
Knowledge Graph Multi-Hop Question Answering Based on Dependent Syntactic Semantic Augmented Graph Networks


Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.1.1. Dataset and Settings
2.1.2. Experimental Environment
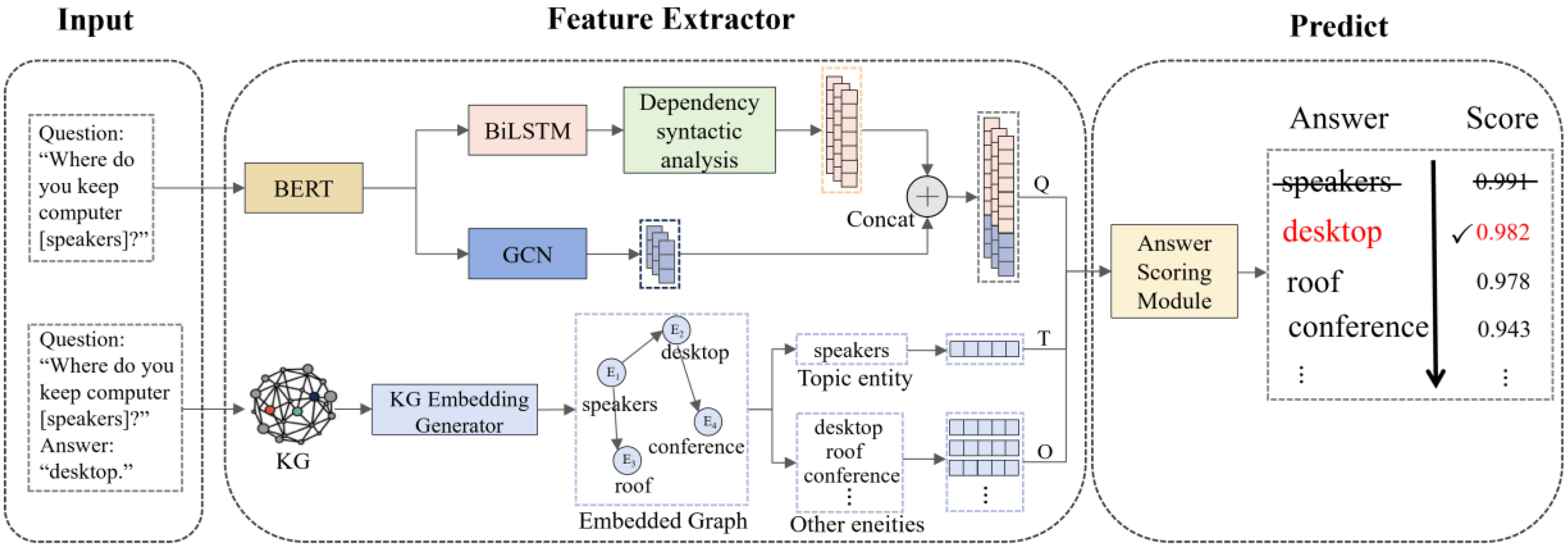
2.2. Methods
2.2.1. KG Embedding Generator
2.2.2. Dependent Syntactic Analysis Module
2.2.3. Graph Convolutional Network
2.2.4. Answer Scoring Module
3. Results
3.1. Comparative Experiments
3.2. Ablation Study
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge Graph Embedding Based Question Answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, Australia, 30 January 2019; ACM: Melbourne, VIC, Australia, 2019; pp. 105–113. [Google Scholar]
- Fu, B.; Qiu, Y.; Tang, C.; Li, Y.; Yu, H.; Sun, J. A Survey on Complex Question Answering over Knowledge Base: Recent Advances and Challenges. arXiv 2020, arXiv:2007.13069. [Google Scholar]
- Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; Zhao, J. An End-to-End Model for Question Answering over Knowledge Base with Cross-Attention Combining Global Knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 221–231. [Google Scholar]
- Petrochuk, M.; Zettlemoyer, L. SimpleQuestions Nearly Solved: A New Upperbound and Baseline Approach. arXiv 2018, arXiv:1804.08798. [Google Scholar]
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J.-R. A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions. arXiv 2021, arXiv:2105.11644. [Google Scholar]
- Mihaylov, T.; Clark, P.; Khot, T.; Sabharwal, A. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. arXiv 2018, arXiv:1809.02789. [Google Scholar]
- Kočiský, T.; Schwarz, J.; Blunsom, P.; Dyer, C.; Hermann, K.M.; Melis, G.; Grefenstette, E. The NarrativeQA Reading Comprehension Challenge. Trans. Assoc. Comput. Linguist. 2017, 6, 317–328. [Google Scholar] [CrossRef]
- Khashabi, D.; Chaturvedi, S.; Roth, M.; Upadhyay, S.; Roth, D. Looking Beyond the Surface: A Challenge Set for Reading Comprehension over Multiple Sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LO, USA, 1–6 June 2018; pp. 252–262. [Google Scholar]
- Welbl, J.; Stenetorp, P.; Riedel, S. Constructing Datasets for Multi-Hop Reading Comprehension Across Documents. TACL 2018, 6, 287–302. [Google Scholar] [CrossRef]
- Talmor, A.; Herzig, J.; Lourie, N.; Berant, J. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. arXiv 2019, arXiv:1811.00937. [Google Scholar]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A Dataset for Diverse, Explainable Multi-Hop Question Answering. arXiv 2018, arXiv:1809.09600. [Google Scholar]
- Min, S.; Zhong, V.; Zettlemoyer, L.; Hajishirzi, H. Multi-Hop Reading Comprehension through Question Decomposition and Rescoring. arXiv 2019, arXiv:1906.02916. [Google Scholar]
- Qiu, L.; Xiao, Y.; Qu, Y.; Zhou, H.; Li, L.; Zhang, W.; Yu, Y. Dynamically Fused Graph Network for Multi-Hop Reasoning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6140–6150. [Google Scholar]
- Jiang, Y.; Bansal, M. Self-Assembling Modular Networks for Interpretable Multi-Hop Reasoning. arXiv 2019, arXiv:1909.05803. [Google Scholar]
- Zhao, C.; Xiong, C.; Rosset, C.; Song, X.; Bennett, P.; Tiwary, S. Transformer-xh: Multi-evidence reasoning with extra hop attention. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Zhang, Q.; Weng, X.; Zhou, G.; Zhang, Y.; Huang, J.X. ARL: An Adaptive Reinforcement Learning Framework for Complex Question Answering over Knowledge Base. Inf. Process. Manag. 2022, 59, 102933. [Google Scholar] [CrossRef]
