1. Introduction
Group activity recognition (GAR) classifies the collective behavior of a group of people in a short video clip of a specific event based on the individual actions of the group members and their interactions with each other [
1]. Different from deep learning tasks, such as human activity recognition [
2], people tracking [
3], and occupancy counting [
4], GAR is unique in its potential to explore critical semantic information from interactions among individuals and thus widely used in security surveillance, social role understanding, and sports video analysis.
A big challenge for GAR is to characterize the distinctive property of interactions among individuals in a group. Almost all early GAR methods [
5,
6,
7] used hand-crafted features to describe the interactions among individuals. The performance of these methods was limited due to their inability to extract semantic features from the video frames. Machine learning-based, especially deep learning, methods are capable of learning features at various levels of abstraction from the training data to obtain better performance than those using hand-crafted features. Among the recent deep learning methods, multi-head self-attention networks (MHSA)-based methods [
8,
9,
10] achieved the best performance with a global receptive field, although not being computationally efficient. Graphs have shown great success in characterizing the structure of a group and the interactions existing in a group in recent years. Some state-of-the-art deep learning-based GAR methods used graphs to learn meaningful features through innovations in interaction modeling and achieved promising results.
To characterize the interactions among individuals in the group, many state-of-the-art deep learning-based GAR methods learn the features of interactions of each person with others in the neighborhood in each frame and characterize the interactions among them with graphs. Early graph neural networks (GNNs)-based methods [
