
Novel Application of Open-Source Cyber Intelligence


Abstract
:1. Introduction
- Previous studies in [32,33,34] showed dependencies on the manual aggregation of multiple reports along with personal judgements, and the analysis of cyber professionals that potentially introduces the authors’ biasness towards certain countries. In contrast, this paper introduces a methodology that automatically obtains cyber-related information from multiple sources and provides instantaneous AI-driven insights without personal prejudice or preconception.
- Compared to all existing social-media-based cyber intelligence solutions [16,17,19,20,21,22,23,24], the presented method utilized the most comprehensive set of natural language processing (NLP) algorithms like sentiment analysis, translation, TF-IDF, LDA, N-gram, Porter stemming, etc. Unlike the existing research on social-media-based cyber intelligence [19,20,21,22,23,24], the presented study provides the most comprehensive cyber intelligence by analyzing social media post in 54 languages, performing 8199 dynamic translations.
- The innovative AI-based method presented in this paper was used for the first time to automatically generate multi-dimensional cyber intelligence for both Australia and China. It was identified that China suffers from higher levels of cyber threat being attacked with spam (i.e., China was identified as the second most attacked country based on spam). On the other hand, Australia’s cyber threat level is moderate with exploit being the most common type of attack (i.e., Australia was identified as the 11th most attacked country in terms of exploit).
- Australians are concerned with data breaches (e.g., Optus, Medibank), cybersecurity threats and assaults, and issues like malware, phishing, and ransomware. Both the general public (i.e., Australians through data breaches) and organizations (e.g., Optus, Medibank) are victims of cyber-attacks in Australia. On the other hand, Chinese social media posts tend to be more geopolitical in nature, discussing cyberespionage and intrusions by foreign countries, particularly the United States. The target of cyber-attacks in China are Chinese tech firms, Chinese-owned apps (e.g., TikTok), as well as supply chains.
2. Background and Literature
2.1. Multi-Dimensional Analysis of Cyber Threats
2.2. Cyber Intelligence Analysis from Social Media with NLP
3. Material and Methods
3.1. Language Detection and Translation
| Algorithm 1: Application of NLP to Processing of Social Media Messages with Cyber Concerns | |
| 1: | For each xi in N, Multilingual Social Media Messages |
| 2: | If Language(xi)<> ‘English’ |
| 3: | yi = Translate(xi) |
| 4: | Else |
| 5: | yi = xi |
| 6: | For each yi in N, English Social Media Messages |
| 7: | si = Sentiment(yi) |
| 8: | If yi Contains ‘Country Name’ |
