
High-Level K-Nearest Neighbors (HLKNN): A Supervised Machine Learning Model for Classification Analysis




Abstract
:1. Introduction
- This paper proposes a machine learning method, named high-level k-nearest neighbors (HLKNN), based on the KNN algorithm.
- It contributes to improving the KNN approach since the noisy samples inefficiently affect its classification ability.
- Our work is original in that the HLKNN model was applied to 32 benchmark datasets to predict the related target values with the objective of model evaluation.
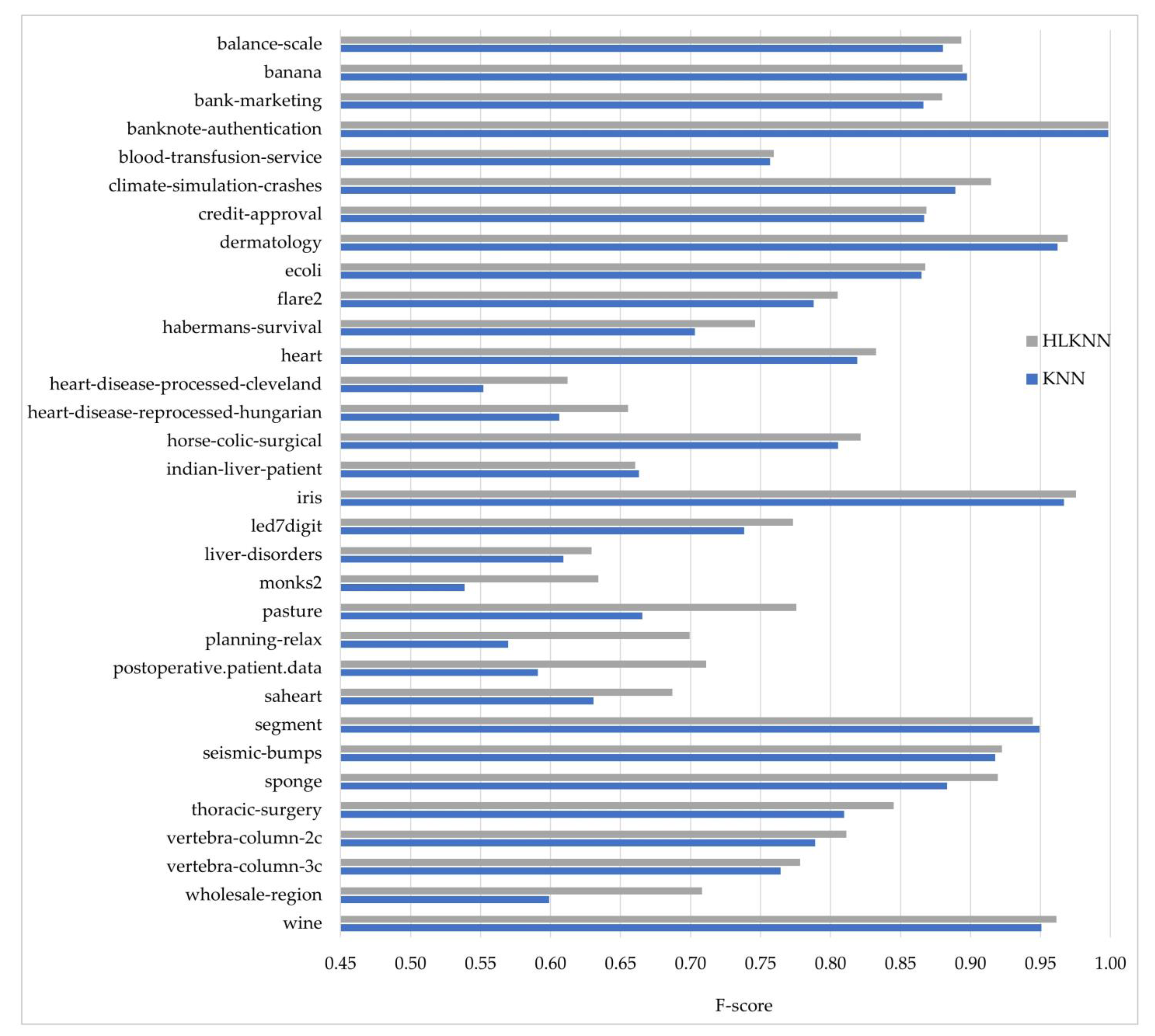
- The experimental results revealed that HLKNN outperformed KNN on 26 out of 32 datasets in terms of classification accuracy.
- The presented method in this study was also compared with the previous KNN variants, including uniform kNN, weighted kNN, kNNGNN, k-MMS, k-MRS, k-NCN, NN, k-NFL, k-NNL, k-CNN, and k-TNN, and the superiority of HLKNN over its counterparts was approved on the same datasets.
