


Multidimensional Domain Knowledge Framework for Poet Profiling

Abstract
:1. Introduction
- (1)
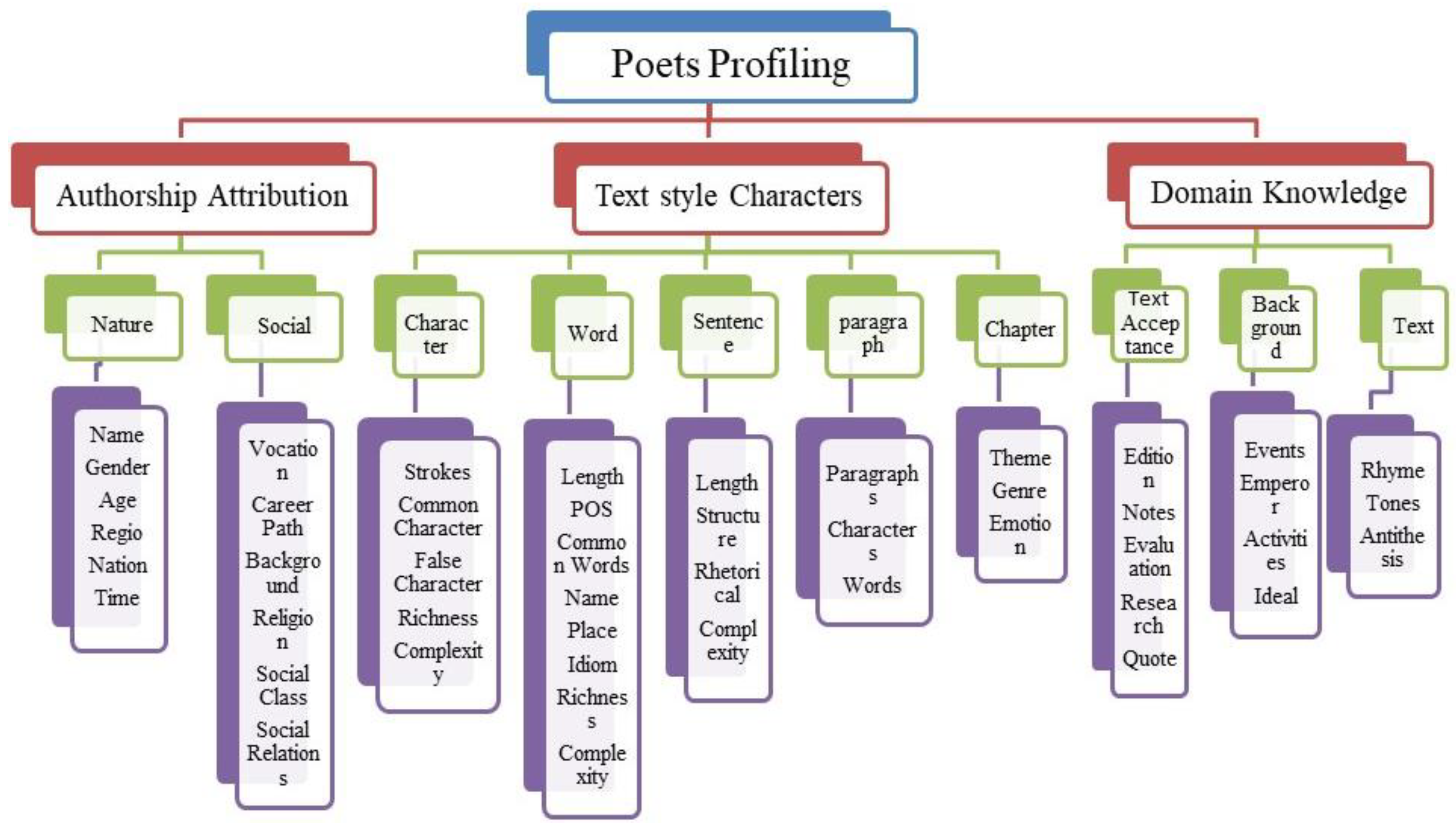
- A novel poetry authorship profiling framework named multidimensional domain knowledge poet profiling (M-DKPP) is proposed, which combines the knowledge of authorship attribution and the text’s stylistic features with domain knowledge described by experts in traditional poetry studies.
- (2)
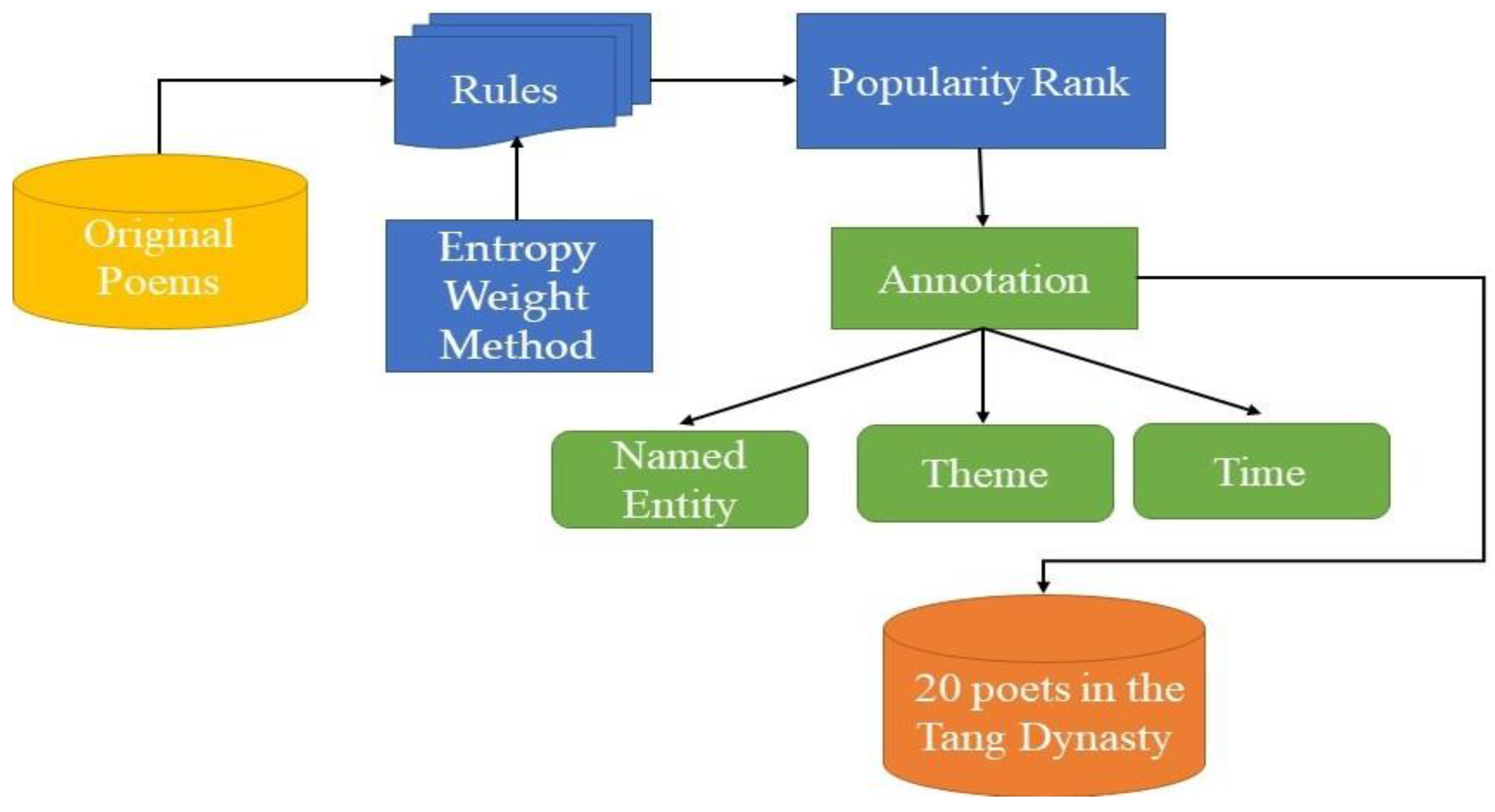
- We proposed an evaluation system to rank poet popularity and a public corpus called 20 Poets in the Tang Dynasty is established for authorship profiling.
