
Incorporating Entity Type-Aware and Word–Word Relation-Aware Attention in Generative Named Entity Recognition


Abstract
:1. Introduction
- We propose a generative NER framework which merges entity-type embedding and word–word relation representation to improve named entity recognition performance.
- We leverage two novel attention mechanisms in the NER framework, namely, entity type-aware attention and word–word relation-aware attention, improving the interaction between entities, entity types, and word–word relations for better contextual information.
- We present a series of experiments demonstrating the effectiveness of our method against various baselines. Ablation studies further show the contribution of each component within our approach, confirming their individual effectiveness.
2. Related Work
2.1. Named Entity Recognition
2.2. Attention Mechanism
3. Generative NER Task Formulation
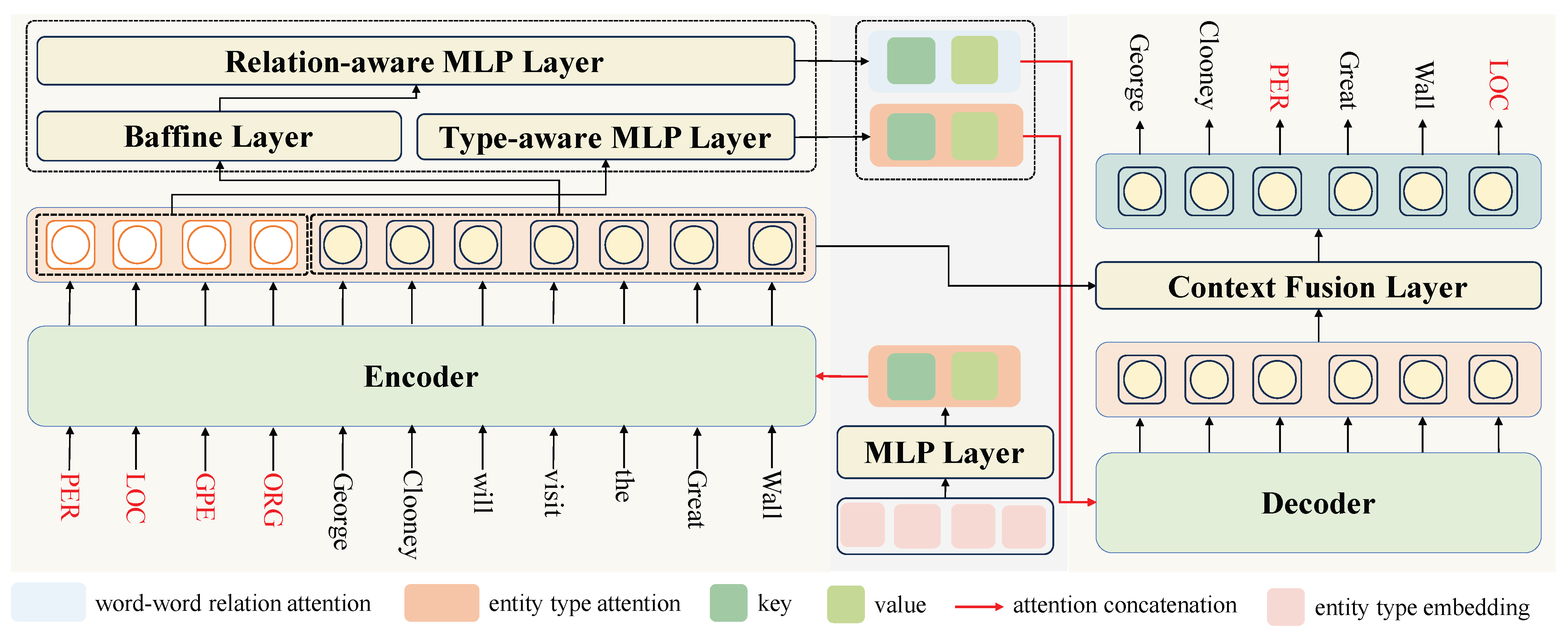
4. Methodology
4.1. Model Overview
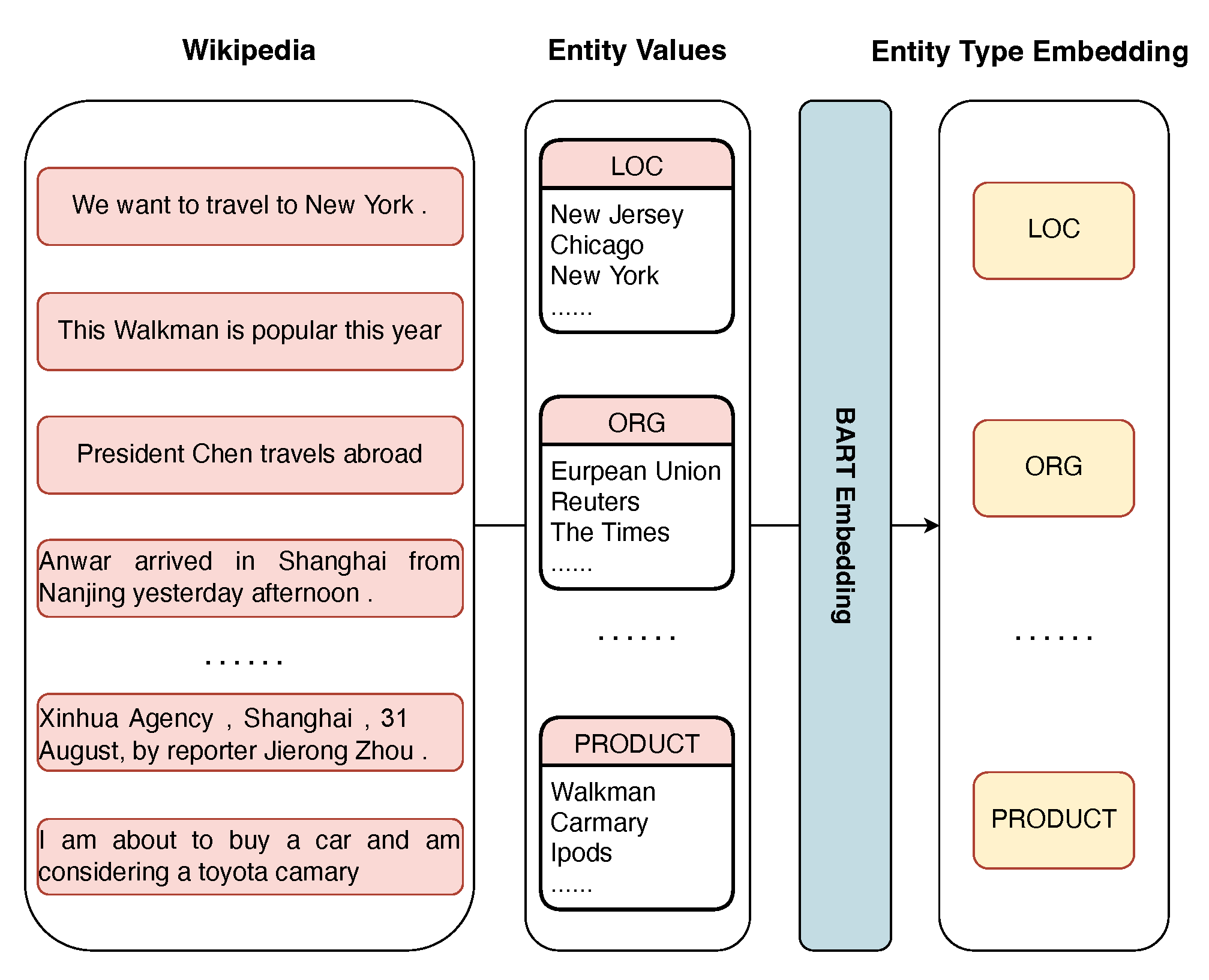
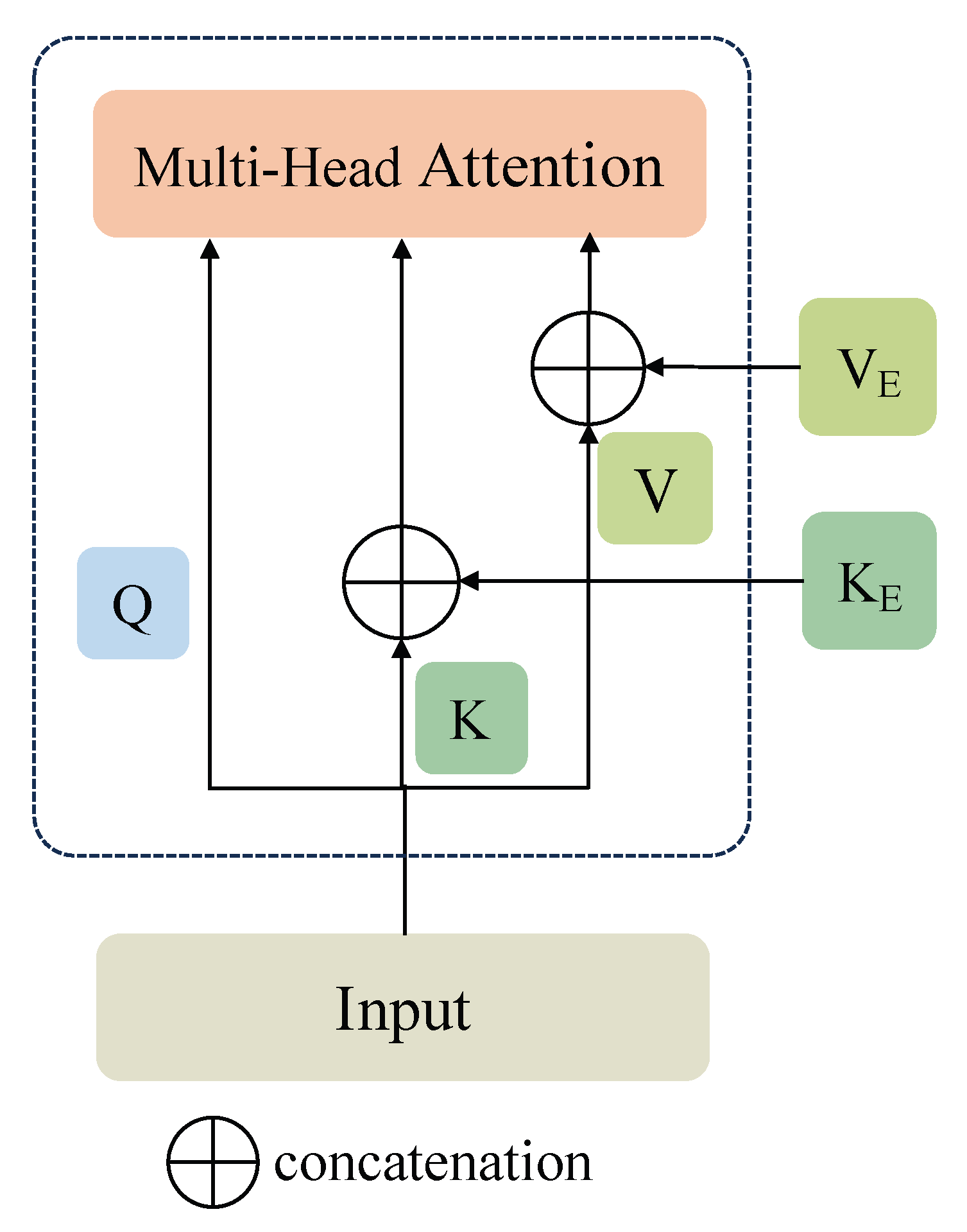
4.2. Entity Type Aware Attention
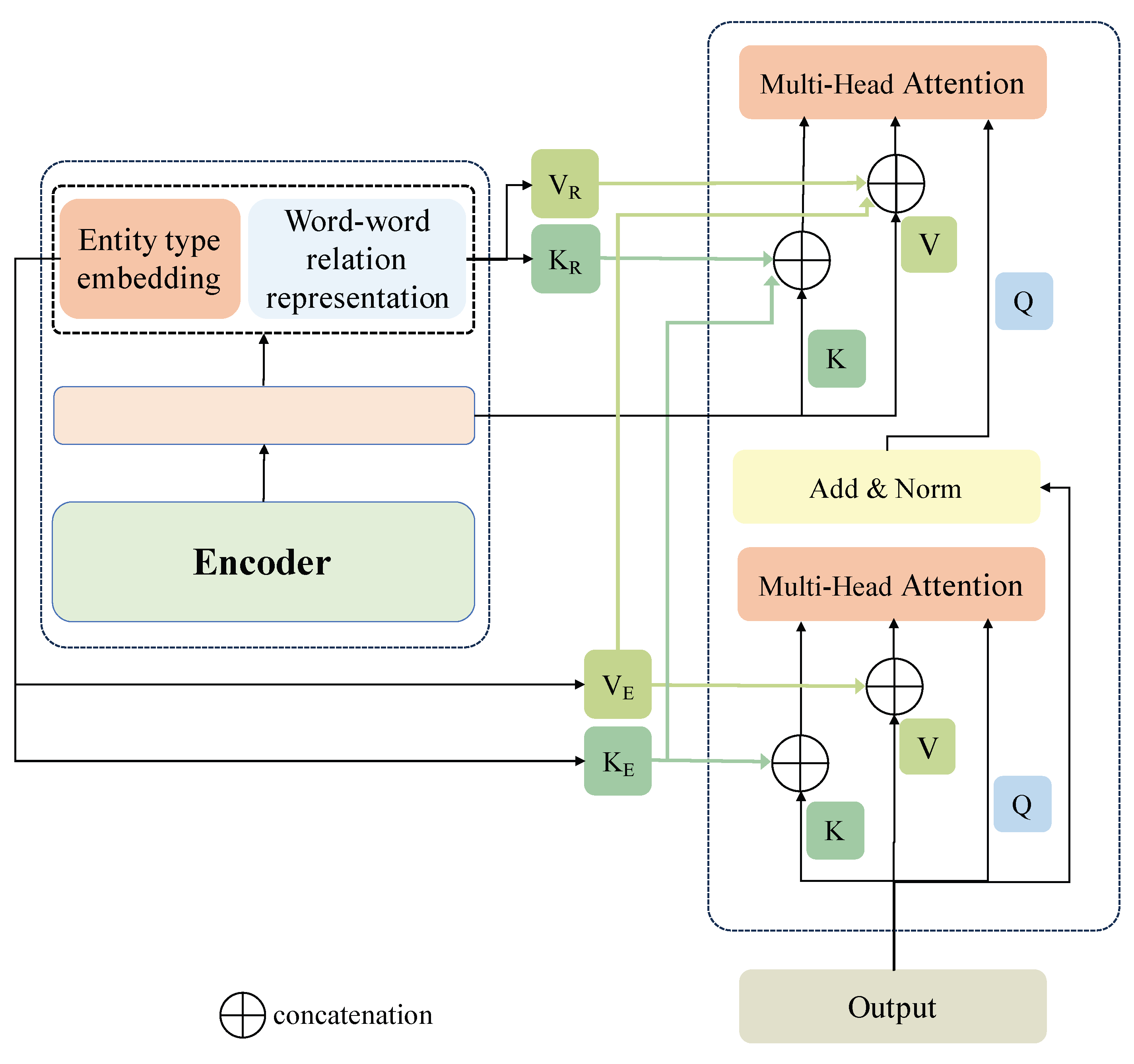
4.3. Word–Word Relation-Aware Attention
4.4. Entity Decoding
5. Experiments
5.1. Datasets
5.2. Implementation Details
5.3. Evaluation Metrics
5.4. Comparative Baselines
- SH [7] propose the use of hypergraphs to address the NER task.
- Seq2Seq [14] obtains tokens with the labels in a sequence.
- BiaffineNER [15] offers a bi-affine module for span-based models to explore spans.
- BartNER [10] offers a unified NER model with a pointer generating the start–end indexes of entities and types.
- DebiasNER [11] designs data augmentation to eliminate incorrect biases from a causality perspective.
- W2NER [37] models the unified NER as word–word relation classification to tackle the different NER tasks.
- LatticeLSTM [56] probes a lattice LSTM encoding the characters and words matching a lexicon.
- TENER [41] uses an encoder to consider character, word, direction, relative distance, and unscaled attention.
- LGN [67] uses a lexicon-based graph neural network with global semantics to interact among characters, words, and sentence semantics.
- FLAT [42] is a flat-lattice model that converts the lattice structure into a flat structure.
- Lexicon [68] uses lexical knowledge in Chinese NER based on a collaborative graph network.
- LR-CNN [69] uses a CNN-based approach with lexicons via a rethinking mechanism.
- PLTE [70] uses the characters and matches lexical words in parallel via the transformer.
- SoftLexcion [71] merges the word lexicon into the character representations and adjusts the character representation layer.
- MECT [72] uses a multi-metadata embedding-based cross-transformer that fuses the characters’ structural information.
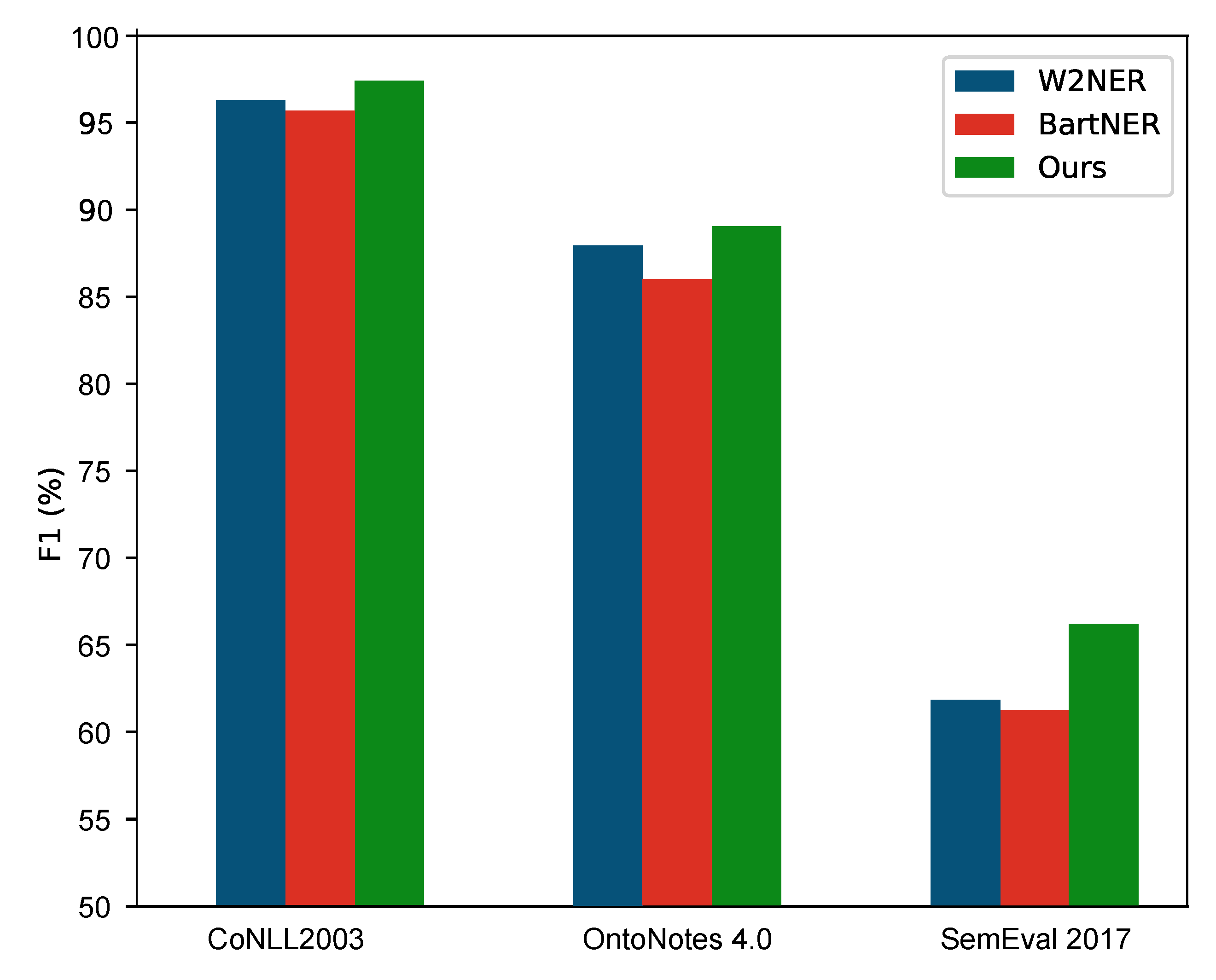
5.5. Results
6. Analysis and Discussion
6.1. Ablation Study
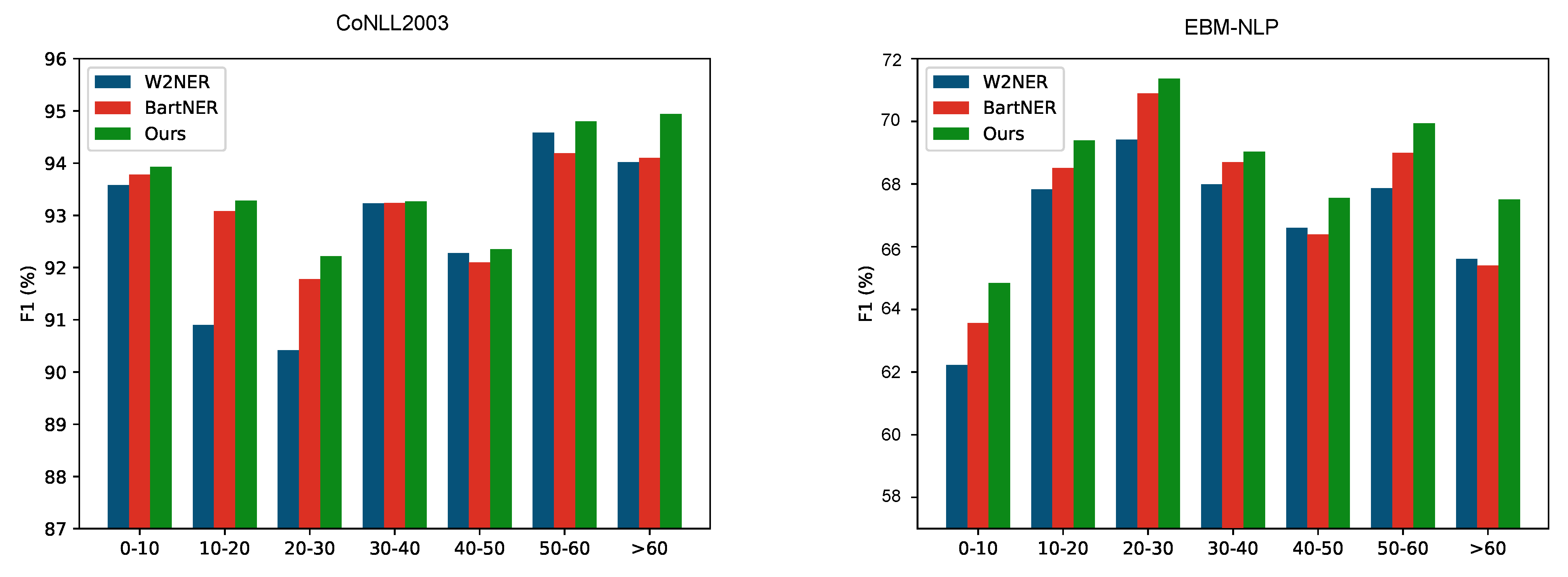
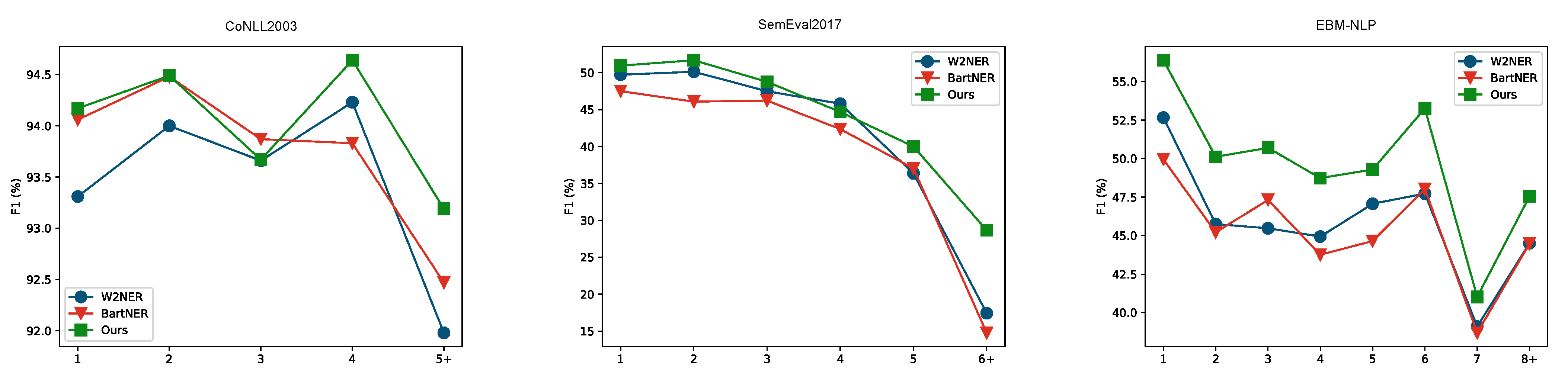
6.2. Effect on Long Sentences