| 9: | } = yi |
| 10: | For each cr in C, Countries |
| 11: | ) |
| 12: | }, …} = TermFrequency(Tokenize(yi)) |
| 13: | }, …} = Stemming(Tokenize(yi)) |
| 14: | }, …} = n_gram(Tokenize(yi)) |
| 15: | , {{}…}}, …} = Topic(Tokenize(yi)) |
| 16: | Generate Interactive Visualization |
3.2. Sentiment Analysis
3.3. Anomaly Detection
- The application of Fourier transforms to generate the log amplitude spectrum.
- The computation of the SR operation.
- The utilization of inverse Fourier transform to revert the sequence back to the spatial domain.
3.4. Term Frequency
3.5. Topic Modelling
3.6. Exponential Smoothing
4. Results
5. Discussion
5.1. Analysis of the Differences in Cyber-Related Concerns
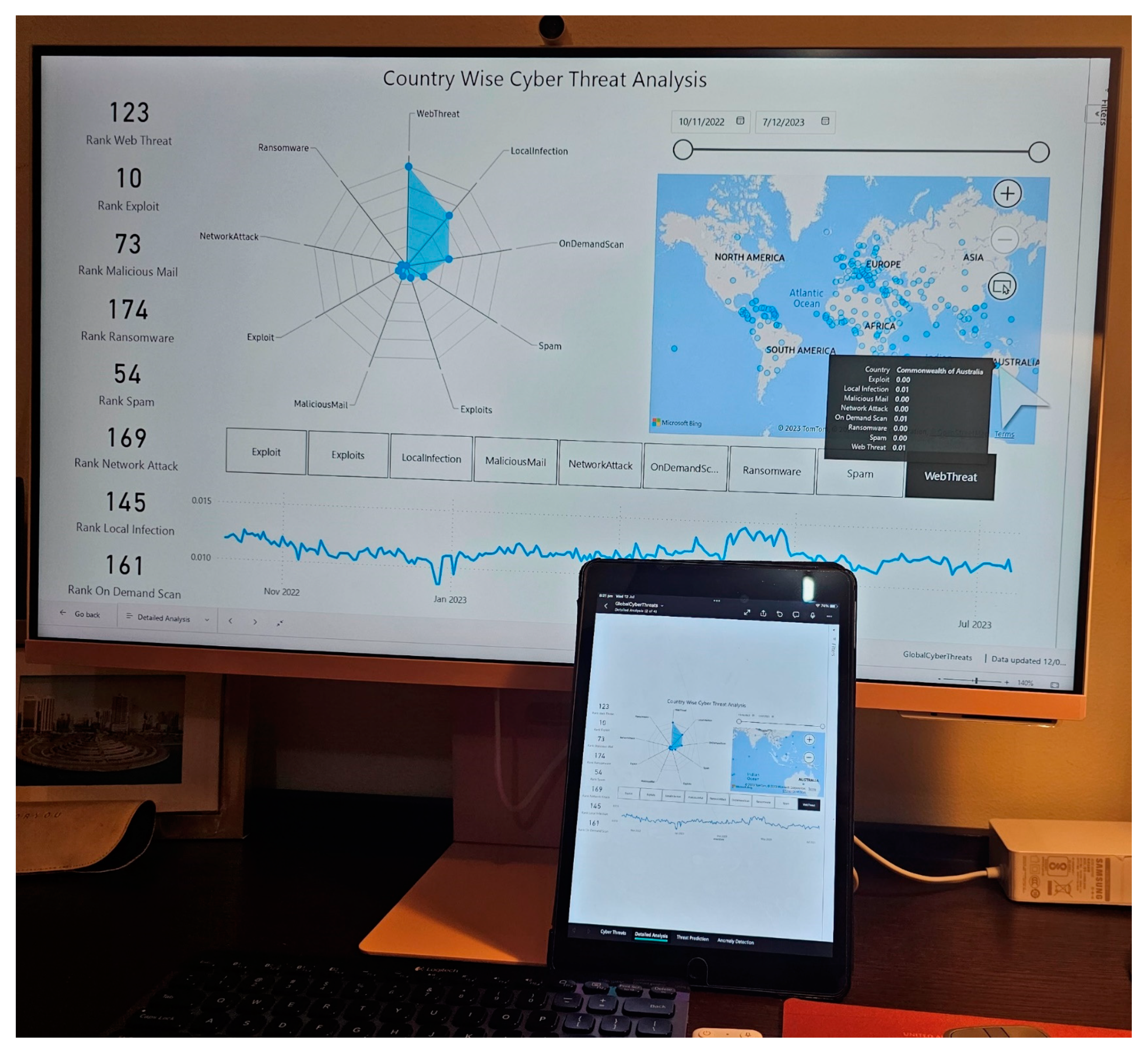
5.2. Implementation of Multi-Dimensional Cyber-Intelligence in Mobile Phones
6. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cremer, F.; Sheehan, B.; Fortmann, M.; Kia, A.N.; Mullins, M.; Murphy, F.; Materne, S. Cyber risk and cybersecurity: A systematic review of data availability. Geneva Pap. Risk Insur. Issues Pract. 2022, 47, 698–736. [Google Scholar] [CrossRef]
- Cybercrime Magazine. Cybercrime to Cost the World $10.5 Trillion Annually by 2025. 13 November 2020. Available online: https://cybersecurityventures.com/hackerpocalypse-cybercrime-report-2016/ (accessed on 15 October 2022).
- Statista Research Department. Consumer Loss through Cyber Crime Worldwide in 2017, by Victim Country. 7 July 2022. Available online: https://www.statista.com/statistics/799875/countries-with-the-largest-losses-through-cybercrime/ (accessed on 26 October 2022).
- Bada, M.; Nurse, J.R. Chapter 4—The Social and Psychological Impact of Cyberattacks. In Emerging Cyber Threats and Cognitive Vulnerabilities; Benson, V., Mcalaney, J., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 73–92. [Google Scholar]
- BBC. News: Optus: How a Massive Data Breach Has Exposed Australia. 29 September 2022. Available online: https://www.bbc.com/news/world-australia-63056838 (accessed on 16 October 2022).
- Australian Securities & Investments Commissions. Guidance for Consumers Impacted by the Optus Data Breach. October 2022. Available online: https://asic.gov.au/about-asic/news-centre/news-items/guidance-for-consumers-impacted-by-the-optus-data-breach/ (accessed on 19 October 2022).
- Merritt, K.; OPTUS Confirms 2.1 Million Customers Affected by Cyberattack. Total Telecom, 3 October 2022. Available online: https://totaltele.com/optus-confirms-2-1-million-customers-affected-by-cyberattack/ (accessed on 23 October 2022).
- Kaye, B. Australia’s No. 1 Health Insurer Says Hacker Stole Patient Details, Reuters. 20 October 2022. Available online: https://www.reuters.com/technology/after-telco-hack-australia-faces-wave-data-breaches-2022-10-20/ (accessed on 25 October 2022).
