


Probability Density Forecasting of Wind Power Based on Transformer Network with Expectile Regression and Kernel Density Estimation


Abstract
:1. Introduction
- (1)
- The transformer network, which possesses the best performance in the NLP domain for sequential data tasks, is migrated for wind power prediction. Then, the internal correlations and remote dependencies of more extended sequential data could be captured better than the RNN. The expectile regression in conjunction with a transformer network is utilized for wind power prediction via the ERNN structure. This newly developed model is capable of estimating the NNM-based parameters more easily than the QRNN. Further, it is more sensitive to sample points with larger errors and can output conditional expectation functions that provide more information for decision making. To the best of our knowledge, this is the first expectile regression added to the ERNN structure of the transformer network.
- (2)
- The nonparametric KDE-based approach is implemented to estimate the prediction results of Transformer-ER at a variety of levels, thus allowing the complete wind power probability density estimate to be derived. Since the bandwidth influences the density function of random variables [27], the leave-one-out cross-validation is employed here for optimal bandwidth selection, fully exploiting the information from the estimation results of various levels τ, while Gaussian kernel functions [3] are commonly utilized to achieve improved probability density estimates.
- (3)
- The probability density estimation results are appropriately derived based on two sets of evaluation criteria for point estimation and interval prediction. The point estimation results, which are attained using the probability density approach, exhibit strong robustness and high accuracy compared with traditional prediction methods [27]. Usually, evaluation metrics, such as prediction interval coverage probability (PICP), prediction interval normalized average width (PINAW), and coverage width-based criterion (CWC), are employed to assess the interval prediction results. The prediction interval estimation error (PIEE) evaluation metrics proposed in [25] are also implemented here for the purpose of evaluating and comparing the probability density interval estimation. Additionally, the PIEE index is incorporated into the CWC composite index to make it more comprehensive and accurate in reflecting the evaluation effect of interval prediction.
2. Related Theories
2.1. Transformer Network
2.1.1. Self-Attention Mechanism
2.1.2. Multi-Head Attention Mechanism
2.1.3. Position Encoding
2.1.4. Transformer
2.2. Expectile Regression
2.3. Cuckoo Search Algorithm
2.4. Kernel Density Estimation
2.4.1. KDE-Based Model
2.4.2. Leave-One-Out Cross-Validation
3. Methodology Framework and Evaluation Metrics
3.1. Methodology Framework
- (1)
- Preprocessing of the wind power data, including the division of data into training and test sets, normalization, and the utilization of the sliding window method for the construction of feature and response variables.
- (2)
- Nine distinct models (ER, QRNN, LSTM, GRU, MLP, RNN, Transformer, Transformer-ER, and CS-Transformer-ER) are employed for wind power series prediction, and four commonly used evaluation metrics (MAE, RMSE, MAPE, and R2) are considered as appropriate measures to compare the performances of the models.