- Sun, X.; Cheng, H.; Li, J.; Liu, B.; Guan, J. All in One: Multi-Task Prompting for Graph Neural Networks. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ACM, Long Beach, CA, USA, 6 August 2023; pp. 2120–2131. [Google Scholar]
- Sun, X.; Cheng, H.; Liu, B.; Li, J.; Chen, H.; Xu, G.; Yin, H. Self-Supervised Hypergraph Representation Learning for Sociological Analysis. IEEE Trans. Knowl. Data Eng. 2023, 35, 11860–11871. [Google Scholar] [CrossRef]
- Cui, Z.; Sun, X.; Pan, L.; Liu, S.; Xu, G. Event-Based Incremental Recommendation via Factors Mixed Hawkes Process. Inf. Sci. 2023, 639, 119007. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, H.; Yang, H.; Sun, X.; Yu, P.S.; Xu, G. Graph Masked Autoencoders with Transformers. arXiv 2022, arXiv:2202.08391. [Google Scholar]
- Cui, Z.; Sun, X.; Chen, H.; Pan, L.; Cui, L.; Liu, S.; Xu, G. Dynamic Recommendation Based on Graph Diffusion and Ebbinghaus Curve. IEEE Trans. Comput. Soc. Syst. 2024, 11, 2755–2764. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the 6th ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Dhingra, B.; Jin, Q.; Yang, Z.; Cohen, W.W.; Salakhutdinov, R. Neural Models for Reasoning over Multiple Mentions Using Coreference. arXiv 2018, arXiv:1804.05922. [Google Scholar]
- Song, L.; Wang, Z.; Yu, M.; Zhang, Y.; Florian, R.; Gildea, D. Exploring Graph-Structured Passage Representation for Multi-Hop Reading Comprehension with Graph Neural Networks. arXiv 2018, arXiv:1809.02040. [Google Scholar]
- Huang, Y.; Yang, M. Breadth First Reasoning Graph for Multi-Hop Question Answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5810–5821. [Google Scholar]
- Li, X.-Y.; Lei, W.-J.; Yang, Y.-B. From Easy to Hard: Two-Stage Selector and Reader for Multi-Hop Question Answering. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4 June 2023; pp. 1–5. [Google Scholar]
- Zhang, G.; Liu, J.; Zhou, G.; Xie, Z.; Yu, X.; Cui, X. Query Path Generation via Bidirectional Reasoning for Multihop Question Answering from Knowledge Bases. IEEE Trans. Cogn. Dev. Syst. 2023, 15, 1183–1195. [Google Scholar] [CrossRef]
- Speer, R.; Chin, J.; Havasi, C. ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving Multi-Hop Question Answering over Knowledge Graphs Using Knowledge Base Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4498–4507. [Google Scholar]
- Jin, W.; Zhao, B.; Yu, H.; Tao, X.; Yin, R.; Liu, G. Improving Embedded Knowledge Graph Multi-Hop Question Answering by Introducing Relational Chain Reasoning. Data Min. Knowl. Disc. 2023, 37, 255–288. [Google Scholar] [CrossRef]
- Trouillon, T.; Welbl, J.; Riedel, S. Complex Embeddings for Simple Link Prediction. Proc. Mach. Learn. Res. 2016, 48, 2071–2080. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of the Advances in Neural Information Processing Systems 26, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Gangemi, A.; Navigli, R.; Vidal, M.-E.; Hitzler, P.; Troncy, R.; Hollink, L.; Tordai, A.; Alam, M. (Eds.) The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 10843, ISBN 978-3-319-93416-7. [Google Scholar]
