
How Do Background and Remote User Representations Affect Social Telepresence in Remote Collaboration?: A Study with Portal Display, a Head Pose-Responsive Video Teleconferencing System




Abstract
:1. Introduction
- RQ1: How does the type of remote user representation (point cloud streaming vs. graphical rendering) in Portal Display influence overall system usability, social telepresence, and concentration toward the remote user?
- RQ2: How does the type of remote user’s background representation (point cloud streaming vs. graphical rendering) impact overall system usability, social telepresence, and concentration toward the remote user?
- RQ3: Do the types of remote user and background representation (point cloud streaming vs. graphical rendering) interact in impacting the overall usability, social telepresence, and concentration within the Portal Display system?
2. Research Hypotheses
- H1a: Point cloud representations of remote users enhance system usability more than graphical renderings.
- H1b: Point cloud representations of remote users enhance telepresence more than graphical renderings.
- H1c: Point cloud representations of remote users enhance user concentration more than graphical renderings.
- H2a: The influence of background representation (point cloud vs. graphical rendering) on system usability is minimal.
- H2b: The influence of background representation (point cloud vs. graphical rendering) on telepresence is minimal.
- H2c: The influence of background representation (point cloud vs. graphical rendering) on user concentration is minimal.
- H3: The interaction effect of different methods of representing remote users and backgrounds on user experience is negligible.
3. Portal Display
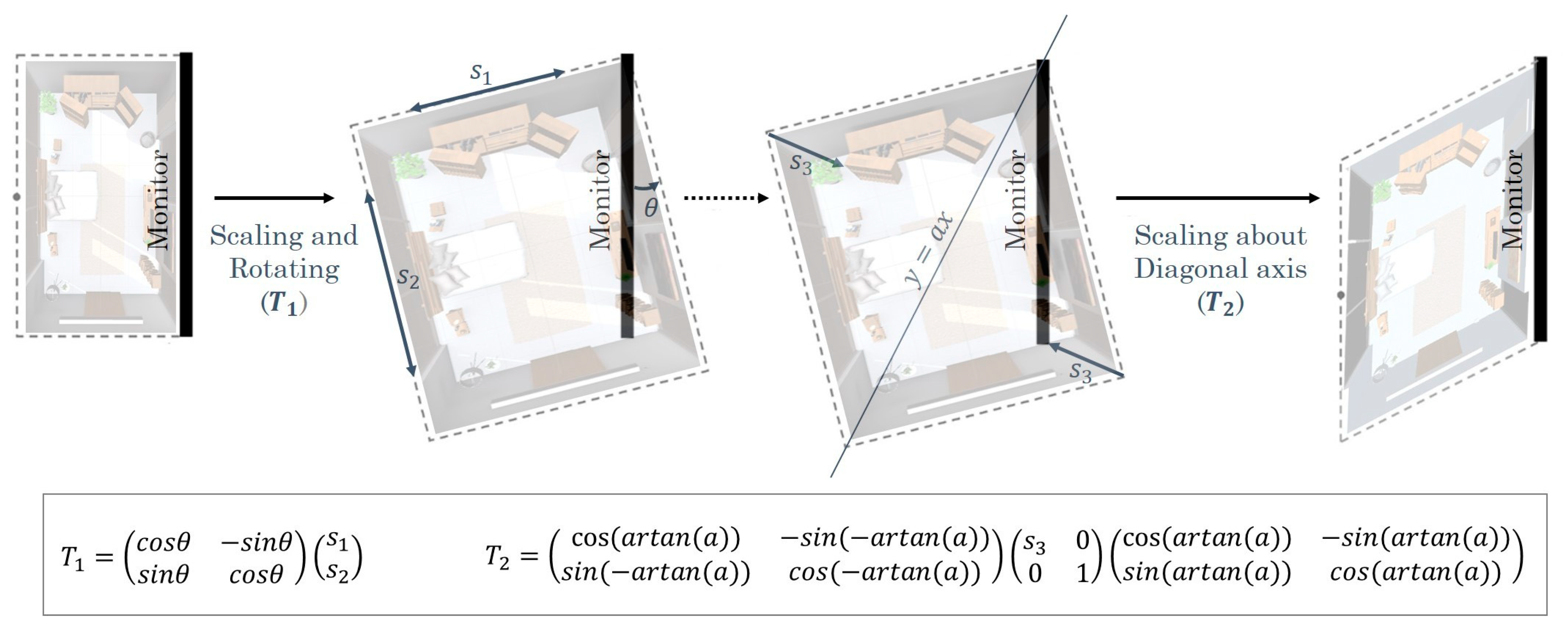
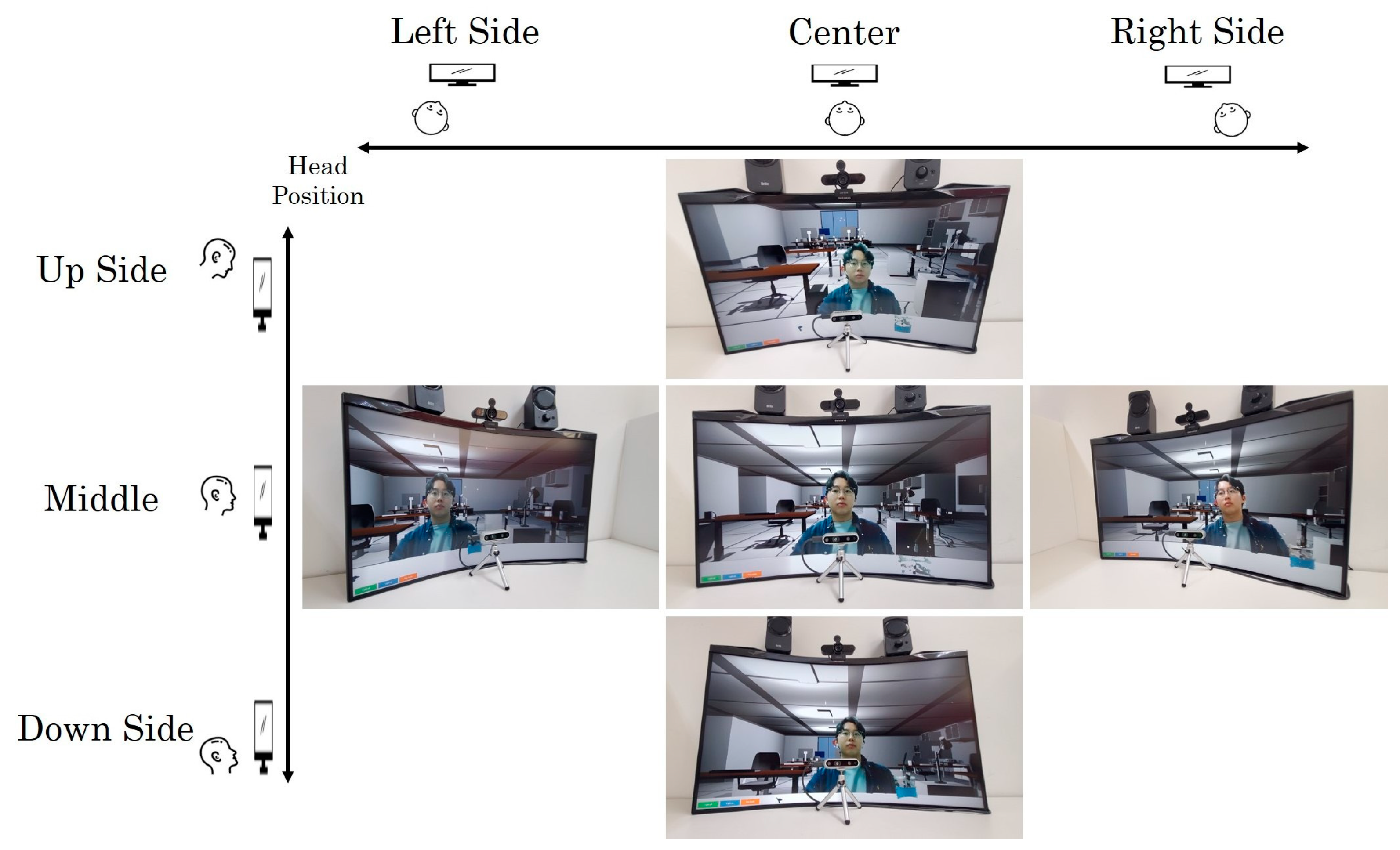
3.1. Stereoscopic Vision with a 2D Screen
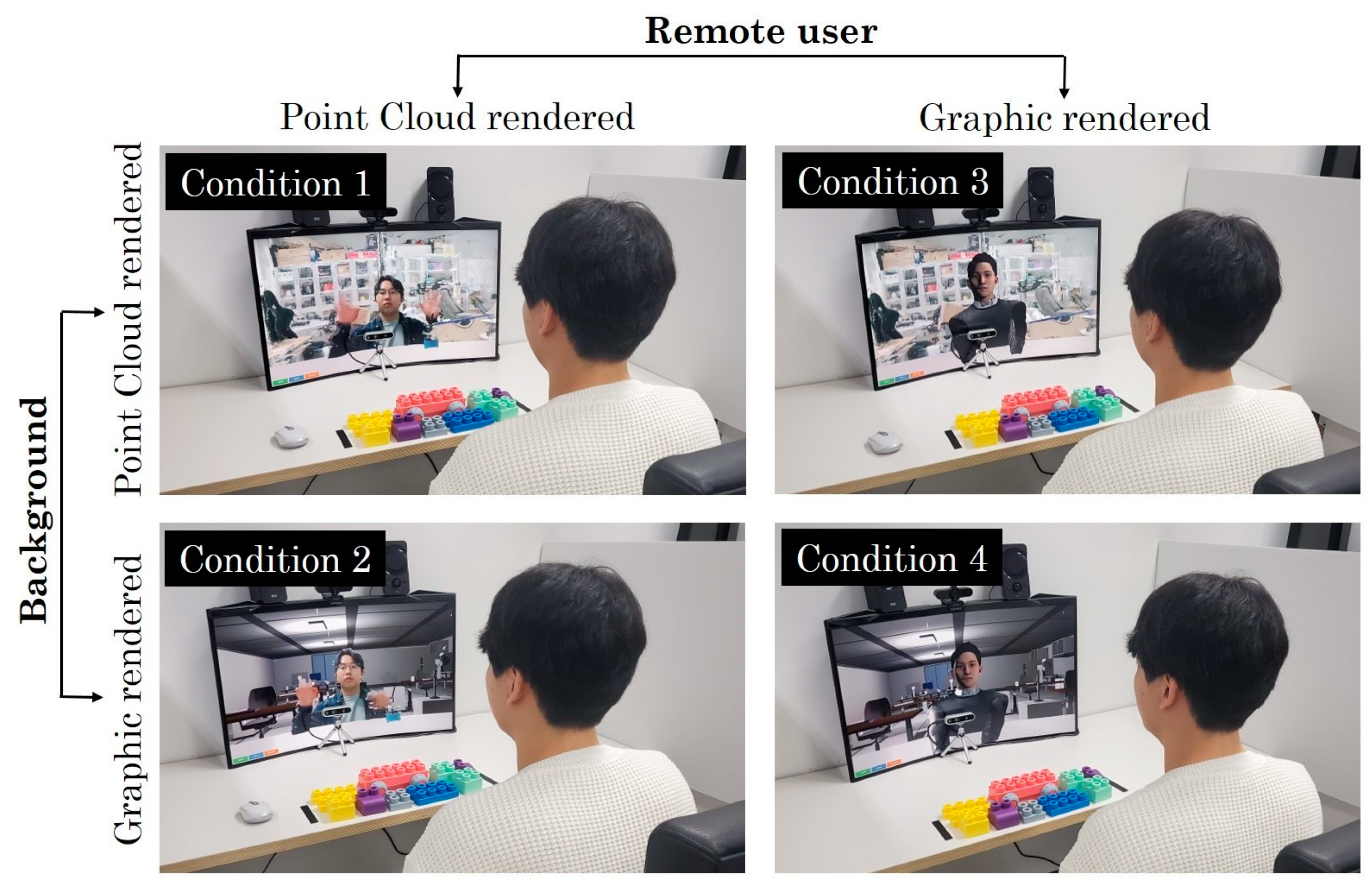
3.2. Representation Types of the Background
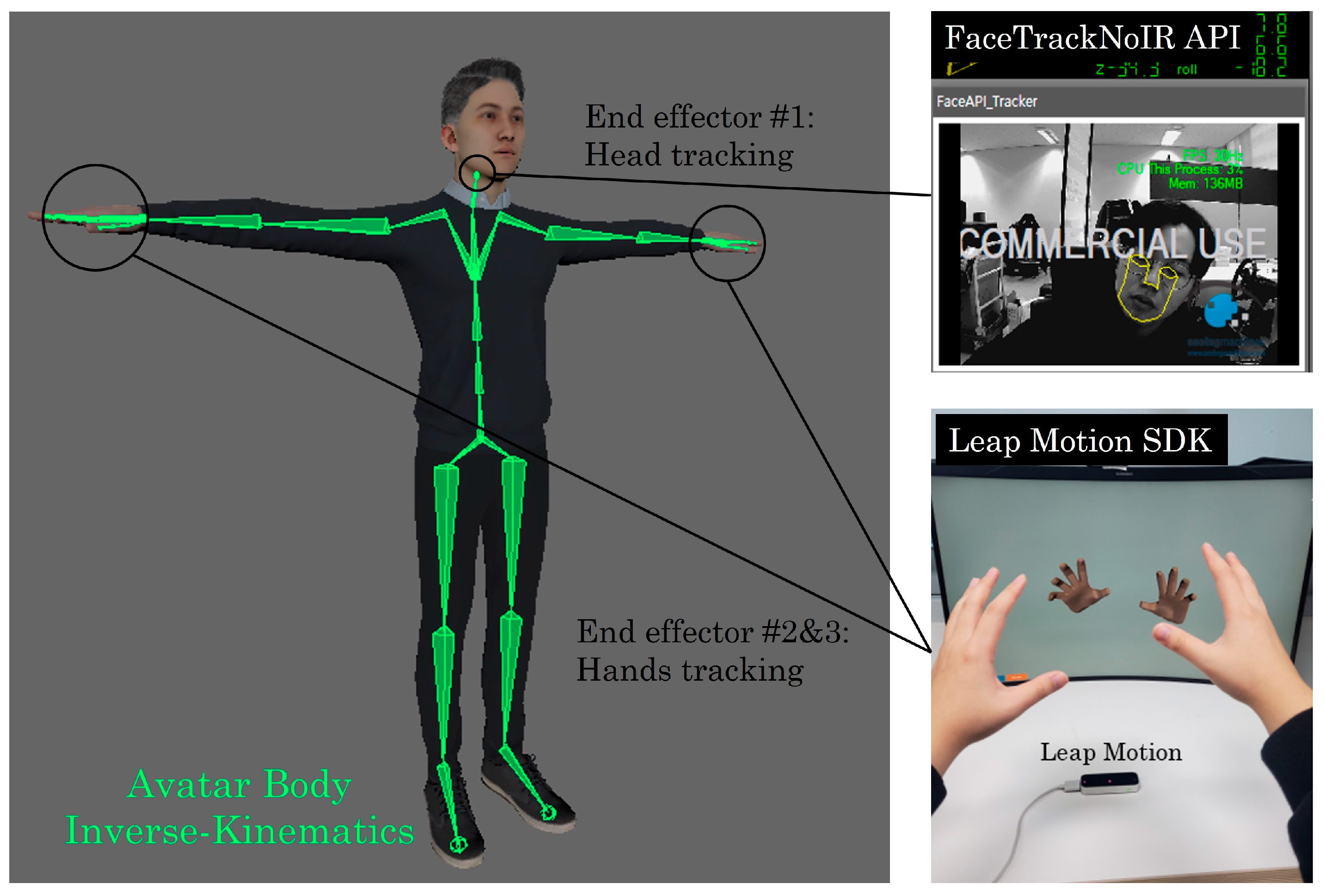
3.3. Representation Types of the Remote User
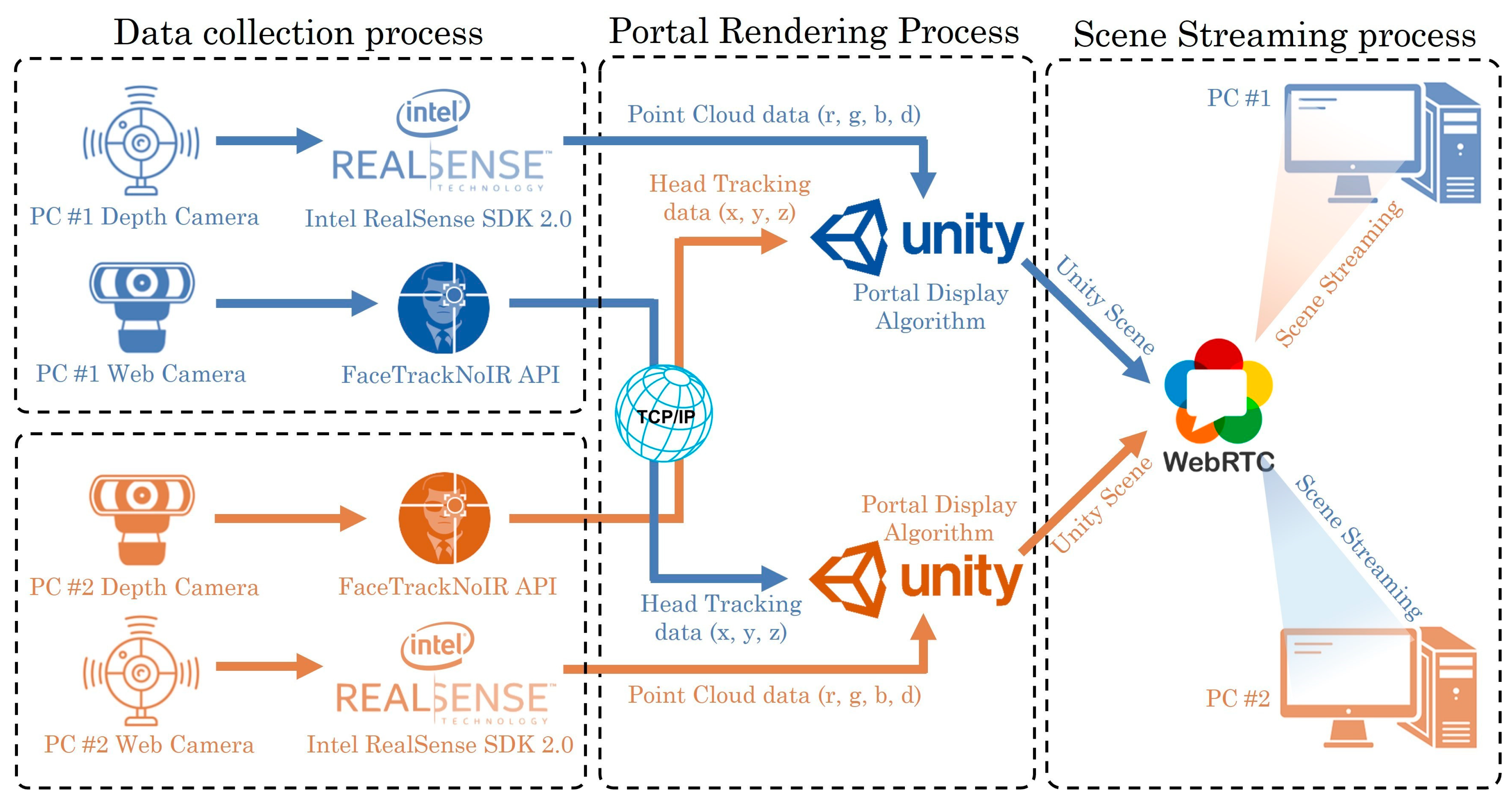
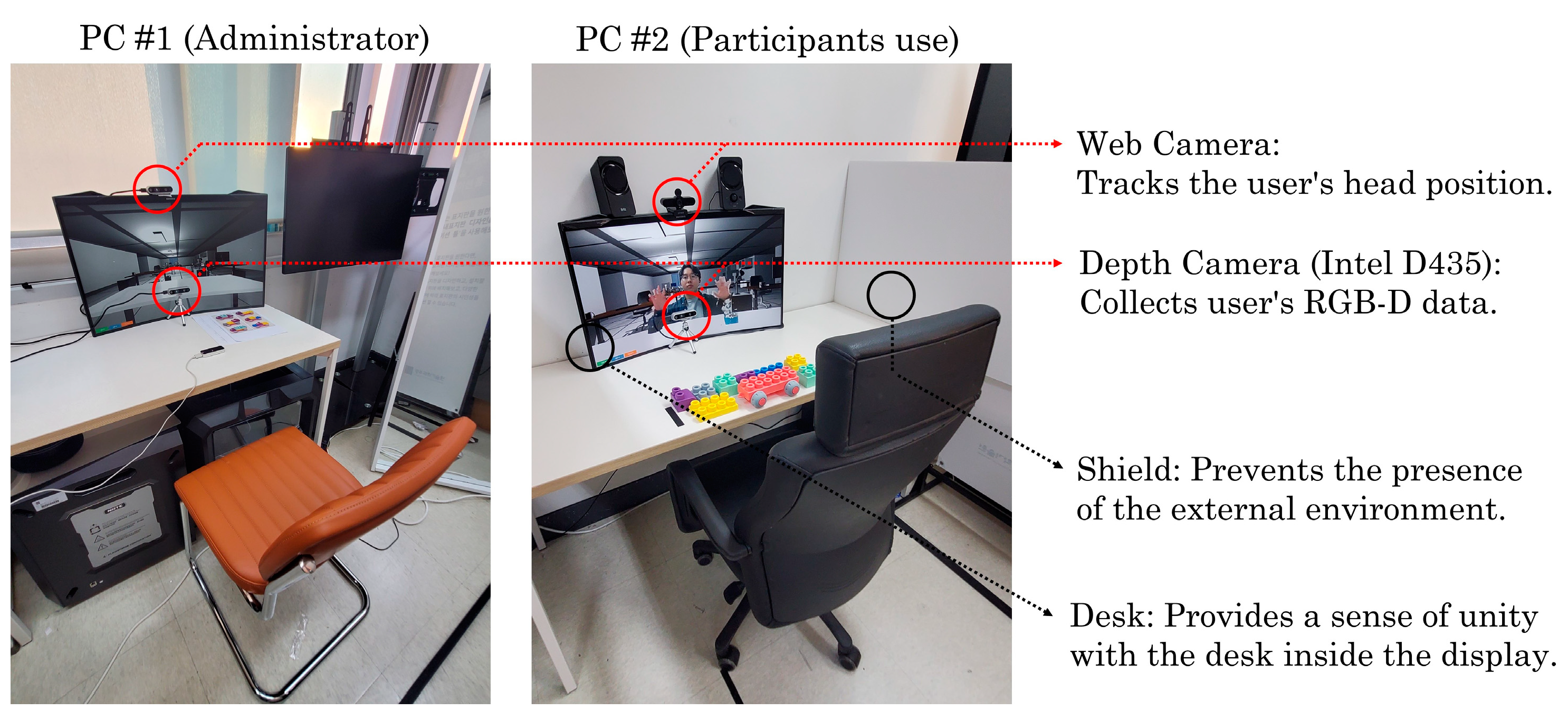
3.4. Networking and Setup between Different PCs
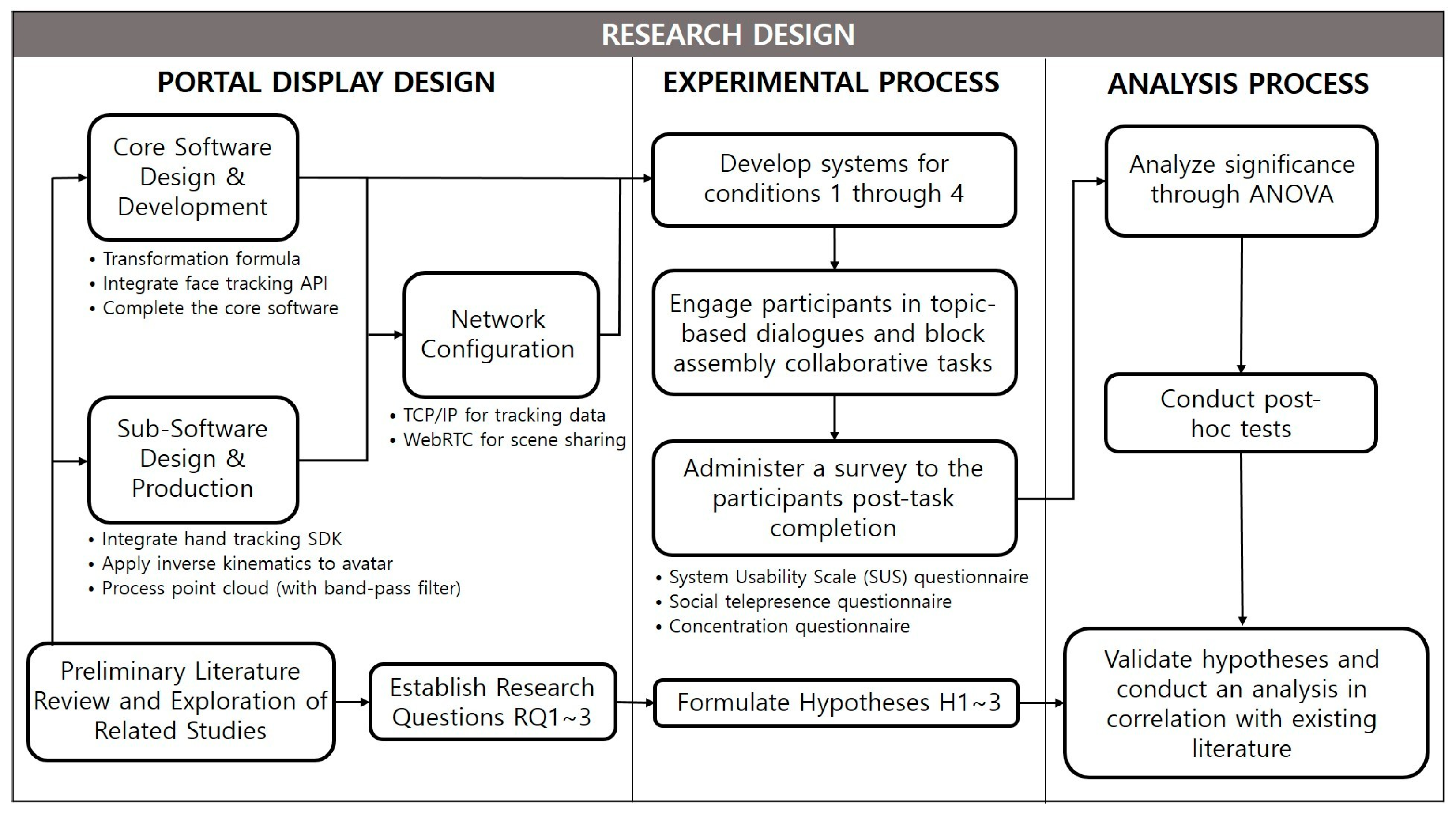
4. Study Procedures
4.1. Task Design
4.2. Analysis Strategy
4.3. Protocol
5. Study Results
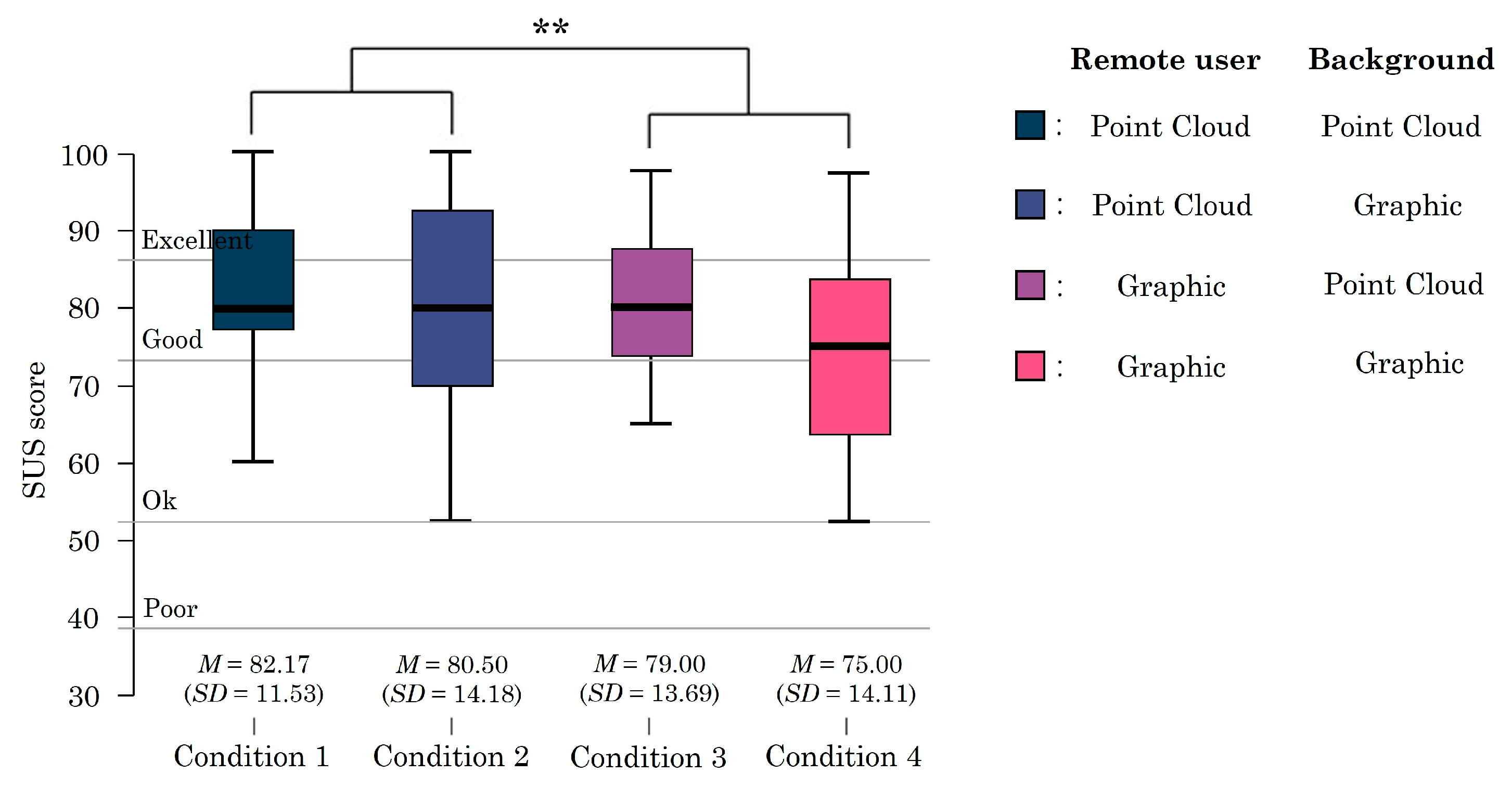
5.1. System Usability Scale (SUS)
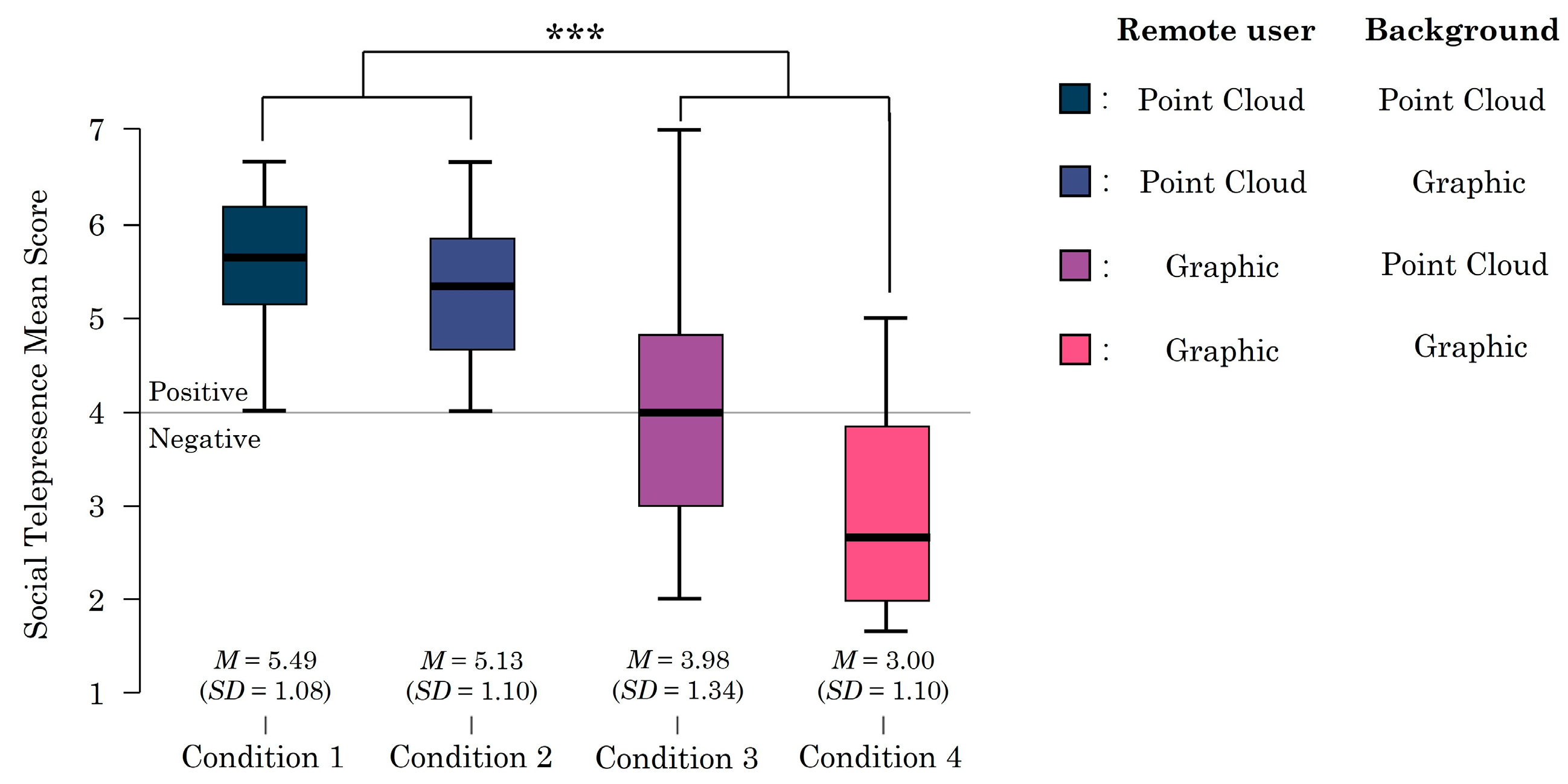
5.2. Social Telepresence
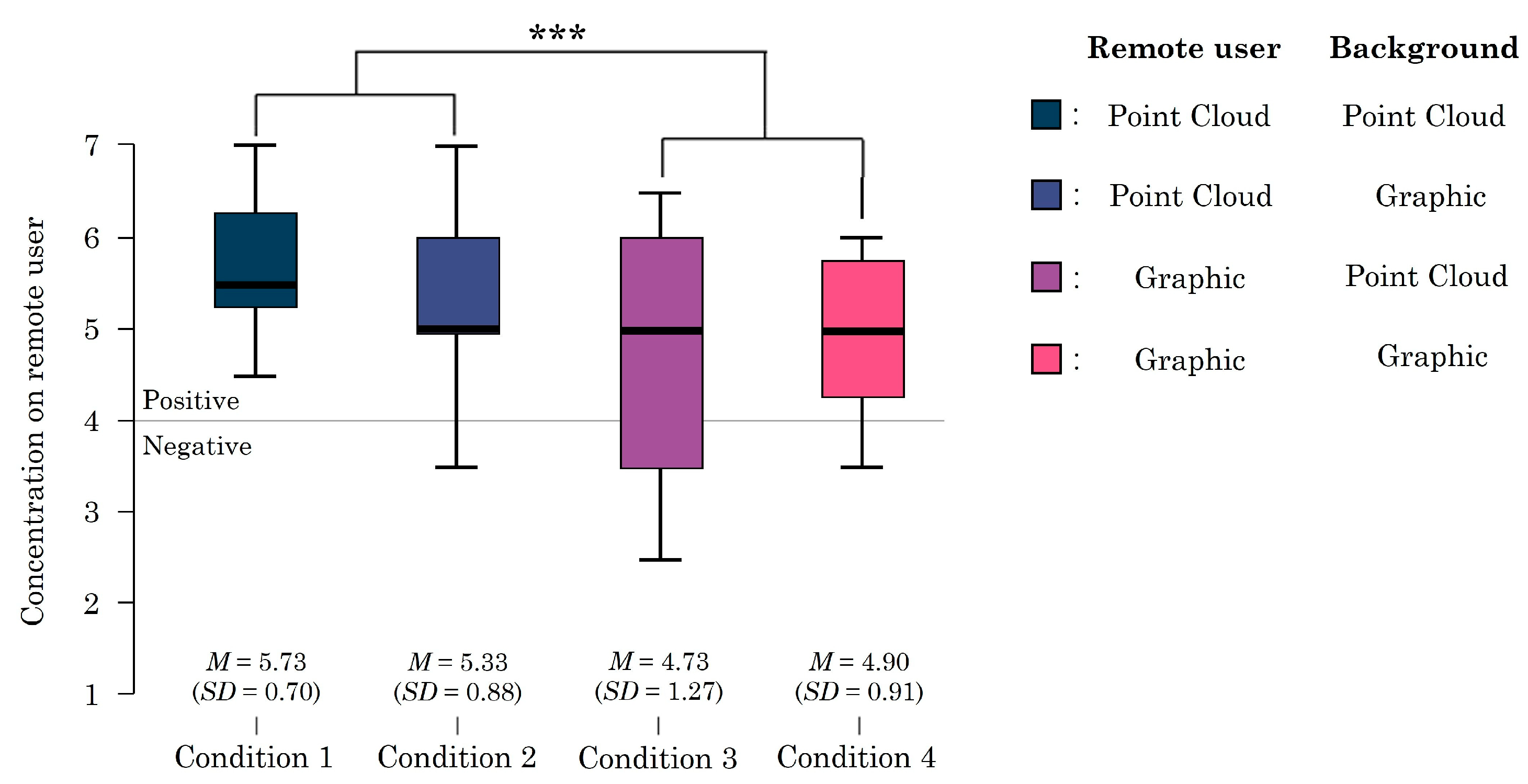