2. Related Works
2.1. A Review of Related Literature
2.2. A Review of KNN Variants
3. Materials and Methods
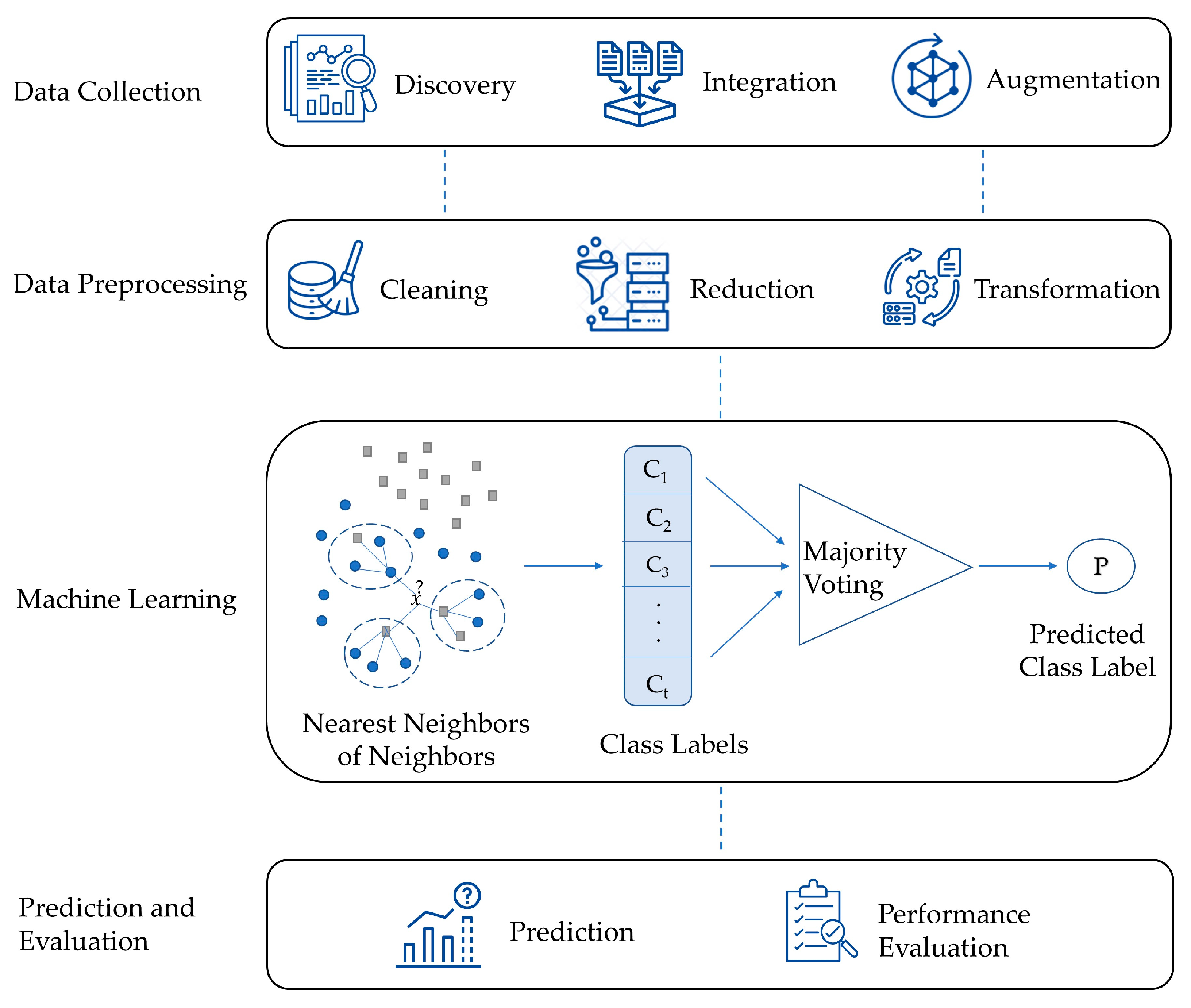
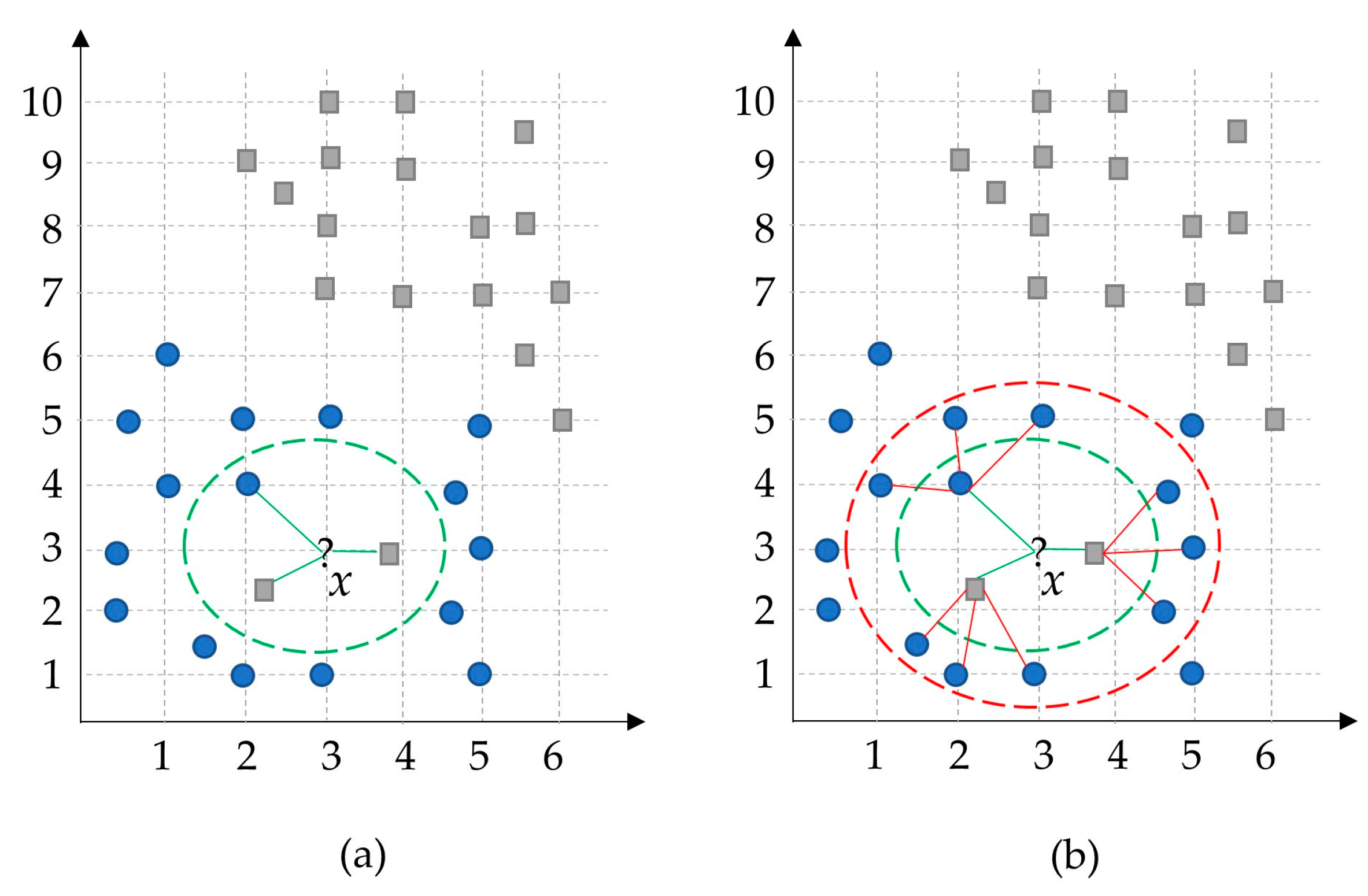
3.1. The Proposed Method: High-Level K-Nearest Neighbors (HLKNN)
3.2. Formal Description
4. Experimental Studies
4.1. Dataset Description
4.2. Results
4.3. Comparison with KNN Variants
5. Conclusions and Future Work
- The experimental results revealed the effectiveness of HLKNN compared to the KNN algorithm for 26 out of 32 datasets in terms of classification accuracy.