- (3)
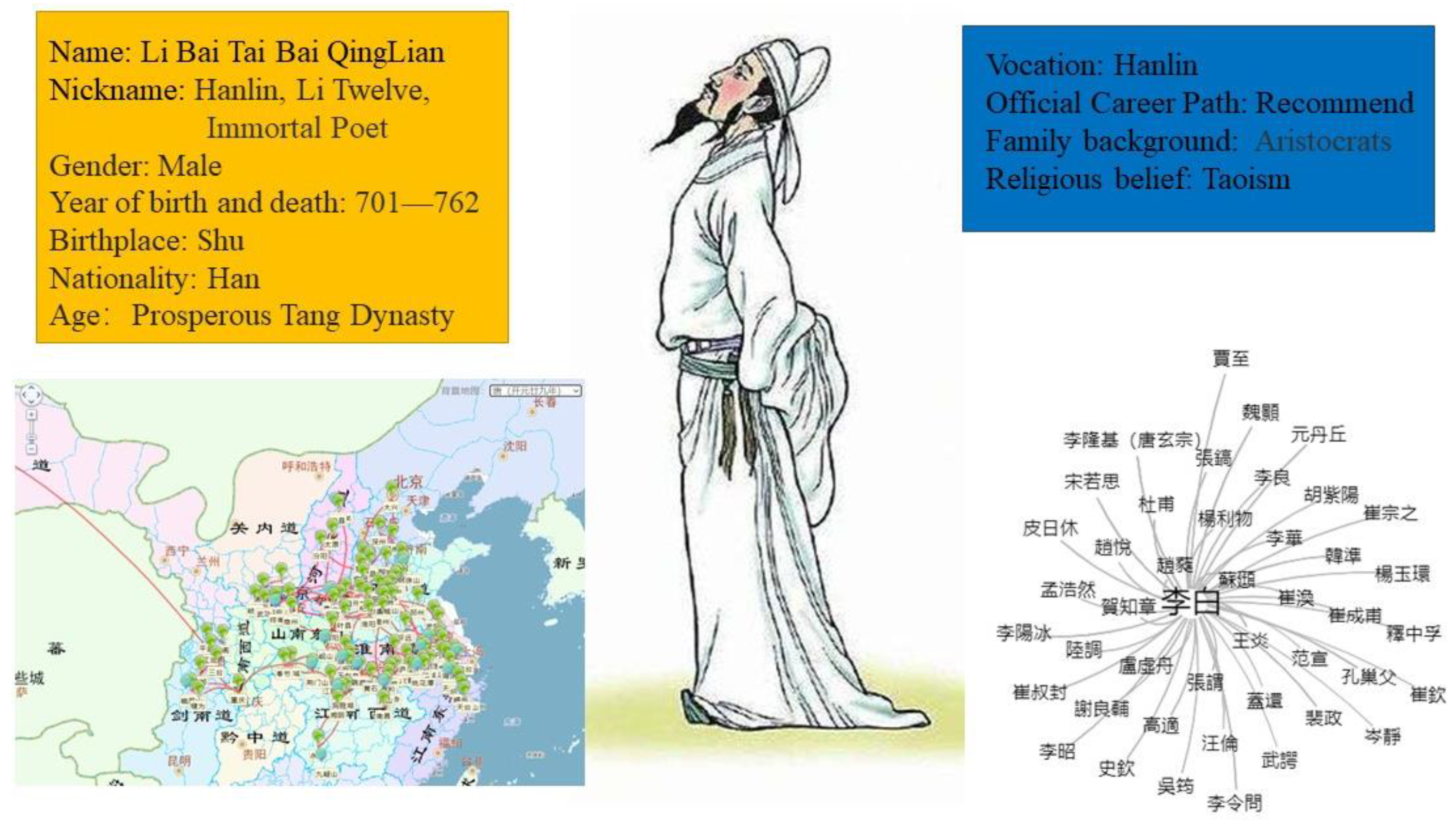
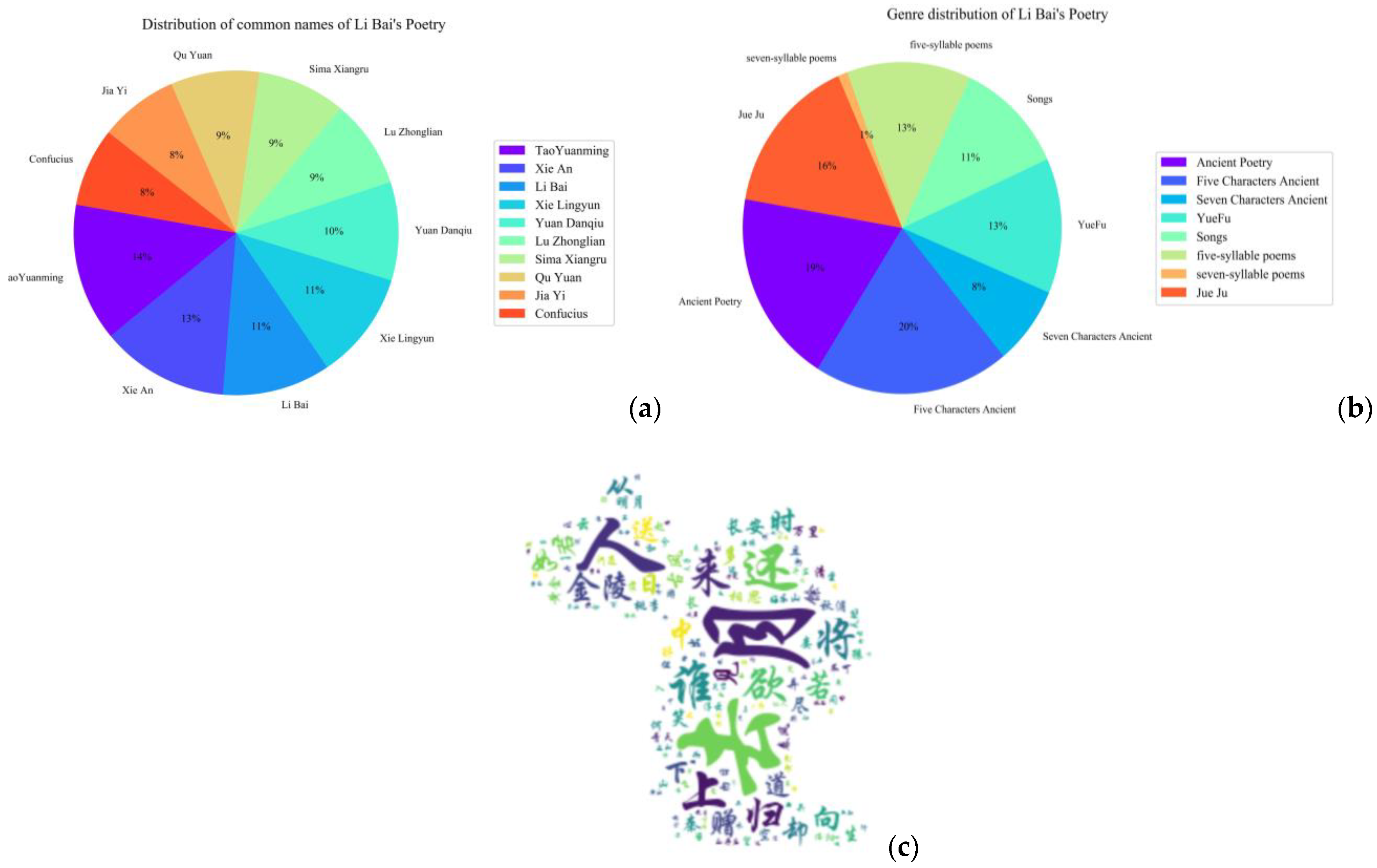
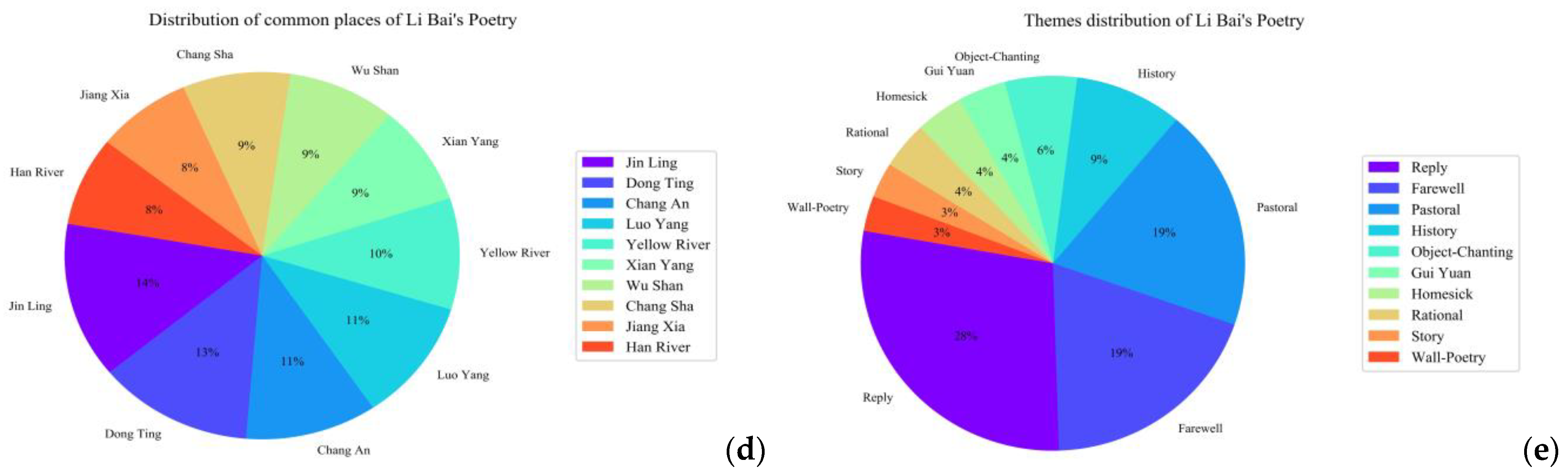
- A case study for Li Bai (李白) is used to verify the validity and applicability of the M-DKPP framework.
- (4)
- Different combination levels are tested in the process of designing the M-DKPP framework, and the results illustrate that the proposed model of our framework is effective.
2. Related Works
2.1. Research in Traditional Humanities
2.2. Research in Digital Humanities
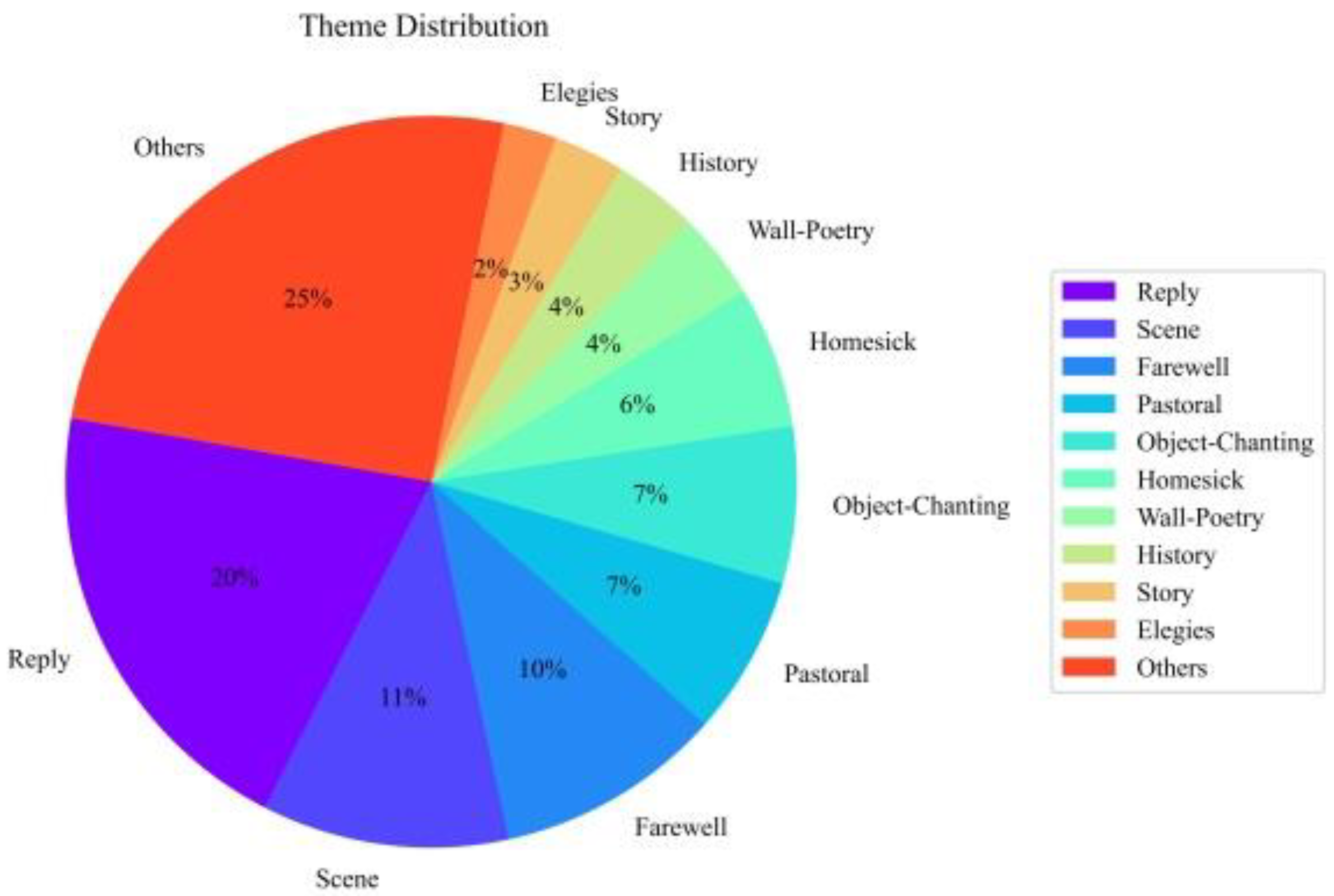
3. Corpus
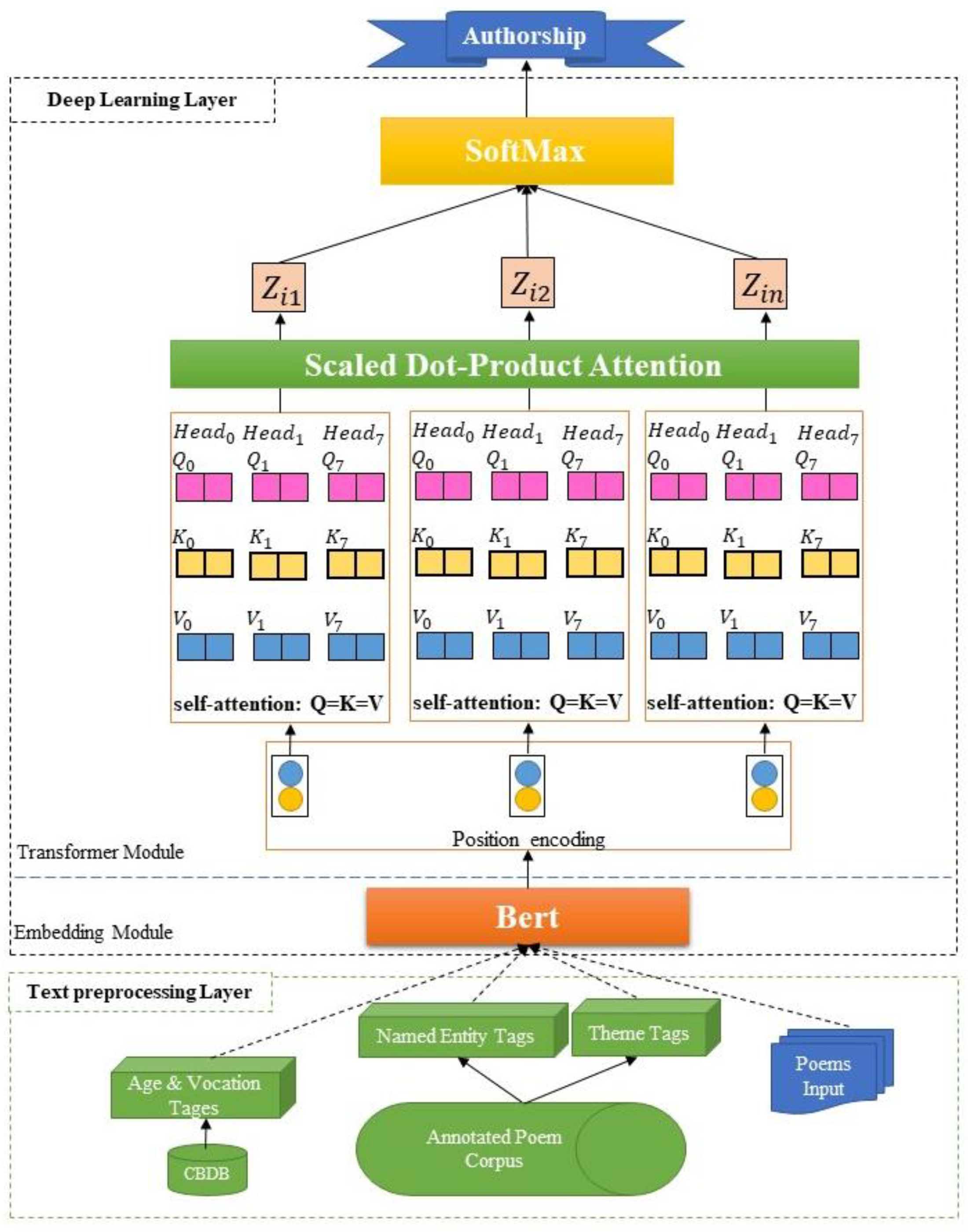
4. M-DKPP Framework Design