6.3. Effect on Long Entities
6.4. Effectiveness for Entity Boundary
6.5. Case Study
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aliod, D.M.; van Zaanen, M.; Smith, D. Named Entity Recognition for Question Answering. In Proceedings of the ALTA 2006; Cavedon, L., Zukerman, I., Eds.; Australasian Language Technology Association: Sydney, NSW, Australia, 2006; pp. 51–58. [Google Scholar]
- Li, Q.; Ji, H. Incremental Joint Extraction of Entity Mentions and Relations. In Proceedings of the ACL 2014, Baltimore, MD, USA, 22–27 June 2014; pp. 402–412. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Entity and Relation Extraction. In Proceedings of the NAACL-HLT 2021, Online, 6–11 June 2021; pp. 50–61. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the NAACL HLT 2016, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions. In Proceedings of the EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017; pp. 2670–2680. [Google Scholar]
- Panchendrarajan, R.; Amaresan, A. Bidirectional LSTM-CRF for Named Entity Recognition. In Proceedings of the PACLIC 2018, Hong Kong, China, 1–3 December 2018; Politzer-Ahles, S., Hsu, Y., Huang, C., Yao, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018. [Google Scholar]
- Wang, B.; Lu, W. Combining Spans into Entities: A Neural Two-Stage Approach for Recognizing Discontiguous Entities. In Proceedings of the EMNLP, Hong Kong, China, 3–7 November 2019; pp. 6215–6223. [Google Scholar]
- Yu, B.; Zhang, Z.; Sheng, J.; Liu, T.; Wang, Y.; Wang, Y.; Wang, B. Semi-Open Information Extraction. In Proceedings of the WWW 2021, Online, 19–23 April 2021; pp. 1661–1672. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A Unified MRC Framework for Named Entity Recognition. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 5849–5859. [Google Scholar]
- Yan, H.; Gui, T.; Dai, J.; Guo, Q.; Zhang, Z.; Qiu, X. A Unified Generative Framework for Various NER Subtasks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 5808–5822. [Google Scholar]
- Zhang, S.; Shen, Y.; Tan, Z.; Wu, Y.; Lu, W. De-Bias for Generative Extraction in Unified NER Task. In Proceedings of the ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 808–818. [Google Scholar]
- Sang, E.F.T.K.; Meulder, F.D. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the Seventh Conference on Natural Language Learning, CoNLL 2003, Held in cooperation with HLT-NAACL 2003, Edmonton, AB, Canada, 31 May– 1 June 2003; pp. 142–147. [Google Scholar]
- Karimi, S.; Metke-Jimenez, A.; Kemp, M.; Wang, C. Cadec: A corpus of adverse drug event annotations. J. Biomed. Inform. 2015, 55, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Straková, J.; Straka, M.; Hajic, J. Neural Architectures for Nested NER through Linearization. In Proceedings of the ACL 2019, Florence, Italy, 28 July–2 August 2019; pp. 5326–5331. [Google Scholar]
- Yu, J.; Bohnet, B.; Poesio, M. Named Entity Recognition as Dependency Parsing. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 6470–6476. [Google Scholar]