- Zibak, A.; Simpson, A. Cyber Threat Information Sharing: Perceived Benefits and Barriers. In Proceedings of the ARES’19: Proceedings of the 14th International Conference on Availability, Reliability and Security, Canterbury, UK, 26–29 August 2019. [Google Scholar]
- Xu, S.; Qian, Y.; Hu, R.Q. Data-Driven Network Intelligence for Anomaly Detection. IEEE Netw. 2019, 33, 88–95. [Google Scholar] [CrossRef]
- Keshk, M.; Sitnikova, E.; Moustafa, N.; Hu, J.; Khalil, I. An Integrated Framework for Privacy-Preserving Based Anomaly Detection for Cyber-Physical Systems. IEEE Trans. Sustain. Comput. 2021, 6, 66–79. [Google Scholar] [CrossRef]
- Ten, C.-W.; Hong, J.; Liu, C.-C. Anomaly Detection for Cybersecurity of the Substations. IEEE Trans. Smart Grid 2011, 2, 865–873. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, C.; Yang, S.; Xu, H. Anomaly Detection Based on Zone Partition for Security Protection of Industrial Cyber-Physical Systems. IEEE Trans. Ind. Electron. 2018, 65, 4257–4267. [Google Scholar] [CrossRef]
- Shi, D.; Guo, Z.; Johansson, K.H.; Shi, L. Causality Countermeasures for Anomaly Detection in Cyber-Physical Systems. IEEE Trans. Autom. Control 2017, 63, 386–401. [Google Scholar] [CrossRef]
- Khan, N.F.; Ikram, N.; Saleem, S.; Zafar, S. Cyber-security and risky behaviors in a developing country context: A Pakistani perspective. Secur. J. 2022, 36, 1–33. Available online: https://link.springer.com/content/pdf/10.1057/s41284-022-00343-4.pdf (accessed on 22 January 2023). [CrossRef]
- Sufi, F. Algorithms in Low-Code-No-Code for Research Applications: A Practical Review. Algorithms 2023, 16, 108. [Google Scholar] [CrossRef]
- Sufi, F. A New Social Media-Driven Cyber Threat Intelligence. Electronics 2023, 12, 1242. [Google Scholar] [CrossRef]
- Sufi, F. A New AI-Based Semantic Cyber Intelligence Agent. Future Internet 2023, 15, 231. [Google Scholar] [CrossRef]
- Pattnaik, N.; Li, S.; Nurse, J.R. Perspectives of non-expert users on cyber security and privacy: An analysis of online discussions on twitter. Comput. Secur. 2023, 125, 103008. [Google Scholar] [CrossRef]
- Geetha, R.; Karthika, S. Sensitive Keyword Extraction Based on Cyber Keywords and LDA in Twitter to Avoid Regrets. In Computational Intelligence in Data Science. ICCIDS 2020. IFIP Advances in Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2020; Volume 578. [Google Scholar]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Perez-Meana, H.; Olivares-Mercado, J.; Sanchez, V. Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization. Sensors 2018, 18, 1380. [Google Scholar] [CrossRef] [PubMed]
- Shah, R.; Aparajit, S.; Chopdekar, R.; Patil, R. Machine Learning based Approach for Detection of Cyberbullying Tweets. Int. J. Comput. Appl. 2020, 175, 51–56. [Google Scholar] [CrossRef]
- Rawat, R.; Mahor, V.; Chirgaiya, S.; Nath Shaw, R.; Ghosh, A. Analysis of Darknet Traffic for Criminal Activities Detection Using TF-IDF and Light Gradient Boosted Machine Learning Algorithm. In Lecture Notes in Electrical Engineering Book Series; Springer: Berlin/Heidelberg, Germany, 2021; Volume 756. [Google Scholar]
- Lanier, H.D.; Diaz, M.I.; Saleh, S.N.; Lehmann, C.U.; Medford, R.J. Analyzing COVID-19 disinformation on Twitter using the hashtags #scamdemic and #plandemic: Retrospective study. PLoS ONE 2022, 17, e0268409. [Google Scholar]
- Correia, V.J. An Explorative Study into the Importance of Defining and Classifying Cyber Terrorism in the United Kingdom. SN Comput. Sci. 2021, 3, 84. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Q. A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments. Energy Rep. 2021, 7, 8176–8186. [Google Scholar] [CrossRef]
- Agrafiotis, I.; Nurse, J.R.C.; Goldsmith, M.; Creese, S.; Upton, D. A taxonomy of cyber-harms: Defining the impacts of cyber-attacks and understanding how they propagate. J. Cybersecur. 2018, 4, tyy006. [Google Scholar] [CrossRef]
- Alkhalil, Z.; Hewage, C.; Nawaf, L.; Khan, I. Phishing Attacks: A Recent Comprehensive Study and a New Anatomy. Front. Comput. Sci. 2021, 3, 563060. [Google Scholar] [CrossRef]
- Hagen, R.A. Unraveling the Complexity of Cyber Security Threats: A Multidimensional Approach. 15 April 2023. Available online: https://www.linkedin.com/pulse/unraveling-complexity-cyber-security-threats-approach-hagen/ (accessed on 25 April 2023).