11,
12] are well suited to model these interactions, but their predefined connectivity is not flexible for every individual’s interactions with others [
13]. The dynamic inference network (DIN) [
13] takes advantage of the deformable convolutional network (DCN) [
14] to generate dynamic convolutional sampling positions and provide a description of group activity that can suit every individual’s interactions with others in the group. A significant challenge for the existing GAR methods is that their models only consider the interactions of each person with their neighbors to characterize their influence on group activity. They do not consider the influence from other individuals.
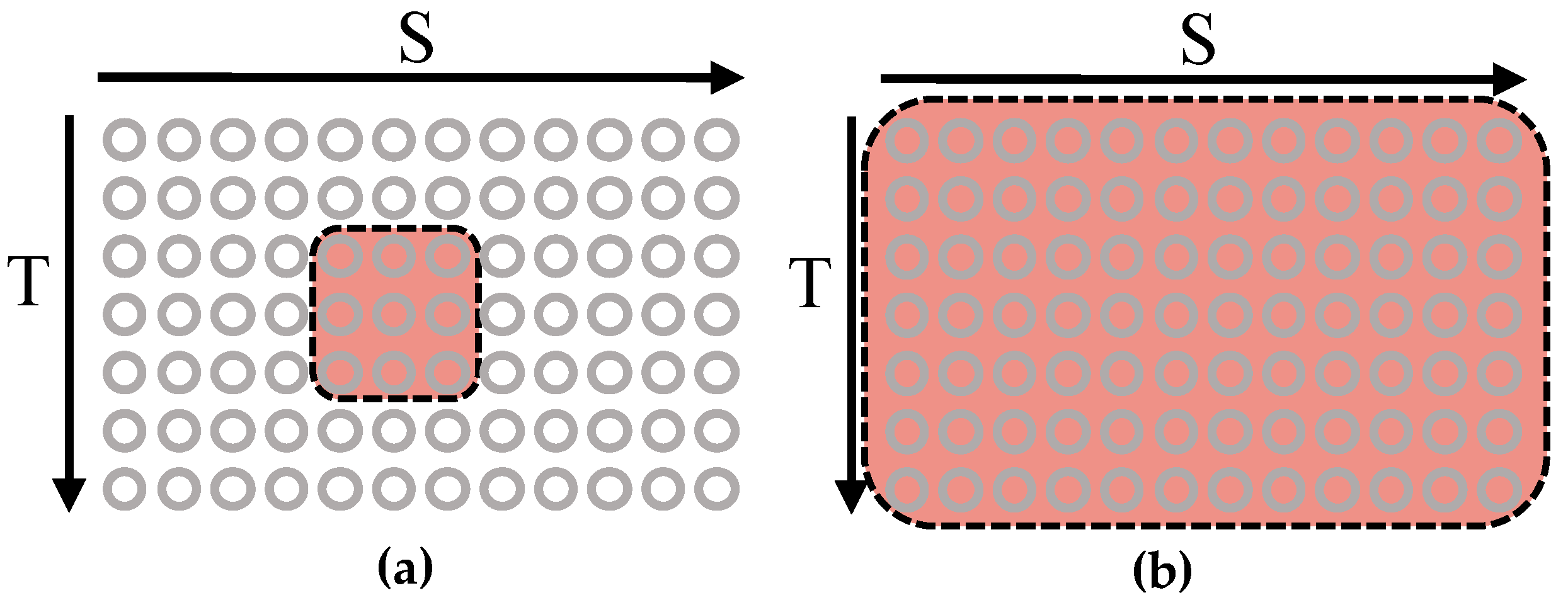
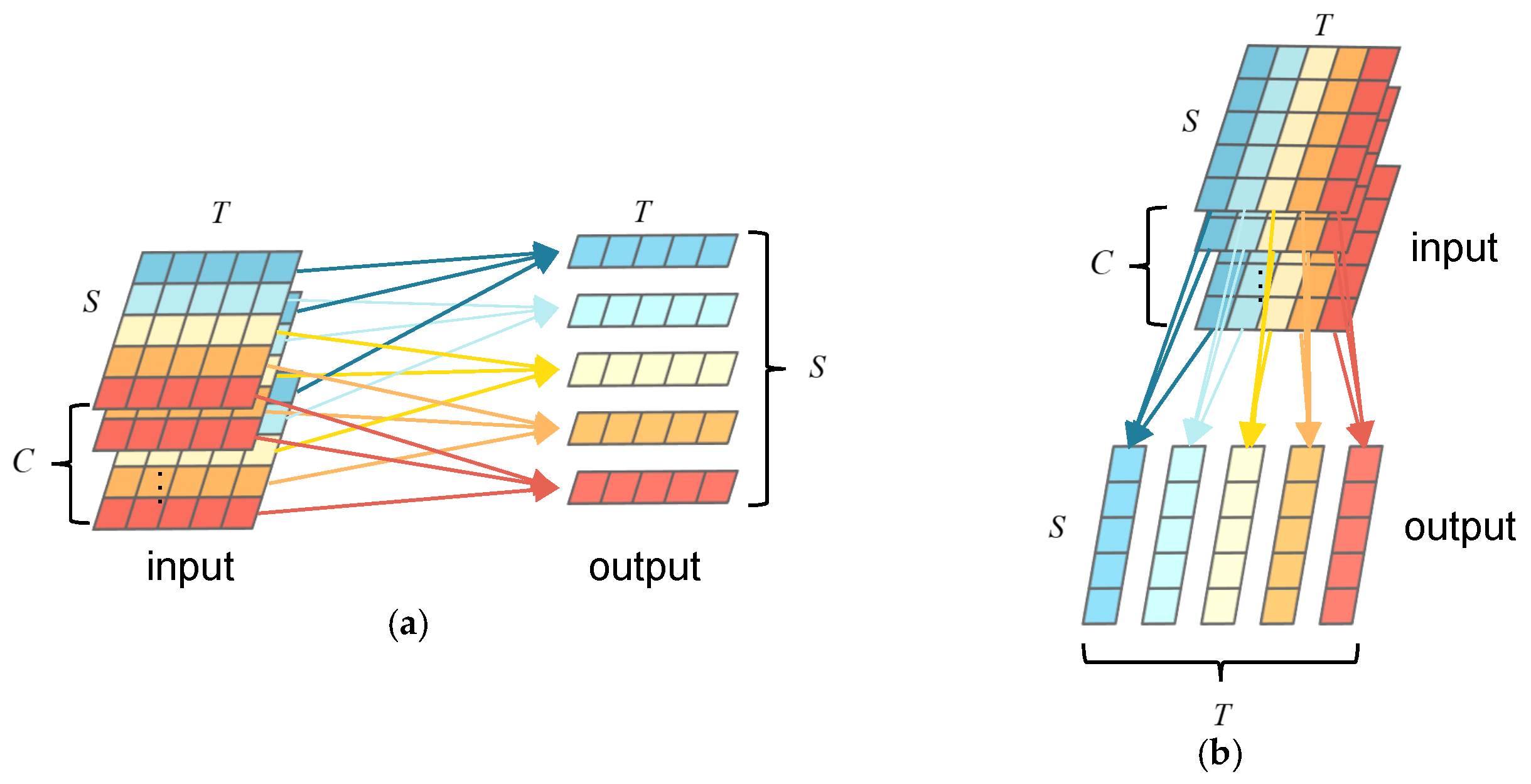
Current GNN-based methods usually use mapping layers [
11,
12,
13], i.e., normal convolutional layers with a receptive field of
as shown in
Figure 1a, or fully connected layers with a receptive field of
in both spatial and temporal dimensions to describe the interactions of each individual with their neighbors. Each circle in
Figure 1 represents the feature of the state of an individual action in one frame. The horizontal (S) axis represents the indexes of individuals in the group according to their locations in the x-axis of the image. The vertical (T) axis represents the indexes of the image frames in the group action video clip. The red-shaded area represents the local receptive field centered around an individual for the mapping layer used in the existing methods [
11,
12,
13]. Although these approaches [
11,
12,
13] simplify the computation and reduce the computation cost, they fail to catch the features of global interaction patterns or the influence from all other individuals involved in the group activity.