- Shen, Y.; Ma, X.; Tan, Z.; Zhang, S.; Wang, W.; Lu, W. Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition. In Proceedings of the ACL/IJCNLP, Bangkok, Thailand, 1–6 August 2021; pp. 2782–2794. [Google Scholar]
- Dai, X.; Karimi, S.; Hachey, B.; Paris, C. An Effective Transition-based Model for Discontinuous NER. In Proceedings of the ACL, Virtual, 5–10 July 2020; pp. 5860–5870. [Google Scholar]
- Li, F.; Lin, Z.; Zhang, M.; Ji, D. A Span-Based Model for Joint Overlapped and Discontinuous Named Entity Recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 4814–4828. [Google Scholar]
- Ratinov, L.; Roth, D. Design Challenges and Misconceptions in Named Entity Recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning, CoNLL 2009, Boulder, CO, USA, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P.P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Metke-Jimenez, A.; Karimi, S. Concept Identification and Normalisation for Adverse Drug Event Discovery in Medical Forums. In Proceedings of the BMDID@ISWC, Kobe, Japan, 17 October 2016. [Google Scholar]
- Chiu, J.P.C.; Nichols, E. Named Entity Recognition with Bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Muis, A.O.; Lu, W. Learning to Recognize Discontiguous Entities. In Proceedings of the EMNLP 2016, Austin, TX, USA, 1–5 November 2016; pp. 75–84. [Google Scholar]
- Ma, X.; Hovy, E.H. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the ACL 2016, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Zhou, P.; Zheng, S.; Xu, J.; Qi, Z.; Bao, H.; Xu, B. Joint Extraction of Multiple Relations and Entities by Using a Hybrid Neural Network. In Proceedings of the Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data—16th China National Conference, CCL 2017, and 5th International Symposium, NLP-NABD 2017; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10565, pp. 135–146. [Google Scholar]
- Ju, M.; Miwa, M.; Ananiadou, S. A Neural Layered Model for Nested Named Entity Recognition. In Proceedings of the NAACL-HLT 2018; Walker, M.A., Ji, H., Stent, A., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2018; pp. 1446–1459. [Google Scholar]
- Tang, B.; Hu, J.; Wang, X.; Chen, Q. Recognizing continuous and discontinuous adverse drug reaction mentions from social media using LSTM-CRF. Wirel. Commun. Mob. Comput. 2018, 2018, 2379208. [Google Scholar] [CrossRef]
- Wang, J.; Shou, L.; Chen, K.; Chen, G. Pyramid: A Layered Model for Nested Named Entity Recognition. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 5918–5928. [Google Scholar]
- Tan, C.; Qiu, W.; Chen, M.; Wang, R.; Huang, F. Boundary Enhanced Neural Span Classification for Nested Named Entity Recognition. In Proceedings of the AAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 9016–9023. [Google Scholar]
- Ouchi, H.; Suzuki, J.; Kobayashi, S.; Yokoi, S.; Kuribayashi, T.; Konno, R.; Inui, K. Instance-Based Learning of Span Representations: A Case Study through Named Entity Recognition. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 6452–6459. [Google Scholar]