- Wang, X.; Kapanipathi, P.; Musa, R.; Yu, M.; Talamadupula, K.; Abdelaziz, I.; Chang, M.; Fokoue, A.; Makni, B.; Mattei, N.; et al. Improving Natural Language Inference Using External Knowledge in the Science Questions Domain. AAAI 2019, 33, 7208–7215. [Google Scholar] [CrossRef]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning. arXiv 2019, arXiv:1909.02151. [Google Scholar]
- Feng, Y.; Chen, X.; Lin, B.Y.; Wang, P.; Yan, J.; Ren, X. Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering. arXiv 2020, arXiv:2005.00646. [Google Scholar]


{kind=link}
| Dataset | Training Set | Test Set | Validation Set |
|---|---|---|---|
| CommonsenseQA | 9741 | 1140 | 1221 |
| OpenbookQA | 4957 | 500 | 500 |
| Computer Information | Operating System | Windows 10 64-bit |
| CPU | Intel(R) Core (TM) i5-8265U CPU @ 1.60 GHz (8 CPUs) ~1.8 GHz | |
| GPU | RTX 3060 | |
| RAM | 16 GB | |
| Toolkit | Python 3.7 | Numpy 1.21.5 |
| Scikit_Learn 1.0.2 | ||
| Pandas 0.25.1 | ||
| Torch 1.12.0 | ||
| Matplotlib 3.5.2 |
| Model | CommonsenseQA | OpenbookQA | ||
|---|---|---|---|---|
| IHdev-Acc. (%) | IHtest-Acc. (%) | Dev-Acc. (%) | Test-Acc. (%) | |
| R-GCN * [35] | 56.72 (±0.42) | 53.90 (±0.62) | 63.51 (±1.81) | 61.83 (±1.60) |
| GconAttn * [36] | 56.37 (±0.72) | 53.64 (±0.78) | 62.62 (±1.07) | 61.21 (±2.14) |
| KagNet * [37] | 55.77 (±0.50) | 56.39 (±0.53) | 64.77 (±1.17) | 61.83 (±2.05) |
| MHGRN * [38] | 60.12 (±0.33) | 56.93 (±0.72) | 67.40 (±1.33) | 66.15 (±1.45) |
| Rce-KGQA * [32] | 61.52 (±0.42) | 59.18 (±0.63) | 67.72 (±1.13) | 66.45 (±1.29) |
| DSSAGN framework * | 63.22 (±0.20) | 62.35 (±0.45) | 68.52 (±0.93) | 67.38 (±1.05) |
| Model | CommonsenseQA | OpenbookQA | ||
|---|---|---|---|---|
| Training Time (min) | Testing Time (min) | Training Time (min) | Testing Time (min) | |
| R-GCN * [35] | 25.90 | 6.23 | 24.85 | 4.66 |
| GconAttn * [36] | 24.66 | 5.68 | 23.60 | 4.08 |
| KagNet * [37] | 22.05 | 4.88 | 19.55 | 3.26 |
| MHGRN * [38] | 21.25 | 4.45 | 19.03 | 3.05 |
| Rce-KGQA * [32] | 19.30 | 3.85 | 17.26 | 2.43 |
| DSSAGN framework * | 21.21 | 4.33 | 17.21 | 2.12 |
| Model | CommonsenseQA | OpenbookQA | ||
|---|---|---|---|---|
| IHdev-Acc. (%) | IHtest-Acc. (%) | Dev-Acc. (%) | Test-Acc. (%) | |
| Model 1 | 61.35 (±0.38) | 60.52 (±0.73) | 66.40 (±1.64) | 65.65 (±1.88) |
| Model 2 | 61.58 (±0.42) | 61.88 (±0.67) | 66.90 (±1.35) | 65.91 (±1.47) |
| Model 3 | 62.67 (±0.25) | 61.93 (±0.36) | 67.89 (±1.03) | 66.31 (±1.21) |
| DSSAGN framework | 63.22 (±0.20) | 62.35 (±0.45) | 68.52 (±0.93) | 67.38 (±1.05) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, S.; Ma, Q.; Hou, Y.; Zeng, G. Knowledge Graph Multi-Hop Question Answering Based on Dependent Syntactic Semantic Augmented Graph Networks. Electronics 2024, 13, 1436. https://doi.org/10.3390/electronics13081436
Cai S, Ma Q, Hou Y, Zeng G. Knowledge Graph Multi-Hop Question Answering Based on Dependent Syntactic Semantic Augmented Graph Networks. Electronics. 2024; 13(8):1436. https://doi.org/10.3390/electronics13081436
Chicago/Turabian StyleCai, Songtao, Qicheng Ma, Yupeng Hou, and Guangping Zeng. 2024. "Knowledge Graph Multi-Hop Question Answering Based on Dependent Syntactic Semantic Augmented Graph Networks" Electronics 13, no. 8: 1436. https://doi.org/10.3390/electronics13081436
APA StyleCai, S., Ma, Q., Hou, Y., & Zeng, G. (2024). Knowledge Graph Multi-Hop Question Answering Based on Dependent Syntactic Semantic Augmented Graph Networks. Electronics, 13(8), 1436. https://doi.org/10.3390/electronics13081436