To obtain better GAR performance, the distinctive pattern of group activity should consider the global interactions among individuals, i.e., the interactions among all group members throughout the video of the entire event. Learning the interaction pattern of a group activity from a global viewpoint is critical to improving GAR performance. Using mapping layers with a global receptive field in the spatial–temporal dimensions helps the network to capture the interactions among all individuals [
8,
9,
10]. The mapping layer with the global receptive field (shown in
Figure 1b) involves the locations of all members in the group and all image frames in the event video when computing, and it is computationally expensive. Characterizing global interactions involved in group activity efficiently remains an open challenge.
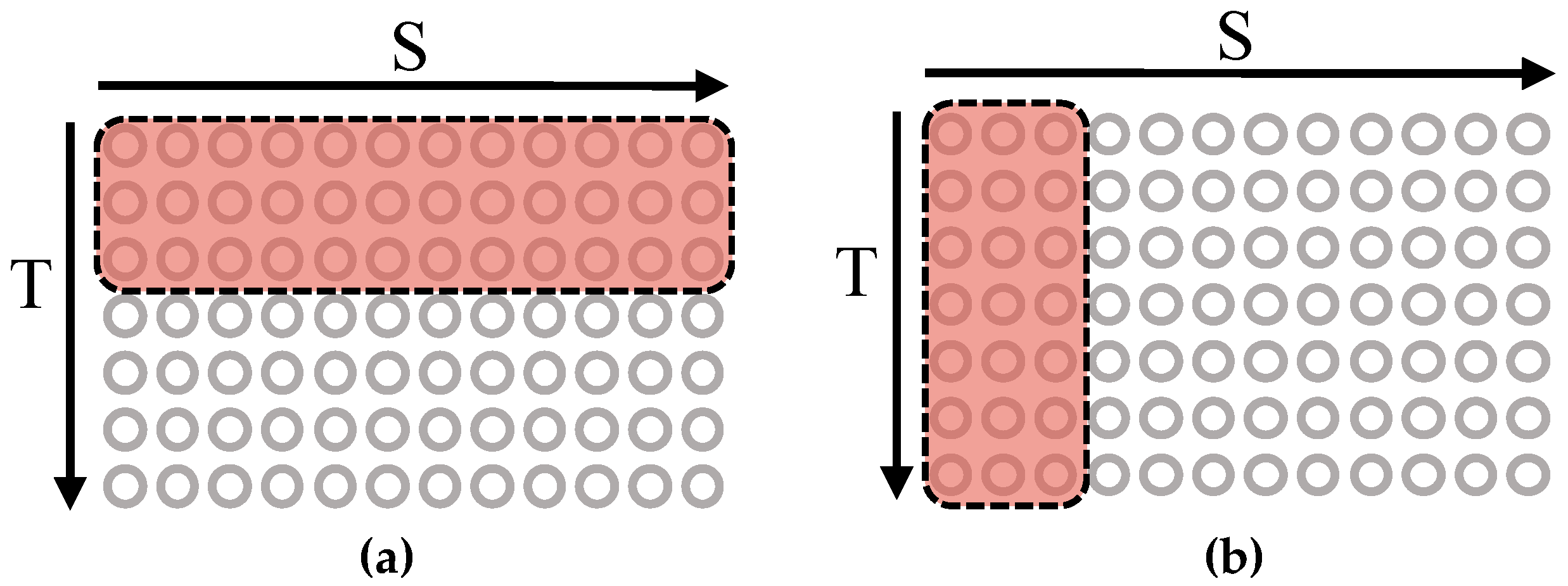
In this paper, we propose a new GNN-based network to recognize group activity in videos. This new network contains two new convolution layers that focus on characterizing the global interactions of group activity efficiently while maintaining reasonable computational requirements. One convolution layer, as shown in
Figure 2a, is designed with a global receptive field in the spatial dimension (S) and a local receptive field in the temporal dimension (T). The second convolutional layer, as shown in
Figure 2b, has a local receptive field in the spatial dimension (S) and a global receptive field in the temporal dimension (T). These two designed convolutional layers allow our new network to use two kinds of global receptive fields in the spatial and temporal dimensions separately to provide an improved ability to capture the spatial–temporal individual interactions from a global perspective. We use these two kinds of convolutional layers in parallel to capture the features of the group activity in a global sense without significantly increasing the computation cost.