- Zhang, F.; Ma, L.; Wang, J.; Cheng, J. An MRC and adaptive positive-unlabeled learning framework for incompletely labeled named entity recognition. Int. J. Intell. Syst. 2022, 37, 9580–9597. [Google Scholar] [CrossRef]
- Lin, H.; Lu, Y.; Han, X.; Sun, L. Sequence-to-Nuggets: Nested Entity Mention Detection via Anchor-Region Networks. In Proceedings of the ACL 2019, Florence, Italy, 28 July–2 August 2019; pp. 5182–5192. [Google Scholar]
- Lu, W.; Roth, D. Joint mention extraction and classification with mention hypergraphs. In Proceedings of the EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; pp. 857–867. [Google Scholar]
- Muis, A.O.; Lu, W. Labeling Gaps Between Words: Recognizing Overlapping Mentions with Mention Separators. In Proceedings of the EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017; pp. 2608–2618. [Google Scholar]
- Katiyar, A.; Cardie, C. Nested Named Entity Recognition Revisited. In Proceedings of the NAACL-HLT 2018, New Orleans, LO, USA, 1–6 June 2018; pp. 861–871. [Google Scholar]
- Wang, Y.; Yu, B.; Zhu, H.; Liu, T.; Yu, N.; Sun, L. Discontinuous Named Entity Recognition as Maximal Clique Discovery. In Proceedings of the ACL/IJCNLP 2021, Bangkok, Thailand, 1–6 August 2021; pp. 764–774. [Google Scholar]
- Li, J.; Fei, H.; Liu, J.; Wu, S.; Zhang, M.; Teng, C.; Ji, D.; Li, F. Unified Named Entity Recognition as Word-Word Relation Classification. In Proceedings of the AAAI 2022, Virtual, 22 February–1 March 2022; pp. 10965–10973. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Rei, M.; Crichton, G.K.O.; Pyysalo, S. Attending to Characters in Neural Sequence Labeling Models. In Proceedings of the COLING 2016, Osaka, Japan, 11–16 December 2016; pp. 309–318. [Google Scholar]
- Tan, Z.; Wang, M.; Xie, J.; Chen, Y.; Shi, X. Deep Semantic Role Labeling With Self-Attention. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LO, USA, 2–7 February 2018; pp. 4929–4936. [Google Scholar]
- Yan, H.; Deng, B.; Li, X.; Qiu, X. TENER: Adapting Transformer Encoder for Named Entity Recognition. arXiv 2019, arXiv:1911.04474. [Google Scholar]
- Li, X.; Yan, H.; Qiu, X.; Huang, X. FLAT: Chinese NER Using Flat-Lattice Transformer. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 6836–6842. [Google Scholar]
- Fu, Y.; Tan, C.; Chen, M.; Huang, S.; Huang, F. Nested Named Entity Recognition with Partially-Observed TreeCRFs. AAAI Conf. Artif. Intell. 2021, 35, 12839–12847. [Google Scholar] [CrossRef]
- Aly, R.; Vlachos, A.; McDonald, R. Leveraging Type Descriptions for Zero-shot Named Entity Recognition and Classification. In Proceedings of the ACL/IJCNLP 2021, Bangkok, Thailand, 1–6 August 2021; pp. 1516–1528. [Google Scholar]
- Mo, Y.; Tang, H.; Liu, J.; Wang, Q.; Xu, Z.; Wang, J.; Wu, W.; Li, Z. Multi-Task Transformer with Relation-Attention and Type-Attention for Named Entity Recognition. In Proceedings of the ICASSP 2023, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, R.; Li, Y.; Tao, L.; Liang, D.; Zheng, H.T. Are we ready for a new paradigm shift? A survey on visual deep mlp. Patterns 2022, 3, 100520. [Google Scholar] [CrossRef]