5.3. Concentration on Remote User
6. Discussion
6.1. Proposed Linear Transformation Matrices for Typical 3D Engines and Their Extension to Telepresence Systems
6.2. Streaming Remote Users with Point Clouds Improves Usability, Telepresence, and Concentration
6.3. Comparative Impact of Point Cloud Streaming for Background and Remote Users on Telepresence
6.4. Insignificant Interaction Effects between Background Types and Remote User Representation Types
6.5. Limitations and Future Works
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1

Appendix A.2

References
- Daly-Jones, O.; Monk, A.; Watts, L. Some advantages of video conferencing over high-quality audio conferencing: Fluency and awareness of attentional focus. Int. J. Hum.-Comput. Stud. 1998, 49, 21–58. [Google Scholar] [CrossRef]
- Junuzovic, S.; Inkpen, K.; Tang, J.; Sedlins, M.; Fisher, K. To see or not to see: A study comparing four-way avatar, video, and audio conferencing for work. In Proceedings of the 2012 ACM International Conference on Supporting Group Work, Sanibel Island, FL, USA, 27–31 October 2012; pp. 31–34. [Google Scholar]
- Maloney, D.; Freeman, G.; Wohn, D.Y. “Talking without a Voice” Understanding Non-verbal Communication in Social Virtual Reality. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–25. [Google Scholar] [CrossRef]
- Nguyen, D.; Canny, J. Multiview: Spatially faithful group video conferencing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 799–808. [Google Scholar]
- Adeboye, D. Exploring the Effect of Spatial Faithfulness on Group Decision-Making; Technical Report 952; University of Cambridge, Computer Laboratory: Cambridge, UK, 2020. [Google Scholar]
- Wang, X.; Love, P.E.; Kim, M.J.; Wang, W. Mutual awareness in collaborative design: An Augmented Reality integrated telepresence system. Comput. Ind. 2014, 65, 314–324. [Google Scholar] [CrossRef]
- Kuster, C.; Popa, T.; Bazin, J.-C.; Gotsman, C.; Gross, M. Gaze correction for home video conferencing. ACM Trans. Graph. 2012, 31, 1–6. [Google Scholar] [CrossRef]
- Avrahami, D.; van Everdingen, E.; Marlow, J. Supporting Multitasking in Video Conferencing using Gaze Tracking and On-Screen Activity Detection. In Proceedings of the 21st International Conference on Intelligent User Interfaces, Sonoma, CA, USA, 7–10 March 2016; pp. 130–134. [Google Scholar]