- (3)
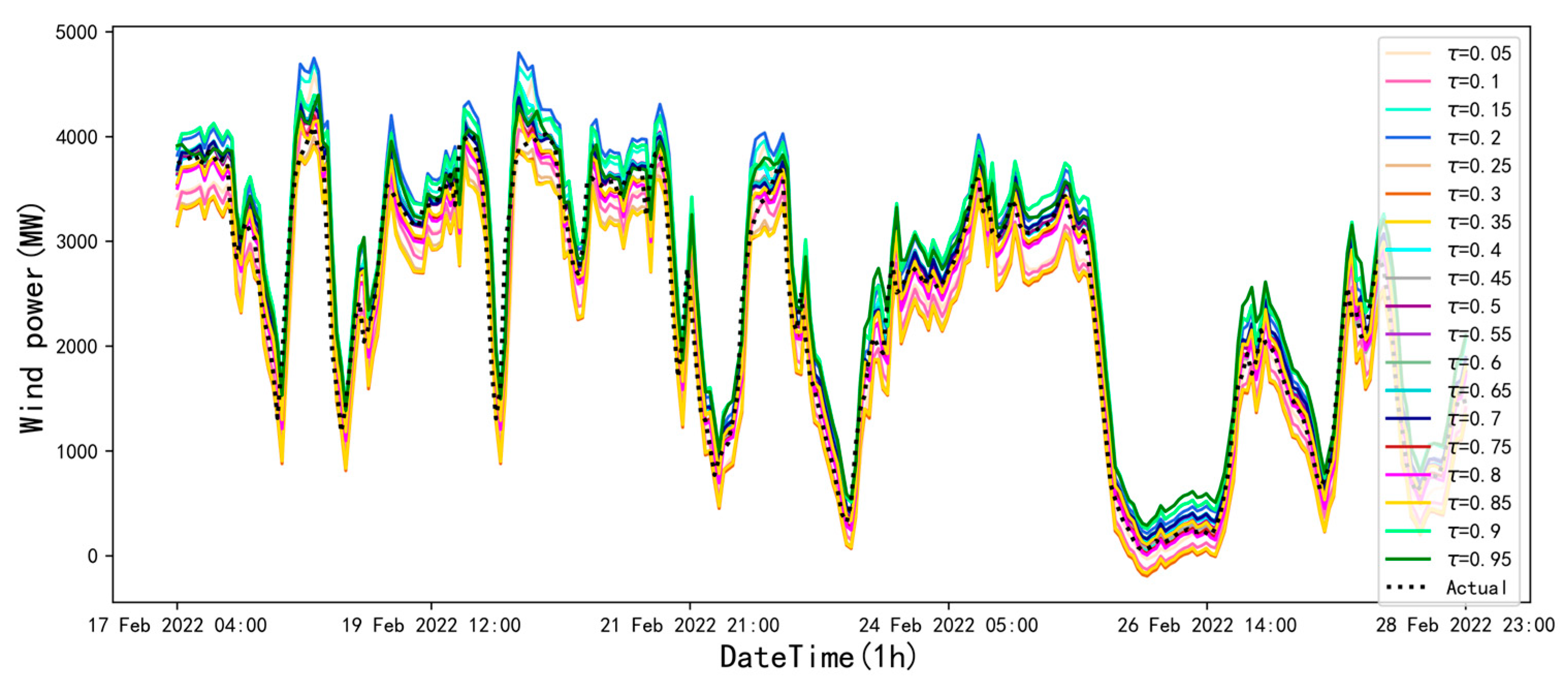
- The structure of the optimal Transformer-ER network, as identified by the CS algorithm, is implemented for point prediction at various levels , and the error evaluation metrics are calculated for it.
- (4)
- The point prediction results for various levels of are utilized as inputs for kernel density estimation, the optimal bandwidth () is then determined through LOOCV, and finally, probability density predictions are achieved accordingly.
- (5)
- The results of probability density estimation are appropriately exploited to construct point and interval predictions, and the evaluation metrics of point and interval estimation of various models are separately obtained for comparison.