- Mo, Y.; Yang, J.; Liu, J.; Wang, Q.; Chen, R.; Wang, J.; Li, Z. mCL-NER: Cross-Lingual Named Entity Recognition via Multi-view Contrastive Learning. arXiv 2023, arXiv:2308.09073. [Google Scholar] [CrossRef]
- Shang, Y.; Huang, H.; Mao, X. OneRel: Joint Entity and Relation Extraction with One Module in One Step. In Proceedings of the AAAI 2022, Virtual, 22 February–1 March 2022; pp. 11285–11293. [Google Scholar]
- Zhu, E.; Li, J. Boundary Smoothing for Named Entity Recognition. In Proceedings of the ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 7096–7108. [Google Scholar]
- Pradhan, S.; Moschitti, A.; Xue, N.; Ng, H.T.; Björkelund, A.; Uryupina, O.; Zhang, Y.; Zhong, Z. Towards Robust Linguistic Analysis using OntoNotes. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, CoNLL 2013, Sofia, Bulgaria, 8–9 August 2013; pp. 143–152. [Google Scholar]
- Pradhan, S.; Moschitti, A.; Xue, N.; Uryupina, O.; Zhang, Y. CoNLL-2012 Shared Task: Modeling Multilingual Unrestricted Coreference in OntoNotes. In Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning—Proceedings of the Shared Task: Modeling Multilingual Unrestricted Conference in OntoNotes, EMNLP-CoNLL 2012, Jeju Island, Republic of Korea, 12–14 July 2012; pp. 1–40. [Google Scholar]
- Weischedel, R.; Pradhan, S.; Ramshaw, L.; Palmer, M.; Xue, N.; Marcus, M.; Taylor, A.; Greenberg, C.; Hovy, E.; Belvin, R.; et al. Ontonotes Release 4.0. LDC2011T03; Linguistic Data Consortium: Philadelphia, PA, USA, 2011. [Google Scholar]
- Levow, G.A. The third international Chinese language processing bakeoff: Word segmentation and named entity recognition. In Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing, Sydney, Australia, 22–23 July 2006; pp. 108–117. [Google Scholar]
- He, H.; Sun, X. F-Score Driven Max Margin Neural Network for Named Entity Recognition in Chinese Social Media. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, 3–7 April 2017; Volume 2: Short Papers, 2017. Association for Computational Linguistics: Kerrville, TX, USA, 2017; pp. 713–718. [Google Scholar]
- Peng, N.; Dredze, M. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; pp. 548–554. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. Association for Computational Linguistics: Kerrville, TX, USA, 2018; pp. 1554–1564. [Google Scholar]
- Nye, B.E.; Li, J.J.; Patel, R.; Yang, Y.; Marshall, I.J.; Nenkova, A.; Wallace, B.C. A Corpus with Multi-Level Annotations of Patients, Interventions and Outcomes to Support Language Processing for Medical Literature. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. Association for Computational Linguistics: Kerrville, TX, USA, 2018; pp. 197–207. [Google Scholar]
