


Aero-YOLO: An Efficient Vehicle and Pedestrian Detection Algorithm Based on Unmanned Aerial Imagery

Abstract
:1. Introduction
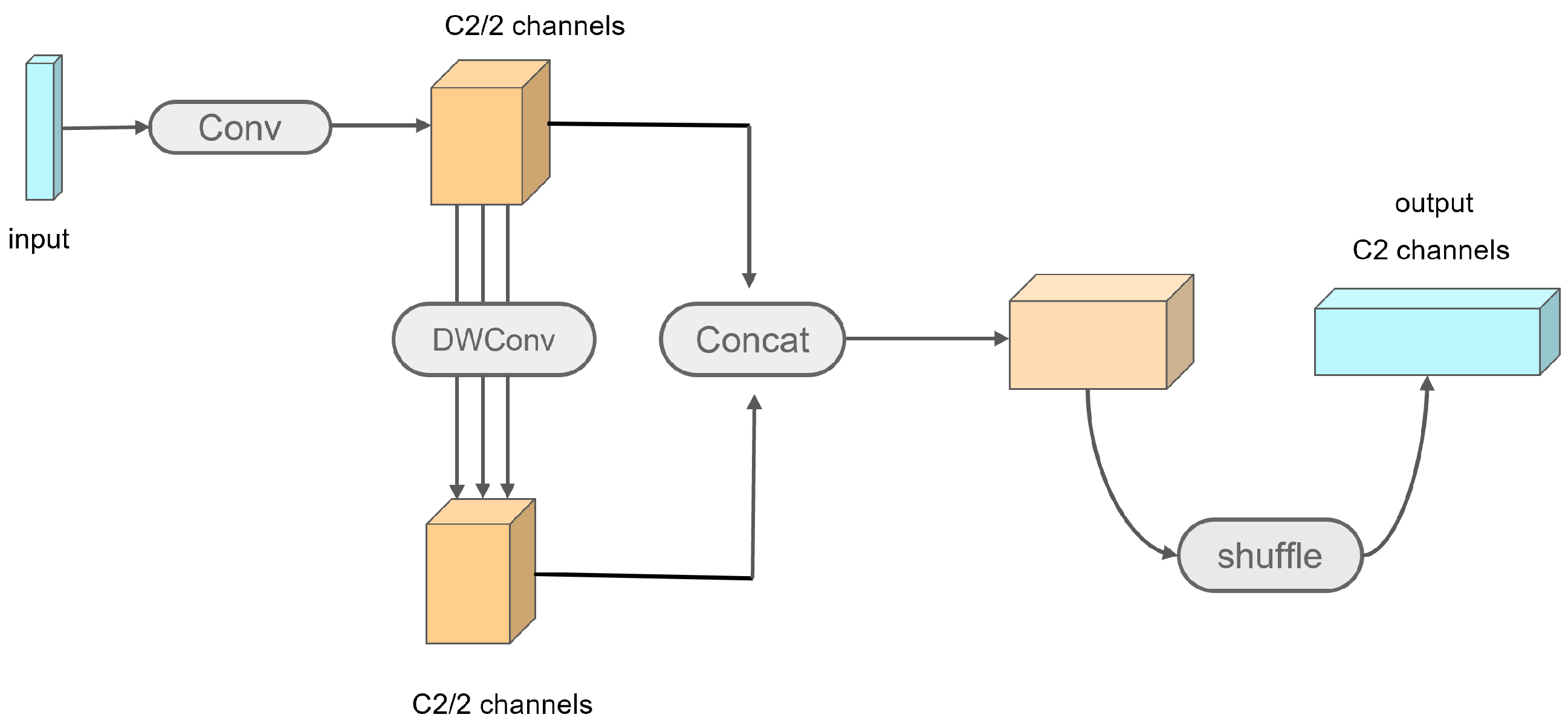
- The replacement of the original Conv module [12] with Grouped Separable Convolution (GSConv) led to a reduction in model parameters, an expanded receptive field, and improved computational efficiency.
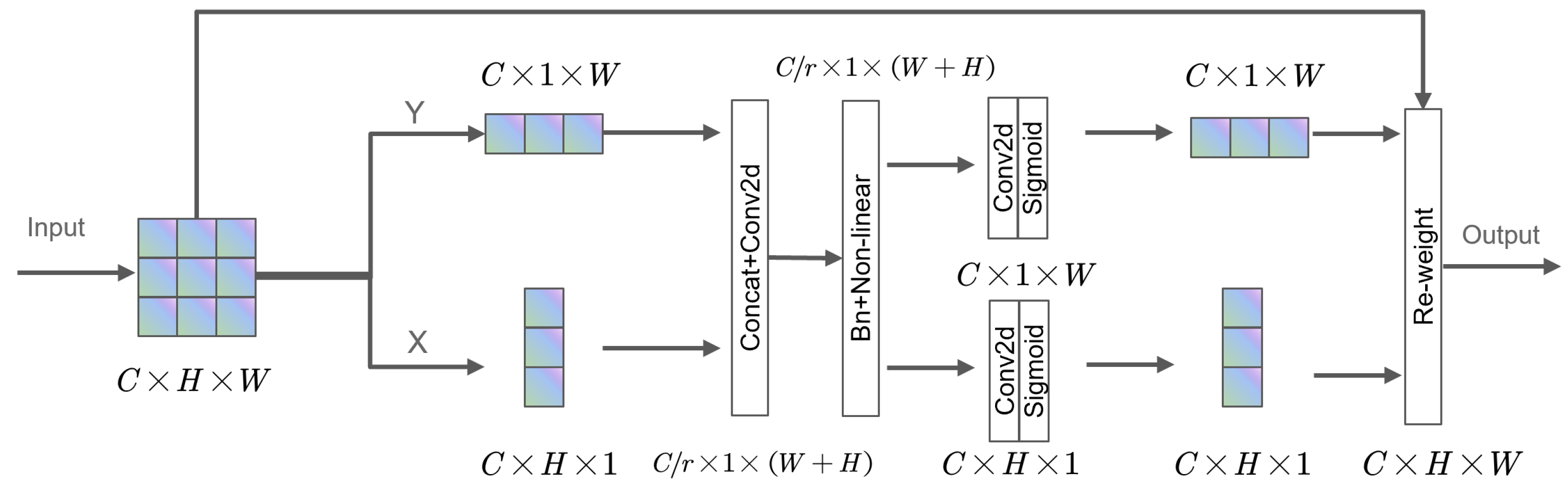
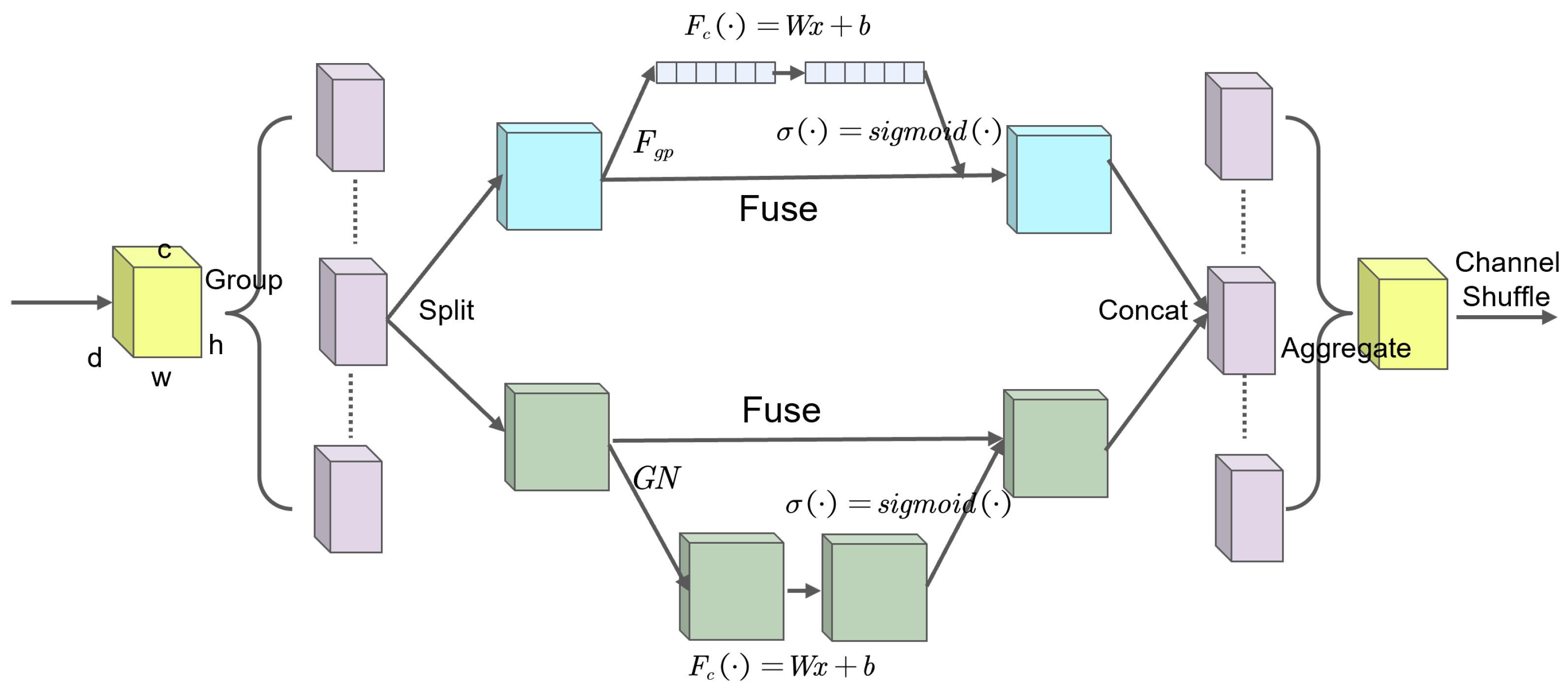
- The incorporation of the CoordAtt and shuffle attention [13] mechanisms bolstered feature extraction, particularly benefiting the detection of small or obstructed vehicles from the perspective of unmanned aerial vehicles.
- After comparative analysis with Adaptive Moment Estimation (Adam) [14], the selection of Stochastic Gradient Descent (SGD) as the optimizer resulted in superior performance in model convergence and overall efficiency.