- Neureiter, K.; Murer, M.; Fuchsberger, V.; Tscheligi, M. Hand and eyes: How eye contact is linked to gestures in video conferencing. In Proceedings of the CHI’13 Extended Abstracts on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 127–132. [Google Scholar]
- Nguyen, D.T.; Canny, J. Multiview: Improving trust in group video conferencing through spatial faithfulness. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 28 April–3 May 2007; pp. 1465–1474. [Google Scholar]
- Wang, W.; Wang, X.; Wang, R. A Spatial Faithful Cooperative System Based on Mixed Presence Groupware Model. In Cooperative Design, Visualization, and Engineering, Proceedings of the International Conference on Cooperative Design, Visualization and Engineering, Luxembourg, 20–23 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 269–275. [Google Scholar]
- Gaver, W.W.; Smets, G.; Overbeeke, K. A virtual window on media space. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 7–11 May 1995; pp. 257–264. [Google Scholar]
- Nakanishi, H.; Murakami, Y.; Kato, K. Movable cameras enhance social telepresence in media spaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 433–442. [Google Scholar]
- Mulligan, J.; Zabulis, X.; Kelshikar, N.; Daniilidis, K. Stereo-based environment scanning for immersive telepresence. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 304–320. [Google Scholar] [CrossRef]
- Maimone, A.; Fuchs, H. A first look at a telepresence system with room-sized real-time 3d capture and life-sized tracked display wall. In Proceedings of the ICAT, Osaka, Japan, 28–30 November 2011; pp. 4–9. [Google Scholar]
- Dou, M.; Shi, Y.; Frahm, J.M.; Fuchs, H.; Mauchly, B.; Marathe, M. Room-sized informal telepresence system. In Proceedings of the 2012 IEEE Virtual Reality Workshops (VRW), Costa Mesa, CA, USA, 4–8 March 2012; pp. 15–18. [Google Scholar]
- Desai, K.; Raghuraman, S.; Jin, R.; Prabhakaran, B. QoE studies on interactive 3D tele-immersion. In Proceedings of the 2017 IEEE International Symposium on Multimedia (ISM), Taichung, Taiwan, 11–13 December 2017; pp. 130–137. [Google Scholar]
- Ebrahimi, T.; Alexiou, E.; Fonseca, T.A.; de Queiroz, R.L.; Torlig, E.M. A novel methodology for quality assessment of voxelized point clouds. In Proceedings of the Applications of Digital Image Processing XLI, San Diego, CA, USA, 19–23 August 2018; Volume 10752, pp. 174–190. [Google Scholar]
- Liu, S.; Chou, P.A.; Zhang, C.; Zhang, Z.; Chen, C.W. Virtual view reconstruction using temporal information. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 115–120. [Google Scholar]