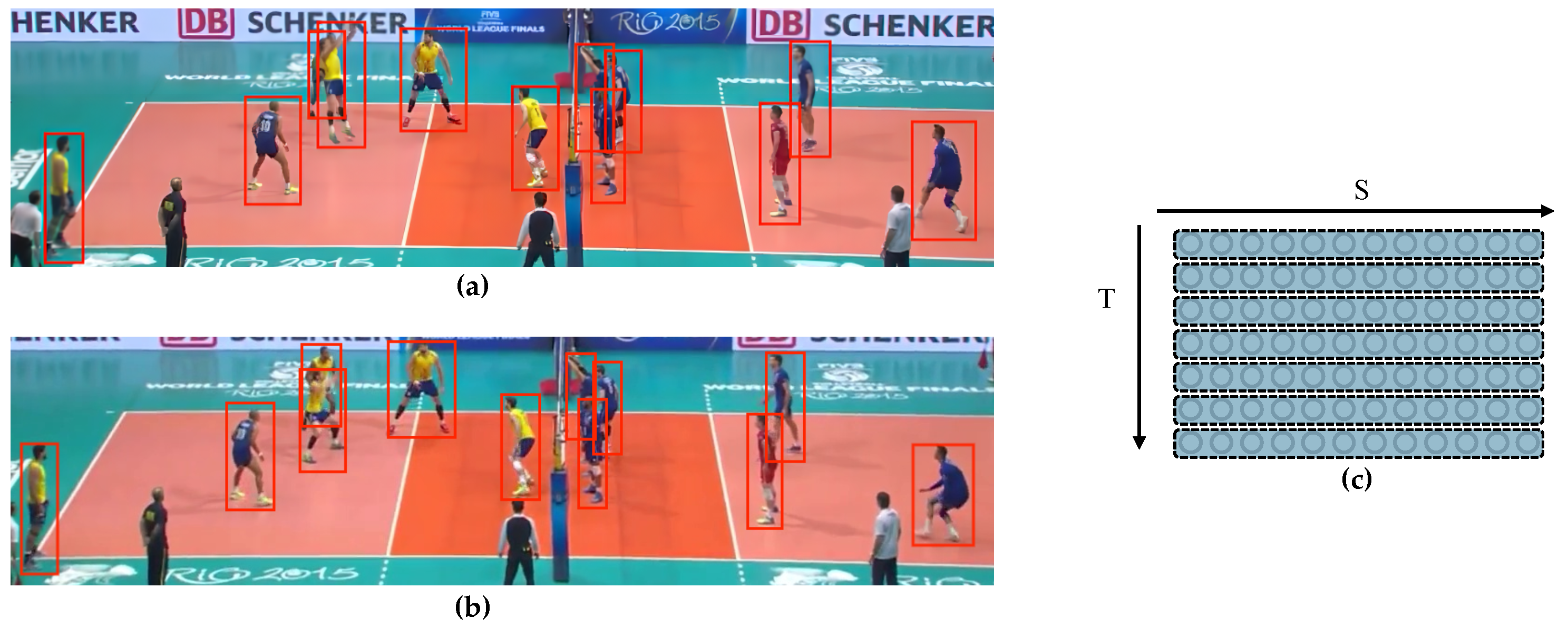
We also introduce constraints to further improve the performance of our network, i.e., global activity consistency and individual action consistency. First, the states of group activity in each frames should be similar to the states in other frames and have similar contribution to the recognition of the group activity. In other words, the features of the states of group activity in each frame in the same event video clip should be similar. The states of the same “set” (or set the ball) group activity in two frames are shown in
Figure 3a,b. Since the states of the group activity in each frame should not change too much over time, the features of the states of group activity in each frame should have similar contributions to the recognition of the group activity. As shown in
Figure 3c, each row or each grayed area represents a feature of the state of group activity in one frame, and all seven grayed areas should have similar features of the states of the group activity. We call this global activity consistency. Second, each individual action in the video clip should have similar contributions to the recognition of the group activity. Two individual actions in the same “set” group activity are shown in
Figure 4a,b. Each corresponding player (each column or grayed area in
Figure 4c) in the same video clip should have similar actions or features of individual actions. We call this individual action consistency. The consistency of individual actions also contributes to the recognition of the group activity.