4.1. Authorship Attribution Component
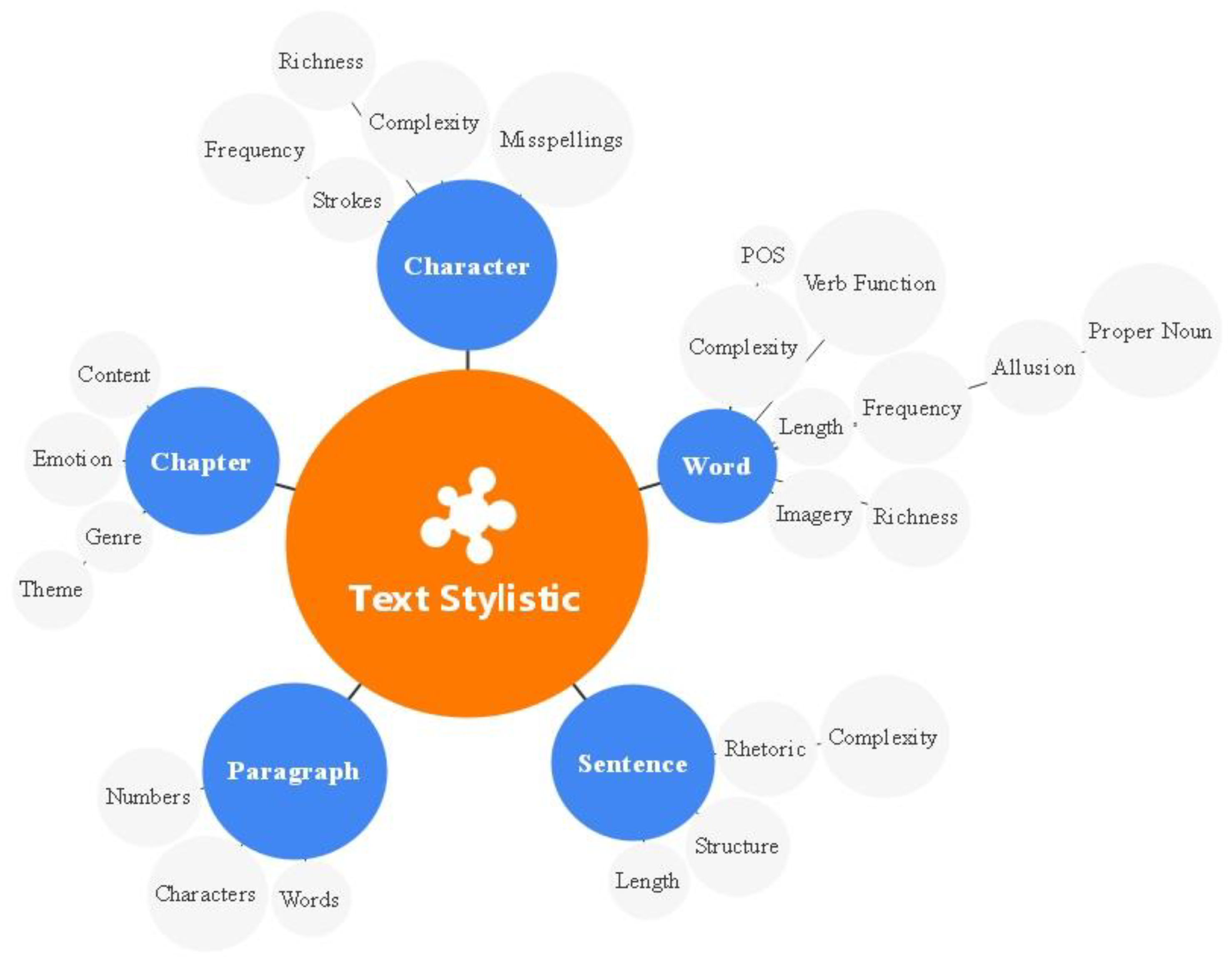
4.2. Stylistic Text Component
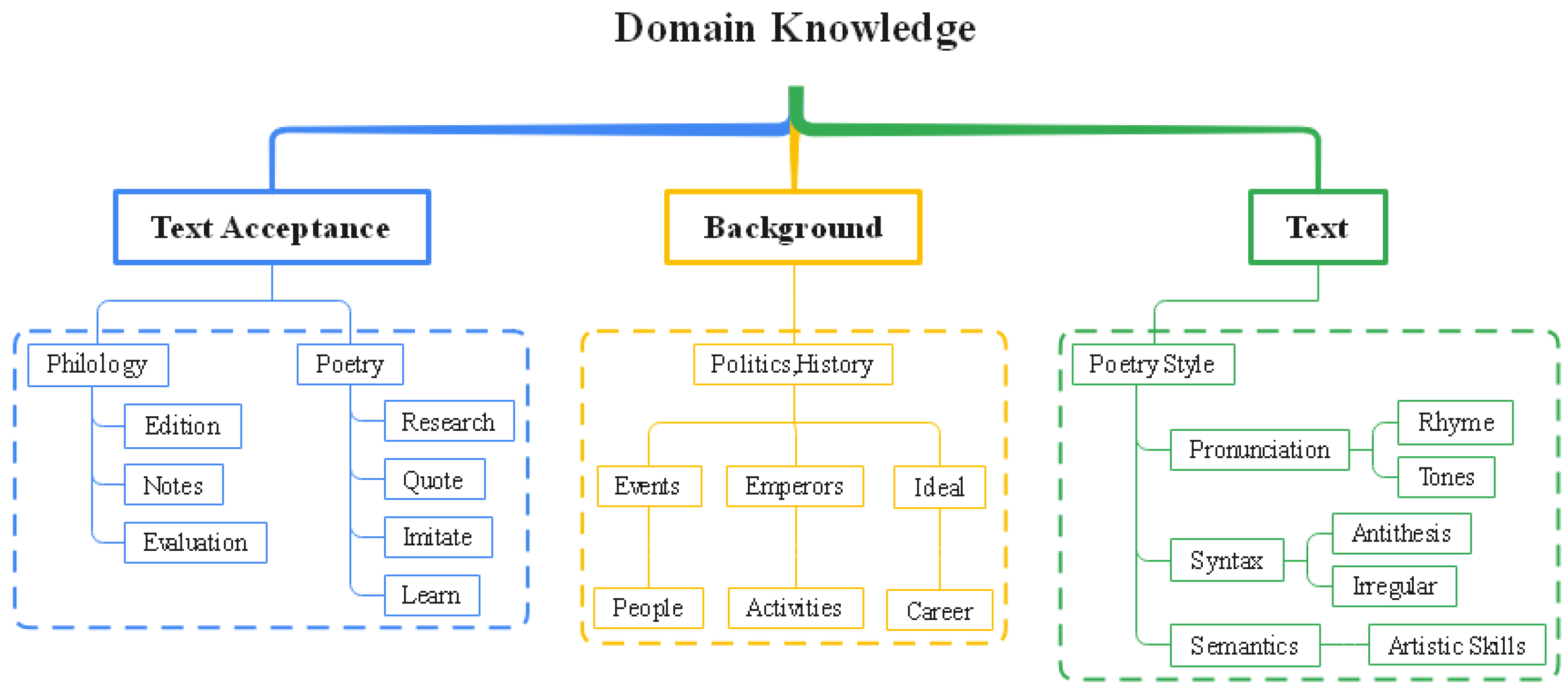
4.3. Domain Knowledge Component
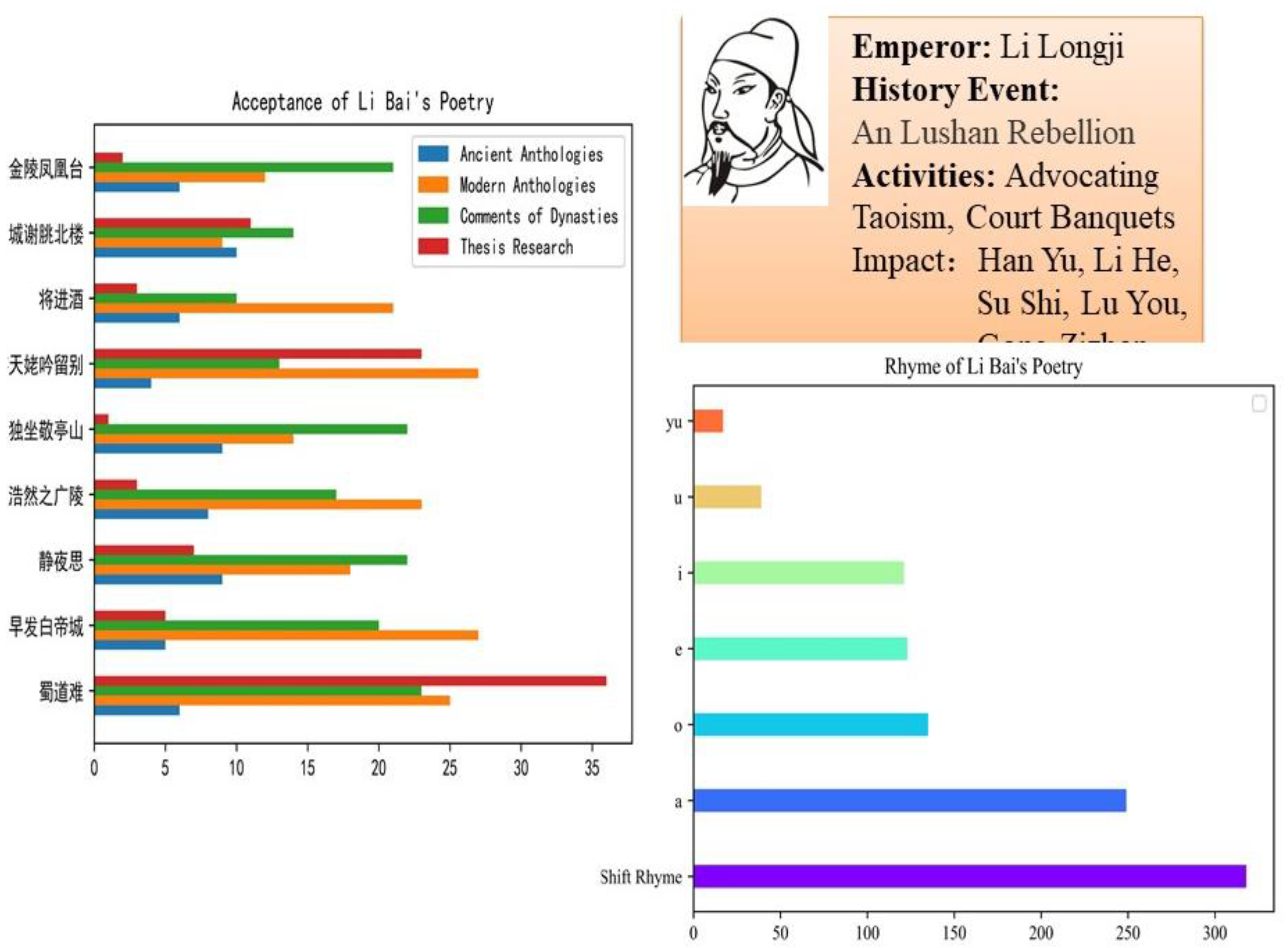
5. Case Studies
5.1. Authorship Attribution (AA) Component
5.2. Stylistic Text Component
5.3. Domain Knowledge Component
6. Experiments
6.1. Datasets
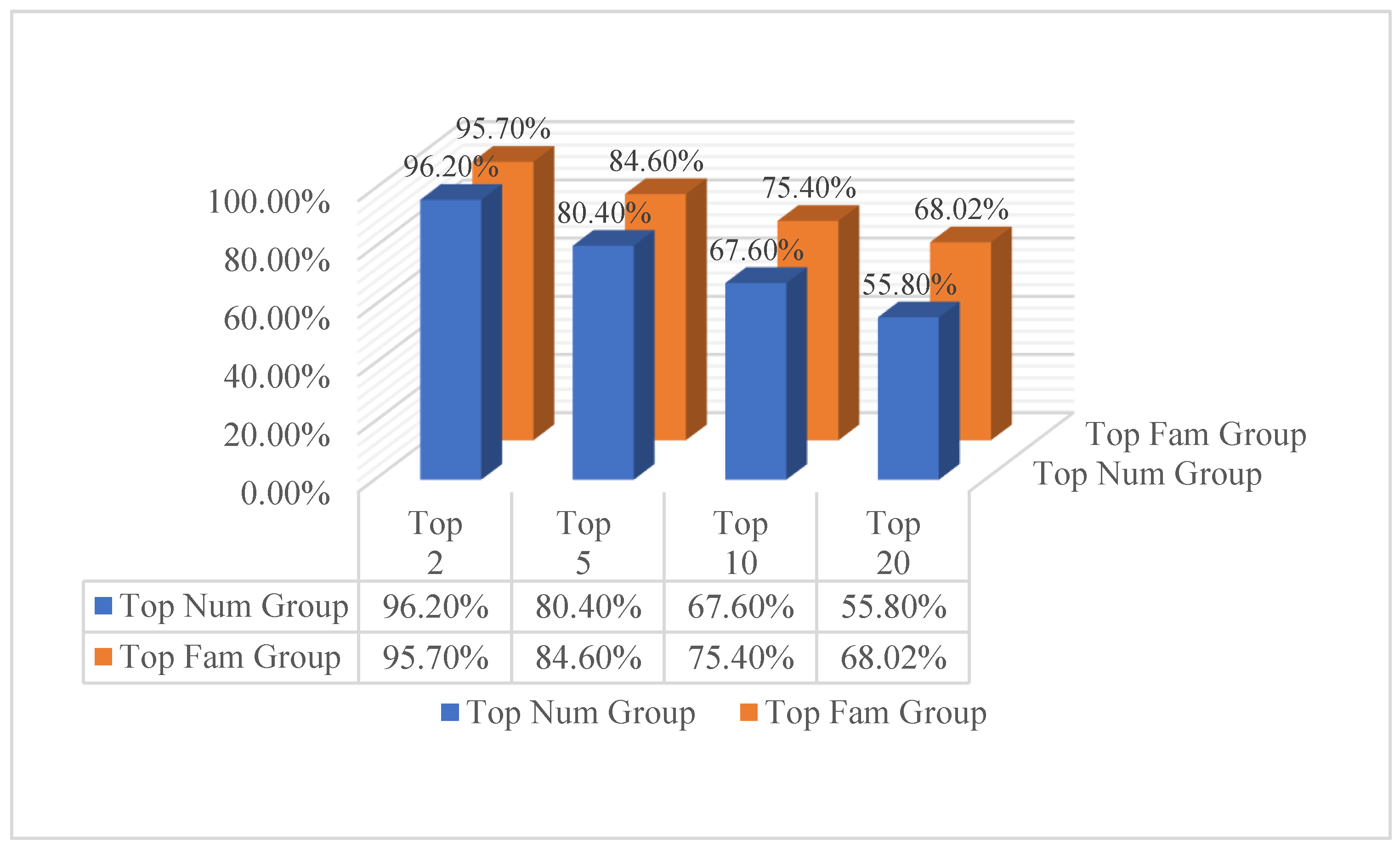
6.2. Experimental Results
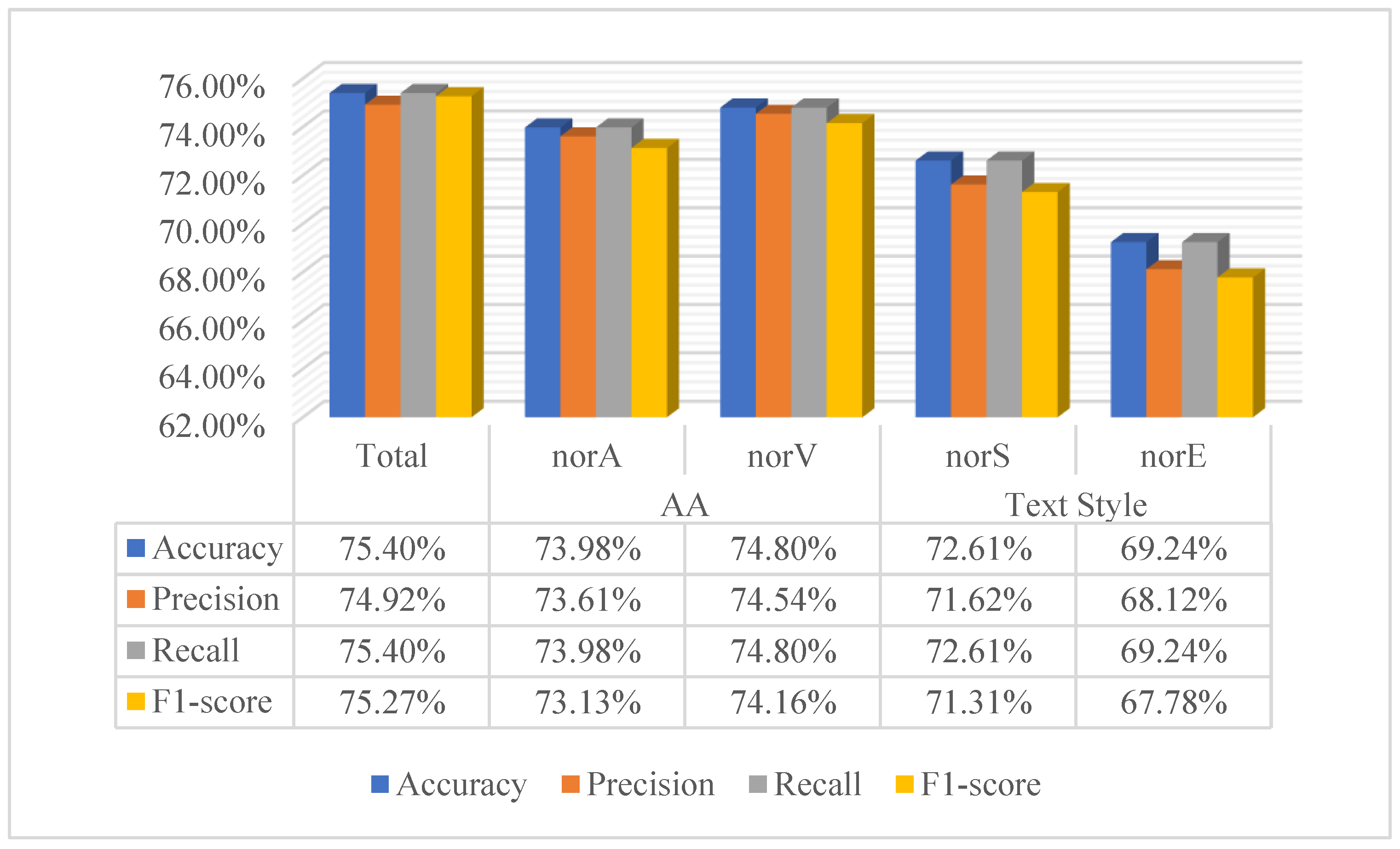
6.3. Ablation Study
6.4. Text Acceptance Component Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jun, W. From Humanities