- Augenstein, I.; Das, M.; Riedel, S.; Vikraman, L.; McCallum, A. SemEval 2017 Task 10: ScienceIE - Extracting Keyphrases and Relations from Scientific Publications. In Proceedings of the 11th International Workshop on Semantic Evaluation, SemEval@ACL 2017, Vancouver, BC, Canada, 3–4 August 2017; pp. 546–555. [Google Scholar]
- Kim, S.; Martínez, D.; Cavedon, L.; Yencken, L. Automatic classification of sentences to support Evidence Based Medicine. BMC Bioinform. 2011, 12, S5. [Google Scholar] [CrossRef]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 3613–3618. [Google Scholar]
- Gu, Y.; Tinn, R.; Cheng, H.; Lucas, M.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. ACM Trans. Comput. Health 2022, 3, 2:1–2:23. [Google Scholar] [CrossRef]
- Hu, D.; Hou, X.; Du, X.; Zhou, M.; Jiang, L.; Mo, Y.; Shi, X. VarMAE: Pre-training of Variational Masked Autoencoder for Domain-adaptive Language Understanding. In Proceedings of the EMNLP Findings 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6276–6286. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Shao, Y.; Geng, Z.; Liu, Y.; Dai, J.; Yang, F.; Zhe, L.; Bao, H.; Qiu, X. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation. arXiv 2021, arXiv:2109.05729. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 4582–4597. [Google Scholar]
- Gui, T.; Zou, Y.; Zhang, Q.; Peng, M.; Fu, J.; Wei, Z.; Huang, X. A Lexicon-Based Graph Neural Network for Chinese NER. In Proceedings of the EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 1040–1050. [Google Scholar]
- Sui, D.; Chen, Y.; Liu, K.; Zhao, J.; Liu, S. Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network. In Proceedings of the EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 3828–3838. [Google Scholar]
- Gui, T.; Ma, R.; Zhang, Q.; Zhao, L.; Jiang, Y.; Huang, X. CNN-Based Chinese NER with Lexicon Rethinking. In Proceedings of the IJCAI 2019, Macao, China, 10–16 August 2019; pp. 4982–4988. [Google Scholar]
- Xue, M.; Yu, B.; Liu, T.; Zhang, Y.; Meng, E.; Wang, B. Porous Lattice Transformer Encoder for Chinese NER. In Proceedings of the COLING 2020, Online, 8–13 December 2020; pp. 3831–3841. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Wei, Z.; Huang, X. Simplify the Usage of Lexicon in Chinese NER. In Proceedings of the ACL 2020, Virtual, 5–10 July 2020; pp. 5951–5960. [Google Scholar]
- Wu, S.; Song, X.; Feng, Z. MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition. In Proceedings of the ACL/IJCNLP 2021, Bangkok, Thailand, 1–6 August 2021; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 1529–1539. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:arXiv1810.04805. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CoNLL 2003 | Ontonotes 5.0 | Ontonotes 4.0 | MSRA | Resume | ||
|---|---|---|---|---|---|---|
| #sentences | 20,744 | 76,714 | 24,371 | 48,442 | 4759 | 1890 |
| #entities | 36,431 | 111,868 | 30,783 | 81,249 | 16,565 | 2677 |
| SemEval 2017 | EBM-NLP | |
|---|---|---|
| #entities | 5730 | 63,693 |
| #unique entities | 1697 | 47,916 |
| #single-word entities | 18% | 19% |
| #entities, word length ≥ 3 | 51% | 51% |