3.2. Point Estimation Evaluation Metrics
3.3. Interval Prediction Evaluation Metrics
3.4. Probability Density Prediction Is Constructed as a Point Estimation
4. Empirical Results
4.1. Data Sources and Preprocessing
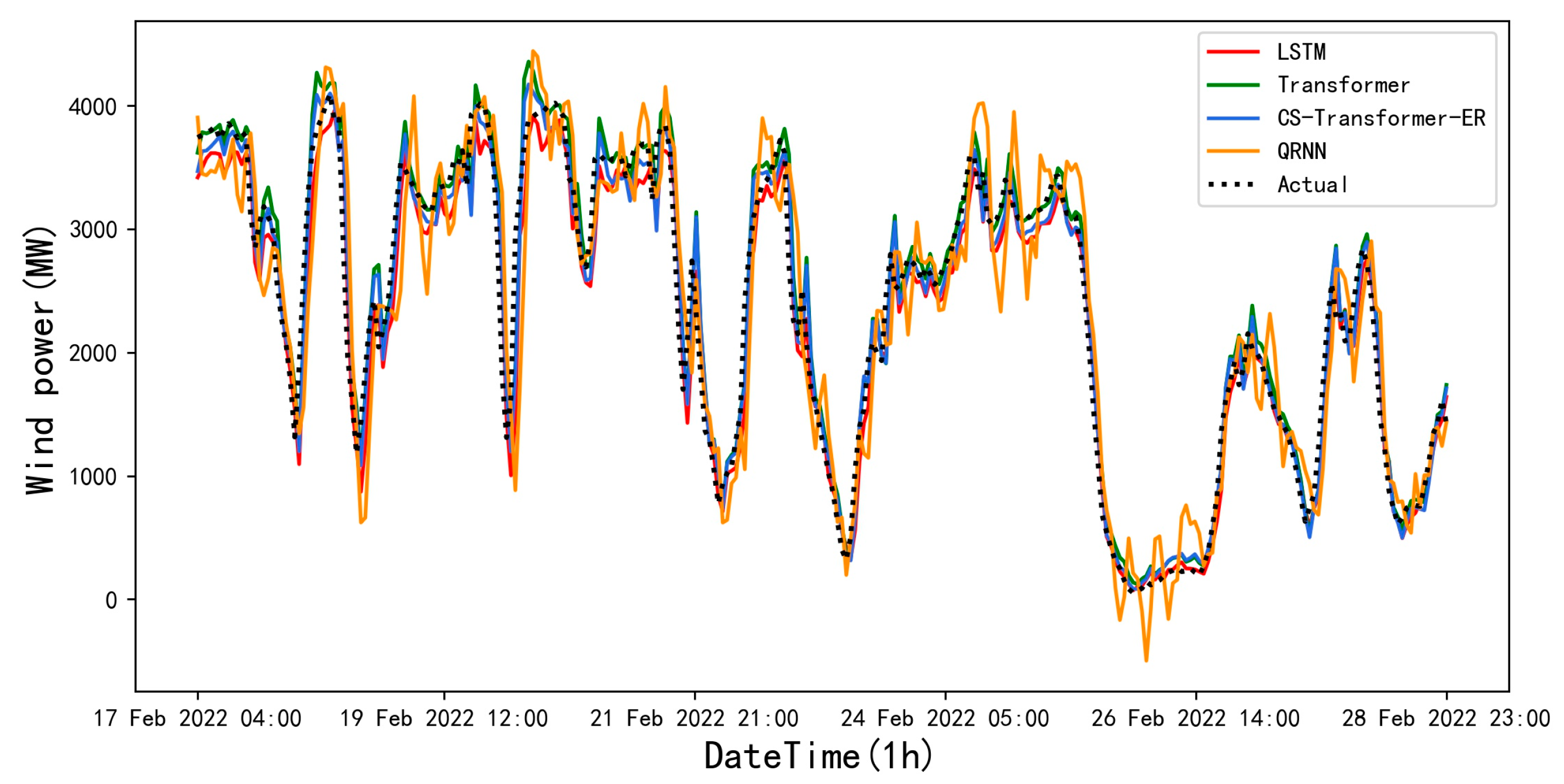
4.2. Comparison of the Model Prediction Results
- (1)
- Among all the models, the transformer model has the best performance in predicting wind power data. The prediction results of the Transformer-ER model when should be theoretically similar to those of the transformer model, and any minor differences between them can be attributed to the numerical calculation variations. In this type of sequential data, compared to the RNN-based model, the transformer model demonstrates superior performance in capturing the internal correlation of longer sequential data. In addition, based on the common sense of deep learning, this effect becomes more noticeable as the amount of training data rises.
- (2)
- The CS algorithm is effective in searching for hyperparameters of NNMs. Additionally, the achieved results from the CS-Transformer-ER model, which exploits the hyperparameters found through the CS algorithm, also exhibit superior performance in all four evaluation metrics. It is crucial to mention that the low MAPE values for the GRU model could be skewed. The MAPE may not be as reliable as the other three indicators in assessing the prediction performance of the models on the test set due to the presence of intervals in the test set data that contain zero values or close to them. This may lead to the calculated MAPE values tending towards infinity, making the metric unreliable. Furthermore, further optimization of the CS algorithm with more iterations could possibly lead to even better predictions.