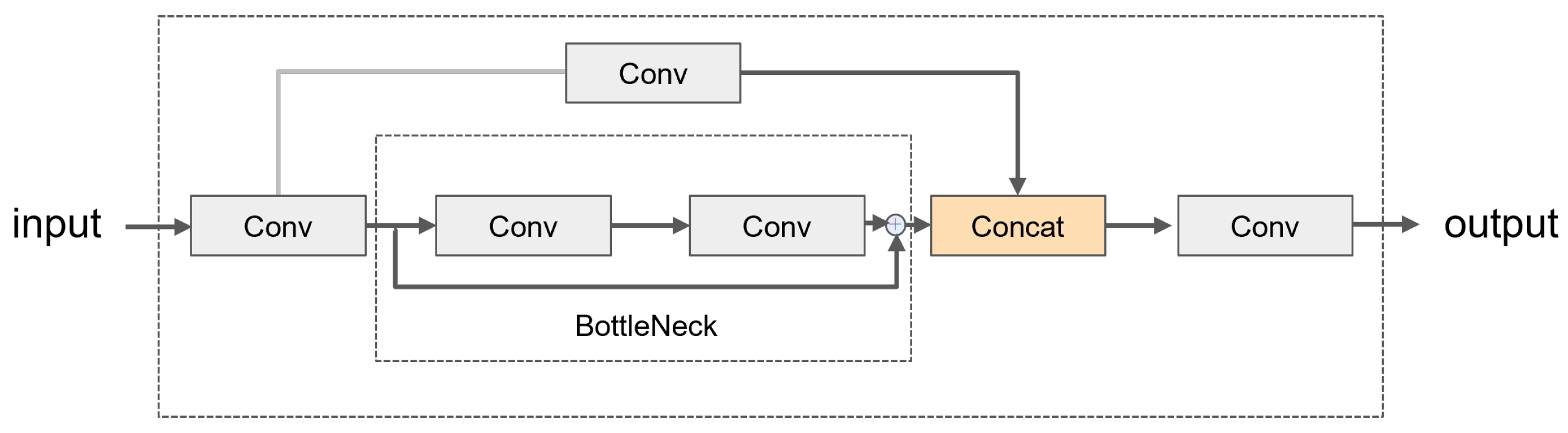
- Substituting the original CSPDarknet53 to Two-Stage FPN (C2f) module with C3 resulted in a lightweight structure for the model.
- Building upon the existing parameters of YOLOv8, three new parameter specifications were introduced, namely Aero-YOLO (extreme), Aero-YOLO (ultra), and Aero-YOLO (omega).
2. Related Works
3. Materials and Methods
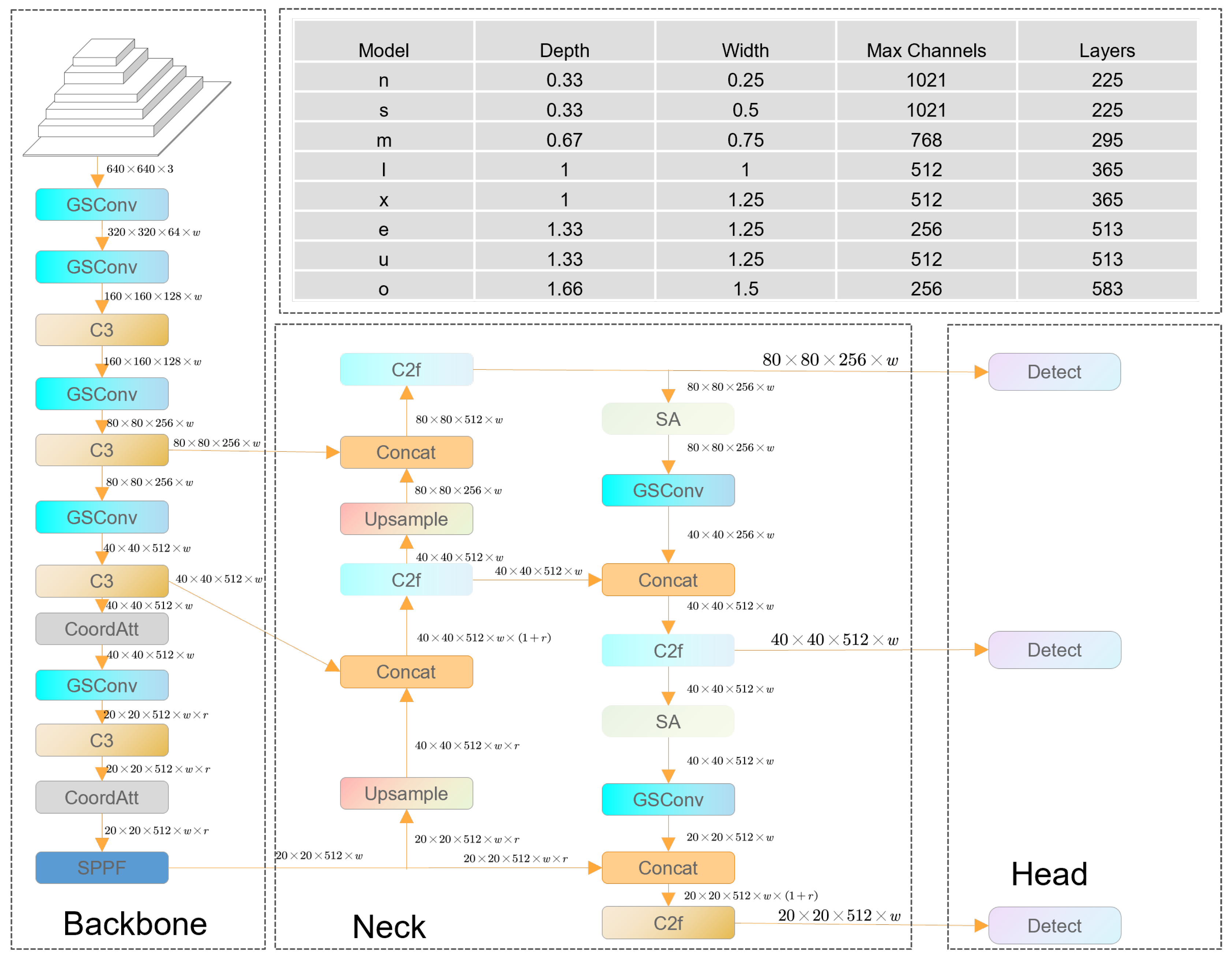
3.1. Aero-YOLO Model Architecture
3.1.1. Object Detection Framework
3.1.2. Lightweight Network Optimization
3.1.3. Feature Extraction Optimization
3.2. The Model Parameters of Aero-YOLO
- Aero-YOLO (extreme): Prioritizes performance enhancement while focusing on improving computational efficiency. It involves a moderate reduction in model size, suitable for resource-constrained scenarios with extensive datasets.