- Kauff, P.; Schreer, O. An immersive 3D video-conferencing system using shared virtual team user environments. In Proceedings of the 4th International Conference on Collaborative Virtual Environments, Bonn, Germany, 30 September–2 October 2002; pp. 105–112. [Google Scholar]
- Jo, D.; Kim, K.H.; Kim, G.J. Effects of avatar and background representation forms to co-presence in mixed reality (MR) tele-conference systems. In Proceedings of the SIGGRAPH ASIA 2016 Virtual Reality meets Physical Reality: Modelling and Simulating Virtual Humans and Environments, Macau, China, 5–8 December 2016; pp. 1–4. [Google Scholar]
- Tanger, R.; Kauff, P.; Schreer, O.; Pavy, D.; Louis Dit Picard, S.; Saugis, G. Team collaboration mixing immersive video conferencing with shared virtual 3D objects. In Signals and Communication Technology, Proceedings of the Distributed Cooperative Laboratories: Networking, Instrumentation, and Measurements; Springer: Berlin/Heidelberg, Germany, 2006; pp. 3–10. [Google Scholar]
- Yu, K.; Gorbachev, G.; Eck, U.; Pankratz, F.; Navab, N.; Roth, D. Avatars for Teleconsultation: Effects of Avatar Embodiment Techniques on User Perception in 3D Asymmetric Telepresence. IEEE Trans. Vis. Comput. Graph. 2021, 27, 4129–4139. [Google Scholar] [CrossRef] [PubMed]
- Petkov, E. Generation of Stereo Images in 3D Graphics Applications for Stereoscopic and Nonstereoscopic Displays. In Computer Science and Technologies; University of Varna: Varna, Bulgaria, 2012; p. 47. [Google Scholar]
- Vápeník, R.; Michalko, M.; Janitor, J.; Jakab, F. Secured web oriented videoconferencing system for educational purposes using WebRTC technology. In Proceedings of the 2014 IEEE 12th IEEE International Conference on Emerging eLearning Technologies and Applications (ICETA), Stary Smokovec, Slovakia, 4–5 December 2014; pp. 495–500. [Google Scholar]
- Ryskeldiev, B.; Cohen, M.; Herder, J. StreamSpace: Pervasive Mixed Reality Telepresence for Remote Collaboration on Mobile Devices. J. Inf. Process. 2018, 26, 177–185. [Google Scholar] [CrossRef]
- Wen, W.-C.; Towles, H.; Nyland, L.; Welch, G.; Fuchs, H. Toward a compelling sensation of telepresence: Demonstrating a portal to a distant (static) office. In Proceedings of the Visualization 2000. VIS 2000 (Cat. No. 00CH37145), Salt Lake City, UT, USA, 8–13 October 2000; pp. 327–333. [Google Scholar]
