each node will be connected to all other nodes and also to itself, and all connections are undirected.
Secondly, the full-graph encoder generates a dimension vector ( in this paper) for each node using the position information. The input comes from the real problem, including the coordinates of all depots and all tasks . Then, a fully connected neural network is used to transform the coordinate vectors into -dimensional feature vectors, completing initialization for the subsequent multi-head attention network. The initial node embedding is calculated after passing through the fully connected layer. In this paper, the uppercase letter E is used to indicate the embedding of all nodes in the graph, and the lowercase letter e is used to indicate the embedding of one node. includes all node embeddings , where .
Finally, the node embeddings and graph embedding are calculated by the multi-head attention mechanism. In the complex multi-depot problem, shallow embeddings cannot effectively represent the features of nodes (the network depth is not enough). Therefore, this paper adopts improved graph attention networks to carry out calculations for deeper embedding. Each graph attention network contains a multi-head attention layer [
18], a fully connected layer, and a skip connection layer [
25]. The graph attention network is shown in
Figure 1 and
Figure 2. The multi-head attention layer is the core structure of the graph attention network; it aims to obtain the features of each node and the correlation among multiple nodes. The fully connected layer ensures that the input and output have the same dimension of t, allowing the graph attention networks to stack with each other. The skip connection layer retains the useful features from the previous layers to prevent them becoming invisible in subsequent calculations. Increasing network depth is crucial in deep neural networks, so the skip connection layer is also crucial to avoid the problem of gradient vanishing and exploding. The number of the stacked graph attention networks
N should be selected moderately (
N = 3 in this paper).
The multi-head attention layer is the core of the graph attention network, and its structure is shown in
Figure 3. It can update from the current embedding
to the next layer
. Specifically, for the embedding
of the
l-th layer, the
r-th single-head attention layer can calculate the query
, key
and value
according to the parameters
,
, and
:
where
h represents the number of heads in the multi-head attention layer.
After obtaining the query
, key
, and value
of the
r-th head, the embedding
of the next layer can be calculated by:
In this formula, the query can give weights to other nodes by calculating the matching degree, which is equal to the cosine value of the angle between these two vectors and . Then, the softmax function is used to calculate the weight from the cosine value. The greater the cosine value, the greater the weight given. The adjustment factor is used to prevent the result of softmax being too close to 0 or 1. Finally, the values of all nodes are linearly combined to calculate the node embedding .
The multi-head attention layer repeats the above single-head attention layer several times, and outputs
by splicing all heads
:
Afterwards, the result of the graph attention network
can be calculated by
after passing through a fully connected layer and a skip connection layer:
It is worth noting that the dimension of each head’s embedding is the quotient of the embedding dimension and the number of heads h. The dimension of the vector must be an integer, so must be divisible by h. In addition, the parameters , , and of each head are different to extract different features.
3.2. Two-Way Selection Decoder
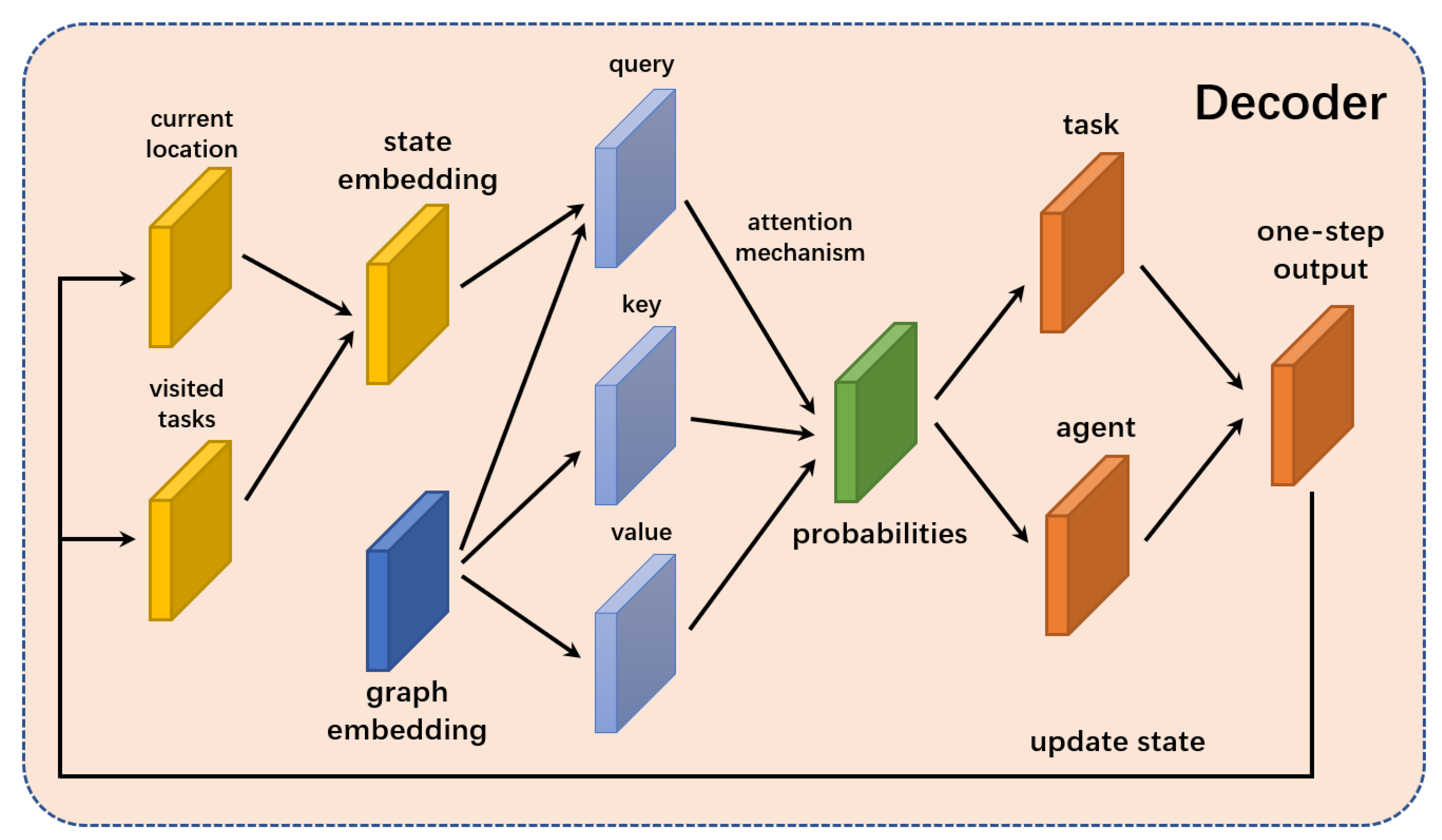
This part studies the structure of the two-way selection decoder. The two-way selection decoder reasonably allocates tasks to multiple agents and arranges the task execution orders of individual agents.
The pointer-network-based decoder is a sequence generator, but the classical pointer network can only output one pointer, which cannot achieve the goal of selecting an agent for a task in a multi-depot problem. Therefore, this paper proposes a two-way selection pointer network that can output two pointers at the same time, allocating tasks reasonably to agents while considering the task execution order.
The routes of all agents (sequences of all tasks) can be obtained when the two-way selection decoder runs multiple times. Each run of the two-way selection decoder obtains the best single step in the current state, and updates the state information every step. All tasks can be allocated after the decoder repeatedly runs. The process of the decoder outputting multiple routes is shown in
Figure 4.
The input of the decoder includes a static part and a dynamic part. The node embeddings obtained in the full-graph encoder are used as the static input of the decoder. The dynamic input includes all information about the current state, which is an important factor affecting the final results. The current location of the agents will obviously affect the node selection in the multi-depot problem, and the “visited state” of all nodes will influence the results as well. To be specific, the “visited state” means that only the tasks that have not been visited can become candidates, while the visited tasks cannot be selected again. So, the dynamic input consists of the current locations of agents and the tasks that have not been visited.
The outputs of the decoder are the routes of multiple agents, corresponding to several sequences of all tasks, and its set
can be represented as:
where
is the set of all task execution routes of
m agents, which is the same as the allocation plan in
Section 2.
The structure of the two-way selection decoder is shown in
Figure 5.
In fact, the output of the two-way selection pointer network is the probability distribution of selecting each node in the current state, where and represent the selected agent and task. The calculation of the probability distribution is an important process of the network, and its core principle is similar to the weight calculation process of the attention mechanism. When calculating the probability, the query, key, and value vectors are crucial. The key and value are produced from the static node embeddings, while the query is dynamic, which directly affects the quality of the results. A critical part of the network is whether the query can fully obtain the state information.