We use contrastive learning to constrain the semantic contributions from the features of the states of group activity in each frame and the features of each individual action. This unique design of combining two one-dimensional global receptive fields allows our network to obtain global interactions more efficiently.
Our network was evaluated on two widely used datasets, the Volleyball dataset (VD) [
14] and the Collective Activity dataset (CAD) [
15]. Experimental results demonstrate that our network obtained superior classification accuracy with the lowest model complexity compared with the state-of-the-art networks.
Our contributions are summarized as follows:
(1) We propose a new global individual interaction network (GIIN) to model the interactions of all people in a group in the spatial–temporal domain. We design new convolution kernels to characterize the interactions of all people in a group activity from a global perspective.
(2) To avoid heavy computation when modeling global interactions, our proposed convolution kernels have two global receptive fields with one in the spatial dimension and another in the temporal dimension. They are connected in parallel to capture features of the group activity in a global sense without significantly increasing the computation cost.
(3) We employ the technique of contrastive learning to refine the features of the states of group activity in each frame and the features of each individual action.
(4) Experimental results show that the proposed network obtained comparable or better performance in terms of recognition accuracy with the lowest model complexity compared to the state-of-the-art networks.
3. Method
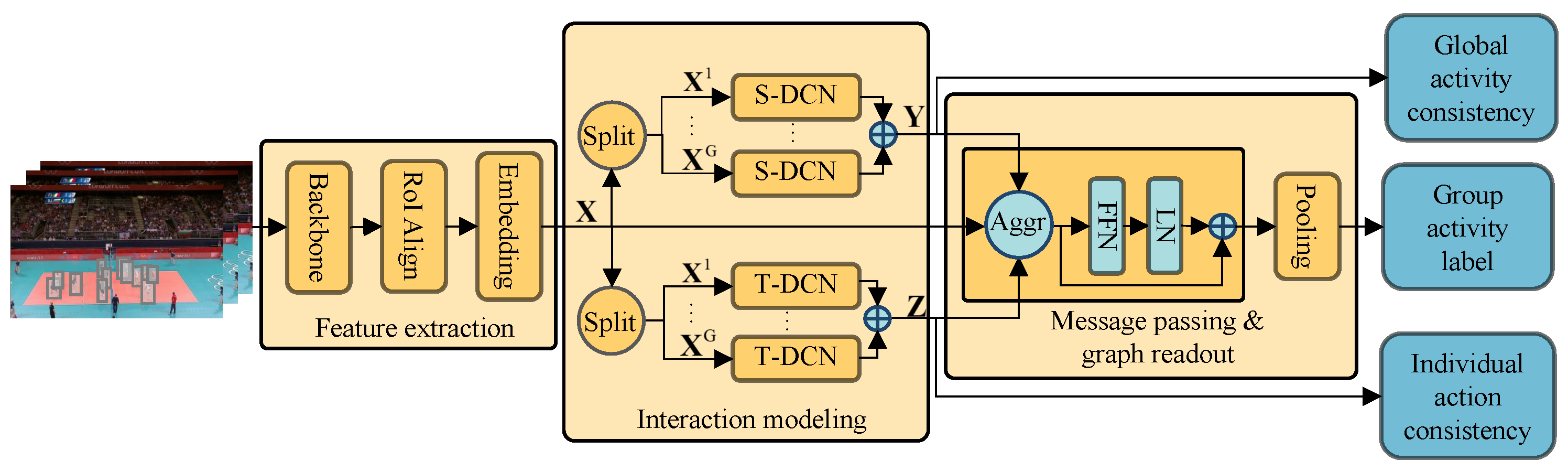
The framework of our proposed global individual interaction network (GIIN) consists of three main modules—the feature extraction module, the interaction modeling module, and the message passing and graph readout module—as shown in
Figure 5.
We use the feature extraction module to extract the features of states of each individual action in each frame in the input video and construct a spatial–temporal feature map with the extracted features. In the interaction modeling module, we arrange the obtained feature map into a spatial–temporal graph and use our proposed convolutional kernels to extract the feature from a global perspective and update the interactions among individuals. We aggregate these features in the message passing and graph readout module and use them for GAR. We learn the global activity consistency and individual action consistency from the above features during training to capture more activity-relevant information.