- Tanaka, K.; Nakanishi, H.; Ishiguro, H. Physical embodiment can produce robot operator’s pseudo presence. Front. ICT 2015, 2, 8. [Google Scholar] [CrossRef]
- Zillner, J.; Rhemann, C.; Izadi, S.; Haller, M. 3D-board: A whole-body remote collaborative whiteboard. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; pp. 471–479. [Google Scholar]
- Onishi, Y.; Tanaka, K.; Nakanishi, H. Embodiment of video-mediated communication enhances social telepresence. In Proceedings of the Fourth International Conference on Human Agent Interaction, Singapore, 4–7 October 2016; pp. 171–178. [Google Scholar]
- Kim, K.; Bolton, J.; Girouard, A.; Cooperstock, J.; Vertegaal, R. Telehuman: Effects of 3d perspective on gaze and pose estimation with a life-size cylindrical telepresence pod. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 2531–2540. [Google Scholar]
- Nakanishi, H.; Murakami, Y.; Nogami, D.; Ishiguro, H. Minimum movement matters: Impact of robot-mounted cameras on social telepresence. In Proceedings of the 2008 ACM Conference on Computer Supported Cooperative Work, San Diego, CA, USA, 8–12 November 2008; pp. 303–312. [Google Scholar]
- Brooke, J. SUS: A retrospective. J. Usability Stud. 2013, 8, 29–40. [Google Scholar]
- Lee, J.C. Hacking the Nintendo Wii Remote. IEEE Pervasive Comput. 2008, 7, 39–45. [Google Scholar] [CrossRef]
- Cruz-Neira, C.; Sandin, D.J.; DeFanti, T.A.; Kenyon, R.V.; Hart, J.C. The CAVE: Audio visual experience automatic virtual environment. Commun. ACM 1992, 35, 64–72. [Google Scholar] [CrossRef]
- Manjrekar, S.; Sandilya, S.; Bhosale, D.; Kanchi, S.; Pitkar, A.; Gondhalekar, M. CAVE: An emerging immersive technology–a review. In Proceedings of the 2014 UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, Cambridge, UK, 26–28 March 2014; pp. 131–136. [Google Scholar]
- Cruz-Neira, C.; Sandin, D.J.; DeFanti, T.A. Surround-screen projection-based virtual reality: The design and implementation of the CAVE. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 51–58. [Google Scholar]
- Lawrence, J.; Goldman, D.B.; Achar, S.; Blascovich, G.M.; Desloge, J.G.; Fortes, T.; Gomez, E.M.; Häberling, S.; Hoppe, H.; Huibers, A.; et al. Project Starline: A high-fidelity telepresence system. ACM Trans. Graph. 2021, 40, 242. [Google Scholar] [CrossRef]
- Caviedes, J.E.; Wu, S.L. Combining computer vision and video processing to achieve immersive mobile videoconferencing. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 2467–2471. [Google Scholar]