The core concept of the two-way selection pointer network is to design two queries, one for an agent and the other for a task. The query
for the agent is calculated by the current location, completing the selection of a task that is suitable for the agent. On the contrary, the query
for the task comes from its node embedding and the “visited state”, completing the selection of an agent that is suitable for the task. Then, the comprehensive probability is calculated based on the results of the two selections, which better reflects the matching situation between the agent and the task. The detailed calculation process of
and
are as follows:
where
represents the embedding of the task of the
j-th agent located at moment
t.
represents the average embedding of all tasks that have not been visited.
means a fully connected layer whose output dimension is the embedding dimension
.
After obtaining
and
, the relationship
between agent
j and task
i can be calculated by the two-way selection rules:
Subsequently, in order to satisfy the constraint of non-repeated task visitation, it is necessary to add a mask function. The purpose of the mask function is to ensure that the probability of all visited tasks is equal to 0. The mask function searches the relationships
of all visited tasks and changes them to negative infinity, so that the probabilities can be equal to 0 after the softmax function. The calculation process of the mask function is as follows:
Then, the probability
of selecting agent
j and task
i can be calculated by the softmax function:
After calculating the probability distribution, the decoder will select one agent and one task according to the probability distribution to obtain a single-step output. The algorithm for selecting the single-step output varies in different circumstances, and it comes from the following three algorithms: greedy search, beam search, and sampling selection.
When training, the sampling selection algorithm should be chosen. It will randomly select a node according to the probability distribution . This algorithm can hardly obtain a good solution, but is more suitable for gradient calculation.
When testing, the greedy search or beam search algorithm should be chosen. The greedy search algorithm selects the highest probability every time. The greedy search algorithm has a very high computational efficiency, but ultimately the performance of the feasible solution is not always the best. The beam search algorithm selects several high probabilities as candidates every time, and finally selects the best plan from all candidates, resulting in better performance but lower computational efficiency.
3.3. Reinforcement with Baseline
The policy gradient deep reinforcement learning algorithm with baseline [
21] is used to train the model due to the difficulty of collecting labels. In the policy gradient algorithm, the probability of the action is determined by the state, where the action is the behavior of the node selection. A loss function is needed for the policy gradient algorithm, so that it can use a gradient descent method to minimize the loss and to determine a model. Based on the model parameters,
,
is the probability distribution of all feasible solutions under the problem instance
s, then the loss function can be defined as:
where
indicates the loss function, and
indicates the cost (the length of all routes). Then, the gradient of the loss function is:
In the calculation of the gradient, the addition of baseline
b, which is independent of
, does not affect the result, because
satisfies:
Therefore, the gradient of the loss for the problem instance
s can be expressed as:
So
can be used instead of
in the policy gradient as long as
b is not related to action
. The addition of
b will not affect the correctness of the policy gradient itself. More importantly, the policy gradient algorithm in deep reinforcement learning is performed from Monte Carlo approximation, which is a kind of sampling method. When the baseline
b is close to
, the variance can be reduced so that the convergence of the neural network can speed up [
26].
The baseline in the model is as follows:
where
is the cost of the baseline policy, and
is an inertia parameter.
4. Experiments and Results
The experiments in this paper are conducted through random positions of task points and agent depots.
This section is organized as follows.
Section 4.1 gives the parameter settings and the training resources in this paper.
Section 4.2 describes the comparative experiment and the numerical results.
Section 4.3 shows some figures of the experiment.
Section 4.4 provides the analysis of the model based on the experimental results.
4.1. Parameter Settings and Training Details
In most deep learning models, the construction of training and validation sets is crucial. The model can only use training data for training and cannot use samples in the validation set. In this paper, a set of validation samples is generated before training, with the number of agents and task points in the validation set unchanged. The positions of agent depots and task points in each sample are randomly generated in a
map. The generation of the training set is the same as the validation set, using a fixed quantity and random location. However, due to the large number of samples in the training set, it is necessary to randomly divide it into multiple batches for training before each epoch training. Then, the model is validated one time after completing each epoch. Specifically, the policy gradient algorithm calculates the baseline required for validation, then the loss between the model and the baseline on the validation set is calculated and finally uses the Adam optimization algorithm to update the weights of the neural network. The final result of each training is selected from the model that performs best in the validation set. Some model parameters and training resources are shown in
Table 1 for reference.
In the above table, the embedding dimension is for the graph encoder, and the hidden layer dimension is for both the encoder and decoder. The attention layer number refers to the number of multi-head attention layers in the encoder. The inertia parameter
is defined in Equation (
21). The batch size is set to 256, and a total of 100 epochs are trained with each epoch containing 12,800 batches. The validation size means the number of instances in the validation set. The learning rate is set to 0.0002.