- On average, the HLKNN outperformed KNN with accuracy values of 81.01% and 79.76%, respectively.
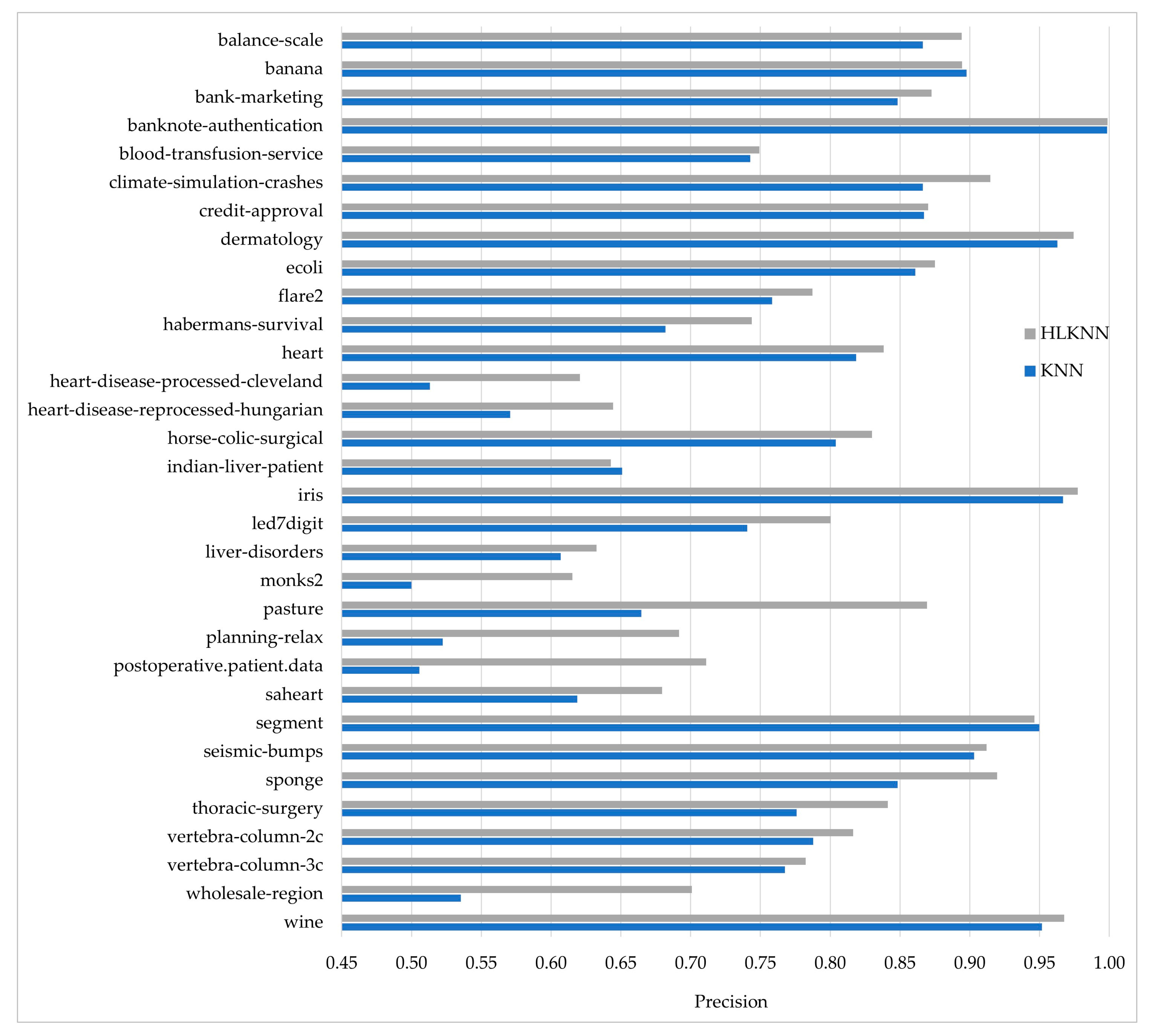
- In terms of the precision metric, HLKNN (0.8129) performed better than KNN (0.7611) with an improvement of over 5% on average.