- Aero-YOLO (ultra): Aims to achieve a comprehensive balance by adjusting the proportions of depth, width, and channel numbers. This adjustment seeks the optimal equilibrium among performance, computational complexity, and resource utilization, suitable for general-purpose application scenarios.
- Aero-YOLO (omega): Emphasizes maintaining high performance while reducing computational complexity. It concentrates on optimizing extreme scenarios and complex environments within object detection to achieve more precise detection and localization.
4. Experiments and Results
4.1. Datasets and Experimental Details
4.1.1. VisDrone2019 Dataset
4.1.2. UAV-ROD Dataset
4.1.3. Experimental Environment
4.1.4. Evaluation Metrics
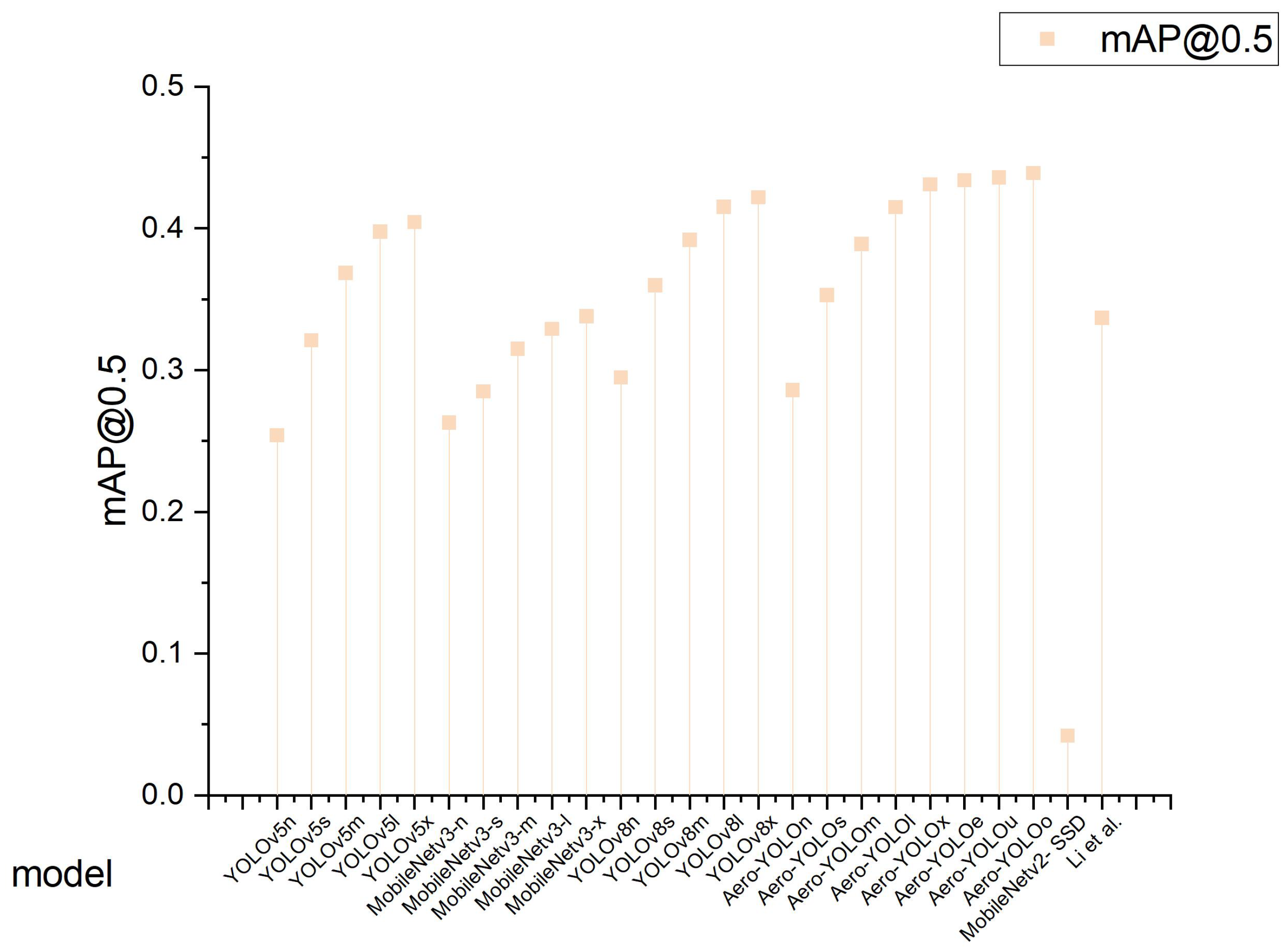
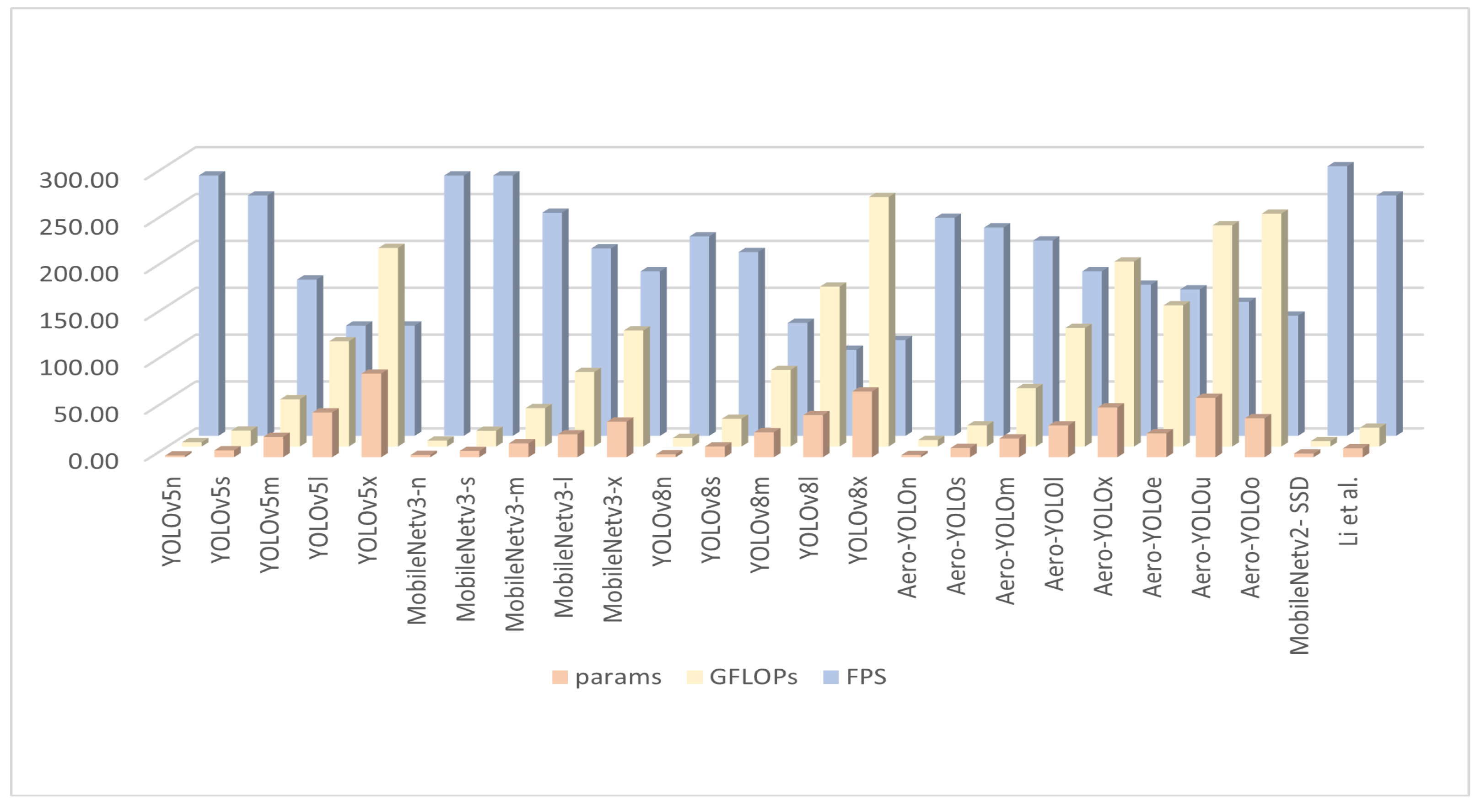
4.2. Results on the VisDrone2019 Dataset
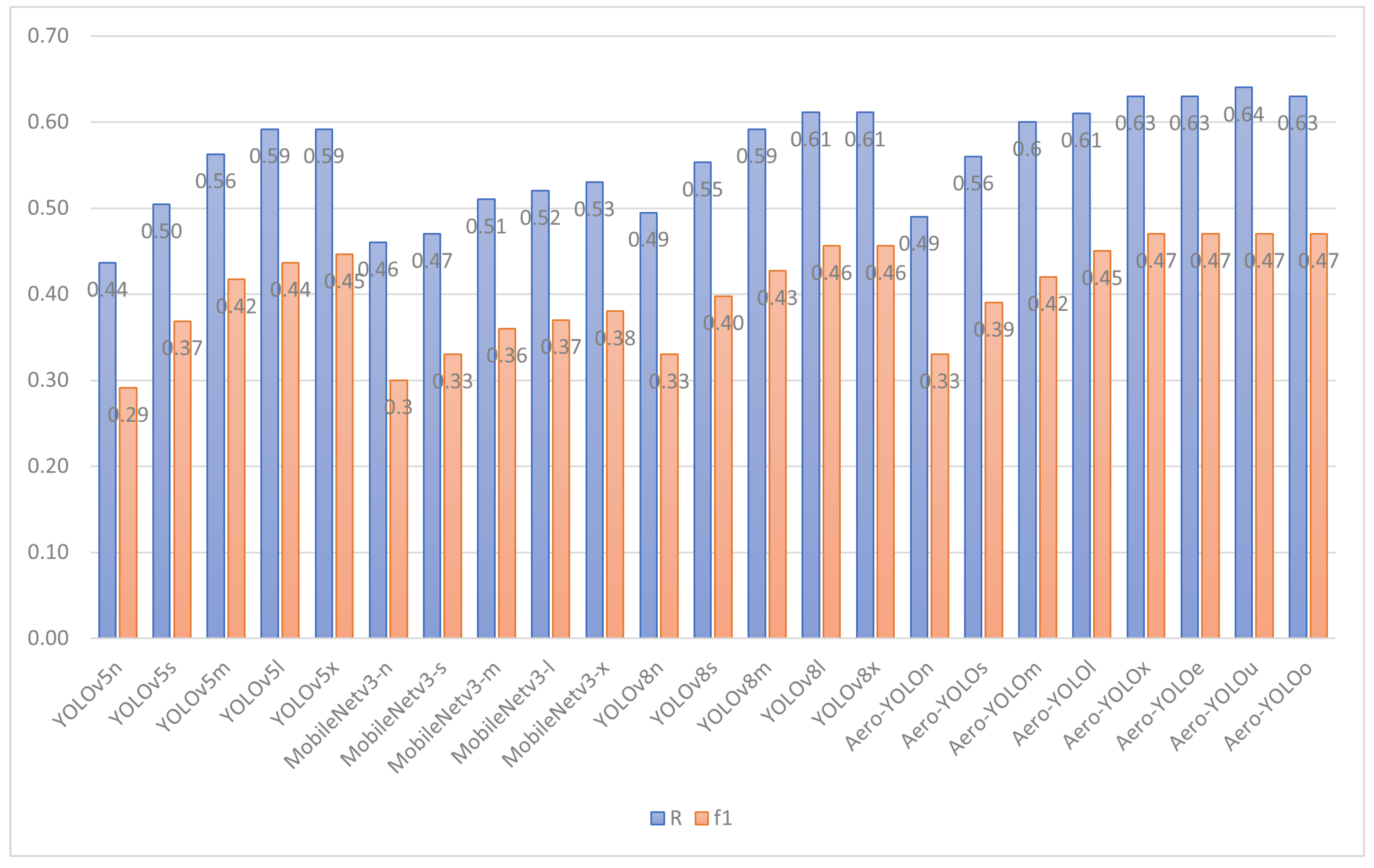
4.3. Results on the UAV-ROD Dataset
4.4. Ablation Experiments
5. Conclusions and Future Outlook
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

| Full Name | Abbreviation |
|---|---|
| unmanned aerial vehicles | UAVs |
| You Only Look Once | YOLO |
| Adaptive Moment Estimation | Adam |
| Stochastic Gradient Descent | SGD |
| CSPDarknet53 to Two-Stage FPN | C2f |
| Aero-YOLO (extreme) | Aero-YOLOe |
| Aero-YOLO (ultra) | Aero-YOLOu |
| Aero-YOLO (omega) | Aero-YOLOo |
| Google Inception Net | GoogleNet |
| Deeper Receptive Field Block | DRFB |
| Vision Transformer Detector | ViTDet |
| Spatial Pyramid Pooling Fusion | SPFF |
| state of the art | SOTA |
| non-maximum suppression | NMS |
| Cross-Stage Partial Network | CSP |
| precision | P |
| recall | R |
| average precision | AP |
| mean average precision | mAP |