In addition, the proposed graph attention pointer network was trained on 2 GPUs “NVIDIA Tesla V100 sxm30 32 GB” for about 6 h.
4.2. Comparative Experiment
The Gurobi and LKH3 methods, which are two commonly used solvers, are selected as comparative experiments. The Gurobi method is one of the most widely used mathematical programming optimizers; it is often used to solve integer programming problems. However, due to limited equipment resources, Gurobi cannot be used to handle larger-scale problems. The LKH3 is an algorithm that optimizes the solution by constantly exchanging edges; it is an excellent solver for TSP and VRP at present. For the LKH3 algorithm, the higher the number of exchanged edges, the better the quality of the solution. In this paper, the solution of the LKH3 algorithm is defined as a solution calculated within an acceptable time. Meanwhile, for the comparison purpose, the particle swarm optimization (PSO) and the genetic algorithm (GA) are also designed to solve this problem. PSO is a well-known heuristic algorithm which is able to deal with large-scale problems. GA can hardly deal with large-scale problems due to the huge memory resources required during genetic computing, so GA is not available when there are more than 10 agents. As for deep learning methods, there are few similar deep learning methods for reference due to the fact that the method in this paper is an extension of the attention model [
4]. The simulation results of the five methods are shown in
Table 2.
Overall, the most obvious advantage of the method proposed in this paper lies in the computational speed, which can be faster by over 100 times compared to all optimization methods and heuristic algorithms mentioned in this paper (such fast computing speed is based on a long training period). In terms of performance, the method proposed in this paper is not as good as the optimization methods but performs better than heuristic algorithms in large-scale problems.
Specifically, the performance of the deep learning method proposed in this paper varies among problems with different scales. At the amount of five agents with 20 task points, the performance of our method lags behind all other methods. Moreover, in this scale of problems, the optimization methods and heuristic algorithms also have fast computational speed, so the advantage of a fast speed does not seem to be important. At the amount of five agents with 50 task points, the performance of our method lags behind LKH3 but leads PSO and GA. At the amount of 10 agents with 50 task points and 100 task points, the performance of our method lags behind LKH3 but significantly leads PSO and GA, and in such large-scale problems, the advantage of the fast speed in our method is even more important (not all problems can accept taking 13 h to find a solution).
4.3. Figures
The performance and characteristics of this method can be further explored from different simulation figures.
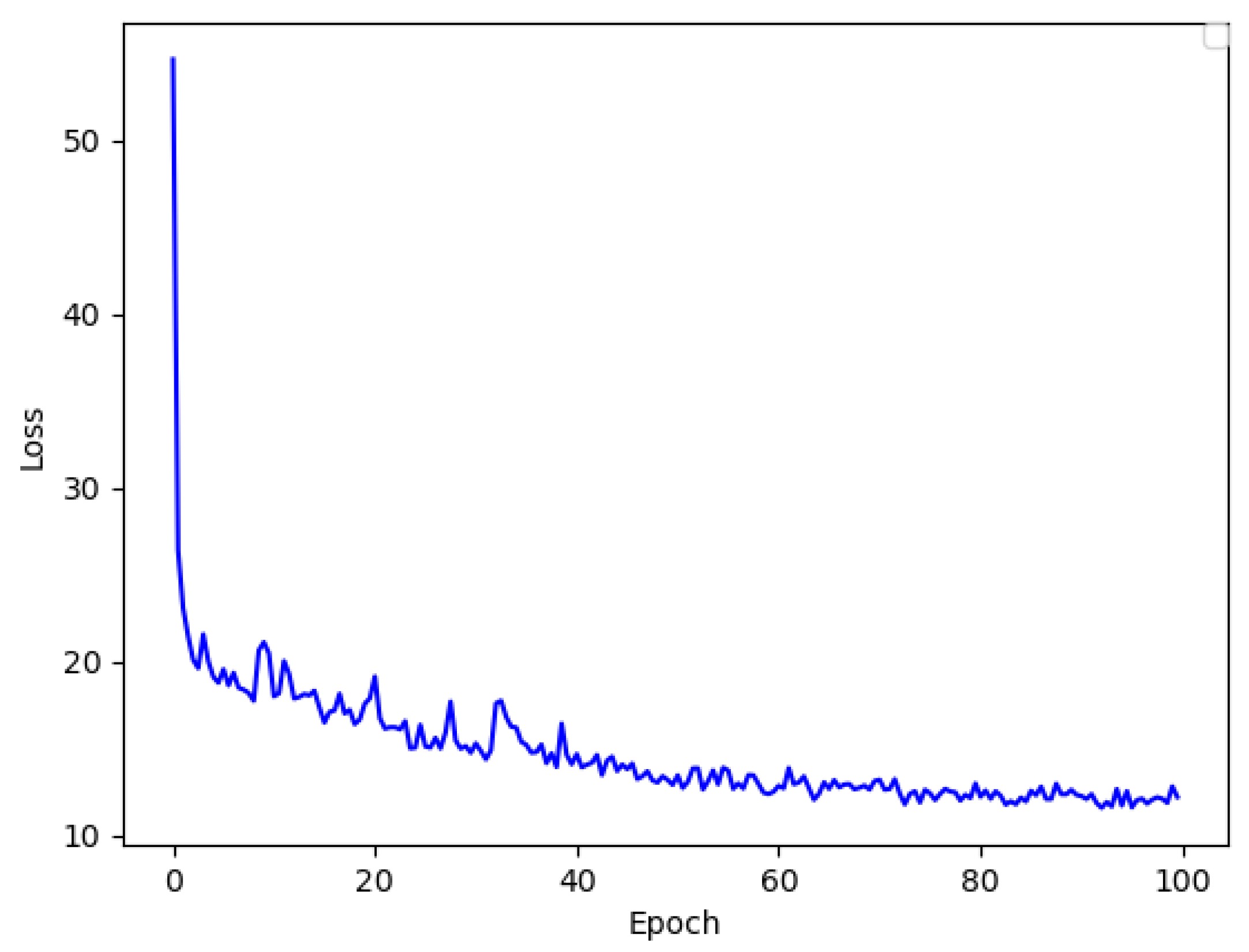
The convergence curve of the loss function is shown in
Figure 6. In the training process of 100 epochs, the loss function exhibits a decaying trend along with the number of epochs and is very close to the minimum value after the 80th epoch.
The visualization graphs can demonstrate the quality of the task allocation results, and can also be used to analyze the advantages and drawbacks of the allocation results. The visualization graphs of the multi-depot problem with 100 tasks and 10 agents are shown in
Figure 7.
In