- Humayun, M.; Niazi, M.; Jhanjhi, N.; Alshayeb, M.; Mahmood, S. Cyber Security Threats and Vulnerabilities: A Systematic Mapping Study. Arab. J. Sci. Eng. 2020, 45, 3171–3189. [Google Scholar] [CrossRef]
- Bhaskar, R. Better Cybersecurity Awareness through Research. 2022. Available online: https://www.isaca.org/resources/isaca-journal/issues/2022/volume-3/better-cybersecurity-awareness-through-research (accessed on 1 April 2023).
- Xu, M.; Lu, C. China–U.S. cyber-crisis management. China Int. Strategy Rev. 2021, 3, 97–114. [Google Scholar] [CrossRef]
- Lai, R.; Rahman, S. Analytics of China Cyberattack. Int. J. Multimed. Its Appl. (IJMA) 2012, 4, 37–56. [Google Scholar] [CrossRef]
- Yuen, S. Becoming a Cyber Power: China’s cybersecurity upgrade and its consequences. China Perspect. 2015, 2, 53–58. [Google Scholar] [CrossRef]
- Deng, L.; Xie, P.; Chen, Y.; Rui, S.; Yang, C.; Deng, B.; Wang, M.; Armstrong, D.; Ma, Y.; Deng, W. Impact of acute hyperglycemic crisis episode on survival in individuals with diabetic foot ulcer using a machine learning approach. Front. Endocrinol. 2022, 13, 974063. [Google Scholar] [CrossRef]
- Huayue, C.; Tingting, W.; Tao, C.; Wu, D. Hyperspectral Image Classification Based on Fusing S3-PCA, 2D-SSA and Random Patch Network. Remote Sens. 2023, 15, 3402. [Google Scholar]
- Li, M.; Zhang, J.; Song, J.; Li, Z.; Lu, S. A Clinical-Oriented Non-Severe Depression Diagnosis Method Based on Cognitive Behavior of Emotional Conflict. IEEE Trans. Comput. Soc. Syst. 2023, 10, 131–141. [Google Scholar] [CrossRef]
- Kurni, M.; Mrunalini, M.; Saritha, K. Deep Learning Techniques for Social Media Analytic. In Principles of Social Networking. Smart Innovation, Systems and Technologies; Biswas, A., Patgiri, R., Biswas, B., Eds.; Springer: Singapore, 2022. [Google Scholar]
- Alsayat, A. Improving Sentiment Analysis for Social Media Applications Using an Ensemble Deep Learning Language Model. Arab. J. Sci. Eng. 2022, 47, 2499–2511. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.-C. NLP-Based Digital Forensic Analysis for Online Social Network Based on System Security. Int. J. Environ. Res. Public Health 2022, 19, 7027. [Google Scholar] [CrossRef]
- Christian, H.; Suhartono, D.; Chowanda, A.; Zamli, K.Z. Text based personality prediction from multiple social media data sources using pre-trained language model and model averaging. J. Big Data 2021, 8, 68. [Google Scholar] [CrossRef]
- Alim, S. Analysis of Tweets Related to Cyberbullying: Exploring Information Diffusion and Advice Available for Cyberbullying Victims. Int. J. Cyber Behav. Psychol. Learn. 2015, 5, 31–52. [Google Scholar] [CrossRef]
- Kaspersky. Securelist. 2023. Available online: https://statistics.securelist.com/ (accessed on 9 August 2023).
- Microsoft Documentation. Choosing a Natural Language Processing Technology in Azure. 25 February 2020. Available online: https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/natural-language-processing (accessed on 22 January 2023).
- Sufi, F.; Khalil, I. Automated Disaster Monitoring from Social Media Posts using AI based Location Intelligence and Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2022, 1–11. [Google Scholar] [CrossRef]
- Sufi, F.K.; Alsulami, M. Automated Multidimensional Analysis of Global Events With Entity Detection, Sentiment Analysis and Anomaly Detection. IEEE Access 2021, 9, 152449–152460. [Google Scholar] [CrossRef]
- Sufi, F.K. Automatic identification and explanation of root causes on COVID-19 index anomalies. MethodsX 2023, 10, 101960. [Google Scholar] [CrossRef] [PubMed]
- Ren, H.; Xu, B.; Wang, Y.; Yi, C.; Huang, C.; Kou, X.; Xing, T.; Yang, M.; Tong, J.; Zhang, Q. Time-Series Anomaly Detection Service at Microsoft. In Proceedings of the KDD’19: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 4–8 August 2019. [Google Scholar]
- Zhao, R.; Ouyang, W.; Li, H.; Wang, X. Saliency detection by multi-context deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Abas, M.N.; Jalil, S.Z.; Aris, S.A.M. Malware Attack Forecasting by Using Exponential Smoothing. In Lecture Notes in Electrical Engineering Book Series; Springer: Berlin/Heidelberg, Germany, 2022; Volume 842. [Google Scholar]
- Checkpoint. Live Cyber Threat Map. 2023. Available online: https://threatmap.checkpoint.com/ (accessed on 9 August 2023).