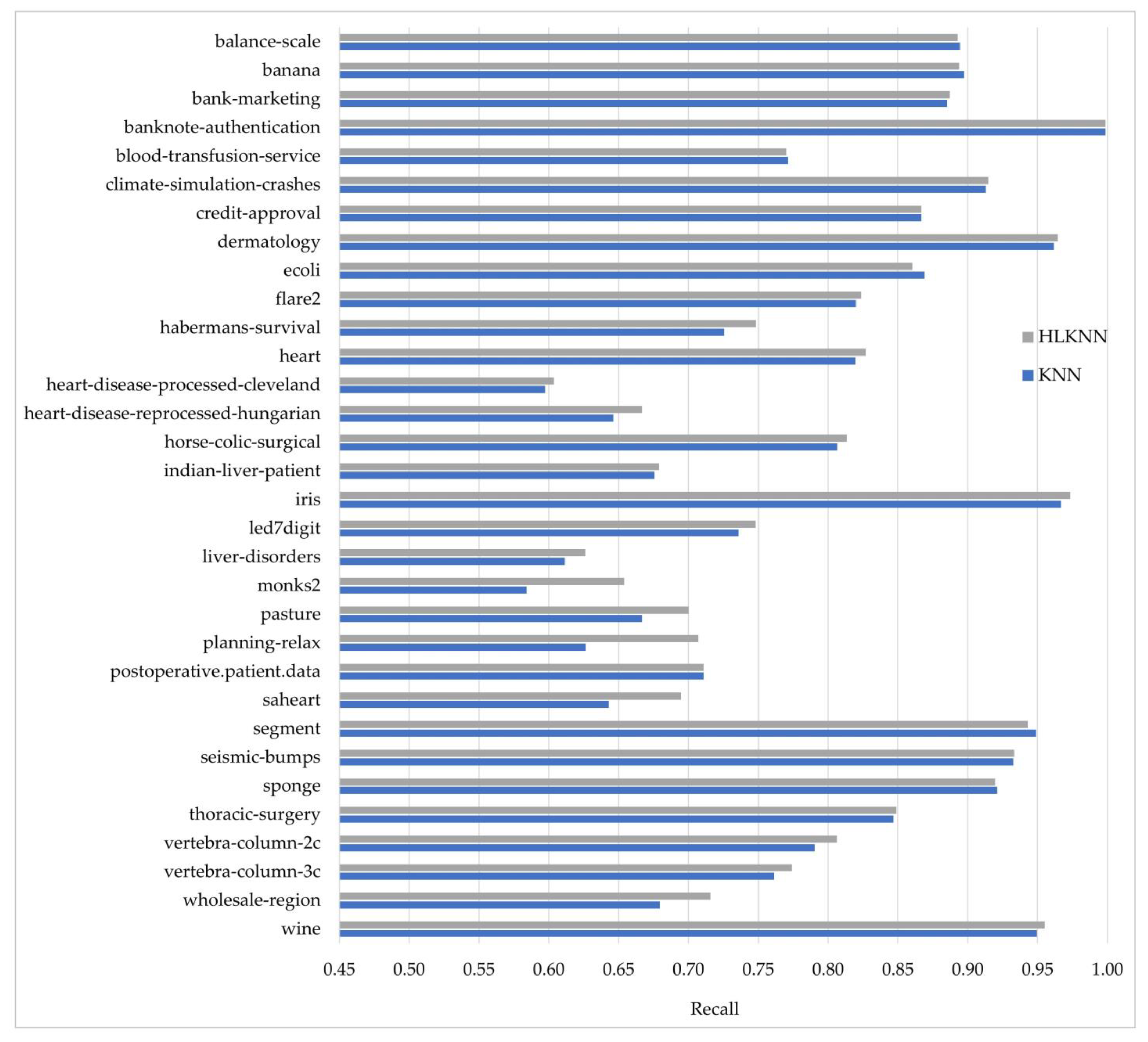
- In terms of the recall metric, the results revealed that HLKNN achieved equal or higher accuracy rates than KNN in 26 of 32 datasets.
- In terms of the f-score metric, HLKNN (0.8111) achieved better performance than KNN (0.7779) with an improvement of over 3% on average.
- The proposed model in this study was also compared with various KNN-based methods, including uniform kNN, weighted kNN, kNNGNN, k-MMS, k-MRS, k-NCN, NN, k-NFL, k-NNL, k-CNN, and k-TNN, and the superiority of HLKNN over its counterparts was approved.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| BICS | Blockchain-based integrity checking system |
| CSC | Cloud service consumers |
| CSP | Cloud service providers |
| DTR | Decision tree regression |
| GIS | Geographical information systems |
| HBoF | Hybrid bag of features |
| HLKNN | High-level k-nearest neighbors |
| IDS | Intrusion detection system |
| KNN | K-nearest neighbors |
| k-CNN | K-center nearest neighbor |
| k-MMS | K-min–max sum |
| k-MRS | k-Min ranking sum |
| k-NCN | K-nearest centroid neighborhood |
| k-NFL | K-nearest feature line |
| k-NNGNN | K-nearest neighbors learning method based on a graph neural network |
| k-NNL | K-nearest neighbor line |
| k-TNN | K-tunable nearest neighbor |
| LSTM | Long short-term memory |
| ML | Machine learning |
| NN | Nearest neighbor rule |
| PCA | Principal component analysis |
| RF | Random forest |
| RSL | Random substance learning |
| SC | Smart contract |
| SDN | Software-defined network |
| SLA | Service level agreements |
| SVR | Support vector regression |
| UAV | Unmanned aerial vehicles |
Appendix A
| Algorithm A1. High-Level K-Nearest Neighbors (HLKNN) |
| Inputs: |
| DTrain: the training set with n data points |
| DTest: test set |
| k: the number of the nearest neighbors |
| Outputs: |
| P: predicted labels for the testing set |
| Begin |
| foreach x DTest do |
| = kNearestNeighbors (DTrain, x, k) # k-nearest neighbors of x |
| C = Ø |
| foreach s do |
| y = Class (s) # class label of the low-level neighborhood |
| C = C y |
| = kNearestNeighbors (DTrain, s, k) # neighbors of the neighbors |
| foreach o |
| y = Class (o) # class label of the high-level neighborhood |
| C = C y |
| end foreach |
| end foreach |
| c = # prediction after the majority voting |
| P = P c |
| end foreach |
| End Algorithm |
References
- Jiang, Y.; Li, X.; Luo, H.; Yin, S.; Kaynak, O. Quo Vadis Artificial Intelligence? Discov. Artif. Intell. 2022, 2, 629869. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine Learning and Deep Learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Pei, J.; Tong, H. Data Mining: Concepts and Techniques, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Ahmad, S.R.; Bakar, A.A.; Yaakub, M.R.; Yusop, N.M.M. Statistical validation of ACO-KNN algorithm for sentiment analysis. J. Telecommun. Electron. Comput. Eng. 2017, 9, 165–170. [Google Scholar]
- Kramer, O. Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- Hasan, M.J.; Kim, J.; Kim, C.H.; Kim, J.-M. Health State Classification of a Spherical Tank Using a Hybrid Bag of Features and K Nearest Neighbor. Appl. Sci. 2020, 10, 2525. [Google Scholar] [CrossRef]
- Beskopylny, A.N.; Stelmakh, S.A.; Shcherban, E.M.; Mailyan, L.R.; Meskhi, B.; Razveeva, I.; Chernilnik, A.; Beskopylny, N. Concrete Strength Prediction Using Machine Learning Methods CatBoost, k-Nearest Neighbors, Support Vector Regression. Appl. Sci. 2022, 12, 10864. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Z.; Li, Z.; Du, S. A Novel Fault Detection Scheme Based on Mutual k-Nearest Neighbor Method: Application on the Industrial Processes with Outliers. Processes 2022, 10, 497. [Google Scholar] [CrossRef]