Figure 7, it can be found that the points distributed at the edge of the map are selected much more preferentially than the dense points in the center. As a result, the sequence is always generated from the edge to the center.
Additionally, the two models of
Figure 7a,b yield completely different strategies for the task allocation. The model of (a) tends to select neighbor points with a closer distance, while the model of (b) gives priority to placing tasks of one path in the same area. The reason for this phenomenon might be that the two models learned different features during the training process. One model learns more about the distribution of nodes, and the other learns more about the spatial distance between nodes.
4.4. Analysis
According to the simulation results in
Section 4.2, the deep learning method proposed in this paper has many advantages. Firstly, the deep learning method performs well in large-scale problems and can be applied to some complex problems. Secondly, the deep learning method has great computational efficiency that can handle some dynamic problems which require high computing speed. Finally, the deep learning method can collect lots of labels in a short time, which is helpful for many practical applications and supervised learning models.
On the contrary, there are several drawbacks of the proposed deep learning method. Firstly, a new model needs to be built when the problem description changes. Secondly, the deep learning method needs a long training period, even if the problem is very simple. Thirdly, the deep learning method cannot yield an optimal solution, so it is not as reliable as classic solvers for some problems with high performance requirements. Finally, the deep learning method yields a black-box model which may not be interpretable, so the strategy may not be reasonable.
In the research of task allocation, various methods have their advantages and limitations. All methods can find suitable application scenarios based on their own characteristics and will not be completely replaced by other methods. Deep learning methods change the solving mode of task allocation problems from the all-points output to point-by-point output. This characteristic of deep learning methods makes the computational complexity only dependent on the network itself and almost unchanged with a change in the problem size. Therefore, deep learning methods can maintain highly efficient computation and good performance even when the problem size is large. Compared to heuristic algorithms, deep learning methods lack flexibility. When the problem becomes complex or the objective changes, deep learning methods not only need to redesign all the networks but also spend a lot of time adjusting parameters to complete training, while heuristic algorithms only need to change the objective function and constraint conditions. Compared to optimization methods, the performance of deep learning methods is not stable enough. When the tolerance for poor performance is low, deep learning methods are often inadequate. Deep learning methods may not perform well in certain examples, but optimization methods can always obtain excellent solutions.
In summary, deep learning methods are better when the problem is large in scale or the problem requires high computational speed; heuristic algorithms are better when the problem is complex enough or there are changes in objectives; optimization methods are better when there is a high demand for optimality.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}