- (3)
- The linear model (i.e., ER) exhibits the worst performance among the benchmark models. Although the MLP and QRNN models are essentially nonlinear, they fail in full consideration of the temporal relationship between data and thus exhibit lower prediction performance than the RNNs. Among the three recurrent neural networks, namely RNN, LSTM, and GRU, the best performance is achieved for the LSTM, which is exploited by most researchers. However, the corresponding MAE error metric of the prediction results is almost 9% higher than that of the transformer model.
4.3. The Predicted Results Based on the Various Levels of
4.4. Probability Density Prediction Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, C.; Niu, T.; Wei, W. Developing a wind power forecasting system based on deep learning with attention mechanism. Energy 2022, 257, 124750. [Google Scholar] [CrossRef]
- He, Y.; Zhang, W. Probability density forecasting of wind power based on multi-core parallel quantile regression neural network. Knowl.-Based Syst. 2020, 209, 106431. [Google Scholar] [CrossRef]
- Niu, D.; Sun, L.; Yu, M.; Wang, K. Point and interval forecasting of ultra-short-term wind power based on a data-driven method and hybrid deep learning model. Energy 2022, 124384. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Qiao, B.; Liu, J.; Wu, P.; Teng, Y. Wind power forecasting based on variational mode decomposition and high-order fuzzy cognitive maps. Appl. Soft Comput. 2022, 129, 109586. [Google Scholar] [CrossRef]
- Ding, M.; Zhou, H.; Xie, H.; Wu, M.; Liu, K.-Z.; Nakanishi, Y.; Yokoyama, R. A time series model based on hybrid-kernel least-squares support vector machine for short-term wind power forecasting. ISA Trans. 2021, 108, 58–68. [Google Scholar] [CrossRef]
- Liu, K. A random forest-based method for wind power system output power prediction. Light Source Light. 2022, 07, 165–167. [Google Scholar]
- Zha, W.; Liu, J.; Li, Y.; Liang, Y. Ultra-short-term power forecast method for the wind farm based on feature selection and temporal convolution network. ISA Trans. 2022, 129, 405–414. [Google Scholar] [CrossRef]
- Wang, W.; Liu, H.; Chen, Y.; Zheng, N.; Li, Z.; Ji, X.; Yu, G.; Kang, J. Wind power prediction based on LSTM recurrent neural network. Renew. Energy 2020, 38, 1187–1191. [Google Scholar]
- Jin, Y.; Kang, J.; Chen, Y. Wind power prediction technology based on LSTM recurrent neural network algorithm. Electron. Test. 2022, 36, 49–51. [Google Scholar]
- Cui, Y.; Chen, Z.; He, Y.; Xiong, X.; Li, F. An algorithm for forecasting day-ahead wind power via novel long short-term memory and wind power ramp events. Energy 2022, 263, 125888. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, D. A data-driven deep sequence-to-sequence long-short memory method along with a gated recurrent neural network for wind power forecasting. Energy 2022, 239, 122109. [Google Scholar] [CrossRef]
- Niu, Z.; Yu, Z.; Tang, W.; Wu, Q.; Reformat, M. Wind power forecasting using attention-based gated recurrent unit network. Energy 2020, 196, 117081. [Google Scholar] [CrossRef]
- Li, L.L.; Liu, Z.F.; Tseng, M.L.; Jantarakolica, K.; Lim, M.K. Using enhanced crow search algorithm optimization-extreme learning machine model to forecast short-term wind power. Expert Syst. Appl. 2021, 184, 115579. [Google Scholar] [CrossRef]