- Lu, J.; Qian, W.; Li, S.; Cui, R. Enhanced K-Nearest Neighbor for Intelligent Fault Diagnosis of Rotating Machinery. Appl. Sci. 2021, 11, 919. [Google Scholar] [CrossRef]
- Salem, H.; Shams, M.Y.; Elzeki, O.M.; Abd Elfattah, M.; Al-Amri, J.F.; Elnazer, S. Fine-Tuning Fuzzy KNN Classifier Based on Uncertainty Membership for the Medical Diagnosis of Diabetes. Appl. Sci. 2022, 12, 950. [Google Scholar] [CrossRef]
- Miron, M.; Moldovanu, S.; Ștefănescu, B.I.; Culea, M.; Pavel, S.M.; Culea-Florescu, A.L. A New Approach in Detectability of Microcalcifications in the Placenta during Pregnancy Using Textural Features and K-Nearest Neighbors Algorithm. J. Imaging 2022, 8, 81. [Google Scholar] [CrossRef]
- Rattanasak, A.; Uthansakul, P.; Uthansakul, M.; Jumphoo, T.; Phapatanaburi, K.; Sindhupakorn, B.; Rooppakhun, S. Real-Time Gait Phase Detection Using Wearable Sensors for Transtibial Prosthesis Based on a kNN Algorithm. Sensors 2022, 22, 4242. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Vo, Q.-T.; Nguyen, T.-H. Adaptive KNN-Based Extended Collaborative Filtering Recommendation Services. Big Data Cogn. Comput. 2023, 7, 106. [Google Scholar] [CrossRef]
- Corso, M.P.; Perez, F.L.; Stefenon, S.F.; Yow, K.-C.; García Ovejero, R.; Leithardt, V.R.Q. Classification of Contaminated Insulators Using k-Nearest Neighbors Based on Computer Vision. Computers 2021, 10, 112. [Google Scholar] [CrossRef]
- Syamsuddin, I.; Barukab, O.M. SUKRY: Suricata IDS with Enhanced kNN Algorithm on Raspberry Pi for Classifying IoT Botnet Attacks. Electronics 2022, 11, 737. [Google Scholar] [CrossRef]
- Derhab, A.; Guerroumi, M.; Gumaei, A.; Maglaras, L.; Ferrag, M.A.; Mukherjee, M.; Khan, F.A. Blockchain and Random Subspace Learning-Based IDS for SDN-Enabled Industrial IoT Security. Sensors 2019, 19, 3119. [Google Scholar] [CrossRef]
- Liu, G.; Zhao, H.; Fan, F.; Liu, G.; Xu, Q.; Nazir, S. An Enhanced Intrusion Detection Model Based on Improved kNN in WSNs. Sensors 2022, 22, 1407. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Q.; Wang, L.; He, J.; Li, T. KNN-Based Consensus Algorithm for Better Service Level Agreement in Blockchain as a Service (BaaS) Systems. Electronics 2023, 12, 1429. [Google Scholar] [CrossRef]
- Fan, G.-F.; Guo, Y.-H.; Zheng, J.-M.; Hong, W.-C. Application of the Weighted K-Nearest Neighbor Algorithm for Short-Term Load Forecasting. Energies 2019, 12, 916. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Huang, K.-Y.; Shen, Y.-X.; Lee, Y.-C. Improved Weighted k-Nearest Neighbor Based on PSO for Wind Power System State Recognition. Energies 2020, 13, 5520. [Google Scholar] [CrossRef]
- Gajan, S. Modeling of Seismic Energy Dissipation of Rocking Foundations Using Nonparametric Machine Learning Algorithms. Geotechnics 2021, 1, 534–557. [Google Scholar] [CrossRef]
- Martínez-Clark, R.; Pliego-Jimenez, J.; Flores-Resendiz, J.F.; Avilés-Velázquez, D. Optimum k-Nearest Neighbors for Heading Synchronization on a Swarm of UAVs under a Time-Evolving Communication Network. Entropy 2023, 25, 853. [Google Scholar] [CrossRef] [PubMed]
- Cha, G.-W.; Choi, S.-H.; Hong, W.-H.; Park, C.-W. Developing a Prediction Model of Demolition-Waste Generation-Rate via Principal Component Analysis. Int. J. Environ. Res. Public Health 2023, 20, 3159. [Google Scholar] [CrossRef]
- Bullejos, M.; Cabezas, D.; Martín-Martín, M.; Alcalá, F.J. A K-Nearest Neighbors Algorithm in Python for Visualizing the 3D Stratigraphic Architecture of the Llobregat River Delta in NE Spain. J. Mar. Sci. Eng. 2022, 10, 986. [Google Scholar] [CrossRef]
- Bullejos, M.; Cabezas, D.; Martín-Martín, M.; Alcalá, F.J. Confidence of a k-Nearest Neighbors Python Algorithm for the 3D Visualization of Sedimentary Porous Media. J. Mar. Sci. Eng. 2023, 11, 60. [Google Scholar] [CrossRef]