- Fortinet. Fortinet Fortiguard Threatmap. 2023. Available online: https://threatmap.fortiguard.com/ (accessed on 9 August 2023).
- Netscout. DDoS & Cyber-Attack Map. 2023. Available online: https://www.netscout.com/ddos-attack-map (accessed on 9 August 2023).
- Radware. Live Threat Map. 2023. Available online: https://livethreatmap.radware.com/ (accessed on 9 August 2023).
- Bitdefender. Cyberthreat Real-Time Map. 2023. Available online: https://threatmap.bitdefender.com/ (accessed on 9 August 2023).
- Microsoft Documentation, Anomaly Detection. 17 January 2023. Available online: https://learn.microsoft.com/en-us/power-bi/visuals/power-bi-visualization-anomaly-detection (accessed on 9 August 2023).
- Microsoft Power BI Report by F. Sufi. Global Cyber Threat with Attach Statistics and Social Media Analysis. 9 August 2023. Available online: https://app.powerbi.com/view?r=eyJrIjoiYWJjOGY5YTUtZDBlNy00MTg1LWFkMTMtM2RmYzYzODQ1NzE1IiwidCI6IjBkMWI4YmRlLWZmYzEtNGY1Yy05NjAwLTJhNzUzZGFjYmEwNSJ9&pageName=ReportSection (accessed on 9 August 2023).
- Microsoft Power BI Report by F. Sufi, Worldwide Cyber Threats. 9 August 2023. Available online: https://app.powerbi.com/view?r=eyJrIjoiMzRmNjU2YjItNDk2Zi00YWU3LThjYzctYmIyOGYwYzQ1OWExIiwidCI6IjBkMWI4YmRlLWZmYzEtNGY1Yy05NjAwLTJhNzUzZGFjYmEwNSJ9 (accessed on 9 August 2023).
- Gurajala, S.; White, J.S.; Hudson, B.; Voter, B.R.; Matthews, J.N. Profile characteristics of fake Twitter accounts. Big Data Soc. 2016, 3, 2053951716674236. [Google Scholar] [CrossRef]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-Level Concern | Dimension of Cyber Intelligence | Reference |
|---|---|---|
| 1. Threat Type | Threat Spectrum (e.g., malware, spyware) | [26,28,29,30] |
| 2. Attacker 3. Attack Origin 4. Reason for the Attack 5. Motivation for Conducting the Attack | Socioeconomic/Geopolitical | [29] |
| 6. Attack Target 7. Victim of the Attack | Victimization (System/Human) | [25,26] |
| 8. Critical Cyber-Related Concern | National Priority and Concerns | [27,31] |
| 9. Impact of Attack | Impacted Target (Supply Chain, Infrastructure, Others, etc.) | [26] |
| 10. Societal Perception 11. Societal Effect 12. Negative Perception of the Attack | Societal/Psychological | [27] |
| 13. Seriousness/Criticality 14. Intensity | Threat Level (Hi, Mid, Lo) | [26] |
| Algorithms Name | Abbreviated Name | Reference |
|---|---|---|