3.1. Feature Extraction Module
In the feature extraction module as shown in
Figure 5, we use ResNet-18 [
25] as our backbone network to extract the features of each frame from the input video first. We crop the region features of individuals by RoIAlign [
26]. We then reduce the channel dimension of the region features through an embedding layer to obtain the features of the states of each individual action in each frame. Here, we implement the embedding layer with a 1 × 1 convolution layer. To construct a spatial–temporal feature map
for the video, we stack the features of the states of each individual action in one frame from left to right according to the positions of the individuals in the x-axis of the image. We denote
S as the number of people in each frame,
T as the number of frames in the video, and
C as the length of the feature of the state of an individual action in one frame. For frames that have fewer people than
S, we follow the method used in [
9,
12,
13] by replicating the available features of the states of individual actions along the spatial dimension until the entire row has features of the states of
S individual actions. We repeat the same process for each frame in the temporal dimension.
3.2. Interaction Modeling
In this module, we first initialize a directed spatial–temporal graph with the feature map , and then learn the spatial and temporal interactions in the spatial–temporal graph by using our proposed convolutional kernels in the T-DCN and S-DCN branches.
To construct a directed spatial–temporal graph based on the feature map of , we regard each person in each frame as a node and treat the features of the states of each individual action in each frame as the attribute of the node. Thus, the constructed spatial–temporal graph contains nodes, and the size of the attribute of each node is C. The edges of the graph represent the interaction between two people or nodes. For each node, we consider it a target node and initialize the corresponding source nodes according to the index difference in the spatial and temporal terms. We denote the nearest K nodes in the spatial dimension to each target node as its source nodes and the nearest K nodes in the temporal dimension as its source nodes so that each node is connected to source nodes through edges. Thus, the initialized spatial–temporal graph has target nodes with temporal edges and spatial edges.
We use the weight of the edge to denote the importance of interaction between a source node and a target node, and use offset to denote the difference of positions between the updated source node and the initial source node. We learn the weights and offsets of spatial edges with the T-DCN branch and the weights and offsets of temporal edges with the S-DCN branch. Based on the learned offsets, we update the position of each source node by adding the offset to its initial position, and use weights to update the attribute of each node.
The constructed spatial–temporal graph characterizes the interactions among individuals in the group. However, the interactions that exist in a group activity are complicated because each individual (node) is influenced by its neighbors (adjacent nodes) dynamically. Previous methods [
11,
12,
13] attempted to model the interactions among nodes by using mapping layers with local receptive fields in spatial–temporal dimensions and generate the model of individual interactions. Their ability to represent the spatial–temporal interactions is fairly limited because the local receptive fields can hardly capture global interaction patterns.
To overcome the above shortcoming, using a convolutional kernel with a larger receptive field is an intuitive approach, as it is more effective in capturing information unique to different locations. However, it comes with the burden of a larger number of parameters. We split a single 2-dimensional receptive field into two much simpler receptive fields to reduce the number of parameters. Specifically, we propose spatial global receptive field convolutional kernels (SGRF-Conv kernels) and temporal global receptive field convolutional kernels (TGRF-Conv kernels), respectively. The proposed SGRF-Conv kernels have global receptive fields in the spatial dimension and are grouped in the spatial dimension. Similarly, the TGRF-Conv kernels have global receptive fields in the temporal dimension and are grouped in the temporal dimension.
3.2.1. Operations of SGRF-Conv and TGRF-Conv
Suppose the input
is an order 3 tensor with size
.
C,
S and
T denote the length of the channel, and the spatial and temporal dimensions of the input, respectively. The SGRF-Conv kernel is an order 3 tensor with size
, where
C,
S and
K are the length of the channel, the spatial and the temporal dimensions, respectively. Please note that the SGRF-Conv kernel has the same length as the input in the spatial dimension to achieve a global receptive field of the spatial dimension as shown in
Figure 2a. We construct the SGRF-Conv layer with
D kernels of SGRF-Conv. We denote all the SGRF-Conv kernels in the SGRF-Conv layer as
. We use variables
,
,
,
and
to index elements in the kernels and the input.
The SGRF-Conv kernel is grouped in the spatial dimension when performing convolutional operations on the input.