- Zhang, L.; Zhu, Y.; Su, J.; Lu, W.; Li, J.; Yao, Y. A Hybrid Prediction Model Based on KNN-LSTM for Vessel Trajectory. Mathematics 2022, 10, 4493. [Google Scholar] [CrossRef]
- Park, J.; Oh, J. Analysis of Collected Data and Establishment of an Abnormal Data Detection Algorithm Using Principal Component Analysis and K-Nearest Neighbors for Predictive Maintenance of Ship Propulsion Engine. Processes 2022, 10, 2392. [Google Scholar] [CrossRef]
- Tamamadin, M.; Lee, C.; Kee, S.-H.; Yee, J.-J. Regional Typhoon Track Prediction Using Ensemble k-Nearest Neighbor Machine Learning in the GIS Environment. Remote Sens. 2022, 14, 5292. [Google Scholar] [CrossRef]
- Mallek, A.; Klosa, D.; Büskens, C. Impact of Data Loss on Multi-Step Forecast of Traffic Flow in Urban Roads Using K-Nearest Neighbors. Sustainability 2022, 14, 11232. [Google Scholar] [CrossRef]
- Kang, S. k-Nearest Neighbor Learning with Graph Neural Networks. Mathematics 2021, 9, 830. [Google Scholar] [CrossRef]
- Mazón, J.N.; Micó, L.; Moreno-Seco, F. New Neighborhood Based Classification Rules for Metric Spaces and Their Use in Ensemble Classification. In Proceedings of the IbPRIA 2007 on Pattern Recognition and Image Analysis, Girona, Spain, 6–8 June 2007; pp. 354–361. [Google Scholar] [CrossRef]
- Sánchez, J.S.; Pla, F.; Ferri, F.J. On the Use of Neighbourhood-Based Non-Parametric Classifiers. Pattern Recognit. Lett. 1997, 18, 1179–1186. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2007; pp. 1–654. [Google Scholar] [CrossRef]
- Orozco-Alzate, M.; Castellanos-Domínguez, C.G. Comparison of the Nearest Feature Classifiers for Face Recognition. Mach. Vis. Appl. 2006, 17, 279–285. [Google Scholar] [CrossRef]
- Lou, Z.; Jin, Z. Novel Adaptive Nearest Neighbor Classifiers Based on Hit-Distance. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 87–90. [Google Scholar] [CrossRef]
- Altiņcay, H. Improving the K-Nearest Neighbour Rule: Using Geometrical Neighbourhoods and Manifold-Based Metrics. Expert Syst. 2011, 28, 391–406. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann: Cambridge, MA, USA, 2016; pp. 1–664. [Google Scholar]
- Aha, D.; Kibler, D. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef]
- Nica, I.; Alexandru, D.B.; Crăciunescu, S.L.P.; Ionescu, Ș. Automated Valuation Modelling: Analysing Mortgage Behavioural Life Profile Models Using Machine Learning Techniques. Sustainability 2021, 13, 5162. [Google Scholar] [CrossRef]
- Kelly, M.; Longjohn, R.; Nottingham, K. The UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu (accessed on 28 July 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Dataset Name | Number of Attributes | Number of Instances | Number of Classes | Missing | Domain |
|---|---|---|---|---|---|---|
| 1 | balance-scale | 4 | 625 | 3 | Yes | psychology |
| 2 | banana | 2 | 5300 | 2 | No | shape |
| 3 | bank-marketing | 16 | 45,211 | 2 | No | banking |
| 4 | banknote-authentication | 4 | 1372 | 2 | No | finance |
| 5 | blood-transfusion-service | 4 | 748 | 2 | No | health |
| 6 | climate-simulation-crashes | 17 | 540 | 2 | No | environment |
| 7 | credit-approval | 15 | 690 | 2 | Yes | finance |
| 8 | dermatology | 33 | 366 | 6 | Yes | health |
| 9 | ecoli | 7 | 336 | 8 | Yes | biology |
| 10 | flare2 | 10 | 1066 | 2 | Yes | environment |
| 11 | habermans-survival | 3 | 306 | 2 | Yes | health |
| 12 | heart | 13 | 270 | 2 | Yes | health |
| 13 | heart-disease-processed-cleveland | 13 | 303 | 5 | No | health |
| 14 | heart-disease-reprocessed-hungarian | 13 | 294 | 5 | No | health |
| 15 | horse-colic-surgical | 27 | 368 | 2 | Yes | animal |
| 16 | indian-liver-patient | 10 | 583 | 2 | No | health |
| 17 | iris | 4 | 150 | 3 | No | life |
| 18 | led7digit | 7 | 500 | 10 | No | science |
| 19 | liver-disorders | 6 | 345 | 2 | Yes | health |