Computing to Visualization: A Survey of the Development of Digital Humanities. Theory Crit. Lit. Art 2020, 2, 18–23. [Google Scholar]
- Sari, Y.; Stevenson, M.; Vlachos, A. Topic or Style? Exploring the Most Useful Features for Authorship Attribution. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 343–353. [Google Scholar]
- Yang, Z.; Ming-Hu, J. A Review on Authorship Identification Research. Act Autom. A Sin. 2021, 47, 2501–2520. [Google Scholar] [CrossRef]
- Tianjiu, X.; Ying, L. Analysis of the Words and N-grams in A Dream of Red Mansions. New Technol. Libr. Inf. Serv. 2015, 257, 50–57. [Google Scholar]
- Xie, L.; Zhibin, W. The Literary Mind and the Carving of Dragons; Zhonghua Book Company: Beijing, China, 2012. [Google Scholar]
- Rong, Z.; Zhenfu, Z. ShiPin; Zhonghua Book Company: Beijing, China, 1998. [Google Scholar]
- Zhiji, H.; Changlu, L.; Wei, Z. The Forewords of Jiang Yan’s Thirty Miscellaneous Poems; Zhonghua Book Company: Beijing, China, 1984. [Google Scholar]
- Tu, S.I.-K.; Mei, Y.; Yulan, C. Twenty-Four Styles of Poetry; Zhonghua Book Company: Beijing, China, 2019. [Google Scholar]
- Zhonghua, L. Three Sixteenth in Late Tang Dynasty. Lit. Herit. 2001, 2, 126–128. [Google Scholar]