Figure 6a shows the result of the convolution operation between the input and the SGRF-Conv kernel. Since the convolution kernel has the same length as the input in the spatial dimension, it has a global receptive field in the spatial dimension and effectively reduces the number of parameters. We divide an SGRF-Conv kernel into
S groups along the spatial dimension, and each group generates the corresponding output separately.
For simplicity, we set the stride to 1 and the padding to
(we use square brackets to indicate that
is rounded down). The output feature of SGRF-Conv is denoted as
,
. The SGRF-Conv operation can be expressed by Equation (
1):
where
is the element of
indexed by
,
is the element of
indexed by
, and
is the element of
indexed by
.
Similarly, suppose the input
is a three-order tensor in size of
. We design the TGRF-Conv kernel to be a three-order tensor with size
, where
C,
K and
T are the length of the channel, the spatial and the temporal dimensions. The TGRF-Conv kernel has the same length as the input in the temporal dimension to achieve a global receptive field of the temporal dimension as shown in
Figure 6b. We suppose that a TGRF-Conv layer contains
D kernels of TGRF-Conv. We denote all TGRF-Conv kernels in the TGRF-Conv layer as
. We use index variables
,
,
,
and
to pinpoint a specific element in the kernels and the input.
For simplicity, we set the stride to 1 and padding to
. Hence, we have output in
. The TGRF-Conv operation can be expressed by Equation (
2):
where
is the element of
indexed by
,
is the element of
indexed by
,
is the element of
indexed by
.
Considering is equipped with a global receptive field in the spatial dimension and has a global receptive field in the temporal dimension, we use and to characterize the global interactions in the spatial–temporal dimensions. Moreover, we use group convolutions to reduce the number of parameters of our convolution kernels while providing more efficient receptive fields in the spatial–temporal dimensions.
3.2.2. S-DCN and T-DCN
In our method, each branch of S-DCN consists of two parallel SGRF-Conv layers (
Figure 7), which learn the offsets and weights of the temporal edges, respectively. Similarly, each branch of T-DCN uses two TGRF-Conv layers to learn the offsets and weights of the spatial edges, respectively. With the offsets and weights of
K temporal edges and
K spatial edges of each target node, we can update the spatial–temporal graph and aggregate the features of each target node. Since the SGRF-Conv and TGRF-Conv operations have global receptive fields in the spatial dimension and temporal dimension respectively, the branches of S-DCN and T-DCN can characterize global interactions in the spatial–temporal dimensions.
Since each temporal edge has an offset and a weight, each graph corresponds to temporal offsets
and temporal weights
. As is shown in
Figure 7a, to obtain the temporal offset
and temporal weight
and update the relationship in the temporal dimension, we use two SGRF-Conv layers, i.e.,
and
in S-DCN. The elements of
and
can be calculated by Equations (
3) and (
4):
where
, and
K is a hyperparameter and denotes the number of edges for each node in the temporal dimension.
is the element of
indexed by
,
is the element of
indexed by
,
is the element of
indexed by
,
is the element of
indexed by
, and
is the element of
indexed by
. Please note that
and
are used to generate the offsets and weights with the same operation of SGRF-Conv as defined for
(please see Equation (
1)). With the temporal offsets and temporal weights, we can update the temporal relationship and acquire the feature
by Equation (
5):
where
,
is a learnable weight matrix,
is a vector composed of all elements in
with temporal dimension
i and spatial dimension
j, and
is a vector composed of all elements in
with temporal dimension
i and spatial dimension
.
represents the feature of group activity to be aggregated in the temporal dimension and has the global interaction information in the spatial dimension since it is obtained from the SGRF-Conv operation. Since the index of the position must be an integer, while the offsets may be floating points, we follow the DCN presented in [
22] and employ bilinear interpolation to generate the features of the source nodes, i.e.,
where
is a vector composed of all elements in
with temporal dimension
i and spatial dimension
j.
Similarly, to obtain the spatial offsets
and spatial weights
, we use two TGRF-Conv layers, i.e.,
and
in T-DCN as shown in Equations (
7) and (
8):
where
and
.
is the element of
indexed by
,
is the element of
indexed by
,
is the element of
indexed by
,
is the element of
indexed by
, and
is the element of
indexed by
. Then, we can update the spatial relationship and acquire feature
by Equations (
9) and (
10):
where
is a learnable weight matrix different from
in Equation (
5),
is a vector composed of all elements in
with temporal dimension
i and spatial dimension
j,
is a vector composed of all elements in
with temporal dimension
and spatial dimension
j.
is a vector composed of all elements in
with temporal dimension
i and spatial dimension
j, and
represents the feature of group activity to be aggregated in the spatial dimension and has the global interaction information in the temporal dimension since it is obtained from TGRF-Conv operation.