| Naïve Bayes Classifier | NV | [21,22] |
| Support Vector Machines | SVM | [19,21,22] |
| Maximum Entropy Classifier | ME | [21] |
| BERT-based | BERT | [19] |
| Logistic Regression | LR | [19,22] |
| Random Forest | LR | [19,22] |
| Extreme Gradient Boosting | XGBoost | [19] |
| Stochastic Gradient Descent Classifier | SGD | [22] |
| Light Gradient-Boosted Machine | LightGBM | [23] |
| Convolutional Neural Network | CNN | Proposed |
| Reference | Sentiment Analysis | Translation | LDA | TF-IDF | Stemming | N-Gram | Forecasting |
|---|---|---|---|---|---|---|---|
| [21] | Yes | No | No | Yes | Yes | Yes | Yes (Regression) |
| [16] | Yes | Yes | No | No | No | No | No |
| [19] | Yes | No | Yes | Yes | No | Yes | No |
| [20] | No | No | Yes | Yes | No | Yes (bigram) | No |
| [22] | No | No | No | Yes | No | No | No |
| [23] | No | No | No | Yes | No | No | No |
| [24] | Yes | No | Yes | No | No | No | No |
| Proposed | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| Process Name | Algorithm Used | Data Used | Algorithm Type | API Used | References |
|---|---|---|---|---|---|
| Sentiment Analysis | Microsoft Text Analytics | Twitter [17,18] | Language Processing | Yes | [19,21,45,46] |
| English Translate | Microsoft Text Analytics | Twitter [17,18] | Language Processing | Yes | [45,46] |
| Anomaly Detection | CNN | Cyber-Attack Statistics [16] | Deep Learning | No | [44,45,46] |
| Analysis with Topic Modelling | LDA | Twitter [17,18] | Language Processing | No | [19,20] |
| Analysis with Term Frequency | TF-IDF | Twitter [17,18] | Language Processing | No | [19,20,21,22,23] |
| Analysis with Term Frequency | Porter Stemming | Twitter [17,18] | Language Processing | No | [21] |
| Analysis with Term Frequency | N-Gram | Twitter [17,18] | Language Processing | No | [19,20,21] |
| Forecasting of Threat | Exponential Smoothing | Cyber-Attack Statistics [16] | Statistical Analysis | No | [50] |
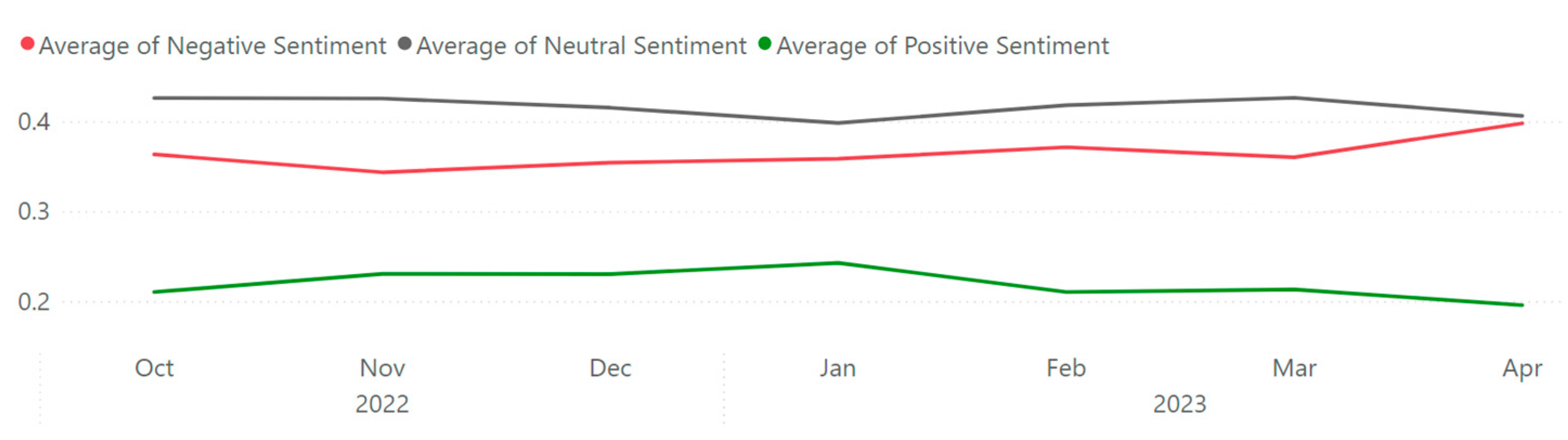
| Month | Tweets | Users | Locations | Languages | Retweets | Confidence of Negative Setiments | Confidence of Neutral Sentiments | Confidence of Positive Setiments | Translations |
|---|---|---|---|---|---|---|---|---|---|
| 22 Oct | 3954 | 3556 | 1588 | 38 | 3,727,756 | 0.36 | 0.43 | 0.21 | 941 |
| 22 Nov | 6470 | 5875 | 2358 | 38 | 9,981,856 | 0.34 | 0.43 | 0.23 | 1283 |