| #entities, word length ≥ 5 | 22% | 30% |
| Hyper-Parameters | Range | Final |
|---|---|---|
| Batch Size | [16, 32, 64] | 16/32 |
| Dropout | [0.2, 0.3, 0.5] | 0.5 |
| Learning Rate for Bart | [5 , 1 , 5 , 1 ] | 1 |
| Learning Rate for Other components | [5 , 1 , 5 , 1 ] | 5 |
| Weight Decay | [0, 0.01] | 0.01 |
| Warmup Ratio | [0, 0.01] | 0.01 |
| Max Sequence Length | [64, 128, 512] | 128 |
| Down_dim | [128, 256, 512] | 512 |
| Up_dim | [512, 768, 1024] | 1024 |
| MLP-hidden size | [128, 256] | 128 |
| Model | CoNLL2003 | OntoNotes 5.0 | ||||
|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |
| LSTM-CRF/Stack-LSTM [4] | - | - | 90.94 | - | - | - |
| ID-CNNs [5] | - | - | 90.65 | - | - | 86.84 |
| SH [7] | - | - | 90.50 | - | - | - |
| Seq2Seq [14] | - | - | 92.98 | - | - | - |
| BiaffineNER [15] | 92.91 | 92.13 | 92.52 | 90.01 | 89.77 | 89.89 |
| BartNER [10] | 92.61 | 93.87 | 93.24 | 89.99 | 90.77 | 90.38 |
| DebiasNER [11] | 92.78 | 93.51 | 93.14 | 89.77 | 91.07 | 90.42 |
| W2NER [37] | 92.71 | 93.44 | 93.07 | 90.03 | 90.97 | 90.50 |
| blackOurs | 93.14 | 93.65 | 93.54 | 90.13 | 91.59 | 90.84 |
| MODEL | OntoNotes 4.0 | MSRA | Resume | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | P | R | F | P | R | F | |
| LatticeLSTM [56] | 76.35 | 71.56 | 73.88 | 93.57 | 92.79 | 93.18 | 94.81 | 94.11 | 94.46 | 53.04 | 62.25 | 58.79 |
| TENER [41] | - | - | 72.43 | - | - | 92.74 | - | - | 95.00 | - | - | 58.17 |
| LGN [67] | 76.40 | 72.60 | 74.45 | 94.50 | 92.93 | 93.71 | 95.37 | 94.84 | 95.11 | 57.14 | 66.67 | 59.92 |
| FLAT [42] | - | - | 81.82 | - | - | 96.09 | - | - | 95.86 | - | - | 68.55 |
| Lexicon [68] | 75.06 | 74.52 | 74.79 | 94.01 | 92.93 | 93.47 | - | - | - | - | - | 63.09 |
| LR-CNN [69] | 76.40 | 72.60 | 74.45 | 94.50 | 92.93 | 93.71 | 95.37 | 94.84 | 95.11 | - | - | 59.92 |
| PLTE[BERT] [70] | 79.62 | 81.82 | 80.60 | 94.91 | 94.15 | 94.53 | 96.16 | 96.75 | 96.45 | 72.00 | 66.67 | 69.23 |
| SoftLexicon [71] | 83.41 | 82.21 | 82.81 | 95.75 | 95.10 | 95.42 | 96.08 | 96.13 | 96.11 | 70.94 | 67.02 | 70.50 |
| MECT[BERT] [72] | - | - | 82.57 | - | - | 96.24 | - | - | 95.98 | - | - | 70.43 |
| BartNER [10] | 79.18 | 80.21 | 79.69 | 95.30 | 94.75 | 95.86 | 96.72 | 90.90 | 94.21 | 67.25 | 63.88 | 65.52 |
| W2NER [37] | 82.31 | 83.36 | 83.08 | 96.12 | 96.08 | 96.10 | 96.96 | 96.35 | 96.65 | 70.84 | 73.87 | 72.32 |
| blackOurs | 83.39 | 87.92 | 85.68 | 96.26 | 95.93 | 96.62 | 96.03 | 96.85 | 96.96 | 69.87 | 68.32 | 72.68 |
| Model | SemEval 2017 | EBM-NLP | ||||
|---|---|---|---|---|---|---|
| P | R | F | P | R | F | |
| SciBERT [60] | - | - | - | - | - | 71.18 |
| PubMedBERT [61] | - | - | - | - | - | 73.38 |
| VarMAE [62] | - | - | - | - | - | 76.01 |
| TIAL UW [58] | - | - | 44.00 | - | - | - |
| BartNER [10] | 38.36 | 47.92 | 42.16 | 51.22 | 47.84 | 40.96 |
| W2NER [37] | 49.92 | 44.68 | 47.16 | 66.22 | 38.84 | 48.96 |
| blackOurs | 53.69 | 63.83 | 57.64 | 63.16 | 68.61 | 71.89 |
| Model | CoNLL2003 | OntoNotes 5.0 |
|---|---|---|
| baseline | 92.82 | 90.02 |