As shown in
Figure 5, to characterize the interactions efficiently, we split
into
G groups along the channel dimension, and denote the
g-th group of
as
,
. Then we initialize the T-DCN and S-DCN branches of
G, respectively, and feed
,
into the
g-th S-DCN and
g-th T-DCN without shared parameters. We denote the output of the
g-th S-DCN as
and the output of the
g-th T-DCN as
. We can acquire the temporal offsets and temporal weights of
by Equations (
3) and (
4). We set the size of the learnable weight matrix in Equation (
5) to
to ensure that the channels of
are the same size as the original channels. Finally, we sum up
,
to acquire
. Similarly, we set the size of the learnable weight matrix in Equation (
10) to
to ensure that the channels of the output
are the same size as the original channels. We sum up
,
to acquire
.
The summary of S-DCN and T-DCN is shown in
Table 1.
3.3. Message Passing and Graph Readout Module
In the message passing and graph readout module, we aggregate
,
and
to update the attributes of each node. Specifically, we use the summation–aggregation to update the features of each target node with
,
and
. We use Equation (
11) to aggregate
and
. Then we use a 2-layer 1×1 convolution in the feed forward network (FFN) to refine the aggregated features
as shown in Equation (
12):
where
is the refined feature. Finally, we perform pooling and linear mapping on
to acquire group activity labels
. We use the cross entropy to calculate classification loss
by Equation (
13):
where
is the ground truth of the group activity.
3.4. Global Activity Consistency and Individual Action Consistency Learning
We use T-DCN branches and S-DCN branches to capture the activity-relevant information more efficiently by maximizing the consistency of the features of the states of group activity in each frame and the consistency of features of individual actions, i.e., the global activity consistency and individual action consistency. We first construct positive and negative sample pairs, and then follow the routine of contrast learning [
27] to constrain the similarity of the constructed sample pairs. Supposing that
and
are feature vectors of two samples, we use Equation (
14) to measure the similarity between them,
where
is a hyperparameter. Specifically, suppose there are
B samples in each mini-batch input into GIIN. We denote the feature samples obtained from the S-DCN branches as
, where
, where
represents the feature of the group activity with global interaction information in the spatial dimension of the
b-th video in the mini-batch. Then, we slice each
,
into
T slices along the temporal dimension, and denote them as
.
represents the features of the states of group activity of the
b-th sample at the
j-th frame. Since
is obtained from SGRF-Conv, it provides global interaction information in the spatial dimension. To maximize the consistency of the features of the states of group activity in each frame, we construct positive and negative sample pairs at the training stage. As shown in
Figure 8a, we consider the features of the states of group activity learned from the same video as positive sample pairs, and the features of the states of group activity learned from different videos in the same mini-batch as the negative sample pairs.
We use Equation (
15) as the loss function for global activity consistency learning. The numerator in Equation (
15) represents the similarity between the features of two states of group activity in a positive sample pair, and the sum term in the denominator indicates the similarity between the features of two states of group activity in the negative sample pairs. To decrease the loss of global activity consistency learning, we want the similarity for positive sample pairs as large as possible and the similarity for negative sample pairs as small as possible:
Similar to the global activity consistency learning, suppose there are
B samples in each mini-batch input into GIIN; we denote the feature samples obtained from the T-DCN branches as
, where
represents the feature of group activity with global interaction information in the temporal dimension of the b-th video in the mini-batch. Then, we slice each
,
in the mini-batch into
S slices along the spatial dimension, and denote them as
.
represents the feature of individual actions of the
b-th sample for the
i-th person. Since
is obtained from TGRF-Conv, it provides global interaction information in the temporal dimension. To maximize the consistency of the features of individual actions, we construct positive and negative sample pairs at the training stage (
Figure 8b). We consider the features of individual actions learned from the same
as positive sample pairs, and the features of individual actions from different videos in the same batch as negative sample pairs. Then, we use Equation (
16) as the loss for individual action consistency:
Finally, we combine all the losses to train our GIIN as shown in Equation (
16):
where
is a hyperparameter. We perform end-to-end training using Equation (
17) to learn effective features with constraints of global activity consistency and individual action consistency.
Our algorithm is shown in Algorithm 1.
![Electronics 12 04104 i001]()















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}