| 22 Dec | 6512 | 5544 | 2225 | 42 | 7,565,946 | 0.35 | 0.42 | 0.23 | 1533 |
| 23 Jan | 6685 | 5785 | 2364 | 40 | 7,802,301 | 0.36 | 0.40 | 0.24 | 1419 |
| 23 Feb | 5976 | 5053 | 2114 | 43 | 4,276,479 | 0.37 | 0.42 | 0.21 | 1373 |
| 23 Mar | 6634 | 5749 | 2357 | 41 | 4,799,540 | 0.36 | 0.43 | 0.21 | 1469 |
| 23 Apr | 1155 | 1083 | 538 | 27 | 713,083 | 0.40 | 0.41 | 0.20 | 258 |
| Total | 37,386 | 30,706 | 10,178 | 54 | 38,866,961 | 0.36 | 0.42 | 0.22 | 8199 |
| China Topic 1 | China Topic 2 | China Topic 3 | China Topic 4 | China Topic 5 | China Topic 6 | China Topic 7 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cyber | 29 | China | 20 | China | 16 | Russia | 6 | China | 21 | China | 15 | China | 17 |
| China | 22 | Cyber | 9 | Hack | 5 | China | 6 | hack | 12 | cyber | 7 | Chinese | 10 |
| attacks | 14 | hack | 6 | country | 4 | North | 4 | chains | 4 | war | 6 | sophisticated | 8 |
| Russia | 8 | TikTok | 4 | national | 3 | Cyber | 4 | supply | 4 | would | 6 | databases | 8 |
| States | 7 | China’s | 4 | IMMEDIATELY | 3 | reports | 3 | etc | 4 | Russia | 5 | Tech | 8 |
| Aus. Topic 1 | Aus. Topic 2 | Aus. Topic 3 | Aus. Topic 4 | Aus. Topic 5 | Aus. Topic 6 | Aus. Topic 7 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Australians | 10 | Australian | 9 | Australia | 7 | cyber | 4 | cyber | 12 | amp | 7 | Police | 16 |
| Australian | 9 | hack | 7 | way | 4 | POTUS | 3 | Australia | 11 | Australia | 7 | Australian | 14 |
| scamming | 6 | Medibank | 6 | Cyber | 3 | Australia | 3 | data | 8 | Cyber | 5 | Cyber | 12 |
| Boys | 6 | million | 5 | Australian | 3 | 2 | Australian | 7 | Leaks | 3 | Australia | 10 | |
| Yahoo | 6 | health | 5 | fundamental | 2 | AustralianOpen | 2 | attack | 5 | https://t.co | 3 | love | 7 |
| Dimensions | China | Australia |
|---|---|---|
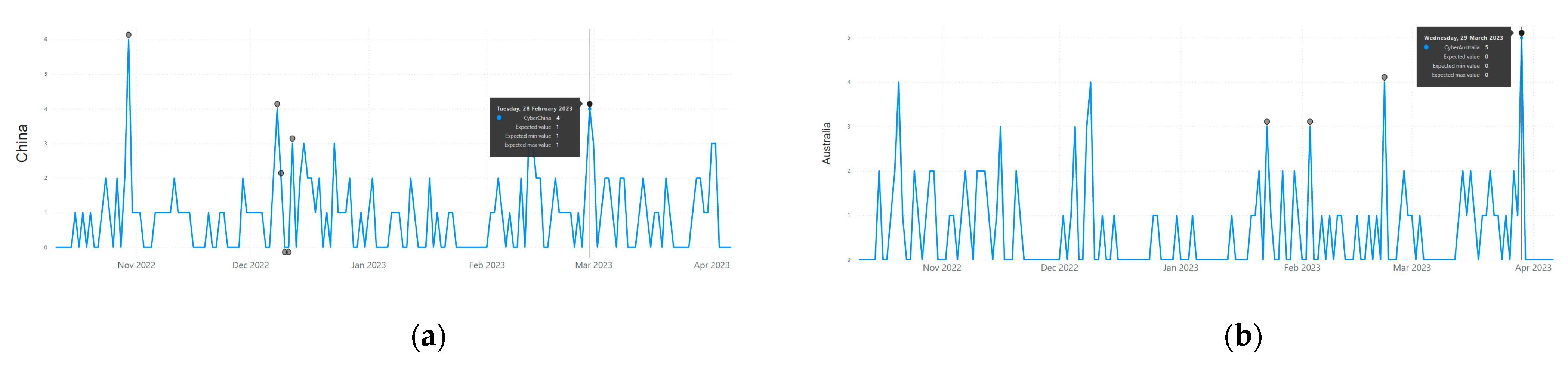
| Threat Spectrum | China suffers from spam (second in the world) and web threats (third in the world), as seen in Figure 7 | As seen from Figure 7, the topmost cyber threat affecting Australia is exploit (11th in the world) |
| Geopolitical | Tension surrounding US and Russia in cyberspace, as evident from Table 6 and Figure 10 and Figure 11 | Tension surrounding China in cyberspace, as evident from Table 7 and Figure 10 and Figure 11 |
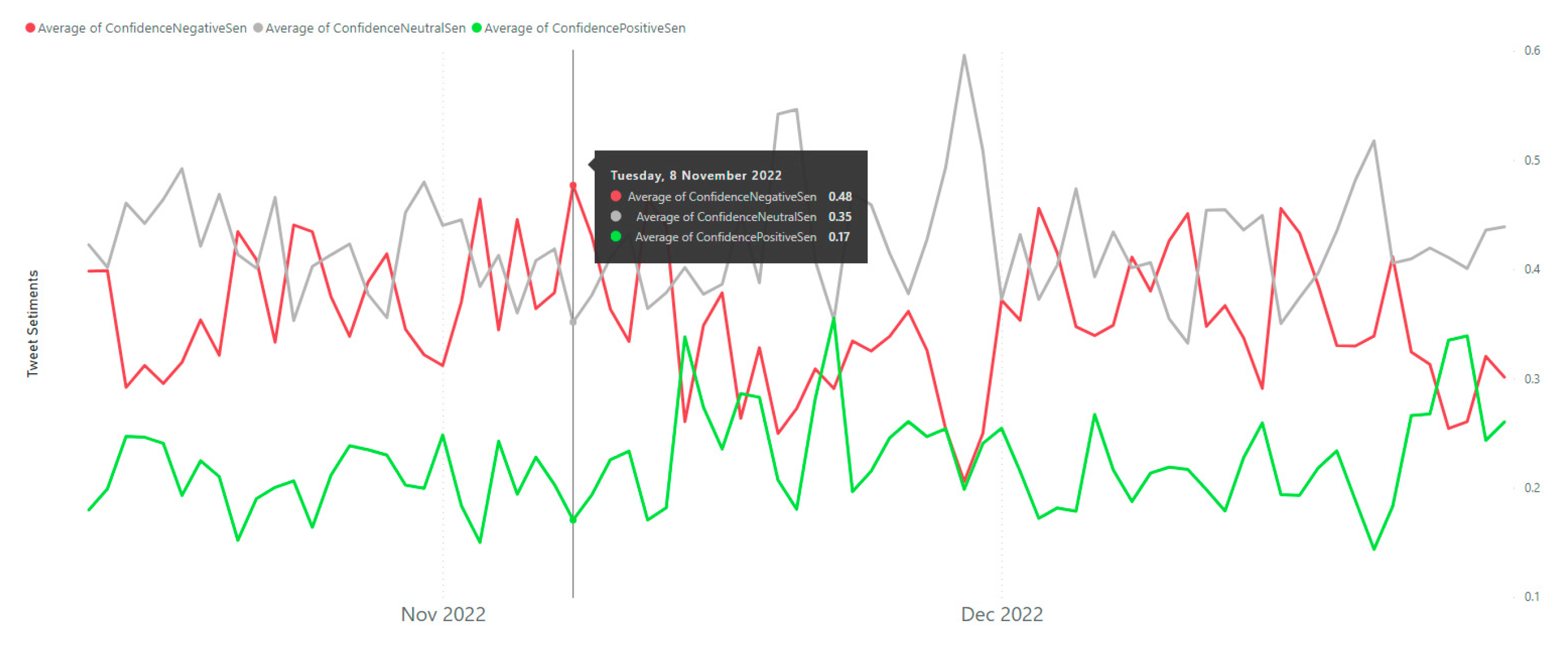