| number of model parameters | Params |
| Giga Floating-Point Operations | GFLOPs |
| Floating-Point Operations | FLOPs |
| Frames per Second | FPS |
References
- Zhou, G.; Ambrosia, V.; Gasiewski, A.J.; Bland, G. Foreword to the special issue on unmanned airborne vehicle (UAV) sensing systems for earth observations. IEEE Trans. Geosci. Remote Sens. 2009, 47, 687–689. [Google Scholar] [CrossRef]
- Kellenberger, B.; Marcos, D.; Tuia, D. Detecting mammals in UAV images: Best practices to address a substantially imbalanced dataset with deep learning. Remote Sens. Environ. 2018, 216, 139–153. [Google Scholar] [CrossRef]
- Ma’Sum, M.A.; Arrofi, M.K.; Jati, G.; Arifin, F.; Kurniawan, M.N.; Mursanto, P.; Jatmiko, W. Simulation of intelligent unmanned aerial vehicle (uav) for military surveillance. In Proceedings of the 2013 international conference on advanced computer science and information systems (ICACSIS), Sanur Bali, Indonesia, 28–29 September 2013; pp. 161–166. [Google Scholar]
- Li, X.; Yang, L. Design and implementation of UAV intelligent aerial photography system. In Proceedings of the 2012 4th International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanchang, China, 26–27 August 2012; Volume 2, pp. 200–203. [Google Scholar]
- Tanaka, S.; Senoo, T.; Ishikawa, M. High-speed uav delivery system with non-stop parcel handover using high-speed visual control. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 4449–4455. [Google Scholar]
- Cong, Y.; Fan, B.; Liu, J.; Luo, J.; Yu, H. Speeded up low-rank online metric learning for object tracking. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 922–934. [Google Scholar] [CrossRef]