- Yi, Y.; Du, L.; Xue, S. Li Bai and Du Fu Poetics; Beijing Publishing Group: Beijing, China, 2002. [Google Scholar]
- Yunxi, W. Ancient Chinese Literary Theory; Shanghai Chinese Classics Publishing House: Shanghai, China, 2006. [Google Scholar]
- Gen, L. Review of Tang Poetry; The Commercial Press: Beijing, China, 2011. [Google Scholar]
- Kao, Y.-K.; Mei, T.-L. The Charm of Tang Poetry; The Commercial Press: Beijing, China, 2013. [Google Scholar]
- Shiwen, Y. The computer aided research system of Chinese ancient poetry. Acta Sci. Nat. Univ. Peking 2001, 37, 727–733. [Google Scholar]
- Ten Thousand Rooms Project [EB/OL]. Available online: https://tenthousandrooms.yale.edu/ (accessed on 16 November 2022).
- Chen, J.W.; Borovsky, Z.; Kawano, Y.; Chen, R. The ShiShuo xinyu as data visualization. Early Mediev. China 2014, 2014, 23–59. [Google Scholar] [CrossRef]
- Protass, J. Toward a Spatial History of Chan. Rev. Relig. Chin. Soc. 2016, 3, 164–188. [Google Scholar] [CrossRef] [Green Version]
- Junfeng, H.; Shiwen, Y. Word meaning similarity analysis in Chinese ancient poetry and its applications. J. Chin. Inf. Process. 2002, 16, 39–44. [Google Scholar]
- Ge, J. [EB/OL]. Available online: https://jiuge.thunlp.cn (accessed on 16 November 2022).