| Psychological and Societal | By measuring the negative sentiments of cyber-related Tweets, China has highly negative psychological and societal effects (Figure 6) | By measuring the negative sentiments of cyber-related Tweets, Australia has moderately negative psychological and societal effects (Figure 6) |
| Impacted Target | Chinese-owned apps like TikTok and database attack, as seen in Table 6 and Figure 10 and Figure 11 | Cyber-attack and data breach in Australian Health Sector (like, Medicare) as well as infrastructure (like the electricity network), as seen in Table 7 and Figure 10 and Figure 11 |
| National Concerns | Chinese concerns are geopolitical in nature, discussing cyberespionage and intrusions by foreign countries, particularly the United States, as observed in Table 6, Figure 10 and Figure 11 | Australians are concerned with data breach (e.g., Optus, Medibank) and cybersecurity threats and assaults, and issues like malware, phishing, and ransomware, as observed in Table 7 and Figure 10 and Figure 11 |
| Victimization | As noticed from Table 6 and Figure 10 and Figure 11, Chinese tech firms as well as the supply chains are most often the victims of cyber-attacks | As noticed from Table 7 and Figure 10 and Figure 11, both the general public (i.e., Australians through data breaches) and organizations (e.g., Optus, Medibank) are victims of cyber-attacks |
| Threat Level | Very high, as seen from Figure 7 (ranked second in terms of global spam attack and ranked third in terms of global network attack). Moreover, the attack scale in Figure 9 represents a higher value (i.e., 0.03 on average) for China | Moderate, as seen from Figure 7 (11th in terms of global exploits). Moreover, the attack scale in Figure 9 represents a lower value (i.e., 0.004 on an average) than China |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sufi, F. Novel Application of Open-Source Cyber Intelligence. Electronics 2023, 12, 3610. https://doi.org/10.3390/electronics12173610
Sufi F. Novel Application of Open-Source Cyber Intelligence. Electronics. 2023; 12(17):3610. https://doi.org/10.3390/electronics12173610
Chicago/Turabian StyleSufi, Fahim. 2023. "Novel Application of Open-Source Cyber Intelligence" Electronics 12, no. 17: 3610. https://doi.org/10.3390/electronics12173610
APA StyleSufi, F. (2023). Novel Application of Open-Source Cyber Intelligence. Electronics, 12(17), 3610. https://doi.org/10.3390/electronics12173610