- Nowak, K.L.; Biocca, F. The effect of the agency and anthropomorphism on users’ sense of telepresence, copresence, and social presence in virtual environments. Presence Teleoper. Virtual Environ. 2003, 12, 481–494. [Google Scholar] [CrossRef]
- Zinchenko, Y.P.; Kovalev, A.I.; Menshikova, G.; Shaigerova, L.A. Postnonclassical methodology and application of virtual reality technologies in social research. Psychol. Russ. State Art 2015, 8, 60–71. [Google Scholar] [CrossRef]
- Kang, S.; Yoon, B.; Kim, B.; Woo, W. Effects of Avatar Face Level of Detail Control on Social Presence in Augmented Reality Remote Collaboration. In Proceedings of the 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Singapore, 17–21 October 2022; pp. 763–767. [Google Scholar]
- Zhang, J.; Huang, W.; Zhu, X.; Hwang, J.N. A subjective quality evaluation for 3D point cloud models. In Proceedings of the 2014 International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2014; pp. 827–831. [Google Scholar]
- Jo, D.; Kim, K.H.; Kim, G.J. Effects of avatar and background types on users’ co-presence and trust for mixed reality-based teleconference systems. In Proceedings of the 30th Conference on Computer Animation and Social Agents, Seoul, Republic of Korea, 22–24 May 2017; pp. 27–36. [Google Scholar]
- Lee, M.; Park, W.; Lee, S.; Lee, S. Distracting moments in videoconferencing: A look back at the pandemic period. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022; pp. 1–21. [Google Scholar]
- Subramanyam, S.; Viola, I.; Hanjalic, A.; Cesar, P. User centered adaptive streaming of dynamic point clouds with low complexity tiling. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3669–3677. [Google Scholar]
- Wang, Z.R.; Yang, C.G.; Dai, S.L. A Fast Compression Framework Based on 3D Point Cloud Data for Telepresence. Int. J. Autom. Comput. 2020, 17, 855–866. [Google Scholar] [CrossRef]
- Van Holland, L.; Stotko, P.; Krumpen, S.; Klein, R.; Weinmann, M. Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments. arXiv 2022, arXiv:2211.14310. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Sum of Squares | df | Mean Square | F | p |
|---|---|---|---|---|---|
| Remote user | 555.104 | 1 | 555.104 | 11.109 | 0.005 ** |
| Residuals | 699.583 | 14 | 49.970 | ||
| Background | 12.604 | 1 | 12.604 | 0.286 | 0.601 |
| Residuals | 617.083 | 14 | 44.077 | ||
| Remote user × Background | 37.604 | 1 | 37.604 | 0.508 | 0.488 |
| Residuals | 1035.833 | 14 | 73.988 |