- Mogili, U.R.; Deepak, B. Review on application of drone systems in precision agriculture. Procedia Comput. Sci. 2018, 133, 502–509. [Google Scholar] [CrossRef]
- Yang, Z.; Pun-Cheng, L.S. Vehicle detection in intelligent transportation systems and its applications under varying environments: A review. Image Vis. Comput. 2018, 69, 143–154. [Google Scholar] [CrossRef]
- Eisenbeiss, H. A mini unmanned aerial vehicle (UAV): System overview and image acquisition. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 36, 1–7. [Google Scholar]
- Konoplich, G.V.; Putin, E.O.; Filchenkov, A.A. Application of deep learning to the problem of vehicle detection in UAV images. In Proceedings of the 2016 XIX IEEE International Conference on Soft Computing and Measurements (SCM), St. Petersburg, Russia, 25–27 May 2016; pp. 4–6. [Google Scholar]
- Vasterling, M.; Meyer, U. Challenges and opportunities for UAV-borne thermal imaging. Therm. Infrared Remote Sens. Sens. Methods Appl. 2013, 17, 69–92. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Feng, K.; Li, W.; Han, J.; Pan, F.; Zheng, D. TS4Net: Two-Stage Sample Selective Strategy for Rotating Object Detection. arXiv 2021, arXiv:2108.03116. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Koopman, B.O. The theory of search. II. Target detection. Oper. Res. 1956, 4, 503–531. [Google Scholar] [CrossRef]
- Wang, X. Intelligent multi-camera video surveillance: A review. Pattern Recognit. Lett. 2013, 34, 3–19. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of theAAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Ultralytics. YOLOv8. Available online: https://docs.ultralytics.com/ (accessed on 21 June 2023).
- JOCHER. Network Data. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 24 December 2022).