- Jalali SM, J.; Ahmadian, S.; Khodayar, M.; Khosravi, A.; Shafie-khah, M.; Nahavandi, S.; Catalão, J.P.S. An advanced short-term wind power forecasting framework based on the optimized deep neural network models. Int. J. Electr. Power Energy Syst. 2022, 141, 108143. [Google Scholar] [CrossRef]
- Jiang, X.; Xu, Y.; Song, C. A new method for short-term wind power load forecasting. J. Beijing Norm. Univ. 2022, 58, 39–46. [Google Scholar]
- Chen, D.; Hong, W.; Zhou, X. Transformer Network for Remaining Useful Life Prediction of Lithium-Ion Batteries. IEEE Access 2022, 10, 19621–19628. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Wang, L.; He, Y.; Liu, X.; Li, L.; Shao, K. M2TNet: Multi-modal multi-task Transformer network for ultra-short-term wind power multi-step forecasting. Energy Rep. 2022, 8, 7628–7642. [Google Scholar] [CrossRef]
- Wu, H.; Meng, K.; Fan, D.; Zhang, Z.; Liu, Q. Multistep short-term wind speed forecasting using transformer. Energy 2022, 261, 125231. [Google Scholar] [CrossRef]
- Qu, K.; Si, G.; Shan, Z.; Kong, X.; Yang, X. Short-term forecasting for multiple wind farms based on transformer model. Energy Rep. 2022, 8, 483–490. [Google Scholar] [CrossRef]
- Xiong, B.; Lou, L.; Meng, X.; Wang, X.; Ma, H.; Wang, Z. Short-term wind power forecasting based on Attention Mechanism and Deep Learning. Electr. Power Syst. Res. 2022, 206, 107776. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, C.; Luo, Y.; Wu, B.; Dong, N.; Xiao, T.; Zhu, H. Wind power forecast based on variational mode decomposition and long short term memory attention network. Energy Rep. 2022, 8, 922–931. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, J.; Infield, D.; Liu, Y.; Lien, F. Short-term forecasting and uncertainty analysis of wind turbine power based on long short-term memory network and Gaussian mixture model. Appl. Energy 2019, 241, 229–244. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Wang, B.; Guo, S.; Watada, J. Multi-objective prediction intervals for wind power forecast based on deep neural networks. Inf. Sci. 2021, 550, 207–220. [Google Scholar] [CrossRef]
- He, Y.; Liu, R.; Li, H.; Wang, S. Short-term power load probability density forecasting method using kernel-based support vector quantile regression and Copula theory. Appl. Energy 2017, 185, 254–266. [Google Scholar]
- He, Y.; Li, H. Probability density forecasting of wind power using quantile regression neural network and kernel density estimation. Energy Convers. Manag. 2018, 164, 374–384. [Google Scholar] [CrossRef]
- Jiang, C.; Jiang, M.; Xu, Q.; Huang, X. Expectile regression neural network model with applications. Neurocomputing 2017, 247, 73–86. [Google Scholar]
- Zhao, H.; Zhang, S.; Zhao, Y.; Liu, H.; Qiu, B. Short-term power load interval forecasting based on adaptive noise-complete empirical modal decomposition-sample entropy-long-term memory neural network and kernel density estimation. Mod. Electr. 2021, 38, 138–146. [Google Scholar]
- Li, J.; Zhang, S.; Yang, Z. A wind power forecasting method based on optimized decomposition prediction and error correction. Electr. Power Syst. Res. 2022, 208, 107886. [Google Scholar]
- Lu, W.; Duan, J.; Wang, P.; Ma, W.; Fang, S. Short-term Wind Power Forecasting Using the Hybrid Model of Improved Variational Mode Decomposition and Maximum Mixture Correntropy Long Short-term Memory Neural Network. Int. J. Electr. Power Energy Syst. 2023, 144, 108552. [Google Scholar] [CrossRef]