- Yan, W. Research on Segmentation Method Applicable to Tang Poetry. Mod. Comput. 2016, 2, 17–19. [Google Scholar]
- Hui, Y. The Establishment of Tang Poetry Corpus Used in the Analysis of Classical Poetry. Master’s Thesis, He Bei University, Bao Ding, China, 2016. [Google Scholar]
- Jingyang, Z.; Peizhuang, S. Frequency entropy analysis and popularity grading of Tang Poetry. Sci. Technol. Inf. 2009, 6, 241–243. [Google Scholar]
- Zhou, L. Construction of Knowledge Graph of Chinese Tang Poetry and Design of Intelligent Knowledge Services. Libr. Inf. Serv. 2019, 63, 24–33. [Google Scholar]
- Garden of Tang Poetry [EB/OL]. Available online: http://poem.Studentsystem.org/index (accessed on 7 May 2022).
- K Vision [EB/OL]. Available online: http://dh.kvlab.org/cbdb_kg (accessed on 7 May 2022).
- CBDB [EB /OL]. Available online: https://projects.iq.harvard.edu/chinesecbdb (accessed on 22 March 2022).
- Zhou, A.; Zhang, Y.; Lu, M. C-Transformer model in Chinese poetry authorship attribution. Int. J. Innov. Comput. Inf. Control 2022, 18, 901–916. [Google Scholar]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Urbana, IL, USA, 1948. [Google Scholar]
- Wang, Z.; Qiao, J.; Mazanec, T. Geographic Distribution and Change in Tang Poetry: Data Analysis from the Chronological Map of Tang-Song Literature. J. Chin. Lit. Cult. 2019, 5, 360–374. [Google Scholar]
- Wei, P. From the distribution of common words examining the author issue of Dream of Red Chamber Author. In Memorial Li Fanggui’s 100th Anniversary International Symposium on Chinese History; University of Washington: Seattle, WA, USA, 2002. [Google Scholar]
- Jin, M.; Jiang, M. Text Clustering on Authorship Attribution Based on the Features of Punctuations Usage. In Proceedings of the 2012 IEEE 11th International Conference on Signal Processing (ICSP), Beijing, China, 21–25 October 2012; Volume 3, pp. 2175–2178. [Google Scholar]
- Ho, J. From the use of three functional words “的(of)”, “地(to)”, “得(for)” examining author’s unique writing style and on dream of red chamber author issues. BIBLID 2015, 120, 119–150. [Google Scholar]
- Jin, M. Author identification based on n-gram pattern of auxiliary word. Meas. Lang. 2002, 23, 225–240. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Yong, Y.; Yan, Z.; Zhongshi, H. Discrimination of Classical Poetry Authors Based on Machine Learning. Mind Calc. 2007, 3, 359–364. [Google Scholar]
- Stamatatos, E. A survey of modern authorship attribution methods. J. Am. Soc. Inf. Sci. Technol. 2008, 60, 538–556. [Google Scholar] [CrossRef]
- Shrestha, P.; Sierra, S.; González, F.A.; Montes, M.; Rosso, P.; Solorio, T. Convolutional Neural Networks for Authorship Attribution of Short Texts. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 669–674. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribution | Character | Description |
|---|---|---|
| Natural | Name | Name, Alias, Style Name Pseudonym, e.g., Li Twelfth |
| Gender | ||
| Birth | ||
| Region | Birthplace, Poet Footprints | |
| Nationalities | ||
| Ages | Early Tang, Prosperous Tang, Middle Tang, and Late Tang | |
| Social | Occupation | e.g., Emperor, Personnel Minister, Law Enforcement Official |
| Official Career Path | e.g., Imperial Examination, Recommendation, Military | |
| Background | Aristocrats, Ordinary People | |
| Religion | Confucian, Buddhism, Taoism | |
| Social Class | ||
| Social Network | Friend relationships extracted from poetry |
| Dataset | TopFam2 | TopFam5 | TopFam10 | TopFam20 |
|---|---|---|---|---|
| Authors | 2 | 5 | 10 | 20 |
| Poems | 2407 | 6210 | 7994 | 11,289 |
| Train | 1684 | 4347 | 5586 | 7902 |
| Dev | 241 | 621 | 800 | 1129 |
| Test | 482 | 1242 | 1598 | 2258 |
| Average Poems | 1204 | 1242 | 800 | 565 |
| Datasets | Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| TopFam2 | NB | 93.29% | 93.34% | 93.29% | 93.37% |
| SVM | 91.19% | 86.35% | 86.19% | 86.42% | |
| CNN | 95.70% | 95.45% | 95.70% | 95.45% | |
| Ours | 97.60% | 97.42% | 97.60% | 97.23% | |
| TopFam5 | NB | 75.75% | 75.08% | 75.75% | 75.50% |
| SVM | 76.26% | 75.62% | 76.26% | 75.74% | |
| CNN | 84.60% | 84.13% | 84.60% | 84.53% | |
| Ours | 90.55% | 89.96% | 90.55% | 90.17% | |
| TopFam10 | NB | 73.56% | 73.65% | 73.56% | 72.53% |
| SVM | 66.16% | 66.16% | 66.16% | 65.83% | |
| CNN | 75.40% | 75.32% | 75.40% | 75.18% | |
| Ours | 86.37% | 85.71% | 86.37% | 85.10% | |
| TopFam20 | NB | 58.79% | 58.43% | 58.79% | 58.51% |
| SVM | 61.42% | 61.07% | 61.42% | 60.65% | |
| CNN | 68.02% | 67.85% | 68.02% | 67.90% | |
| Ours | 80.98% | 80.25% | 79.98% | 80.36% |
| Dataset | TopNum2 | TopNum5 | TopNum10 | TopNum20 |
|---|---|---|---|---|
| Authors | 2 | 5 | 10 | 20 |
| Poems | 4294 | 6922 | 10,189 | 15,177 |
| Train | 3006 | 4846 | 7133 | 10,624 |
| Dev | 430 | 692 | 1019 | 1518 |
| Test | 858 | 1384 | 2037 | 3035 |
| Average Poems | 2147 | 1384 | 1019 | 759 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, A.; Zhang, Y.; Lu, M. Multidimensional Domain Knowledge Framework for Poet Profiling. Electronics 2023, 12, 656. https://doi.org/10.3390/electronics12030656
Zhou A, Zhang Y, Lu M. Multidimensional Domain Knowledge Framework for Poet Profiling. Electronics. 2023; 12(3):656. https://doi.org/10.3390/electronics12030656
Chicago/Turabian StyleZhou, Ai, Yijia Zhang, and Mingyu Lu. 2023. "Multidimensional Domain Knowledge Framework for Poet Profiling" Electronics 12, no. 3: 656. https://doi.org/10.3390/electronics12030656
APA StyleZhou, A., Zhang, Y., & Lu, M. (2023). Multidimensional Domain Knowledge Framework for Poet Profiling. Electronics, 12(3), 656. https://doi.org/10.3390/electronics12030656