- Zhang, R.; Newsam, S.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Multi-scale adversarial network for vehicle detection in UAV imagery. ISPRS J. Photogramm. Remote Sens. 2021, 180, 283–295. [Google Scholar] [CrossRef]
- Han, S.; Yoo, J.; Kwon, S. Real-time vehicle-detection method in bird-view unmanned-aerial-vehicle imagery. Sensors 2019, 19, 3958. [Google Scholar] [CrossRef]
- Mekhalfi, M.L.; Bejiga, M.B.; Soresina, D.; Melgani, F.; Demir, B. Capsule networks for object detection in UAV imagery. Remote Sens. 2019, 11, 1694. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, T.; Fan, X. A ViTDet based dual-source fusion object detection method of UAV. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 628–633. [Google Scholar]
- Mao, Y.; Chen, M.; Wei, X.; Chen, B. Obstacle recognition and avoidance for UAVs under resource-constrained environments. IEEE Access 2020, 8, 169408–169422. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhao, X.; Song, Y. Improved Ship Detection with YOLOv8 Enhanced with MobileViT and GSConv. Electronics 2023, 12, 4666. [Google Scholar] [CrossRef]
- Lin, X.; Song, A. Research on improving pedestrian detection algorithm based on YOLOv5. In Proceedings of the International Conference on Electronic Information Engineering and Data Processing (EIEDP 2023), Nanchang, China, 17–19 March 2023; Volume 12700, pp. 506–511. [Google Scholar]
- Cui, Z.; Wang, X.; Liu, N.; Cao, Z.; Yang, J. Ship detection in large-scale SAR images via spatial shuffle-group enhance attention. IEEE Trans. Geosci. Remote Sens. 2020, 59, 379–391. [Google Scholar] [CrossRef]
- Wan, H.; Chen, J.; Huang, Z.; Feng, Y.; Zhou, Z.; Liu, X.; Yao, B.; Xu, T. Lightweight channel attention and multiscale feature fusion discrimination for remote sensing scene classification. IEEE Access 2021, 9, 94586–94600. [Google Scholar] [CrossRef]
- Cheng, C. Real-time mask detection based on SSD-MobileNetV2. In Proceedings of the 2022 IEEE 5th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 18–20 November 2022; pp. 761–767. [Google Scholar]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A modified YOLOv8 detection network for UAV aerial image recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



| Model | Depth | Width | Max. Channels | Layers |
|---|---|---|---|---|
| n | 0.33 | 0.25 | 1021 | 225 |
| s | 0.33 | 0.50 | 1021 | 225 |
| m | 0.67 | 0.75 | 768 | 295 |
| l | 1.00 | 1.00 | 512 | 365 |
| x | 1.00 | 1.25 | 512 | 365 |
| e | 1.33 | 1.25 | 256 | 513 |
| u | 1.33 | 1.25 | 512 | 513 |
| o | 1.66 | 1.50 | 256 | 583 |
| Layer | Type | Parameters |
|---|---|---|
| 1 | GSConv | [−1, 1, GSConv, [64, 3, 2]] |
| 2 | GSConv | [−1, 1, GSConv, [128, 3, 2]] |
| 3 | C3 | [−1, 3, C3, [128, True]] |
| 4 | GSConv | [−1, 1, GSConv, [256, 3, 2]] |
| 5 | C3 | [−1, 6, C3, [256, True]] |
| 6 | CoordAtt | [−1, 1, CoordAtt, []] |
| 7 | GSConv | [−1, 1, GSConv, [512, 3, 2]] |
| 8 | C3 | [−1, 6, C3, [512, True]] |
| 9 | CoordAtt | [−1, 1, CoordAtt, []] |
| 10 | GSConv | [−1, 1, GSConv, [1024, 3, 2]] |
| 11 | C3 | [−1, 3, C3, [1024, True]] |
| 12 | CoordAtt | [−1, 1, CoordAtt, []] |
| 13 | SPPF | [−1, 1, SPPF, [1024, 5]] |
| Layer | Type | Parameters |
|---|---|---|
| 1 | nn.Upsample | [None, 2, ‘nearest’] |
| 2 | Concat | [−1, 8], 1, Concat, [1] |
| 3 | C2f | [−1, 3, C2f, [512]] |
| 4 | nn.Upsample | [None, 2, ‘nearest’] |
| 5 | Concat | [−1, 3], 1, Concat, [1] |
| 6 | C2f | [−1, 3, C2f, [256]] |
| 7 | Shuffle Attention | [−1, 1, Shuffle Attention, [16, 8]] |
| 8 | GSConv | [−1, 1, GSConv, [256, 3, 2]] |
| 9 | Concat | [[−1, 15], 1, Concat, [1]] |
| 10 | C2f | [−1, 3, C2f, [512]] |
| 11 | Shuffle Attention | [−1, 1, Shuffle Attention, [16, 8]] |
| 12 | GSConv | [−1, 1, GSConv, [512, 3, 2]] |
| 13 | Concat | [[−1, 12], 1, Concat, [1]] |
| 14 | C2f | [−1, 3, C2f, [1024]] |
| 15 | Detect | [[18, 21, 24], 1, Detect, [nc]] |
| Device | Configuration |
|---|---|