| 20 | monks2 | 6 | 601 | 2 | No | science |
| 21 | pasture | 22 | 36 | 3 | No | environment |
| 22 | planning-relax | 13 | 182 | 2 | No | health |
| 23 | postoperative.patient.data | 8 | 90 | 3 | Yes | health |
| 24 | saheart | 9 | 462 | 2 | No | health |
| 25 | segment | 19 | 2310 | 7 | No | science |
| 26 | seismic-bumps | 18 | 2584 | 2 | No | geology |
| 27 | sponge | 45 | 76 | 3 | Yes | marine |
| 28 | thoracic-surgery | 16 | 470 | 2 | No | health |
| 29 | vertebra-column-2c | 6 | 310 | 2 | No | health |
| 30 | vertebra-column-3c | 6 | 310 | 3 | No | health |
| 31 | wholesale-region | 8 | 440 | 3 | No | business |
| 32 | wine | 13 | 178 | 3 | No | chemistry |
| Dataset Name | KNN | HLKNN |
|---|---|---|
| balance-scale | 89.44 | 89.29 |
| banana | 89.75 | 89.40 |
| bank-marketing | 88.52 | 88.72 |
| banknote-authentication | 99.85 | 99.85 |
| blood-transfusion-service | 77.14 | 77.01 |
| climate-simulation-crashes | 91.30 | 91.48 |
| credit-approval | 86.67 | 86.67 |
| dermatology | 96.17 | 96.44 |
| ecoli | 86.90 | 86.03 |
| flare2 | 81.99 | 82.37 |
| habermans-survival | 72.55 | 74.84 |
| heart | 81.97 | 82.69 |
| heart-disease-processed-cleveland | 59.74 | 60.37 |
| heart-disease-reprocessed-hungarian | 64.63 | 66.69 |
| horse-colic-surgical | 80.67 | 81.33 |
| indian-liver-patient | 67.58 | 67.90 |
| iris | 96.67 | 97.33 |
| led7digit | 73.60 | 74.80 |
| liver-disorders | 61.16 | 62.61 |
| monks2 | 58.40 | 65.41 |
| pasture | 66.67 | 70.00 |
| planning-relax | 62.64 | 70.73 |
| postoperative.patient.data | 71.11 | 71.11 |
| saheart | 64.29 | 69.48 |
| segment | 94.89 | 94.28 |
| seismic-bumps | 93.27 | 93.31 |
| sponge | 92.11 | 91.96 |
| thoracic-surgery | 84.68 | 84.89 |
| vertebra-column-2c | 79.03 | 80.65 |
| vertebra-column-3c | 76.13 | 77.42 |
| wholesale-region | 67.95 | 71.59 |
| wine | 94.94 | 95.52 |
| Mean | 79.76 | 81.01 |
| Dataset Name | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| balance-scale | 90.48 | 84.13 | 80.95 | 88.89 | 95.24 | 87.10 | 98.39 | 90.32 | 87.10 | 90.32 | 89.29 |
| banana | 90.00 | 90.94 | 88.68 | 88.11 | 91.70 | 86.98 | 88.68 | 90.94 | 88.30 | 89.62 | 89.40 |
| bank-marketing | 90.07 | 88.94 | 87.61 | 89.16 | 87.61 | 89.38 | 86.06 | 90.49 | 89.16 | 88.72 | 88.72 |
| banknote-authentication | 100.00 | 100.00 | 100.00 | 100.00 | 99.27 | 100.00 | 99.27 | 100.00 | 100.00 | 100.00 | 99.85 |
| blood-transfusion-service | 74.67 | 76.00 | 81.33 | 76.00 | 80.00 | 74.67 | 76.00 | 76.00 | 77.03 | 78.38 | 77.01 |
| climate-simulation-crashes | 92.59 | 92.59 | 92.59 | 90.74 | 94.44 | 88.89 | 90.74 | 90.74 | 92.59 | 88.89 | 91.48 |
| credit-approval | 85.51 | 86.96 | 73.91 | 86.96 | 84.06 | 92.75 | 88.41 | 84.06 | 94.20 | 89.86 | 86.67 |
| dermatology | 94.59 | 97.30 | 100.00 | 97.30 | 97.30 | 94.59 | 100.00 | 97.22 | 97.22 | 88.89 | 96.44 |
| ecoli | 85.29 | 85.29 | 91.18 | 79.41 | 85.29 | 82.35 | 90.91 | 90.91 | 81.82 | 87.88 | 86.03 |
| flare2 | 85.05 | 84.11 | 85.05 | 81.31 | 81.31 | 77.57 | 84.91 | 85.85 | 82.08 | 76.42 | 82.37 |
| habermans-survival | 74.19 | 83.87 | 80.65 | 74.19 | 70.97 | 64.52 | 80.00 | 80.00 | 66.67 | 73.33 | 74.84 |
| heart | 86.67 | 80.00 | 80.00 | 73.33 | 79.31 | 96.55 | 82.76 | 86.21 | 68.97 | 93.10 | 82.69 |
| heart-disease-processed-cleveland | 64.52 | 64.52 | 61.29 | 53.33 | 60.00 | 43.33 | 56.67 | 76.67 | 56.67 | 66.67 | 60.37 |
| heart-disease-reprocessed-hungarian | 76.67 | 63.33 | 60.00 | 60.00 | 86.21 | 68.97 | 58.62 | 58.62 | 79.31 | 55.17 | 66.69 |
| horse-colic-surgical | 80.00 | 70.00 | 90.00 | 80.00 | 80.00 | 83.33 | 83.33 | 90.00 | 76.67 | 80.00 | 81.33 |
| indian-liver-patient | 67.80 | 69.49 | 77.97 | 72.41 | 60.34 | 65.52 | 74.14 | 62.07 | 55.17 | 74.14 | 67.90 |