| + rel-att | 93.19 ↑0.37 | 90.32 ↑0.30 |
| + type-att | 93.39 ↑0.57 | 90.48 ↑0.46 |
| + rel-att & type-att | 93.54 ↑0.72 | 90.84 ↑0.82 |
| Model | OntoNotes 4.0 | MSRA | Resume | |
|---|---|---|---|---|
| baseline | 82.73 | 95.01 | 94.56 | 65.32 |
| + rel-att | 83.97 ↑1.24 | 95.77 ↑0.76 | 95.73 ↑1.17 | 68.55 ↑3.23 |
| + type-att | 84.81 ↑2.08 | 95.98 ↑0.97 | 96.34 ↑1.78 | 69.46 ↑4.14 |
| + rel-att & type-att | 85.68 ↑2.95 | 96.62 ↑1.61 | 96.96 ↑2.40 | 72.68 ↑7.36 |
| Model | SemEval 2017 | EBM-NLP |
|---|---|---|
| baseline | 52.55 | 66.15 |
| + rel-att | 55.69 ↑3.14 | 69.61 ↑3.46 |
| + type-att | 56.75 ↑4.20 | 70.24 ↑4.09 |
| + rel-att & type-att | 57.64 ↑5.09 | 71.89 ↑5.74 |
| Instance |
|---|
| instance #1: 中韩经贸研讨会即将在北京举行 |
| Pred: (中韩, GPE), (北京, GPE) |
| Gold: (中, GPE), (韩, GPE), (北京, GPE) |
| instance #2: the Office of Fair Trade called for British Airways/American to allow |
| third-party access to their joint frequent flyer programme where the |
| applicant does not have access to an equivalent programme. |
| Pred: (Office of Fair Trade, ORG), (British Airways American, ORG) |
| Gold: (Office of Fair Trade, ORG), (British Airways American, ORG) |
| instance #3: These data were converted to standard triangulation language (STL) surface |
| data as an aggregation of fine triangular meshes using 3D visualization and |
| measurement software (Amira version X, FEI, Burlington, MA, USA). |
| Pred: (standard triangulation language, Process), (triangular meshes, Material), |
| (3D visualization, Process) |
| Gold: (standard triangulation language, Process), (triangular meshes, Material), |
| (3D visualization, Process), (Amira version X, Material) |
| instance #4: South Africa’s trip to Kanpur for the third test against India has given |
| former England test cricketer Bob Woolmer the chance of a sentimental |
| return to his birthplace. |
| Pred: (South Africa, LOC), (Kanpur, LOC), (India, LOC), (England, LOC), |
| (Bob Woolmer, PER) (test cricketer, PER) |
| Gold: (South Africa, LOC), (Kanpur, LOC), (India, LOC), (England, LOC), |
| (Bob Woolmer, PER) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, Y.; Li, Z. Incorporating Entity Type-Aware and Word–Word Relation-Aware Attention in Generative Named Entity Recognition. Electronics 2024, 13, 1407. https://doi.org/10.3390/electronics13071407
Mo Y, Li Z. Incorporating Entity Type-Aware and Word–Word Relation-Aware Attention in Generative Named Entity Recognition. Electronics. 2024; 13(7):1407. https://doi.org/10.3390/electronics13071407
Chicago/Turabian StyleMo, Ying, and Zhoujun Li. 2024. "Incorporating Entity Type-Aware and Word–Word Relation-Aware Attention in Generative Named Entity Recognition" Electronics 13, no. 7: 1407. https://doi.org/10.3390/electronics13071407
APA StyleMo, Y., & Li, Z. (2024). Incorporating Entity Type-Aware and Word–Word Relation-Aware Attention in Generative Named Entity Recognition. Electronics, 13(7), 1407. https://doi.org/10.3390/electronics13071407