| CPU | 13th Gen. Intel(R) Core(TM) i9-13900K |
| GPU | NVIDIA GeForce RTX 4090 |
| System | Windows 10 |
| Framework | Pytorch 2.0.0 |
| IDE | Pycharm 2022.2.2 |
| Python version | version 3.10.9 |
| Methods | P | R | mAP@50 | mAP50-95 | Params (M) | GFLOPs |
|---|---|---|---|---|---|---|
| Aero-YOLOn | 0.980 | 0.971 | 0.993 | 0.916 | 27.7 | 6.7 |
| Aero-YOLOs | 0.984 | 0.975 | 0.993 | 0.93 | 99 | 22.3 |
| Aero-YOLOm | 0.987 | 0.974 | 0.994 | 0.936 | 201.1 | 61.8 |
| Aero-YOLOl | 0.989 | 0.977 | 0.994 | 0.941 | 440 | 125.9 |
| Aero-YOLOx | 0.99 | 0.976 | 0.994 | 0.945 | 531 | 196.6 |
| Aero-YOLOe | 0.989 | 0.977 | 0.994 | 0.944 | 254.9 | 149.9 |
| Aero-YOLOu | 0.991 | 0.98 | 0.995 | 0.946 | 634.1 | 235.1 |
| Aero-YOLOo | 0.992 | 0.979 | 0.996 | 0.947 | 415.8 | 247.3 |
| YOLOv8n | 0.974 | 0.961 | 0.991 | 0.88 | 30.1 | 8.1 |
| YOLOv8s | 0.985 | 0.963 | 0.991 | 0.911 | 111.3 | 28.4 |
| YOLOv8m | 0.984 | 0.969 | 0.993 | 0.925 | 258.4 | 78.7 |
| YOLOv8l | 0.986 | 0.975 | 0.993 | 0.932 | 436.1 | 164.8 |
| YOLOv8x | 0.985 | 0.977 | 0.993 | 0.934 | 681.2 | 257.4 |
| R-RetinaNet | 0.968 | 0.942 | 0.977 | 0.885 | 36.3 | 9.2 |
| Faster R-CNN | 0.972 | 0.951 | 0.980 | 0.912 | 41.4 | 11.7 |
| TS4Net | 0.977 | 0.952 | 0.981 | 0.906 | 37.6 | 9.4 |
| YOLOv5m-CSL | 0.936 | 0.927 | 0.943 | 0.844 | 20.8 | 6.1 |
| CFC-Net | 0.981 | 0.972 | 0.993 | 0.924 | 37.5 | 9.4 |
| Method | Size | R | mAP@50 | F1 | Params (M) | GFLOPs |
|---|---|---|---|---|---|---|
| YOLO v8 | n | 0.49 | 0.295 | 0.33 | 3.2 | 8.7 |
| s | 0.55 | 0.360 | 0.40 | 11.2 | 28.6 | |
| m | 0.59 | 0.392 | 0.43 | 25.9 | 78.9 | |
| l | 0.61 | 0.415 | 0.46 | 43.7 | 165.2 | |
| x | 0.61 | 0.422 | 0.46 | 68.2 | 257.8 | |
| YOLO v8 + GSConv | n | 0.48 | 0.287 | 0.32 | 2.82 | 7.8 |
| s | 0.55 | 0.355 | 0.39 | 10.36 | 26.8 | |
| m | 0.58 | 0.387 | 0.42 | 24.44 | 75.2 | |
| l | 0.60 | 0.410 | 0.45 | 41.69 | 158.9 | |
| x | 0.60 | 0.417 | 0.45 | 65.12 | 248.0 | |
| YOLO v8 + GSConv + C3 | n | 0.47 | 0.274 | 0.31 | 2.55 | 7.0 |
| s | 0.54 | 0.352 | 0.39 | 9.29 | 23.1 | |
| m | 0.58 | 0.384 | 0.42 | 20.89 | 62.1 | |
| l | 0.60 | 0.406 | 0.45 | 34.69 | 125.9 | |
| x | 0.60 | 0.412 | 0.45 | 54.18 | 196.4 | |
| YOLO v8 + GSConv + C3 + Double Shuffle Attention + Adam | n | 0.48 | 0.294 | 0.33 | 2.77 | 7.3 |
| m | 0.58 | 0.383 | 0.41 | 22.22 | 64.2 | |
| x | 0.62 | 0.411 | 0.44 | 57.63 | 201.9 | |
| YOLO v8 + GSConv + C3 + Double Shuffle Attention + SGD | n | 0.49 | 0.293 | 0.33 | 2.77 | 7.3 |
| s | 0.55 | 0.355 | 0.39 | 9.95 | 24.8 | |
| m | 0.59 | 0.391 | 0.43 | 22.22 | 64.2 | |
| l | 0.61 | 0.414 | 0.45 | 36.90 | 129.5 | |
| x | 0.62 | 0.422 | 0.46 | 57.63 | 201.9 | |
| Aero-YOLO | n | 0.49 | 0.286 | 0.33 | 2.40 | 7.0 |
| s | 0.56 | 0.353 | 0.39 | 9.91 | 22.6 | |
| m | 0.60 | 0.389 | 0.42 | 20.12 | 62.2 | |
| l | 0.61 | 0.415 | 0.45 | 34.02 | 126.6 | |
| x | 0.63 | 0.431 | 0.47 | 53.13 | 197.4 | |
| e | 0.63 | 0.434 | 0.47 | 25.51 | 150.7 | |
| u | 0.64 | 0.436 | 0.47 | 63.44 | 236.0 | |
| o | 0.63 | 0.439 | 0.47 | 41.61 | 248.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Yang, Z.; Li, Z.; Li, J. Aero-YOLO: An Efficient Vehicle and Pedestrian Detection Algorithm Based on Unmanned Aerial Imagery. Electronics 2024, 13, 1190. https://doi.org/10.3390/electronics13071190
Shao Y, Yang Z, Li Z, Li J. Aero-YOLO: An Efficient Vehicle and Pedestrian Detection Algorithm Based on Unmanned Aerial Imagery. Electronics. 2024; 13(7):1190. https://doi.org/10.3390/electronics13071190
Chicago/Turabian StyleShao, Yifan, Zhaoxu Yang, Zhongheng Li, and Jun Li. 2024. "Aero-YOLO: An Efficient Vehicle and Pedestrian Detection Algorithm Based on Unmanned Aerial Imagery" Electronics 13, no. 7: 1190. https://doi.org/10.3390/electronics13071190
APA StyleShao, Y., Yang, Z., Li, Z., & Li, J. (2024). Aero-YOLO: An Efficient Vehicle and Pedestrian Detection Algorithm Based on Unmanned Aerial Imagery. Electronics, 13(7), 1190. https://doi.org/10.3390/electronics13071190