| iris | 100.00 | 100.00 | 93.33 | 100.00 | 100.00 | 100.00 | 100.00 | 93.33 | 93.33 | 93.33 | 97.33 |
| led7digit | 78.00 | 70.00 | 84.00 | 70.00 | 70.00 | 68.00 | 76.00 | 78.00 | 84.00 | 70.00 | 74.80 |
| liver-disorders | 65.71 | 57.14 | 62.86 | 57.14 | 68.57 | 47.06 | 70.59 | 67.65 | 64.71 | 64.71 | 62.61 |
| monks2 | 55.74 | 65.00 | 60.00 | 73.33 | 61.67 | 73.33 | 76.67 | 60.00 | 63.33 | 65.00 | 65.41 |
| pasture | 75.00 | 50.00 | 25.00 | 100.00 | 75.00 | 75.00 | 100.00 | 66.67 | 66.67 | 66.67 | 70.00 |
| planning-relax | 94.74 | 73.68 | 66.67 | 38.89 | 77.78 | 72.22 | 66.67 | 88.89 | 50.00 | 77.78 | 70.73 |
| postoperative.patient.data | 77.78 | 77.78 | 55.56 | 88.89 | 44.44 | 55.56 | 66.67 | 77.78 | 100.00 | 66.67 | 71.11 |
| saheart | 63.83 | 76.60 | 63.04 | 60.87 | 69.57 | 67.39 | 73.91 | 71.74 | 78.26 | 69.57 | 69.48 |
| segment | 91.77 | 96.10 | 93.94 | 91.34 | 94.37 | 94.81 | 95.24 | 96.10 | 95.24 | 93.94 | 94.28 |
| seismic-bumps | 93.05 | 91.12 | 95.37 | 93.44 | 91.86 | 94.19 | 92.25 | 93.80 | 93.80 | 94.19 | 93.31 |
| sponge | 100.00 | 100.00 | 100.00 | 75.00 | 100.00 | 87.50 | 85.71 | 85.71 | 85.71 | 100.00 | 91.96 |
| thoracic-surgery | 87.23 | 82.98 | 85.11 | 87.23 | 78.72 | 87.23 | 80.85 | 87.23 | 82.98 | 89.36 | 84.89 |
| vertebra-column-2c | 77.42 | 67.74 | 70.97 | 87.10 | 80.65 | 90.32 | 77.42 | 87.10 | 77.42 | 90.32 | 80.65 |
| vertebra-column-3c | 80.65 | 67.74 | 67.74 | 80.65 | 80.65 | 90.32 | 67.74 | 80.65 | 74.19 | 83.87 | 77.42 |
| wholesale-region | 68.18 | 75.00 | 77.27 | 65.91 | 70.45 | 59.09 | 81.82 | 77.27 | 65.91 | 75.00 | 71.59 |
| wine | 100.00 | 100.00 | 88.89 | 94.44 | 83.33 | 94.44 | 100.00 | 100.00 | 100.00 | 94.12 | 95.52 |
| Dataset Name | Uniform | Weighted | kNN | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| kNN | kNN | GNN | k-MMS | k-MRS | k-NCN | NN | k-NFL | k-NNL | k-CNN | k-TNN | HLKNN | |
| [31] | [31] | [31] | [32] | [32] | [33] | [34] | [35] | [36] | [37] | [37] | (Proposed) | |
| balance-scale | 85.47 | 85.64 | 86.73 | - | - | - | - | - | - | - | - | 89.29 |
| dermatology | - | - | - | 85.08 | 85.68 | 89.89 | 85.68 | 95.36 | 93.34 | 95.03 | 90.77 | 96.44 |
| ecoli | 81.47 | 82.97 | 81.51 | - | - | - | - | - | - | - | - | 86.03 |
| habermans-survival | - | - | - | 73.14 | 73.99 | 72.94 | 68.25 | 72.42 | 64.72 | 74.31 | 73.07 | 74.84 |
| heart | 79.19 | 79.07 | 78.74 | 63.36 | 64.29 | 67.39 | 59.67 | 67.79 | 64.29 | 66.47 | 64.75 | 82.69 |
| iris | 91.14 | 92.34 | 94.27 | 94.53 | 95.20 | 96.27 | 95.20 | 96.13 | 93.73 | 95.07 | 96.27 | 97.33 |
| liver-disorders | - | - | - | 66.15 | 66.32 | 69.28 | 61.63 | 67.36 | 59.83 | 63.48 | 66.09 | 62.61 |
| segment | 89.79 | 91.6 | 92.51 | - | - | - | - | - | - | - | - | 94.28 |
| wine | 89.65 | 91.39 | 94.78 | 69.63 | 68.75 | 71.22 | 71.57 | 85.84 | 83.36 | 77.28 | 69.86 | 95.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ozturk Kiyak, E.; Ghasemkhani, B.; Birant, D. High-Level K-Nearest Neighbors (HLKNN): A Supervised Machine Learning Model for Classification Analysis. Electronics 2023, 12, 3828. https://doi.org/10.3390/electronics12183828
Ozturk Kiyak E, Ghasemkhani B, Birant D. High-Level K-Nearest Neighbors (HLKNN): A Supervised Machine Learning Model for Classification Analysis. Electronics. 2023; 12(18):3828. https://doi.org/10.3390/electronics12183828
Chicago/Turabian StyleOzturk Kiyak, Elife, Bita Ghasemkhani, and Derya Birant. 2023. "High-Level K-Nearest Neighbors (HLKNN): A Supervised Machine Learning Model for Classification Analysis" Electronics 12, no. 18: 3828. https://doi.org/10.3390/electronics12183828
APA StyleOzturk Kiyak, E., Ghasemkhani, B., & Birant, D. (2023). High-Level K-Nearest Neighbors (HLKNN): A Supervised Machine Learning Model for Classification Analysis. Electronics, 12(18), 3828. https://doi.org/10.3390/electronics12183828