| Mean Difference | SE | t | pbon f | ||
|---|---|---|---|---|---|
| PCD remote user, PCD background | Graphic remote user, PCD background | 4.500 | 2.875 | 1.565 | 0.775 |
| PCD remote user, Graphic background | −0.667 | 2.806 | −0.238 | 1.000 | |
| Graphic remote user, Graphic background | 7.000 | 2.504 | 2.796 | 0.056 | |
| Graphic remote user, PCD background | PCD remote user, Graphic background | −5.167 | 2.504 | −2.063 | 0.291 |
| Graphic remote user, Graphic background | 2.500 | 2.806 | 0.891 | 1.000 | |
| PCD remote user, Graphic background | Graphic remote user, Graphic background | 7.667 | 2.875 | 2.667 | 0.077 |
| Case | Sum of Squares | df | Mean Square | F | p |
|---|---|---|---|---|---|
| Remote user | 49.807 | 1 | 49.807 | 25.696 | <0.001 *** |
| Residuals | 27.137 | 14 | 1.938 | ||
| Background | 6.667 | 1 | 6.667 | 12.263 | 0.004 ** |
| Residuals | 7.611 | 14 | 0.544 | ||
| Remote user × Background | 1.452 | 1 | 1.452 | 3.940 | 0.067 |
| Residuals | 5.159 | 14 | 0.369 |
| Mean Difference | SE | t | pbon f | ||
|---|---|---|---|---|---|
| PCD remote user, PCD background | Graphic remote user, PCD background | 1.511 | 0.392 | 3.853 | 0.006 ** |
| PCD remote user, Graphic background | 0.356 | 0.247 | 1.442 | 0.965 | |
| Graphic remote user, Graphic background | 2.489 | 0.407 | 6.119 | <0.001 *** | |
| Graphic remote user, PCD background | PCD remote user, Graphic background | −1.156 | 0.407 | −2.841 | 0.058 |
| Graphic remote user, Graphic background | 0.978 | 0.247 | 3.965 | 0.003 ** | |
| PCD remote user, Graphic background | Graphic remote user, Graphic background | 2.133 | 0.392 | 5.440 | <0.001 *** |
| Case | Sum of Squares | df | Mean Square | F | p |
|---|---|---|---|---|---|
| Remote user | 7.704 | 1 | 7.704 | 23.405 | <0.001 *** |
| Residuals | 4.608 | 14 | 0.329 | ||
| Background | 0.204 | 1 | 0.204 | 0.227 | 0.641 |
| Residuals | 12.608 | 14 | 0.901 | ||
| Remote user × Background | 1.204 | 1 | 1.204 | 1.364 | 0.262 |
| Residuals | 12.358 | 14 | 0.883 |
| Mean Difference | SE | t | pbon f | ||
|---|---|---|---|---|---|
| PCD remote user, PCD background | Graphic remote user, PCD background | 1.00 | 0.284 | 3.518 | 0.011 ** |
| PCD remote user, Graphic background | 0.400 | 0.345 | 1.160 | 1.000 | |
| Graphic remote user, Graphic background | 0.833 | 0.286 | 2.910 | 0.047 ** | |
| Graphic remote user, PCD background | PCD remote user, Graphic background | −0.600 | 0.286 | −2.095 | 0.284 |