- Ewees, A.A.; Al-qaness MA, A.; Abualigah, L.; Elaziz, M.A. HBO-LSTM: Optimized long short term memory with heap-based optimizer for wind power forecasting. Energy Convers. Manag. 2022, 268, 116022. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, H.; Wang, C.; Zhou, X. Wind power forecasting based on stacking ensemble model, decomposition and intelligent optimization algorithm. Neurocomputing 2021, 462, 169–184. [Google Scholar] [CrossRef]
- Zhang, Y.; Pi, Z.; Zhu, R.; Song, J.; Shi, J. Wind power prediction based on WOA-BiLSTM neural network. Electrotechnology 2022, 10, 28–31. [Google Scholar]
- Kang, H.; Li, Q.; Yu, S.; Yao, S. Ultra-short-term wind power output prediction based on SA-PSO-BP neural network algorithm. Inn. Mong. Power Technol. 2020, 38, 64–68. [Google Scholar]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), IEEE, Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Yang, X.S. Nature-Inspired Metaheuristic Algorithms; Luniver Press: Coventry, UK, 2010; pp. 16–17. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of hidden layers | 2 |
| Number of neurons in the hidden layer | [64, 32] |
| Batch size | 32 |
| Maximum number of iterations | 50 |
| Embedding layer dimension | 32 |
| Number of multi-head attention heads | 4 |
| Level | 0.5 |
| Model | MAE | RMSE | MAPE | R2 |
|---|---|---|---|---|
| ER | 428.4206 | 565.2859 | 1.8311 | 0.7672 |
| QRNN | 354.1195 | 460.9649 | 1.8252 | 0.8452 |
| LSTM | 207.8788 | 278.8663 | 1.7486 | 0.9434 |
| GRU | 228.8504 | 308.0818 | 1.7363 | 0.9309 |
| MLP | 361.4761 | 478.3939 | 1.8812 | 0.8392 |
| RNN | 239.0550 | 321.7016 | 1.7537 | 0.9246 |
| Transformer | 190.5266 | 269.8500 | 1.8787 | 0.9470 |
| Transformer-ER | 194.9061 | 268.8835 | 1.7945 | 0.9473 |
| CS-Transformer-ER | 183.9616 | 252.6901 | 1.8142 | 0.9535 |
| Methods | Point Estimates | MAE | RMSE | MAPE | R2 |
|---|---|---|---|---|---|
| Transformer-ER | Mode | 203.1176 | 282.0029 | 1.9020 | 0.9421 |
| Median | 191.4592 | 271.6375 | 1.8843 | 0.9463 | |
| Mean | 187.0430 | 263.9477 | 1.8611 | 0.9493 | |
| QRNN | Mode | 334.9645 | 428.0405 | 1.8301 | 0.8665 |
| Median | 310.3674 | 419.9150 | 1.7790 | 0.8716 | |
| Mean | 303.6449 | 411.5041 | 1.7964 | 0.8767 | |
| ER | Mode | 428.8808 | 564.8208 | 1.8274 | 0.7676 |
| Median | 430.2076 | 566.8995 | 1.8285 | 0.7659 | |
| Mean | 430.0491 | 566.1494 | 1.8323 | 0.7665 |
| Methods | PICP | PIEE | PINAW | CWC |
|---|---|---|---|---|
| Transformer-ER | 0.8697 | 0.0064 | 0.1728 | 0.3510 |
| QRNN | 0.9824 | 0.0008 | 0.5580 | 0.5580 |
| ER | 0.4225 | 0.0572 | 0.1781 | 0.4732 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, H.; He, X.; Li, C. Probability Density Forecasting of Wind Power Based on Transformer Network with Expectile Regression and Kernel Density Estimation. Electronics 2023, 12, 1187. https://doi.org/10.3390/electronics12051187
Xiao H, He X, Li C. Probability Density Forecasting of Wind Power Based on Transformer Network with Expectile Regression and Kernel Density Estimation. Electronics. 2023; 12(5):1187. https://doi.org/10.3390/electronics12051187
Chicago/Turabian StyleXiao, Haoyi, Xiaoxia He, and Chunli Li. 2023. "Probability Density Forecasting of Wind Power Based on Transformer Network with Expectile Regression and Kernel Density Estimation" Electronics 12, no. 5: 1187. https://doi.org/10.3390/electronics12051187
APA StyleXiao, H., He, X., & Li, C. (2023). Probability Density Forecasting of Wind Power Based on Transformer Network with Expectile Regression and Kernel Density Estimation. Electronics, 12(5), 1187. https://doi.org/10.3390/electronics12051187