| Graphic remote user, Graphic background | −0.167 | 0.345 | −0.483 | 1.000 | |
| PCD remote user, Graphic background | Graphic remote user, Graphic background | 0.433 | 0.284 | 1.5250 | 0.845 |
| Hypothesis | Status |
|---|---|
| H1a: Point cloud representations of remote users enhance system usability more than graphical renderings. | Confirmed |
| H1b: Point cloud representations of remote users enhance telepresence more than graphical renderings. | Confirmed |
| H1c: Point cloud representations of remote users enhance user concentration more than graphical renderings. | Confirmed |
| H2a: The influence of background representation (point cloud vs. graphical rendering) on system usability is minimal. | Confirmed |
| H2b: The influence of background representation (point cloud vs. graphical rendering) on telepresence is minimal. | Rejected |
| H2c: The influence of background representation (point cloud vs. graphical rendering) on user concentration is minimal. | Confirmed |
| H3: The interaction effect of different methods of representing remote users and backgrounds on user experience is negligible. | Confirmed |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, S.; Kim, G.; Lee, K.-T.; Kim, S. How Do Background and Remote User Representations Affect Social Telepresence in Remote Collaboration?: A Study with Portal Display, a Head Pose-Responsive Video Teleconferencing System. Electronics 2023, 12, 4339. https://doi.org/10.3390/electronics12204339
Kang S, Kim G, Lee K-T, Kim S. How Do Background and Remote User Representations Affect Social Telepresence in Remote Collaboration?: A Study with Portal Display, a Head Pose-Responsive Video Teleconferencing System. Electronics. 2023; 12(20):4339. https://doi.org/10.3390/electronics12204339
Chicago/Turabian StyleKang, Seongjun, Gwangbin Kim, Kyung-Taek Lee, and SeungJun Kim. 2023. "How Do Background and Remote User Representations Affect Social Telepresence in Remote Collaboration?: A Study with Portal Display, a Head Pose-Responsive Video Teleconferencing System" Electronics 12, no. 20: 4339. https://doi.org/10.3390/electronics12204339
APA StyleKang, S., Kim, G., Lee, K. -T., & Kim, S. (2023). How Do Background and Remote User Representations Affect Social Telepresence in Remote Collaboration?: A Study with Portal Display, a Head Pose-Responsive Video Teleconferencing System. Electronics, 12(20), 4339. https://doi.org/10.3390/electronics12204339